 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Answering Diverse Questions via Text Attached with Key Audio-Visual Clues
Mar 11, 2024
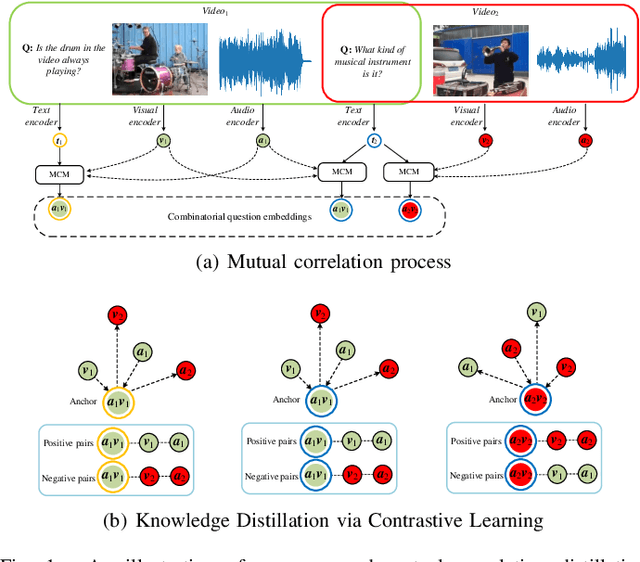
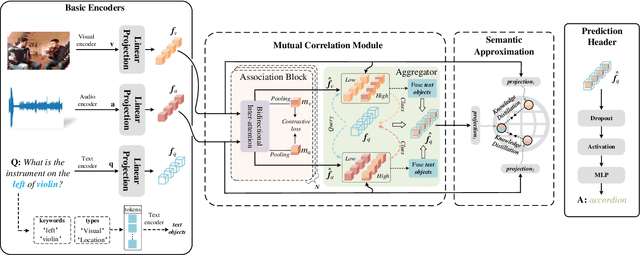
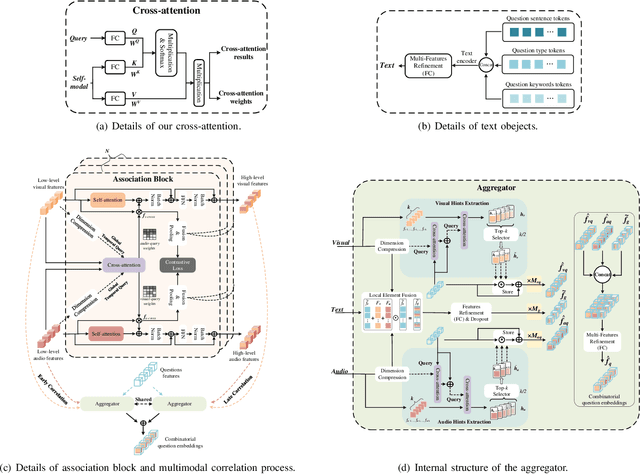
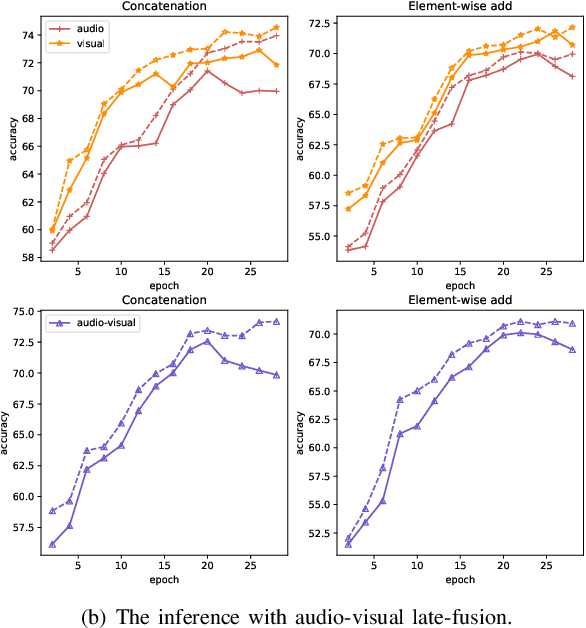
Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.
The Effectiveness of Graph Contrastive Learning on Mathematical Information Retrieval
Feb 21, 2024This paper details an empirical investigation into using Graph Contrastive Learning (GCL) to generate mathematical equation representations, a critical aspect of Mathematical Information Retrieval (MIR). Our findings reveal that this simple approach consistently exceeds the performance of the current leading formula retrieval model, TangentCFT. To support ongoing research and development in this field, we have made our source code accessible to the public at https://github.com/WangPeiSyuan/GCL-Formula-Retrieval/.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
SemGauss-SLAM: Dense Semantic Gaussian Splatting SLAM
Mar 12, 2024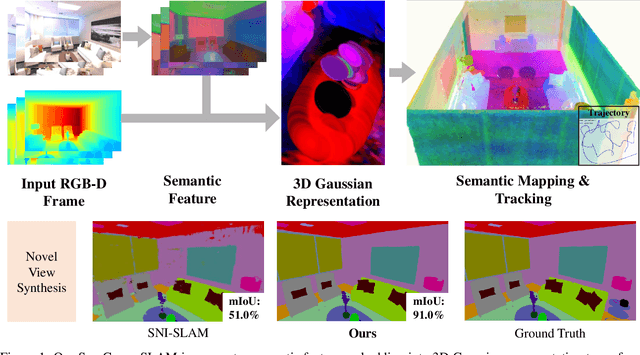
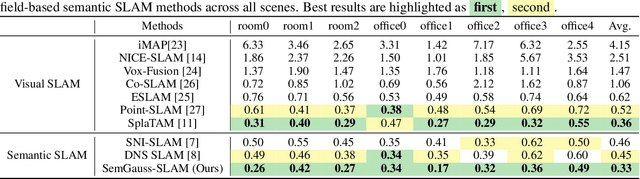
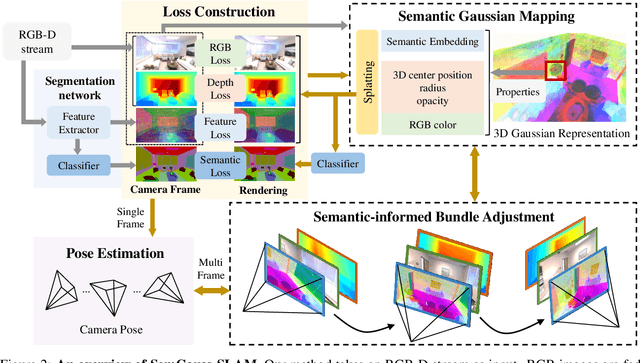
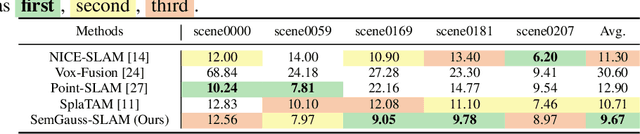
We propose SemGauss-SLAM, the first semantic SLAM system utilizing 3D Gaussian representation, that enables accurate 3D semantic mapping, robust camera tracking, and high-quality rendering in real-time. In this system, we incorporate semantic feature embedding into 3D Gaussian representation, which effectively encodes semantic information within the spatial layout of the environment for precise semantic scene representation. Furthermore, we propose feature-level loss for updating 3D Gaussian representation, enabling higher-level guidance for 3D Gaussian optimization. In addition, to reduce cumulative drift and improve reconstruction accuracy, we introduce semantic-informed bundle adjustment leveraging semantic associations for joint optimization of 3D Gaussian representation and camera poses, leading to more robust tracking and consistent mapping. Our SemGauss-SLAM method demonstrates superior performance over existing dense semantic SLAM methods in terms of mapping and tracking accuracy on Replica and ScanNet datasets, while also showing excellent capabilities in novel-view semantic synthesis and 3D semantic mapping.
Task and Motion Planning in Hierarchical 3D Scene Graphs
Mar 12, 2024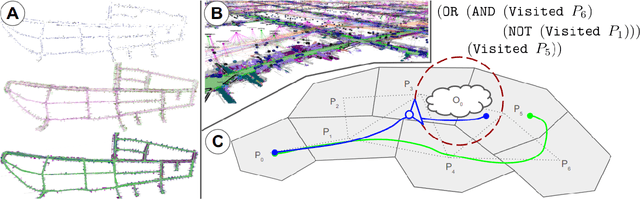
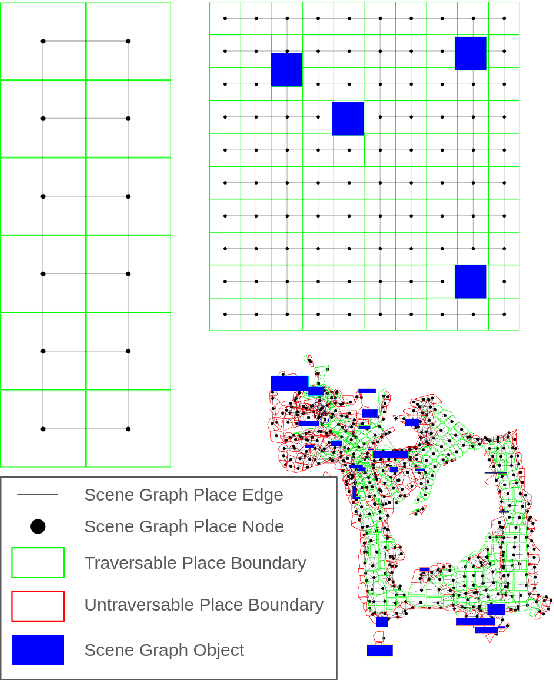
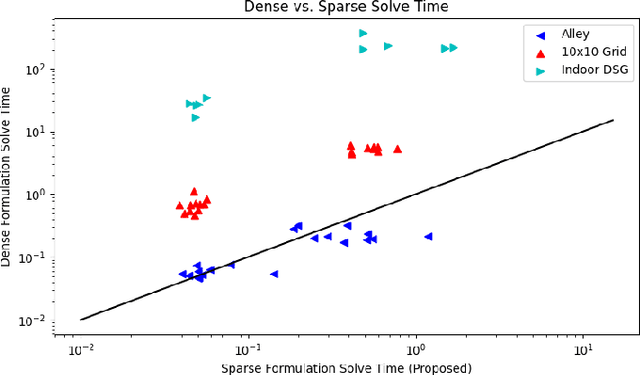
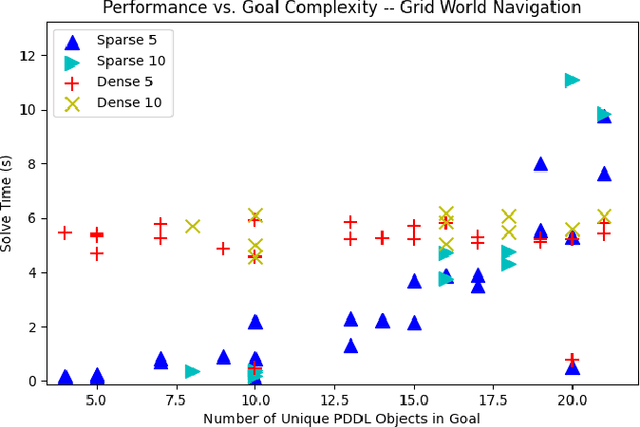
Recent work in the construction of 3D scene graphs has enabled mobile robots to build large-scale hybrid metric-semantic hierarchical representations of the world. These detailed models contain information that is useful for planning, however how to derive a planning domain from a 3D scene graph that enables efficient computation of executable plans is an open question. In this work, we present a novel approach for defining and solving Task and Motion Planning problems in large-scale environments using hierarchical 3D scene graphs. We identify a method for building sparse problem domains which enable scaling to large scenes, and propose a technique for incrementally adding objects to that domain during planning time to avoid wasting computation on irrelevant elements of the scene graph. We test our approach in two hand crafted domains as well as two scene graphs built from perception, including one constructed from the KITTI dataset. A video supplement is available at https://youtu.be/63xuCCaN0I4.
Open-World Semantic Segmentation Including Class Similarity
Mar 12, 2024

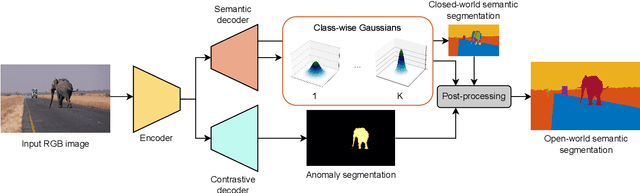
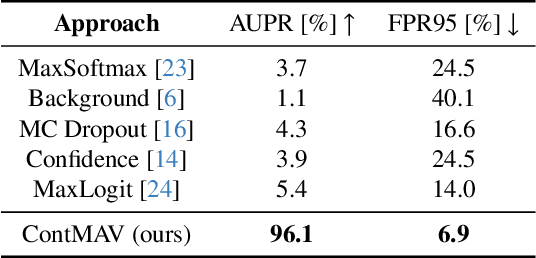
Interpreting camera data is key for autonomously acting systems, such as autonomous vehicles. Vision systems that operate in real-world environments must be able to understand their surroundings and need the ability to deal with novel situations. This paper tackles open-world semantic segmentation, i.e., the variant of interpreting image data in which objects occur that have not been seen during training. We propose a novel approach that performs accurate closed-world semantic segmentation and, at the same time, can identify new categories without requiring any additional training data. Our approach additionally provides a similarity measure for every newly discovered class in an image to a known category, which can be useful information in downstream tasks such as planning or mapping. Through extensive experiments, we show that our model achieves state-of-the-art results on classes known from training data as well as for anomaly segmentation and can distinguish between different unknown classes.
Visual Privacy Auditing with Diffusion Models
Mar 12, 2024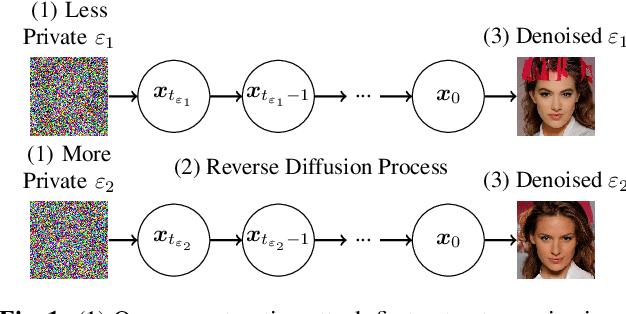
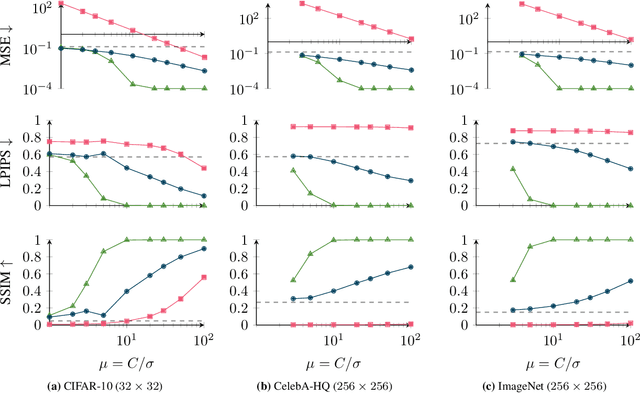
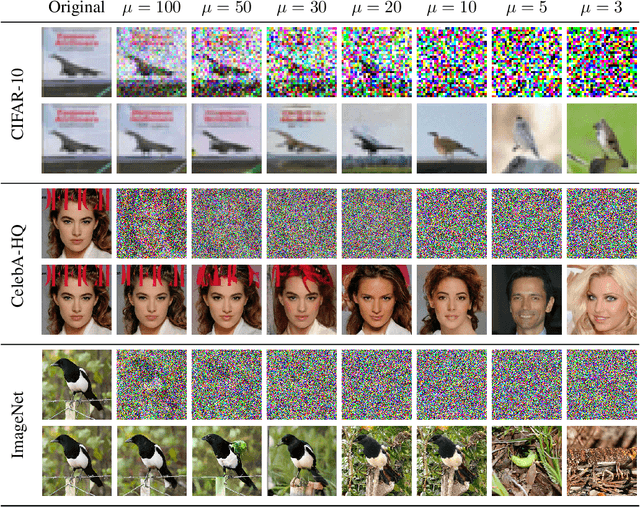
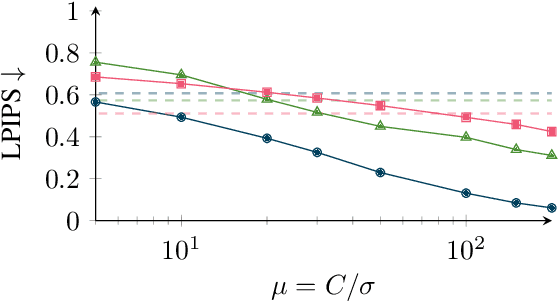
Image reconstruction attacks on machine learning models pose a significant risk to privacy by potentially leaking sensitive information. Although defending against such attacks using differential privacy (DP) has proven effective, determining appropriate DP parameters remains challenging. Current formal guarantees on data reconstruction success suffer from overly theoretical assumptions regarding adversary knowledge about the target data, particularly in the image domain. In this work, we empirically investigate this discrepancy and find that the practicality of these assumptions strongly depends on the domain shift between the data prior and the reconstruction target. We propose a reconstruction attack based on diffusion models (DMs) that assumes adversary access to real-world image priors and assess its implications on privacy leakage under DP-SGD. We show that (1) real-world data priors significantly influence reconstruction success, (2) current reconstruction bounds do not model the risk posed by data priors well, and (3) DMs can serve as effective auditing tools for visualizing privacy leakage.
An Audio-textual Diffusion Model For Converting Speech Signals Into Ultrasound Tongue Imaging Data
Mar 12, 2024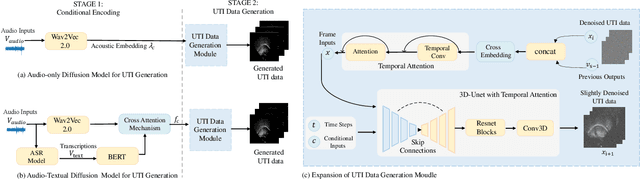
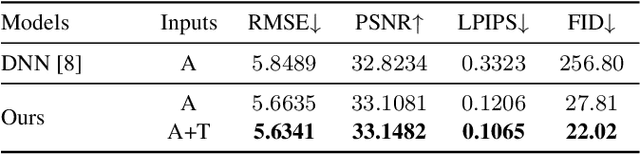
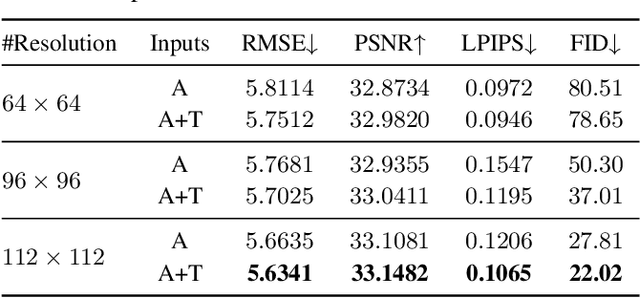
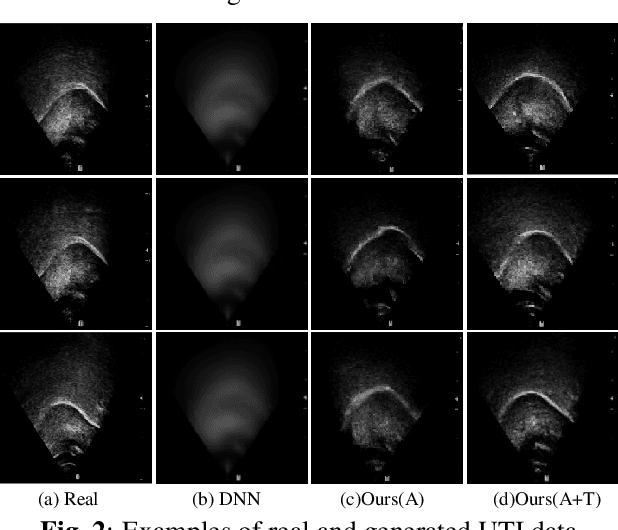
Acoustic-to-articulatory inversion (AAI) is to convert audio into articulator movements, such as ultrasound tongue imaging (UTI) data. An issue of existing AAI methods is only using the personalized acoustic information to derive the general patterns of tongue motions, and thus the quality of generated UTI data is limited. To address this issue, this paper proposes an audio-textual diffusion model for the UTI data generation task. In this model, the inherent acoustic characteristics of individuals related to the tongue motion details are encoded by using wav2vec 2.0, while the ASR transcriptions related to the universality of tongue motions are encoded by using BERT. UTI data are then generated by using a diffusion module. Experimental results showed that the proposed diffusion model could generate high-quality UTI data with clear tongue contour that is crucial for the linguistic analysis and clinical assessment. The project can be found on the website\footnote{https://yangyudong2020.github.io/wav2uti/
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Mar 12, 2024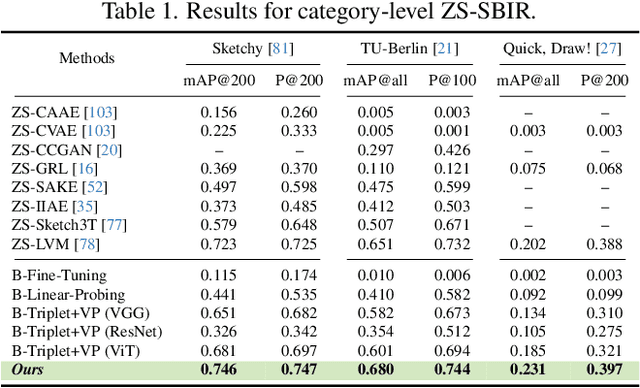
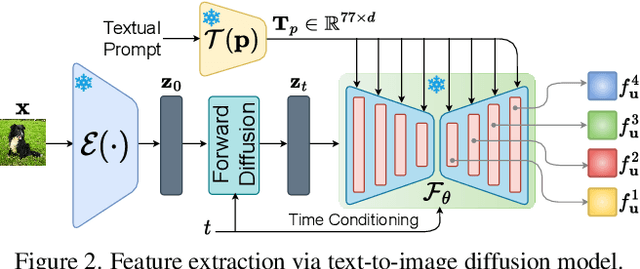


This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
The Missing Piece in Model Editing: A Deep Dive into the Hidden Damage Brought By Model Editing
Mar 12, 2024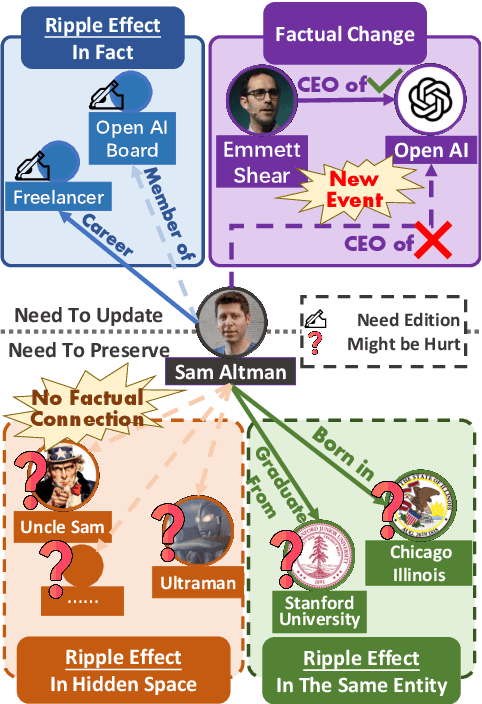
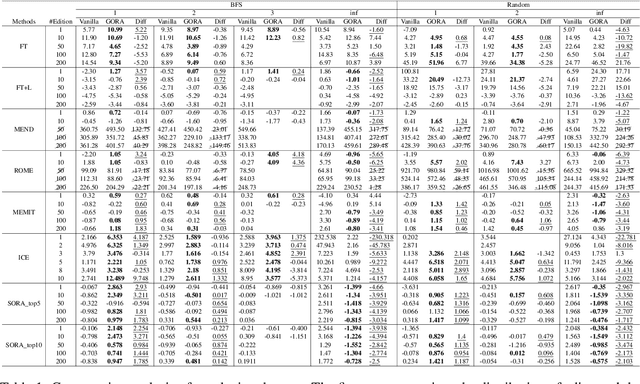
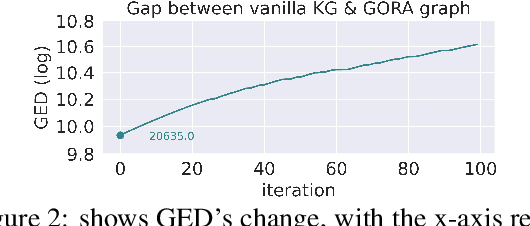

Large Language Models have revolutionized numerous tasks with their remarkable efficacy.However, the editing of these models, crucial for rectifying outdated or erroneous information, often leads to a complex issue known as the ripple effect in the hidden space. This effect, while difficult to detect, can significantly impede the efficacy of model editing tasks and deteriorate model performance.This paper addresses this scientific challenge by proposing a novel evaluation methodology, Graphical Outlier Relation based Assessment(GORA), which quantitatively evaluates the adaptations of the model and the subsequent impact of editing. Furthermore, we introduce the Selective Outlier Re-Editing Approach(SORA), a model editing method designed to mitigate this ripple effect. Our comprehensive evaluations reveal that the ripple effect in the hidden space is a significant issue in all current model editing methods. However, our proposed methods, GORA and SORA, effectively identify and alleviate this issue, respectively, contributing to the advancement of LLM editing techniques.