 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Attention Flow Fields for Dynamic Scene Decomposition
Mar 02, 2023
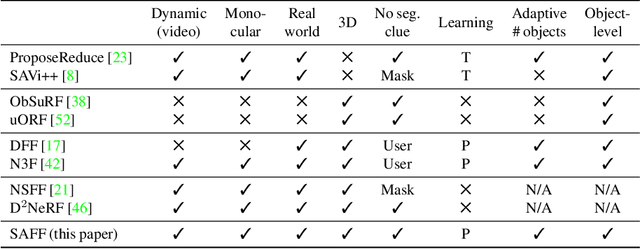
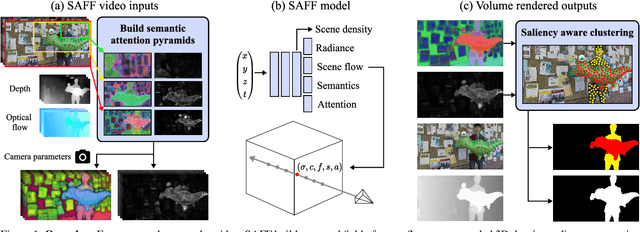
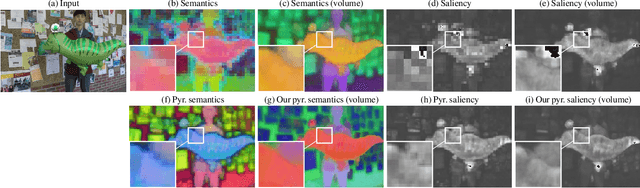
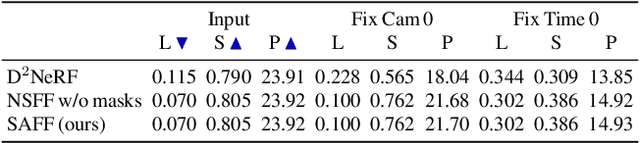
We present SAFF: a dynamic neural volume reconstruction of a casual monocular video that consists of time-varying color, density, scene flow, semantics, and attention information. The semantics and attention let us identify salient foreground objects separately from the background in arbitrary spacetime views. We add two network heads to represent the semantic and attention information. For optimization, we design semantic attention pyramids from DINO-ViT outputs that trade detail with whole-image context. After optimization, we perform a saliency-aware clustering to decompose the scene. For evaluation on real-world dynamic scene decomposition across spacetime, we annotate object masks in the NVIDIA Dynamic Scene Dataset. We demonstrate that SAFF can decompose dynamic scenes without affecting RGB or depth reconstruction quality, that volume-integrated SAFF outperforms 2D baselines, and that SAFF improves foreground/background segmentation over recent static/dynamic split methods. Project Webpage: https://visual.cs.brown.edu/saff
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 19, 2023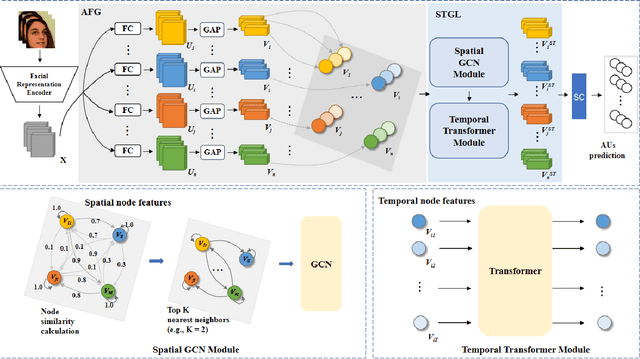

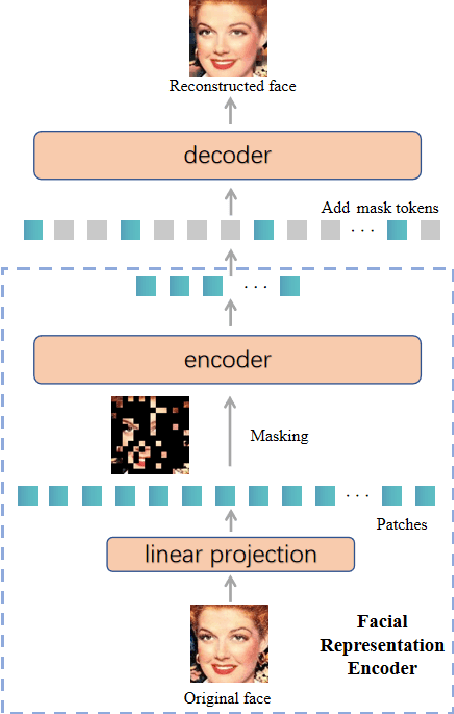

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows the model to generate the best results among all ablation systems.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023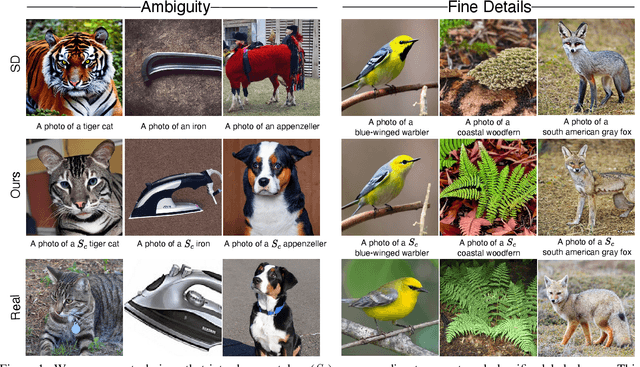
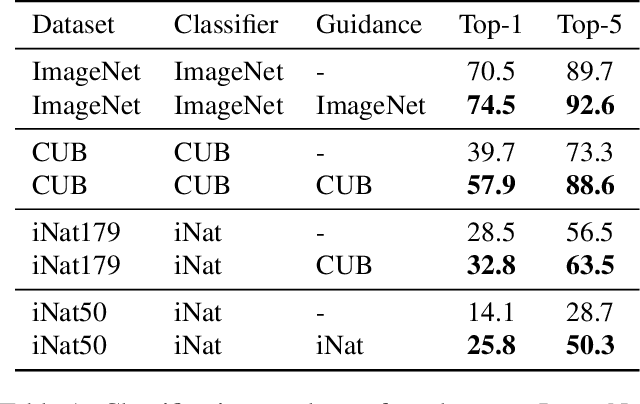
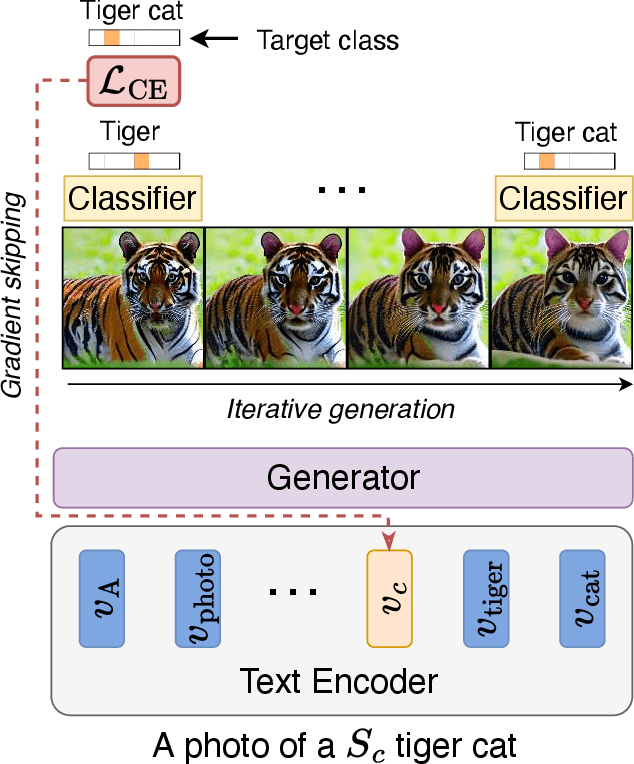
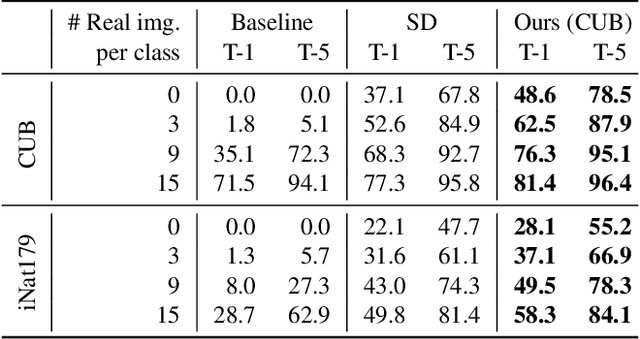
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Generating Accurate Virtual Examples For Lifelong Machine Learning
Feb 28, 2023Lifelong machine learning (LML) is an area of machine learning research concerned with human-like persistent and cumulative nature of learning. LML system's objective is consolidating new information into an existing machine learning model without catastrophically disrupting the prior information. Our research addresses this LML retention problem for creating a knowledge consolidation network through task rehearsal without retaining the prior task's training examples. We discovered that the training data reconstruction error from a trained Restricted Boltzmann Machine can be successfully used to generate accurate virtual examples from the reconstructed set of a uniform random set of examples given to the trained model. We also defined a measure for comparing the probability distributions of two datasets given to a trained network model based on their reconstruction mean square errors.
* 4 pages, Canadian AI GSS 2019
Document Flattening: Beyond Concatenating Context for Document-Level Neural Machine Translation
Feb 16, 2023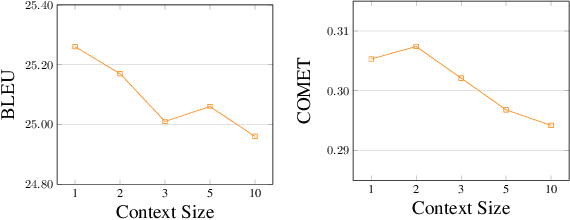
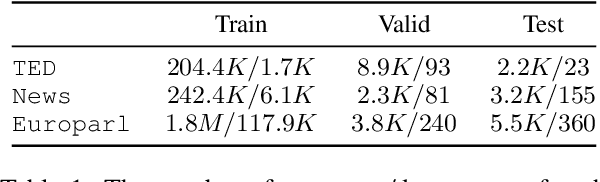
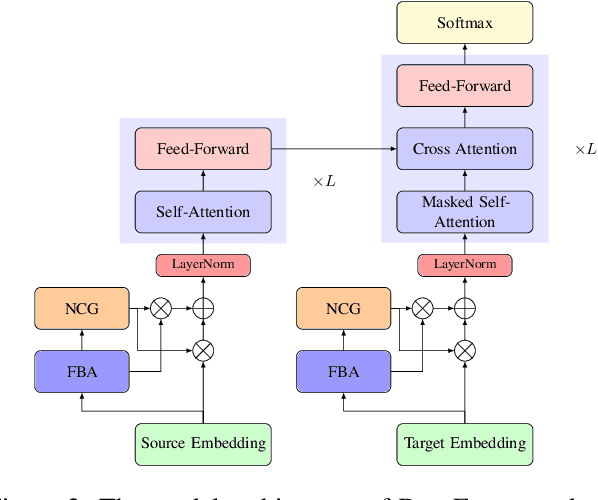
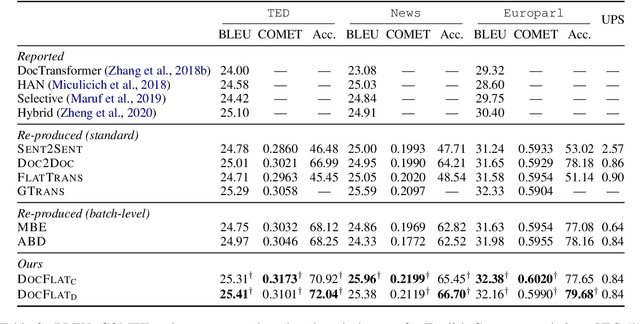
Existing work in document-level neural machine translation commonly concatenates several consecutive sentences as a pseudo-document, and then learns inter-sentential dependencies. This strategy limits the model's ability to leverage information from distant context. We overcome this limitation with a novel Document Flattening (DocFlat) technique that integrates Flat-Batch Attention (FBA) and Neural Context Gate (NCG) into Transformer model to utilize information beyond the pseudo-document boundaries. FBA allows the model to attend to all the positions in the batch and learns the relationships between positions explicitly and NCG identifies the useful information from the distant context. We conduct comprehensive experiments and analyses on three benchmark datasets for English-German translation, and validate the effectiveness of two variants of DocFlat. Empirical results show that our approach outperforms strong baselines with statistical significance on BLEU, COMET and accuracy on the contrastive test set. The analyses highlight that DocFlat is highly effective in capturing the long-range information.
MCIBI++: Soft Mining Contextual Information Beyond Image for Semantic Segmentation
Sep 09, 2022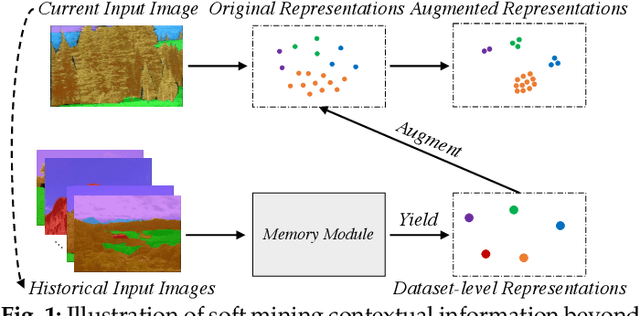

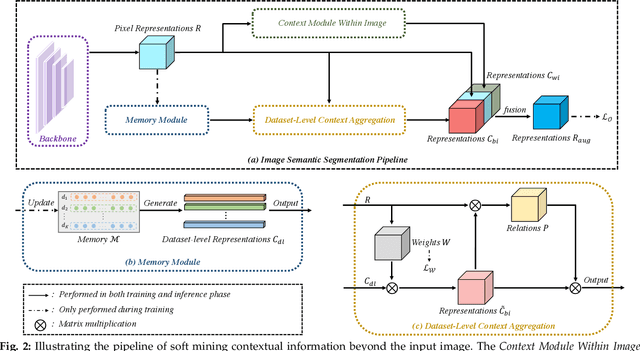
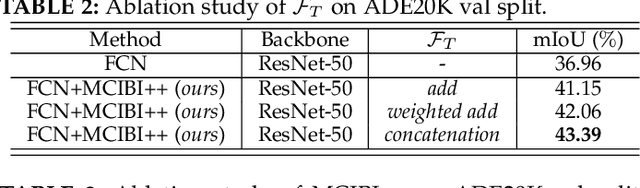
Co-occurrent visual pattern makes context aggregation become an essential paradigm for semantic segmentation.The existing studies focus on modeling the contexts within image while neglecting the valuable semantics of the corresponding category beyond image. To this end, we propose a novel soft mining contextual information beyond image paradigm named MCIBI++ to further boost the pixel-level representations. Specifically, we first set up a dynamically updated memory module to store the dataset-level distribution information of various categories and then leverage the information to yield the dataset-level category representations during network forward. After that, we generate a class probability distribution for each pixel representation and conduct the dataset-level context aggregation with the class probability distribution as weights. Finally, the original pixel representations are augmented with the aggregated dataset-level and the conventional image-level contextual information. Moreover, in the inference phase, we additionally design a coarse-to-fine iterative inference strategy to further boost the segmentation results. MCIBI++ can be effortlessly incorporated into the existing segmentation frameworks and bring consistent performance improvements. Also, MCIBI++ can be extended into the video semantic segmentation framework with considerable improvements over the baseline. Equipped with MCIBI++, we achieved the state-of-the-art performance on seven challenging image or video semantic segmentation benchmarks.
Neighborhood Contrastive Transformer for Change Captioning
Mar 06, 2023
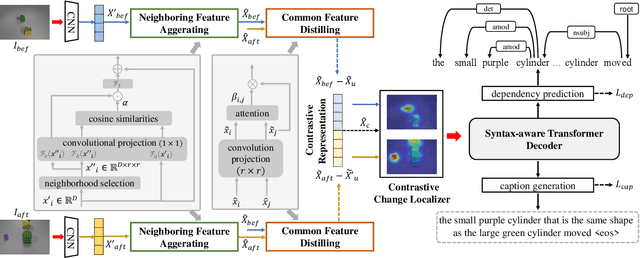
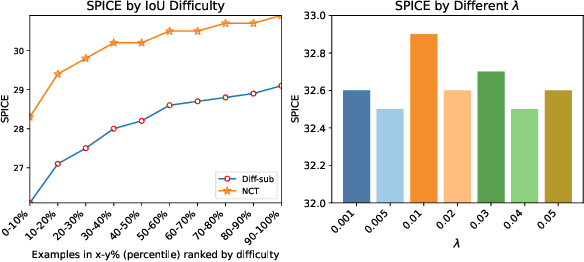
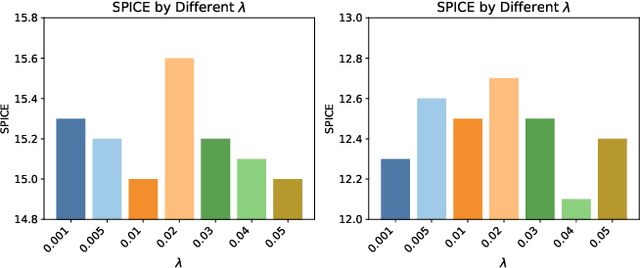
Change captioning is to describe the semantic change between a pair of similar images in natural language. It is more challenging than general image captioning, because it requires capturing fine-grained change information while being immune to irrelevant viewpoint changes, and solving syntax ambiguity in change descriptions. In this paper, we propose a neighborhood contrastive transformer to improve the model's perceiving ability for various changes under different scenes and cognition ability for complex syntax structure. Concretely, we first design a neighboring feature aggregating to integrate neighboring context into each feature, which helps quickly locate the inconspicuous changes under the guidance of conspicuous referents. Then, we devise a common feature distilling to compare two images at neighborhood level and extract common properties from each image, so as to learn effective contrastive information between them. Finally, we introduce the explicit dependencies between words to calibrate the transformer decoder, which helps better understand complex syntax structure during training. Extensive experimental results demonstrate that the proposed method achieves the state-of-the-art performance on three public datasets with different change scenarios. The code is available at https://github.com/tuyunbin/NCT.
Cutaneous Feedback Interface for Teleoperated In-Hand Manipulation
Mar 06, 2023
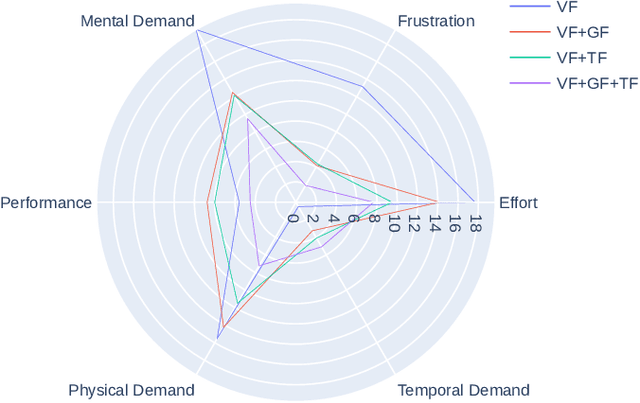
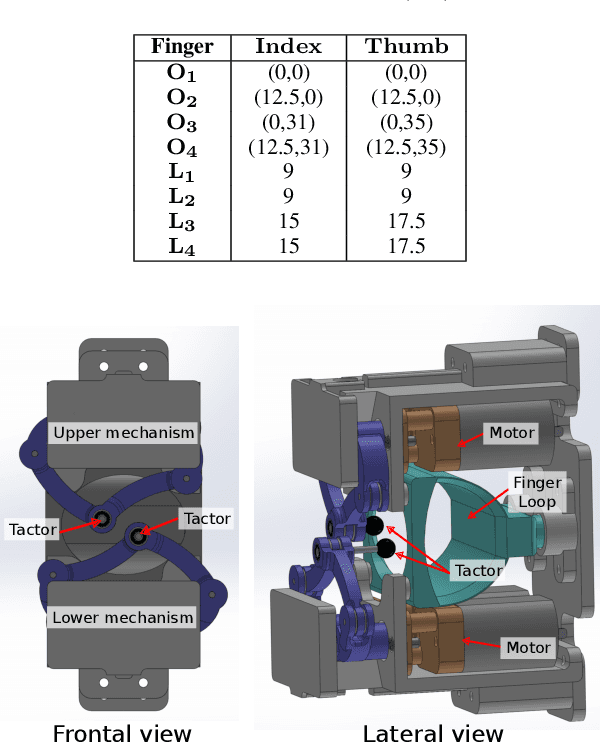
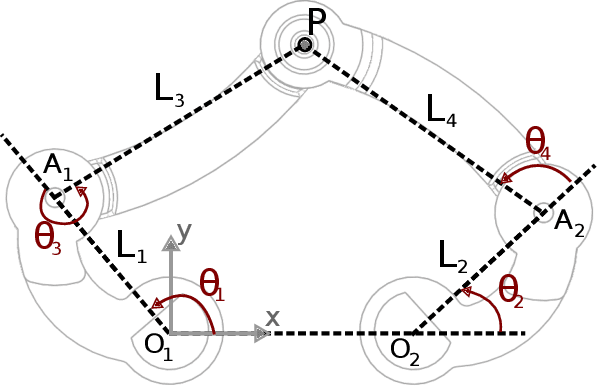
In-hand pivoting is one of the important manipulation skills that leverage robot grippers' extrinsic dexterity to perform repositioning tasks to compensate for environmental uncertainties and imprecise motion execution. Although many researchers have been trying to solve pivoting problems using mathematical modeling or learning-based approaches, the problems remain as open challenges. On the other hand, humans perform in-hand manipulation with remarkable precision and speed. Hence, the solution could be provided by making full use of this intrinsic human skill through dexterous teleoperation. For dexterous teleoperation to be successful, interfaces that enhance and complement haptic feedback are of great necessity. In this paper, we propose a cutaneous feedback interface that complements the somatosensory information humans rely on when performing dexterous skills. The interface is designed based on five-bar link mechanisms and provides two contact points in the index finger and thumb for cutaneous feedback. By integrating the interface with a commercially available haptic device, the system can display information such as grasping force, shear force, friction, and grasped object's pose. Passive pivoting tasks inside a numerical simulator Isaac Sim is conducted to evaluate the effect of the proposed cutaneous feedback interface.
* 7 pages, 10 figures, Accepted at 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Unleashing the Potential of Spiking Neural Networks by Dynamic Confidence
Mar 26, 2023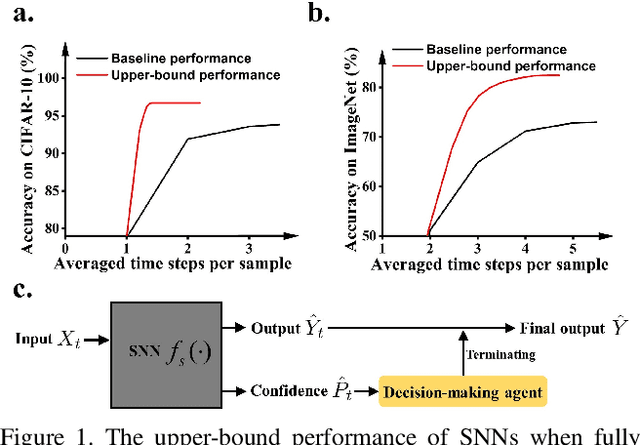
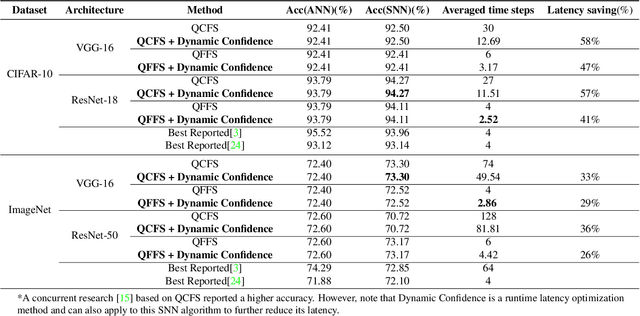
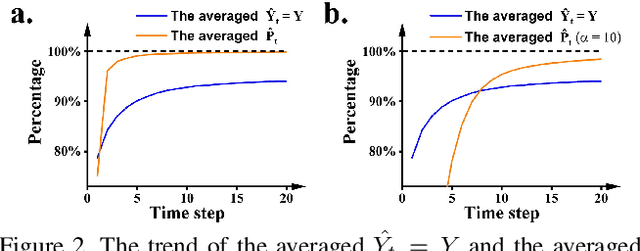
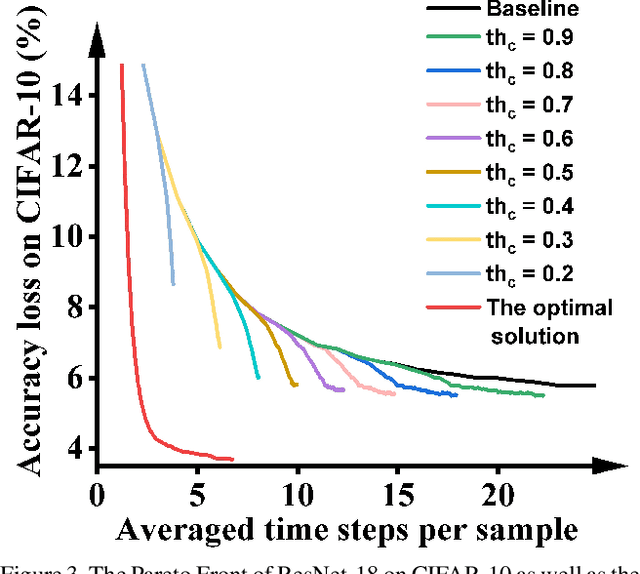
This paper presents a new methodology to alleviate the fundamental trade-off between accuracy and latency in spiking neural networks (SNNs). The approach involves decoding confidence information over time from the SNN outputs and using it to develop a decision-making agent that can dynamically determine when to terminate each inference. The proposed method, Dynamic Confidence, provides several significant benefits to SNNs. 1. It can effectively optimize latency dynamically at runtime, setting it apart from many existing low-latency SNN algorithms. Our experiments on CIFAR-10 and ImageNet datasets have demonstrated an average 40% speedup across eight different settings after applying Dynamic Confidence. 2. The decision-making agent in Dynamic Confidence is straightforward to construct and highly robust in parameter space, making it extremely easy to implement. 3. The proposed method enables visualizing the potential of any given SNN, which sets a target for current SNNs to approach. For instance, if an SNN can terminate at the most appropriate time point for each input sample, a ResNet-50 SNN can achieve an accuracy as high as 82.47% on ImageNet within just 4.71 time steps on average. Unlocking the potential of SNNs needs a highly-reliable decision-making agent to be constructed and fed with a high-quality estimation of ground truth. In this regard, Dynamic Confidence represents a meaningful step toward realizing the potential of SNNs.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023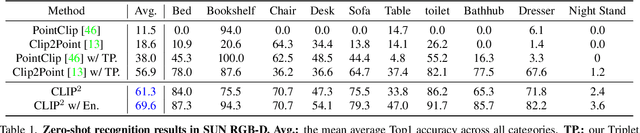
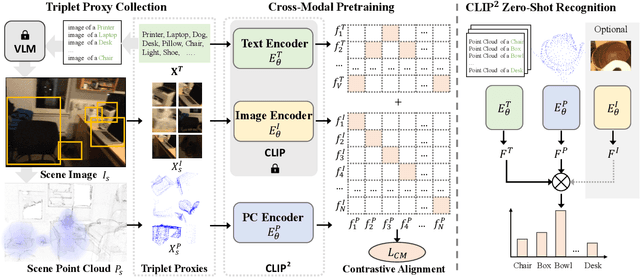

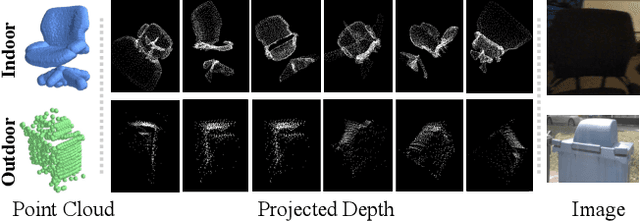
Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.