 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLSA: Contrastive Learning-based Survival Analysis for Popularity Prediction in MEC Networks
Mar 21, 2023
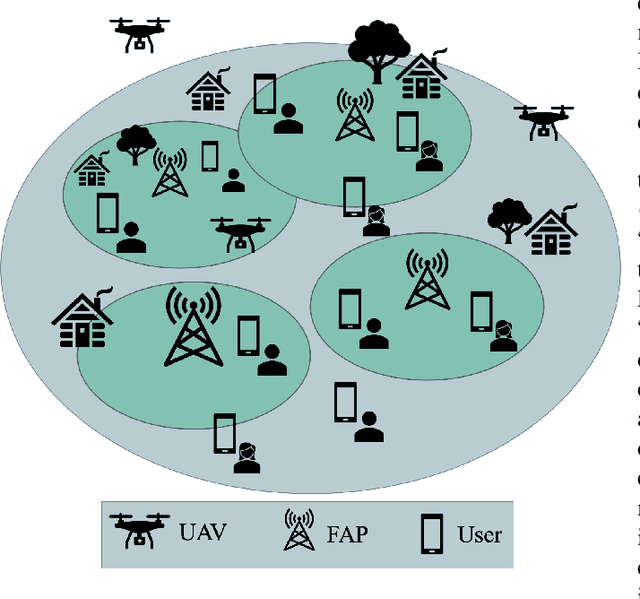
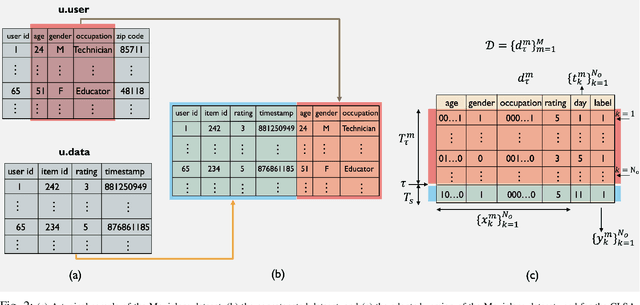
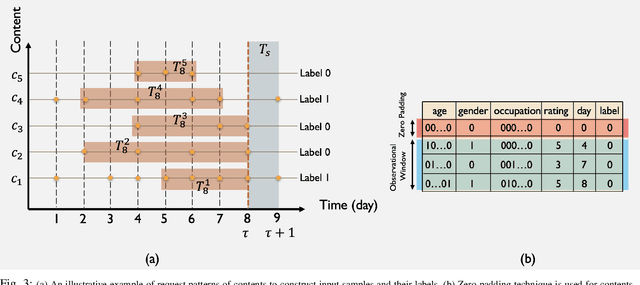
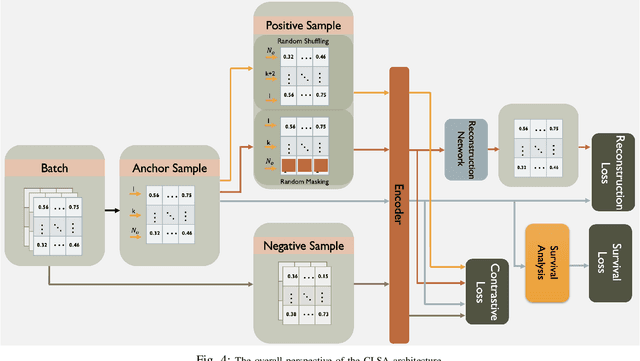
Mobile Edge Caching (MEC) integrated with Deep Neural Networks (DNNs) is an innovative technology with significant potential for the future generation of wireless networks, resulting in a considerable reduction in users' latency. The MEC network's effectiveness, however, heavily relies on its capacity to predict and dynamically update the storage of caching nodes with the most popular contents. To be effective, a DNN-based popularity prediction model needs to have the ability to understand the historical request patterns of content, including their temporal and spatial correlations. Existing state-of-the-art time-series DNN models capture the latter by simultaneously inputting the sequential request patterns of multiple contents to the network, considerably increasing the size of the input sample. This motivates us to address this challenge by proposing a DNN-based popularity prediction framework based on the idea of contrasting input samples against each other, designed for the Unmanned Aerial Vehicle (UAV)-aided MEC networks. Referred to as the Contrastive Learning-based Survival Analysis (CLSA), the proposed architecture consists of a self-supervised Contrastive Learning (CL) model, where the temporal information of sequential requests is learned using a Long Short Term Memory (LSTM) network as the encoder of the CL architecture. Followed by a Survival Analysis (SA) network, the output of the proposed CLSA architecture is probabilities for each content's future popularity, which are then sorted in descending order to identify the Top-K popular contents. Based on the simulation results, the proposed CLSA architecture outperforms its counterparts across the classification accuracy and cache-hit ratio.
Self-Supervised One-Shot Learning for Automatic Segmentation of StyleGAN Images
Mar 17, 2023

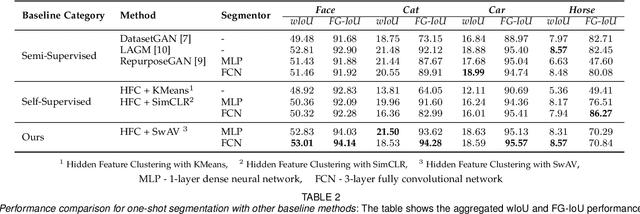
We propose a framework for the automatic one-shot segmentation of synthetic images generated by a StyleGAN. Our framework is based on the observation that the multi-scale hidden features in the GAN generator hold useful semantic information that can be utilized for automatic on-the-fly segmentation of the generated images. Using these features, our framework learns to segment synthetic images using a self-supervised contrastive clustering algorithm that projects the hidden features into a compact space for per-pixel classification. This novel contrastive learner is based on using a pixel-wise swapped prediction loss for image segmentation that leads to faster learning of the feature vectors for one-shot segmentation. We have tested our implementation on a number of standard benchmarks to yield a segmentation performance that not only outperforms the semi-supervised baseline methods by an average wIoU margin of 1.02% but also improves the inference speeds by a factor of 4.5. Finally, we also show the results of using the proposed one-shot learner in implementing BagGAN, a framework for producing annotated synthetic baggage X-ray scans for threat detection. This framework was trained and tested on the PIDRay baggage benchmark to yield a performance comparable to its baseline segmenter based on manual annotations.
MRIS: A Multi-modal Retrieval Approach for Image Synthesis on Diverse Modalities
Mar 17, 2023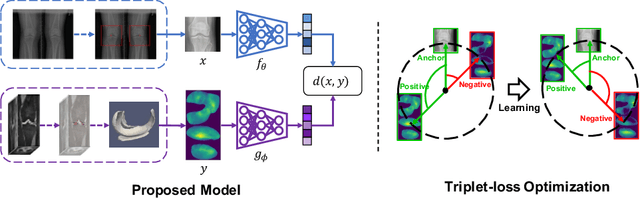
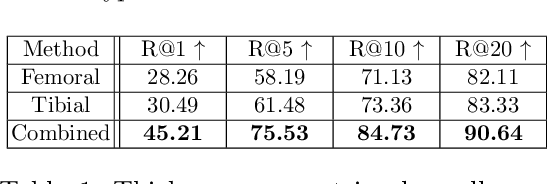
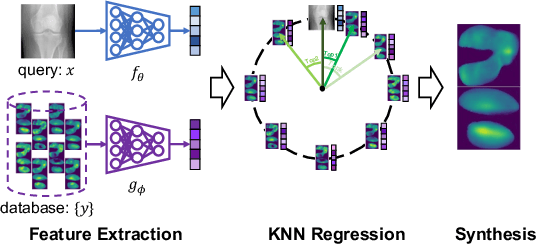
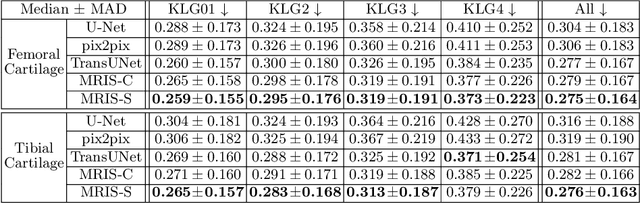
Multiple imaging modalities are often used for disease diagnosis, prediction, or population-based analyses. However, not all modalities might be available due to cost, different study designs, or changes in imaging technology. If the differences between the types of imaging are small, data harmonization approaches can be used; for larger changes, direct image synthesis approaches have been explored. In this paper, we develop an approach based on multi-modal metric learning to synthesize images of diverse modalities. We use metric learning via multi-modal image retrieval, resulting in embeddings that can relate images of different modalities. Given a large image database, the learned image embeddings allow us to use k-nearest neighbor (k-NN) regression for image synthesis. Our driving medical problem is knee osteoarthritis (KOA), but our developed method is general after proper image alignment. We test our approach by synthesizing cartilage thickness maps obtained from 3D magnetic resonance (MR) images using 2D radiographs. Our experiments show that the proposed method outperforms direct image synthesis and that the synthesized thickness maps retain information relevant to downstream tasks such as progression prediction and Kellgren-Lawrence grading (KLG). Our results suggest that retrieval approaches can be used to obtain high-quality and meaningful image synthesis results given large image databases.
Star-Net: Improving Single Image Desnowing Model With More Efficient Connection and Diverse Feature Interaction
Mar 17, 2023


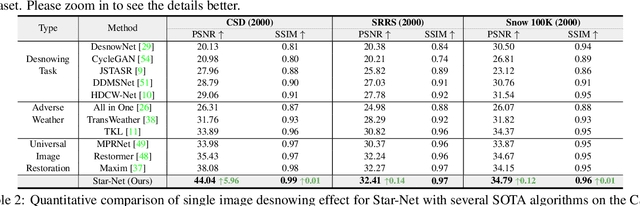
Compared to other severe weather image restoration tasks, single image desnowing is a more challenging task. This is mainly due to the diversity and irregularity of snow shape, which makes it extremely difficult to restore images in snowy scenes. Moreover, snow particles also have a veiling effect similar to haze or mist. Although current works can effectively remove snow particles with various shapes, they also bring distortion to the restored image. To address these issues, we propose a novel single image desnowing network called Star-Net. First, we design a Star type Skip Connection (SSC) to establish information channels for all different scale features, which can deal with the complex shape of snow particles.Second, we present a Multi-Stage Interactive Transformer (MIT) as the base module of Star-Net, which is designed to better understand snow particle shapes and to address image distortion by explicitly modeling a variety of important image recovery features. Finally, we propose a Degenerate Filter Module (DFM) to filter the snow particle and snow fog residual in the SSC on the spatial and channel domains. Extensive experiments show that our Star-Net achieves state-of-the-art snow removal performances on three standard snow removal datasets and retains the original sharpness of the images.
A real-time blind quality-of-experience assessment metric for HTTP adaptive streaming
Mar 17, 2023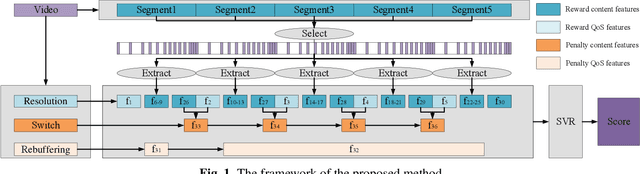

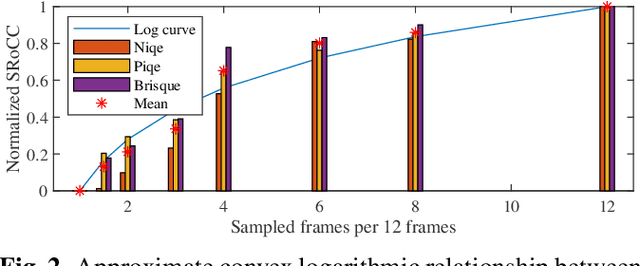
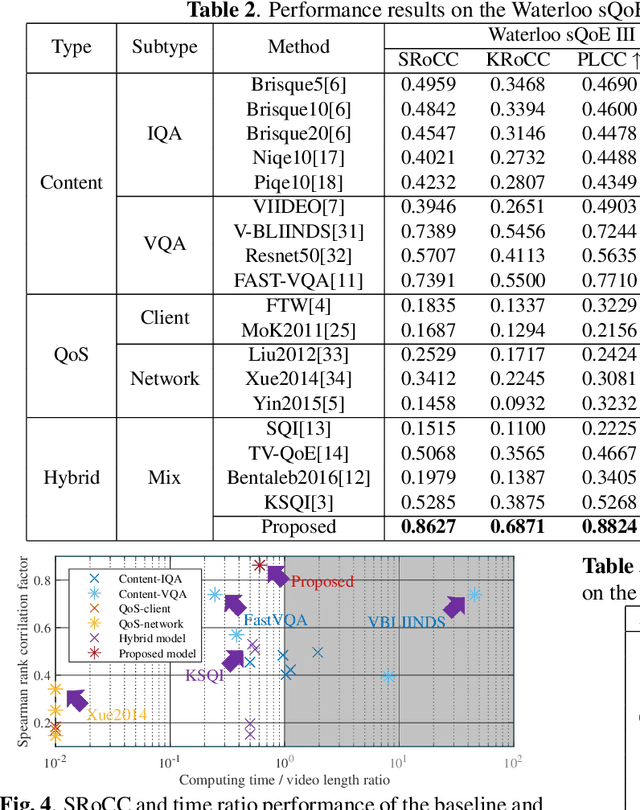
In today's Internet, HTTP Adaptive Streaming (HAS) is the mainstream standard for video streaming, which switches the bitrate of the video content based on an Adaptive BitRate (ABR) algorithm. An effective Quality of Experience (QoE) assessment metric can provide crucial feedback to an ABR algorithm. However, predicting such real-time QoE on the client side is challenging. The QoE prediction requires high consistency with the Human Visual System (HVS), low latency, and blind assessment, which are difficult to realize together. To address this challenge, we analyzed various characteristics of HAS systems and propose a non-uniform sampling metric to reduce time complexity. Furthermore, we design an effective QoE metric that integrates resolution and rebuffering time as the Quality of Service (QoS), as well as spatiotemporal output from a deep neural network and specific switching events as content information. These reward and penalty features are regressed into quality scores with a Support Vector Regression (SVR) model. Experimental results show that the accuracy of our metric outperforms the mainstream blind QoE metrics by 0.3, and its computing time is only 60\% of the video playback, indicating that the proposed metric is capable of providing real-time guidance to ABR algorithms and improving the overall performance of HAS.
A Bi-LSTM Autoencoder Framework for Anomaly Detection -- A Case Study of a Wind Power Dataset
Mar 17, 2023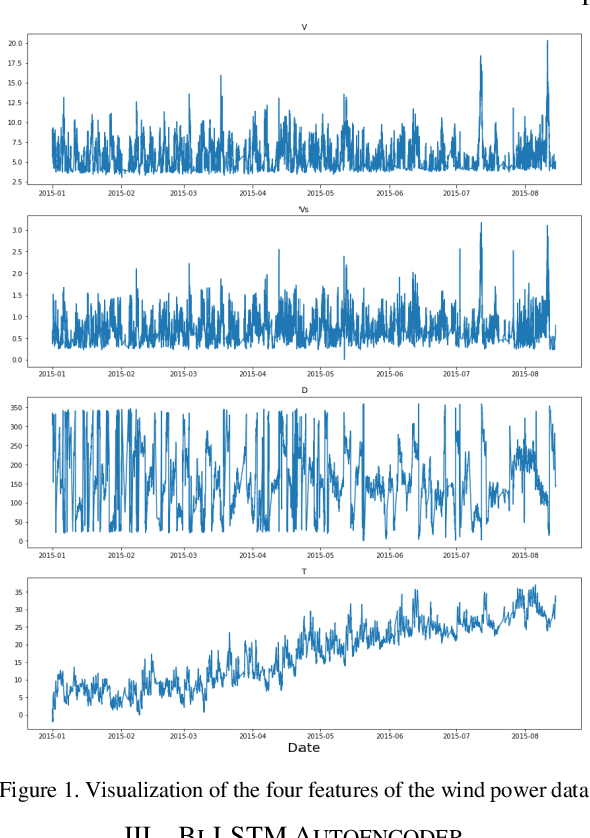
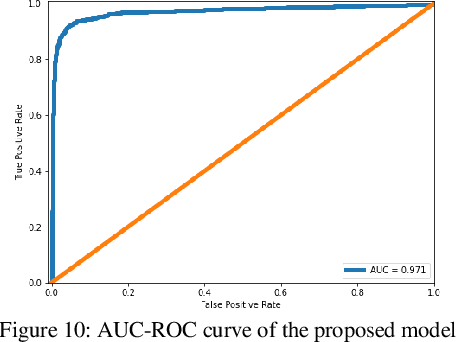
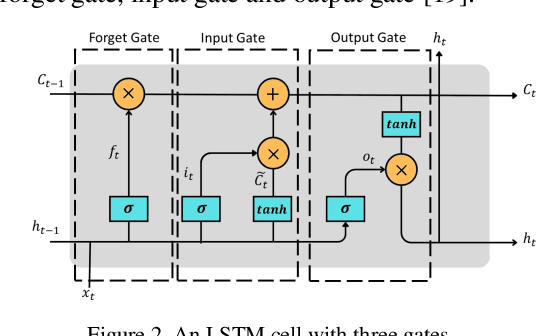
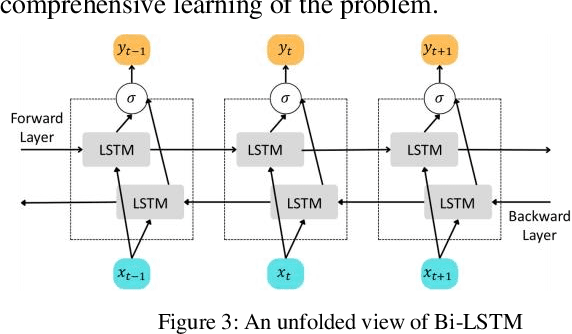
Anomalies refer to data points or events that deviate from normal and homogeneous events, which can include fraudulent activities, network infiltrations, equipment malfunctions, process changes, or other significant but infrequent events. Prompt detection of such events can prevent potential losses in terms of finances, information, and human resources. With the advancement of computational capabilities and the availability of large datasets, anomaly detection has become a major area of research. Among these, anomaly detection in time series has gained more attention recently due to the added complexity imposed by the time dimension. This study presents a novel framework for time series anomaly detection using a combination of Bidirectional Long Short Term Memory (Bi-LSTM) architecture and Autoencoder. The Bi-LSTM network, which comprises two unidirectional LSTM networks, can analyze the time series data from both directions and thus effectively discover the long-term dependencies hidden in the sequential data. Meanwhile, the Autoencoder mechanism helps to establish the optimal threshold beyond which an event can be classified as an anomaly. To demonstrate the effectiveness of the proposed framework, it is applied to a real-world multivariate time series dataset collected from a wind farm. The Bi-LSTM Autoencoder model achieved a classification accuracy of 96.79% and outperformed more commonly used LSTM Autoencoder models.
FOSI: Hybrid First and Second Order Optimization
Feb 23, 2023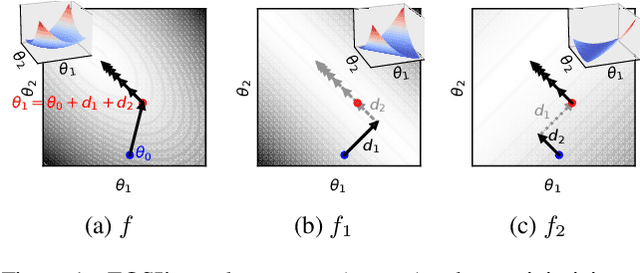
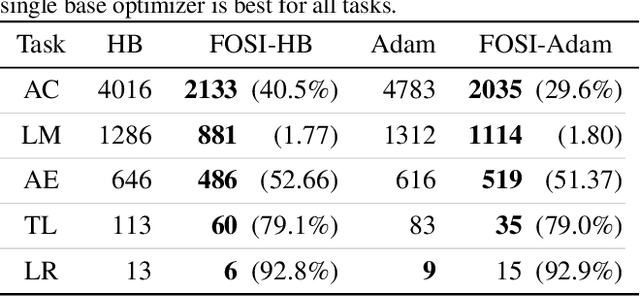
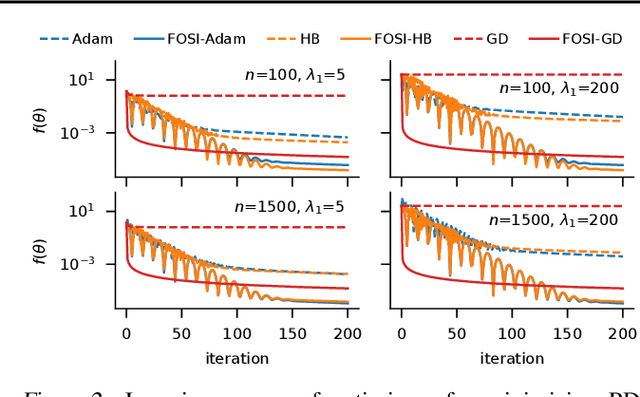

Though second-order optimization methods are highly effective, popular approaches in machine learning such as SGD and Adam use only first-order information due to the difficulty of computing curvature in high dimensions. We present FOSI, a novel meta-algorithm that improves the performance of any first-order optimizer by efficiently incorporating second-order information during the optimization process. In each iteration, FOSI implicitly splits the function into two quadratic functions defined on orthogonal subspaces, then uses a second-order method to minimize the first, and the base optimizer to minimize the other. Our analysis of FOSI's preconditioner and effective Hessian proves that FOSI improves the condition number for a large family of optimizers. Our empirical evaluation demonstrates that FOSI improves the convergence rate and optimization time of GD, Heavy-Ball, and Adam when applied to several deep neural networks training tasks such as audio classification, transfer learning, and object classification and when applied to convex functions.
A Dynamic-Neighbor Particle Swarm Optimizer for Accurate Latent Factor Analysis
Feb 23, 2023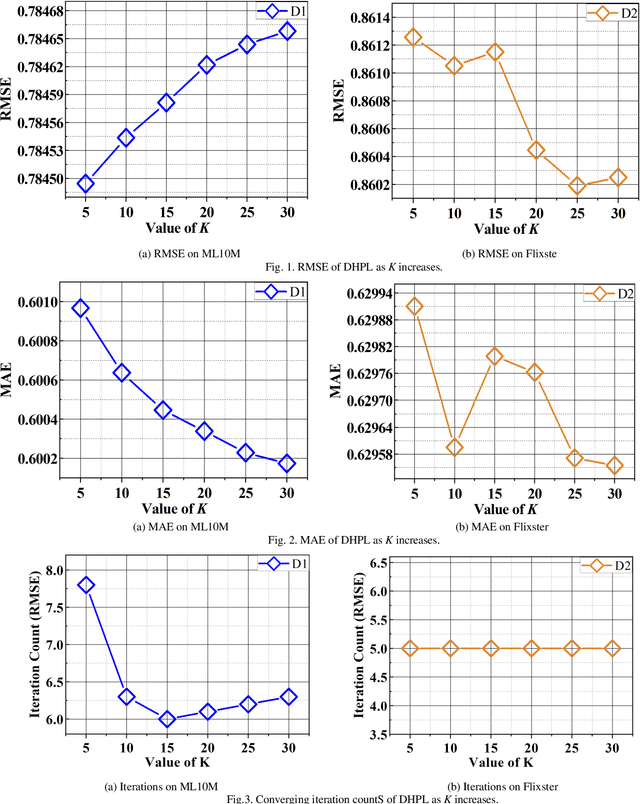
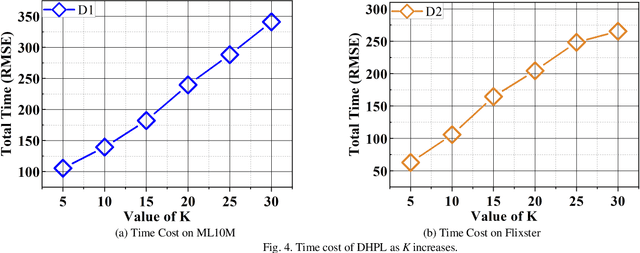

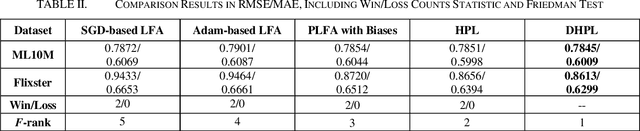
High-Dimensional and Incomplete matrices, which usually contain a large amount of valuable latent information, can be well represented by a Latent Factor Analysis model. The performance of an LFA model heavily rely on its optimization process. Thereby, some prior studies employ the Particle Swarm Optimization to enhance an LFA model's optimization process. However, the particles within the swarm follow the static evolution paths and only share the global best information, which limits the particles' searching area to cause sub-optimum issue. To address this issue, this paper proposes a Dynamic-neighbor-cooperated Hierarchical PSO-enhanced LFA model with two-fold main ideas. First is the neighbor-cooperated strategy, which enhances the randomly chosen neighbor's velocity for particles' evolution. Second is the dynamic hyper-parameter tunning. Extensive experiments on two benchmark datasets are conducted to evaluate the proposed DHPL model. The results substantiate that DHPL achieves a higher accuracy without hyper-parameters tunning than the existing PSO-incorporated LFA models in representing an HDI matrix.
Data Dependent Regret Guarantees Against General Comparators for Full or Bandit Feedback
Mar 12, 2023We study the adversarial online learning problem and create a completely online algorithmic framework that has data dependent regret guarantees in both full expert feedback and bandit feedback settings. We study the expected performance of our algorithm against general comparators, which makes it applicable for a wide variety of problem scenarios. Our algorithm works from a universal prediction perspective and the performance measure used is the expected regret against arbitrary comparator sequences, which is the difference between our losses and a competing loss sequence. The competition class can be designed to include fixed arm selections, switching bandits, contextual bandits, periodic bandits or any other competition of interest. The sequences in the competition class are generally determined by the specific application at hand and should be designed accordingly. Our algorithm neither uses nor needs any preliminary information about the loss sequences and is completely online. Its performance bounds are data dependent, where any affine transform of the losses has no effect on the normalized regret.
Multistage Stochastic Optimization via Kernels
Mar 11, 2023
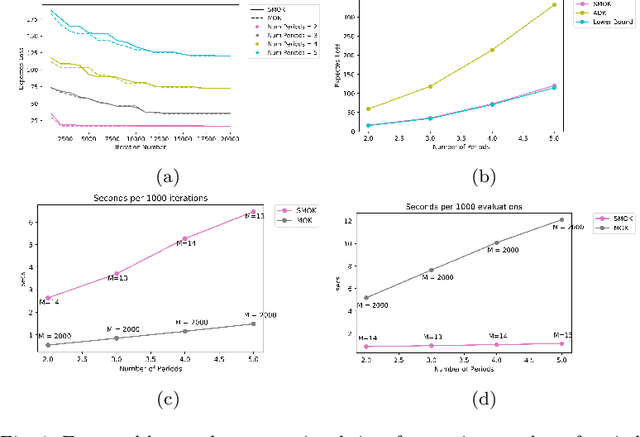
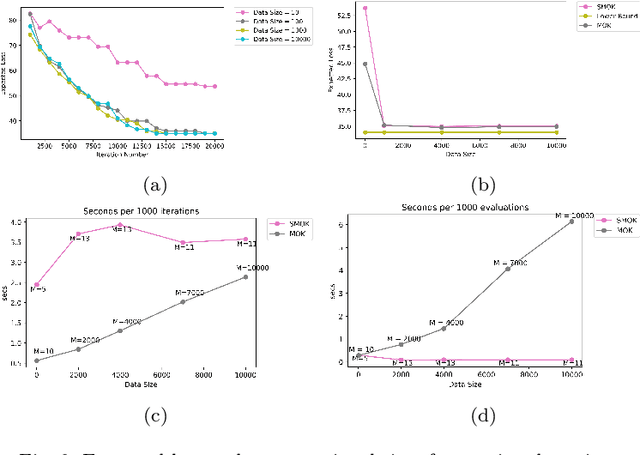

We develop a non-parametric, data-driven, tractable approach for solving multistage stochastic optimization problems in which decisions do not affect the uncertainty. The proposed framework represents the decision variables as elements of a reproducing kernel Hilbert space and performs functional stochastic gradient descent to minimize the empirical regularized loss. By incorporating sparsification techniques based on function subspace projections we are able to overcome the computational complexity that standard kernel methods introduce as the data size increases. We prove that the proposed approach is asymptotically optimal for multistage stochastic optimization with side information. Across various computational experiments on stochastic inventory management problems, {our method performs well in multidimensional settings} and remains tractable when the data size is large. Lastly, by computing lower bounds for the optimal loss of the inventory control problem, we show that the proposed method produces decision rules with near-optimal average performance.