 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Mar 15, 2023
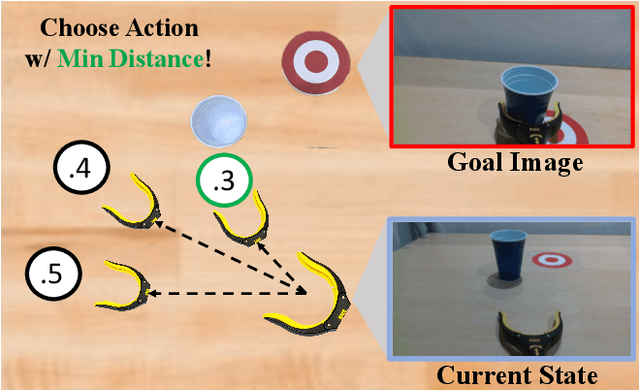
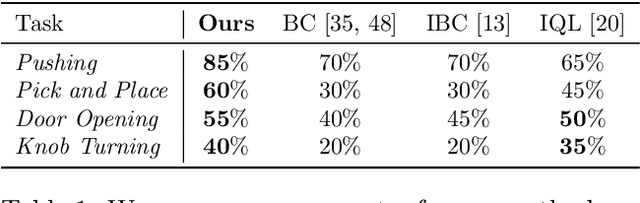
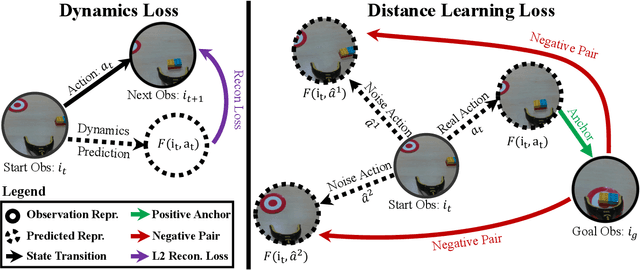
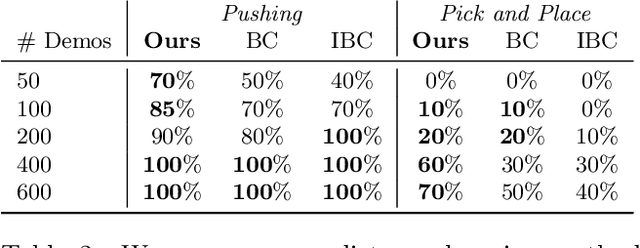
The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as distances (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time. For visualizations of the learned policies please check: https://agi-labs.github.io/manipulate-by-seeing/
VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression
Mar 15, 2023
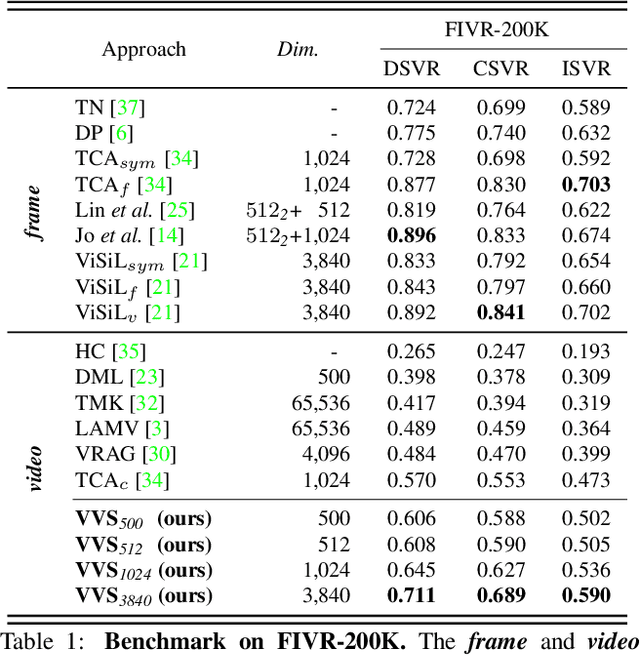
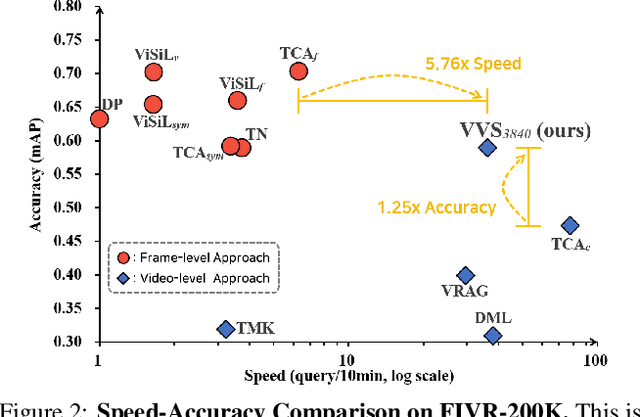
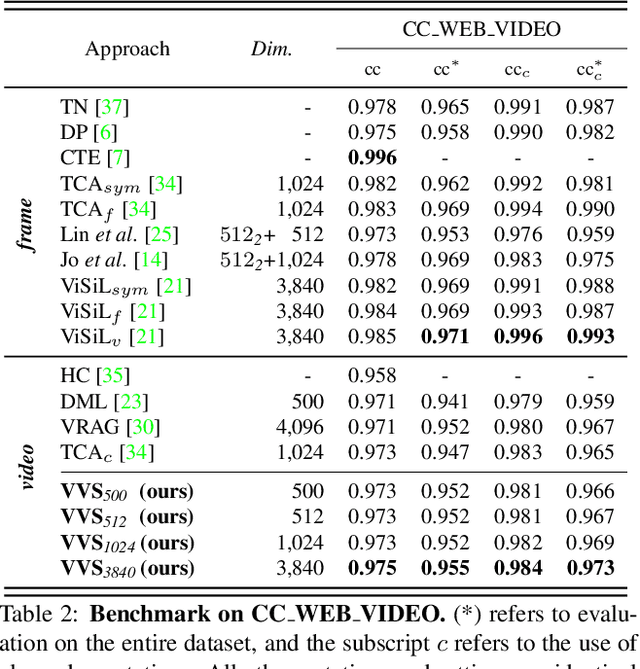
In content-based video retrieval (CBVR), dealing with large-scale collections, efficiency is as important as accuracy. For this reason, several video-level feature-based studies have actively been conducted; nevertheless, owing to the severe difficulty of embedding a lengthy and untrimmed video into a single feature, these studies have shown insufficient for accurate retrieval compared to frame-level feature-based studies. In this paper, we show an insight that appropriate suppression of irrelevant frames can be a clue to overcome the current obstacles of the video-level feature-based approaches. Furthermore, we propose a Video-to-Video Suppression network (VVS) as a solution. The VVS is an end-to-end framework that consists of an easy distractor elimination stage for identifying which frames to remove and a suppression weight generation stage for determining how much to suppress the remaining frames. This structure is intended to effectively describe an untrimmed video with varying content and meaningless information. Its efficacy is proved via extensive experiments, and we show that our approach is not only state-of-the-art in video-level feature-based approaches but also has a fast inference time despite possessing retrieval capabilities close to those of frame-level feature-based approaches.
FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors
Mar 15, 2023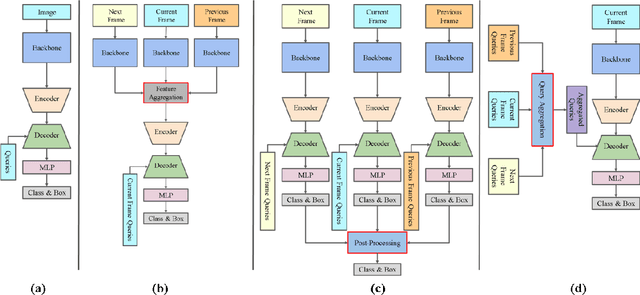
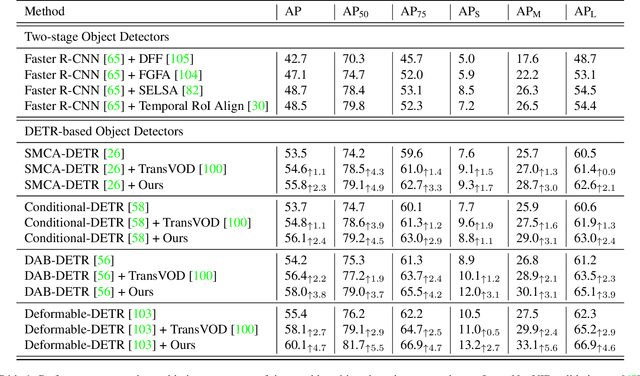
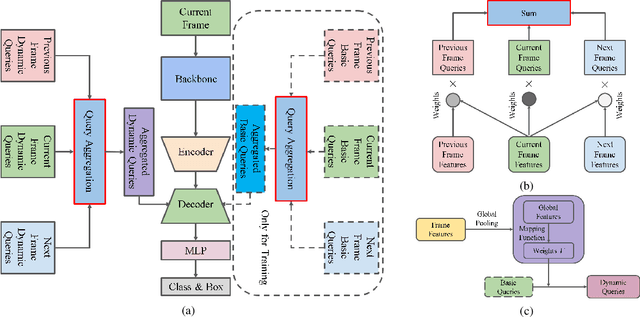
Video object detection needs to solve feature degradation situations that rarely happen in the image domain. One solution is to use the temporal information and fuse the features from the neighboring frames. With Transformerbased object detectors getting a better performance on the image domain tasks, recent works began to extend those methods to video object detection. However, those existing Transformer-based video object detectors still follow the same pipeline as those used for classical object detectors, like enhancing the object feature representations by aggregation. In this work, we take a different perspective on video object detection. In detail, we improve the qualities of queries for the Transformer-based models by aggregation. To achieve this goal, we first propose a vanilla query aggregation module that weighted averages the queries according to the features of the neighboring frames. Then, we extend the vanilla module to a more practical version, which generates and aggregates queries according to the features of the input frames. Extensive experimental results validate the effectiveness of our proposed methods: On the challenging ImageNet VID benchmark, when integrated with our proposed modules, the current state-of-the-art Transformer-based object detectors can be improved by more than 2.4% on mAP and 4.2% on AP50.
Modified EDAS Method Based on Cumulative Prospect Theory for Multiple Attributes Group Decision Making with Interval-valued Intuitionistic Fuzzy Information
Nov 05, 2022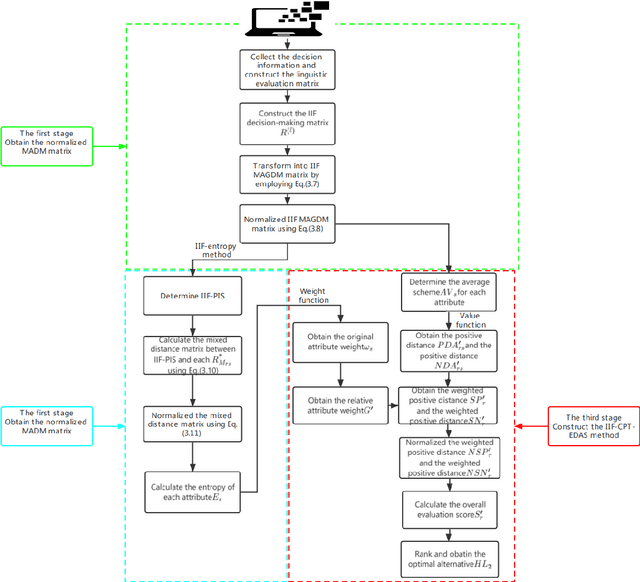
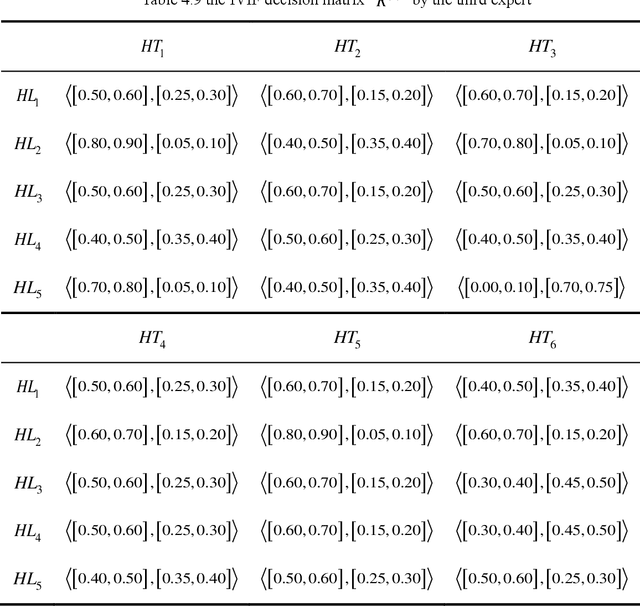
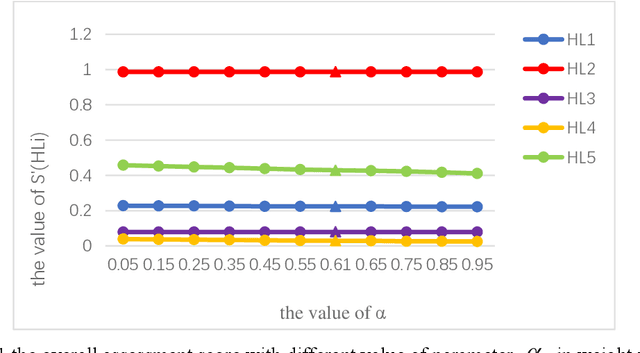
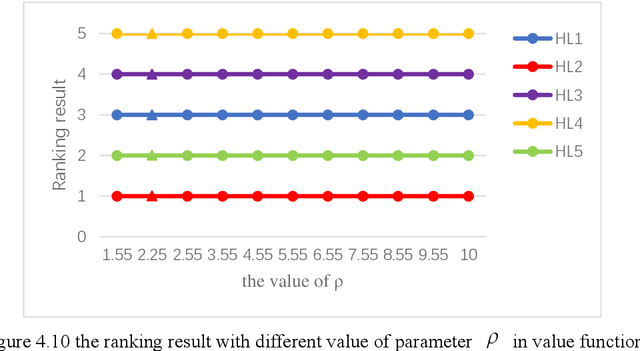
The Interval-valued intuitionistic fuzzy sets (IVIFSs) based on the intuitionistic fuzzy sets combines the classical decision method is in its research and application is attracting attention. After comparative analysis, there are multiple classical methods with IVIFSs information have been applied into many practical issues. In this paper, we extended the classical EDAS method based on cumulative prospect theory (CPT) considering the decision makers (DMs) psychological factor under IVIFSs. Taking the fuzzy and uncertain character of the IVIFSs and the psychological preference into consideration, the original EDAS method based on the CPT under IVIFSs (IVIF-CPT-MABAC) method is built for MAGDM issues. Meanwhile, information entropy method is used to evaluate the attribute weight. Finally, a numerical example for project selection of green technology venture capital has been given and some comparisons is used to illustrate advantages of IVIF-CPT-MABAC method and some comparison analysis and sensitivity analysis are applied to prove this new methods effectiveness and stability.
Fusing Visual Appearance and Geometry for Multi-modality 6DoF Object Tracking
Feb 22, 2023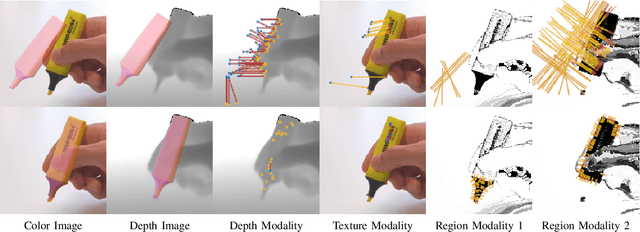
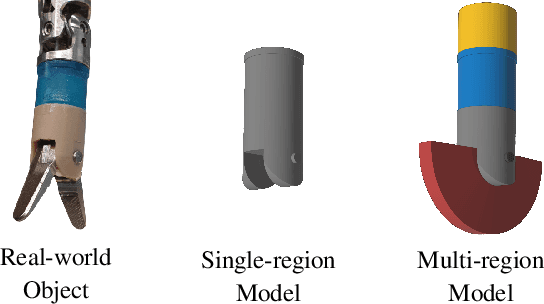
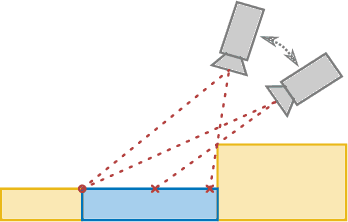
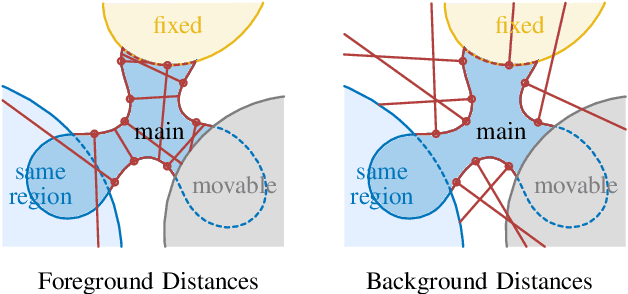
In many applications of advanced robotic manipulation, six degrees of freedom (6DoF) object pose estimates are continuously required. In this work, we develop a multi-modality tracker that fuses information from visual appearance and geometry to estimate object poses. The algorithm extends our previous method ICG, which uses geometry, to additionally consider surface appearance. In general, object surfaces contain local characteristics from text, graphics, and patterns, as well as global differences from distinct materials and colors. To incorporate this visual information, two modalities are developed. For local characteristics, keypoint features are used to minimize distances between points from keyframes and the current image. For global differences, a novel region approach is developed that considers multiple regions on the object surface. In addition, it allows the modeling of external geometries. Experiments on the YCB-Video and OPT datasets demonstrate that our approach ICG+ performs best on both datasets, outperforming both conventional and deep learning-based methods. At the same time, the algorithm is highly efficient and runs at more than 300 Hz. The source code of our tracker is publicly available.
TRUSformer: Improving Prostate Cancer Detection from Micro-Ultrasound Using Attention and Self-Supervision
Mar 03, 2023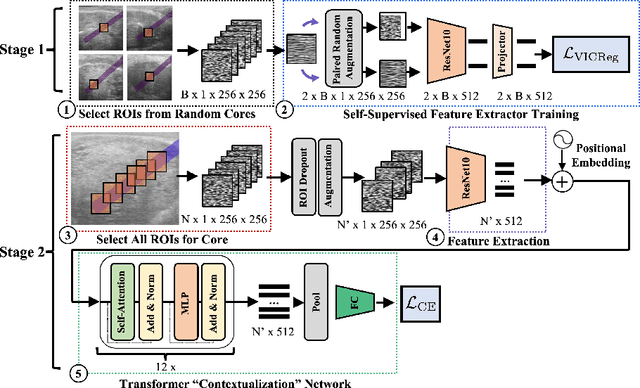
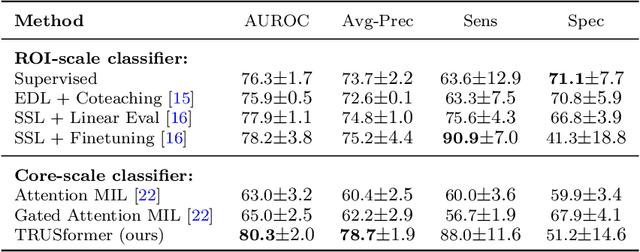
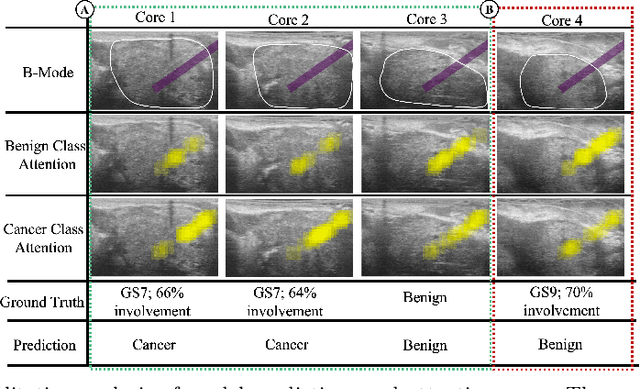

A large body of previous machine learning methods for ultrasound-based prostate cancer detection classify small regions of interest (ROIs) of ultrasound signals that lie within a larger needle trace corresponding to a prostate tissue biopsy (called biopsy core). These ROI-scale models suffer from weak labeling as histopathology results available for biopsy cores only approximate the distribution of cancer in the ROIs. ROI-scale models do not take advantage of contextual information that are normally considered by pathologists, i.e. they do not consider information about surrounding tissue and larger-scale trends when identifying cancer. We aim to improve cancer detection by taking a multi-scale, i.e. ROI-scale and biopsy core-scale, approach. Methods: Our multi-scale approach combines (i) an "ROI-scale" model trained using self-supervised learning to extract features from small ROIs and (ii) a "core-scale" transformer model that processes a collection of extracted features from multiple ROIs in the needle trace region to predict the tissue type of the corresponding core. Attention maps, as a byproduct, allow us to localize cancer at the ROI scale. We analyze this method using a dataset of micro-ultrasound acquired from 578 patients who underwent prostate biopsy, and compare our model to baseline models and other large-scale studies in the literature. Results and Conclusions: Our model shows consistent and substantial performance improvements compared to ROI-scale-only models. It achieves 80.3% AUROC, a statistically significant improvement over ROI-scale classification. We also compare our method to large studies on prostate cancer detection, using other imaging modalities. Our code is publicly available at www.github.com/med-i-lab/TRUSFormer
Envisioning the Next-Gen Document Reader
Feb 15, 2023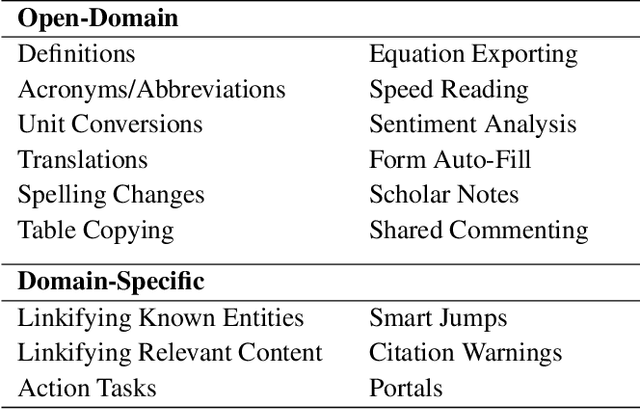
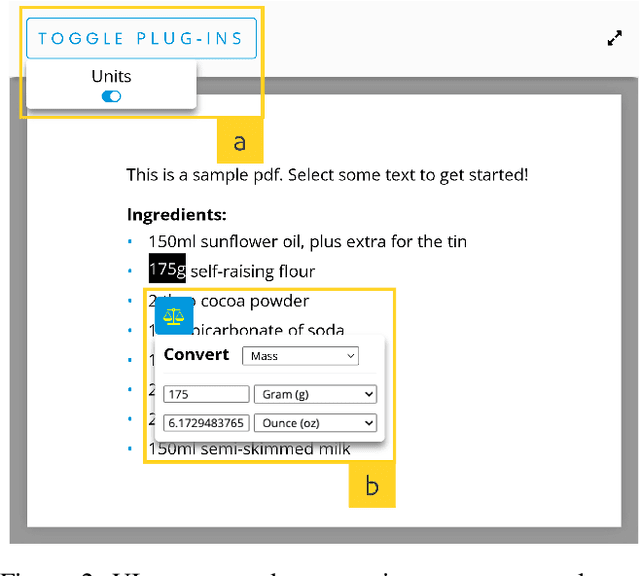

People read digital documents on a daily basis to share, exchange, and understand information in electronic settings. However, current document readers create a static, isolated reading experience, which does not support users' goals of gaining more knowledge and performing additional tasks through document interaction. In this work, we present our vision for the next-gen document reader that strives to enhance user understanding and create a more connected, trustworthy information experience. We describe 18 NLP-powered features to add to existing document readers and propose a novel plug-in marketplace that allows users to further customize their reading experience, as demonstrated through 3 exploratory UI prototypes available at https://github.com/catherinesyeh/nextgen-prototypes
Lag selection and estimation of stable parameters for multiple autoregressive processes through convex programming
Mar 03, 2023Motivated by a variety of applications, high-dimensional time series have become an active topic of research. In particular, several methods and finite-sample theories for individual stable autoregressive processes with known lag have become available very recently. We, instead, consider multiple stable autoregressive processes that share an unknown lag. We use information across the different processes to simultaneously select the lag and estimate the parameters. We prove that the estimated process is stable, and we establish rates for the forecasting error that can outmatch the known rate in our setting. Our insights on the lag selection and the stability are also of interest for the case of individual autoregressive processes.
Information bottleneck theory of high-dimensional regression: relevancy, efficiency and optimality
Aug 08, 2022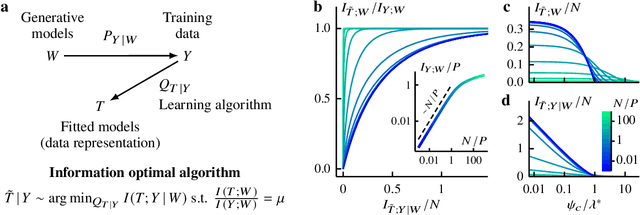
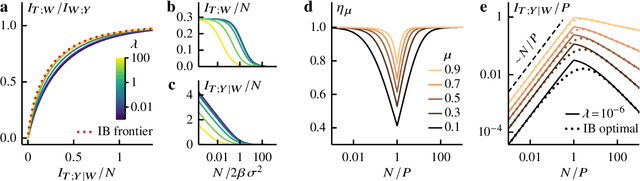
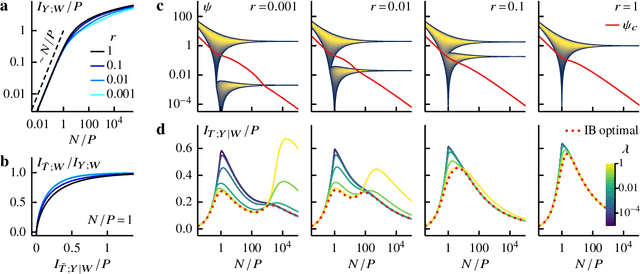
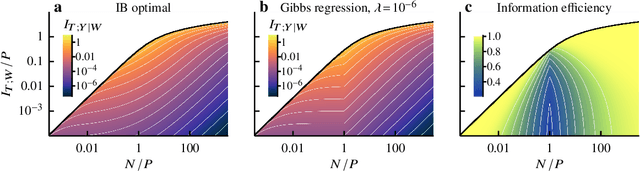
Avoiding overfitting is a central challenge in machine learning, yet many large neural networks readily achieve zero training loss. This puzzling contradiction necessitates new approaches to the study of overfitting. Here we quantify overfitting via residual information, defined as the bits in fitted models that encode noise in training data. Information efficient learning algorithms minimize residual information while maximizing the relevant bits, which are predictive of the unknown generative models. We solve this optimization to obtain the information content of optimal algorithms for a linear regression problem and compare it to that of randomized ridge regression. Our results demonstrate the fundamental tradeoff between residual and relevant information and characterize the relative information efficiency of randomized regression with respect to optimal algorithms. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil information-theoretic analogs of double and multiple descent phenomena.
Federated Learning for ASR based on Wav2vec 2.0
Feb 20, 2023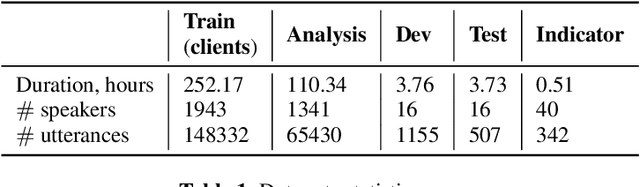
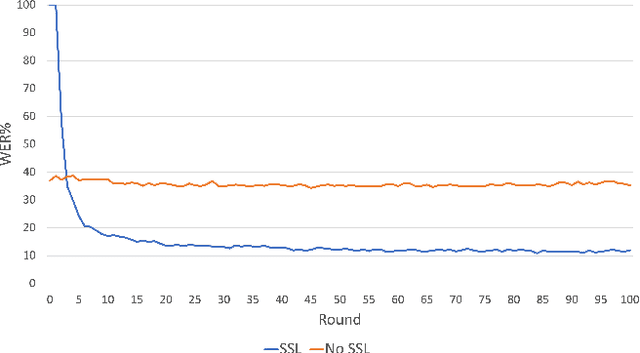
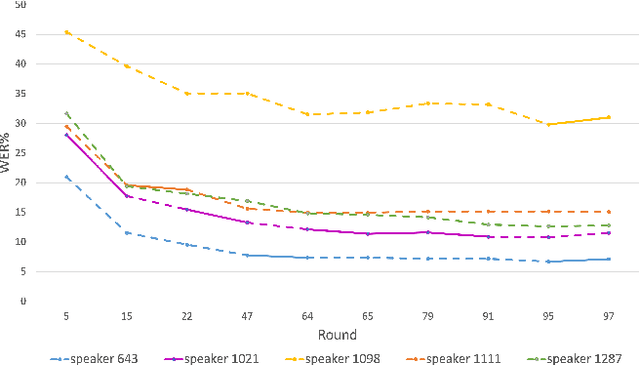
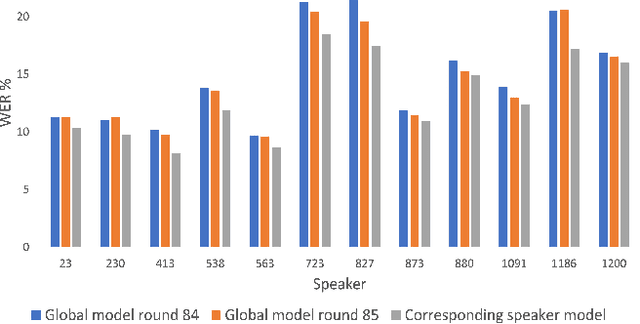
This paper presents a study on the use of federated learning to train an ASR model based on a wav2vec 2.0 model pre-trained by self supervision. Carried out on the well-known TED-LIUM 3 dataset, our experiments show that such a model can obtain, with no use of a language model, a word error rate of 10.92% on the official TED-LIUM 3 test set, without sharing any data from the different users. We also analyse the ASR performance for speakers depending to their participation to the federated learning. Since federated learning was first introduced for privacy purposes, we also measure its ability to protect speaker identity. To do that, we exploit an approach to analyze information contained in exchanged models based on a neural network footprint on an indicator dataset. This analysis is made layer-wise and shows which layers in an exchanged wav2vec 2.0 based model bring the speaker identity information.