 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two-level Graph Network for Few-Shot Class-Incremental Learning
Mar 24, 2023
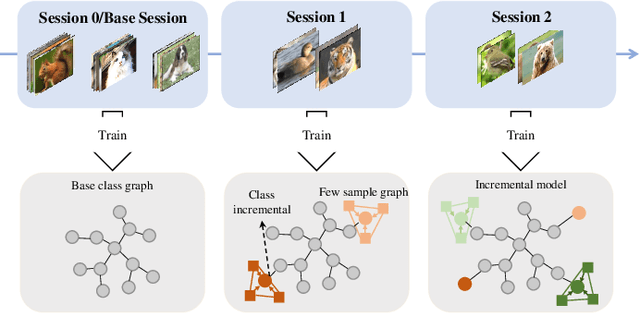
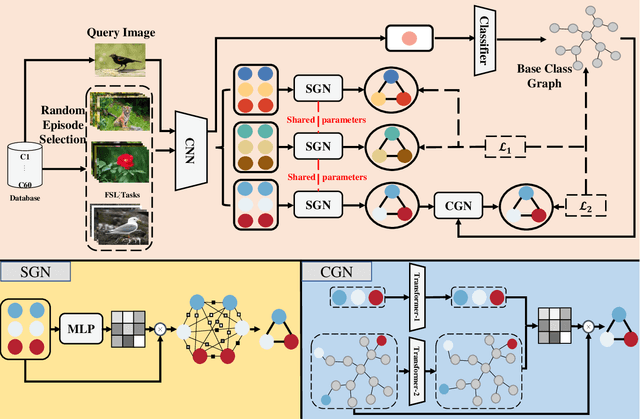
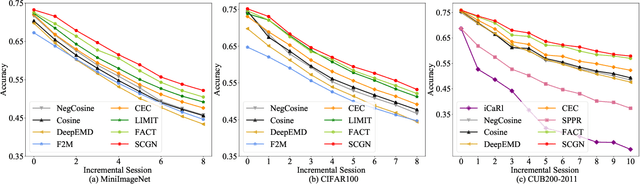
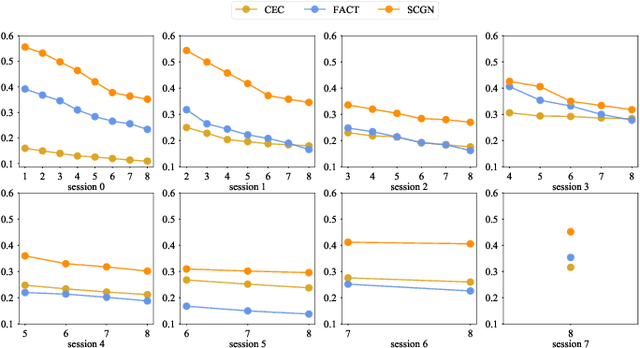
Few-shot class-incremental learning (FSCIL) aims to design machine learning algorithms that can continually learn new concepts from a few data points, without forgetting knowledge of old classes. The difficulty lies in that limited data from new classes not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. However, existing FSCIL methods ignore the semantic relationships between sample-level and class-level. % Using the advantage that graph neural network (GNN) can mine rich information among few samples, In this paper, we designed a two-level graph network for FSCIL named Sample-level and Class-level Graph Neural Network (SCGN). Specifically, a pseudo incremental learning paradigm is designed in SCGN, which synthesizes virtual few-shot tasks as new tasks to optimize SCGN model parameters in advance. Sample-level graph network uses the relationship of a few samples to aggregate similar samples and obtains refined class-level features. Class-level graph network aims to mitigate the semantic conflict between prototype features of new classes and old classes. SCGN builds two-level graph networks to guarantee the latent semantic of each few-shot class can be effectively represented in FSCIL. Experiments on three popular benchmark datasets show that our method significantly outperforms the baselines and sets new state-of-the-art results with remarkable advantages.
Voice-Based Conversational Agents and Knowledge Graphs for Improving News Search in Assisted Living
Mar 24, 2023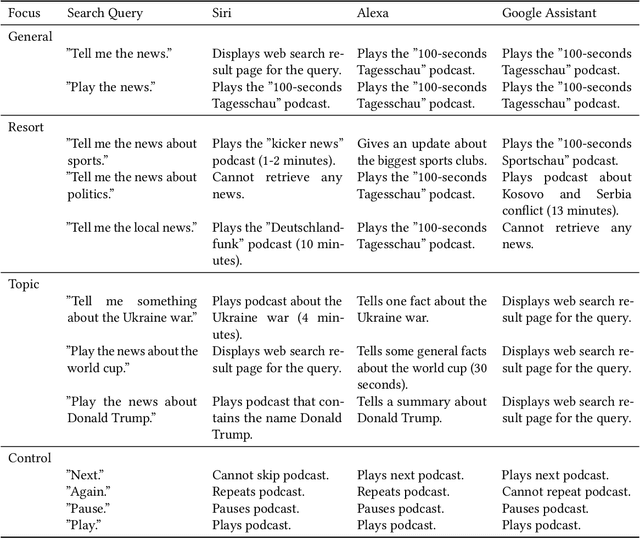
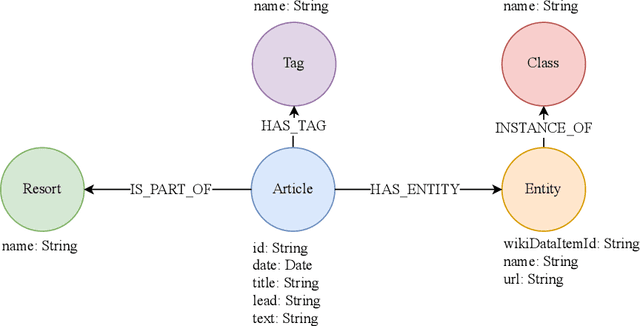
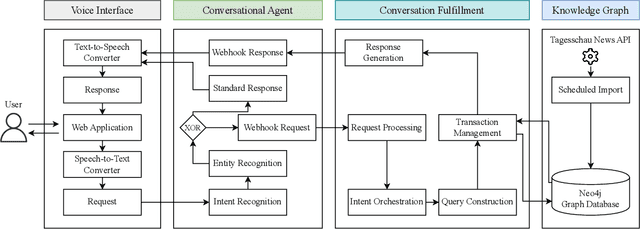
As the healthcare sector is facing major challenges, such as aging populations, staff shortages, and common chronic diseases, delivering high-quality care to individuals has become very difficult. Conversational agents have shown to be a promising technology to alleviate some of these issues. In the form of digital health assistants, they have the potential to improve the everyday life of the elderly and chronically ill people. This includes, for example, medication reminders, routine checks, or social chit-chat. In addition, conversational agents can satisfy the fundamental need of having access to information about daily news or local events, which enables individuals to stay informed and connected with the world around them. However, finding relevant news sources and navigating the plethora of news articles available online can be overwhelming, particularly for those who may have limited technological literacy or health-related impairments. To address this challenge, we propose an innovative solution that combines knowledge graphs and conversational agents for news search in assisted living. By leveraging graph databases to semantically structure news data and implementing an intuitive voice-based interface, our system can help care-dependent people to easily discover relevant news articles and give personalized recommendations. We explain our design choices, provide a system architecture, share insights of an initial user test, and give an outlook on planned future work.
Natural language processing to automatically extract the presence and severity of esophagitis in notes of patients undergoing radiotherapy
Mar 24, 2023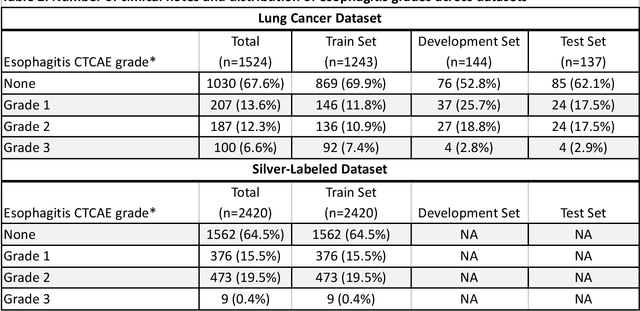
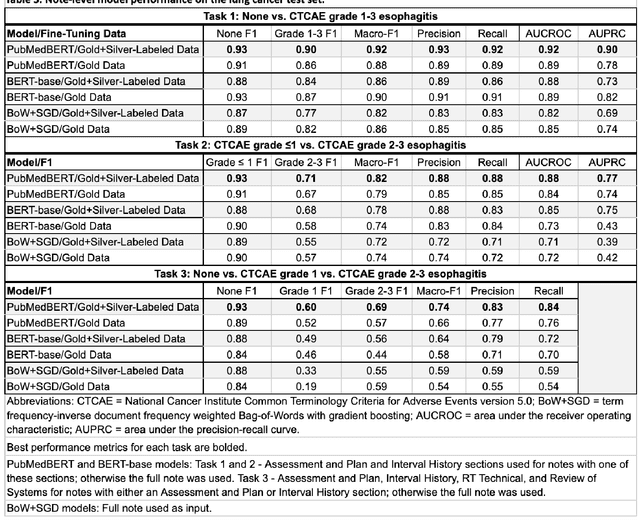

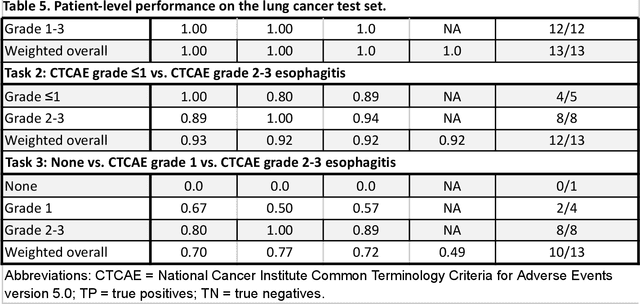
Radiotherapy (RT) toxicities can impair survival and quality-of-life, yet remain under-studied. Real-world evidence holds potential to improve our understanding of toxicities, but toxicity information is often only in clinical notes. We developed natural language processing (NLP) models to identify the presence and severity of esophagitis from notes of patients treated with thoracic RT. We fine-tuned statistical and pre-trained BERT-based models for three esophagitis classification tasks: Task 1) presence of esophagitis, Task 2) severe esophagitis or not, and Task 3) no esophagitis vs. grade 1 vs. grade 2-3. Transferability was tested on 345 notes from patients with esophageal cancer undergoing RT. Fine-tuning PubmedBERT yielded the best performance. The best macro-F1 was 0.92, 0.82, and 0.74 for Task 1, 2, and 3, respectively. Selecting the most informative note sections during fine-tuning improved macro-F1 by over 2% for all tasks. Silver-labeled data improved the macro-F1 by over 3% across all tasks. For the esophageal cancer notes, the best macro-F1 was 0.73, 0.74, and 0.65 for Task 1, 2, and 3, respectively, without additional fine-tuning. To our knowledge, this is the first effort to automatically extract esophagitis toxicity severity according to CTCAE guidelines from clinic notes. The promising performance provides proof-of-concept for NLP-based automated detailed toxicity monitoring in expanded domains.
OCELOT: Overlapped Cell on Tissue Dataset for Histopathology
Mar 24, 2023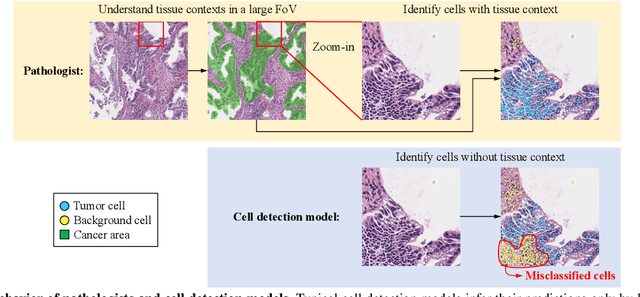

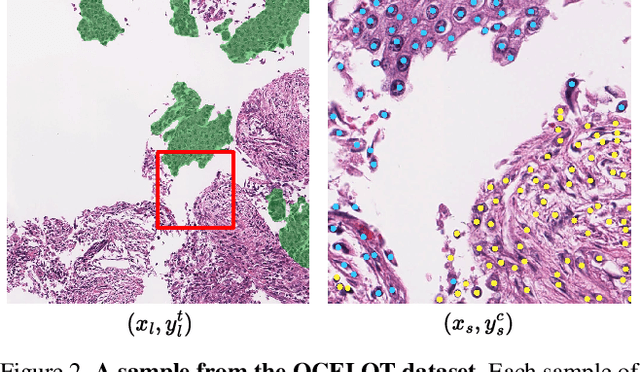
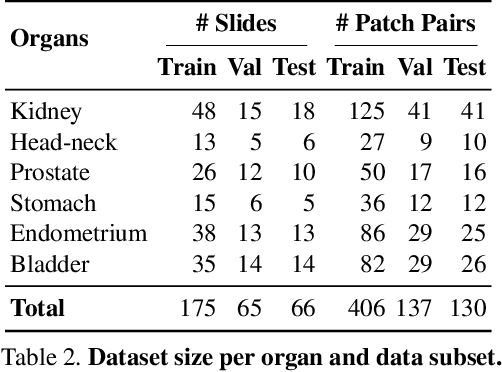
Cell detection is a fundamental task in computational pathology that can be used for extracting high-level medical information from whole-slide images. For accurate cell detection, pathologists often zoom out to understand the tissue-level structures and zoom in to classify cells based on their morphology and the surrounding context. However, there is a lack of efforts to reflect such behaviors by pathologists in the cell detection models, mainly due to the lack of datasets containing both cell and tissue annotations with overlapping regions. To overcome this limitation, we propose and publicly release OCELOT, a dataset purposely dedicated to the study of cell-tissue relationships for cell detection in histopathology. OCELOT provides overlapping cell and tissue annotations on images acquired from multiple organs. Within this setting, we also propose multi-task learning approaches that benefit from learning both cell and tissue tasks simultaneously. When compared against a model trained only for the cell detection task, our proposed approaches improve cell detection performance on 3 datasets: proposed OCELOT, public TIGER, and internal CARP datasets. On the OCELOT test set in particular, we show up to 6.79 improvement in F1-score. We believe the contributions of this paper, including the release of the OCELOT dataset at https://lunit-io.github.io/research/publications/ocelot are a crucial starting point toward the important research direction of incorporating cell-tissue relationships in computation pathology.
Curricular Contrastive Regularization for Physics-aware Single Image Dehazing
Mar 24, 2023
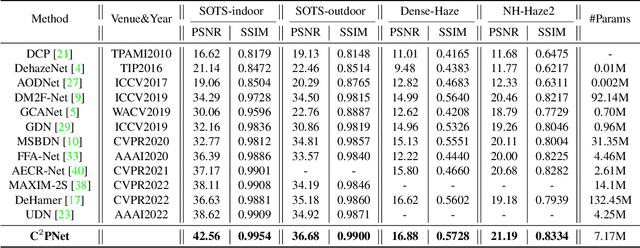
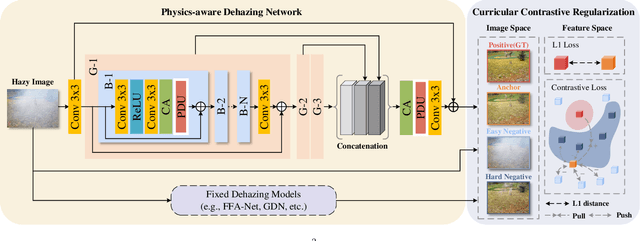

Considering the ill-posed nature, contrastive regularization has been developed for single image dehazing, introducing the information from negative images as a lower bound. However, the contrastive samples are nonconsensual, as the negatives are usually represented distantly from the clear (i.e., positive) image, leaving the solution space still under-constricted. Moreover, the interpretability of deep dehazing models is underexplored towards the physics of the hazing process. In this paper, we propose a novel curricular contrastive regularization targeted at a consensual contrastive space as opposed to a non-consensual one. Our negatives, which provide better lower-bound constraints, can be assembled from 1) the hazy image, and 2) corresponding restorations by other existing methods. Further, due to the different similarities between the embeddings of the clear image and negatives, the learning difficulty of the multiple components is intrinsically imbalanced. To tackle this issue, we customize a curriculum learning strategy to reweight the importance of different negatives. In addition, to improve the interpretability in the feature space, we build a physics-aware dual-branch unit according to the atmospheric scattering model. With the unit, as well as curricular contrastive regularization, we establish our dehazing network, named C2PNet. Extensive experiments demonstrate that our C2PNet significantly outperforms state-of-the-art methods, with extreme PSNR boosts of 3.94dB and 1.50dB, respectively, on SOTS-indoor and SOTS-outdoor datasets.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023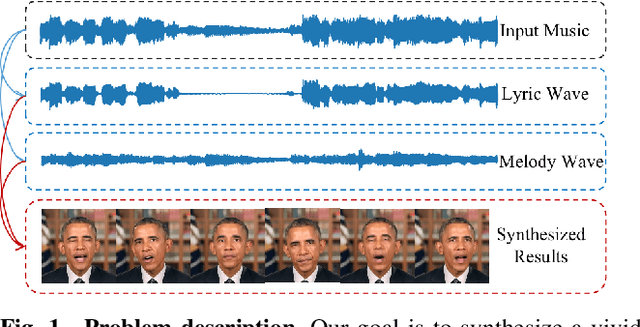
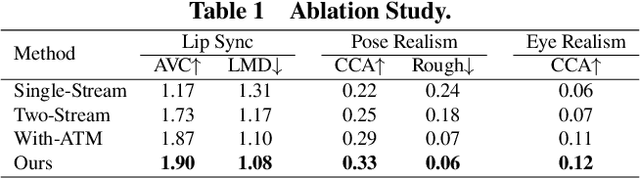
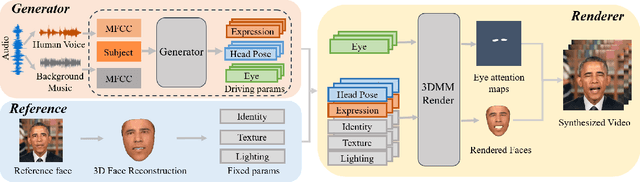

It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
Automated Self-Supervised Learning for Recommendation
Mar 21, 2023

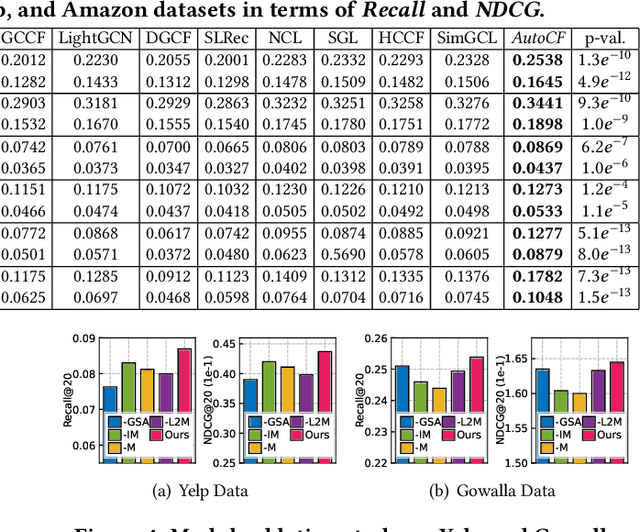
Graph neural networks (GNNs) have emerged as the state-of-the-art paradigm for collaborative filtering (CF). To improve the representation quality over limited labeled data, contrastive learning has attracted attention in recommendation and benefited graph-based CF model recently. However, the success of most contrastive methods heavily relies on manually generating effective contrastive views for heuristic-based data augmentation. This does not generalize across different datasets and downstream recommendation tasks, which is difficult to be adaptive for data augmentation and robust to noise perturbation. To fill this crucial gap, this work proposes a unified Automated Collaborative Filtering (AutoCF) to automatically perform data augmentation for recommendation. Specifically, we focus on the generative self-supervised learning framework with a learnable augmentation paradigm that benefits the automated distillation of important self-supervised signals. To enhance the representation discrimination ability, our masked graph autoencoder is designed to aggregate global information during the augmentation via reconstructing the masked subgraph structures. Experiments and ablation studies are performed on several public datasets for recommending products, venues, and locations. Results demonstrate the superiority of AutoCF against various baseline methods. We release the model implementation at https://github.com/HKUDS/AutoCF.
Affordance Diffusion: Synthesizing Hand-Object Interactions
Mar 21, 2023
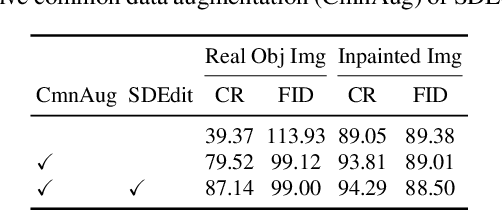

Recent successes in image synthesis are powered by large-scale diffusion models. However, most methods are currently limited to either text- or image-conditioned generation for synthesizing an entire image, texture transfer or inserting objects into a user-specified region. In contrast, in this work we focus on synthesizing complex interactions (ie, an articulated hand) with a given object. Given an RGB image of an object, we aim to hallucinate plausible images of a human hand interacting with it. We propose a two-step generative approach: a LayoutNet that samples an articulation-agnostic hand-object-interaction layout, and a ContentNet that synthesizes images of a hand grasping the object given the predicted layout. Both are built on top of a large-scale pretrained diffusion model to make use of its latent representation. Compared to baselines, the proposed method is shown to generalize better to novel objects and perform surprisingly well on out-of-distribution in-the-wild scenes of portable-sized objects. The resulting system allows us to predict descriptive affordance information, such as hand articulation and approaching orientation. Project page: https://judyye.github.io/affordiffusion-www
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023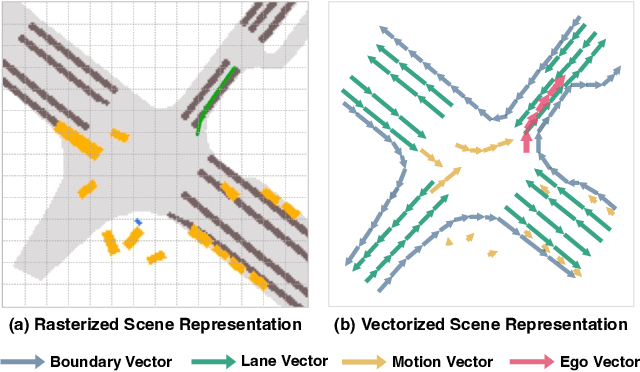
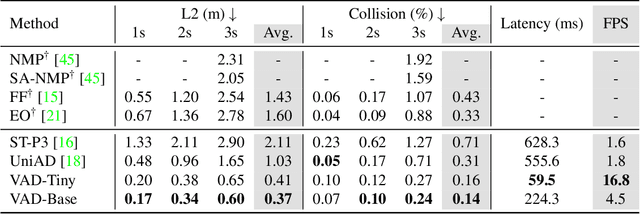
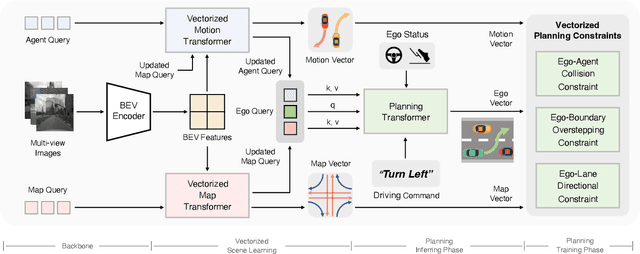
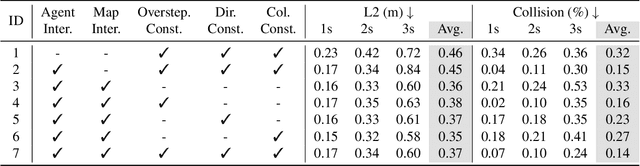
Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Community detection in complex networks via node similarity, graph representation learning, and hierarchical clustering
Mar 21, 2023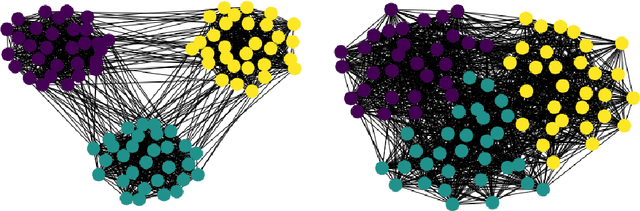
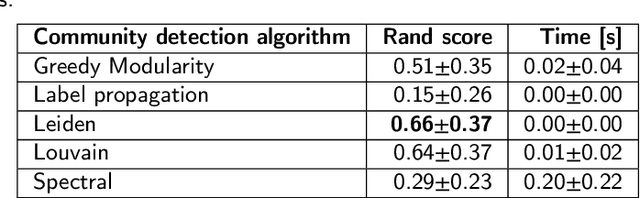
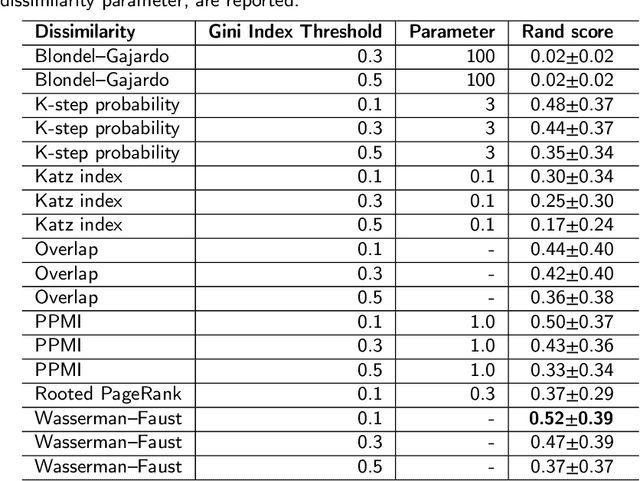
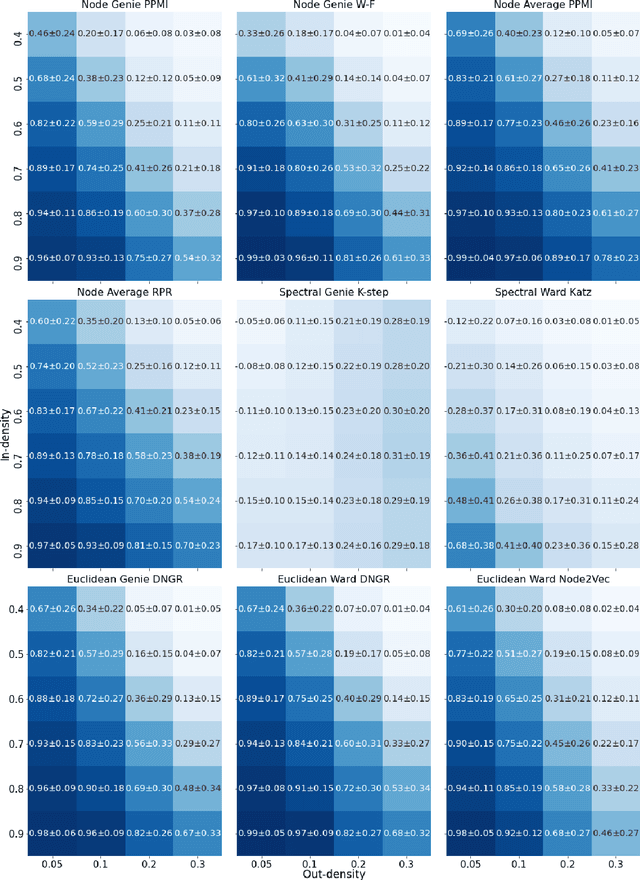
Community detection is a critical challenge in the analysis of real-world graphs and complex networks, including social, transportation, citation, cybersecurity networks, and food webs. Motivated by many similarities between community detection and clustering in Euclidean spaces, we propose three algorithm frameworks to apply hierarchical clustering methods for community detection in graphs. We show that using our methods, it is possible to apply various linkage-based (single-, complete-, average- linkage, Ward, Genie) clustering algorithms to find communities based on vertex similarity matrices, eigenvector matrices thereof, and Euclidean vector representations of nodes. We convey a comprehensive analysis of choices for each framework, including state-of-the-art graph representation learning algorithms, such as Deep Neural Graph Representation, and a vertex proximity matrix known to yield high-quality results in machine learning -- Positive Pointwise Mutual Information. Overall, we test over a hundred combinations of framework components and show that some -- including Wasserman-Faust and PPMI proximity, DNGR representation -- can compete with algorithms such as state-of-the-art Leiden and Louvain and easily outperform other known community detection algorithms. Notably, our algorithms remain hierarchical and allow the user to specify any number of clusters a priori.