 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Accelerating Interface Adaptation with User-Friendly Priors
Mar 11, 2024
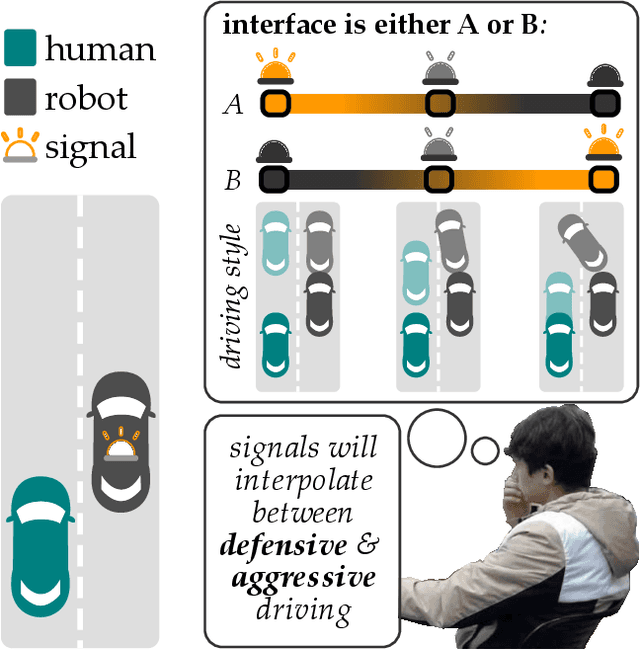
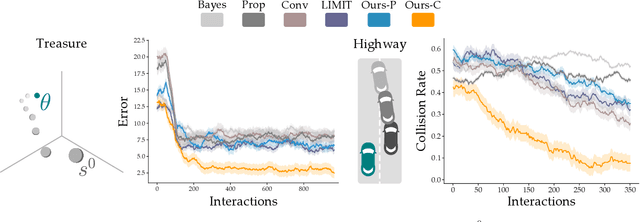
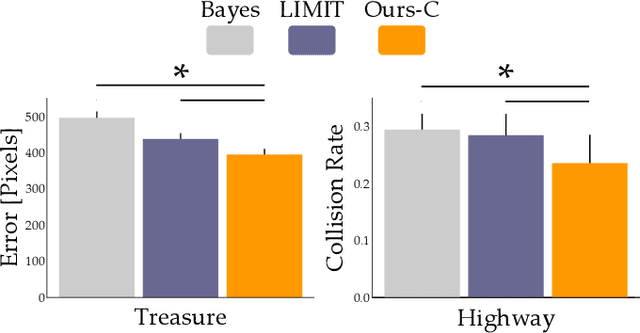
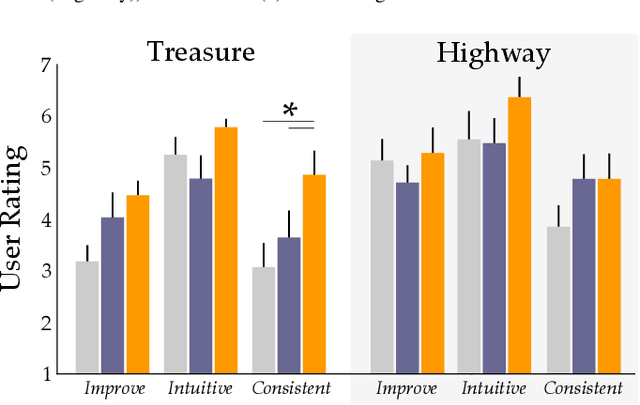
Robots often need to convey information to human users. For example, robots can leverage visual, auditory, and haptic interfaces to display their intent or express their internal state. In some scenarios there are socially agreed upon conventions for what these signals mean: e.g., a red light indicates an autonomous car is slowing down. But as robots develop new capabilities and seek to convey more complex data, the meaning behind their signals is not always mutually understood: one user might think a flashing light indicates the autonomous car is an aggressive driver, while another user might think the same signal means the autonomous car is defensive. In this paper we enable robots to adapt their interfaces to the current user so that the human's personalized interpretation is aligned with the robot's meaning. We start with an information theoretic end-to-end approach, which automatically tunes the interface policy to optimize the correlation between human and robot. But to ensure that this learning policy is intuitive -- and to accelerate how quickly the interface adapts to the human -- we recognize that humans have priors over how interfaces should function. For instance, humans expect interface signals to be proportional and convex. Our approach biases the robot's interface towards these priors, resulting in signals that are adapted to the current user while still following social expectations. Our simulations and user study results across $15$ participants suggest that these priors improve robot-to-human communication. See videos here: https://youtu.be/Re3OLg57hp8
Financial Default Prediction via Motif-preserving Graph Neural Network with Curriculum Learning
Mar 11, 2024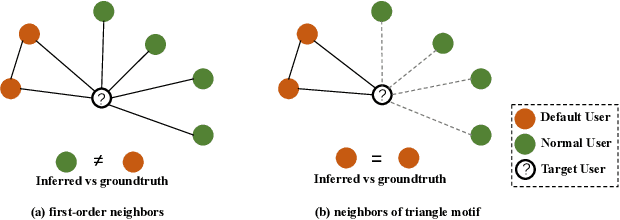
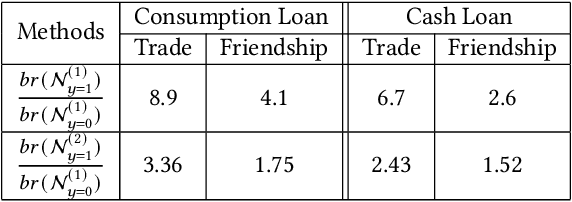
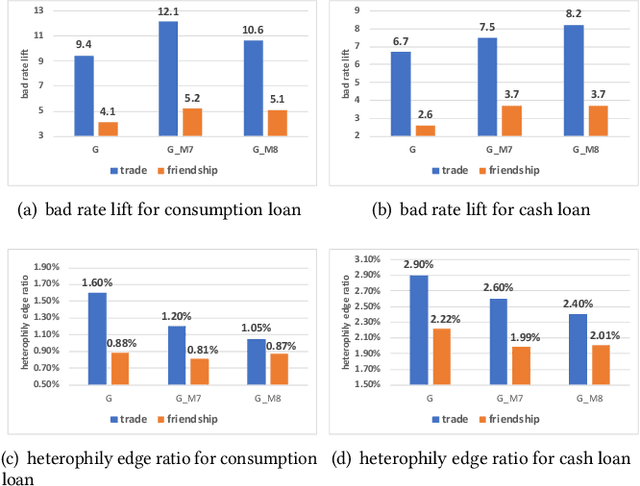
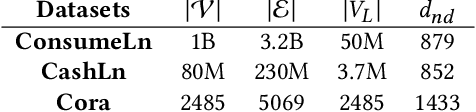
User financial default prediction plays a critical role in credit risk forecasting and management. It aims at predicting the probability that the user will fail to make the repayments in the future. Previous methods mainly extract a set of user individual features regarding his own profiles and behaviors and build a binary-classification model to make default predictions. However, these methods cannot get satisfied results, especially for users with limited information. Although recent efforts suggest that default prediction can be improved by social relations, they fail to capture the higher-order topology structure at the level of small subgraph patterns. In this paper, we fill in this gap by proposing a motif-preserving Graph Neural Network with curriculum learning (MotifGNN) to jointly learn the lower-order structures from the original graph and higherorder structures from multi-view motif-based graphs for financial default prediction. Specifically, to solve the problem of weak connectivity in motif-based graphs, we design the motif-based gating mechanism. It utilizes the information learned from the original graph with good connectivity to strengthen the learning of the higher-order structure. And considering that the motif patterns of different samples are highly unbalanced, we propose a curriculum learning mechanism on the whole learning process to more focus on the samples with uncommon motif distributions. Extensive experiments on one public dataset and two industrial datasets all demonstrate the effectiveness of our proposed method.
IEPile: Unearthing Large-Scale Schema-Based Information Extraction Corpus
Feb 22, 2024Large Language Models (LLMs) demonstrate remarkable potential across various domains; however, they exhibit a significant performance gap in Information Extraction (IE). Note that high-quality instruction data is the vital key for enhancing the specific capabilities of LLMs, while current IE datasets tend to be small in scale, fragmented, and lack standardized schema. To this end, we introduce IEPile, a comprehensive bilingual (English and Chinese) IE instruction corpus, which contains approximately 0.32B tokens. We construct IEPile by collecting and cleaning 33 existing IE datasets, and introduce schema-based instruction generation to unearth a large-scale corpus. Experimental results on LLaMA and Baichuan demonstrate that using IEPile can enhance the performance of LLMs for IE, especially the zero-shot generalization. We open-source the resource and pre-trained models, hoping to provide valuable support to the NLP community.
A Self-matching Training Method with Annotation Embedding Models for Ontology Subsumption Prediction
Mar 10, 2024Recently, ontology embeddings representing entities in a low-dimensional space have been proposed for ontology completion. However, the ontology embeddings for concept subsumption prediction do not address the difficulties of similar and isolated entities and fail to extract the global information of annotation axioms from an ontology. In this paper, we propose a self-matching training method for the two ontology embedding models: Inverted-index Matrix Embedding (InME) and Co-occurrence Matrix Embedding (CoME). The two embeddings capture the global and local information in annotation axioms by means of the occurring locations of each word in a set of axioms and the co-occurrences of words in each axiom. The self-matching training method increases the robustness of the concept subsumption prediction when predicted superclasses are similar to subclasses and are isolated to other entities in an ontology. Our evaluation experiments show that the self-matching training method with InME outperforms the existing ontology embeddings for the GO and FoodOn ontologies and that the method with the concatenation of CoME and OWL2Vec* outperforms them for the HeLiS ontology.
MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
Mar 13, 2024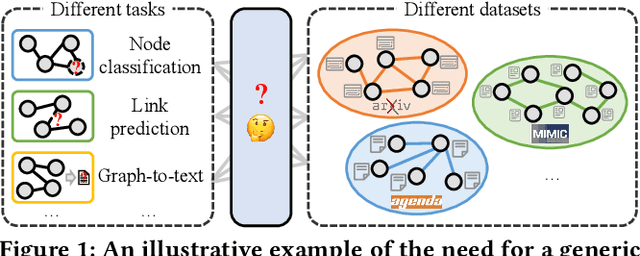
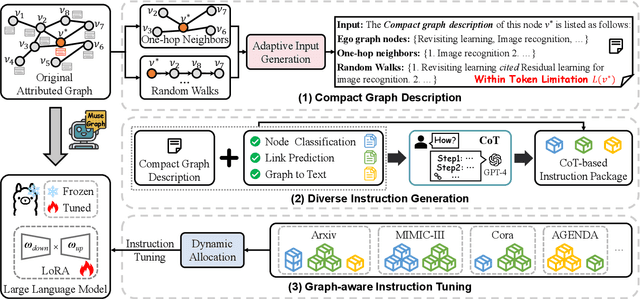
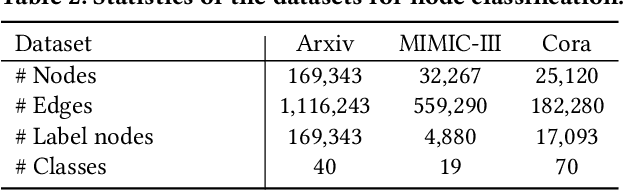
Graphs with abundant attributes are essential in modeling interconnected entities and improving predictions in various real-world applications. Traditional Graph Neural Networks (GNNs), which are commonly used for modeling attributed graphs, need to be re-trained every time when applied to different graph tasks and datasets. Although the emergence of Large Language Models (LLMs) has introduced a new paradigm in natural language processing, the generative potential of LLMs in graph mining remains largely under-explored. To this end, we propose a novel framework MuseGraph, which seamlessly integrates the strengths of GNNs and LLMs and facilitates a more effective and generic approach for graph mining across different tasks and datasets. Specifically, we first introduce a compact graph description via the proposed adaptive input generation to encapsulate key information from the graph under the constraints of language token limitations. Then, we propose a diverse instruction generation mechanism, which distills the reasoning capabilities from LLMs (e.g., GPT-4) to create task-specific Chain-of-Thought-based instruction packages for different graph tasks. Finally, we propose a graph-aware instruction tuning with a dynamic instruction package allocation strategy across tasks and datasets, ensuring the effectiveness and generalization of the training process. Our experimental results demonstrate significant improvements in different graph tasks, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while keeping the generation powers of LLMs.
Deep Learning based Positioning with Multi-task Learning and Uncertainty-based Fusion
Mar 13, 2024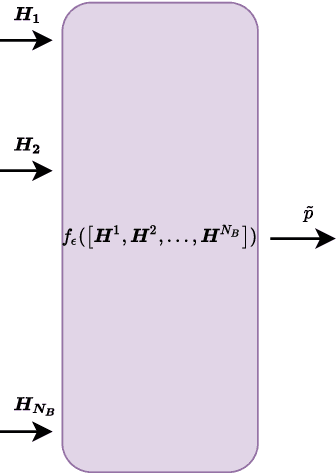
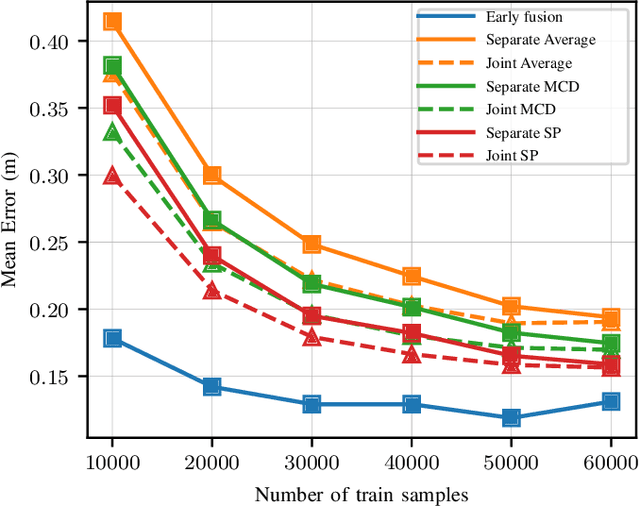
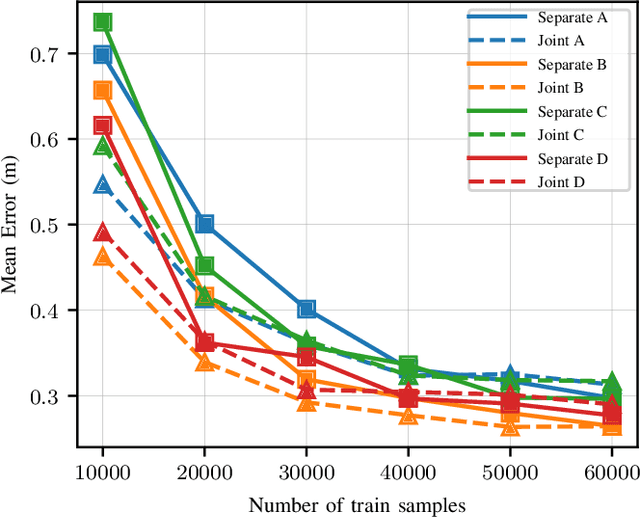
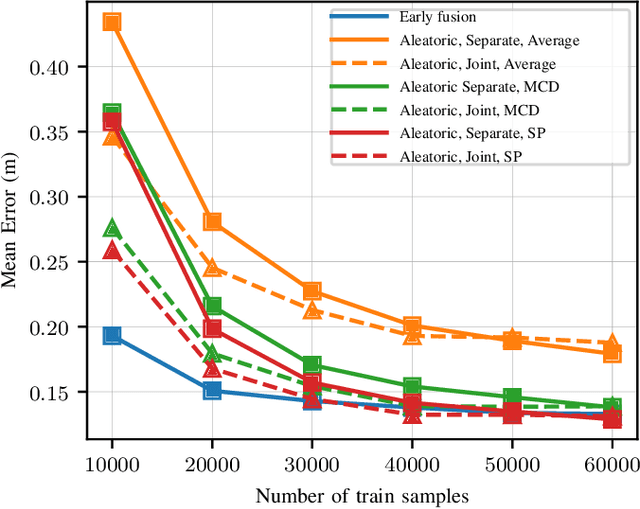
Deep learning (DL) methods have been shown to improve the performance of several use cases for the fifth-generation (5G) New radio (NR) air interface. In this paper we investigate user equipment (UE) positioning using the channel state information (CSI) fingerprints between a UE and multiple base stations (BSs). In such a setup, a single DL model can be trained for UE positioning using the CSI fingerprints of the multiple BSs as input. Alternatively, based on the CSI at each BS, a separate DL model can be trained at each BS and then the output of the different models are combined to determine the UE's position. In this work we compare these different fusion techniques and show that fusing the output of separate models achieves higher positioning accuracy, especially in a dynamic scenario. We also show that the fusion of multiple outputs further benefits from considering the uncertainty of the output of the DL model at each BS. For a more efficient training of the DL model across BSs, we additionally propose a multi-task learning (MTL) scheme by sharing some parameters across the models while jointly training all models. This method, not only improves the accuracy of the individual models, but also of the final combined estimate. Lastly, we evaluate the reliability of the uncertainty estimation to ascertain which of the fusion methods provides the highest quality of uncertainty estimates.
Prototyping and Experimental Results for Environment-Aware Millimeter Wave Beam Alignment via Channel Knowledge Map
Mar 13, 2024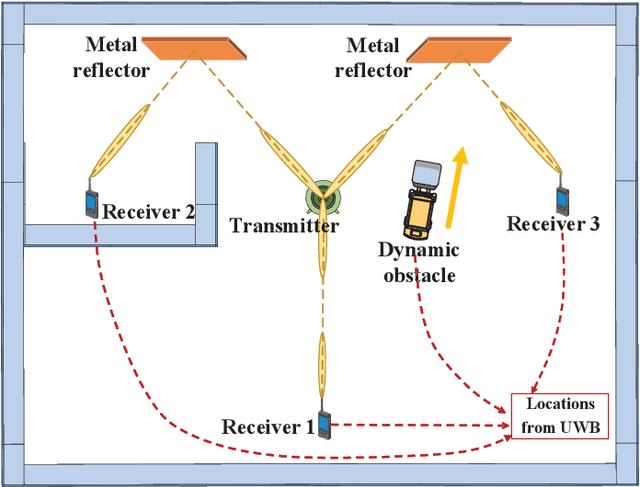
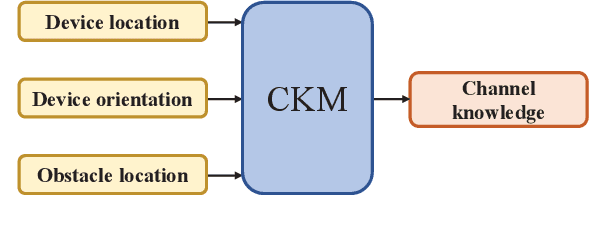
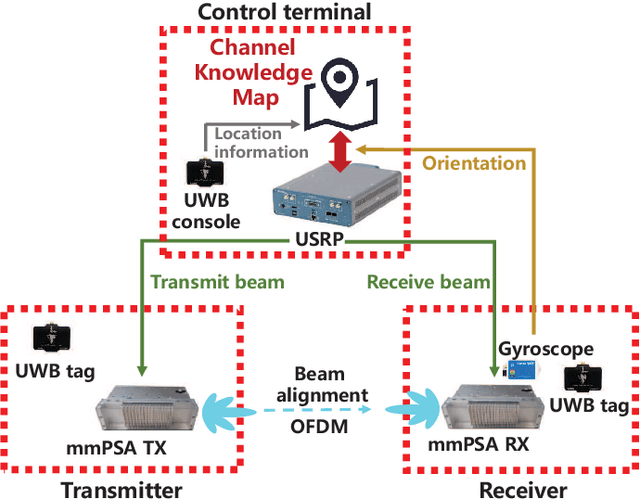
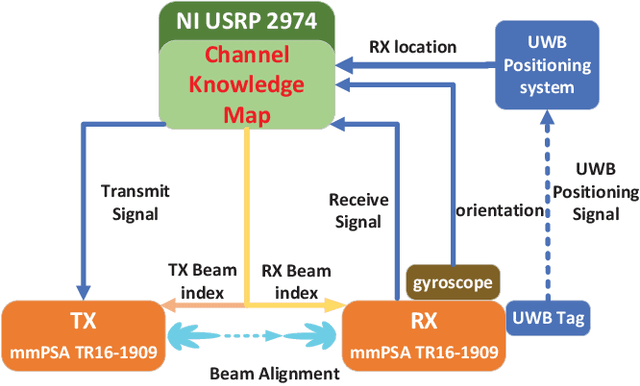
Channel knowledge map (CKM), which aims to directly reflect the intrinsic channel properties of the local wireless environment, is a novel technique for achieving environmentaware communication. In this paper, to alleviate the large training overhead in millimeter wave (mmWave) beam alignment, an environment-aware and training-free beam alignment prototype is established based on a typical CKM, termed beam index map (BIM). To this end, a general CKM construction method is first presented, and an indoor BIM is constructed offline to learn the candidate transmit and receive beam index pairs for each grid in the experimental area. Furthermore, based on the location information of the receiver (or the dynamic obstacles) from the ultra-wide band (UWB) positioning system, the established BIM is used to achieve training-free beam alignment by directly providing the beam indexes for the transmitter and receiver. Three typical scenarios are considered in the experiment, including quasi-static environment with line-of-sight (LoS) link, quasistatic environment without LoS link and dynamic environment. Besides, the receiver orientation measured from the gyroscope is also used to help CKM predict more accurate beam indexes. The experiment results show that compared with the benchmark location-based beam alignment strategy, the CKM-based beam alignment strategy can achieve much higher received power, which is close to that achieved by exhaustive beam search, but with significantly reduced training overhead.
Meta-Learning-Based Fronthaul Compression for Cloud Radio Access Networks
Mar 13, 2024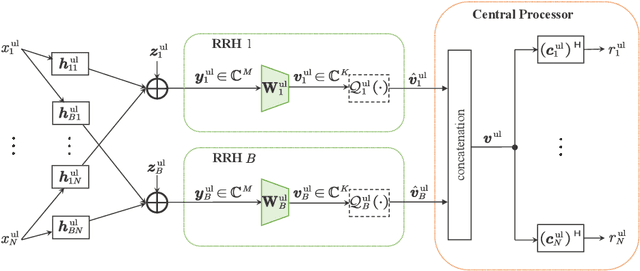
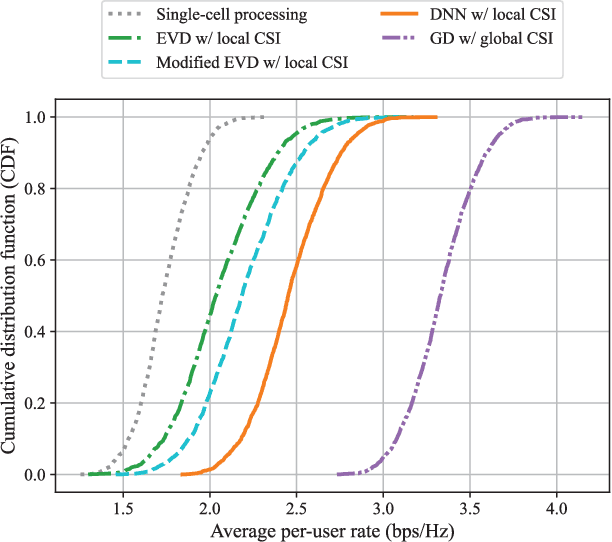
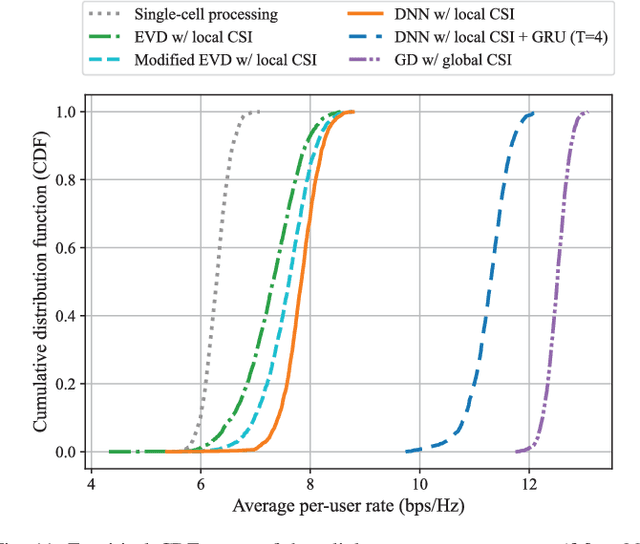
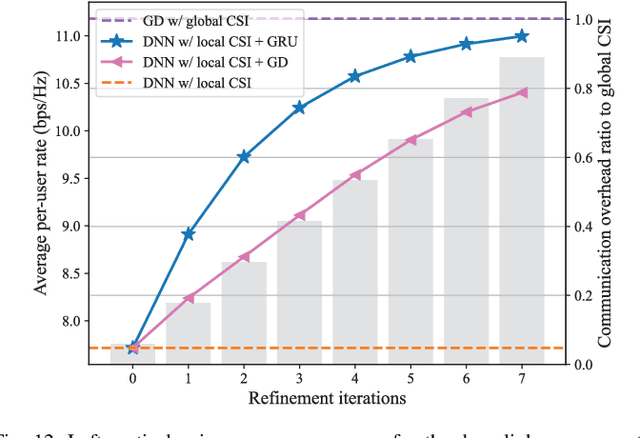
This paper investigates the fronthaul compression problem in a user-centric cloud radio access network, in which single-antenna users are served by a central processor (CP) cooperatively via a cluster of remote radio heads (RRHs). To satisfy the fronthaul capacity constraint, this paper proposes a transform-compress-forward scheme, which consists of well-designed transformation matrices and uniform quantizers. The transformation matrices perform dimension reduction in the uplink and dimension expansion in the downlink. To reduce the communication overhead for designing the transformation matrices, this paper further proposes a deep learning framework to first learn a suboptimal transformation matrix at each RRH based on the local channel state information (CSI), and then to refine it iteratively. To facilitate the refinement process, we propose an efficient signaling scheme that only requires the transmission of low-dimensional effective CSI and its gradient between the CP and RRH, and further, a meta-learning based gated recurrent unit network to reduce the number of signaling transmission rounds. For the sum-rate maximization problem, simulation results show that the proposed two-stage neural network can perform close to the fully cooperative global CSI based benchmark with significantly reduced communication overhead for both the uplink and the downlink. Moreover, using the first stage alone can already outperform the existing local CSI based benchmark.
SpeechColab Leaderboard: An Open-Source Platform for Automatic Speech Recognition Evaluation
Mar 13, 2024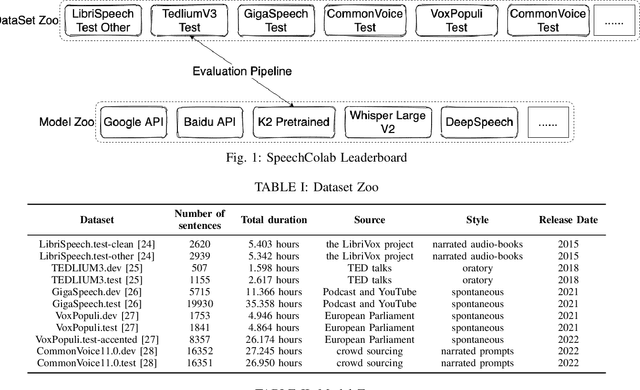
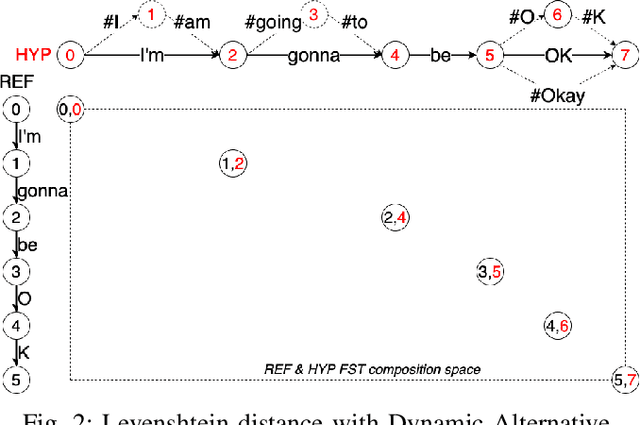
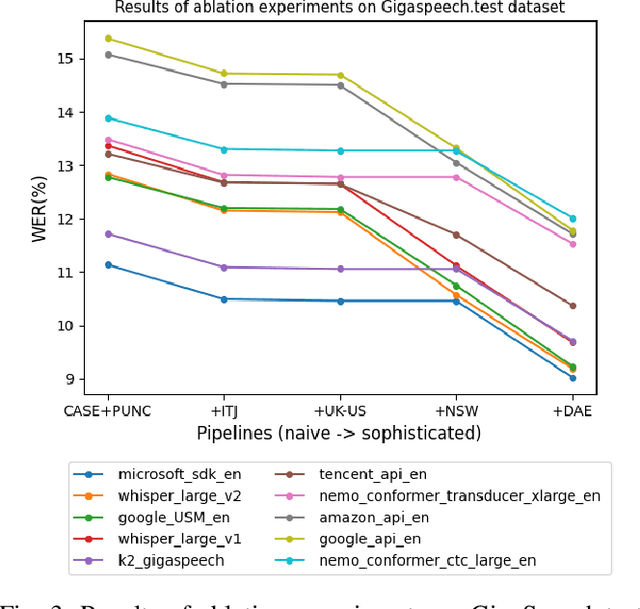

In the wake of the surging tide of deep learning over the past decade, Automatic Speech Recognition (ASR) has garnered substantial attention, leading to the emergence of numerous publicly accessible ASR systems that are actively being integrated into our daily lives. Nonetheless, the impartial and replicable evaluation of these ASR systems encounters challenges due to various crucial subtleties. In this paper we introduce the SpeechColab Leaderboard, a general-purpose, open-source platform designed for ASR evaluation. With this platform: (i) We report a comprehensive benchmark, unveiling the current state-of-the-art panorama for ASR systems, covering both open-source models and industrial commercial services. (ii) We quantize how distinct nuances in the scoring pipeline influence the final benchmark outcomes. These include nuances related to capitalization, punctuation, interjection, contraction, synonym usage, compound words, etc. These issues have gained prominence in the context of the transition towards an End-to-End future. (iii) We propose a practical modification to the conventional Token-Error-Rate (TER) evaluation metric, with inspirations from Kolmogorov complexity and Normalized Information Distance (NID). This adaptation, called modified-TER (mTER), achieves proper normalization and symmetrical treatment of reference and hypothesis. By leveraging this platform as a large-scale testing ground, this study demonstrates the robustness and backward compatibility of mTER when compared to TER. The SpeechColab Leaderboard is accessible at https://github.com/SpeechColab/Leaderboard
Memory-based Adapters for Online 3D Scene Perception
Mar 11, 2024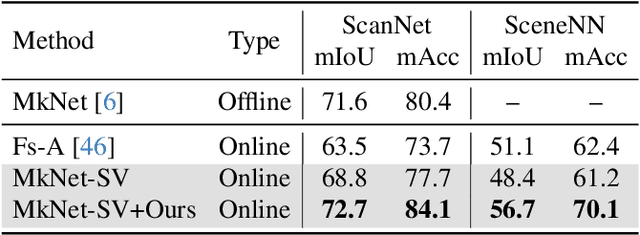
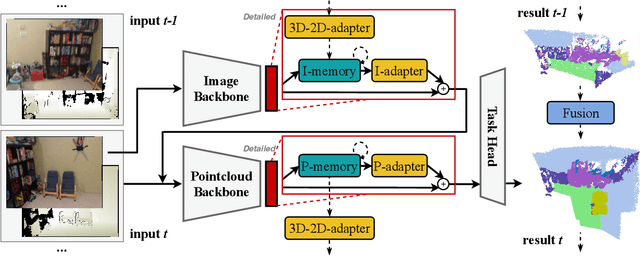
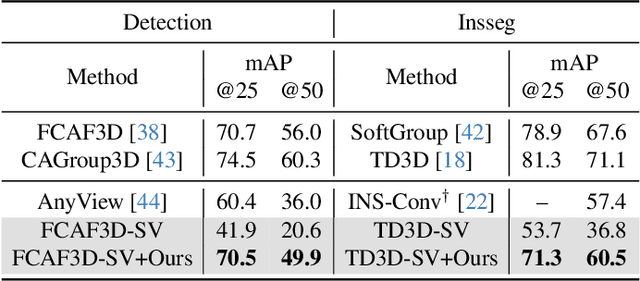
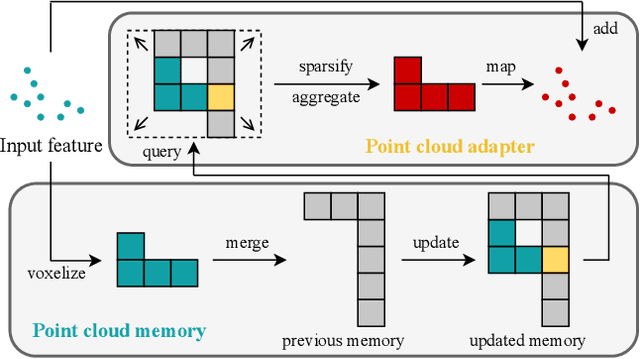
In this paper, we propose a new framework for online 3D scene perception. Conventional 3D scene perception methods are offline, i.e., take an already reconstructed 3D scene geometry as input, which is not applicable in robotic applications where the input data is streaming RGB-D videos rather than a complete 3D scene reconstructed from pre-collected RGB-D videos. To deal with online 3D scene perception tasks where data collection and perception should be performed simultaneously, the model should be able to process 3D scenes frame by frame and make use of the temporal information. To this end, we propose an adapter-based plug-and-play module for the backbone of 3D scene perception model, which constructs memory to cache and aggregate the extracted RGB-D features to empower offline models with temporal learning ability. Specifically, we propose a queued memory mechanism to cache the supporting point cloud and image features. Then we devise aggregation modules which directly perform on the memory and pass temporal information to current frame. We further propose 3D-to-2D adapter to enhance image features with strong global context. Our adapters can be easily inserted into mainstream offline architectures of different tasks and significantly boost their performance on online tasks. Extensive experiments on ScanNet and SceneNN datasets demonstrate our approach achieves leading performance on three 3D scene perception tasks compared with state-of-the-art online methods by simply finetuning existing offline models, without any model and task-specific designs. \href{https://xuxw98.github.io/Online3D/}{Project page}.