 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Event Voxel Set Transformer for Spatiotemporal Representation Learning on Event Streams
Mar 07, 2023
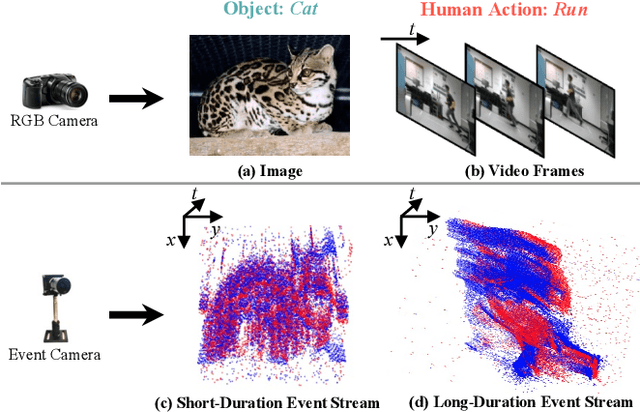
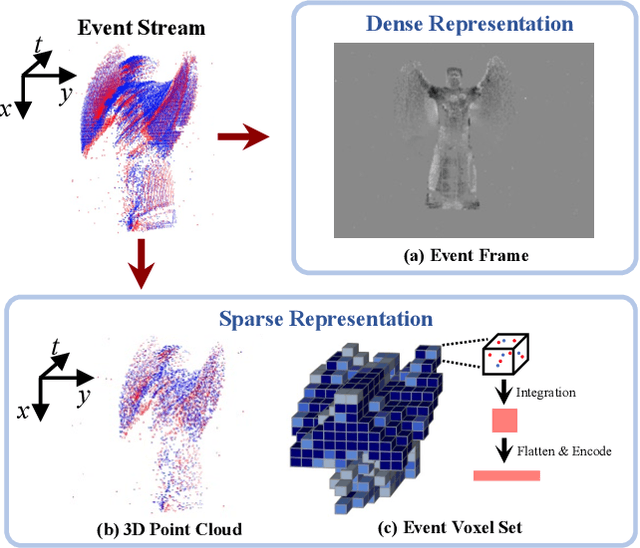
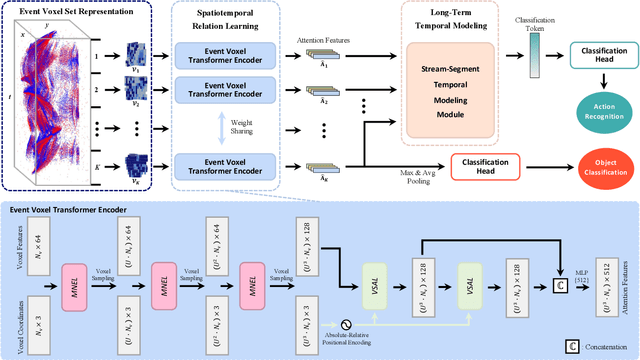
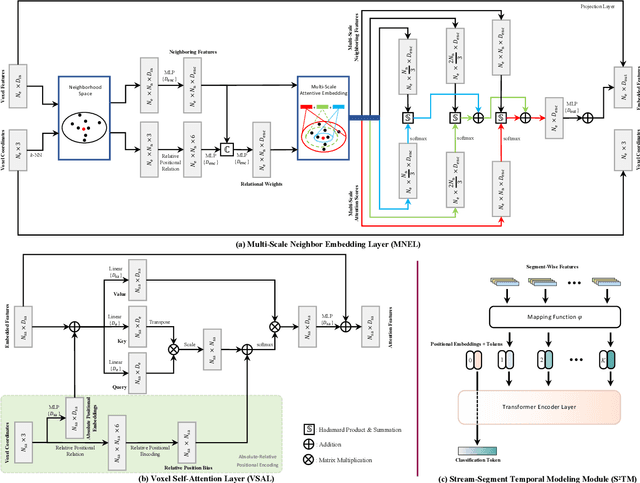
Event cameras are neuromorphic vision sensors representing visual information as sparse and asynchronous event streams. Most state-of-the-art event-based methods project events into dense frames and process them with conventional learning models. However, these approaches sacrifice the sparsity and high temporal resolution of event data, resulting in a large model size and high computational complexity. To fit the sparse nature of events and sufficiently explore their implicit relationship, we develop a novel attention-aware framework named Event Voxel Set Transformer (EVSTr) for spatiotemporal representation learning on event streams. It first converts the event stream into a voxel set and then hierarchically aggregates voxel features to obtain robust representations. The core of EVSTr is an event voxel transformer encoder to extract discriminative spatiotemporal features, which consists of two well-designed components, including a multi-scale neighbor embedding layer (MNEL) for local information aggregation and a voxel self-attention layer (VSAL) for global representation modeling. Enabling the framework to incorporate a long-term temporal structure, we introduce a segmental consensus strategy for modeling motion patterns over a sequence of segmented voxel sets. We evaluate the proposed framework on two event-based tasks: object classification and action recognition. Comprehensive experiments show that EVSTr achieves state-of-the-art performance while maintaining low model complexity. Additionally, we present a new dataset (NeuroHAR) recorded in challenging visual scenarios to address the lack of real-world event-based datasets for action recognition.
Random Padding Data Augmentation
Feb 17, 2023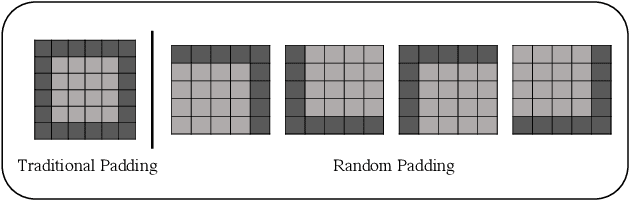
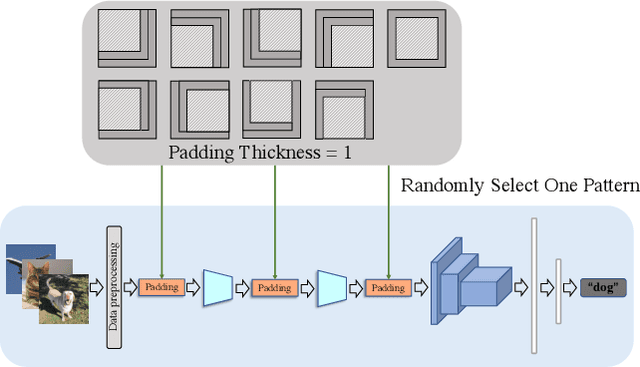
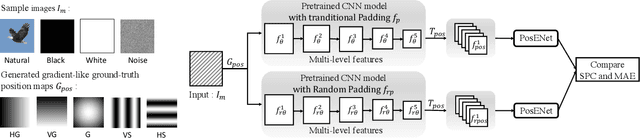
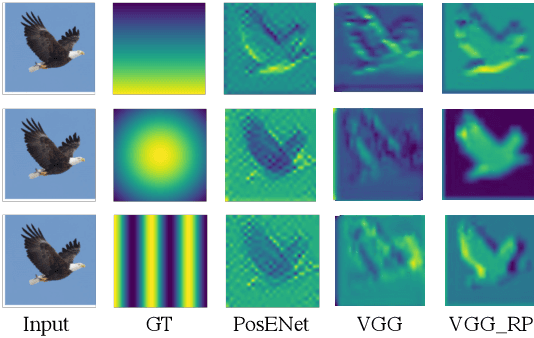
The convolutional neural network (CNN) learns the same object in different positions in images, which can improve the recognition accuracy of the model. An implication of this is that CNN may know where the object is. The usefulness of the features' spatial information in CNNs has not been well investigated. In this paper, we found that the model's learning of features' position information hindered the learning of the features' relationship. Therefore, we introduced Random Padding, a new type of padding method for training CNNs that impairs the architecture's capacity to learn position information by adding zero-padding randomly to half of the border of feature maps. Random Padding is parameter-free, simple to construct, and compatible with the majority of CNN-based recognition models. This technique is also complementary to data augmentations such as random cropping, rotation, flipping and erasing, and consistently improves the performance of image classification over strong baselines.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023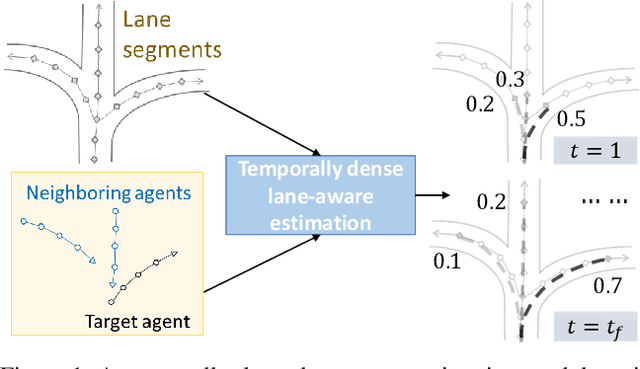
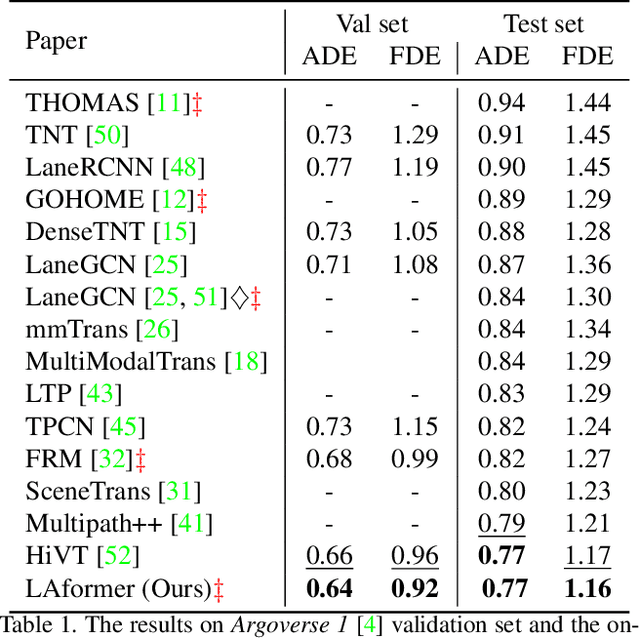
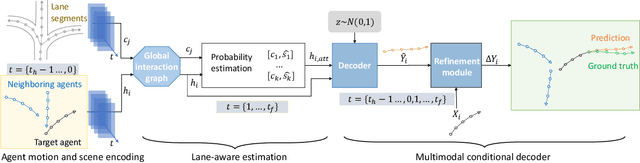
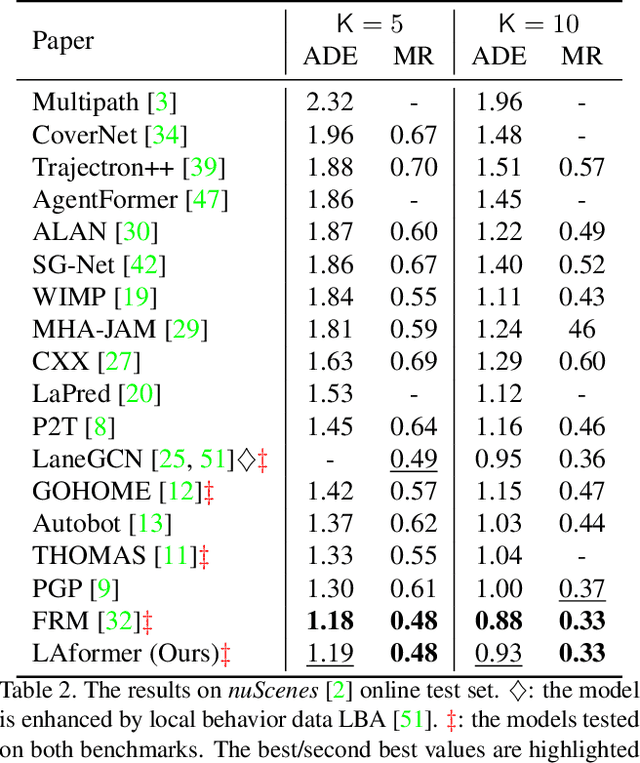
Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.
Towards Scalable Neural Representation for Diverse Videos
Mar 24, 2023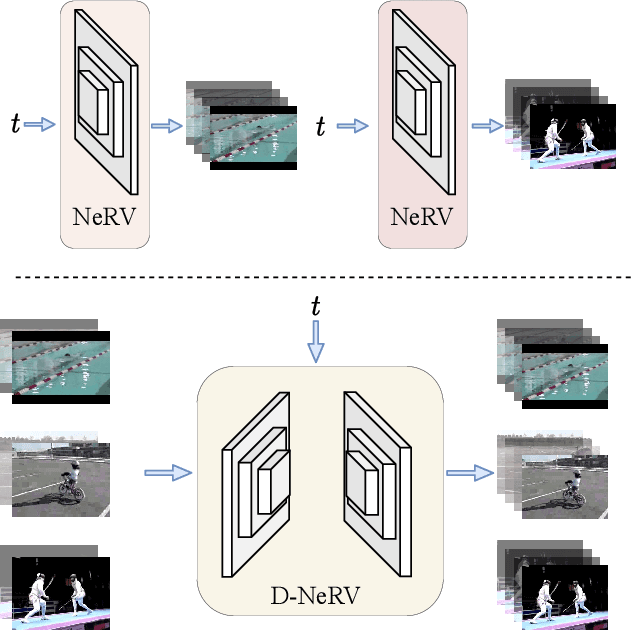
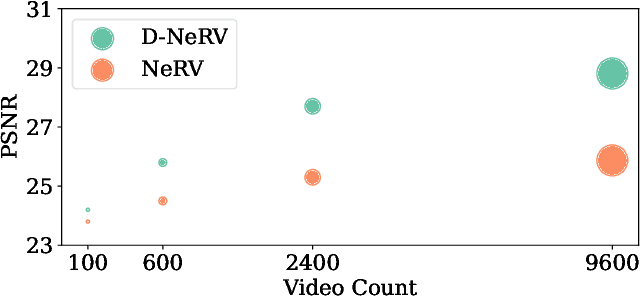
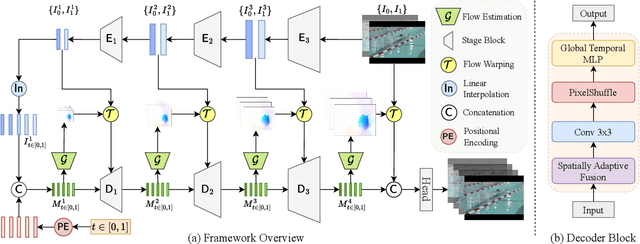
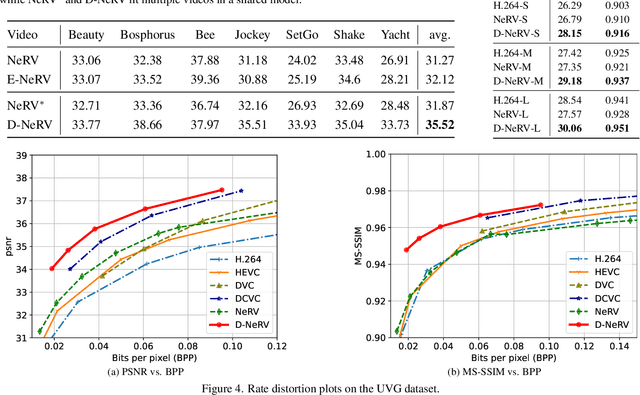
Implicit neural representations (INR) have gained increasing attention in representing 3D scenes and images, and have been recently applied to encode videos (e.g., NeRV, E-NeRV). While achieving promising results, existing INR-based methods are limited to encoding a handful of short videos (e.g., seven 5-second videos in the UVG dataset) with redundant visual content, leading to a model design that fits individual video frames independently and is not efficiently scalable to a large number of diverse videos. This paper focuses on developing neural representations for a more practical setup -- encoding long and/or a large number of videos with diverse visual content. We first show that instead of dividing videos into small subsets and encoding them with separate models, encoding long and diverse videos jointly with a unified model achieves better compression results. Based on this observation, we propose D-NeRV, a novel neural representation framework designed to encode diverse videos by (i) decoupling clip-specific visual content from motion information, (ii) introducing temporal reasoning into the implicit neural network, and (iii) employing the task-oriented flow as intermediate output to reduce spatial redundancies. Our new model largely surpasses NeRV and traditional video compression techniques on UCF101 and UVG datasets on the video compression task. Moreover, when used as an efficient data-loader, D-NeRV achieves 3%-10% higher accuracy than NeRV on action recognition tasks on the UCF101 dataset under the same compression ratios.
GQE-Net: A Graph-based Quality Enhancement Network for Point Cloud Color Attribute
Mar 24, 2023

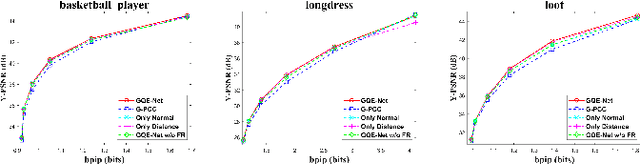
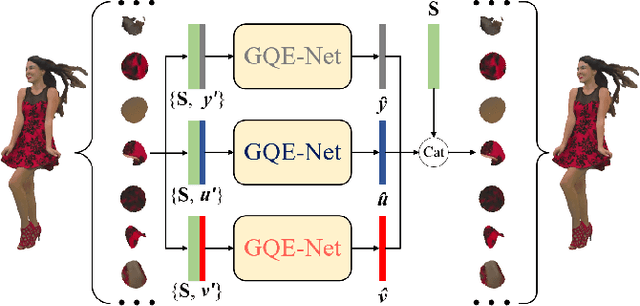
In recent years, point clouds have become increasingly popular for representing three-dimensional (3D) visual objects and scenes. To efficiently store and transmit point clouds, compression methods have been developed, but they often result in a degradation of quality. To reduce color distortion in point clouds, we propose a graph-based quality enhancement network (GQE-Net) that uses geometry information as an auxiliary input and graph convolution blocks to extract local features efficiently. Specifically, we use a parallel-serial graph attention module with a multi-head graph attention mechanism to focus on important points or features and help them fuse together. Additionally, we design a feature refinement module that takes into account the normals and geometry distance between points. To work within the limitations of GPU memory capacity, the distorted point cloud is divided into overlap-allowed 3D patches, which are sent to GQE-Net for quality enhancement. To account for differences in data distribution among different color omponents, three models are trained for the three color components. Experimental results show that our method achieves state-of-the-art performance. For example, when implementing GQE-Net on the recent G-PCC coding standard test model, 0.43 dB, 0.25 dB, and 0.36 dB Bjontegaard delta (BD)-peak-signal-to-noise ratio (PSNR), corresponding to 14.0%, 9.3%, and 14.5% BD-rate savings can be achieved on dense point clouds for the Y, Cb, and Cr components, respectively.
MoWE: Mixture of Weather Experts for Multiple Adverse Weather Removal
Mar 24, 2023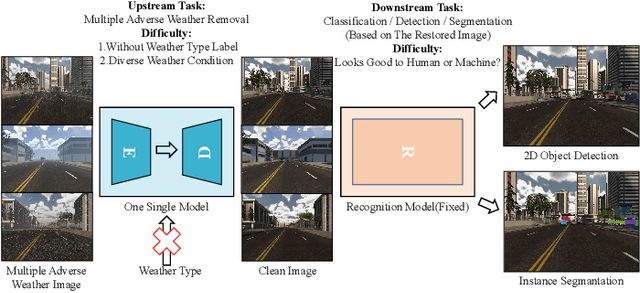
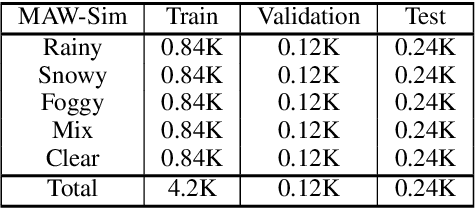
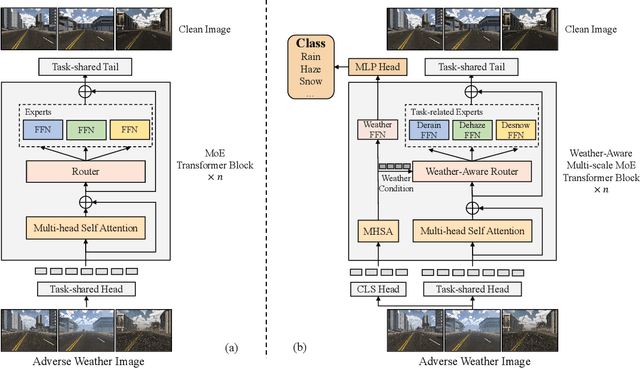
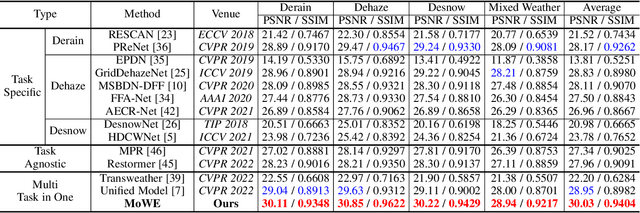
Currently, most adverse weather removal tasks are handled independently, such as deraining, desnowing, and dehazing. However, in autonomous driving scenarios, the type, intensity, and mixing degree of the weather are unknown, so the separated task setting cannot deal with these complex conditions well. Besides, the vision applications in autonomous driving often aim at high-level tasks, but existing weather removal methods neglect the connection between performance on perceptual tasks and signal fidelity. To this end, in upstream task, we propose a novel \textbf{Mixture of Weather Experts(MoWE)} Transformer framework to handle complex weather removal in a perception-aware fashion. We design a \textbf{Weather-aware Router} to make the experts targeted more relevant to weather types while without the need for weather type labels during inference. To handle diverse weather conditions, we propose \textbf{Multi-scale Experts} to fuse information among neighbor tokens. In downstream task, we propose a \textbf{Label-free Perception-aware Metric} to measure whether the outputs of image processing models are suitable for high level perception tasks without the demand for semantic labels. We collect a syntactic dataset \textbf{MAW-Sim} towards autonomous driving scenarios to benchmark the multiple weather removal performance of existing methods. Our MoWE achieves SOTA performance in upstream task on the proposed dataset and two public datasets, i.e. All-Weather and Rain/Fog-Cityscapes, and also have better perceptual results in downstream segmentation task compared to other methods. Our codes and datasets will be released after acceptance.
Wave-U-Net Discriminator: Fast and Lightweight Discriminator for Generative Adversarial Network-Based Speech Synthesis
Mar 24, 2023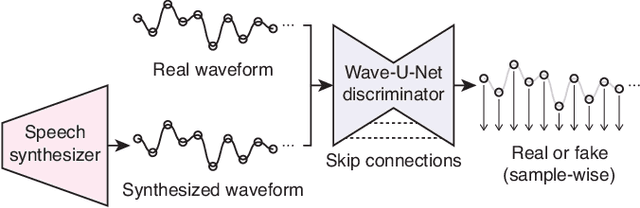
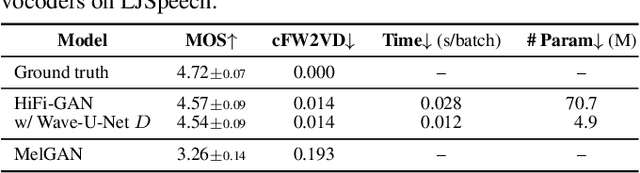
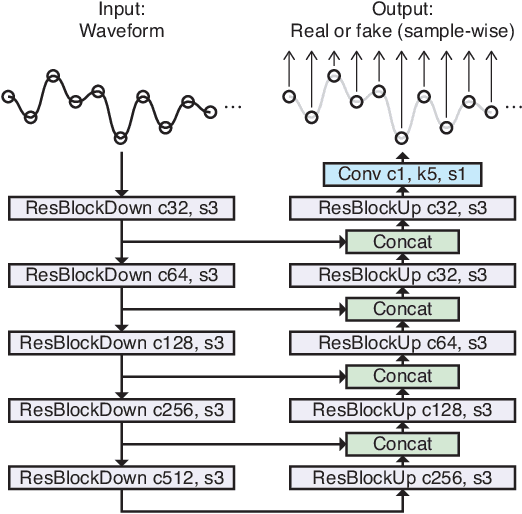
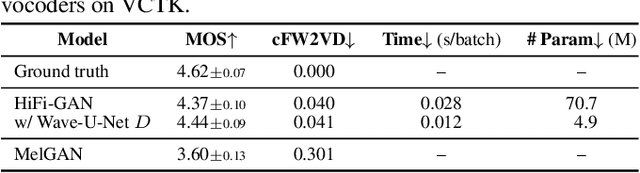
In speech synthesis, a generative adversarial network (GAN), training a generator (speech synthesizer) and a discriminator in a min-max game, is widely used to improve speech quality. An ensemble of discriminators is commonly used in recent neural vocoders (e.g., HiFi-GAN) and end-to-end text-to-speech (TTS) systems (e.g., VITS) to scrutinize waveforms from multiple perspectives. Such discriminators allow synthesized speech to adequately approach real speech; however, they require an increase in the model size and computation time according to the increase in the number of discriminators. Alternatively, this study proposes a Wave-U-Net discriminator, which is a single but expressive discriminator with Wave-U-Net architecture. This discriminator is unique; it can assess a waveform in a sample-wise manner with the same resolution as the input signal, while extracting multilevel features via an encoder and decoder with skip connections. This architecture provides a generator with sufficiently rich information for the synthesized speech to be closely matched to the real speech. During the experiments, the proposed ideas were applied to a representative neural vocoder (HiFi-GAN) and an end-to-end TTS system (VITS). The results demonstrate that the proposed models can achieve comparable speech quality with a 2.31 times faster and 14.5 times more lightweight discriminator when used in HiFi-GAN and a 1.90 times faster and 9.62 times more lightweight discriminator when used in VITS. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/waveunetd/.
SIM-Trans: Structure Information Modeling Transformer for Fine-grained Visual Categorization
Aug 31, 2022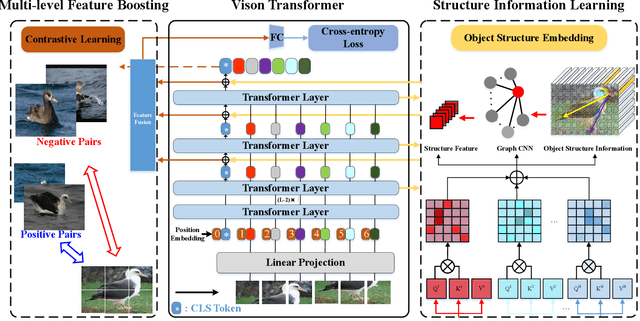
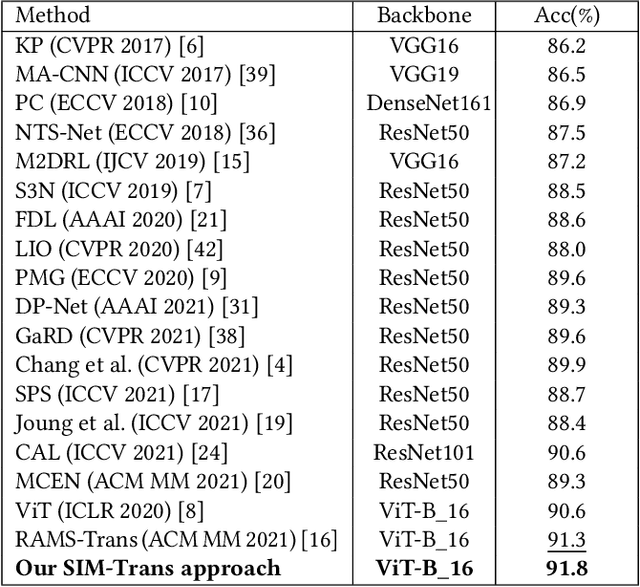
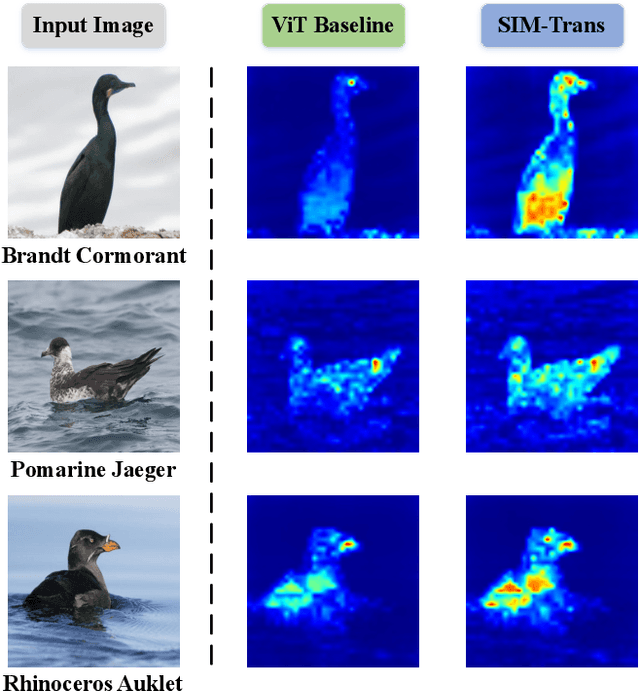
Fine-grained visual categorization (FGVC) aims at recognizing objects from similar subordinate categories, which is challenging and practical for human's accurate automatic recognition needs. Most FGVC approaches focus on the attention mechanism research for discriminative regions mining while neglecting their interdependencies and composed holistic object structure, which are essential for model's discriminative information localization and understanding ability. To address the above limitations, we propose the Structure Information Modeling Transformer (SIM-Trans) to incorporate object structure information into transformer for enhancing discriminative representation learning to contain both the appearance information and structure information. Specifically, we encode the image into a sequence of patch tokens and build a strong vision transformer framework with two well-designed modules: (i) the structure information learning (SIL) module is proposed to mine the spatial context relation of significant patches within the object extent with the help of the transformer's self-attention weights, which is further injected into the model for importing structure information; (ii) the multi-level feature boosting (MFB) module is introduced to exploit the complementary of multi-level features and contrastive learning among classes to enhance feature robustness for accurate recognition. The proposed two modules are light-weighted and can be plugged into any transformer network and trained end-to-end easily, which only depends on the attention weights that come with the vision transformer itself. Extensive experiments and analyses demonstrate that the proposed SIM-Trans achieves state-of-the-art performance on fine-grained visual categorization benchmarks. The code is available at https://github.com/PKU-ICST-MIPL/SIM-Trans_ACMMM2022.
Towards Proactively Forecasting Sentence-Specific Information Popularity within Online News Documents
Dec 31, 2022
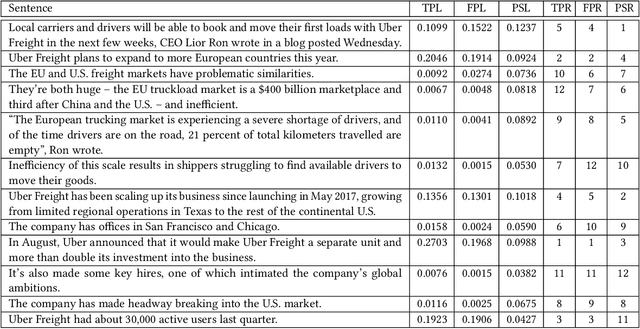
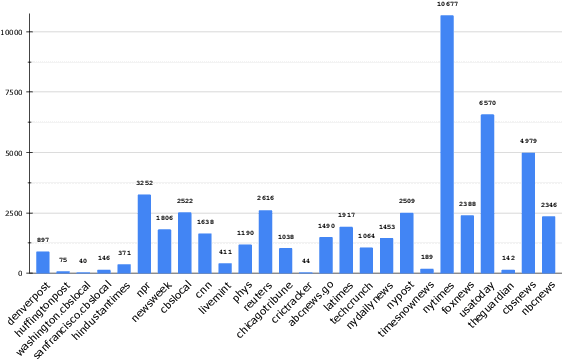
Multiple studies have focused on predicting the prospective popularity of an online document as a whole, without paying attention to the contributions of its individual parts. We introduce the task of proactively forecasting popularities of sentences within online news documents solely utilizing their natural language content. We model sentence-specific popularity forecasting as a sequence regression task. For training our models, we curate InfoPop, the first dataset containing popularity labels for over 1.7 million sentences from over 50,000 online news documents. To the best of our knowledge, this is the first dataset automatically created using streams of incoming search engine queries to generate sentence-level popularity annotations. We propose a novel transfer learning approach involving sentence salience prediction as an auxiliary task. Our proposed technique coupled with a BERT-based neural model exceeds nDCG values of 0.8 for proactive sentence-specific popularity forecasting. Notably, our study presents a non-trivial takeaway: though popularity and salience are different concepts, transfer learning from salience prediction enhances popularity forecasting. We release InfoPop and make our code publicly available: https://github.com/sayarghoshroy/InfoPopularity
* In 33rd ACM Conference on Hypertext and Social Media [HT '22] (Main Track), Link: https://dl.acm.org/doi/10.1145/3511095.3531268
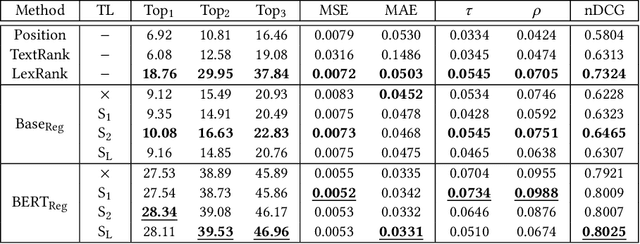
TypeT5: Seq2seq Type Inference using Static Analysis
Mar 16, 2023
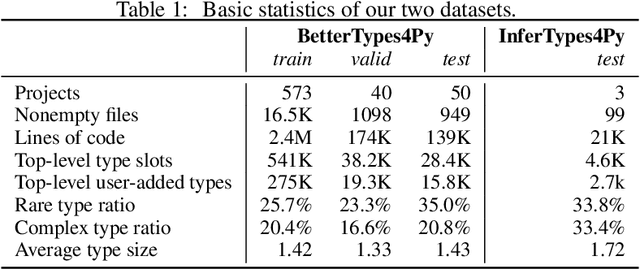
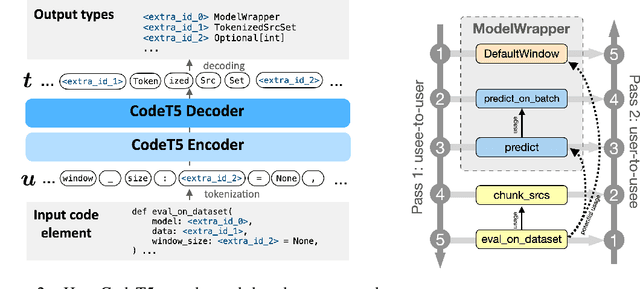
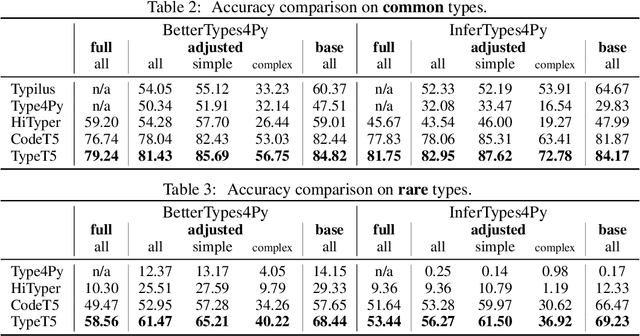
There has been growing interest in automatically predicting missing type annotations in programs written in Python and JavaScript. While prior methods have achieved impressive accuracy when predicting the most common types, they often perform poorly on rare or complex types. In this paper, we present a new type inference method that treats type prediction as a code infilling task by leveraging CodeT5, a state-of-the-art seq2seq pre-trained language model for code. Our method uses static analysis to construct dynamic contexts for each code element whose type signature is to be predicted by the model. We also propose an iterative decoding scheme that incorporates previous type predictions in the model's input context, allowing information exchange between related code elements. Our evaluation shows that the proposed approach, TypeT5, not only achieves a higher overall accuracy (particularly on rare and complex types) but also produces more coherent results with fewer type errors -- while enabling easy user intervention.