 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real-time Multi-Object Tracking Based on Bi-directional Matching
Mar 15, 2023
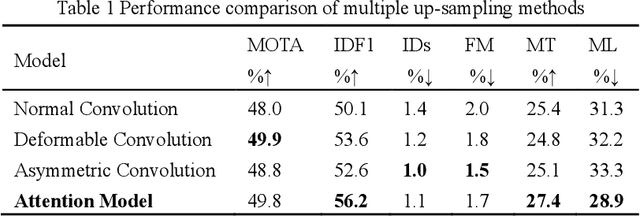
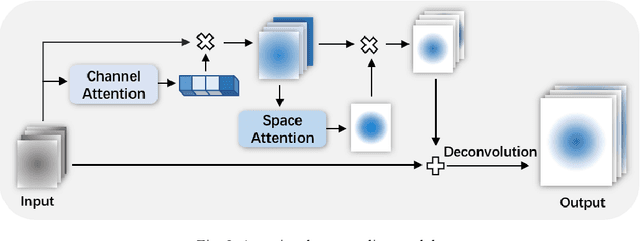
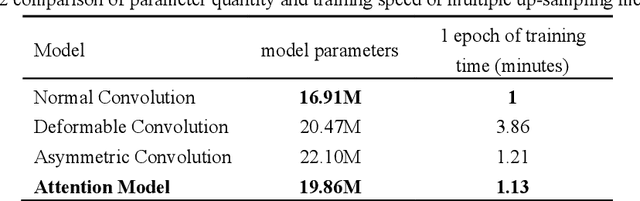

In recent years, anchor-free object detection models combined with matching algorithms are used to achieve real-time muti-object tracking and also ensure high tracking accuracy. However, there are still great challenges in multi-object tracking. For example, when most part of a target is occluded or the target just disappears from images temporarily, it often leads to tracking interruptions for most of the existing tracking algorithms. Therefore, this study offers a bi-directional matching algorithm for multi-object tracking that makes advantage of bi-directional motion prediction information to improve occlusion handling. A stranded area is used in the matching algorithm to temporarily store the objects that fail to be tracked. When objects recover from occlusions, our method will first try to match them with objects in the stranded area to avoid erroneously generating new identities, thus forming a more continuous trajectory. Experiments show that our approach can improve the multi-object tracking performance in the presence of occlusions. In addition, this study provides an attentional up-sampling module that not only assures tracking accuracy but also accelerates training speed. In the MOT17 challenge, the proposed algorithm achieves 63.4% MOTA, 55.3% IDF1, and 20.1 FPS tracking speed.
Learning Accurate Template Matching with Differentiable Coarse-to-Fine Correspondence Refinement
Mar 15, 2023Template matching is a fundamental task in computer vision and has been studied for decades. It plays an essential role in manufacturing industry for estimating the poses of different parts, facilitating downstream tasks such as robotic grasping. Existing methods fail when the template and source images have different modalities, cluttered backgrounds or weak textures. They also rarely consider geometric transformations via homographies, which commonly exist even for planar industrial parts. To tackle the challenges, we propose an accurate template matching method based on differentiable coarse-to-fine correspondence refinement. We use an edge-aware module to overcome the domain gap between the mask template and the grayscale image, allowing robust matching. An initial warp is estimated using coarse correspondences based on novel structure-aware information provided by transformers. This initial alignment is passed to a refinement network using references and aligned images to obtain sub-pixel level correspondences which are used to give the final geometric transformation. Extensive evaluation shows that our method is significantly better than state-of-the-art methods and baselines, providing good generalization ability and visually plausible results even on unseen real data.
Interference-Aware Constellation Design for Z-Interference Channels with Imperfect CSI
Mar 15, 2023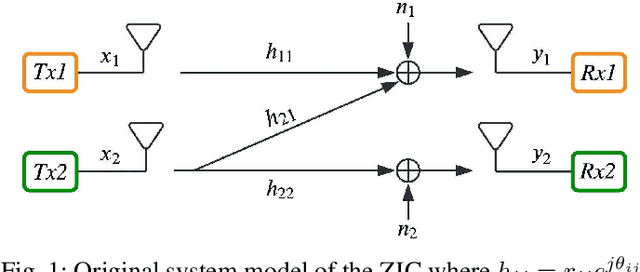
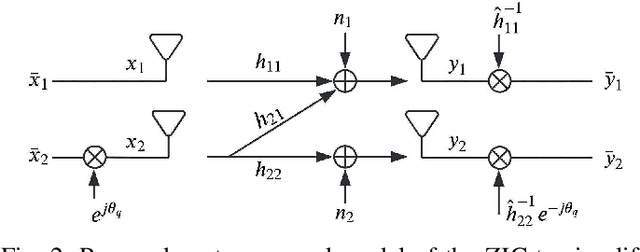
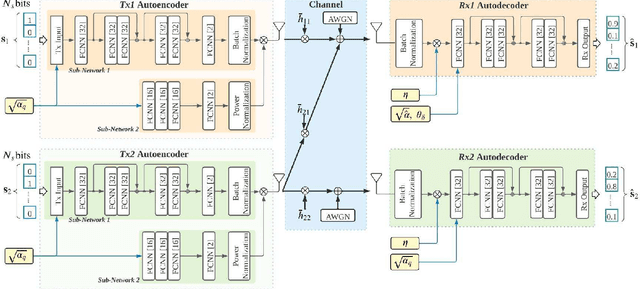
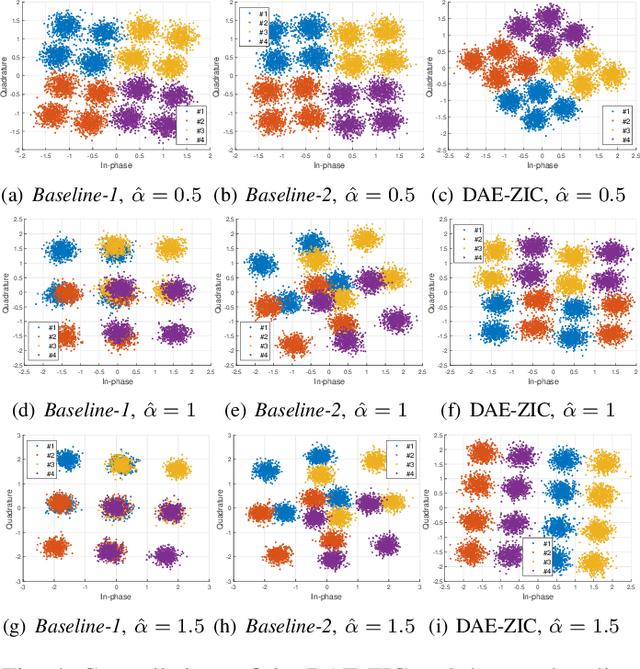
A deep autoencoder (DAE)-based end-to-end communication over the two-user Z-interference channel (ZIC) with finite-alphabet inputs is designed in this paper. The design is for imperfect channel state information (CSI) where both estimation and quantization errors exist. The proposed structure jointly optimizes the encoders and decoders to generate interferenceaware constellations that adapt their shape to the interference intensity in order to minimize the bit error rate. A normalization layer is designed to guarantee an average power constraint in the DAE while allowing the architecture to generate constellations with nonuniform shapes. This brings further shaping gain compared to standard uniform constellations such as quadrature amplitude modulation. The performance of the DAE-ZIC is compared with two conventional methods, i.e., standard and rotated constellations. The proposed structure significantly enhances the performance of the ZIC. Simulation results confirm bit error rate reduction in all interference regimes (weak, moderate, and strong). At a signal-to-noise ratio of 20dB, the improvements reach about two orders of magnitude when only quantization error exists, indicating that the DAE-ZIC is highly robust to the interference compared to the conventional methods.
Lane Graph as Path: Continuity-preserving Path-wise Modeling for Online Lane Graph Construction
Mar 15, 2023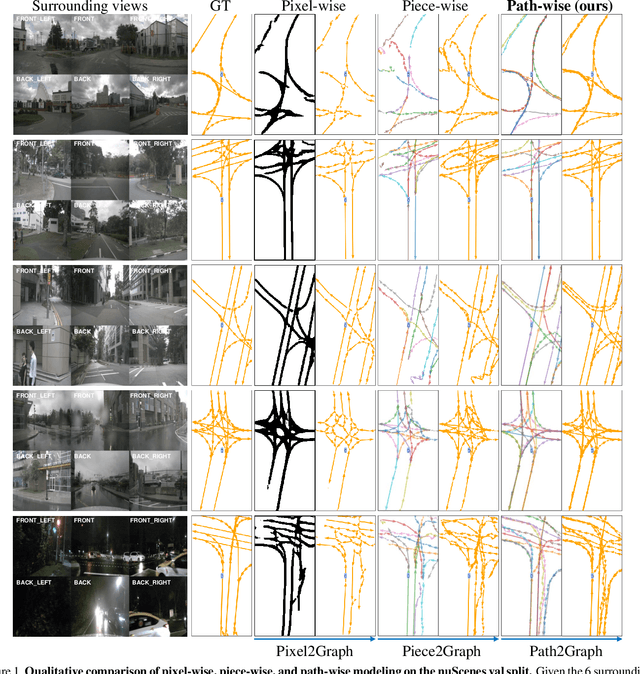
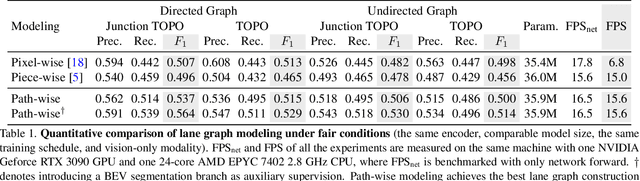
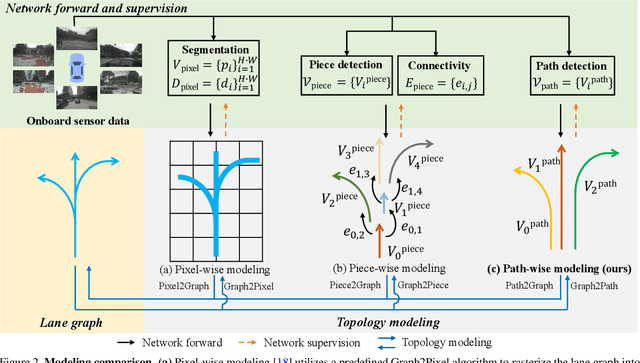
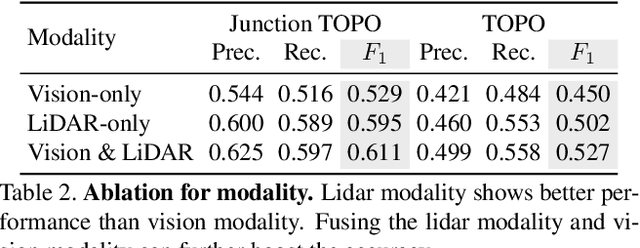
Online lane graph construction is a promising but challenging task in autonomous driving. Previous methods usually model the lane graph at the pixel or piece level, and recover the lane graph by pixel-wise or piece-wise connection, which breaks down the continuity of the lane. Human drivers focus on and drive along the continuous and complete paths instead of considering lane pieces. Autonomous vehicles also require path-specific guidance from lane graph for trajectory planning. We argue that the path, which indicates the traffic flow, is the primitive of the lane graph. Motivated by this, we propose to model the lane graph in a novel path-wise manner, which well preserves the continuity of the lane and encodes traffic information for planning. We present a path-based online lane graph construction method, termed LaneGAP, which end-to-end learns the path and recovers the lane graph via a Path2Graph algorithm. We qualitatively and quantitatively demonstrate the superiority of LaneGAP over conventional pixel-based and piece-based methods. Abundant visualizations show LaneGAP can cope with diverse traffic conditions. Code and models will be released at \url{https://github.com/hustvl/LaneGAP} for facilitating future research.
Pixel-Level Explanation of Multiple Instance Learning Models in Biomedical Single Cell Images
Mar 15, 2023

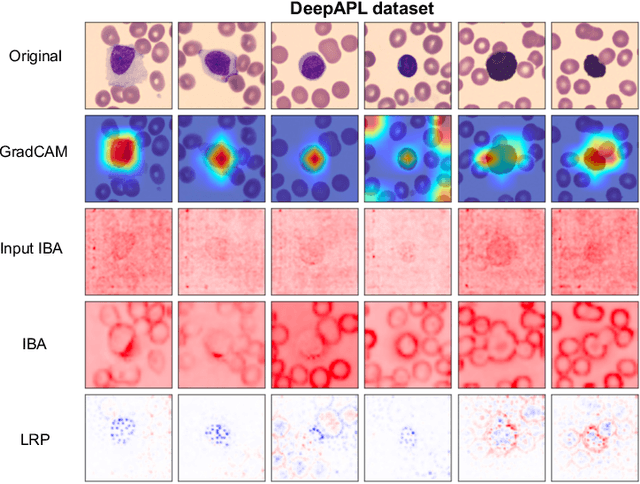
Explainability is a key requirement for computer-aided diagnosis systems in clinical decision-making. Multiple instance learning with attention pooling provides instance-level explainability, however for many clinical applications a deeper, pixel-level explanation is desirable, but missing so far. In this work, we investigate the use of four attribution methods to explain a multiple instance learning models: GradCAM, Layer-Wise Relevance Propagation (LRP), Information Bottleneck Attribution (IBA), and InputIBA. With this collection of methods, we can derive pixel-level explanations on for the task of diagnosing blood cancer from patients' blood smears. We study two datasets of acute myeloid leukemia with over 100 000 single cell images and observe how each attribution method performs on the multiple instance learning architecture focusing on different properties of the white blood single cells. Additionally, we compare attribution maps with the annotations of a medical expert to see how the model's decision-making differs from the human standard. Our study addresses the challenge of implementing pixel-level explainability in multiple instance learning models and provides insights for clinicians to better understand and trust decisions from computer-aided diagnosis systems.
DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
Mar 15, 2023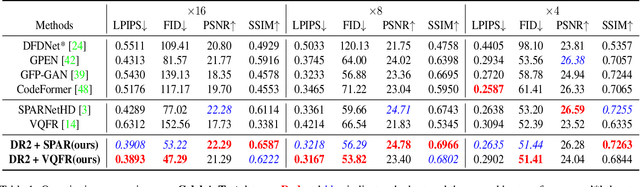
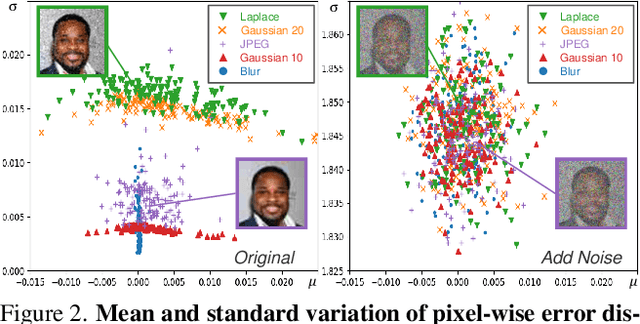
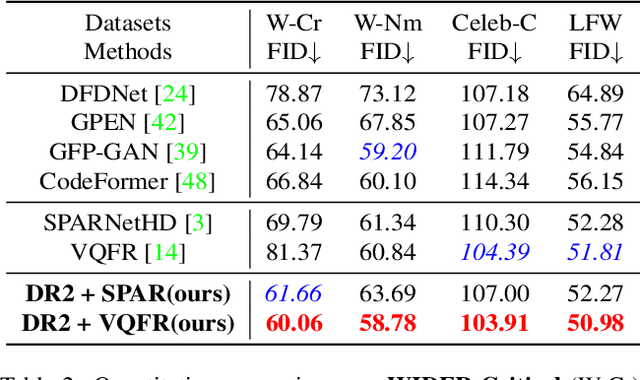
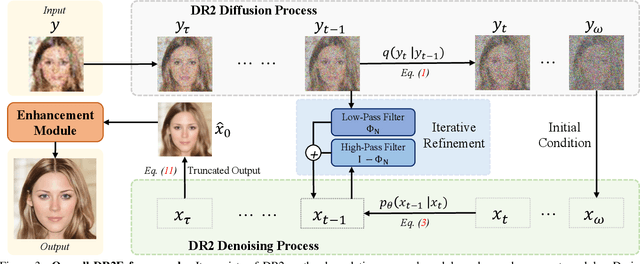
Blind face restoration usually synthesizes degraded low-quality data with a pre-defined degradation model for training, while more complex cases could happen in the real world. This gap between the assumed and actual degradation hurts the restoration performance where artifacts are often observed in the output. However, it is expensive and infeasible to include every type of degradation to cover real-world cases in the training data. To tackle this robustness issue, we propose Diffusion-based Robust Degradation Remover (DR2) to first transform the degraded image to a coarse but degradation-invariant prediction, then employ an enhancement module to restore the coarse prediction to a high-quality image. By leveraging a well-performing denoising diffusion probabilistic model, our DR2 diffuses input images to a noisy status where various types of degradation give way to Gaussian noise, and then captures semantic information through iterative denoising steps. As a result, DR2 is robust against common degradation (e.g. blur, resize, noise and compression) and compatible with different designs of enhancement modules. Experiments in various settings show that our framework outperforms state-of-the-art methods on heavily degraded synthetic and real-world datasets.
Crowd Counting with Online Knowledge Learning
Mar 18, 2023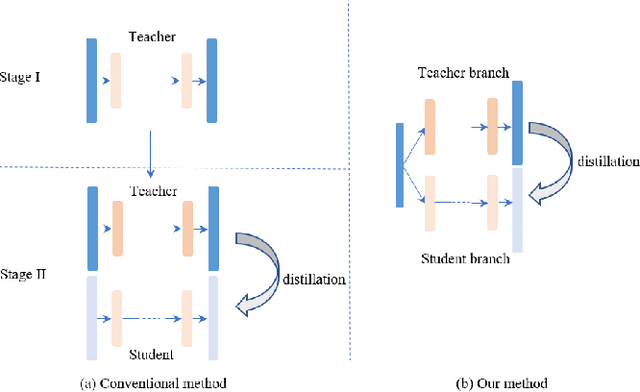
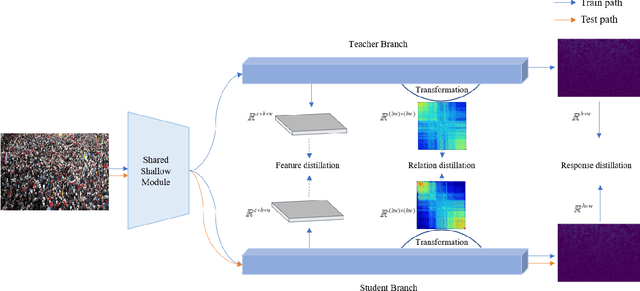

Efficient crowd counting models are urgently required for the applications in scenarios with limited computing resources, such as edge computing and mobile devices. A straightforward method to achieve this is knowledge distillation (KD), which involves using a trained teacher network to guide the training of a student network. However, this traditional two-phase training method can be time-consuming, particularly for large datasets, and it is also challenging for the student network to mimic the learning process of the teacher network. To overcome these challenges, we propose an online knowledge learning method for crowd counting. Our method builds an end-to-end training framework that integrates two independent networks into a single architecture, which consists of a shared shallow module, a teacher branch, and a student branch. This approach is more efficient than the two-stage training technique of traditional KD. Moreover, we propose a feature relation distillation method which allows the student branch to more effectively comprehend the evolution of inter-layer features by constructing a new inter-layer relationship matrix. It is combined with response distillation and feature internal distillation to enhance the transfer of mutually complementary information from the teacher branch to the student branch. Extensive experiments on four challenging crowd counting datasets demonstrate the effectiveness of our method which achieves comparable performance to state-of-the-art methods despite using far fewer parameters.
Scope of Pre-trained Language Models for Detecting Conflicting Health Information
Sep 22, 2022

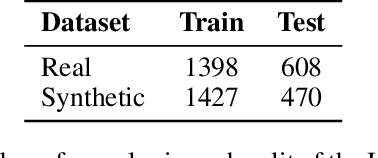

An increasing number of people now rely on online platforms to meet their health information needs. Thus identifying inconsistent or conflicting textual health information has become a safety-critical task. Health advice data poses a unique challenge where information that is accurate in the context of one diagnosis can be conflicting in the context of another. For example, people suffering from diabetes and hypertension often receive conflicting health advice on diet. This motivates the need for technologies which can provide contextualized, user-specific health advice. A crucial step towards contextualized advice is the ability to compare health advice statements and detect if and how they are conflicting. This is the task of health conflict detection (HCD). Given two pieces of health advice, the goal of HCD is to detect and categorize the type of conflict. It is a challenging task, as (i) automatically identifying and categorizing conflicts requires a deeper understanding of the semantics of the text, and (ii) the amount of available data is quite limited. In this study, we are the first to explore HCD in the context of pre-trained language models. We find that DeBERTa-v3 performs best with a mean F1 score of 0.68 across all experiments. We additionally investigate the challenges posed by different conflict types and how synthetic data improves a model's understanding of conflict-specific semantics. Finally, we highlight the difficulty in collecting real health conflicts and propose a human-in-the-loop synthetic data augmentation approach to expand existing HCD datasets. Our HCD training dataset is over 2x bigger than the existing HCD dataset and is made publicly available on Github.
Transductive Matrix Completion with Calibration for Multi-Task Learning
Feb 20, 2023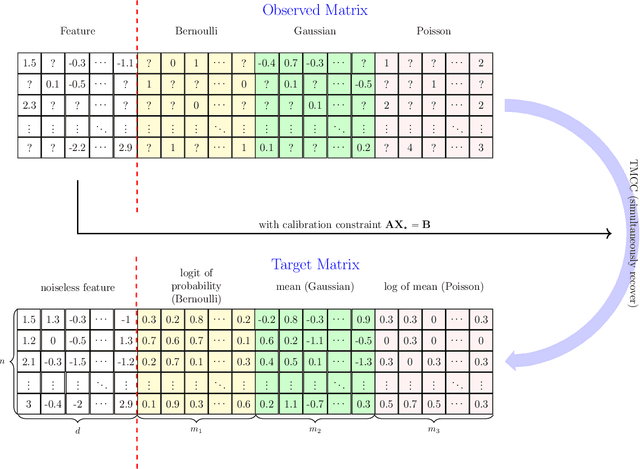
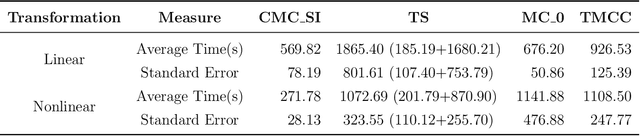
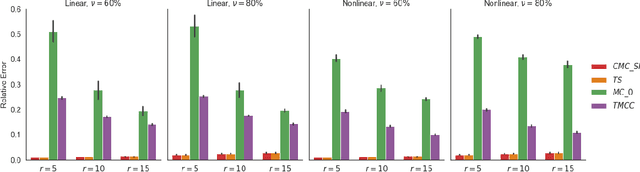
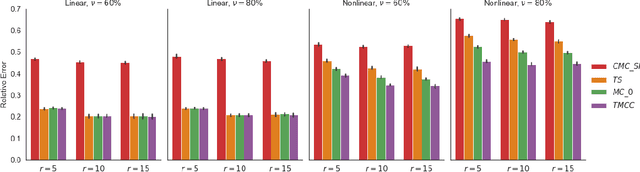
Multi-task learning has attracted much attention due to growing multi-purpose research with multiple related data sources. Moreover, transduction with matrix completion is a useful method in multi-label learning. In this paper, we propose a transductive matrix completion algorithm that incorporates a calibration constraint for the features under the multi-task learning framework. The proposed algorithm recovers the incomplete feature matrix and target matrix simultaneously. Fortunately, the calibration information improves the completion results. In particular, we provide a statistical guarantee for the proposed algorithm, and the theoretical improvement induced by calibration information is also studied. Moreover, the proposed algorithm enjoys a sub-linear convergence rate. Several synthetic data experiments are conducted, which show the proposed algorithm out-performs other existing methods, especially when the target matrix is associated with the feature matrix in a nonlinear way.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023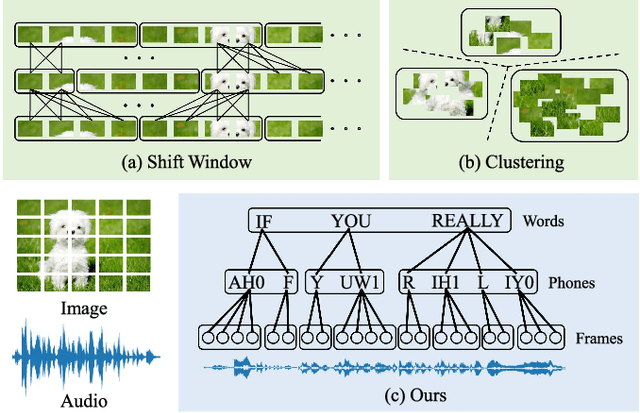
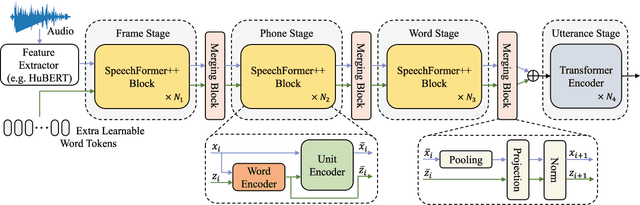
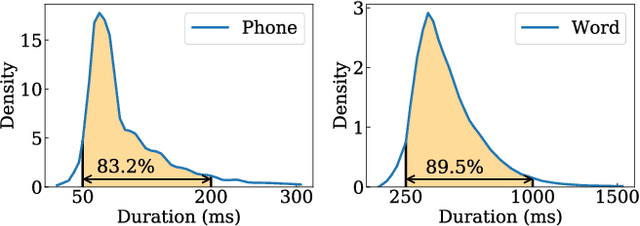
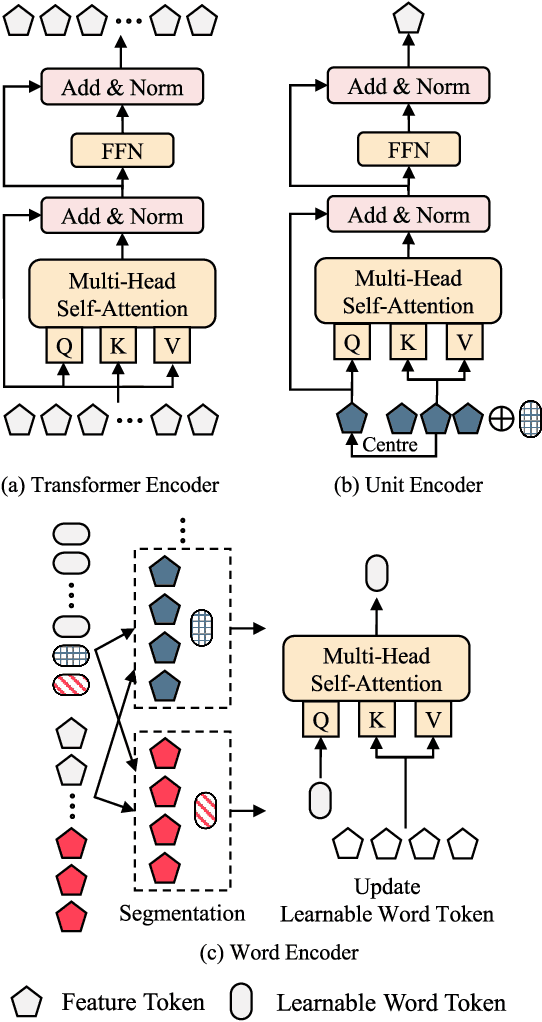
Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.