 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DICNet: Deep Instance-Level Contrastive Network for Double Incomplete Multi-View Multi-Label Classification
Mar 23, 2023
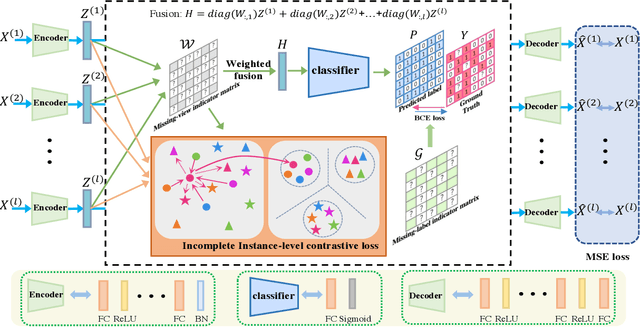
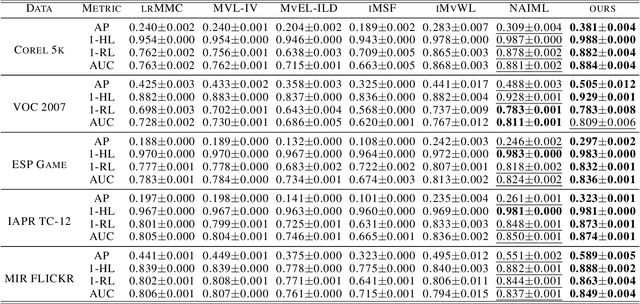
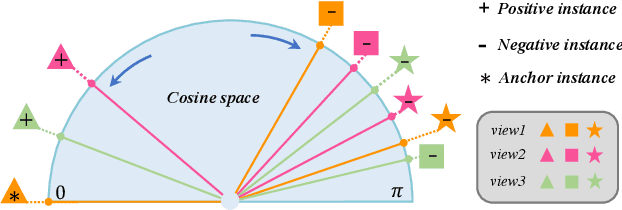
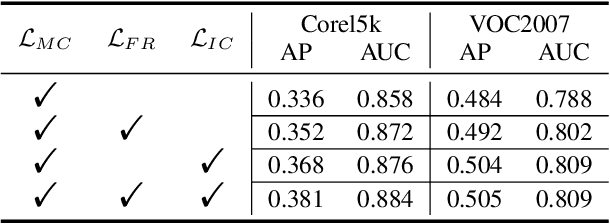
In recent years, multi-view multi-label learning has aroused extensive research enthusiasm. However, multi-view multi-label data in the real world is commonly incomplete due to the uncertain factors of data collection and manual annotation, which means that not only multi-view features are often missing, and label completeness is also difficult to be satisfied. To deal with the double incomplete multi-view multi-label classification problem, we propose a deep instance-level contrastive network, namely DICNet. Different from conventional methods, our DICNet focuses on leveraging deep neural network to exploit the high-level semantic representations of samples rather than shallow-level features. First, we utilize the stacked autoencoders to build an end-to-end multi-view feature extraction framework to learn the view-specific representations of samples. Furthermore, in order to improve the consensus representation ability, we introduce an incomplete instance-level contrastive learning scheme to guide the encoders to better extract the consensus information of multiple views and use a multi-view weighted fusion module to enhance the discrimination of semantic features. Overall, our DICNet is adept in capturing consistent discriminative representations of multi-view multi-label data and avoiding the negative effects of missing views and missing labels. Extensive experiments performed on five datasets validate that our method outperforms other state-of-the-art methods.
Prior-free Category-level Pose Estimation with Implicit Space Transformation
Mar 23, 2023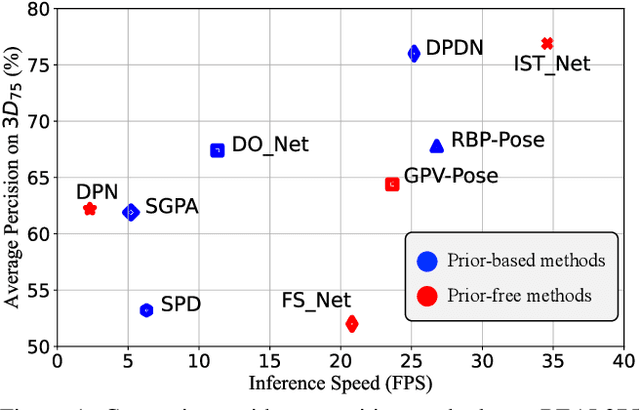
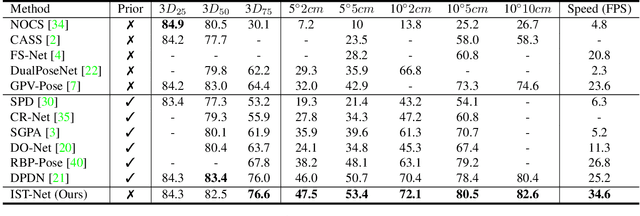
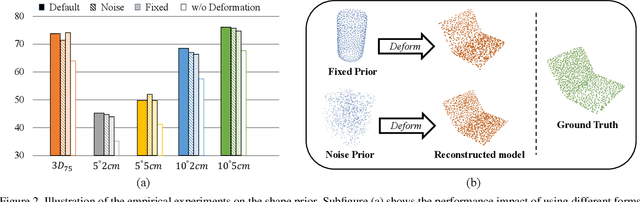
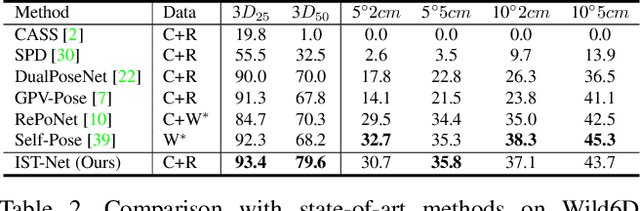
Category-level 6D pose estimation aims to predict the poses and sizes of unseen objects from a specific category. Thanks to prior deformation, which explicitly adapts a category-specific 3D prior (i.e., a 3D template) to a given object instance, prior-based methods attained great success and have become a major research stream. However, obtaining category-specific priors requires collecting a large amount of 3D models, which is labor-consuming and often not accessible in practice. This motivates us to investigate whether priors are necessary to make prior-based methods effective. Our empirical study shows that the 3D prior itself is not the credit to the high performance. The keypoint actually is the explicit deformation process, which aligns camera and world coordinates supervised by world-space 3D models (also called canonical space). Inspired by these observation, we introduce a simple prior-free implicit space transformation network, namely IST-Net, to transform camera-space features to world-space counterparts and build correspondence between them in an implicit manner without relying on 3D priors. Besides, we design camera- and world-space enhancers to enrich the features with pose-sensitive information and geometrical constraints, respectively. Albeit simple, IST-Net becomes the first prior-free method that achieves state-of-the-art performance, with top inference speed on the REAL275 dataset. Our code and models will be publicly available.
Learning and generalization of compositional representations of visual scenes
Mar 23, 2023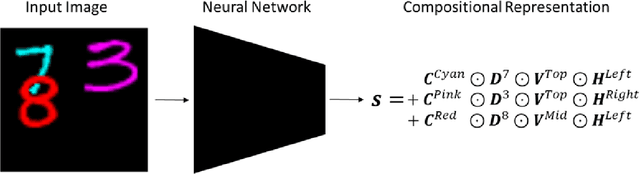
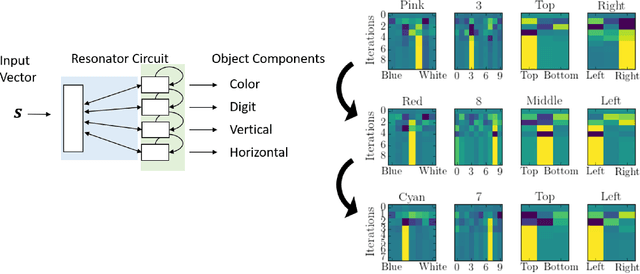
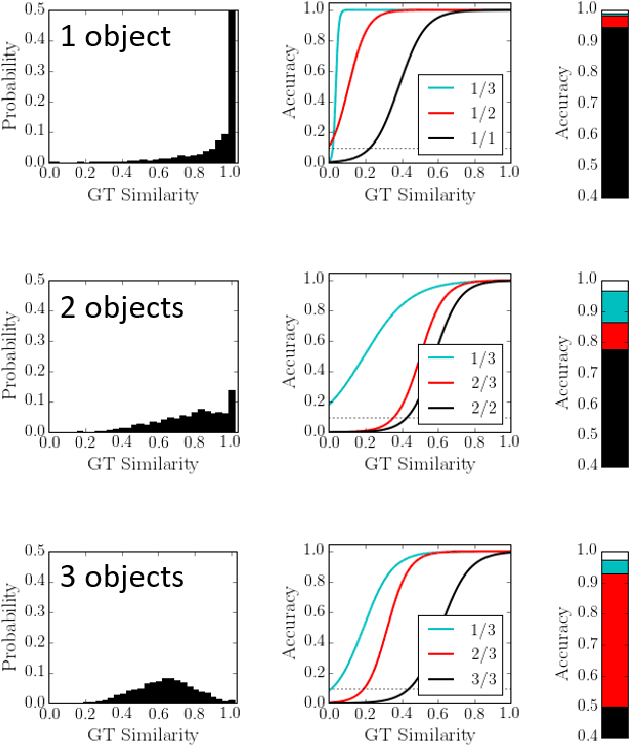
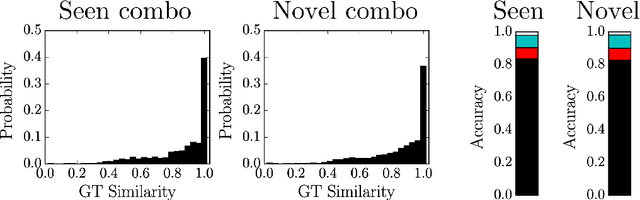
Complex visual scenes that are composed of multiple objects, each with attributes, such as object name, location, pose, color, etc., are challenging to describe in order to train neural networks. Usually,deep learning networks are trained supervised by categorical scene descriptions. The common categorical description of a scene contains the names of individual objects but lacks information about other attributes. Here, we use distributed representations of object attributes and vector operations in a vector symbolic architecture to create a full compositional description of a scene in a high-dimensional vector. To control the scene composition, we use artificial images composed of multiple, translated and colored MNIST digits. In contrast to learning category labels, here we train deep neural networks to output the full compositional vector description of an input image. The output of the deep network can then be interpreted by a VSA resonator network, to extract object identity or other properties of indiviual objects. We evaluate the performance and generalization properties of the system on randomly generated scenes. Specifically, we show that the network is able to learn the task and generalize to unseen seen digit shapes and scene configurations. Further, the generalisation ability of the trained model is limited. For example, with a gap in the training data, like an object not shown in a particular image location during training, the learning does not automatically fill this gap.
Plug-and-Play Regulators for Image-Text Matching
Mar 23, 2023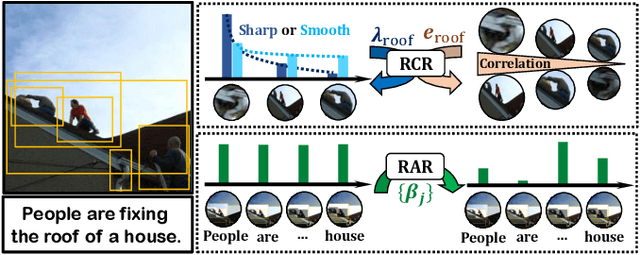
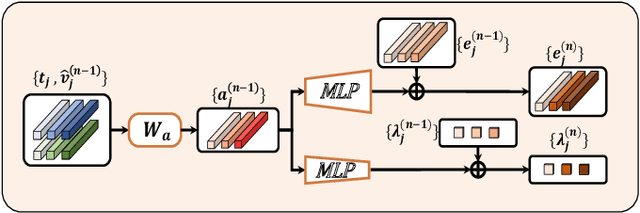
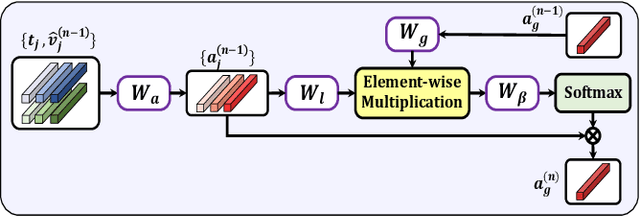
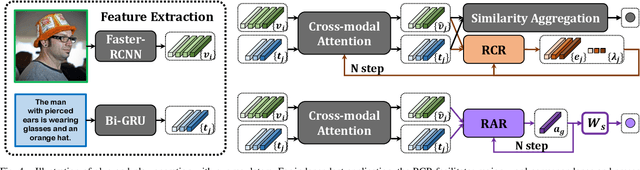
Exploiting fine-grained correspondence and visual-semantic alignments has shown great potential in image-text matching. Generally, recent approaches first employ a cross-modal attention unit to capture latent region-word interactions, and then integrate all the alignments to obtain the final similarity. However, most of them adopt one-time forward association or aggregation strategies with complex architectures or additional information, while ignoring the regulation ability of network feedback. In this paper, we develop two simple but quite effective regulators which efficiently encode the message output to automatically contextualize and aggregate cross-modal representations. Specifically, we propose (i) a Recurrent Correspondence Regulator (RCR) which facilitates the cross-modal attention unit progressively with adaptive attention factors to capture more flexible correspondence, and (ii) a Recurrent Aggregation Regulator (RAR) which adjusts the aggregation weights repeatedly to increasingly emphasize important alignments and dilute unimportant ones. Besides, it is interesting that RCR and RAR are plug-and-play: both of them can be incorporated into many frameworks based on cross-modal interaction to obtain significant benefits, and their cooperation achieves further improvements. Extensive experiments on MSCOCO and Flickr30K datasets validate that they can bring an impressive and consistent R@1 gain on multiple models, confirming the general effectiveness and generalization ability of the proposed methods. Code and pre-trained models are available at: https://github.com/Paranioar/RCAR.
NEWTON: Neural View-Centric Mapping for On-the-Fly Large-Scale SLAM
Mar 23, 2023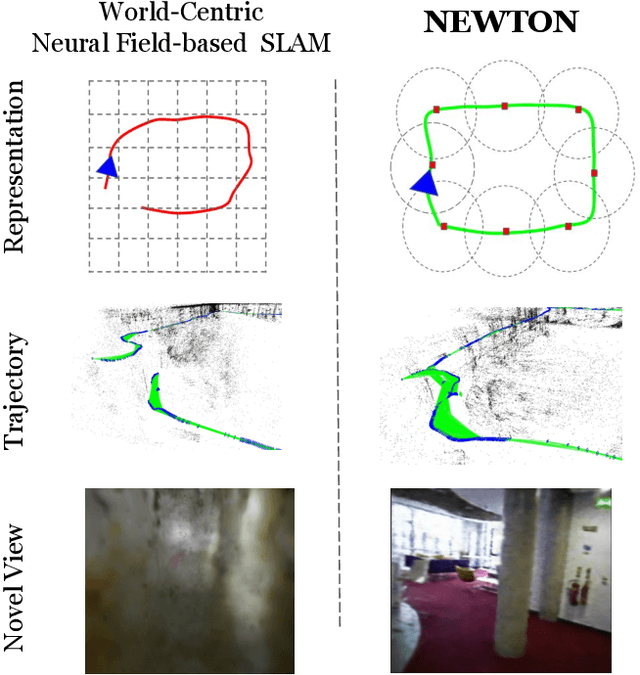
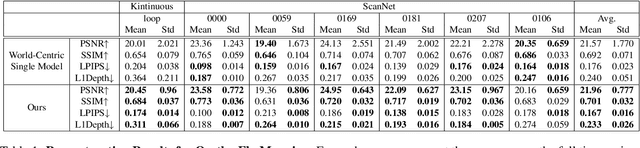
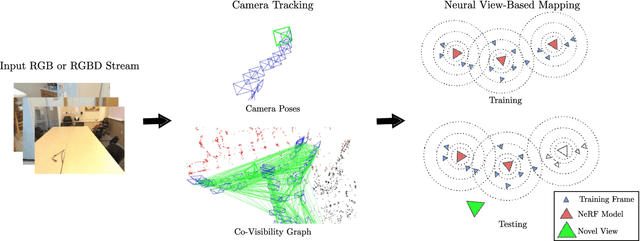
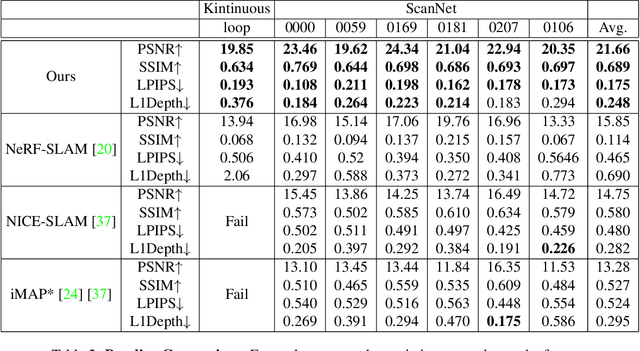
Neural field-based 3D representations have recently been adopted in many areas including SLAM systems. Current neural SLAM or online mapping systems lead to impressive results in the presence of simple captures, but they rely on a world-centric map representation as only a single neural field model is used. To define such a world-centric representation, accurate and static prior information about the scene, such as its boundaries and initial camera poses, are required. However, in real-time and on-the-fly scene capture applications, this prior knowledge cannot be assumed as fixed or static, since it dynamically changes and it is subject to significant updates based on run-time observations. Particularly in the context of large-scale mapping, significant camera pose drift is inevitable, necessitating the correction via loop closure. To overcome this limitation, we propose NEWTON, a view-centric mapping method that dynamically constructs neural fields based on run-time observation. In contrast to prior works, our method enables camera pose updates using loop closures and scene boundary updates by representing the scene with multiple neural fields, where each is defined in a local coordinate system of a selected keyframe. The experimental results demonstrate the superior performance of our method over existing world-centric neural field-based SLAM systems, in particular for large-scale scenes subject to camera pose updates.
DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
Mar 20, 2023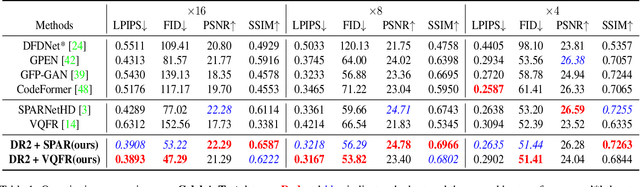
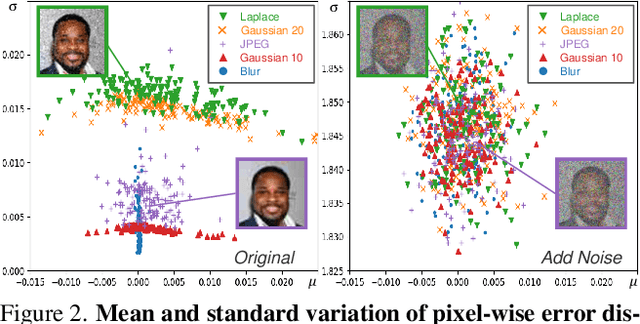
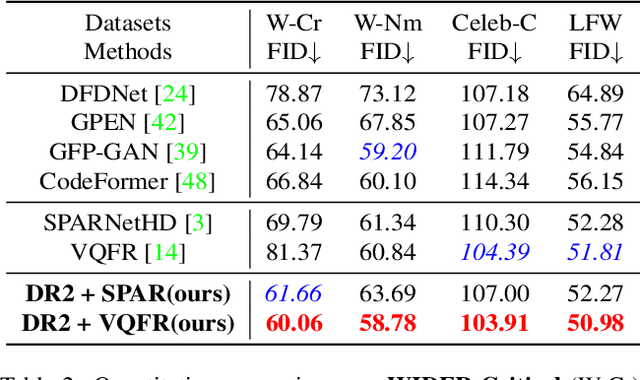
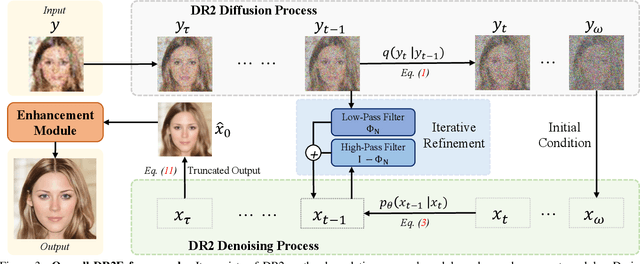
Blind face restoration usually synthesizes degraded low-quality data with a pre-defined degradation model for training, while more complex cases could happen in the real world. This gap between the assumed and actual degradation hurts the restoration performance where artifacts are often observed in the output. However, it is expensive and infeasible to include every type of degradation to cover real-world cases in the training data. To tackle this robustness issue, we propose Diffusion-based Robust Degradation Remover (DR2) to first transform the degraded image to a coarse but degradation-invariant prediction, then employ an enhancement module to restore the coarse prediction to a high-quality image. By leveraging a well-performing denoising diffusion probabilistic model, our DR2 diffuses input images to a noisy status where various types of degradation give way to Gaussian noise, and then captures semantic information through iterative denoising steps. As a result, DR2 is robust against common degradation (e.g. blur, resize, noise and compression) and compatible with different designs of enhancement modules. Experiments in various settings show that our framework outperforms state-of-the-art methods on heavily degraded synthetic and real-world datasets.
Multi-task Transformer with Relation-attention and Type-attention for Named Entity Recognition
Mar 20, 2023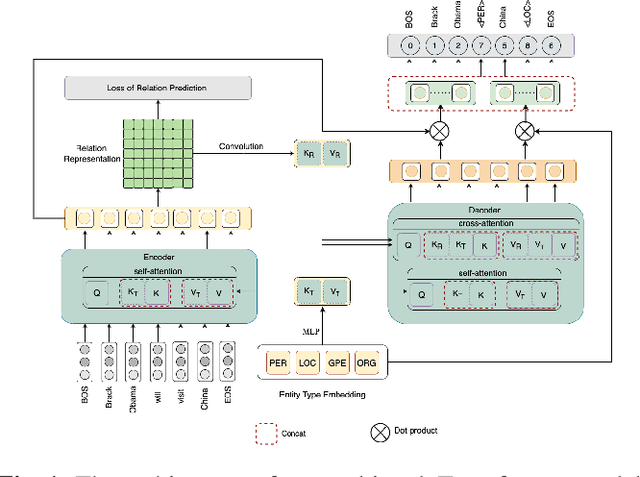
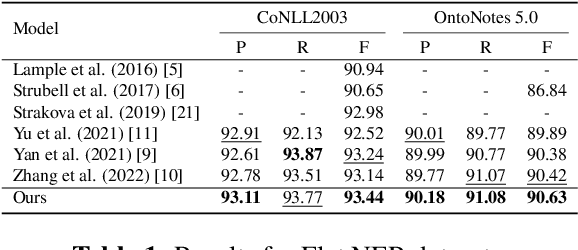
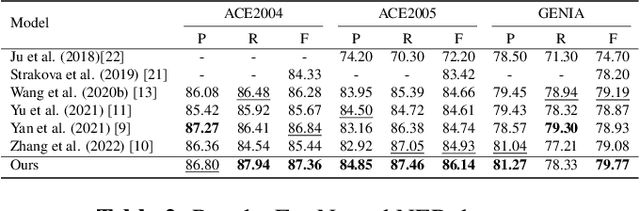
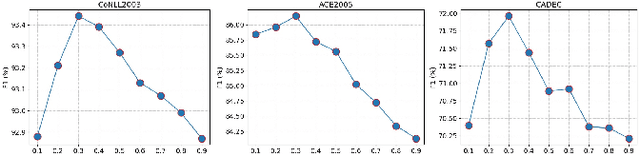
Named entity recognition (NER) is an important research problem in natural language processing. There are three types of NER tasks, including flat, nested and discontinuous entity recognition. Most previous sequential labeling models are task-specific, while recent years have witnessed the rising of generative models due to the advantage of unifying all NER tasks into the seq2seq model framework. Although achieving promising performance, our pilot studies demonstrate that existing generative models are ineffective at detecting entity boundaries and estimating entity types. This paper proposes a multi-task Transformer, which incorporates an entity boundary detection task into the named entity recognition task. More concretely, we achieve entity boundary detection by classifying the relations between tokens within the sentence. To improve the accuracy of entity-type mapping during decoding, we adopt an external knowledge base to calculate the prior entity-type distributions and then incorporate the information into the model via the self and cross-attention mechanisms. We perform experiments on an extensive set of NER benchmarks, including two flat, three nested, and three discontinuous NER datasets. Experimental results show that our approach considerably improves the generative NER model's performance.
Making Sense of Meaning: A Survey on Metrics for Semantic and Goal-Oriented Communication
Mar 20, 2023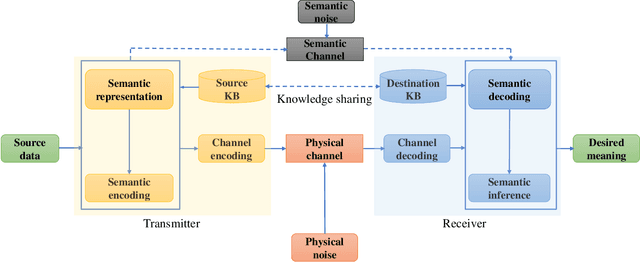
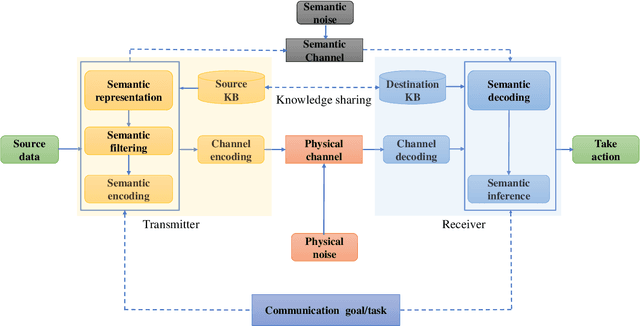
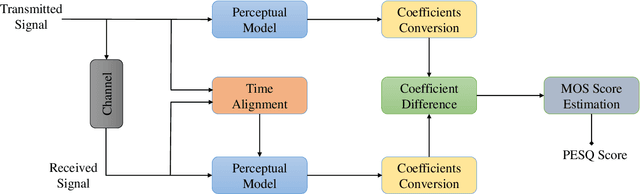
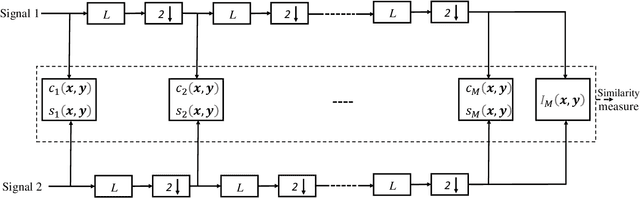
Semantic communication (SemCom) aims to convey the meaning behind a transmitted message by transmitting only semantically-relevant information. This semantic-centric design helps to minimize power usage, bandwidth consumption, and transmission delay. SemCom and goal-oriented SemCom (or effectiveness-level SemCom) are therefore promising enablers of 6G and developing rapidly. Despite the surge in their swift development, the design, analysis, optimization, and realization of robust and intelligent SemCom as well as goal-oriented SemCom are fraught with many fundamental challenges. One of the challenges is that the lack of unified/universal metrics of SemCom and goal-oriented SemCom can stifle research progress on their respective algorithmic, theoretical, and implementation frontiers. Consequently, this survey paper documents the existing metrics -- scattered in many references -- of wireless SemCom, optical SemCom, quantum SemCom, and goal-oriented wireless SemCom. By doing so, this paper aims to inspire the design, analysis, and optimization of a wide variety of SemCom and goal-oriented SemCom systems. This article also stimulates the development of unified/universal performance assessment metrics of SemCom and goal-oriented SemCom, as the existing metrics are purely statistical and hardly applicable to reasoning-type tasks that constitute the heart of 6G and beyond.
Location-Free Scene Graph Generation
Mar 20, 2023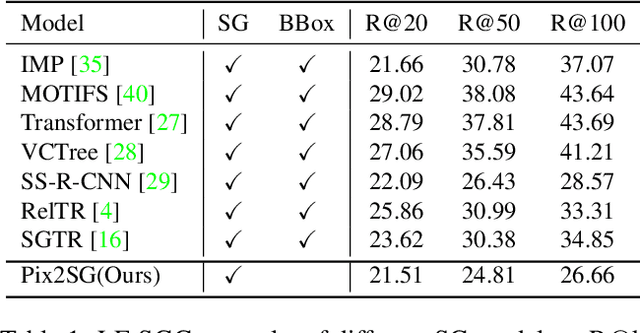
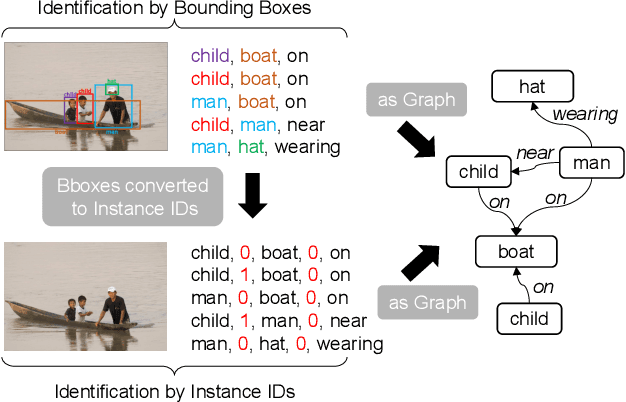
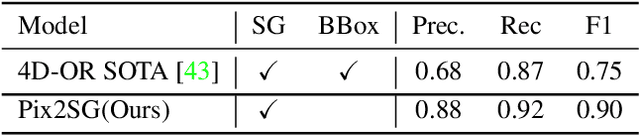
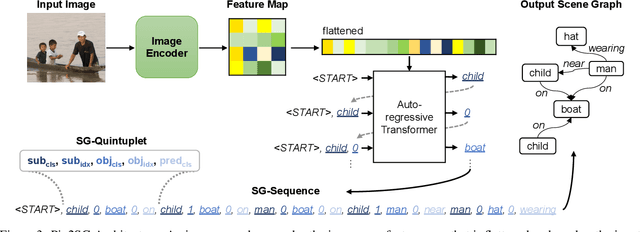
Scene Graph Generation (SGG) is a challenging visual understanding task. It combines the detection of entities and relationships between them in a scene. Both previous works and existing evaluation metrics rely on bounding box labels, even though many downstream scene graph applications do not need location information. The need for localization labels significantly increases the annotation cost and hampers the creation of more and larger scene graph datasets. We suggest breaking the dependency of scene graphs on bounding box labels by proposing location-free scene graph generation (LF-SGG). This new task aims at predicting instances of entities, as well as their relationships, without spatial localization. To objectively evaluate the task, the predicted and ground truth scene graphs need to be compared. We solve this NP-hard problem through an efficient algorithm using branching. Additionally, we design the first LF-SGG method, Pix2SG, using autoregressive sequence modeling. Our proposed method is evaluated on Visual Genome and 4D-OR. Although using significantly fewer labels during training, we achieve 74.12\% of the location-supervised SOTA performance on Visual Genome and even outperform the best method on 4D-OR.
Polynomial Implicit Neural Representations For Large Diverse Datasets
Mar 20, 2023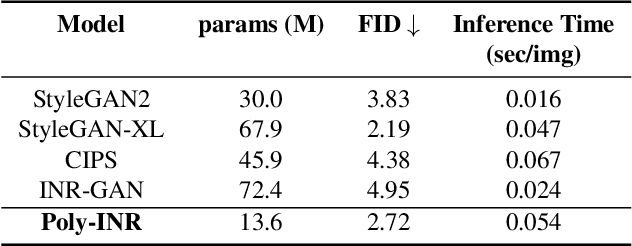
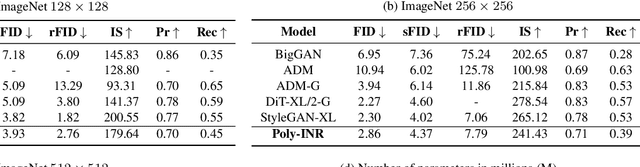
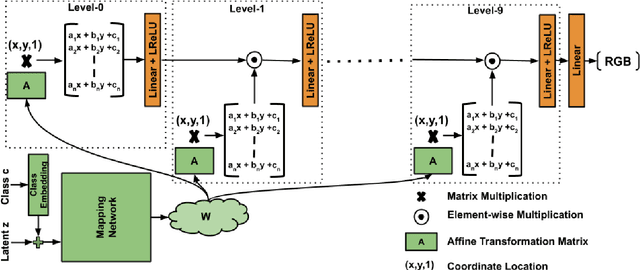
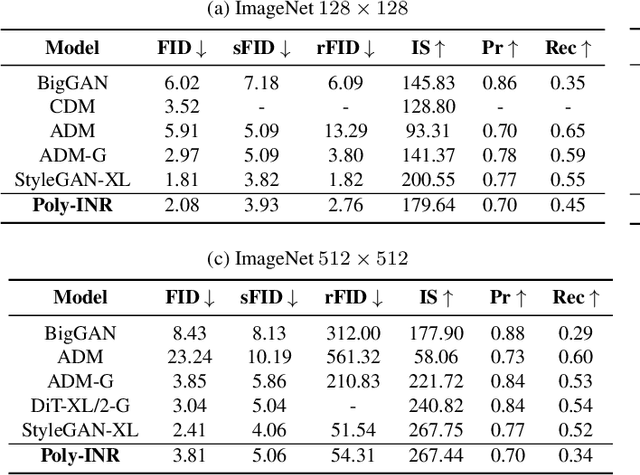
Implicit neural representations (INR) have gained significant popularity for signal and image representation for many end-tasks, such as superresolution, 3D modeling, and more. Most INR architectures rely on sinusoidal positional encoding, which accounts for high-frequency information in data. However, the finite encoding size restricts the model's representational power. Higher representational power is needed to go from representing a single given image to representing large and diverse datasets. Our approach addresses this gap by representing an image with a polynomial function and eliminates the need for positional encodings. Therefore, to achieve a progressively higher degree of polynomial representation, we use element-wise multiplications between features and affine-transformed coordinate locations after every ReLU layer. The proposed method is evaluated qualitatively and quantitatively on large datasets like ImageNet. The proposed Poly-INR model performs comparably to state-of-the-art generative models without any convolution, normalization, or self-attention layers, and with far fewer trainable parameters. With much fewer training parameters and higher representative power, our approach paves the way for broader adoption of INR models for generative modeling tasks in complex domains. The code is available at \url{https://github.com/Rajhans0/Poly_INR}