 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Depth Correction of Lidar Measurements from Map Consistency Loss
Mar 02, 2023

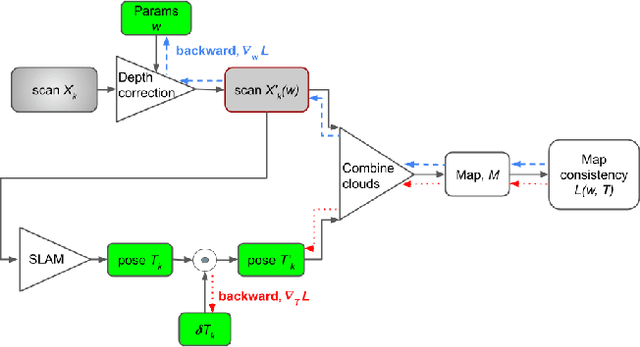
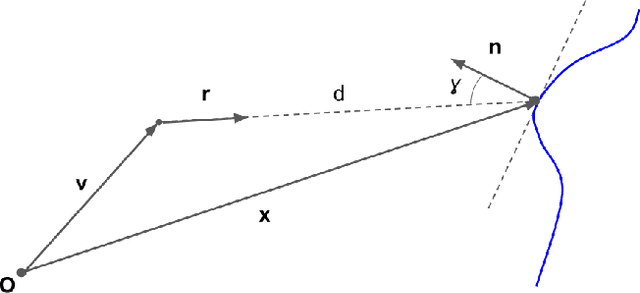

Depth perception is considered an invaluable source of information in the context of 3D mapping and various robotics applications. However, point cloud maps acquired using consumer-level light detection and ranging sensors (lidars) still suffer from bias related to local surface properties such as measuring beam-to-surface incidence angle, distance, texture, reflectance, or illumination conditions. This fact has recently motivated researchers to exploit traditional filters, as well as the deep learning paradigm, in order to suppress the aforementioned depth sensors error while preserving geometric and map consistency details. Despite the effort, depth correction of lidar measurements is still an open challenge mainly due to the lack of clean 3D data that could be used as ground truth. In this paper, we introduce two novel point cloud map consistency losses, which facilitate self-supervised learning on real data of lidar depth correction models. Specifically, the models exploit multiple point cloud measurements of the same scene from different view-points in order to learn to reduce the bias based on the constructed map consistency signal. Complementary to the removal of the bias from the measurements, we demonstrate that the depth correction models help to reduce localization drift. Additionally, we release a data set that contains point cloud data captured in an indoor corridor environment with precise localization and ground truth mapping information.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 02, 2023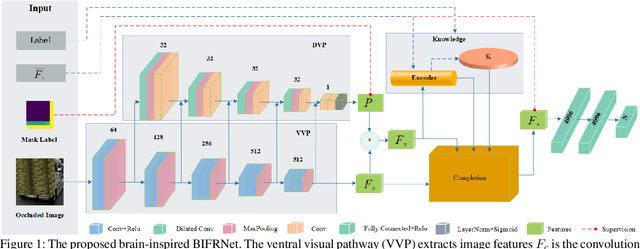


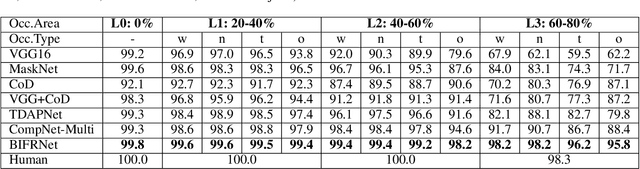
The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.
Assisting Human Decisions in Document Matching
Feb 16, 2023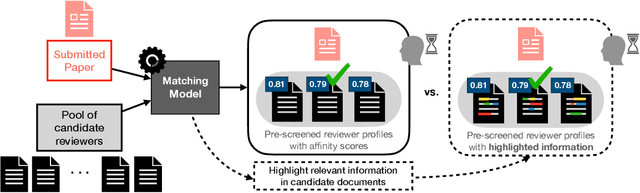

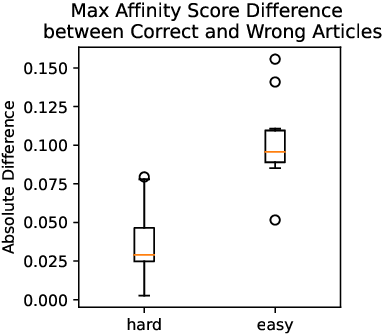
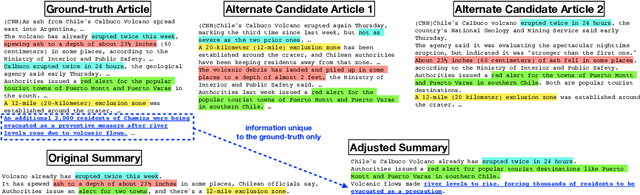
Many practical applications, ranging from paper-reviewer assignment in peer review to job-applicant matching for hiring, require human decision makers to identify relevant matches by combining their expertise with predictions from machine learning models. In many such model-assisted document matching tasks, the decision makers have stressed the need for assistive information about the model outputs (or the data) to facilitate their decisions. In this paper, we devise a proxy matching task that allows us to evaluate which kinds of assistive information improve decision makers' performance (in terms of accuracy and time). Through a crowdsourced (N=271 participants) study, we find that providing black-box model explanations reduces users' accuracy on the matching task, contrary to the commonly-held belief that they can be helpful by allowing better understanding of the model. On the other hand, custom methods that are designed to closely attend to some task-specific desiderata are found to be effective in improving user performance. Surprisingly, we also find that the users' perceived utility of assistive information is misaligned with their objective utility (measured through their task performance).
A new band selection approach based on information theory and support vector machine for hyperspectral images reduction and classification
Oct 26, 2022
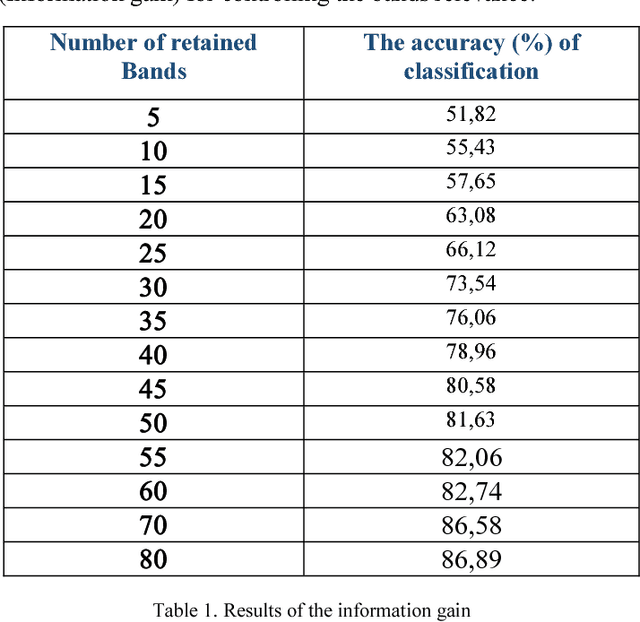
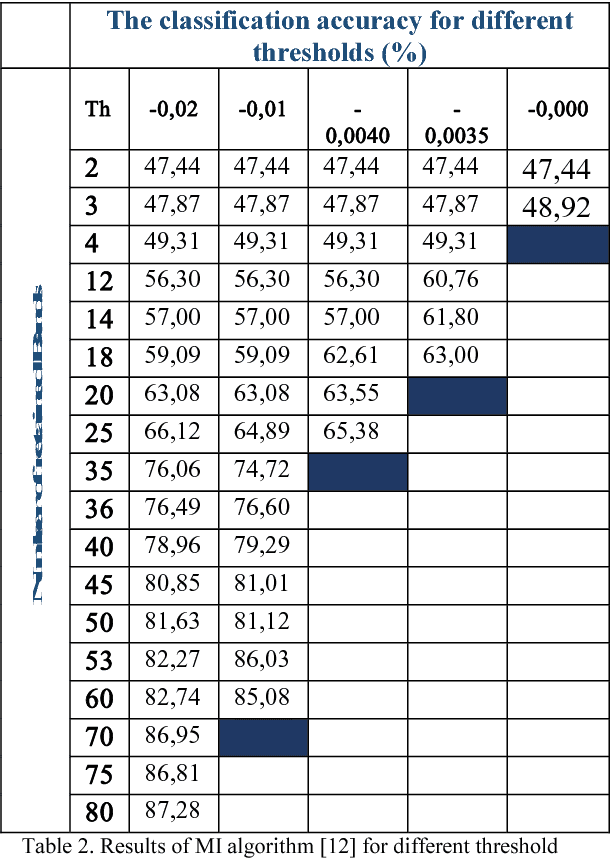
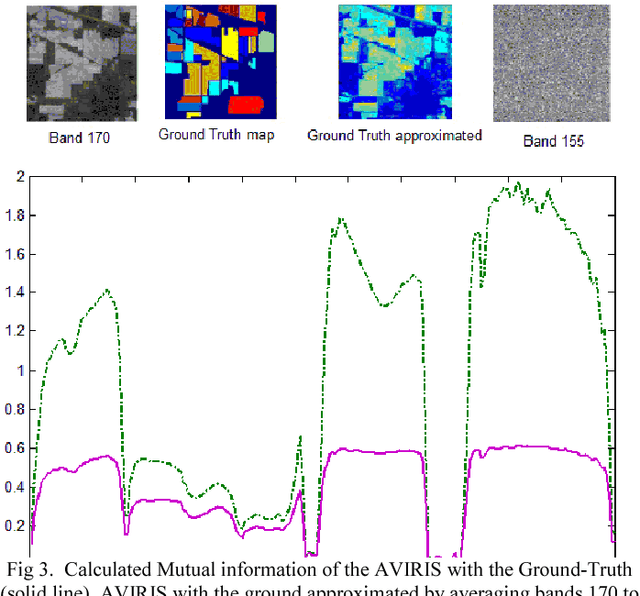
The high dimensionality of hyperspectral images consisting of several bands often imposes a big computational challenge for image processing. Therefore, spectral band selection is an essential step for removing the irrelevant, noisy and redundant bands. Consequently increasing the classification accuracy. However, identification of useful bands from hundreds or even thousands of related bands is a nontrivial task. This paper aims at identifying a small set of highly discriminative bands, for improving computational speed and prediction accuracy. Hence, we proposed a new strategy based on joint mutual information to measure the statistical dependence and correlation between the selected bands and evaluate the relative utility of each one to classification. The proposed filter approach is compared to an effective reproduced filters based on mutual information. Simulations results on the hyperpectral image HSI AVIRIS 92AV3C using the SVM classifier have shown that the effective proposed algorithm outperforms the reproduced filters strategy performance. Keywords-Hyperspectral images, Classification, band Selection, Joint Mutual Information, dimensionality reduction ,correlation, SVM.
GaIA: Graphical Information Gain based Attention Network for Weakly Supervised Point Cloud Semantic Segmentation
Oct 02, 2022
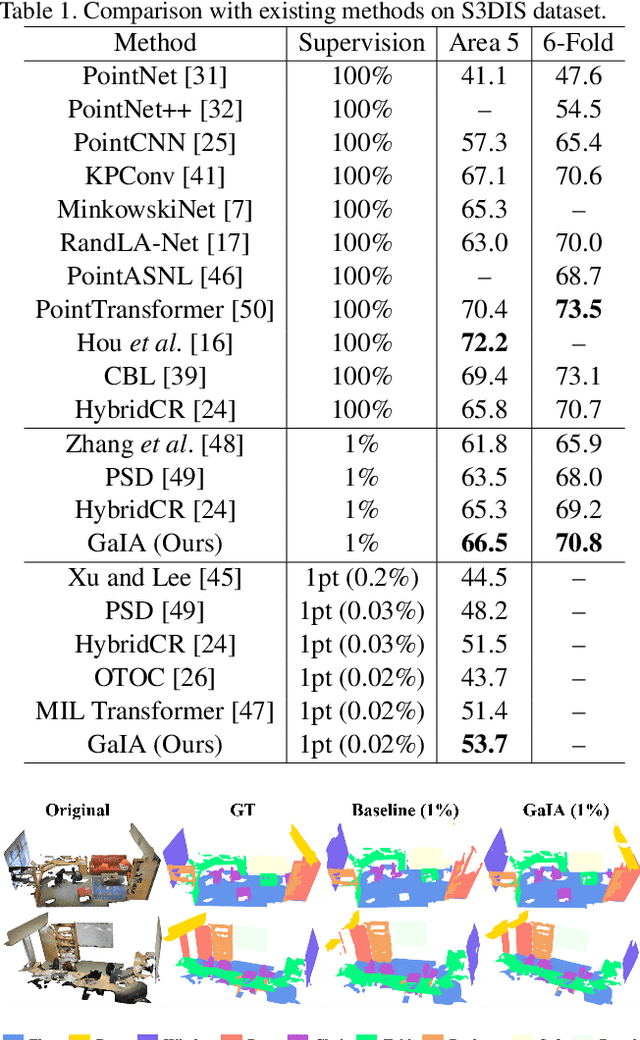
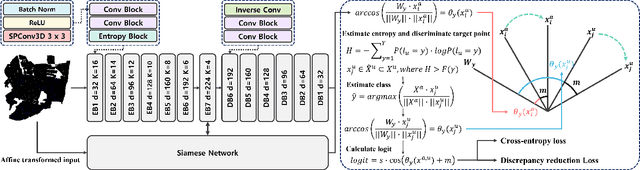
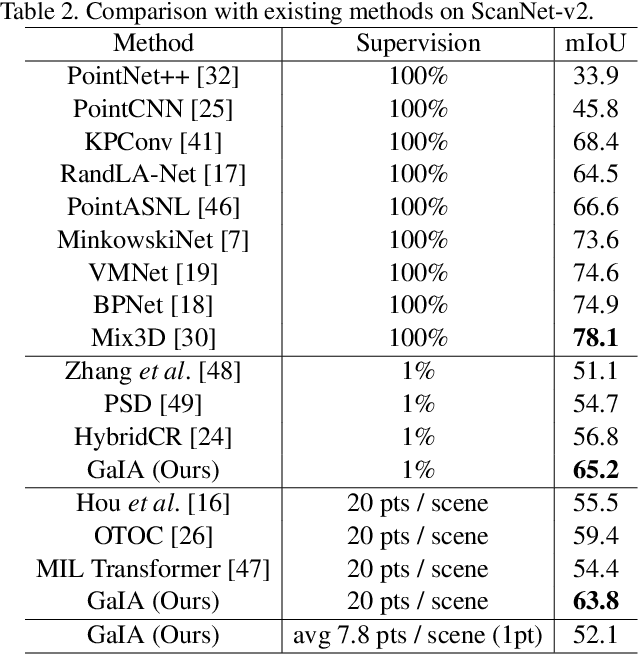
While point cloud semantic segmentation is a significant task in 3D scene understanding, this task demands a time-consuming process of fully annotating labels. To address this problem, recent studies adopt a weakly supervised learning approach under the sparse annotation. Different from the existing studies, this study aims to reduce the epistemic uncertainty measured by the entropy for a precise semantic segmentation. We propose the graphical information gain based attention network called GaIA, which alleviates the entropy of each point based on the reliable information. The graphical information gain discriminates the reliable point by employing relative entropy between target point and its neighborhoods. We further introduce anchor-based additive angular margin loss, ArcPoint. The ArcPoint optimizes the unlabeled points containing high entropy towards semantically similar classes of the labeled points on hypersphere space. Experimental results on S3DIS and ScanNet-v2 datasets demonstrate our framework outperforms the existing weakly supervised methods. We have released GaIA at https://github.com/Karel911/GaIA.
Semantic segmentation of surgical hyperspectral images under geometric domain shifts
Mar 20, 2023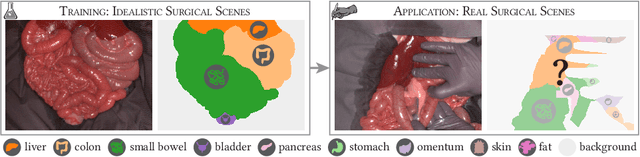
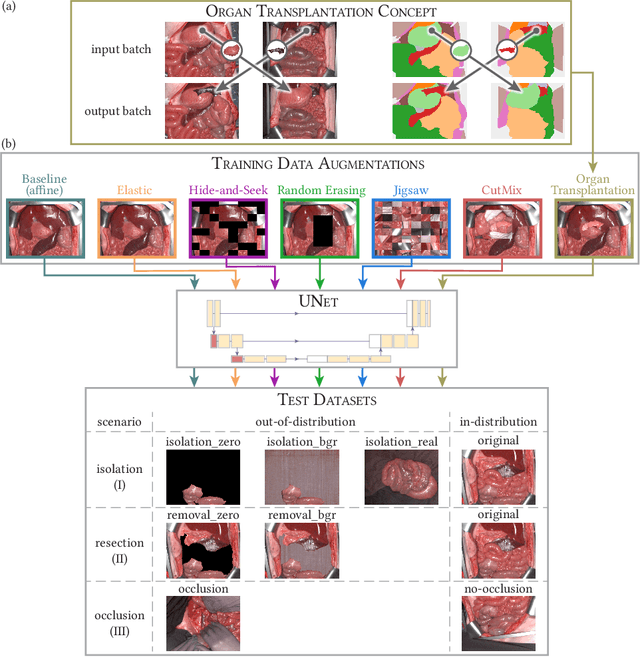
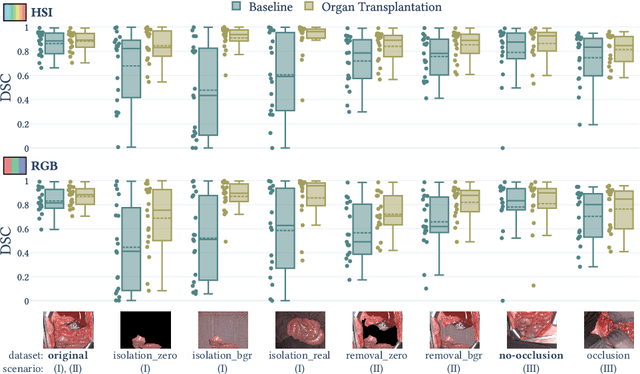
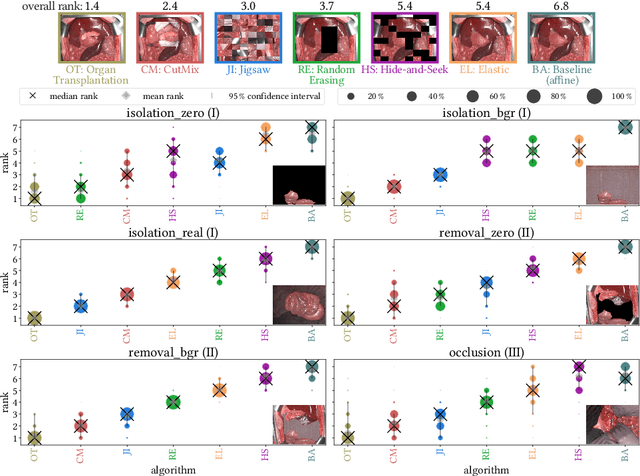
Robust semantic segmentation of intraoperative image data could pave the way for automatic surgical scene understanding and autonomous robotic surgery. Geometric domain shifts, however, although common in real-world open surgeries due to variations in surgical procedures or situs occlusions, remain a topic largely unaddressed in the field. To address this gap in the literature, we (1) present the first analysis of state-of-the-art (SOA) semantic segmentation networks in the presence of geometric out-of-distribution (OOD) data, and (2) address generalizability with a dedicated augmentation technique termed "Organ Transplantation" that we adapted from the general computer vision community. According to a comprehensive validation on six different OOD data sets comprising 600 RGB and hyperspectral imaging (HSI) cubes from 33 pigs semantically annotated with 19 classes, we demonstrate a large performance drop of SOA organ segmentation networks applied to geometric OOD data. Surprisingly, this holds true not only for conventional RGB data (drop of Dice similarity coefficient (DSC) by 46 %) but also for HSI data (drop by 45 %), despite the latter's rich information content per pixel. Using our augmentation scheme improves on the SOA DSC by up to 67 % (RGB) and 90 % (HSI) and renders performance on par with in-distribution performance on real OOD test data. The simplicity and effectiveness of our augmentation scheme makes it a valuable network-independent tool for addressing geometric domain shifts in semantic scene segmentation of intraoperative data. Our code and pre-trained models will be made publicly available.
MedLocker: A Transferable Adversarial Watermarking for Preventing Unauthorized Analysis of Medical Image Dataset
Mar 20, 2023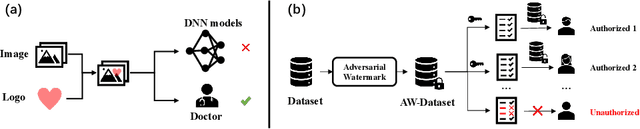
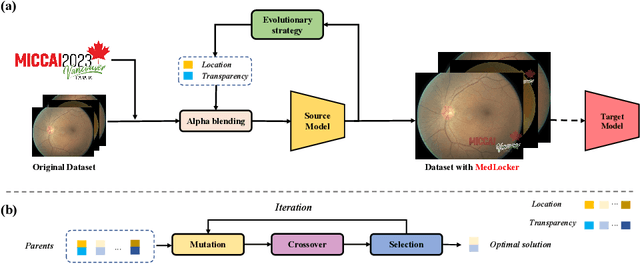
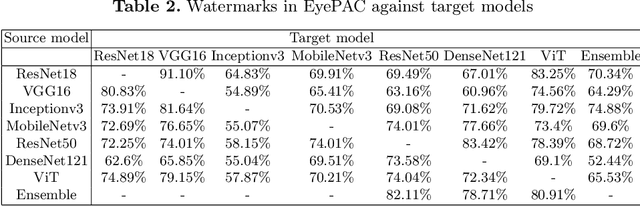

The collection of medical image datasets is a demanding and laborious process that requires significant resources. Furthermore, these medical datasets may contain personally identifiable information, necessitating measures to ensure that unauthorized access is prevented. Failure to do so could violate the intellectual property rights of the dataset owner and potentially compromise the privacy of patients. As a result, safeguarding medical datasets and preventing unauthorized usage by AI diagnostic models is a pressing challenge. To address this challenge, we propose a novel visible adversarial watermarking method for medical image copyright protection, called MedLocker. Our approach involves continuously optimizing the position and transparency of a watermark logo, which reduces the performance of the target model, leading to incorrect predictions. Importantly, we ensure that our method minimizes the impact on clinical visualization by constraining watermark positions using semantical masks (WSM), which are bounding boxes of lesion regions based on semantic segmentation. To ensure the transferability of the watermark across different models, we verify the cross-model transferability of the watermark generated on a single model. Additionally, we generate a unique watermark parameter list each time, which can be used as a certification to verify the authorization. We evaluate the performance of MedLocker on various mainstream backbones and validate the feasibility of adversarial watermarking for copyright protection on two widely-used diabetic retinopathy detection datasets. Our results demonstrate that MedLocker can effectively protect the copyright of medical datasets and prevent unauthorized users from analyzing medical images with AI diagnostic models.
Learning Behavior Recognition in Smart Classroom with Multiple Students Based on YOLOv5
Mar 20, 2023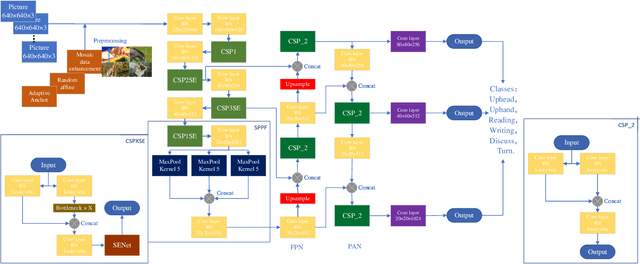
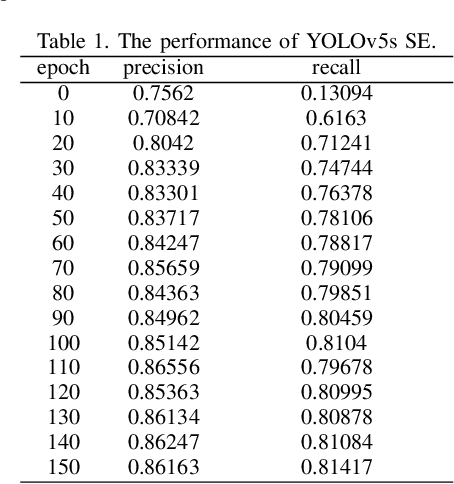
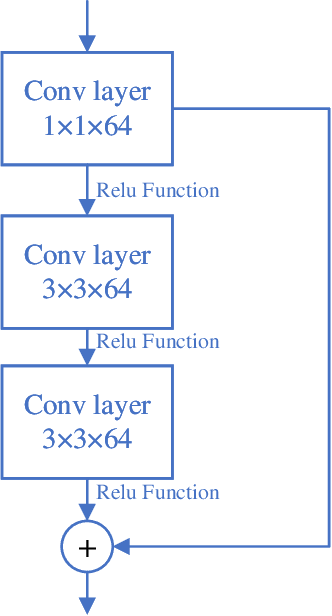
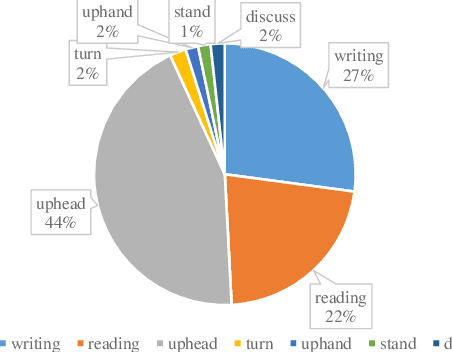
Deep learning-based computer vision technology has grown stronger in recent years, and cross-fertilization using computer vision technology has been a popular direction in recent years. The use of computer vision technology to identify students' learning behavior in the classroom can reduce the workload of traditional teachers in supervising students in the classroom, and ensure greater accuracy and comprehensiveness. However, existing student learning behavior detection systems are unable to track and detect multiple targets precisely, and the accuracy of learning behavior recognition is not high enough to meet the existing needs for the accurate recognition of student behavior in the classroom. To solve this problem, we propose a YOLOv5s network structure based on you only look once (YOLO) algorithm to recognize and analyze students' classroom behavior in this paper. Firstly, the input images taken in the smart classroom are pre-processed. Then, the pre-processed image is fed into the designed YOLOv5 networks to extract deep features through convolutional layers, and the Squeeze-and-Excitation (SE) attention detection mechanism is applied to reduce the weight of background information in the recognition process. Finally, the extracted features are classified by the Feature Pyramid Networks (FPN) and Path Aggregation Network (PAN) structures. Multiple groups of experiments were performed to compare with traditional learning behavior recognition methods to validate the effectiveness of the proposed method. When compared with YOLOv4, the proposed method is able to improve the mAP performance by 11%.
Induced Feature Selection by Structured Pruning
Mar 20, 2023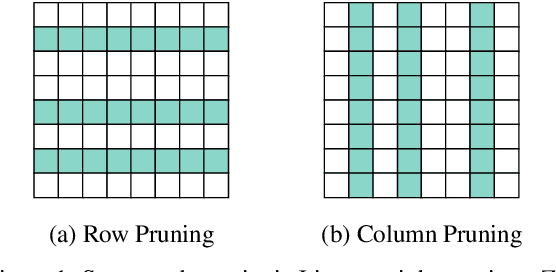
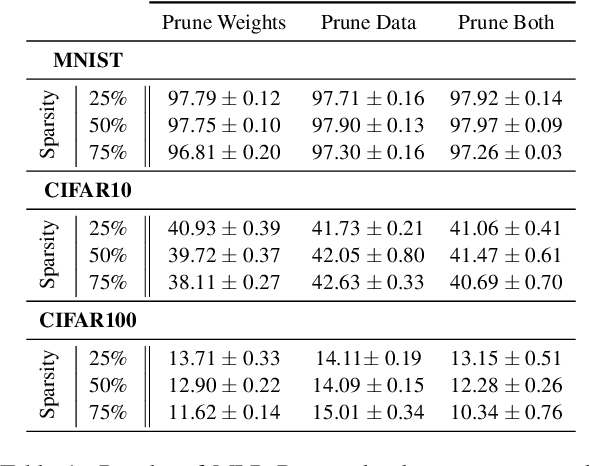
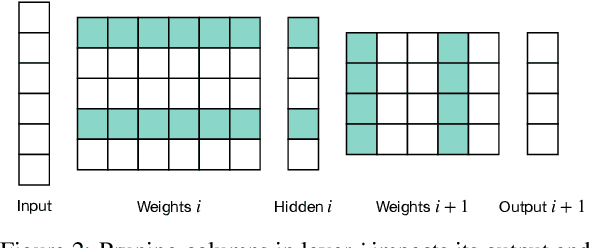
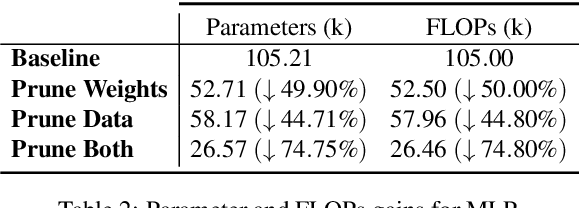
The advent of sparsity inducing techniques in neural networks has been of a great help in the last few years. Indeed, those methods allowed to find lighter and faster networks, able to perform more efficiently in resource-constrained environment such as mobile devices or highly requested servers. Such a sparsity is generally imposed on the weights of neural networks, reducing the footprint of the architecture. In this work, we go one step further by imposing sparsity jointly on the weights and on the input data. This can be achieved following a three-step process: 1) impose a certain structured sparsity on the weights of the network; 2) track back input features corresponding to zeroed blocks of weight; 3) remove useless weights and input features and retrain the network. Performing pruning both on the network and on input data not only allows for extreme reduction in terms of parameters and operations but can also serve as an interpretation process. Indeed, with the help of data pruning, we now have information about which input feature is useful for the network to keep its performance. Experiments conducted on a variety of architectures and datasets: MLP validated on MNIST, CIFAR10/100 and ConvNets (VGG16 and ResNet18), validated on CIFAR10/100 and CALTECH101 respectively, show that it is possible to achieve additional gains in terms of total parameters and in FLOPs by performing pruning on input data, while also increasing accuracy.
Uncertainty-aware deep learning for digital twin-driven monitoring: Application to fault detection in power lines
Mar 20, 2023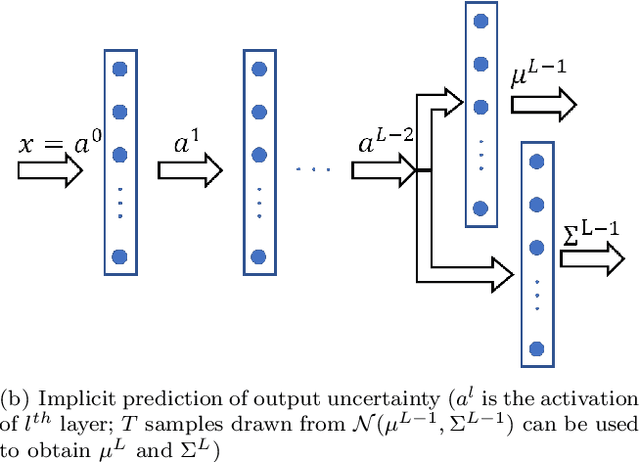
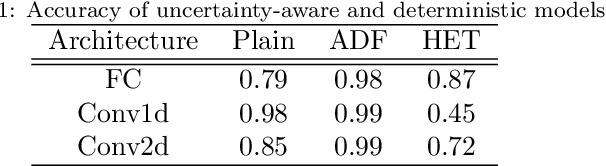
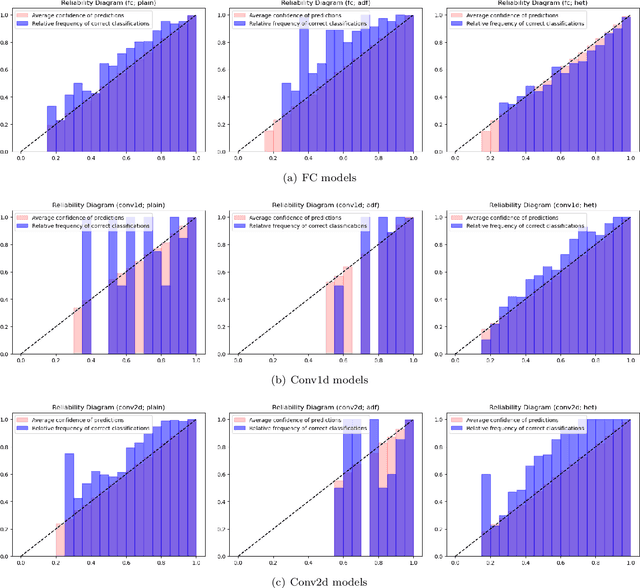
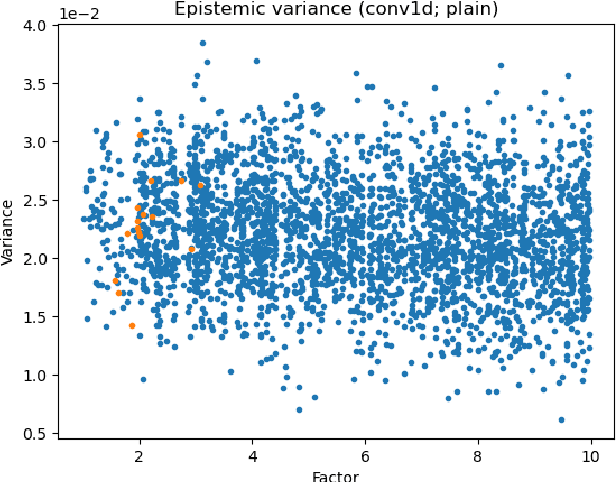
Deep neural networks (DNNs) are often coupled with physics-based models or data-driven surrogate models to perform fault detection and health monitoring of systems in the low data regime. These models serve as digital twins to generate large quantities of data to train DNNs which would otherwise be difficult to obtain from the real-life system. However, such models can exhibit parametric uncertainty that propagates to the generated data. In addition, DNNs exhibit uncertainty in the parameters learnt during training. In such a scenario, the performance of the DNN model will be influenced by the uncertainty in the physics-based model as well as the parameters of the DNN. In this article, we quantify the impact of both these sources of uncertainty on the performance of the DNN. We perform explicit propagation of uncertainty in input data through all layers of the DNN, as well as implicit prediction of output uncertainty to capture the former. Furthermore, we adopt Monte Carlo dropout to capture uncertainty in DNN parameters. We demonstrate the approach for fault detection of power lines with a physics-based model, two types of input data and three different neural network architectures. We compare the performance of such uncertainty-aware probabilistic models with their deterministic counterparts. The results show that the probabilistic models provide important information regarding the confidence of predictions, while also delivering an improvement in performance over deterministic models.