 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A real-time blind quality-of-experience assessment metric for HTTP adaptive streaming
Mar 17, 2023
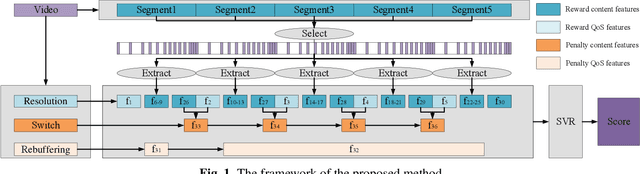

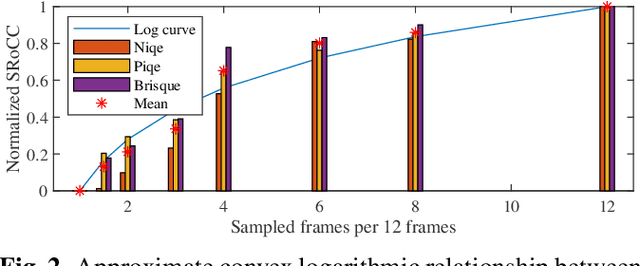
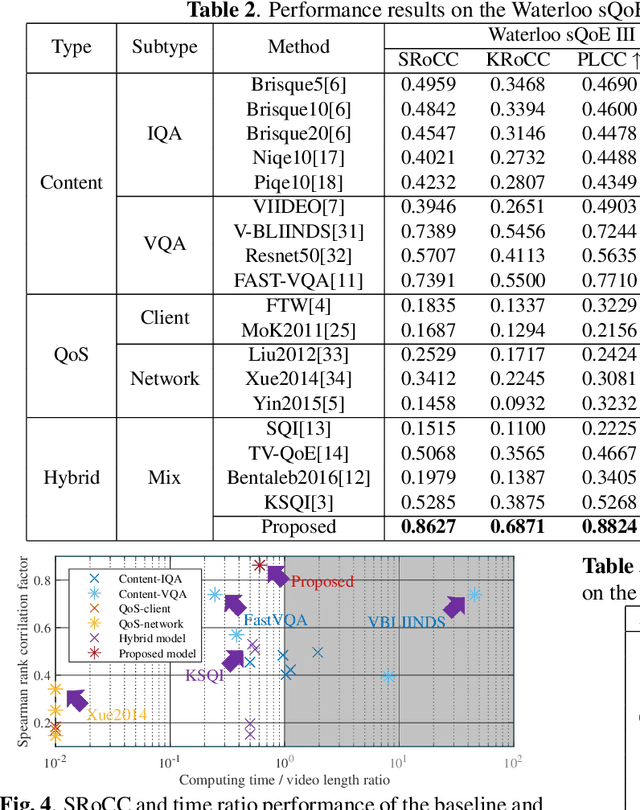
In today's Internet, HTTP Adaptive Streaming (HAS) is the mainstream standard for video streaming, which switches the bitrate of the video content based on an Adaptive BitRate (ABR) algorithm. An effective Quality of Experience (QoE) assessment metric can provide crucial feedback to an ABR algorithm. However, predicting such real-time QoE on the client side is challenging. The QoE prediction requires high consistency with the Human Visual System (HVS), low latency, and blind assessment, which are difficult to realize together. To address this challenge, we analyzed various characteristics of HAS systems and propose a non-uniform sampling metric to reduce time complexity. Furthermore, we design an effective QoE metric that integrates resolution and rebuffering time as the Quality of Service (QoS), as well as spatiotemporal output from a deep neural network and specific switching events as content information. These reward and penalty features are regressed into quality scores with a Support Vector Regression (SVR) model. Experimental results show that the accuracy of our metric outperforms the mainstream blind QoE metrics by 0.3, and its computing time is only 60\% of the video playback, indicating that the proposed metric is capable of providing real-time guidance to ABR algorithms and improving the overall performance of HAS.
A Bi-LSTM Autoencoder Framework for Anomaly Detection -- A Case Study of a Wind Power Dataset
Mar 17, 2023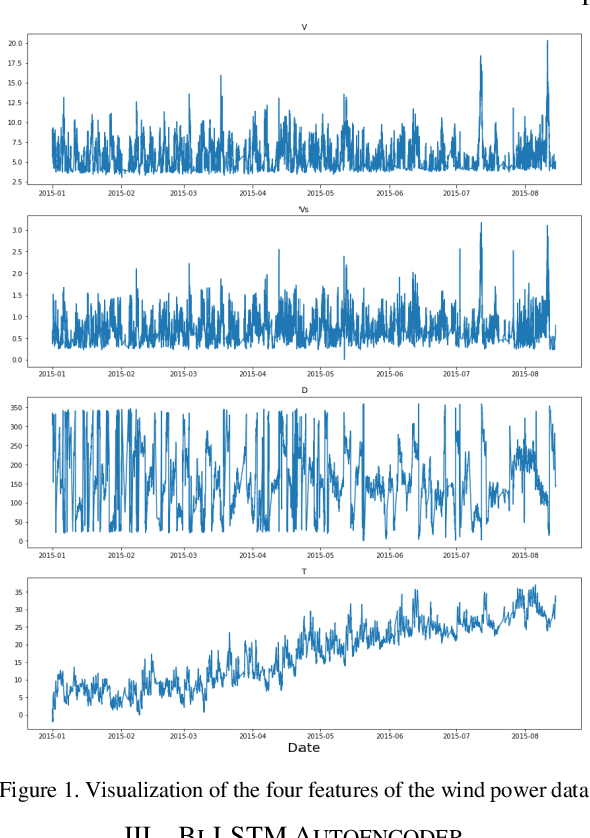
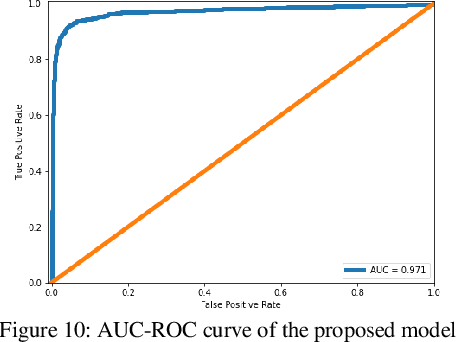
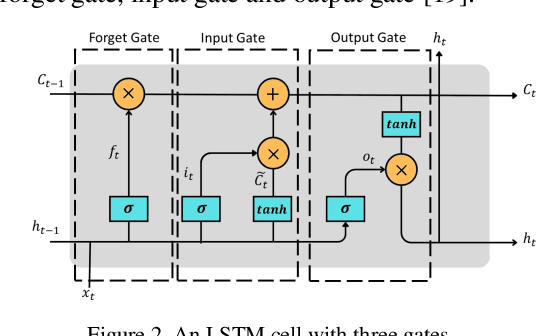
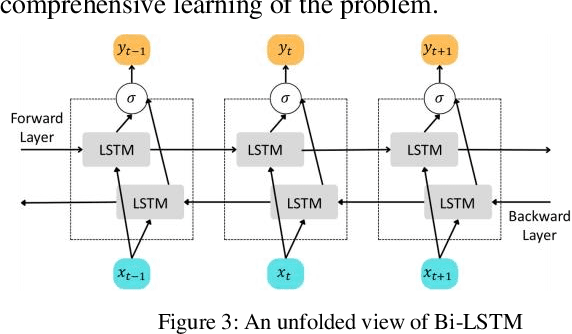
Anomalies refer to data points or events that deviate from normal and homogeneous events, which can include fraudulent activities, network infiltrations, equipment malfunctions, process changes, or other significant but infrequent events. Prompt detection of such events can prevent potential losses in terms of finances, information, and human resources. With the advancement of computational capabilities and the availability of large datasets, anomaly detection has become a major area of research. Among these, anomaly detection in time series has gained more attention recently due to the added complexity imposed by the time dimension. This study presents a novel framework for time series anomaly detection using a combination of Bidirectional Long Short Term Memory (Bi-LSTM) architecture and Autoencoder. The Bi-LSTM network, which comprises two unidirectional LSTM networks, can analyze the time series data from both directions and thus effectively discover the long-term dependencies hidden in the sequential data. Meanwhile, the Autoencoder mechanism helps to establish the optimal threshold beyond which an event can be classified as an anomaly. To demonstrate the effectiveness of the proposed framework, it is applied to a real-world multivariate time series dataset collected from a wind farm. The Bi-LSTM Autoencoder model achieved a classification accuracy of 96.79% and outperformed more commonly used LSTM Autoencoder models.
Data Dependent Regret Guarantees Against General Comparators for Full or Bandit Feedback
Mar 12, 2023We study the adversarial online learning problem and create a completely online algorithmic framework that has data dependent regret guarantees in both full expert feedback and bandit feedback settings. We study the expected performance of our algorithm against general comparators, which makes it applicable for a wide variety of problem scenarios. Our algorithm works from a universal prediction perspective and the performance measure used is the expected regret against arbitrary comparator sequences, which is the difference between our losses and a competing loss sequence. The competition class can be designed to include fixed arm selections, switching bandits, contextual bandits, periodic bandits or any other competition of interest. The sequences in the competition class are generally determined by the specific application at hand and should be designed accordingly. Our algorithm neither uses nor needs any preliminary information about the loss sequences and is completely online. Its performance bounds are data dependent, where any affine transform of the losses has no effect on the normalized regret.
Multistage Stochastic Optimization via Kernels
Mar 11, 2023
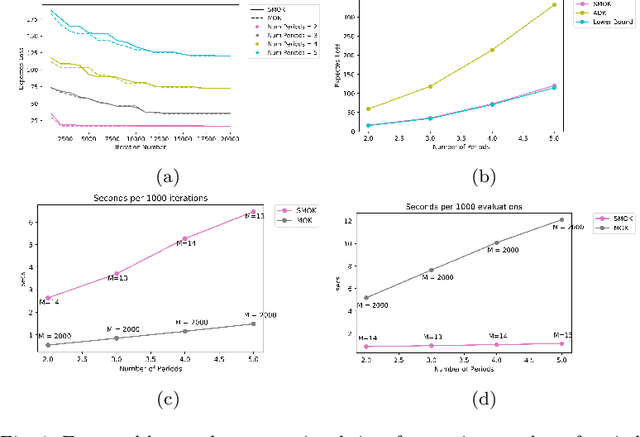
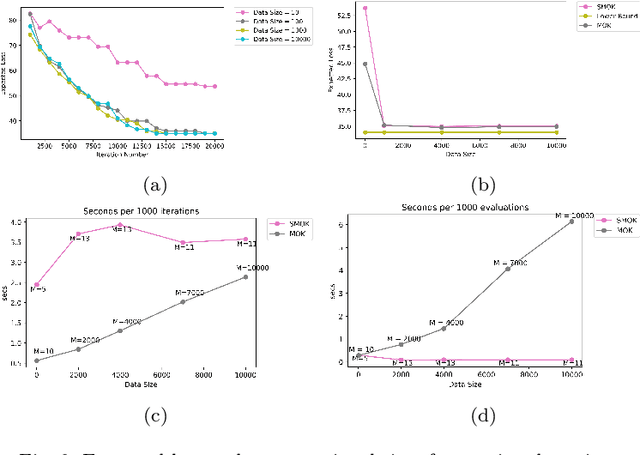

We develop a non-parametric, data-driven, tractable approach for solving multistage stochastic optimization problems in which decisions do not affect the uncertainty. The proposed framework represents the decision variables as elements of a reproducing kernel Hilbert space and performs functional stochastic gradient descent to minimize the empirical regularized loss. By incorporating sparsification techniques based on function subspace projections we are able to overcome the computational complexity that standard kernel methods introduce as the data size increases. We prove that the proposed approach is asymptotically optimal for multistage stochastic optimization with side information. Across various computational experiments on stochastic inventory management problems, {our method performs well in multidimensional settings} and remains tractable when the data size is large. Lastly, by computing lower bounds for the optimal loss of the inventory control problem, we show that the proposed method produces decision rules with near-optimal average performance.
Learning interpretable causal networks from very large datasets, application to 400,000 medical records of breast cancer patients
Mar 11, 2023Discovering causal effects is at the core of scientific investigation but remains challenging when only observational data is available. In practice, causal networks are difficult to learn and interpret, and limited to relatively small datasets. We report a more reliable and scalable causal discovery method (iMIIC), based on a general mutual information supremum principle, which greatly improves the precision of inferred causal relations while distinguishing genuine causes from putative and latent causal effects. We showcase iMIIC on synthetic and real-life healthcare data from 396,179 breast cancer patients from the US Surveillance, Epidemiology, and End Results program. More than 90\% of predicted causal effects appear correct, while the remaining unexpected direct and indirect causal effects can be interpreted in terms of diagnostic procedures, therapeutic timing, patient preference or socio-economic disparity. iMIIC's unique capabilities open up new avenues to discover reliable and interpretable causal networks across a range of research fields.
Sequential Information Design: Learning to Persuade in the Dark
Sep 08, 2022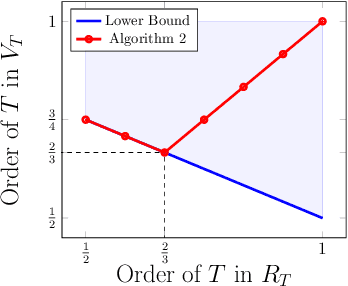
We study a repeated information design problem faced by an informed sender who tries to influence the behavior of a self-interested receiver. We consider settings where the receiver faces a sequential decision making (SDM) problem. At each round, the sender observes the realizations of random events in the SDM problem. This begets the challenge of how to incrementally disclose such information to the receiver to persuade them to follow (desirable) action recommendations. We study the case in which the sender does not know random events probabilities, and, thus, they have to gradually learn them while persuading the receiver. We start by providing a non-trivial polytopal approximation of the set of sender's persuasive information structures. This is crucial to design efficient learning algorithms. Next, we prove a negative result: no learning algorithm can be persuasive. Thus, we relax persuasiveness requirements by focusing on algorithms that guarantee that the receiver's regret in following recommendations grows sub-linearly. In the full-feedback setting -- where the sender observes all random events realizations -- , we provide an algorithm with $\tilde{O}(\sqrt{T})$ regret for both the sender and the receiver. Instead, in the bandit-feedback setting -- where the sender only observes the realizations of random events actually occurring in the SDM problem -- , we design an algorithm that, given an $\alpha \in [1/2, 1]$ as input, ensures $\tilde{O}({T^\alpha})$ and $\tilde{O}( T^{\max \{ \alpha, 1-\frac{\alpha}{2} \} })$ regrets, for the sender and the receiver respectively. This result is complemented by a lower bound showing that such a regrets trade-off is essentially tight.
SemanticAC: Semantics-Assisted Framework for Audio Classification
Feb 12, 2023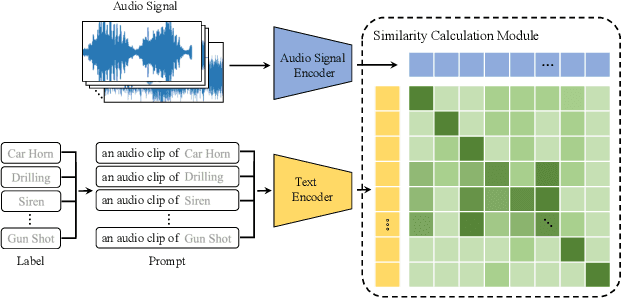
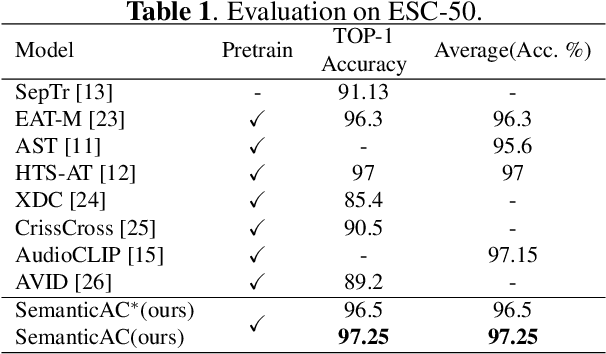
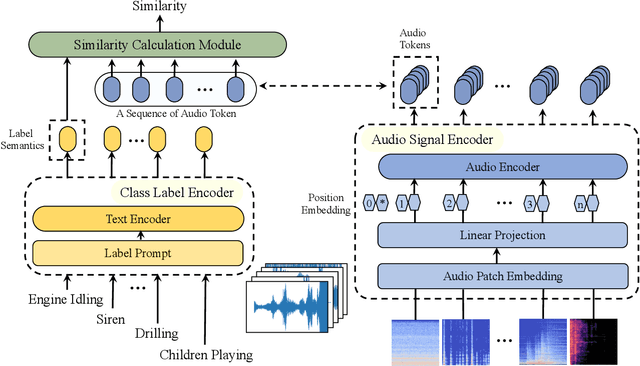

In this paper, we propose SemanticAC, a semantics-assisted framework for Audio Classification to better leverage the semantic information. Unlike conventional audio classification methods that treat class labels as discrete vectors, we employ a language model to extract abundant semantics from labels and optimize the semantic consistency between audio signals and their labels. We verify that simple textual information from labels and advanced pretraining models enable more abundant semantic supervision for better performance. Specifically, we design a text encoder to capture the semantic information from the text extension of labels. Then we map the audio signals to align with the semantics of corresponding class labels via an audio encoder and a similarity calculation module so as to enforce the semantic consistency. Extensive experiments on two audio datasets, ESC-50 and US8K demonstrate that our proposed method consistently outperforms the compared audio classification methods.
Average Age of Information Penalty of Short-Packet Communications with Packet Management
Oct 26, 2022
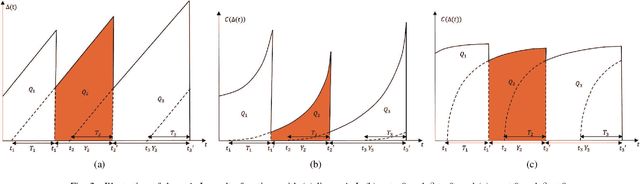
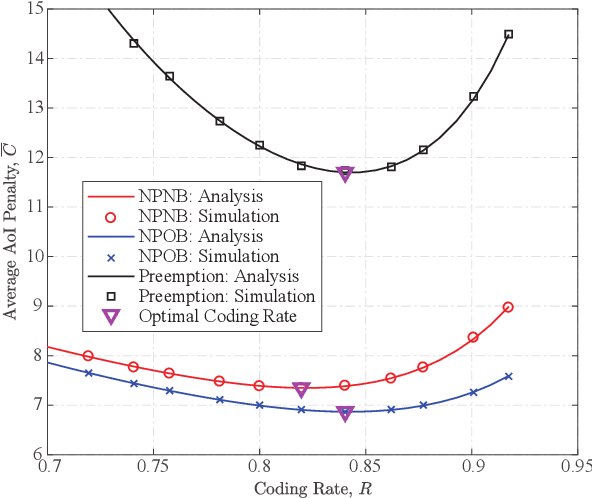
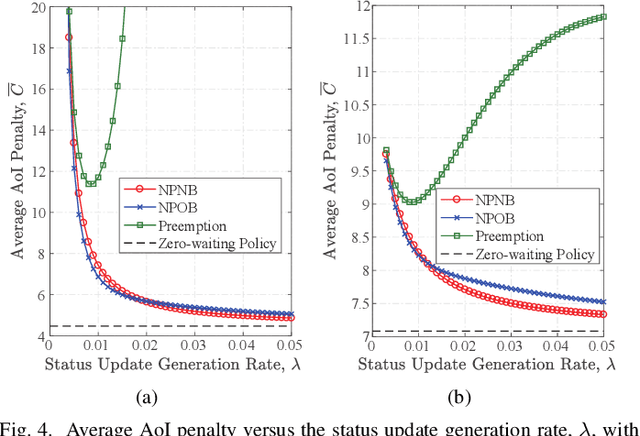
In this paper, we analyze the non-linear age of information (AoI) performance in a point-to-point short packet communication system, where a transmitter generates packets based on status updates and transmits the packets to a receiver. Specifically, we investigate three packet management strategies, namely, the non-preemption with no buffer strategy, the non-preemption with one buffer strategy, and the preemption strategy. To characterize the level of the receiver's dissatisfaction on outdated data, we adopt a generalized \alpha-\beta AoI penalty function into the analysis and derive closed-form expressions for the average AoI penalty achieved by the three packet management strategies. Simulation results are used to corroborate our analysis and explicitly evaluate the impact of various system parameters, such as the coding rate and status update generation rate, on the AoI performance. Additionally, we find that the value of \alpha reflects the system transmission reliability.
Improving Contextual Spelling Correction by External Acoustics Attention and Semantic Aware Data Augmentation
Feb 22, 2023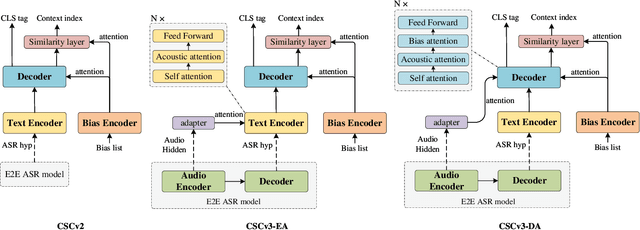
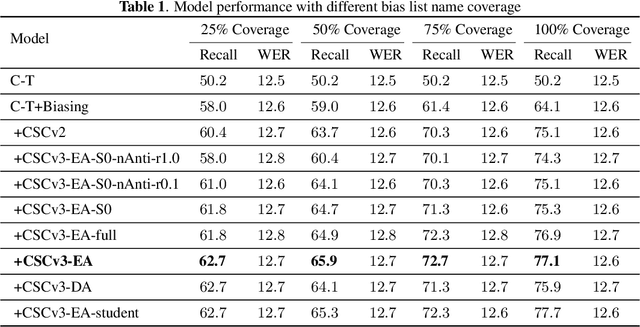

We previously proposed contextual spelling correction (CSC) to correct the output of end-to-end (E2E) automatic speech recognition (ASR) models with contextual information such as name, place, etc. Although CSC has achieved reasonable improvement in the biasing problem, there are still two drawbacks for further accuracy improvement. First, due to information limitation in text only hypothesis or weak performance of ASR model on rare domains, the CSC model may fail to correct phrases with similar pronunciation or anti-context cases where all biasing phrases are not present in the utterance. Second, there is a discrepancy between the training and inference of CSC. The bias list in training is randomly selected but in inference there may be more similarity between ground truth phrase and other phrases. To solve above limitations, in this paper we propose an improved non-autoregressive (NAR) spelling correction model for contextual biasing in E2E neural transducer-based ASR systems to improve the previous CSC model from two perspectives: Firstly, we incorporate acoustics information with an external attention as well as text hypotheses into CSC to better distinguish target phrase from dissimilar or irrelevant phrases. Secondly, we design a semantic aware data augmentation schema in training phrase to reduce the mismatch between training and inference to further boost the biasing accuracy. Experiments show that the improved method outperforms the baseline ASR+Biasing system by as much as 20.3% relative name recall gain and achieves stable improvement compared to the previous CSC method over different bias list name coverage ratio.
A Gold Standard Dataset for the Reviewer Assignment Problem
Mar 23, 2023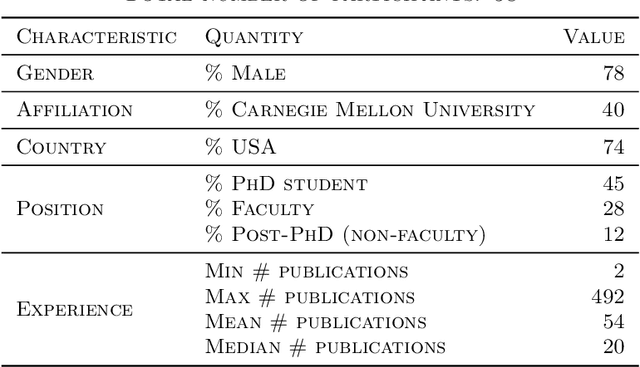
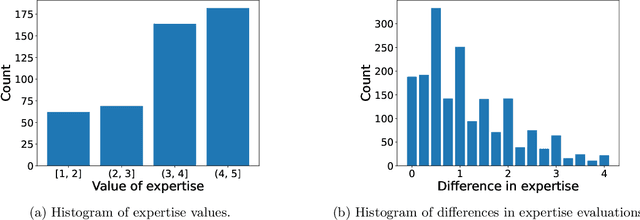

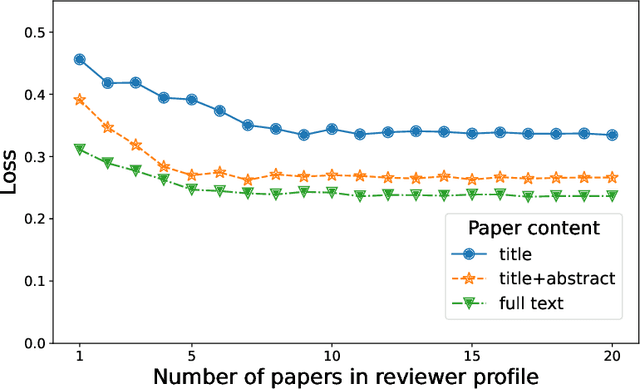
Many peer-review venues are either using or looking to use algorithms to assign submissions to reviewers. The crux of such automated approaches is the notion of the "similarity score"--a numerical estimate of the expertise of a reviewer in reviewing a paper--and many algorithms have been proposed to compute these scores. However, these algorithms have not been subjected to a principled comparison, making it difficult for stakeholders to choose the algorithm in an evidence-based manner. The key challenge in comparing existing algorithms and developing better algorithms is the lack of the publicly available gold-standard data that would be needed to perform reproducible research. We address this challenge by collecting a novel dataset of similarity scores that we release to the research community. Our dataset consists of 477 self-reported expertise scores provided by 58 researchers who evaluated their expertise in reviewing papers they have read previously. We use this data to compare several popular algorithms employed in computer science conferences and come up with recommendations for stakeholders. Our main findings are as follows. First, all algorithms make a non-trivial amount of error. For the task of ordering two papers in terms of their relevance for a reviewer, the error rates range from 12%-30% in easy cases to 36%-43% in hard cases, highlighting the vital need for more research on the similarity-computation problem. Second, most existing algorithms are designed to work with titles and abstracts of papers, and in this regime the Specter+MFR algorithm performs best. Third, to improve performance, it may be important to develop modern deep-learning based algorithms that can make use of the full texts of papers: the classical TD-IDF algorithm enhanced with full texts of papers is on par with the deep-learning based Specter+MFR that cannot make use of this information.