 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extracting Victim Counts from Text
Feb 23, 2023
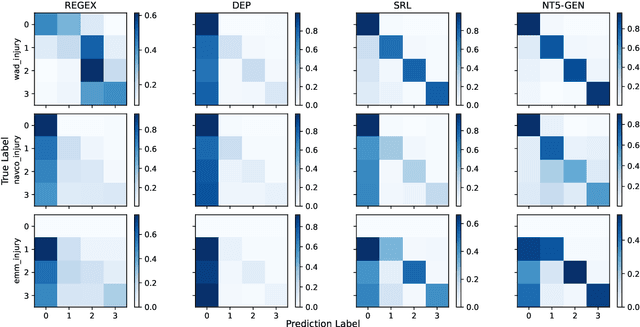
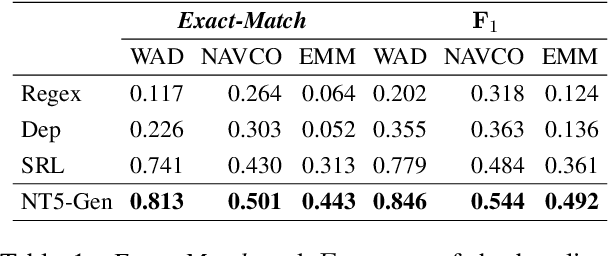

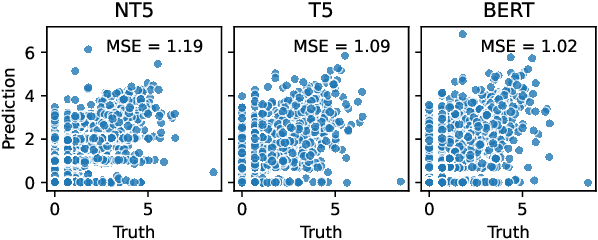
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.
XL-MIMO Channel Modeling and Prediction for Wireless Power Transfer
Feb 23, 2023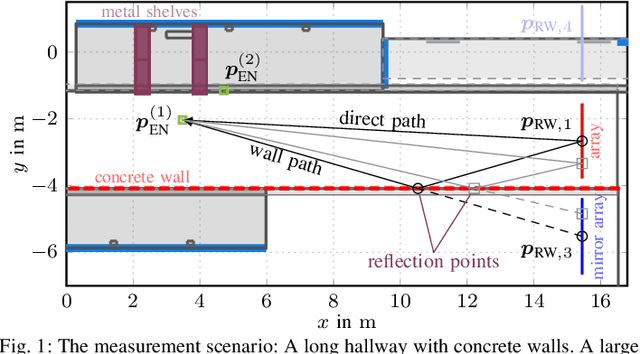
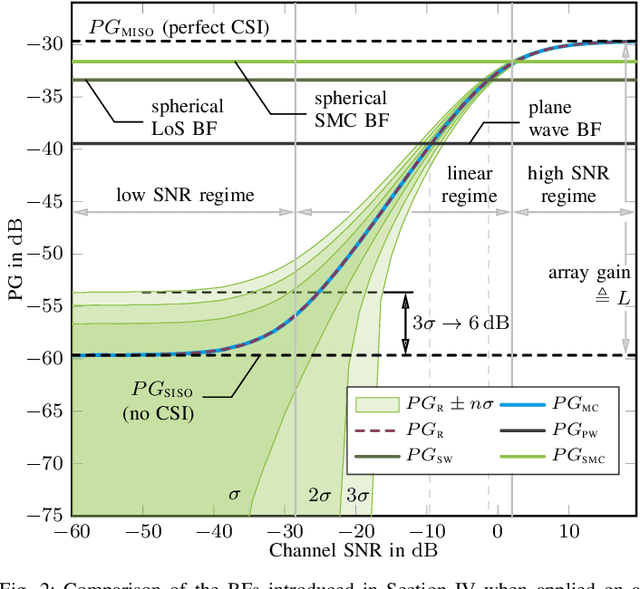
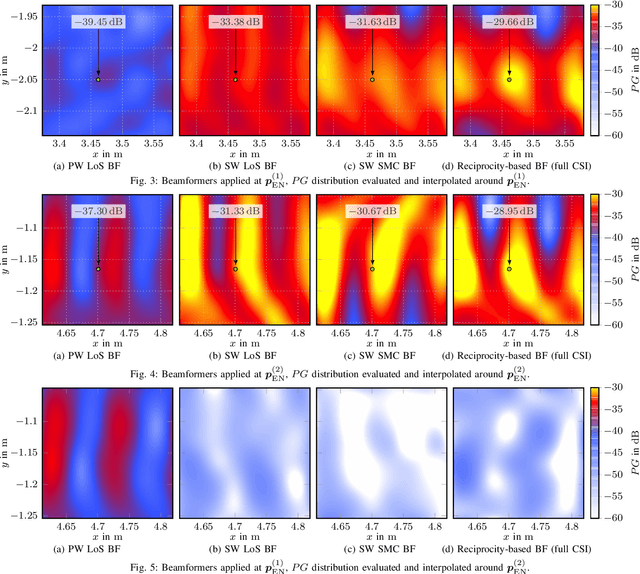
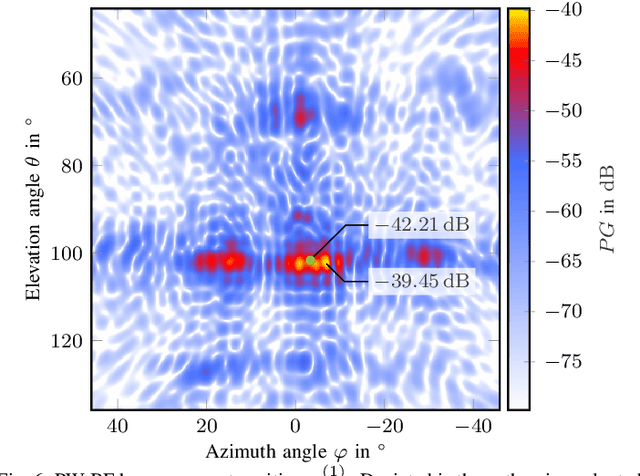
Massive antenna arrays form physically large apertures with a beam-focusing capability, leading to outstanding wireless power transfer (WPT) efficiency paired with low radiation levels outside the focusing region. However, leveraging these features requires accurate knowledge of the multipath propagation channel and overcoming the (Rayleigh) fading channel present in typical application scenarios. For that, reciprocity-based beamforming is an optimal solution that estimates the actual channel gains from pilot transmissions on the uplink. But this solution is unsuitable for passive backscatter nodes that are not capable of sending any pilots in the initial access phase. Using measured channel data from an extremely large-scale MIMO (XL-MIMO) testbed, we compare geometry-based planar wavefront and spherical wavefront beamformers with a reciprocity-based beamformer, to address this initial access problem. We also show that we can predict specular multipath components (SMCs) based only on geometric environment information. We demonstrate that a transmit power of 1W is sufficient to transfer more than 1mW of power to a device located at a distance of 12.3m when using a (40x25) array at 3.8GHz. The geometry-based beamformer exploiting predicted SMCs suffers a loss of only 2dB compared with perfect channel state information.
Automated Ensemble Search Framework for Semantic Segmentation Using Medical Imaging Labels
Mar 14, 2023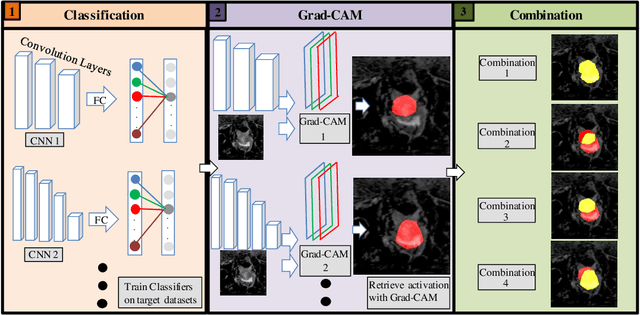
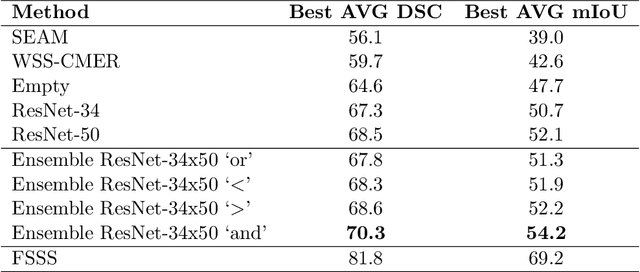
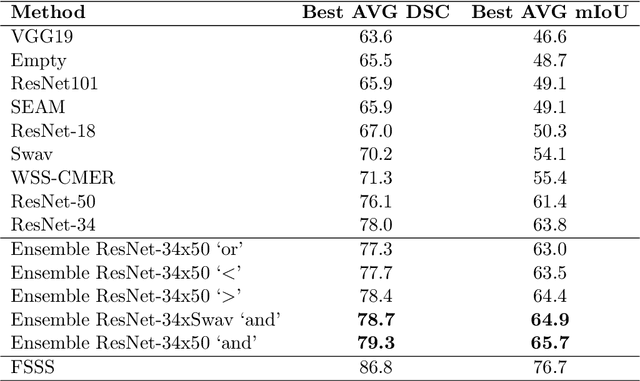
Reliable classification and detection of certain medical conditions, in images, with state-of-the-art semantic segmentation networks, require vast amounts of pixel-wise annotation. However, the public availability of such datasets is minimal. Therefore, semantic segmentation with image-level labels presents a promising alternative to this problem. Nevertheless, very few works have focused on evaluating this technique and its applicability to the medical sector. Due to their complexity and the small number of training examples in medical datasets, classifier-based weakly supervised networks like class activation maps (CAMs) struggle to extract useful information from them. However, most state-of-the-art approaches rely on them to achieve their improvements. Therefore, we propose a framework that can still utilize the low-quality CAM predictions of complicated datasets to improve the accuracy of our results. Our framework achieves that by first utilizing lower threshold CAMs to cover the target object with high certainty; second, by combining multiple low-threshold CAMs that even out their errors while highlighting the target object. We performed exhaustive experiments on the popular multi-modal BRATS and prostate DECATHLON segmentation challenge datasets. Using the proposed framework, we have demonstrated an improved dice score of up to 8% on BRATS and 6% on DECATHLON datasets compared to the previous state-of-the-art.
BoundaryCAM: A Boundary-based Refinement Framework for Weakly Supervised Semantic Segmentation of Medical Images
Mar 14, 2023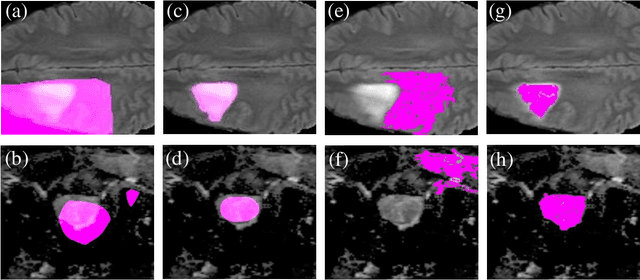
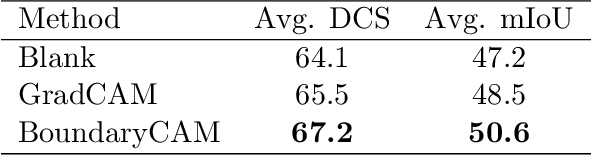
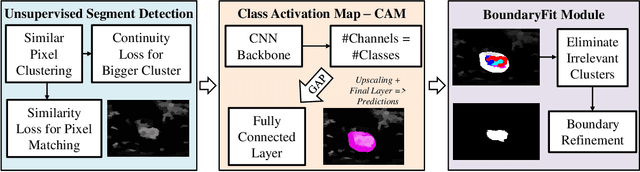
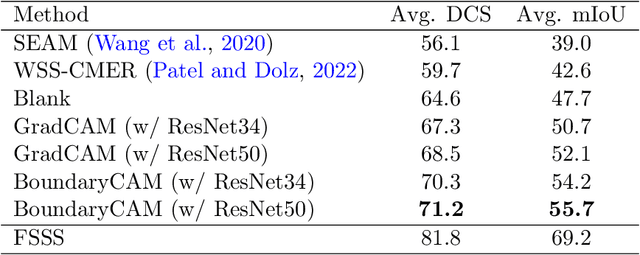
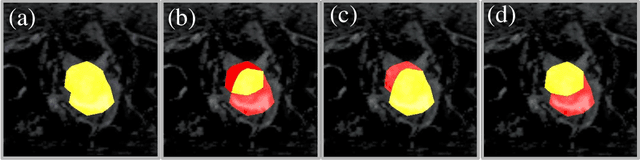
Weakly Supervised Semantic Segmentation (WSSS) with only image-level supervision is a promising approach to deal with the need for Segmentation networks, especially for generating a large number of pixel-wise masks in a given dataset. However, most state-of-the-art image-level WSSS techniques lack an understanding of the geometric features embedded in the images since the network cannot derive any object boundary information from just image-level labels. We define a boundary here as the line separating an object and its background, or two different objects. To address this drawback, we propose our novel BoundaryCAM framework, which deploys state-of-the-art class activation maps combined with various post-processing techniques in order to achieve fine-grained higher-accuracy segmentation masks. To achieve this, we investigate a state-of-the-art unsupervised semantic segmentation network that can be used to construct a boundary map, which enables BoundaryCAM to predict object locations with sharper boundaries. By applying our method to WSSS predictions, we were able to achieve up to 10% improvements even to the benefit of the current state-of-the-art WSSS methods for medical imaging. The framework is open-source and accessible online at https://github.com/bharathprabakaran/BoundaryCAM.
Disentangled Graph Social Recommendation
Mar 14, 2023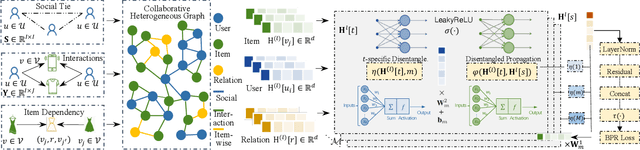
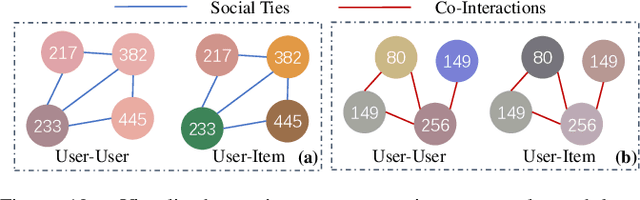
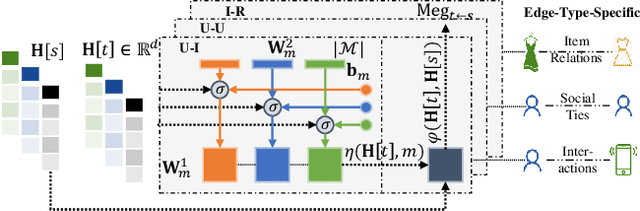
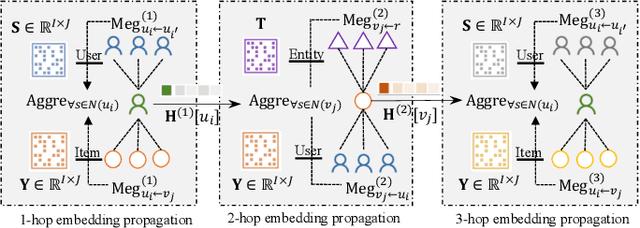
Social recommender systems have drawn a lot of attention in many online web services, because of the incorporation of social information between users in improving recommendation results. Despite the significant progress made by existing solutions, we argue that current methods fall short in two limitations: (1) Existing social-aware recommendation models only consider collaborative similarity between items, how to incorporate item-wise semantic relatedness is less explored in current recommendation paradigms. (2) Current social recommender systems neglect the entanglement of the latent factors over heterogeneous relations (e.g., social connections, user-item interactions). Learning the disentangled representations with relation heterogeneity poses great challenge for social recommendation. In this work, we design a Disentangled Graph Neural Network (DGNN) with the integration of latent memory units, which empowers DGNN to maintain factorized representations for heterogeneous types of user and item connections. Additionally, we devise new memory-augmented message propagation and aggregation schemes under the graph neural architecture, allowing us to recursively distill semantic relatedness into the representations of users and items in a fully automatic manner. Extensive experiments on three benchmark datasets verify the effectiveness of our model by achieving great improvement over state-of-the-art recommendation techniques. The source code is publicly available at: https://github.com/HKUDS/DGNN.
VE-KWS: Visual Modality Enhanced End-to-End Keyword Spotting
Mar 14, 2023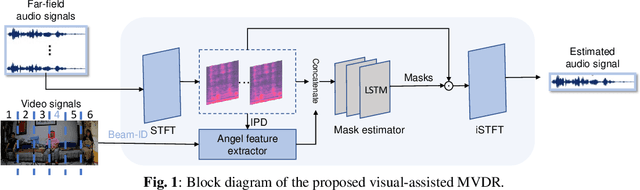
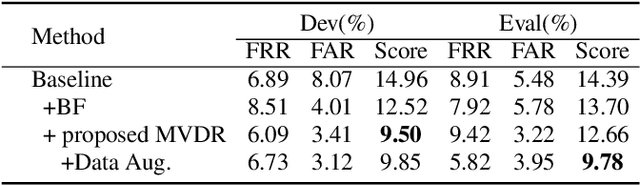
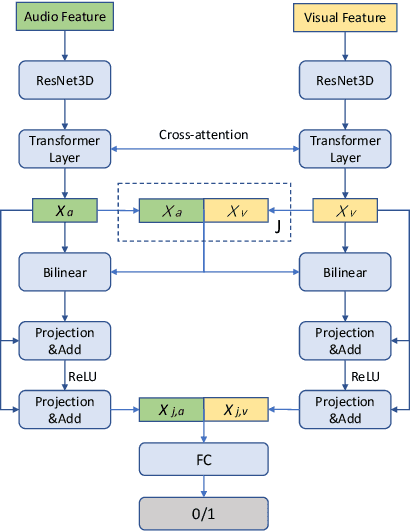

The performance of the keyword spotting (KWS) system based on audio modality, commonly measured in false alarms and false rejects, degrades significantly under the far field and noisy conditions. Therefore, audio-visual keyword spotting, which leverages complementary relationships over multiple modalities, has recently gained much attention. However, current studies mainly focus on combining the exclusively learned representations of different modalities, instead of exploring the modal relationships during each respective modeling. In this paper, we propose a novel visual modality enhanced end-to-end KWS framework (VE-KWS), which fuses audio and visual modalities from two aspects. The first one is utilizing the speaker location information obtained from the lip region in videos to assist the training of multi-channel audio beamformer. By involving the beamformer as an audio enhancement module, the acoustic distortions, caused by the far field or noisy environments, could be significantly suppressed. The other one is conducting cross-attention between different modalities to capture the inter-modal relationships and help the representation learning of each modality. Experiments on the MSIP challenge corpus show that our proposed model achieves 2.79% false rejection rate and 2.95% false alarm rate on the Eval set, resulting in a new SOTA performance compared with the top-ranking systems in the ICASSP2022 MISP challenge.
Time-aware Multiway Adaptive Fusion Network for Temporal Knowledge Graph Question Answering
Mar 14, 2023
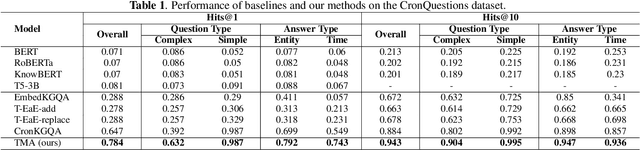
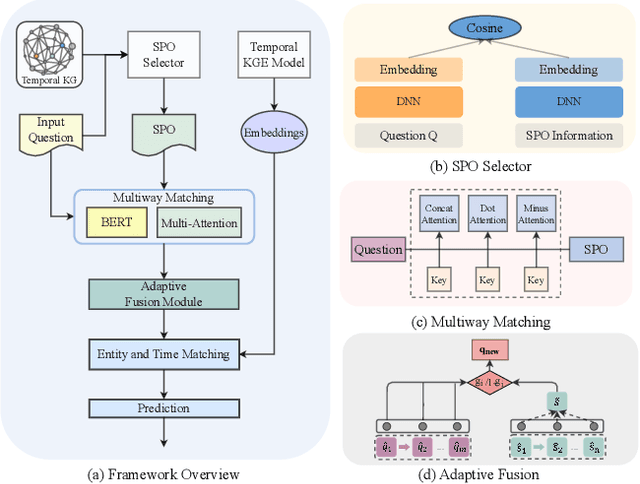
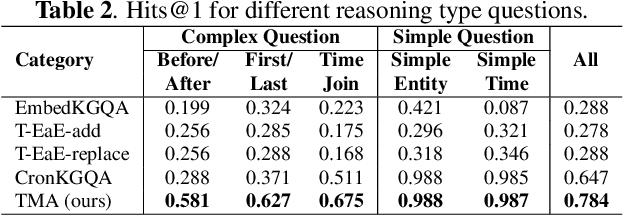
Knowledge graphs (KGs) have received increasing attention due to its wide applications on natural language processing. However, its use case on temporal question answering (QA) has not been well-explored. Most of existing methods are developed based on pre-trained language models, which might not be capable to learn \emph{temporal-specific} presentations of entities in terms of temporal KGQA task. To alleviate this problem, we propose a novel \textbf{T}ime-aware \textbf{M}ultiway \textbf{A}daptive (\textbf{TMA}) fusion network. Inspired by the step-by-step reasoning behavior of humans. For each given question, TMA first extracts the relevant concepts from the KG, and then feeds them into a multiway adaptive module to produce a \emph{temporal-specific} representation of the question. This representation can be incorporated with the pre-trained KG embedding to generate the final prediction. Empirical results verify that the proposed model achieves better performance than the state-of-the-art models in the benchmark dataset. Notably, the Hits@1 and Hits@10 results of TMA on the CronQuestions dataset's complex questions are absolutely improved by 24\% and 10\% compared to the best-performing baseline. Furthermore, we also show that TMA employing an adaptive fusion mechanism can provide interpretability by analyzing the proportion of information in question representations.
* ICASSP 2023
Tensor-based Multimodal Learning for Prediction of Pulmonary Arterial Wedge Pressure from Cardiac MRI
Mar 14, 2023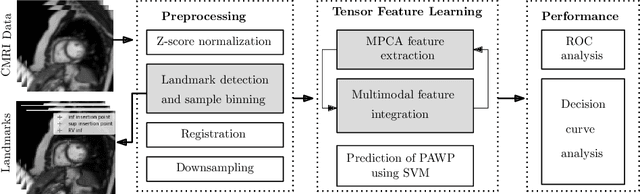
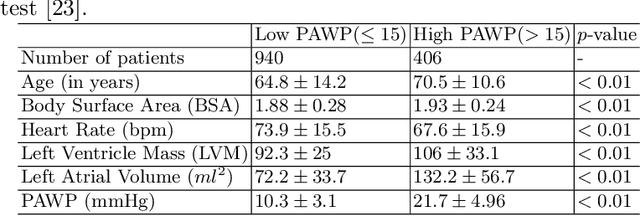
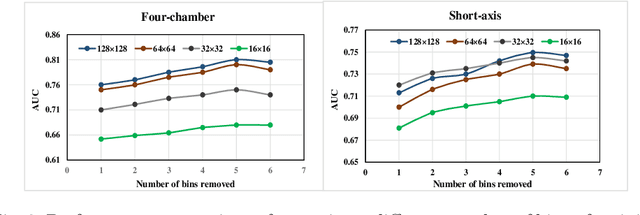
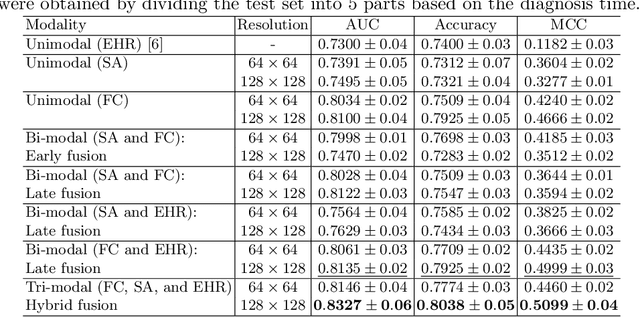
Heart failure is a serious and life-threatening condition that can lead to elevated pressure in the left ventricle. Pulmonary Arterial Wedge Pressure (PAWP) is an important surrogate marker indicating high pressure in the left ventricle. PAWP is determined by Right Heart Catheterization (RHC) but it is an invasive procedure. A non-invasive method is useful in quickly identifying high-risk patients from a large population. In this work, we develop a tensor learning-based pipeline for identifying PAWP from multimodal cardiac Magnetic Resonance Imaging (MRI). This pipeline extracts spatial and temporal features from high-dimensional scans. For quality control, we incorporate an epistemic uncertainty-based binning strategy to identify poor-quality training samples. To improve the performance, we learn complementary information by integrating features from multimodal data: cardiac MRI with short-axis and four-chamber views, and Electronic Health Records. The experimental analysis on a large cohort of $1346$ subjects who underwent the RHC procedure for PAWP estimation indicates that the proposed pipeline has a diagnostic value and can produce promising performance with significant improvement over the baseline in clinical practice (i.e., $\Delta$AUC $=0.10$, $\Delta$Accuracy $=0.06$, and $\Delta$MCC $=0.39$). The decision curve analysis further confirms the clinical utility of our method.
FPUS23: An Ultrasound Fetus Phantom Dataset with Deep Neural Network Evaluations for Fetus Orientations, Fetal Planes, and Anatomical Features
Mar 14, 2023
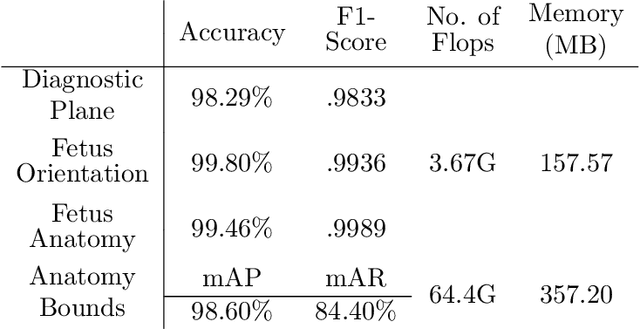

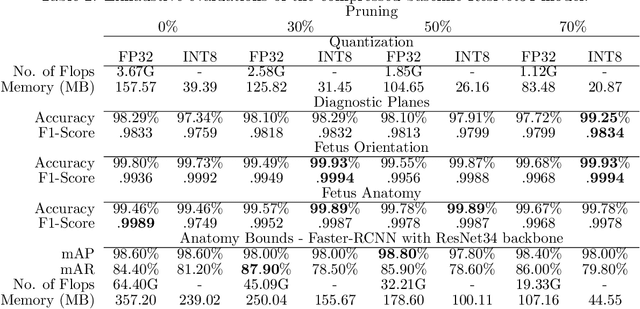
Ultrasound imaging is one of the most prominent technologies to evaluate the growth, progression, and overall health of a fetus during its gestation. However, the interpretation of the data obtained from such studies is best left to expert physicians and technicians who are trained and well-versed in analyzing such images. To improve the clinical workflow and potentially develop an at-home ultrasound-based fetal monitoring platform, we present a novel fetus phantom ultrasound dataset, FPUS23, which can be used to identify (1) the correct diagnostic planes for estimating fetal biometric values, (2) fetus orientation, (3) their anatomical features, and (4) bounding boxes of the fetus phantom anatomies at 23 weeks gestation. The entire dataset is composed of 15,728 images, which are used to train four different Deep Neural Network models, built upon a ResNet34 backbone, for detecting aforementioned fetus features and use-cases. We have also evaluated the models trained using our FPUS23 dataset, to show that the information learned by these models can be used to substantially increase the accuracy on real-world ultrasound fetus datasets. We make the FPUS23 dataset and the pre-trained models publicly accessible at https://github.com/bharathprabakaran/FPUS23, which will further facilitate future research on fetal ultrasound imaging and analysis.
A Theory of Emergent In-Context Learning as Implicit Structure Induction
Mar 14, 2023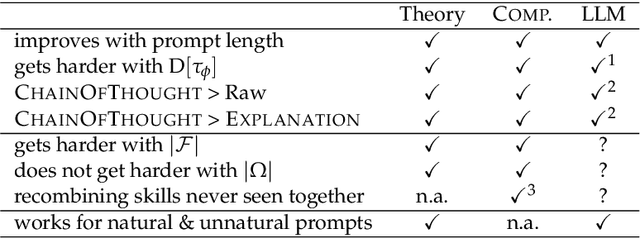
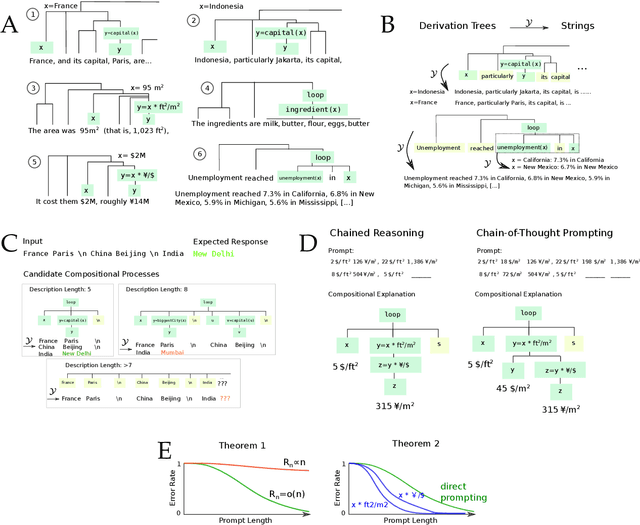


Scaling large language models (LLMs) leads to an emergent capacity to learn in-context from example demonstrations. Despite progress, theoretical understanding of this phenomenon remains limited. We argue that in-context learning relies on recombination of compositional operations found in natural language data. We derive an information-theoretic bound showing how in-context learning abilities arise from generic next-token prediction when the pretraining distribution has sufficient amounts of compositional structure, under linguistically motivated assumptions. A second bound provides a theoretical justification for the empirical success of prompting LLMs to output intermediate steps towards an answer. To validate theoretical predictions, we introduce a controlled setup for inducing in-context learning; unlike previous approaches, it accounts for the compositional nature of language. Trained transformers can perform in-context learning for a range of tasks, in a manner consistent with the theoretical results. Mirroring real-world LLMs in a miniature setup, in-context learning emerges when scaling parameters and data, and models perform better when prompted to output intermediate steps. Probing shows that in-context learning is supported by a representation of the input's compositional structure. Taken together, these results provide a step towards theoretical understanding of emergent behavior in large language models.