 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023
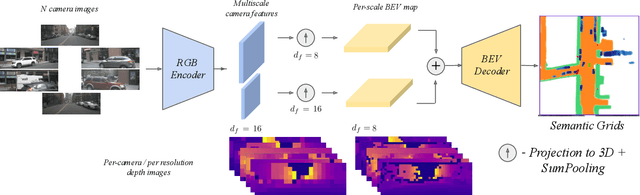

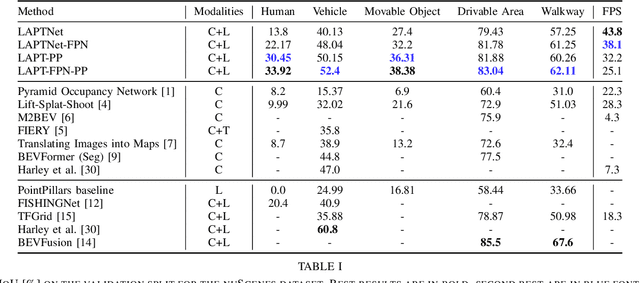
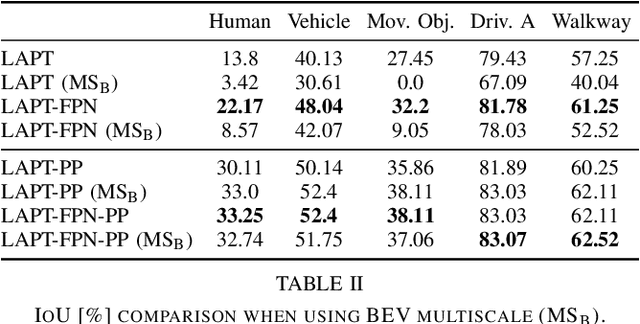
Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
Sufficient dimension reduction for feature matrices
Mar 07, 2023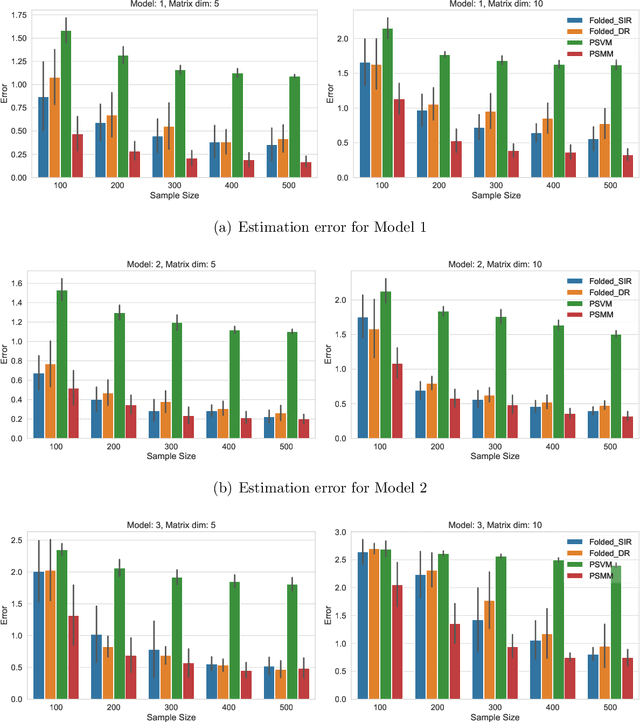
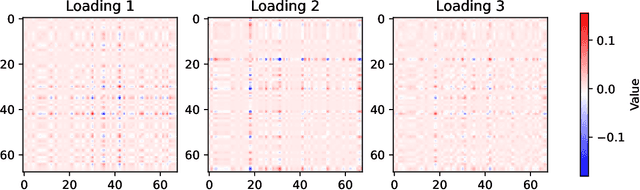
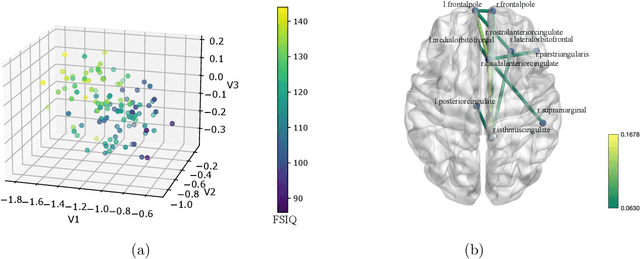
We address the problem of sufficient dimension reduction for feature matrices, which arises often in sensor network localization, brain neuroimaging, and electroencephalography analysis. In general, feature matrices have both row- and column-wise interpretations and contain structural information that can be lost with naive vectorization approaches. To address this, we propose a method called principal support matrix machine (PSMM) for the matrix sufficient dimension reduction. The PSMM converts the sufficient dimension reduction problem into a series of classification problems by dividing the response variables into slices. It effectively utilizes the matrix structure by finding hyperplanes with rank-1 normal matrix that optimally separate the sliced responses. Additionally, we extend our approach to the higher-order tensor case. Our numerical analysis demonstrates that the PSMM outperforms existing methods and has strong interpretability in real data applications.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023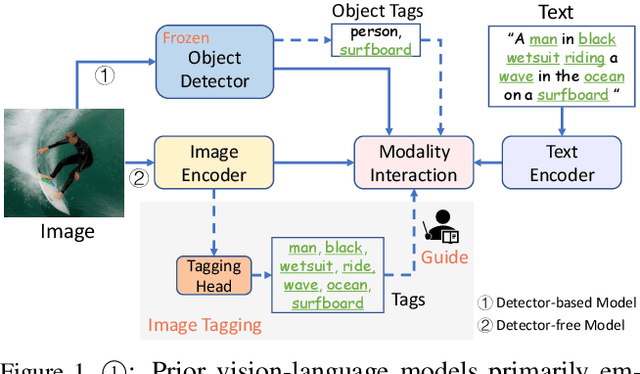
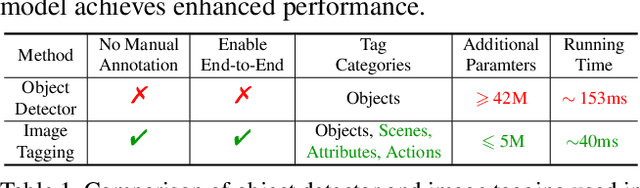

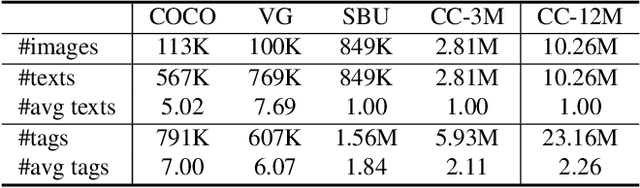
This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
DDS3D: Dense Pseudo-Labels with Dynamic Threshold for Semi-Supervised 3D Object Detection
Mar 10, 2023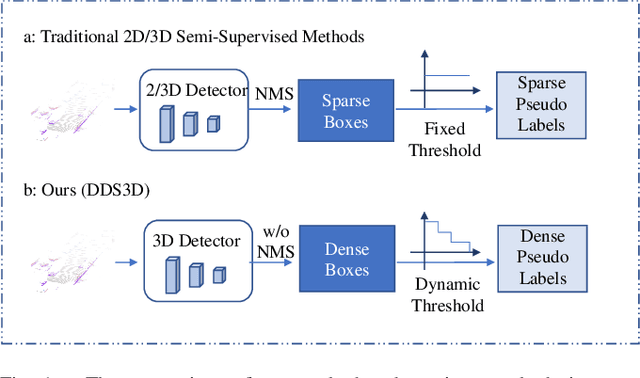
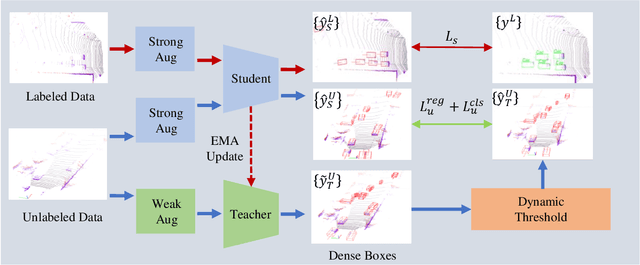
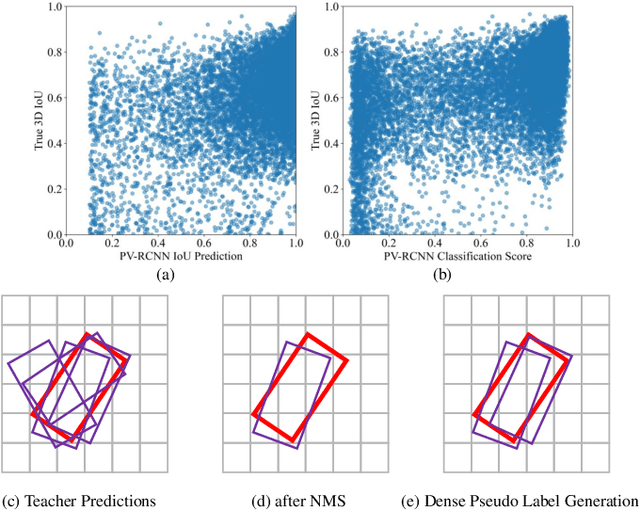
In this paper, we present a simple yet effective semi-supervised 3D object detector named DDS3D. Our main contributions have two-fold. On the one hand, different from previous works using Non-Maximal Suppression (NMS) or its variants for obtaining the sparse pseudo labels, we propose a dense pseudo-label generation strategy to get dense pseudo-labels, which can retain more potential supervision information for the student network. On the other hand, instead of traditional fixed thresholds, we propose a dynamic threshold manner to generate pseudo-labels, which can guarantee the quality and quantity of pseudo-labels during the whole training process. Benefiting from these two components, our DDS3D outperforms the state-of-the-art semi-supervised 3d object detection with mAP of 3.1% on the pedestrian and 2.1% on the cyclist under the same configuration of 1% samples. Extensive ablation studies on the KITTI dataset demonstrate the effectiveness of our DDS3D. The code and models will be made publicly available at https://github.com/hust-jy/DDS3D
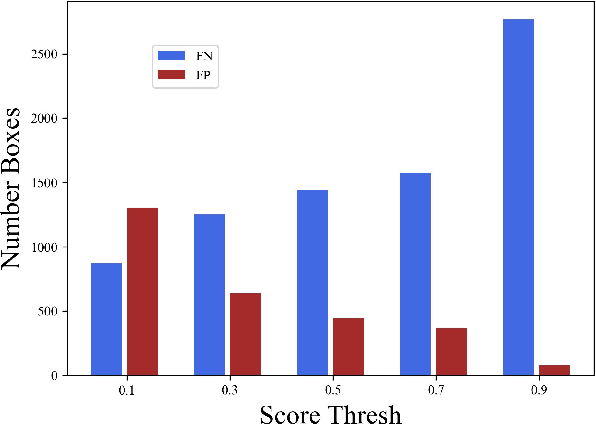
Accurate Real-time Polyp Detection in Videos from Concatenation of Latent Features Extracted from Consecutive Frames
Mar 10, 2023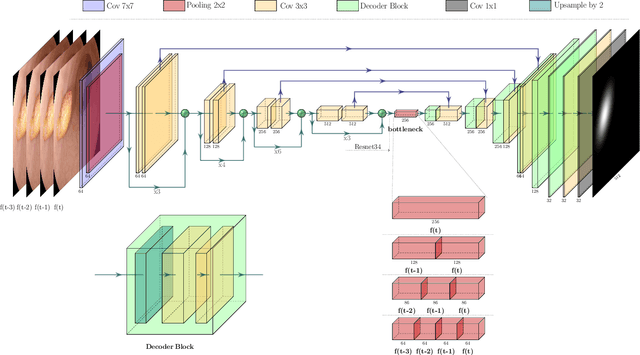
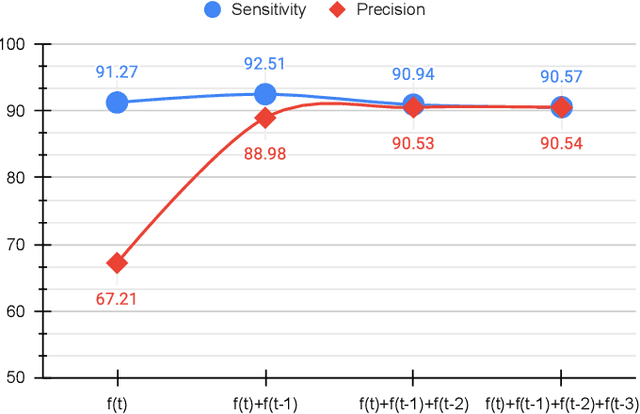

An efficient deep learning model that can be implemented in real-time for polyp detection is crucial to reducing polyp miss-rate during screening procedures. Convolutional neural networks (CNNs) are vulnerable to small changes in the input image. A CNN-based model may miss the same polyp appearing in a series of consecutive frames and produce unsubtle detection output due to changes in camera pose, lighting condition, light reflection, etc. In this study, we attempt to tackle this problem by integrating temporal information among neighboring frames. We propose an efficient feature concatenation method for a CNN-based encoder-decoder model without adding complexity to the model. The proposed method incorporates extracted feature maps of previous frames to detect polyps in the current frame. The experimental results demonstrate that the proposed method of feature concatenation improves the overall performance of automatic polyp detection in videos. The following results are obtained on a public video dataset: sensitivity 90.94\%, precision 90.53\%, and specificity 92.46%
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023
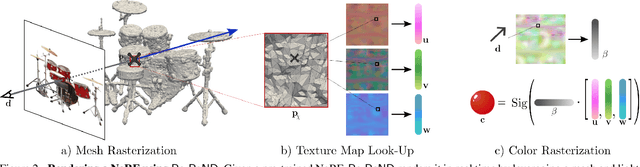
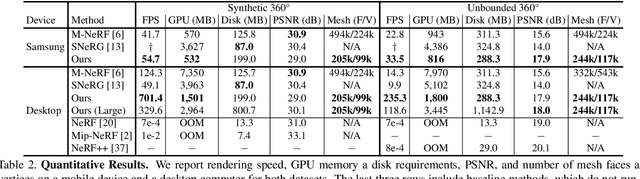
This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
FTM: A Frame-level Timeline Modeling Method for Temporal Graph Representation Learning
Mar 15, 2023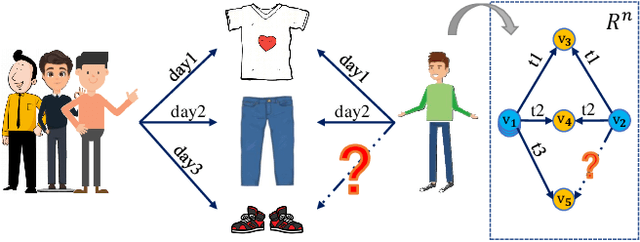
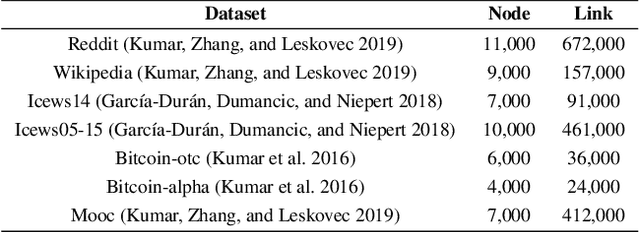

Learning representations for graph-structured data is essential for graph analytical tasks. While remarkable progress has been made on static graphs, researches on temporal graphs are still in its beginning stage. The bottleneck of the temporal graph representation learning approach is the neighborhood aggregation strategy, based on which graph attributes share and gather information explicitly. Existing neighborhood aggregation strategies fail to capture either the short-term features or the long-term features of temporal graph attributes, leading to unsatisfactory model performance and even poor robustness and domain generality of the representation learning method. To address this problem, we propose a Frame-level Timeline Modeling (FTM) method that helps to capture both short-term and long-term features and thus learns more informative representations on temporal graphs. In particular, we present a novel link-based framing technique to preserve the short-term features and then incorporate a timeline aggregator module to capture the intrinsic dynamics of graph evolution as long-term features. Our method can be easily assembled with most temporal GNNs. Extensive experiments on common datasets show that our method brings great improvements to the capability, robustness, and domain generality of backbone methods in downstream tasks. Our code can be found at https://github.com/yeeeqichen/FTM.
FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors
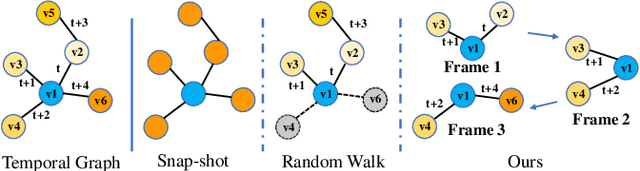
Mar 15, 2023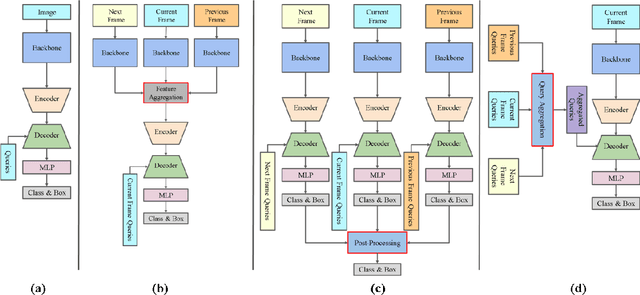
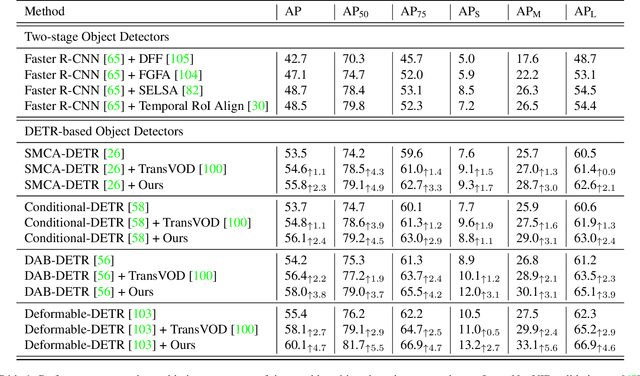
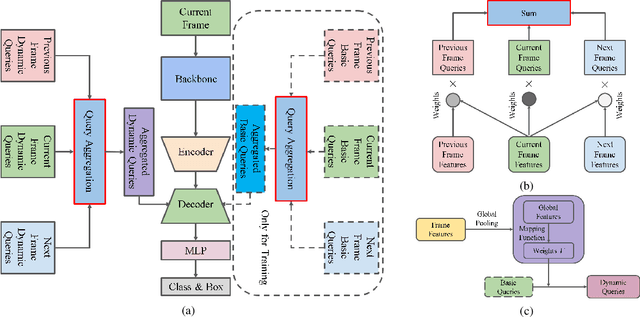
Video object detection needs to solve feature degradation situations that rarely happen in the image domain. One solution is to use the temporal information and fuse the features from the neighboring frames. With Transformerbased object detectors getting a better performance on the image domain tasks, recent works began to extend those methods to video object detection. However, those existing Transformer-based video object detectors still follow the same pipeline as those used for classical object detectors, like enhancing the object feature representations by aggregation. In this work, we take a different perspective on video object detection. In detail, we improve the qualities of queries for the Transformer-based models by aggregation. To achieve this goal, we first propose a vanilla query aggregation module that weighted averages the queries according to the features of the neighboring frames. Then, we extend the vanilla module to a more practical version, which generates and aggregates queries according to the features of the input frames. Extensive experimental results validate the effectiveness of our proposed methods: On the challenging ImageNet VID benchmark, when integrated with our proposed modules, the current state-of-the-art Transformer-based object detectors can be improved by more than 2.4% on mAP and 4.2% on AP50.
Observation of Periodic Systems: Bridge Centralized Kalman Filtering and Consensus-Based Distributed Filtering
Mar 15, 2023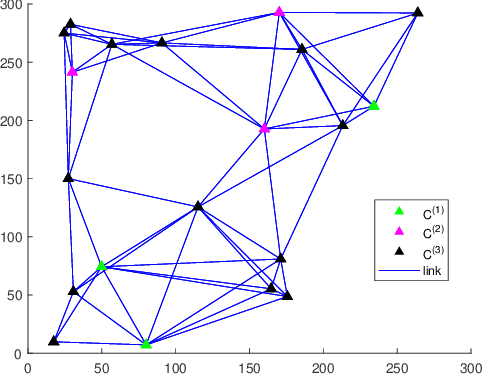
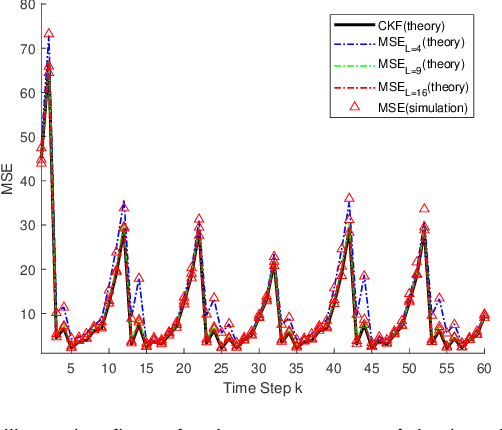
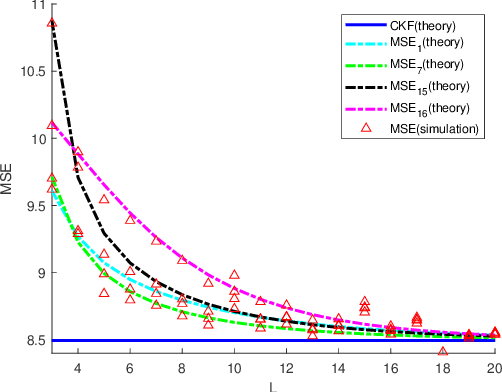
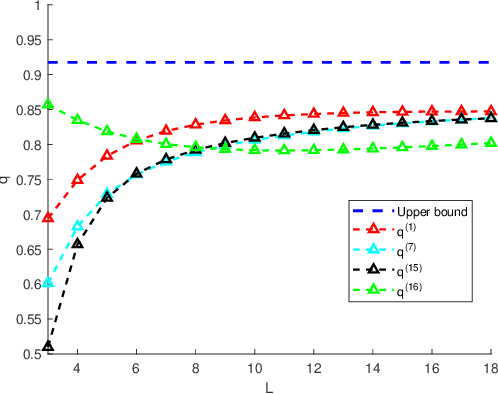
Compared with linear time invariant systems, linear periodic system can describe the periodic processes arising from nature and engineering more precisely. However, the time-varying system parameters increase the difficulty of the research on periodic system, such as stabilization and observation. This paper aims to consider the observation problem of periodic systems by bridging two fundamental filtering algorithms for periodic systems with a sensor network: consensus-on-measurement-based distributed filtering (CMDF) and centralized Kalman filtering (CKF). Firstly, one mild convergence condition based on uniformly collective observability is established for CMDF, under which the filtering performance of CMDF can be formulated as a symmetric periodic positive semidefinite (SPPS) solution to a discrete-time periodic Lyapunov equation. Then, the closed form of the performance gap between CMDF and CKF is presented in terms of the information fusion steps and the consensus weights of the network. Moreover, it is pointed out that the estimation error covariance of CMDF exponentially converges to the centralized one with the fusion steps tending to infinity. Altogether, these new results establish a concise and specific relationship between distributed and centralized filterings, and formulate the trade-off between the communication cost and distributed filtering performance on periodic systems. Finally, the theoretical results are verified with numerical experiments.
Automated Query Generation for Evidence Collection from Web Search Engines
Mar 15, 2023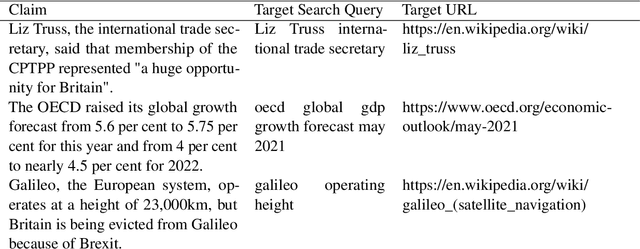
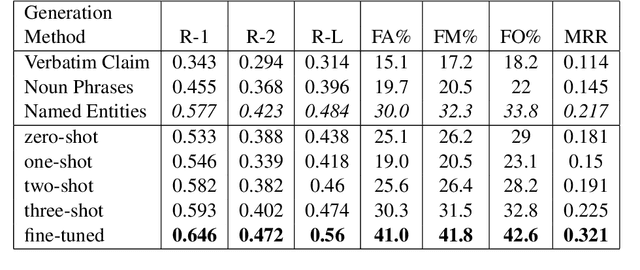
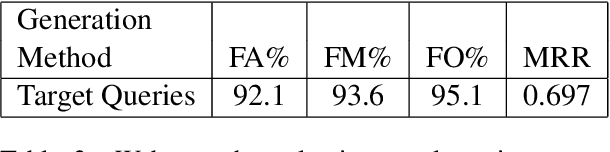
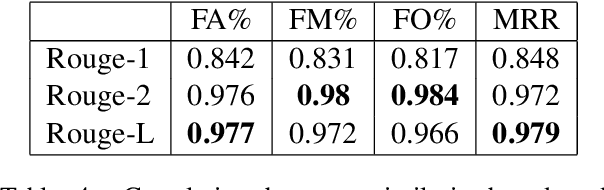
It is widely accepted that so-called facts can be checked by searching for information on the Internet. This process requires a fact-checker to formulate a search query based on the fact and to present it to a search engine. Then, relevant and believable passages need to be identified in the search results before a decision is made. This process is carried out by sub-editors at many news and media organisations on a daily basis. Here, we ask the question as to whether it is possible to automate the first step, that of query generation. Can we automatically formulate search queries based on factual statements which are similar to those formulated by human experts? Here, we consider similarity both in terms of textual similarity and with respect to relevant documents being returned by a search engine. First, we introduce a moderate-sized evidence collection dataset which includes 390 factual statements together with associated human-generated search queries and search results. Then, we investigate generating queries using a number of rule-based and automatic text generation methods based on pre-trained large language models (LLMs). We show that these methods have different merits and propose a hybrid approach which has superior performance in practice.