 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Smoothing Algorithm for Minimum Sensing Path Plans in Gaussian Belief Space
Mar 13, 2023
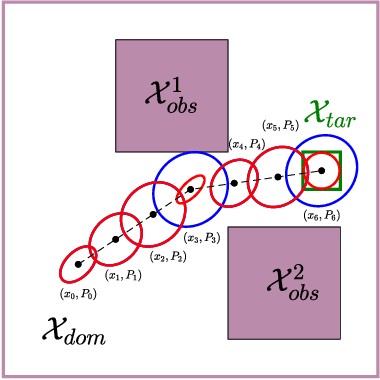
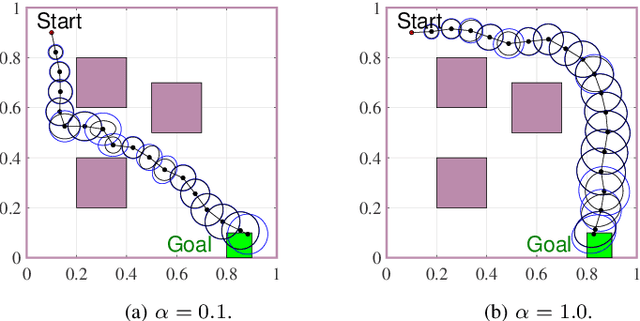
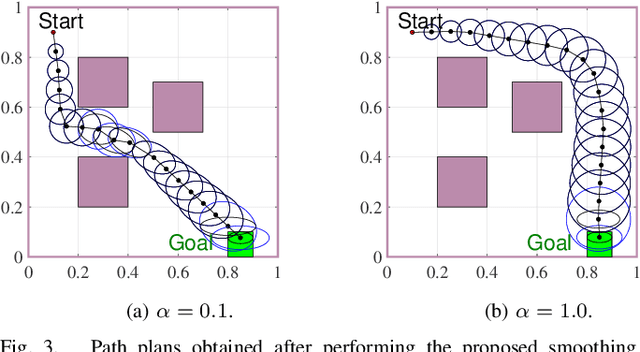
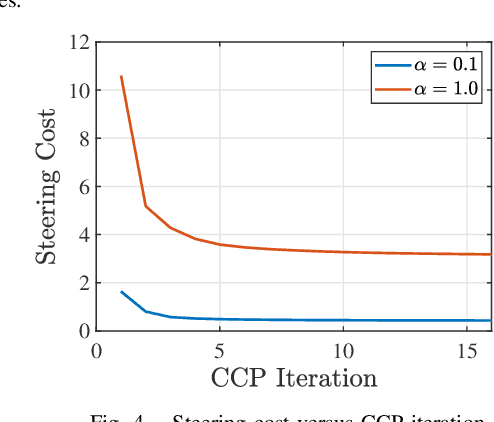
This paper explores minimum sensing navigation of robots in environments cluttered with obstacles. The general objective is to find a path plan to a goal region that requires minimal sensing effort. In [1], the information-geometric RRT* (IG-RRT*) algorithm was proposed to efficiently find such a path. However, like any stochastic sampling-based planner, the computational complexity of IG-RRT* grows quickly, impeding its use with a large number of nodes. To remedy this limitation, we suggest running IG-RRT* with a moderate number of nodes, and then using a smoothing algorithm to adjust the path obtained. To develop a smoothing algorithm, we explicitly formulate the minimum sensing path planning problem as an optimization problem. For this formulation, we introduce a new safety constraint to impose a bound on the probability of collision with obstacles in continuous-time, in contrast to the common discrete-time approach. The problem is amenable to solution via the convex-concave procedure (CCP). We develop a CCP algorithm for the formulated optimization and use this algorithm for path smoothing. We demonstrate the efficacy of the proposed approach through numerical simulations.
FusionLoc: Camera-2D LiDAR Fusion Using Multi-Head Self-Attention for End-to-End Serving Robot Relocalization
Mar 13, 2023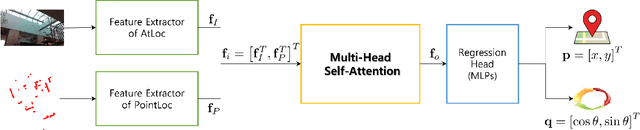
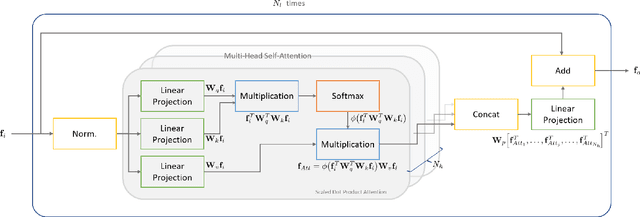
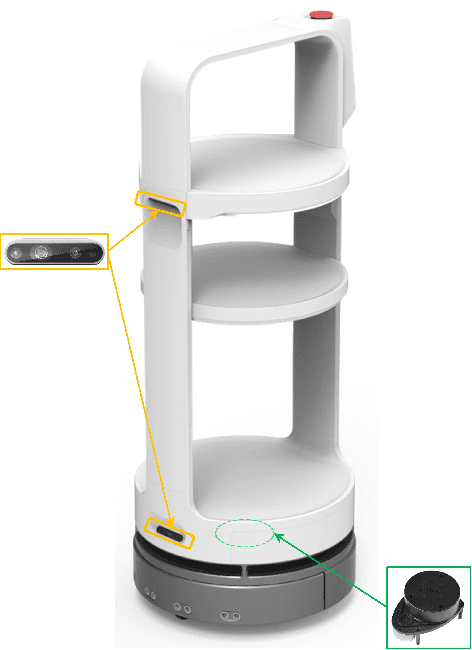
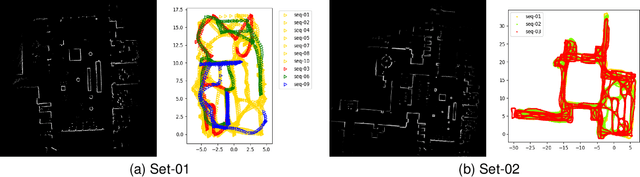
With the recent development of autonomous driving technology, as the pursuit of efficiency for repetitive tasks and the value of non-face-to-face services increase, mobile service robots such as delivery robots and serving robots attract attention, and their demands are increasing day by day. However, when something goes wrong, most commercial serving robots need to return to their starting position and orientation to operate normally again. In this paper, we focus on end-to-end relocalization of serving robots to address the problem. It is to predict robot pose directly from only the onboard sensor data using neural networks. In particular, we propose a deep neural network architecture for the relocalization based on camera-2D LiDAR sensor fusion. We call the proposed method FusionLoc. In the proposed method, the multi-head self-attention complements different types of information captured by the two sensors. Our experiments on a dataset collected by a commercial serving robot demonstrate that FusionLoc can provide better performances than previous relocalization methods taking only a single image or a 2D LiDAR point cloud as well as a straightforward fusion method concatenating their features.
Lag selection and estimation of stable parameters for multiple autoregressive processes through convex programming
Mar 03, 2023Motivated by a variety of applications, high-dimensional time series have become an active topic of research. In particular, several methods and finite-sample theories for individual stable autoregressive processes with known lag have become available very recently. We, instead, consider multiple stable autoregressive processes that share an unknown lag. We use information across the different processes to simultaneously select the lag and estimate the parameters. We prove that the estimated process is stable, and we establish rates for the forecasting error that can outmatch the known rate in our setting. Our insights on the lag selection and the stability are also of interest for the case of individual autoregressive processes.
Fusing Visual Appearance and Geometry for Multi-modality 6DoF Object Tracking
Feb 22, 2023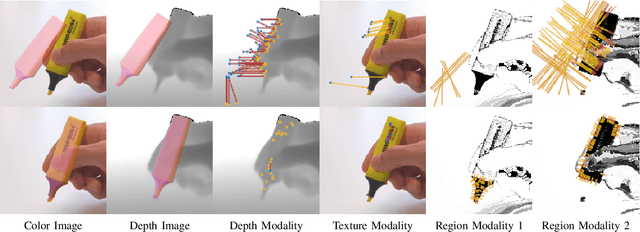
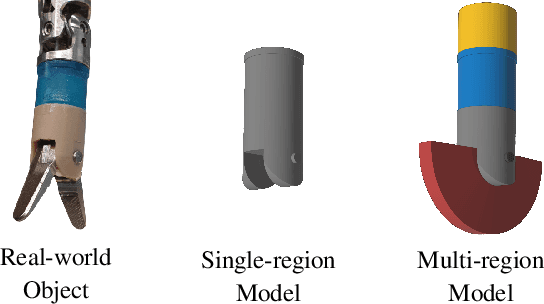
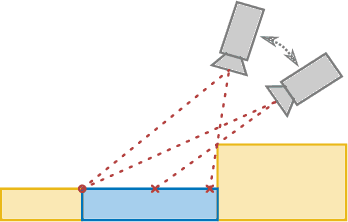
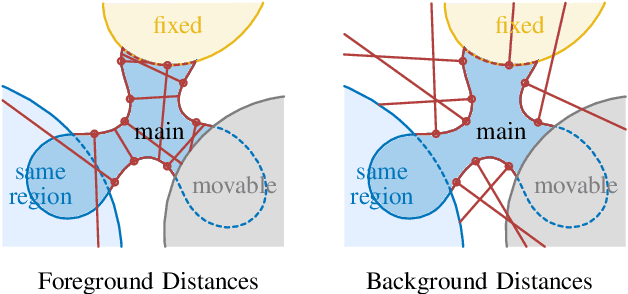
In many applications of advanced robotic manipulation, six degrees of freedom (6DoF) object pose estimates are continuously required. In this work, we develop a multi-modality tracker that fuses information from visual appearance and geometry to estimate object poses. The algorithm extends our previous method ICG, which uses geometry, to additionally consider surface appearance. In general, object surfaces contain local characteristics from text, graphics, and patterns, as well as global differences from distinct materials and colors. To incorporate this visual information, two modalities are developed. For local characteristics, keypoint features are used to minimize distances between points from keyframes and the current image. For global differences, a novel region approach is developed that considers multiple regions on the object surface. In addition, it allows the modeling of external geometries. Experiments on the YCB-Video and OPT datasets demonstrate that our approach ICG+ performs best on both datasets, outperforming both conventional and deep learning-based methods. At the same time, the algorithm is highly efficient and runs at more than 300 Hz. The source code of our tracker is publicly available.
Negative Shannon Information Hides Networks
Jun 09, 2022
Negative numbers are essential in mathematics. They are not needed to describe statistical experiments, as those are expressed in terms of positive probabilities. Shannon information was firstly defined for characterizing informational uncertainty of classical probabilistic distributions. However, it is unknown why there is negative information for more than two random variables on finite sample spaces. We first show the negative Shannon mutual information of three random variables implies Bayesian network representations of its joint distribution. We then show the intrinsic compatibility with negative Shannon information is generic for Bayesian networks with quantum realizations. This further suggests a new kind of space-dependent nonlocality. The present result provides a device-independent witness of negative Shannon information.
Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation
Feb 28, 2023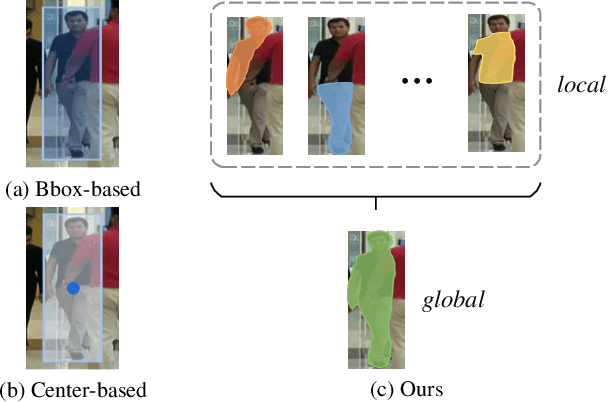
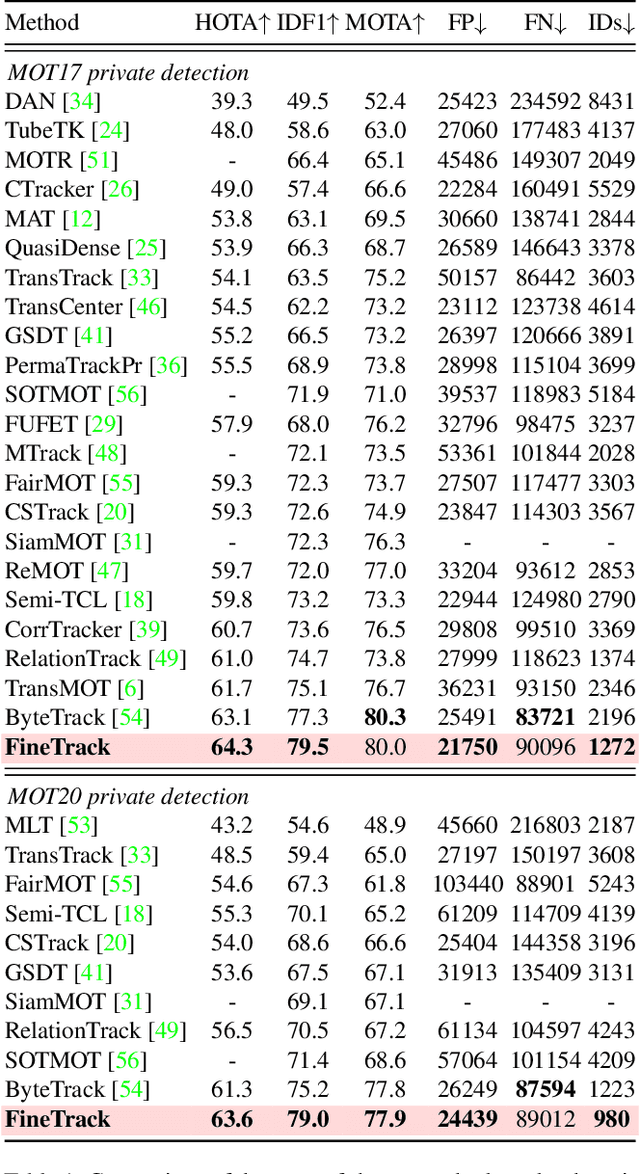
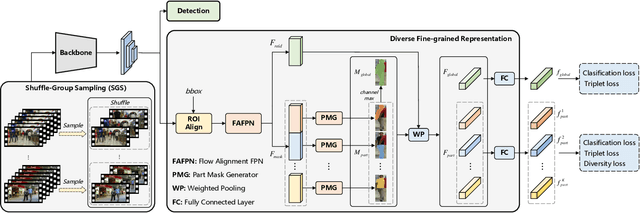
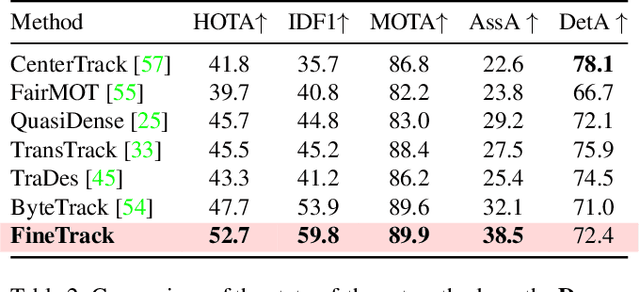
Discriminative representation is essential to keep a unique identifier for each target in Multiple object tracking (MOT). Some recent MOT methods extract features of the bounding box region or the center point as identity embeddings. However, when targets are occluded, these coarse-grained global representations become unreliable. To this end, we propose exploring diverse fine-grained representation, which describes appearance comprehensively from global and local perspectives. This fine-grained representation requires high feature resolution and precise semantic information. To effectively alleviate the semantic misalignment caused by indiscriminate contextual information aggregation, Flow Alignment FPN (FAFPN) is proposed for multi-scale feature alignment aggregation. It generates semantic flow among feature maps from different resolutions to transform their pixel positions. Furthermore, we present a Multi-head Part Mask Generator (MPMG) to extract fine-grained representation based on the aligned feature maps. Multiple parallel branches of MPMG allow it to focus on different parts of targets to generate local masks without label supervision. The diverse details in target masks facilitate fine-grained representation. Eventually, benefiting from a Shuffle-Group Sampling (SGS) training strategy with positive and negative samples balanced, we achieve state-of-the-art performance on MOT17 and MOT20 test sets. Even on DanceTrack, where the appearance of targets is extremely similar, our method significantly outperforms ByteTrack by 5.0% on HOTA and 5.6% on IDF1. Extensive experiments have proved that diverse fine-grained representation makes Re-ID great again in MOT.
WISK: A Workload-aware Learned Index for Spatial Keyword Queries
Feb 28, 2023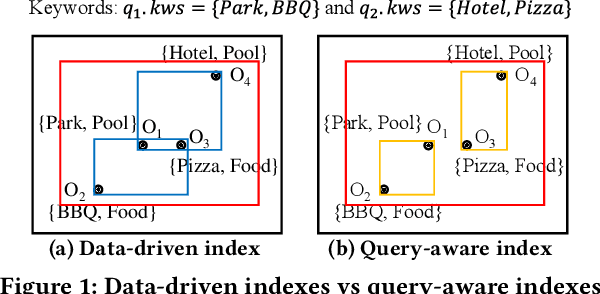
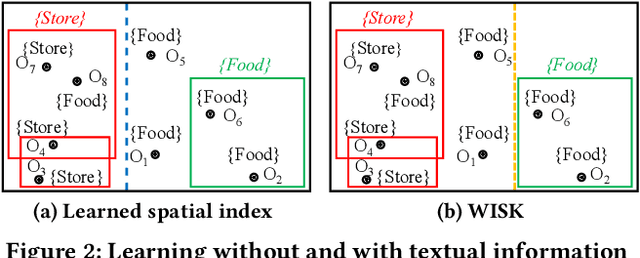
Spatial objects often come with textual information, such as Points of Interest (POIs) with their descriptions, which are referred to as geo-textual data. To retrieve such data, spatial keyword queries that take into account both spatial proximity and textual relevance have been extensively studied. Existing indexes designed for spatial keyword queries are mostly built based on the geo-textual data without considering the distribution of queries already received. However, previous studies have shown that utilizing the known query distribution can improve the index structure for future query processing. In this paper, we propose WISK, a learned index for spatial keyword queries, which self-adapts for optimizing querying costs given a query workload. One key challenge is how to utilize both structured spatial attributes and unstructured textual information during learning the index. We first divide the data objects into partitions, aiming to minimize the processing costs of the given query workload. We prove the NP-hardness of the partitioning problem and propose a machine learning model to find the optimal partitions. Then, to achieve more pruning power, we build a hierarchical structure based on the generated partitions in a bottom-up manner with a reinforcement learning-based approach. We conduct extensive experiments on real-world datasets and query workloads with various distributions, and the results show that WISK outperforms all competitors, achieving up to 8x speedup in querying time with comparable storage overhead.
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023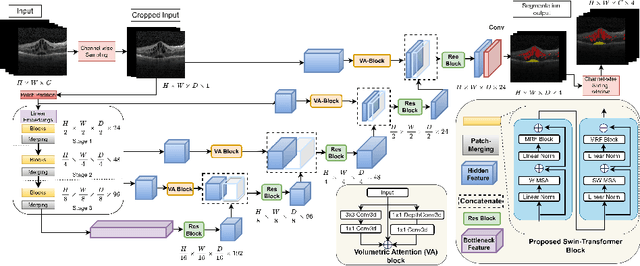
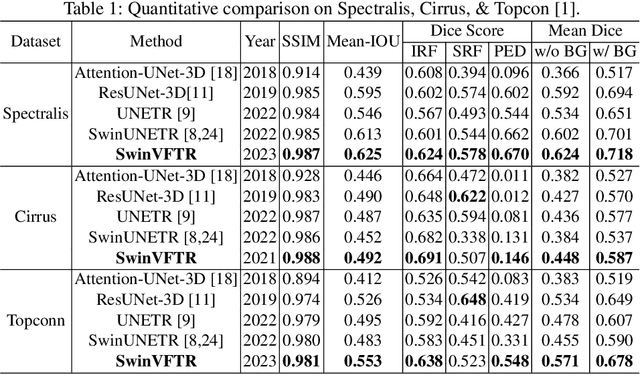
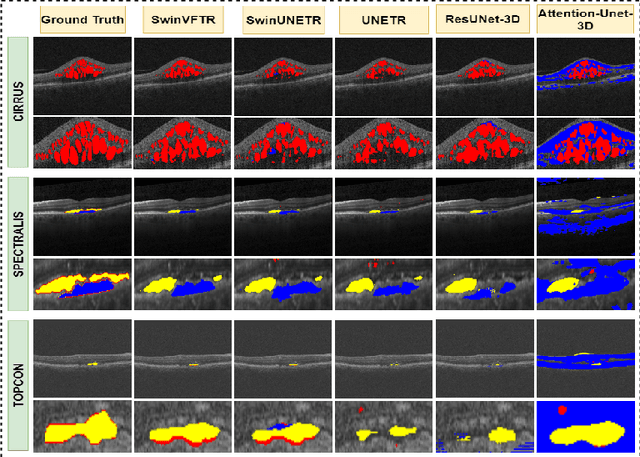
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS "Cold-Start"
Feb 02, 2023
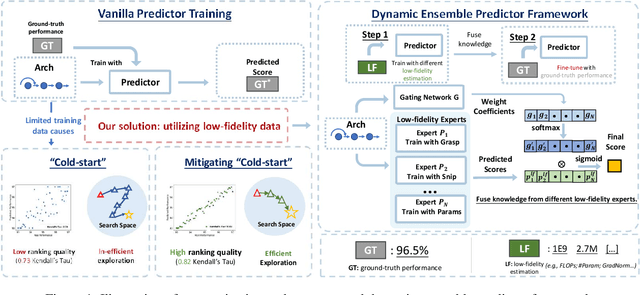
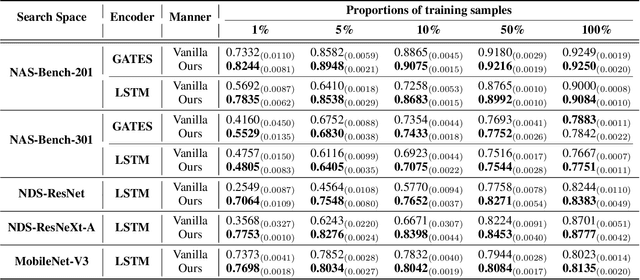
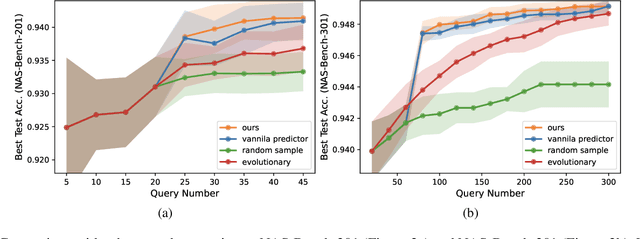
Predictor-based Neural Architecture Search (NAS) employs an architecture performance predictor to improve the sample efficiency. However, predictor-based NAS suffers from the severe ``cold-start'' problem, since a large amount of architecture-performance data is required to get a working predictor. In this paper, we focus on exploiting information in cheaper-to-obtain performance estimations (i.e., low-fidelity information) to mitigate the large data requirements of predictor training. Despite the intuitiveness of this idea, we observe that using inappropriate low-fidelity information even damages the prediction ability and different search spaces have different preferences for low-fidelity information types. To solve the problem and better fuse beneficial information provided by different types of low-fidelity information, we propose a novel dynamic ensemble predictor framework that comprises two steps. In the first step, we train different sub-predictors on different types of available low-fidelity information to extract beneficial knowledge as low-fidelity experts. In the second step, we learn a gating network to dynamically output a set of weighting coefficients conditioned on each input neural architecture, which will be used to combine the predictions of different low-fidelity experts in a weighted sum. The overall predictor is optimized on a small set of actual architecture-performance data to fuse the knowledge from different low-fidelity experts to make the final prediction. We conduct extensive experiments across five search spaces with different architecture encoders under various experimental settings. Our method can easily be incorporated into existing predictor-based NAS frameworks to discover better architectures.
Probing neural representations of scene perception in a hippocampally dependent task using artificial neural networks
Mar 11, 2023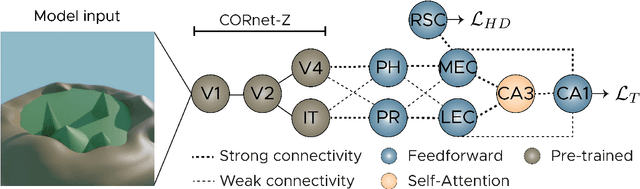
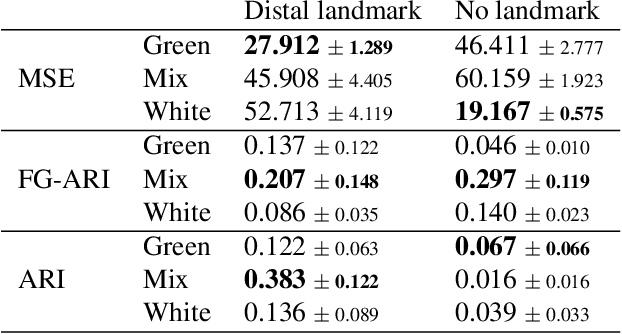
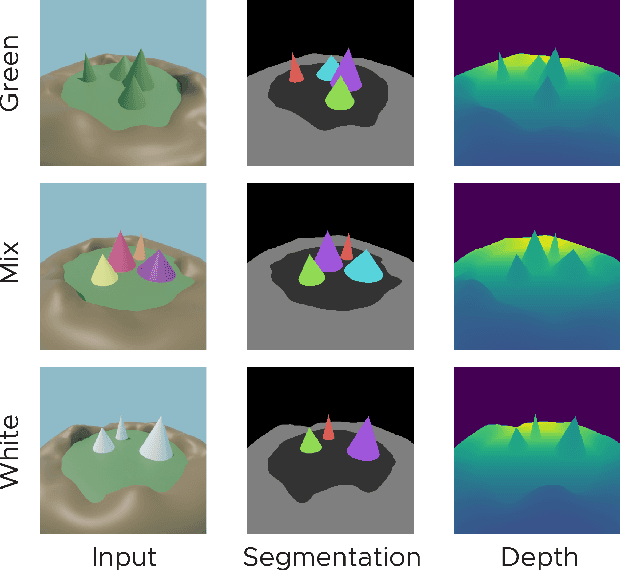

Deep artificial neural networks (DNNs) trained through backpropagation provide effective models of the mammalian visual system, accurately capturing the hierarchy of neural responses through primary visual cortex to inferior temporal cortex (IT). However, the ability of these networks to explain representations in higher cortical areas is relatively lacking and considerably less well researched. For example, DNNs have been less successful as a model of the egocentric to allocentric transformation embodied by circuits in retrosplenial and posterior parietal cortex. We describe a novel scene perception benchmark inspired by a hippocampal dependent task, designed to probe the ability of DNNs to transform scenes viewed from different egocentric perspectives. Using a network architecture inspired by the connectivity between temporal lobe structures and the hippocampus, we demonstrate that DNNs trained using a triplet loss can learn this task. Moreover, by enforcing a factorized latent space, we can split information propagation into "what" and "where" pathways, which we use to reconstruct the input. This allows us to beat the state-of-the-art for unsupervised object segmentation on the CATER and MOVi-A,B,C benchmarks.