 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EmotionIC: Emotional Inertia and Contagion-driven Dependency Modelling for Emotion Recognition in Conversation
Mar 22, 2023
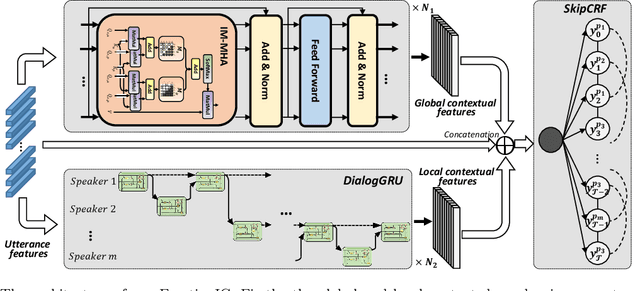
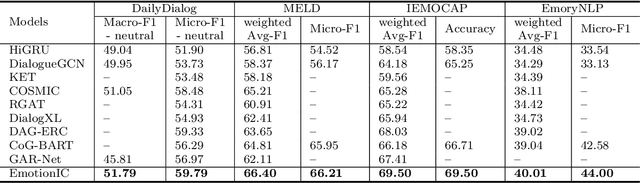
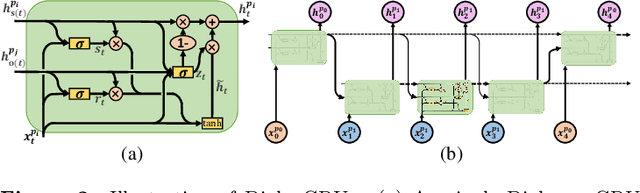

Emotion Recognition in Conversation (ERC) has attracted growing attention in recent years as a result of the advancement and implementation of human-computer interface technologies. However, previous approaches to modeling global and local context dependencies lost the diversity of dependency information and do not take the context dependency into account at the classification level. In this paper, we propose a novel approach to dependency modeling driven by Emotional Inertia and Contagion (EmotionIC) for conversational emotion recognition at the feature extraction and classification levels. At the feature extraction level, our designed Identity Masked Multi-head Attention (IM-MHA) captures the identity-based long-distant context in the dialogue to contain the diverse influence of different participants and construct the global emotional atmosphere, while the devised Dialogue-based Gate Recurrent Unit (DialogGRU) that aggregates the emotional tendencies of dyadic dialogue is applied to refine the contextual features with inter- and intra-speaker dependencies. At the classification level, by introducing skip connections in Conditional Random Field (CRF), we elaborate the Skip-chain CRF (SkipCRF) to capture the high-order dependencies within and between speakers, and to emulate the emotional flow of distant participants. Experimental results show that our method can significantly outperform the state-of-the-art models on four benchmark datasets. The ablation studies confirm that our modules can effectively model emotional inertia and contagion.
LFM-3D: Learnable Feature Matching Across Wide Baselines Using 3D Signals
Mar 22, 2023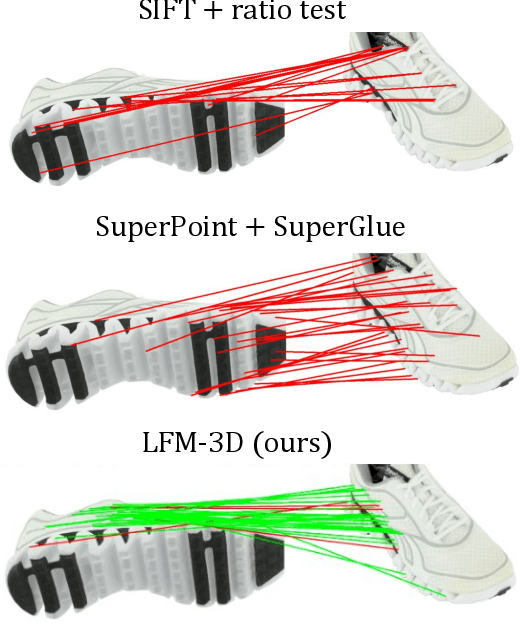
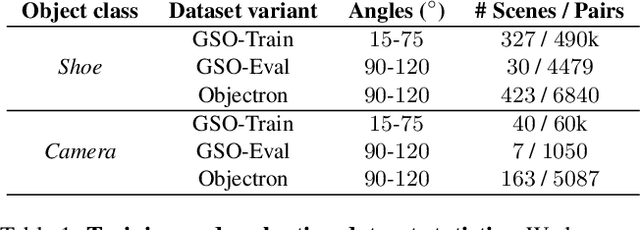
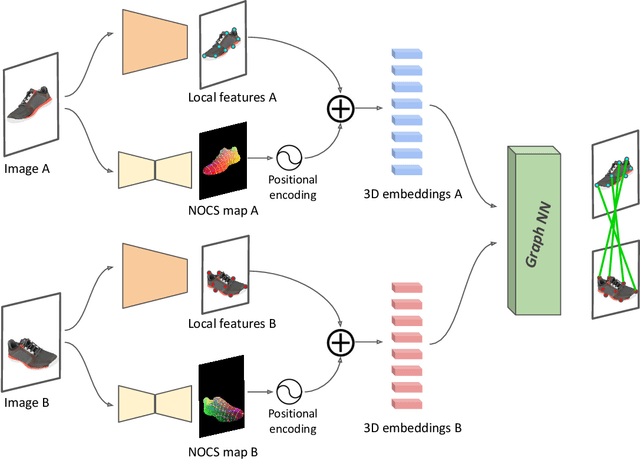
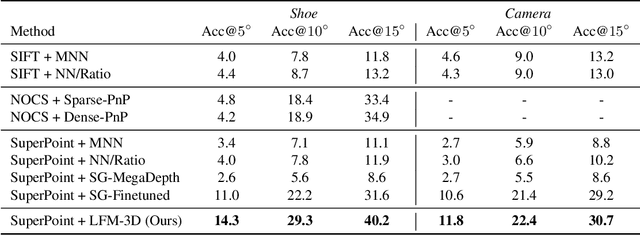
Finding localized correspondences across different images of the same object is crucial to understand its geometry. In recent years, this problem has seen remarkable progress with the advent of deep learning based local image features and learnable matchers. Still, learnable matchers often underperform when there exists only small regions of co-visibility between image pairs (i.e. wide camera baselines). To address this problem, we leverage recent progress in coarse single-view geometry estimation methods. We propose LFM-3D, a Learnable Feature Matching framework that uses models based on graph neural networks, and enhances their capabilities by integrating noisy, estimated 3D signals to boost correspondence estimation. When integrating 3D signals into the matcher model, we show that a suitable positional encoding is critical to effectively make use of the low-dimensional 3D information. We experiment with two different 3D signals - normalized object coordinates and monocular depth estimates - and evaluate our method on large-scale (synthetic and real) datasets containing object-centric image pairs across wide baselines. We observe strong feature matching improvements compared to 2D-only methods, with up to +6% total recall and +28% precision at fixed recall. We additionally demonstrate that the resulting improved correspondences lead to much higher relative posing accuracy for in-the-wild image pairs, with a more than 8% boost compared to the 2D-only approach.
Exploring Turkish Speech Recognition via Hybrid CTC/Attention Architecture and Multi-feature Fusion Network
Mar 22, 2023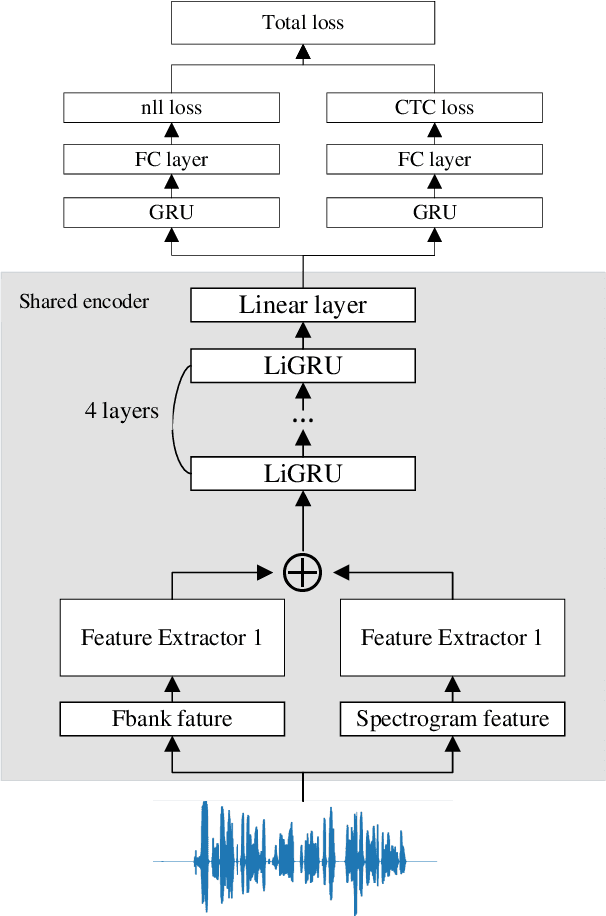
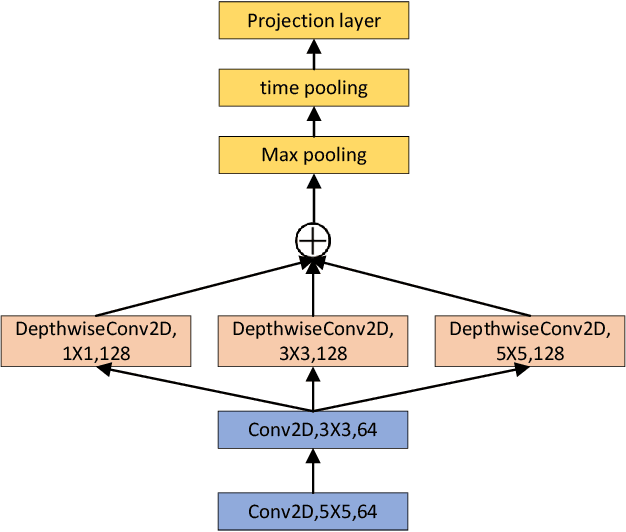
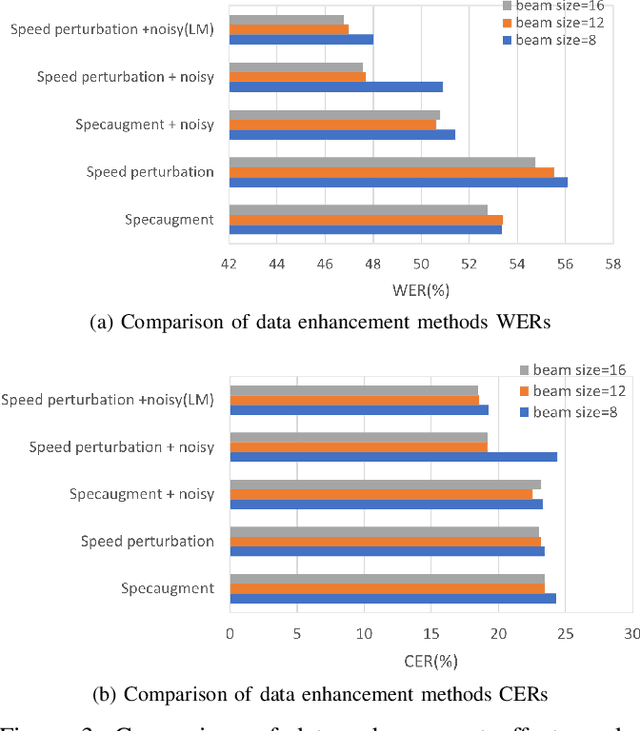

In recent years, End-to-End speech recognition technology based on deep learning has developed rapidly. Due to the lack of Turkish speech data, the performance of Turkish speech recognition system is poor. Firstly, this paper studies a series of speech recognition tuning technologies. The results show that the performance of the model is the best when the data enhancement technology combining speed perturbation with noise addition is adopted and the beam search width is set to 16. Secondly, to maximize the use of effective feature information and improve the accuracy of feature extraction, this paper proposes a new feature extractor LSPC. LSPC and LiGRU network are combined to form a shared encoder structure, and model compression is realized. The results show that the performance of LSPC is better than MSPC and VGGnet when only using Fbank features, and the WER is improved by 1.01% and 2.53% respectively. Finally, based on the above two points, a new multi-feature fusion network is proposed as the main structure of the encoder. The results show that the WER of the proposed feature fusion network based on LSPC is improved by 0.82% and 1.94% again compared with the single feature (Fbank feature and Spectrogram feature) extraction using LSPC. Our model achieves performance comparable to that of advanced End-to-End models.
DiffMIC: Dual-Guidance Diffusion Network for Medical Image Classification
Mar 19, 2023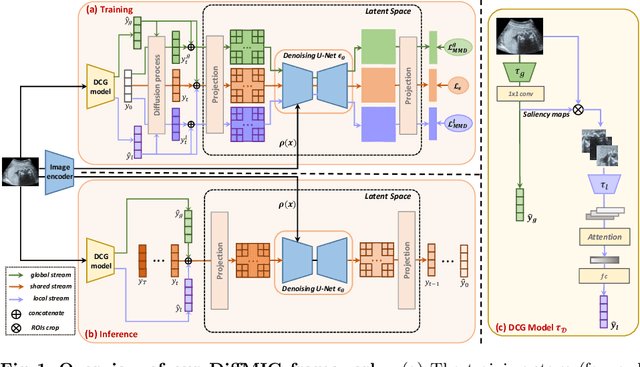
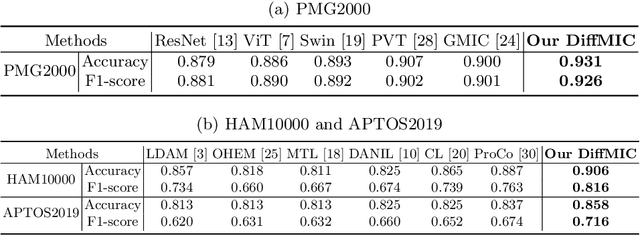
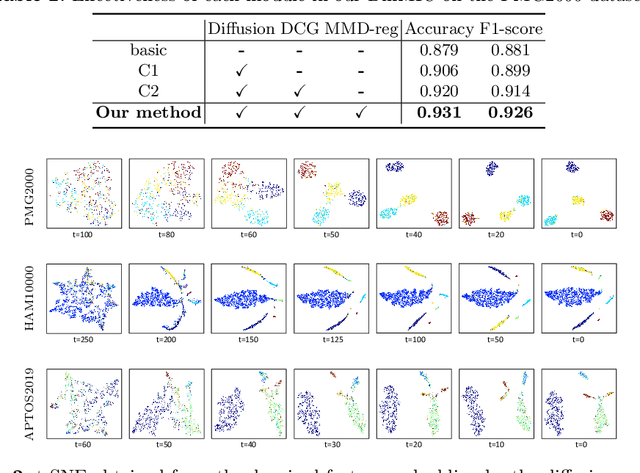
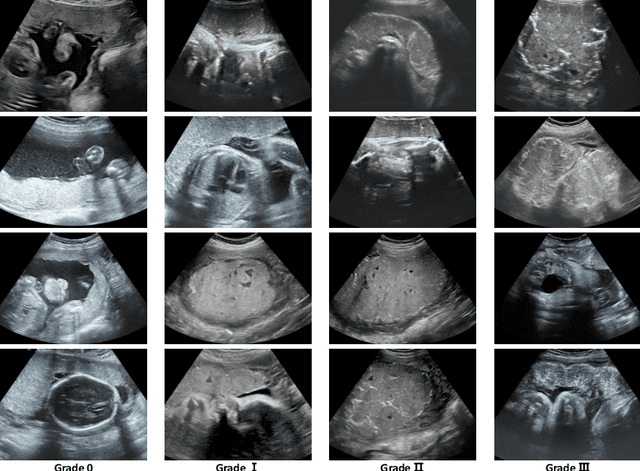
Diffusion Probabilistic Models have recently shown remarkable performance in generative image modeling, attracting significant attention in the computer vision community. However, while a substantial amount of diffusion-based research has focused on generative tasks, few studies have applied diffusion models to general medical image classification. In this paper, we propose the first diffusion-based model (named DiffMIC) to address general medical image classification by eliminating unexpected noise and perturbations in medical images and robustly capturing semantic representation. To achieve this goal, we devise a dual conditional guidance strategy that conditions each diffusion step with multiple granularities to improve step-wise regional attention. Furthermore, we propose learning the mutual information in each granularity by enforcing Maximum-Mean Discrepancy regularization during the diffusion forward process. We evaluate the effectiveness of our DiffMIC on three medical classification tasks with different image modalities, including placental maturity grading on ultrasound images, skin lesion classification using dermatoscopic images, and diabetic retinopathy grading using fundus images. Our experimental results demonstrate that DiffMIC outperforms state-of-the-art methods by a significant margin, indicating the universality and effectiveness of the proposed model.
Elastic Interaction Energy-Based Generative Model: Approximation in Feature Space
Mar 19, 2023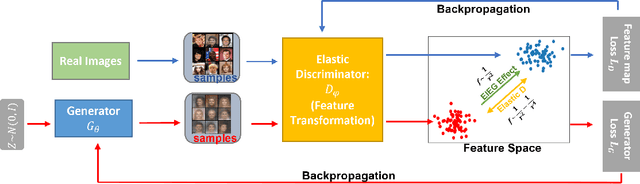
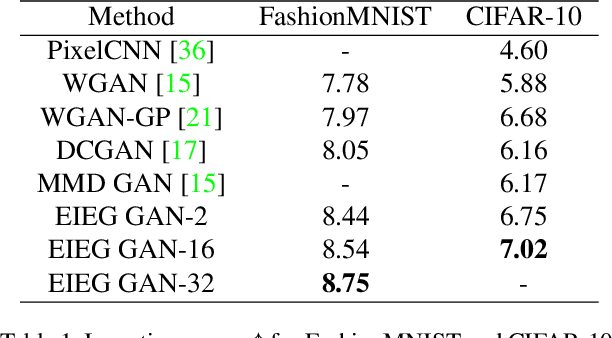
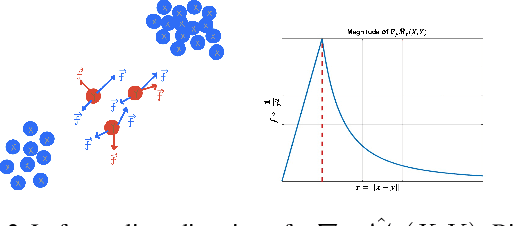

In this paper, we propose a novel approach to generative modeling using a loss function based on elastic interaction energy (EIE), which is inspired by the elastic interaction between defects in crystals. The utilization of the EIE-based metric presents several advantages, including its long range property that enables consideration of global information in the distribution. Moreover, its inclusion of a self-interaction term helps to prevent mode collapse and captures all modes of distribution. To overcome the difficulty of the relatively scattered distribution of high-dimensional data, we first map the data into a latent feature space and approximate the feature distribution instead of the data distribution. We adopt the GAN framework and replace the discriminator with a feature transformation network to map the data into a latent space. We also add a stabilizing term to the loss of the feature transformation network, which effectively addresses the issue of unstable training in GAN-based algorithms. Experimental results on popular datasets, such as MNIST, FashionMNIST, CIFAR-10, and CelebA, demonstrate that our EIEG GAN model can mitigate mode collapse, enhance stability, and improve model performance.
Pliable Private Information Retrieval
Jun 12, 2022
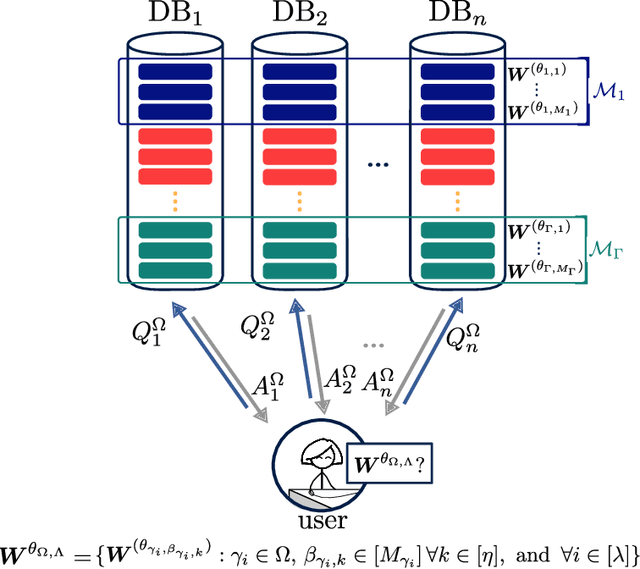
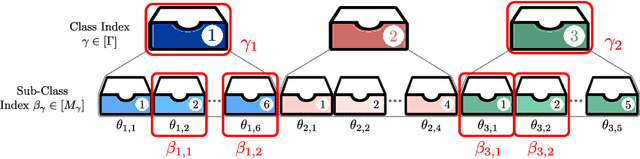
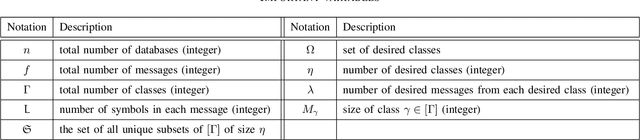
We formulate a new variant of the private information retrieval (PIR) problem where the user is pliable, i.e., interested in any message from a desired subset of the available dataset, denoted as pliable private information retrieval (PPIR). We consider a setup where a dataset consisting of $f$ messages is replicated in $n$ noncolluding databases and classified into $\Gamma$ classes. For this setup, the user wishes to retrieve any $\lambda\geq 1$ messages from multiple desired classes, i.e., $\eta\geq 1$, while revealing no information about the identity of the desired classes to the databases. We term this problem multi-message PPIR (M-PPIR) and introduce the single-message PPIR (PPIR) problem as an elementary special case of M-PPIR. We first derive converse bounds on the M-PPIR rate, which is defined as the ratio of the desired amount of information and the total amount of downloaded information, followed by the corresponding achievable schemes. As a result, we show that the PPIR capacity, i.e., the maximum achievable PPIR rate, for $n$ noncolluding databases matches the capacity of PIR with $n$ databases and $\Gamma$ messages. Thus, enabling flexibility, i.e., pliability, where privacy is only guaranteed for classes, but not for messages as in classical PIR, allows to trade-off privacy versus download rate. A similar insight is shown to hold for the general case of M-PPIR.
On the Fusion Strategies for Federated Decision Making
Mar 10, 2023
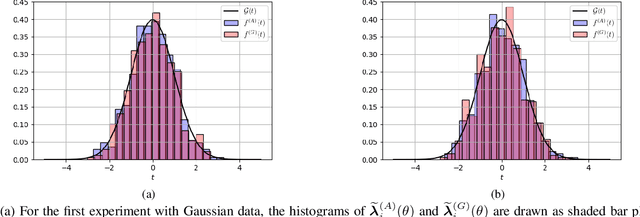
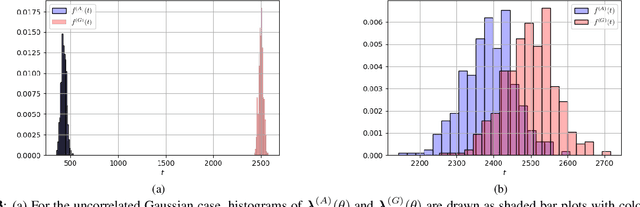
We consider the problem of information aggregation in federated decision making, where a group of agents collaborate to infer the underlying state of nature without sharing their private data with the central processor or each other. We analyze the non-Bayesian social learning strategy in which agents incorporate their individual observations into their opinions (i.e., soft-decisions) with Bayes rule, and the central processor aggregates these opinions by arithmetic or geometric averaging. Building on our previous work, we establish that both pooling strategies result in asymptotic normality characterization of the system, which, for instance, can be utilized in order to give approximate expressions for the error probability. We verify the theoretical findings with simulations and compare both strategies.
X$^3$KD: Knowledge Distillation Across Modalities, Tasks and Stages for Multi-Camera 3D Object Detection
Mar 03, 2023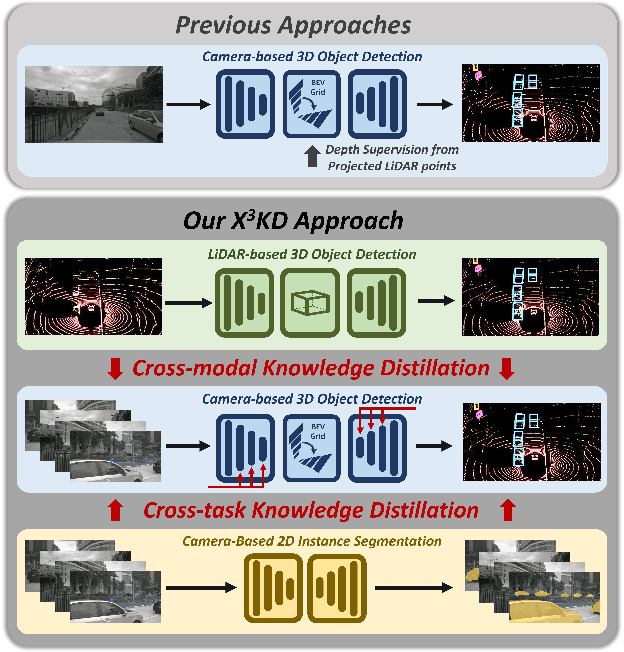
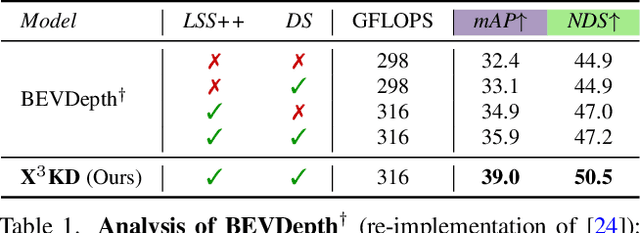
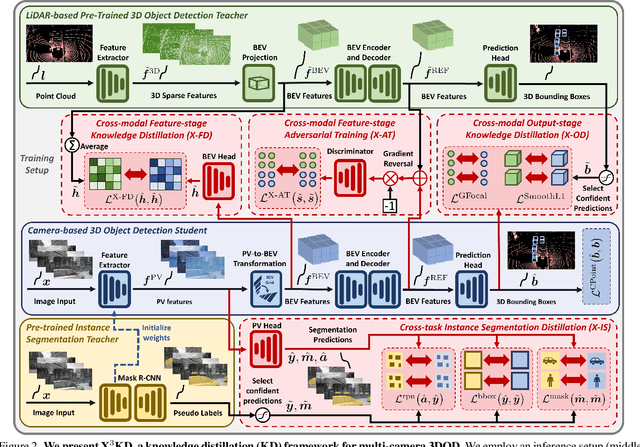
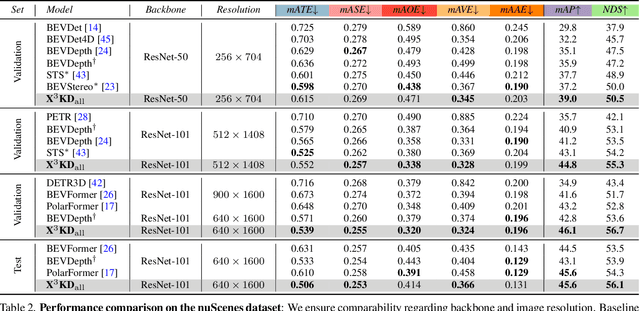
Recent advances in 3D object detection (3DOD) have obtained remarkably strong results for LiDAR-based models. In contrast, surround-view 3DOD models based on multiple camera images underperform due to the necessary view transformation of features from perspective view (PV) to a 3D world representation which is ambiguous due to missing depth information. This paper introduces X$^3$KD, a comprehensive knowledge distillation framework across different modalities, tasks, and stages for multi-camera 3DOD. Specifically, we propose cross-task distillation from an instance segmentation teacher (X-IS) in the PV feature extraction stage providing supervision without ambiguous error backpropagation through the view transformation. After the transformation, we apply cross-modal feature distillation (X-FD) and adversarial training (X-AT) to improve the 3D world representation of multi-camera features through the information contained in a LiDAR-based 3DOD teacher. Finally, we also employ this teacher for cross-modal output distillation (X-OD), providing dense supervision at the prediction stage. We perform extensive ablations of knowledge distillation at different stages of multi-camera 3DOD. Our final X$^3$KD model outperforms previous state-of-the-art approaches on the nuScenes and Waymo datasets and generalizes to RADAR-based 3DOD. Qualitative results video at https://youtu.be/1do9DPFmr38.
Graph-based Simultaneous Coverage and Exploration Planning for Fast Multi-robot Search
Mar 03, 2023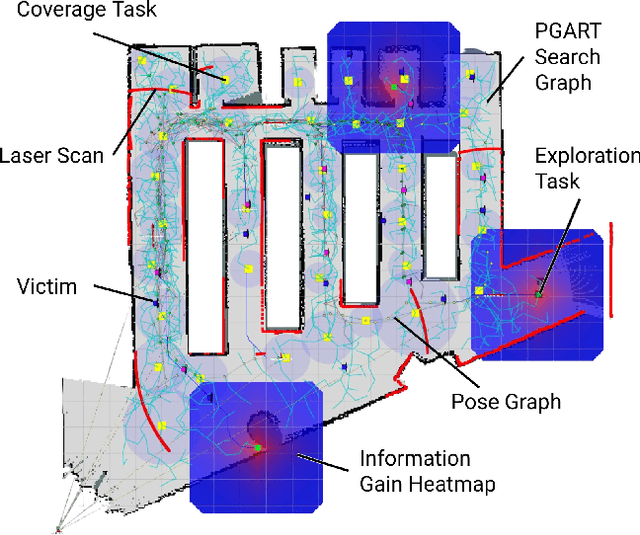
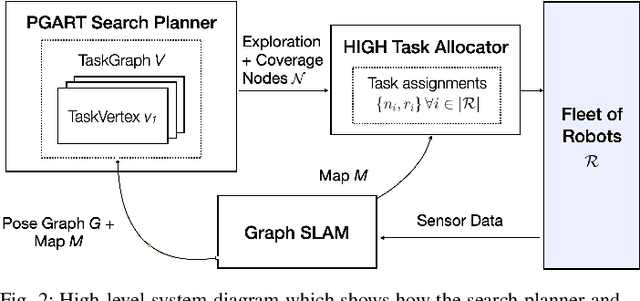
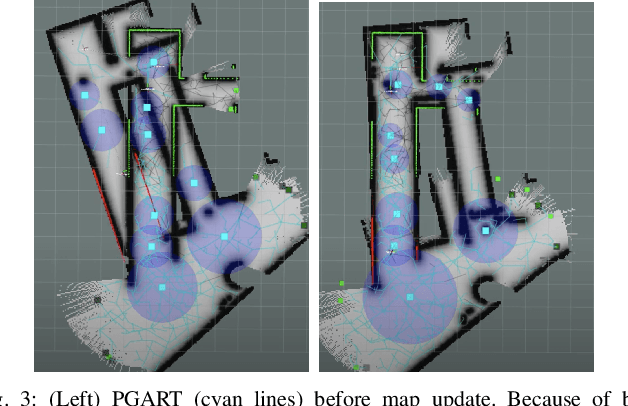
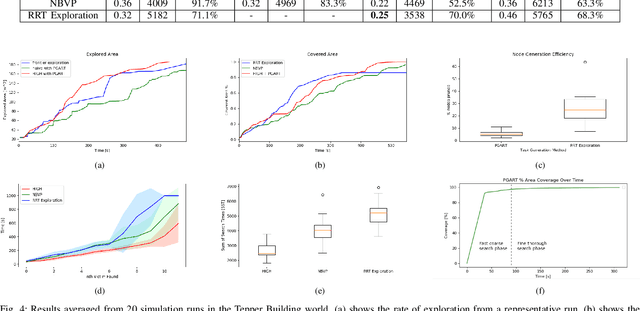
In large unknown environments, search operations can be much more time-efficient with the use of multi-robot fleets by parallelizing efforts. This means robots must efficiently perform collaborative mapping (exploration) while simultaneously searching an area for victims (coverage). Previous simultaneous mapping and planning techniques treat these problems as separate and do not take advantage of the possibility for a unified approach. We propose a novel exploration-coverage planner which bridges the mapping and search domains by growing sets of random trees rooted upon a pose graph produced through mapping to generate points of interest, or tasks. Furthermore, it is important for the robots to first prioritize high information tasks to locate the greatest number of victims in minimum time by balancing coverage and exploration, which current methods do not address. Towards this goal, we also present a new multi-robot task allocator that formulates a notion of a hierarchical information heuristic for time-critical collaborative search. Our results show that our algorithm produces 20% more coverage efficiency, defined as average covered area per second, compared to the existing state-of-the-art. Our algorithms and the rest of our multi-robot search stack is based in ROS and made open source
Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering
Mar 03, 2023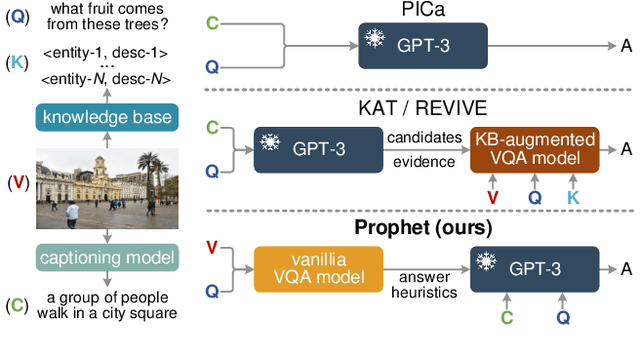

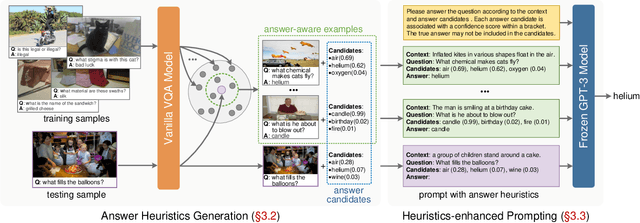
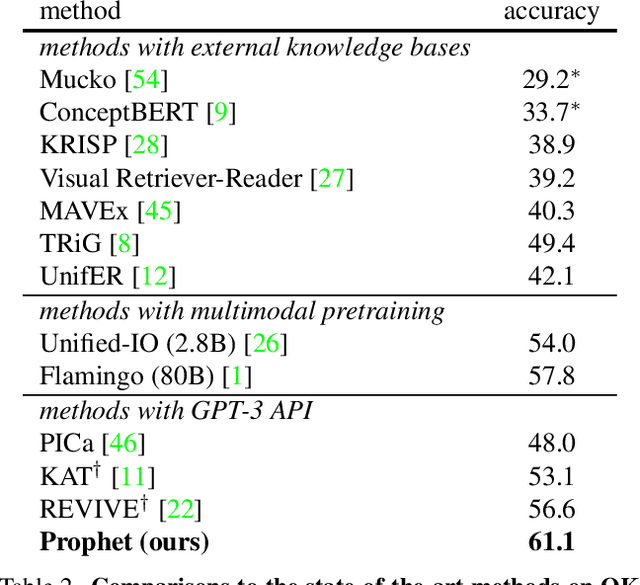
Knowledge-based visual question answering (VQA) requires external knowledge beyond the image to answer the question. Early studies retrieve required knowledge from explicit knowledge bases (KBs), which often introduces irrelevant information to the question, hence restricting the performance of their models. Recent works have sought to use a large language model (i.e., GPT-3) as an implicit knowledge engine to acquire the necessary knowledge for answering. Despite the encouraging results achieved by these methods, we argue that they have not fully activated the capacity of GPT-3 as the provided input information is insufficient. In this paper, we present Prophet -- a conceptually simple framework designed to prompt GPT-3 with answer heuristics for knowledge-based VQA. Specifically, we first train a vanilla VQA model on a specific knowledge-based VQA dataset without external knowledge. After that, we extract two types of complementary answer heuristics from the model: answer candidates and answer-aware examples. Finally, the two types of answer heuristics are encoded into the prompts to enable GPT-3 to better comprehend the task thus enhancing its capacity. Prophet significantly outperforms all existing state-of-the-art methods on two challenging knowledge-based VQA datasets, OK-VQA and A-OKVQA, delivering 61.1% and 55.7% accuracies on their testing sets, respectively.