 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Iterative Geometry Encoding Volume for Stereo Matching
Mar 14, 2023
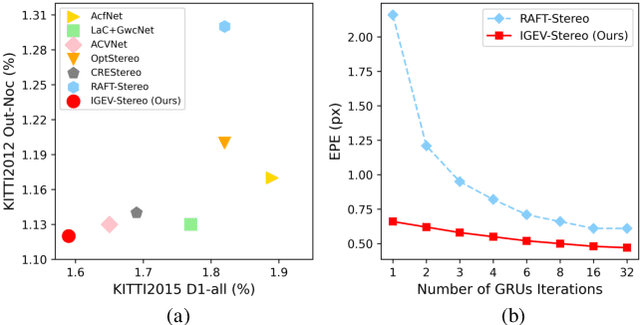
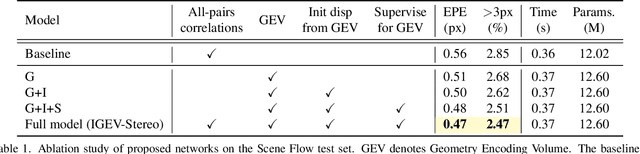

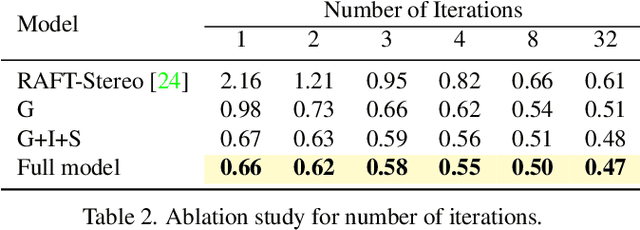
Recurrent All-Pairs Field Transforms (RAFT) has shown great potentials in matching tasks. However, all-pairs correlations lack non-local geometry knowledge and have difficulties tackling local ambiguities in ill-posed regions. In this paper, we propose Iterative Geometry Encoding Volume (IGEV-Stereo), a new deep network architecture for stereo matching. The proposed IGEV-Stereo builds a combined geometry encoding volume that encodes geometry and context information as well as local matching details, and iteratively indexes it to update the disparity map. To speed up the convergence, we exploit GEV to regress an accurate starting point for ConvGRUs iterations. Our IGEV-Stereo ranks $1^{st}$ on KITTI 2015 and 2012 (Reflective) among all published methods and is the fastest among the top 10 methods. In addition, IGEV-Stereo has strong cross-dataset generalization as well as high inference efficiency. We also extend our IGEV to multi-view stereo (MVS), i.e. IGEV-MVS, which achieves competitive accuracy on DTU benchmark. Code is available at https://github.com/gangweiX/IGEV.
Act-Then-Measure: Reinforcement Learning for Partially Observable Environments with Active Measuring
Mar 14, 2023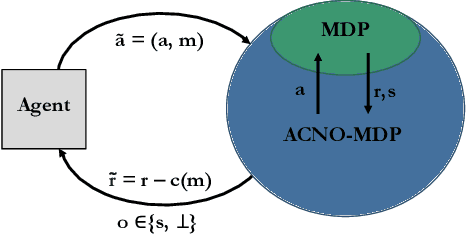

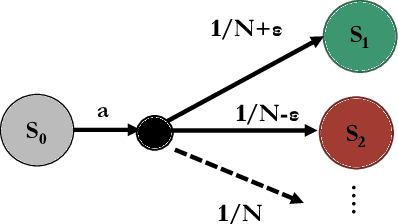
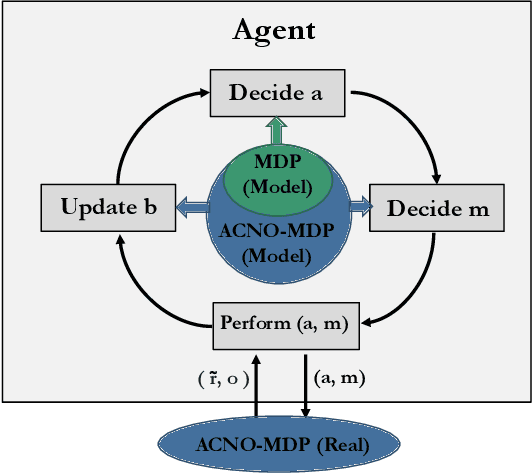
We study Markov decision processes (MDPs), where agents have direct control over when and how they gather information, as formalized by action-contingent noiselessly observable MDPs (ACNO-MPDs). In these models, actions consist of two components: a control action that affects the environment, and a measurement action that affects what the agent can observe. To solve ACNO-MDPs, we introduce the act-then-measure (ATM) heuristic, which assumes that we can ignore future state uncertainty when choosing control actions. We show how following this heuristic may lead to shorter policy computation times and prove a bound on the performance loss incurred by the heuristic. To decide whether or not to take a measurement action, we introduce the concept of measuring value. We develop a reinforcement learning algorithm based on the ATM heuristic, using a Dyna-Q variant adapted for partially observable domains, and showcase its superior performance compared to prior methods on a number of partially-observable environments.
Decision Making for Human-in-the-loop Robotic Agents via Uncertainty-Aware Reinforcement Learning
Mar 14, 2023
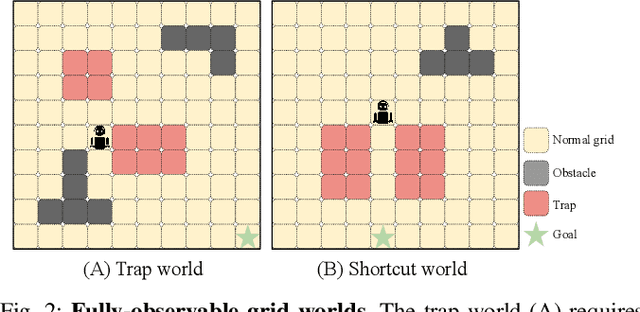
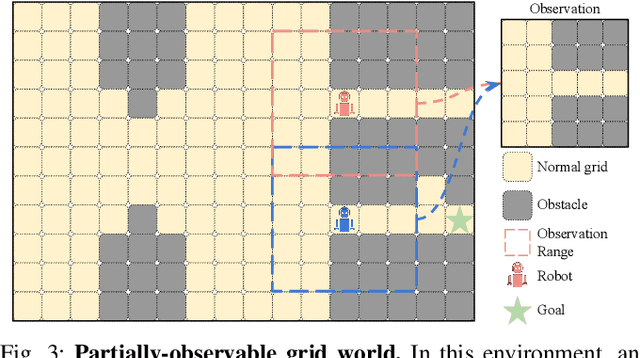
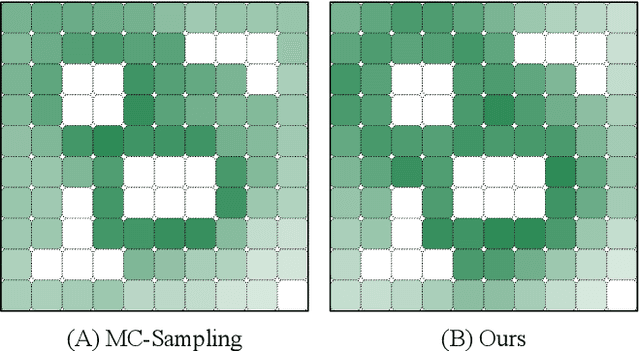
In a Human-in-the-Loop paradigm, a robotic agent is able to act mostly autonomously in solving a task, but can request help from an external expert when needed. However, knowing when to request such assistance is critical: too few requests can lead to the robot making mistakes, but too many requests can overload the expert. In this paper, we present a Reinforcement Learning based approach to this problem, where a semi-autonomous agent asks for external assistance when it has low confidence in the eventual success of the task. The confidence level is computed by estimating the variance of the return from the current state. We show that this estimate can be iteratively improved during training using a Bellman-like recursion. On discrete navigation problems with both fully- and partially-observable state information, we show that our method makes effective use of a limited budget of expert calls at run-time, despite having no access to the expert at training time.
Blind2Sound: Self-Supervised Image Denoising without Residual Noise
Mar 14, 2023

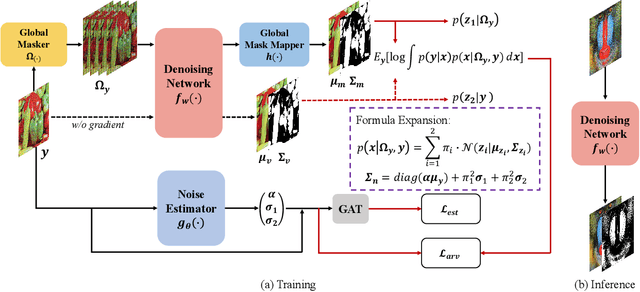
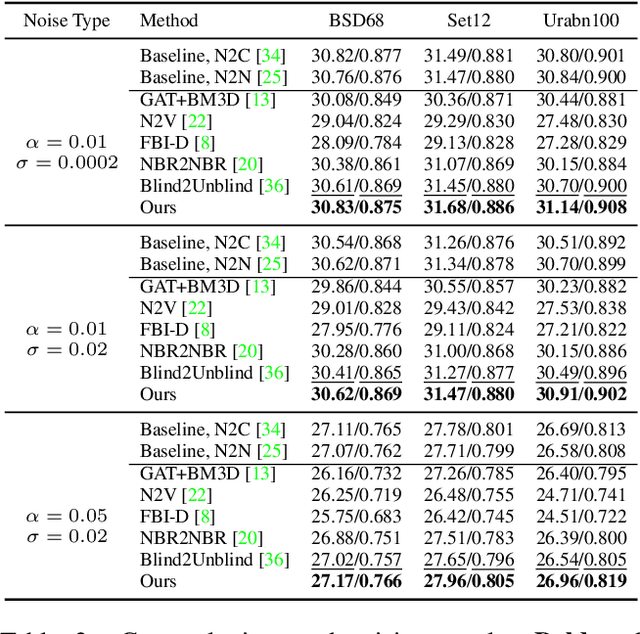
Self-supervised blind denoising for Poisson-Gaussian noise remains a challenging task. Pseudo-supervised pairs constructed from single noisy images re-corrupt the signal and degrade the performance. The visible blindspots solve the information loss in masked inputs. However, without explicitly noise sensing, mean square error as an objective function cannot adjust denoising intensities for dynamic noise levels, leading to noticeable residual noise. In this paper, we propose Blind2Sound, a simple yet effective approach to overcome residual noise in denoised images. The proposed adaptive re-visible loss senses noise levels and performs personalized denoising without noise residues while retaining the signal lossless. The theoretical analysis of intermediate medium gradients guarantees stable training, while the Cramer Gaussian loss acts as a regularization to facilitate the accurate perception of noise levels and improve the performance of the denoiser. Experiments on synthetic and real-world datasets show the superior performance of our method, especially for single-channel images.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
Mar 24, 2023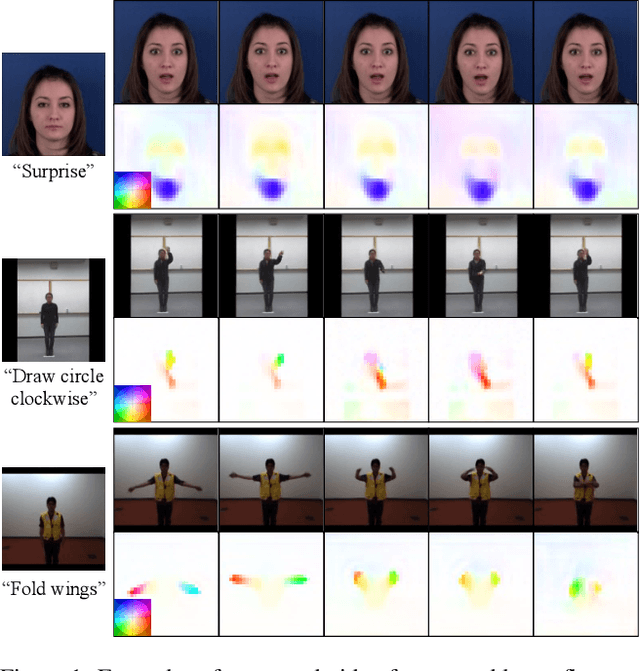

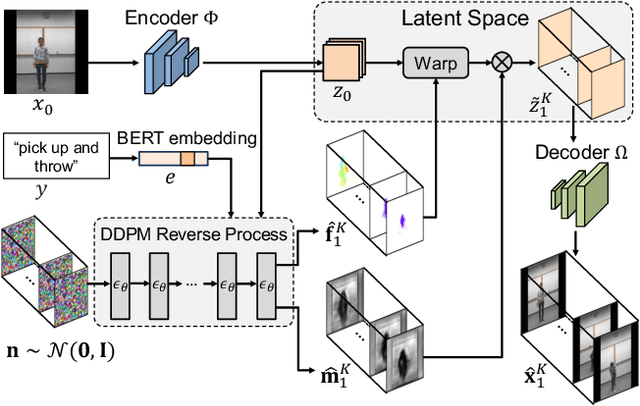
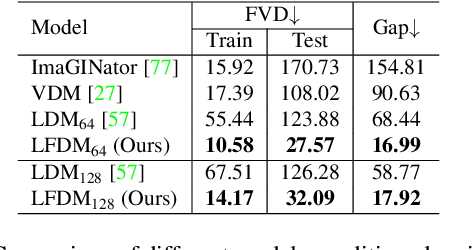
Conditional image-to-video (cI2V) generation aims to synthesize a new plausible video starting from an image (e.g., a person's face) and a condition (e.g., an action class label like smile). The key challenge of the cI2V task lies in the simultaneous generation of realistic spatial appearance and temporal dynamics corresponding to the given image and condition. In this paper, we propose an approach for cI2V using novel latent flow diffusion models (LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: (1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. We conduct comprehensive experiments on multiple datasets, where LFDM consistently outperforms prior arts. Furthermore, we show that LFDM can be easily adapted to new domains by simply finetuning the image decoder. Our code is available at https://github.com/nihaomiao/CVPR23_LFDM.
OverlapNetVLAD: A Coarse-to-Fine Framework for LiDAR-based Place Recognition
Mar 13, 2023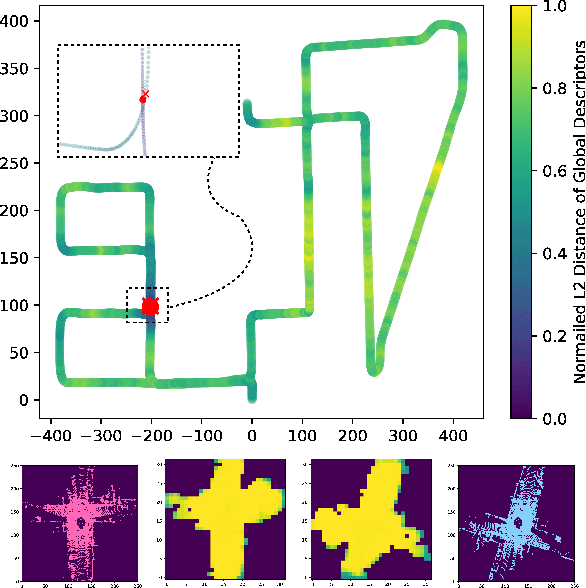
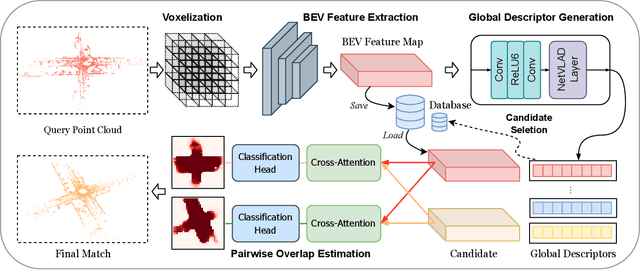
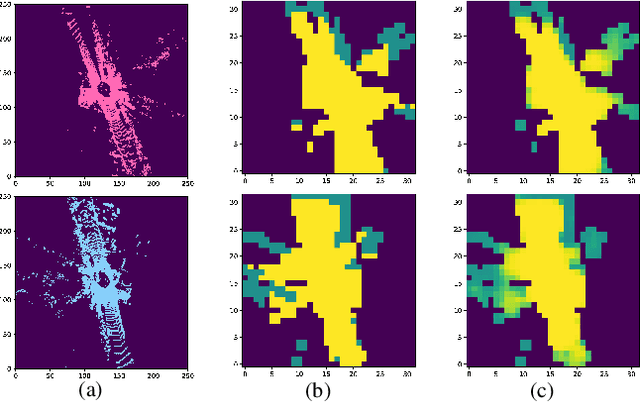
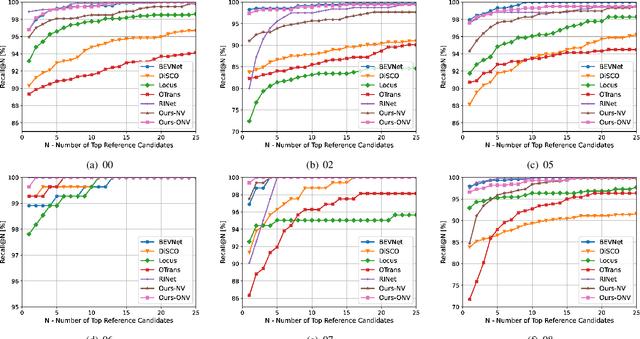
Place recognition is a challenging yet crucial task in robotics. Existing 3D LiDAR place recognition methods suffer from limited feature representation capability and long search times. To address these challenges, we propose a novel coarse-to-fine framework for 3D LiDAR place recognition that combines Birds' Eye View (BEV) feature extraction, coarse-grained matching, and fine-grained verification. In the coarse stage, our framework leverages the rich contextual information contained in BEV features to produce global descriptors. Then the top-\textit{K} most similar candidates are identified via descriptor matching, which is fast but coarse-grained. In the fine stage, our overlap estimation network reuses the corresponding BEV features to predict the overlap region, enabling meticulous and precise matching. Experimental results on the KITTI odometry benchmark demonstrate that our framework achieves leading performance compared to state-of-the-art methods. Our code is available at: \url{https://github.com/fcchit/OverlapNetVLAD}.
Intersection Warning System for Occlusion Risks using Relational Local Dynamic Maps
Mar 13, 2023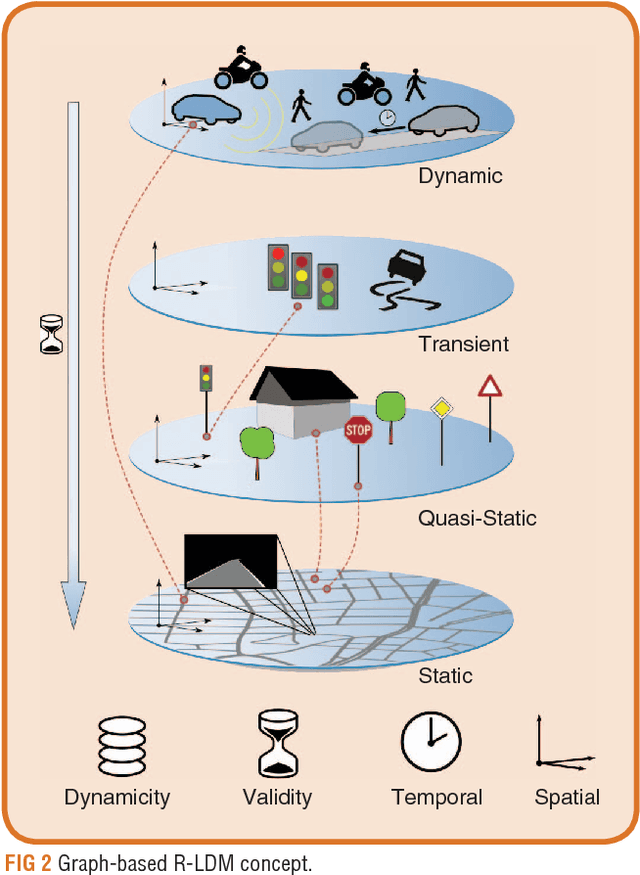
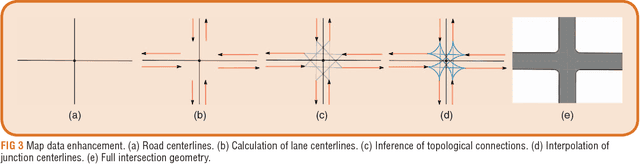
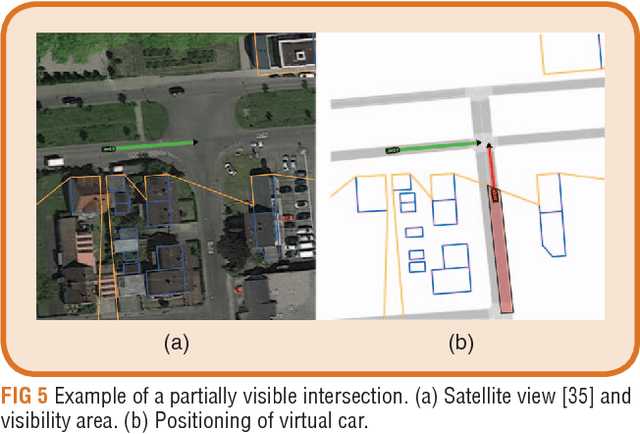
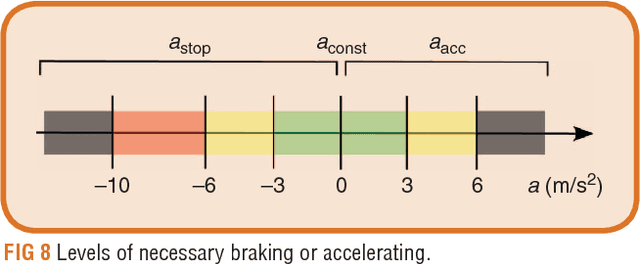
This work addresses the task of risk evaluation in traffic scenarios with limited observability due to restricted sensorial coverage. Here, we concentrate on intersection scenarios that are difficult to access visually. To identify the area of sight, we employ ray casting on a local dynamic map providing geometrical information and road infrastructure. Based on the area with reduced visibility, we first model scene entities that pose a potential risk without being visually perceivable yet. Then, we predict a worst-case trajectory in the survival analysis for collision risk estimation. Resulting risk indicators are utilized to evaluate the driver's current behavior, to warn the driver in critical situations, to give suggestions on how to act safely or to plan safe trajectories. We validate our approach by applying the resulting intersection warning system on real world scenarios. The proposed system's behavior reveals to mimic the general behavior of a correctly acting human driver.
Next-Best-View Selection for Robot Eye-in-Hand Calibration
Mar 12, 2023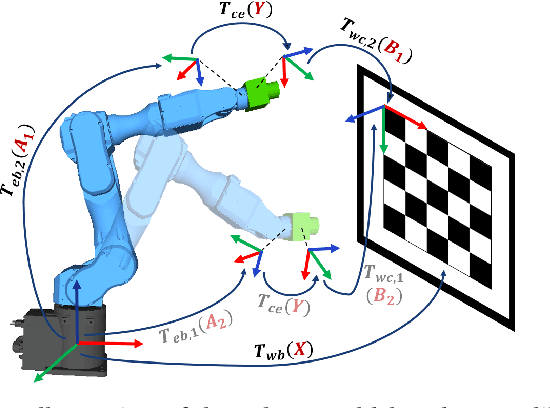
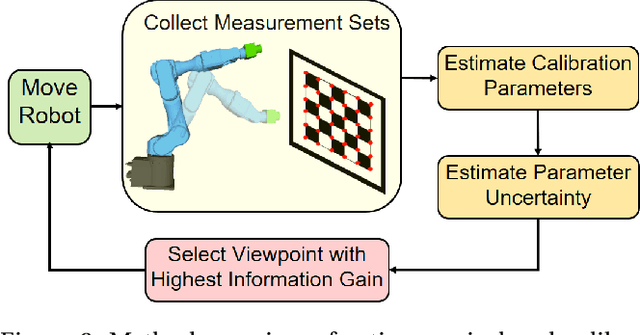
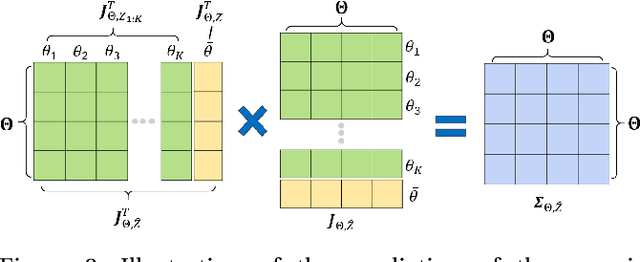

Robotic eye-in-hand calibration is the task of determining the rigid 6-DoF pose of the camera with respect to the robot end-effector frame. In this paper, we formulate this task as a non-linear optimization problem and introduce an active vision approach to strategically select the robot pose for maximizing calibration accuracy. Specifically, given an initial collection of measurement sets, our system first computes the calibration parameters and estimates the parameter uncertainties. We then predict the next robot pose from which to collect the next measurement that brings about the maximum information gain (uncertainty reduction) in the calibration parameters. We test our approach on a simulated dataset and validate the results on a real 6-axis robot manipulator. The results demonstrate that our approach can achieve accurate calibrations using many fewer viewpoints than other commonly used baseline calibration methods.
Spatio-Temporal driven Attention Graph Neural Network with Block Adjacency matrix (STAG-NN-BA)
Mar 25, 2023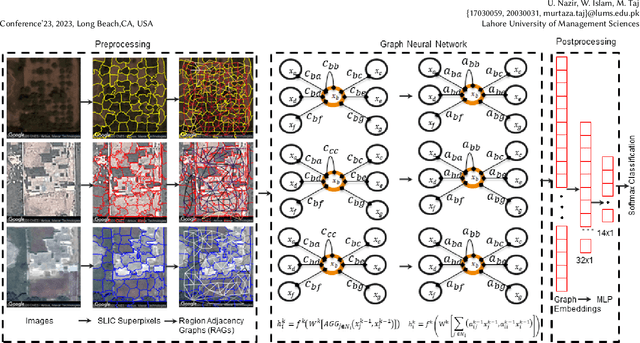


Despite the recent advances in deep neural networks, standard convolutional kernels limit the applications of these networks to the Euclidean domain only. Considering the geodesic nature of the measurement of the earth's surface, remote sensing is one such area that can benefit from non-Euclidean and spherical domains. For this purpose, we propose a novel Graph Neural Network architecture for spatial and spatio-temporal classification using satellite imagery. We propose a hybrid attention method to learn the relative importance of irregular neighbors in remote sensing data. Instead of classifying each pixel, we propose a method based on Simple Linear Iterative Clustering (SLIC) image segmentation and Graph Attention GAT. The superpixels obtained from SLIC become the nodes of our Graph Convolution Network (GCN). We then construct a region adjacency graph (RAG) where each superpixel is connected to every other adjacent superpixel in the image, enabling information to propagate globally. Finally, we propose a Spatially driven Attention Graph Neural Network (SAG-NN) to classify each RAG. We also propose an extension to our SAG-NN for spatio-temporal data. Unlike regular grids of pixels in images, superpixels are irregular in nature and cannot be used to create spatio-temporal graphs. We introduce temporal bias by combining unconnected RAGs from each image into one supergraph. This is achieved by introducing block adjacency matrices resulting in novel Spatio-Temporal driven Attention Graph Neural Network with Block Adjacency matrix (STAG-NN-BA). We evaluate our proposed methods on two remote sensing datasets namely Asia14 and C2D2. In comparison with both non-graph and graph-based approaches our SAG-NN and STAG-NN-BA achieved superior accuracy on all the datasets while incurring less computation cost. The code and dataset will be made public via our GitHub repository.
SIM-Trans: Structure Information Modeling Transformer for Fine-grained Visual Categorization
Aug 31, 2022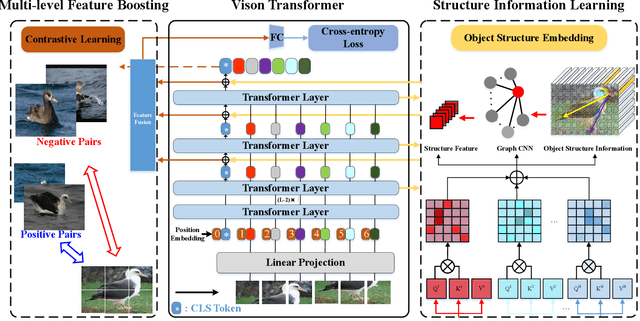
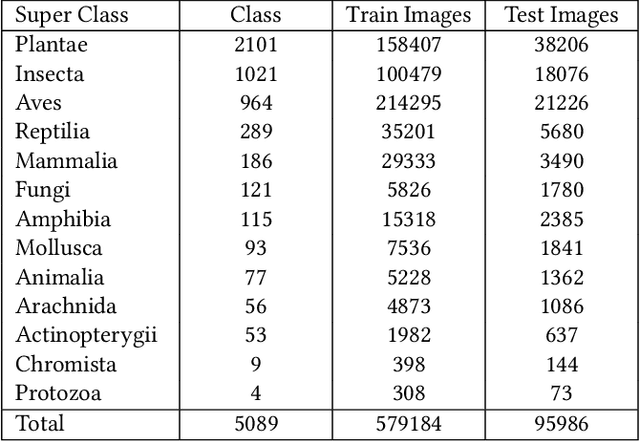
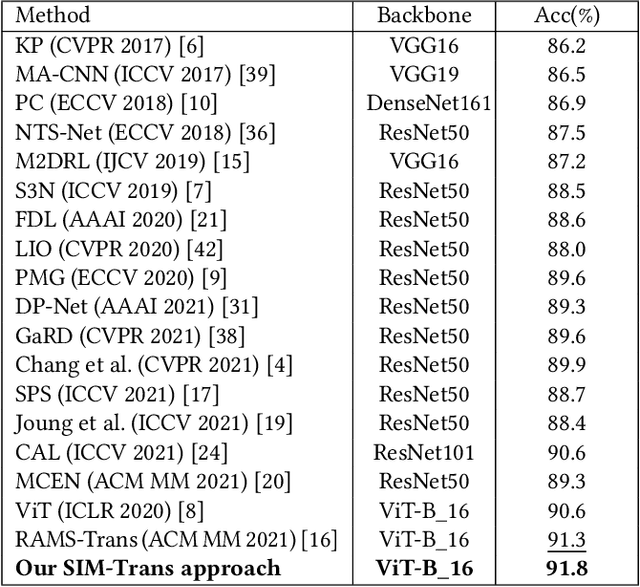
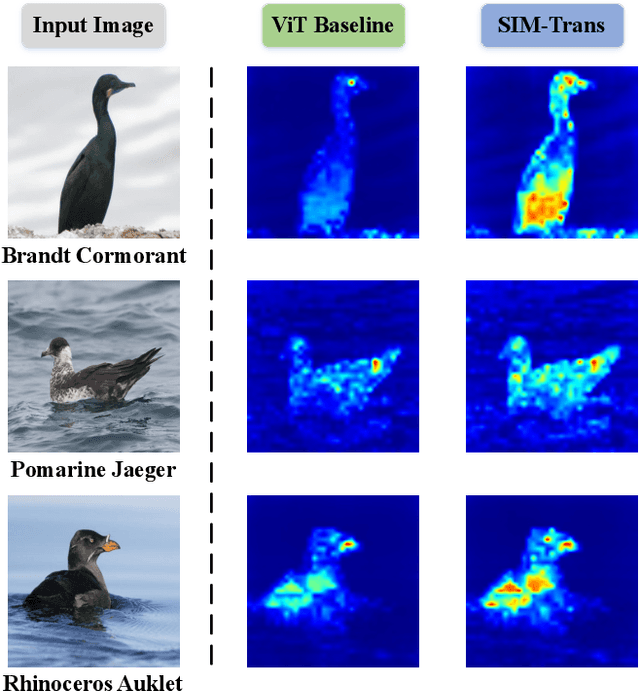
Fine-grained visual categorization (FGVC) aims at recognizing objects from similar subordinate categories, which is challenging and practical for human's accurate automatic recognition needs. Most FGVC approaches focus on the attention mechanism research for discriminative regions mining while neglecting their interdependencies and composed holistic object structure, which are essential for model's discriminative information localization and understanding ability. To address the above limitations, we propose the Structure Information Modeling Transformer (SIM-Trans) to incorporate object structure information into transformer for enhancing discriminative representation learning to contain both the appearance information and structure information. Specifically, we encode the image into a sequence of patch tokens and build a strong vision transformer framework with two well-designed modules: (i) the structure information learning (SIL) module is proposed to mine the spatial context relation of significant patches within the object extent with the help of the transformer's self-attention weights, which is further injected into the model for importing structure information; (ii) the multi-level feature boosting (MFB) module is introduced to exploit the complementary of multi-level features and contrastive learning among classes to enhance feature robustness for accurate recognition. The proposed two modules are light-weighted and can be plugged into any transformer network and trained end-to-end easily, which only depends on the attention weights that come with the vision transformer itself. Extensive experiments and analyses demonstrate that the proposed SIM-Trans achieves state-of-the-art performance on fine-grained visual categorization benchmarks. The code is available at https://github.com/PKU-ICST-MIPL/SIM-Trans_ACMMM2022.