 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Active Learning and Bayesian Optimization: a Unified Perspective to Learn with a Goal
Mar 08, 2023
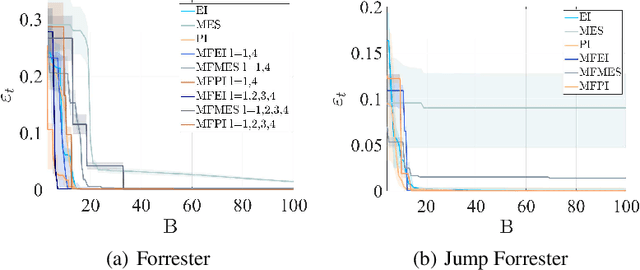
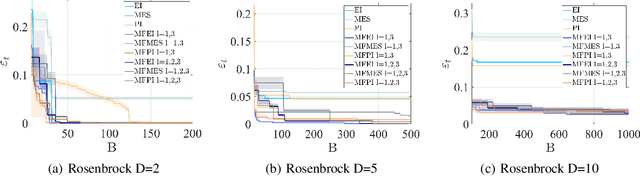
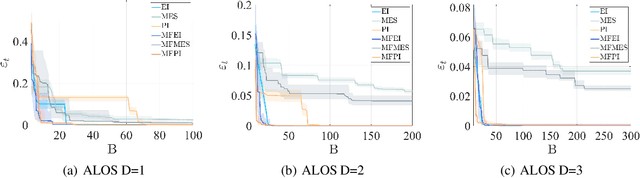
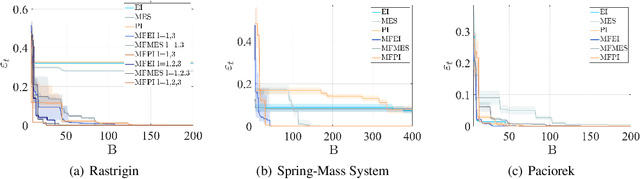
Both Bayesian optimization and active learning realize an adaptive sampling scheme to achieve a specific learning goal. However, while the two fields have seen an exponential growth in popularity in the past decade, their dualism has received relatively little attention. In this paper, we argue for an original unified perspective of Bayesian optimization and active learning based on the synergy between the principles driving the sampling policies. This symbiotic relationship is demonstrated through the substantial analogy between the infill criteria of Bayesian optimization and the learning criteria in active learning, and is formalized for the case of single information source and when multiple sources at different levels of fidelity are available. We further investigate the capabilities of each infill criteria both individually and in combination on a variety of analytical benchmark problems, to highlight benefits and limitations over mathematical properties that characterize real-world applications.
Uncertainty Driven Bottleneck Attention U-net for OAR Segmentation
Mar 19, 2023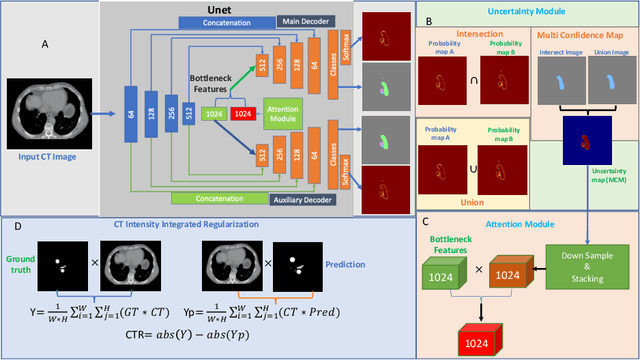
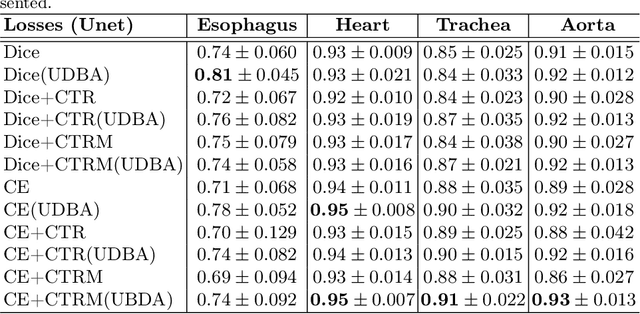

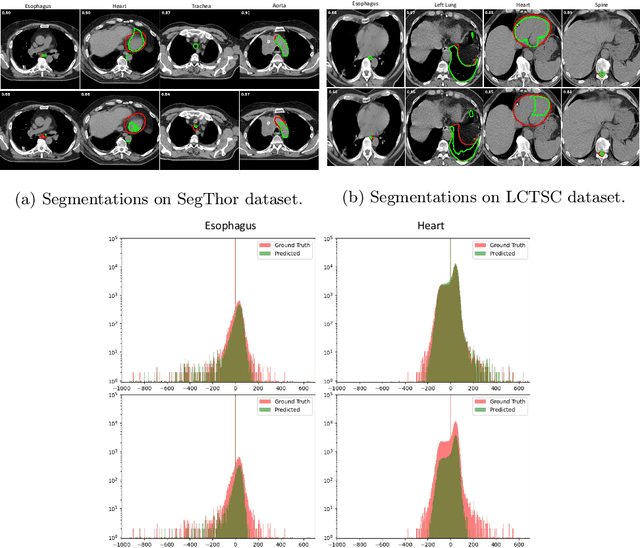
Organ at risk (OAR) segmentation in computed tomography (CT) imagery is a difficult task for automated segmentation methods and can be crucial for downstream radiation treatment planning. U-net has become a de-facto standard for medical image segmentation and is frequently used as a common baseline in medical image segmentation tasks. In this paper, we develop a multiple decoder U-net architecture where a noisy auxiliary decoder is used to generate noisy segmentation. The segmentation from the main branch and the noisy segmentation from the auxiliary branch are used together to estimate the attention. Our contribution is the development of a new attention module which derives the attention from the softmax probabilities of two decoder branches. The union and intersection of two segmentation masks from two branches carry the information where both decoders agree and disagree. The softmax probabilities from regions of agreement and disagreement are the indicators of low and high uncertainty. Thus, the probabilities of those selected regions are used as attention in the bottleneck layer of the encoder and passes only through the main decoder for segmentation. For accurate contour segmentation, we also developed a CT intensity integrated regularization loss. We tested our model on two publicly available OAR challenge datasets, Segthor and LCTSC respectively. We trained 12 models on each dataset with and without the proposed attention model and regularization loss to check the effectiveness of the attention module and the regularization loss. The experiments demonstrate a clear accuracy improvement (2\% to 5\% Dice) on both datasets. Code for the experiments will be made available upon the acceptance for publication.
Extracting Victim Counts from Text
Feb 23, 2023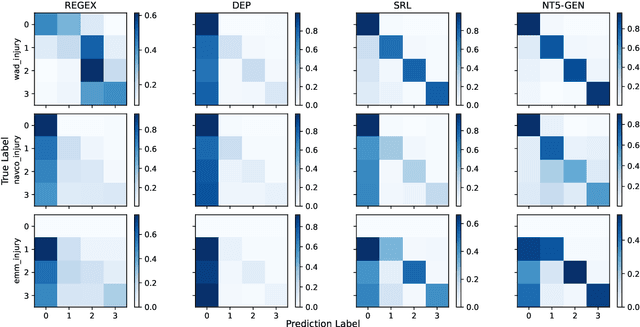
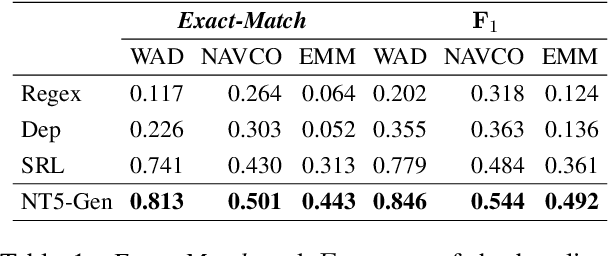

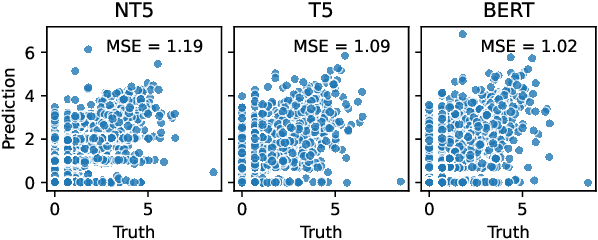
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.
XL-MIMO Channel Modeling and Prediction for Wireless Power Transfer
Feb 23, 2023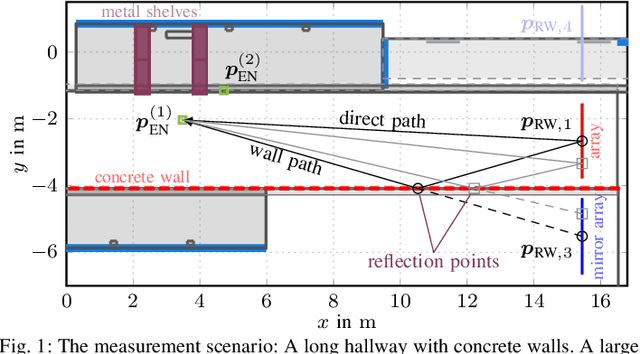
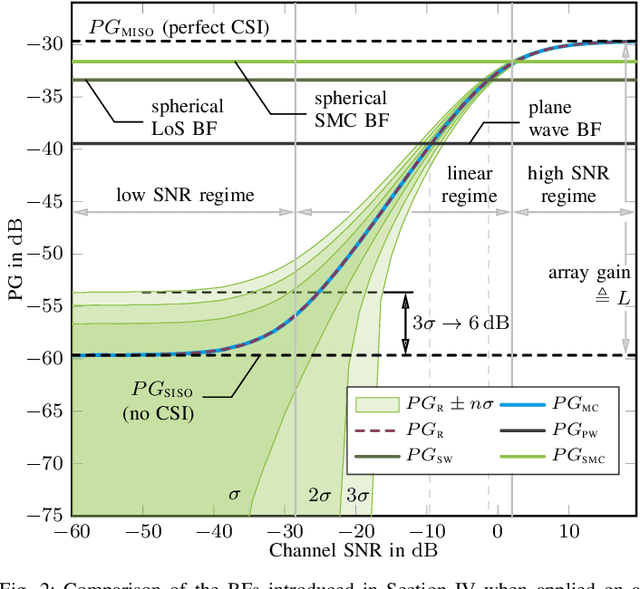
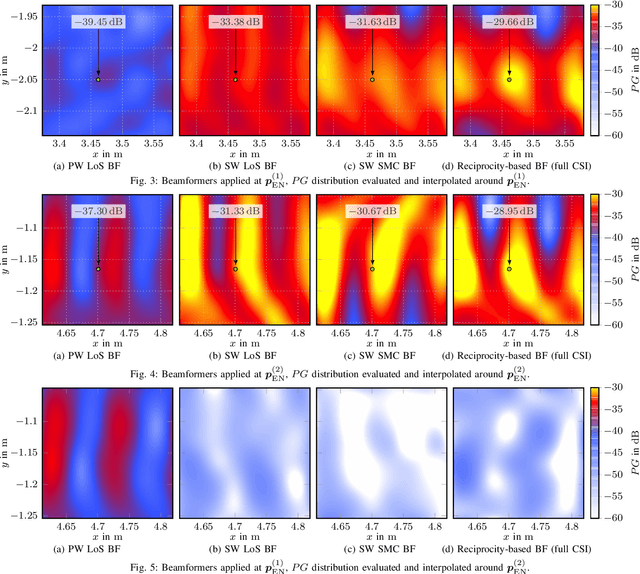
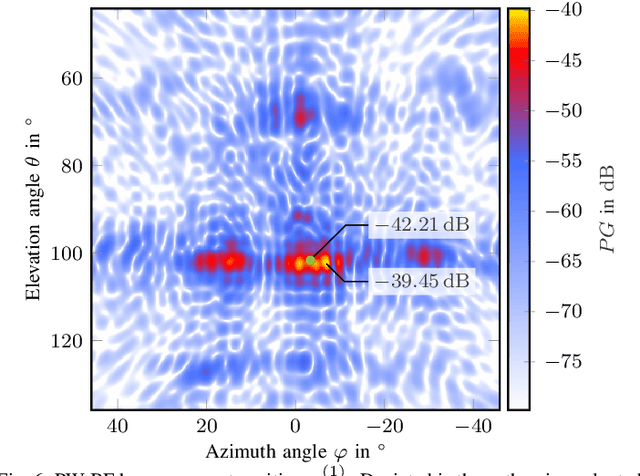
Massive antenna arrays form physically large apertures with a beam-focusing capability, leading to outstanding wireless power transfer (WPT) efficiency paired with low radiation levels outside the focusing region. However, leveraging these features requires accurate knowledge of the multipath propagation channel and overcoming the (Rayleigh) fading channel present in typical application scenarios. For that, reciprocity-based beamforming is an optimal solution that estimates the actual channel gains from pilot transmissions on the uplink. But this solution is unsuitable for passive backscatter nodes that are not capable of sending any pilots in the initial access phase. Using measured channel data from an extremely large-scale MIMO (XL-MIMO) testbed, we compare geometry-based planar wavefront and spherical wavefront beamformers with a reciprocity-based beamformer, to address this initial access problem. We also show that we can predict specular multipath components (SMCs) based only on geometric environment information. We demonstrate that a transmit power of 1W is sufficient to transfer more than 1mW of power to a device located at a distance of 12.3m when using a (40x25) array at 3.8GHz. The geometry-based beamformer exploiting predicted SMCs suffers a loss of only 2dB compared with perfect channel state information.
Single Cells Are Spatial Tokens: Transformers for Spatial Transcriptomic Data Imputation
Feb 06, 2023
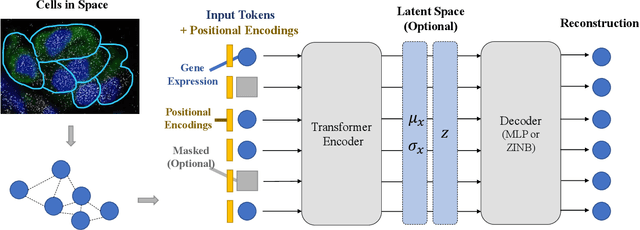
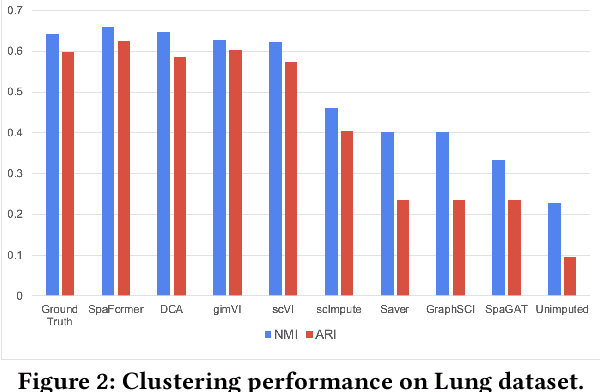
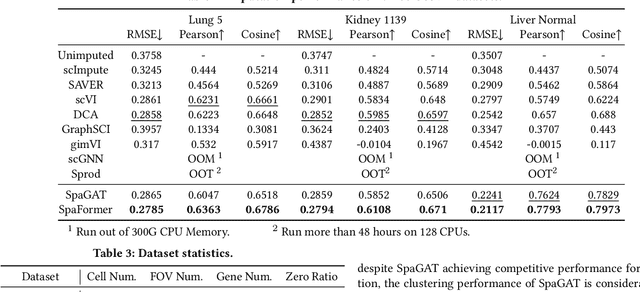
Spatially resolved transcriptomics brings exciting breakthroughs to single-cell analysis by providing physical locations along with gene expression. However, as a cost of the extremely high spatial resolution, the cellular level spatial transcriptomic data suffer significantly from missing values. While a standard solution is to perform imputation on the missing values, most existing methods either overlook spatial information or only incorporate localized spatial context without the ability to capture long-range spatial information. Using multi-head self-attention mechanisms and positional encoding, transformer models can readily grasp the relationship between tokens and encode location information. In this paper, by treating single cells as spatial tokens, we study how to leverage transformers to facilitate spatial tanscriptomics imputation. In particular, investigate the following two key questions: (1) $\textit{how to encode spatial information of cells in transformers}$, and (2) $\textit{ how to train a transformer for transcriptomic imputation}$. By answering these two questions, we present a transformer-based imputation framework, SpaFormer, for cellular-level spatial transcriptomic data. Extensive experiments demonstrate that SpaFormer outperforms existing state-of-the-art imputation algorithms on three large-scale datasets.
Mind meets machine: Unravelling GPT-4's cognitive psychology
Mar 20, 2023
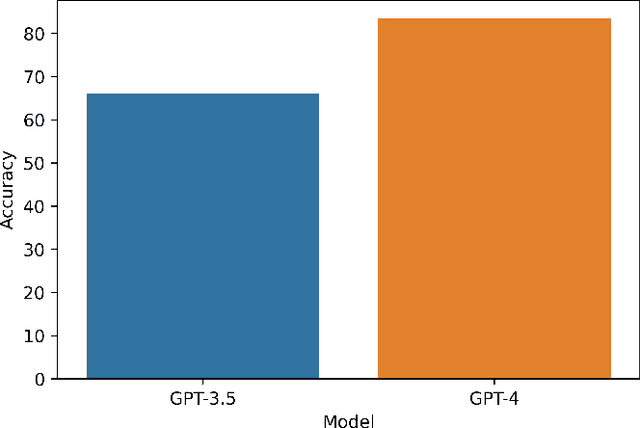
Commonsense reasoning is a basic ingredient of intelligence in humans, empowering the ability to deduce conclusions based on the observations of surroundings. Large language models (LLMs) are emerging as potent tools increasingly capable of performing human-level tasks. The recent development in the form of GPT-4 and its demonstrated success in tasks complex to humans such as medical exam, bar exam and others has led to an increased confidence in the LLMs to become perfect instruments of intelligence. Though, the GPT-4 paper has shown performance on some common sense reasoning tasks, a comprehensive assessment of GPT-4 on common sense reasoning tasks, particularly on the existing well-established datasets is missing. In this study, we focus on the evaluation of GPT-4's performance on a set of common sense reasoning questions from the widely used CommonsenseQA dataset along with tools from cognitive psychology. In doing so, we understand how GPT-4 processes and integrates common sense knowledge with contextual information, providing insight into the underlying cognitive processes that enable its ability to generate common sense responses. We show that GPT-4 exhibits a high level of accuracy in answering common sense questions, outperforming its predecessor, GPT-3 and GPT-3.5. We show that the accuracy of GPT-4 on CommonSenseQA is 83 % and it has been shown in the original study that human accuracy over the same data was 89 %. Although, GPT-4 falls short of the human performance, it is a substantial improvement from the original 56.5 % in the original language model used by the CommonSenseQA study. Our results strengthen the already available assessments and confidence on GPT-4's common sense reasoning abilities which have significant potential to revolutionize the field of AI, by enabling machines to bridge the gap between human and machine reasoning.
Approaching an unknown communication system by latent space exploration and causal inference
Mar 20, 2023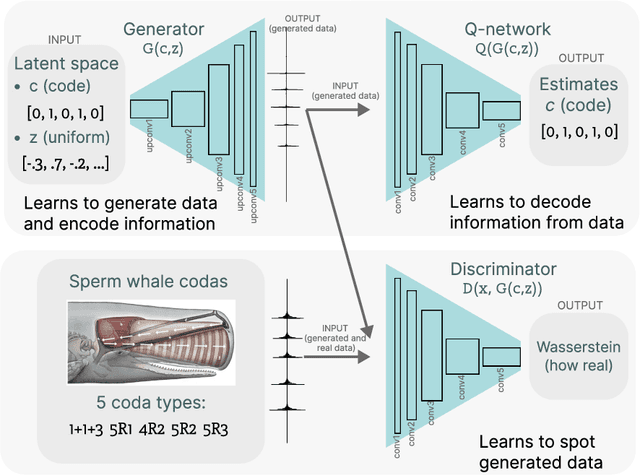
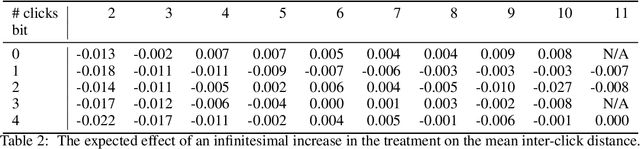
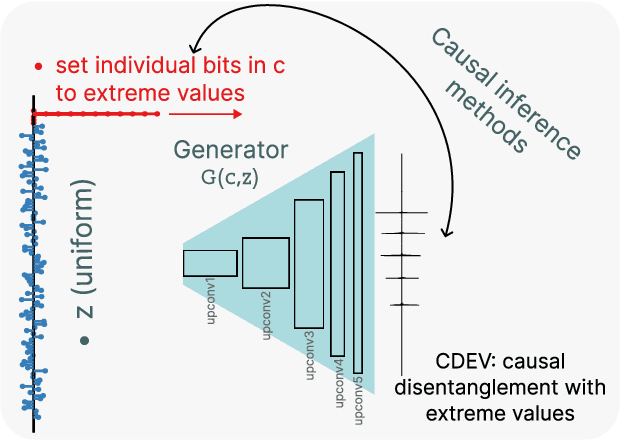
This paper proposes a methodology for discovering meaningful properties in data by exploring the latent space of unsupervised deep generative models. We combine manipulation of individual latent variables to extreme values outside the training range with methods inspired by causal inference into an approach we call causal disentanglement with extreme values (CDEV) and show that this approach yields insights for model interpretability. Using this technique, we can infer what properties of unknown data the model encodes as meaningful. We apply the methodology to test what is meaningful in the communication system of sperm whales, one of the most intriguing and understudied animal communication systems. We train a network that has been shown to learn meaningful representations of speech and test whether we can leverage such unsupervised learning to decipher the properties of another vocal communication system for which we have no ground truth. The proposed technique suggests that sperm whales encode information using the number of clicks in a sequence, the regularity of their timing, and audio properties such as the spectral mean and the acoustic regularity of the sequences. Some of these findings are consistent with existing hypotheses, while others are proposed for the first time. We also argue that our models uncover rules that govern the structure of communication units in the sperm whale communication system and apply them while generating innovative data not shown during training. This paper suggests that an interpretation of the outputs of deep neural networks with causal methodology can be a viable strategy for approaching data about which little is known and presents another case of how deep learning can limit the hypothesis space. Finally, the proposed approach combining latent space manipulation and causal inference can be extended to other architectures and arbitrary datasets.
Convergence analysis and acceleration of the smoothing methods for solving extensive-form games
Mar 20, 2023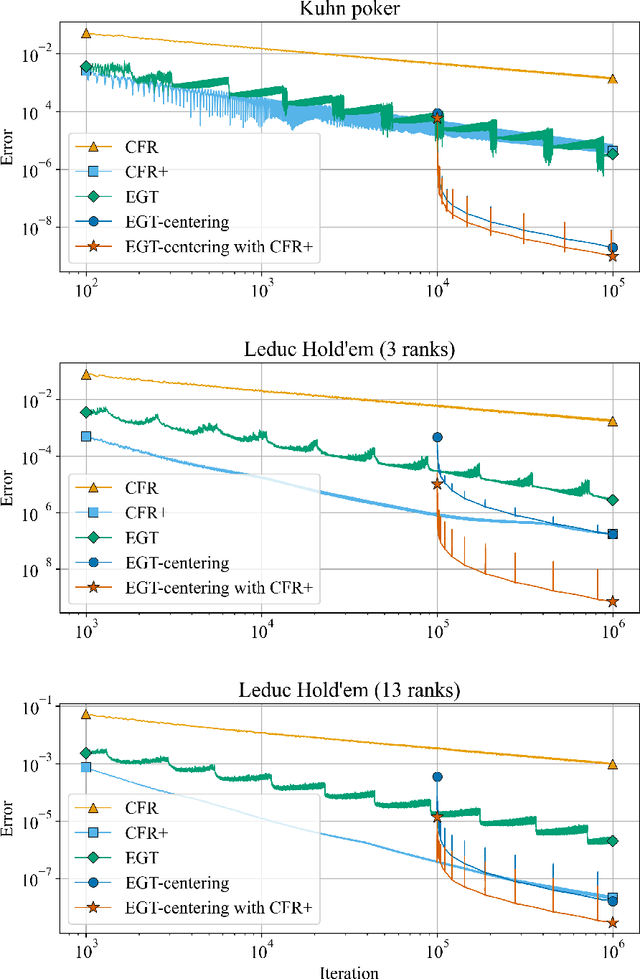
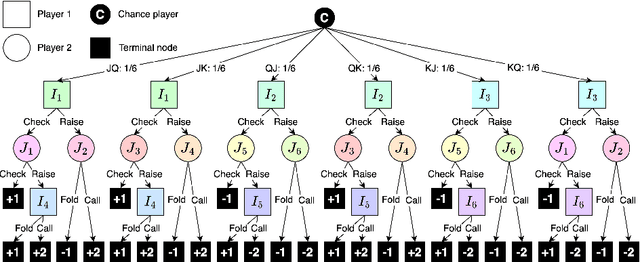

The extensive-form game has been studied considerably in recent years. It can represent games with multiple decision points and incomplete information, and hence it is helpful in formulating games with uncertain inputs, such as poker. We consider an extended-form game with two players and zero-sum, i.e., the sum of their payoffs is always zero. In such games, the problem of finding the optimal strategy can be formulated as a bilinear saddle-point problem. This formulation grows huge depending on the size of the game, since it has variables representing the strategies at all decision points for each player. To solve such large-scale bilinear saddle-point problems, the excessive gap technique (EGT), a smoothing method, has been studied. This method generates a sequence of approximate solutions whose error is guaranteed to converge at $\mathcal{O}(1/k)$, where $k$ is the number of iterations. However, it has the disadvantage of having poor theoretical bounds on the error related to the game size. This makes it inapplicable to large games. Our goal is to improve the smoothing method for solving extensive-form games so that it can be applied to large-scale games. To this end, we make two contributions in this work. First, we slightly modify the strongly convex function used in the smoothing method in order to improve the theoretical bounds related to the game size. Second, we propose a heuristic called centering trick, which allows the smoothing method to be combined with other methods and consequently accelerates the convergence in practice. As a result, we combine EGT with CFR+, a state-of-the-art method for extensive-form games, to achieve good performance in games where conventional smoothing methods do not perform well. The proposed smoothing method is shown to have the potential to solve large games in practice.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023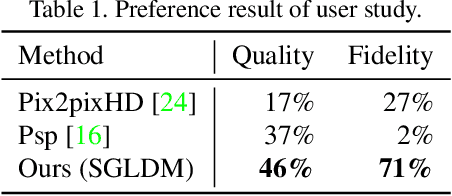

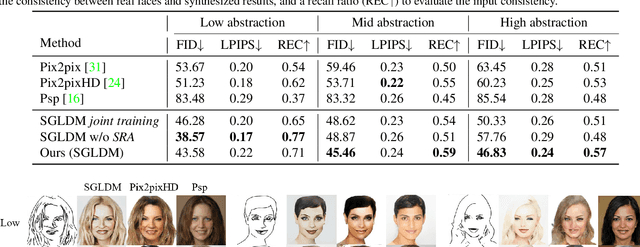
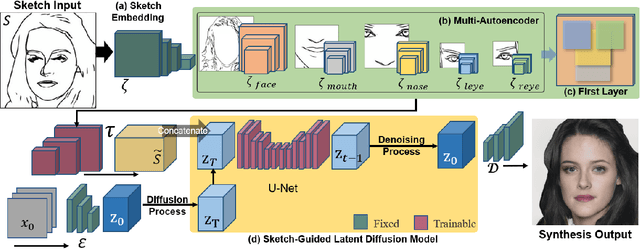
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Artificial Influence: An Analysis Of AI-Driven Persuasion
Mar 15, 2023Persuasion is a key aspect of what it means to be human, and is central to business, politics, and other endeavors. Advancements in artificial intelligence (AI) have produced AI systems that are capable of persuading humans to buy products, watch videos, click on search results, and more. Even systems that are not explicitly designed to persuade may do so in practice. In the future, increasingly anthropomorphic AI systems may form ongoing relationships with users, increasing their persuasive power. This paper investigates the uncertain future of persuasive AI systems. We examine ways that AI could qualitatively alter our relationship to and views regarding persuasion by shifting the balance of persuasive power, allowing personalized persuasion to be deployed at scale, powering misinformation campaigns, and changing the way humans can shape their own discourse. We consider ways AI-driven persuasion could differ from human-driven persuasion. We warn that ubiquitous highlypersuasive AI systems could alter our information environment so significantly so as to contribute to a loss of human control of our own future. In response, we examine several potential responses to AI-driven persuasion: prohibition, identification of AI agents, truthful AI, and legal remedies. We conclude that none of these solutions will be airtight, and that individuals and governments will need to take active steps to guard against the most pernicious effects of persuasive AI.