 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scale space radon transform-based inertia axis and object central symmetry estimation
Mar 22, 2023
Inertia Axes are involved in many techniques for image content measurement when involving information obtained from lines, angles, centroids... etc. We investigate, here, the estimation of the main axis of inertia of an object in the image. We identify the coincidence conditions of the Scale Space Radon Transform (SSRT) maximum and the inertia main axis. We show, that by choosing the appropriate scale parameter, it is possible to match the SSRT maximum and the main axis of inertia location and orientation of the embedded object in the image. Furthermore, an example of use case is presented where binary objects central symmetry computation is derived by means of SSRT projections and the axis of inertia orientation. To this end, some SSRT characteristics have been highlighted and exploited. The experimentations show the SSRT-based main axis of inertia computation effectiveness. Concerning the central symmetry, results are very satisfying as experimentations carried out on randomly created images dataset and existing datasets have permitted to divide successfully these images bases into centrally symmetric and non-centrally symmetric objects.
PRSNet: A Masked Self-Supervised Learning Pedestrian Re-Identification Method
Mar 11, 2023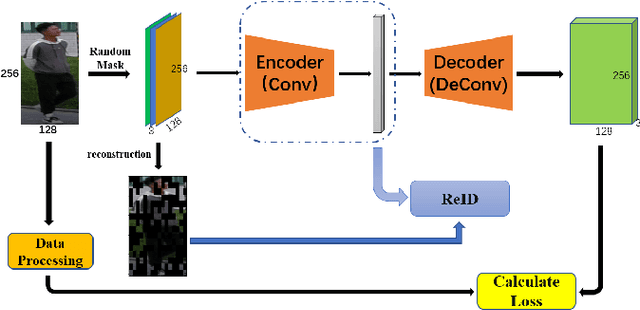
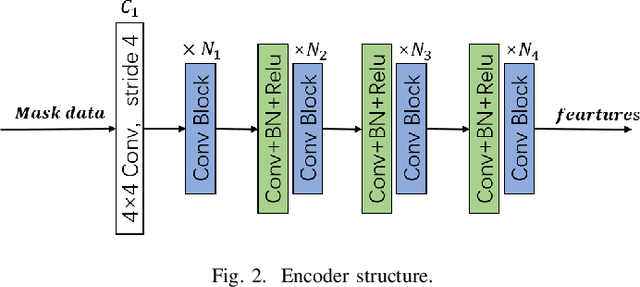
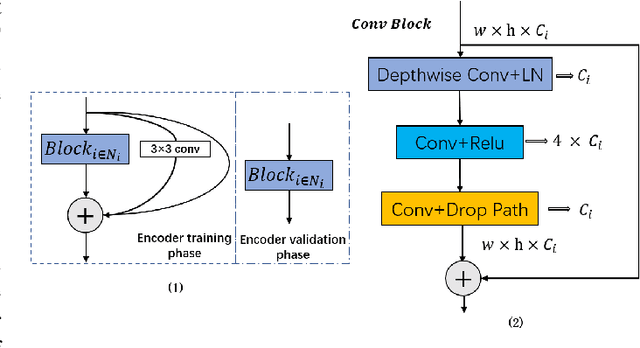
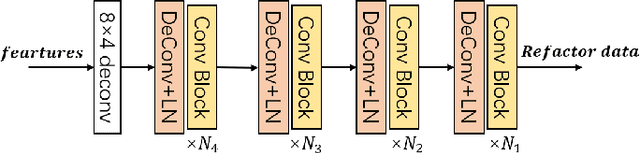
In recent years, self-supervised learning has attracted widespread academic debate and addressed many of the key issues of computer vision. The present research focus is on how to construct a good agent task that allows for improved network learning of advanced semantic information on images so that model reasoning is accelerated during pre-training of the current task. In order to solve the problem that existing feature extraction networks are pre-trained on the ImageNet dataset and cannot extract the fine-grained information in pedestrian images well, and the existing pre-task of contrast self-supervised learning may destroy the original properties of pedestrian images, this paper designs a pre-task of mask reconstruction to obtain a pre-training model with strong robustness and uses it for the pedestrian re-identification task. The training optimization of the network is performed by improving the triplet loss based on the centroid, and the mask image is added as an additional sample to the loss calculation, so that the network can better cope with the pedestrian matching in practical applications after the training is completed. This method achieves about 5% higher mAP on Marker1501 and CUHK03 data than existing self-supervised learning pedestrian re-identification methods, and about 1% higher for Rank1, and ablation experiments are conducted to demonstrate the feasibility of this method. Our model code is located at https://github.com/ZJieX/prsnet.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 22, 2023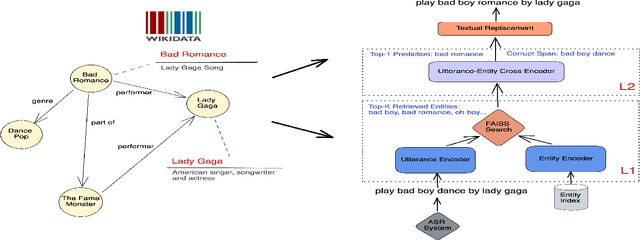

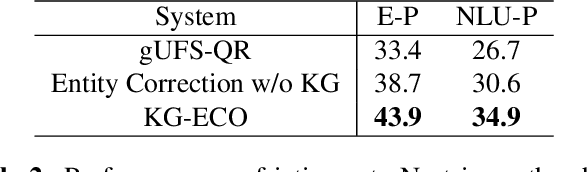
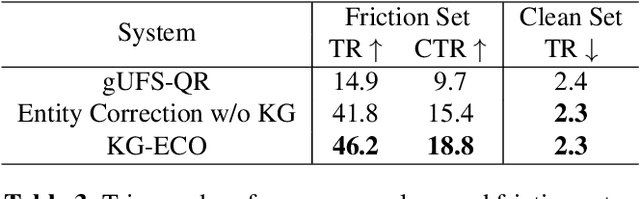
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities. To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
A Picture is Worth a Thousand Words: Language Models Plan from Pixels
Mar 16, 2023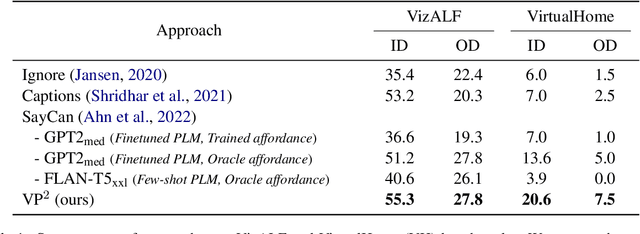
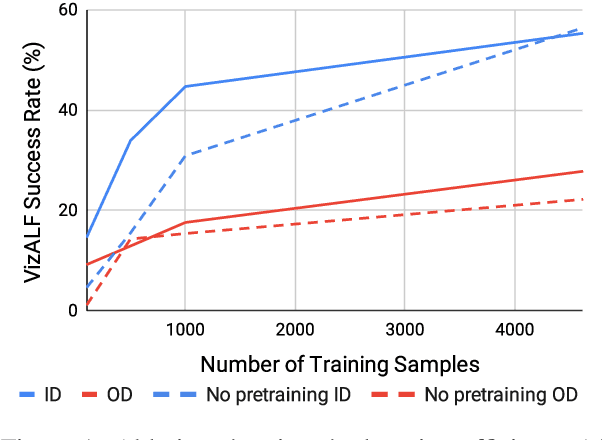
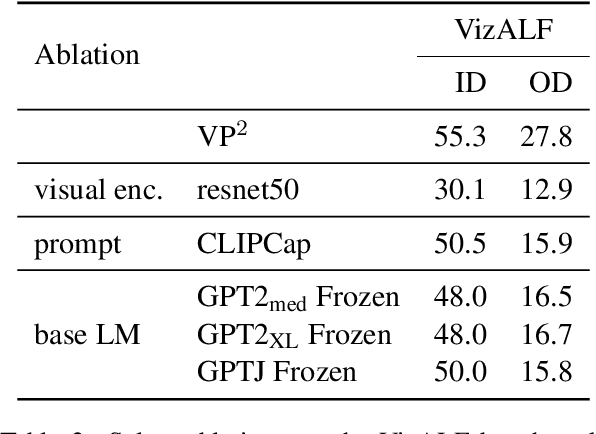
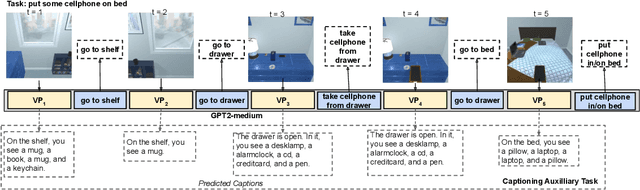
Planning is an important capability of artificial agents that perform long-horizon tasks in real-world environments. In this work, we explore the use of pre-trained language models (PLMs) to reason about plan sequences from text instructions in embodied visual environments. Prior PLM based approaches for planning either assume observations are available in the form of text (e.g., provided by a captioning model), reason about plans from the instruction alone, or incorporate information about the visual environment in limited ways (such as a pre-trained affordance function). In contrast, we show that PLMs can accurately plan even when observations are directly encoded as input prompts for the PLM. We show that this simple approach outperforms prior approaches in experiments on the ALFWorld and VirtualHome benchmarks.
Domain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023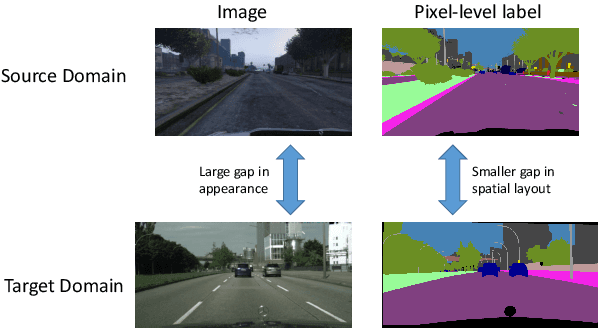
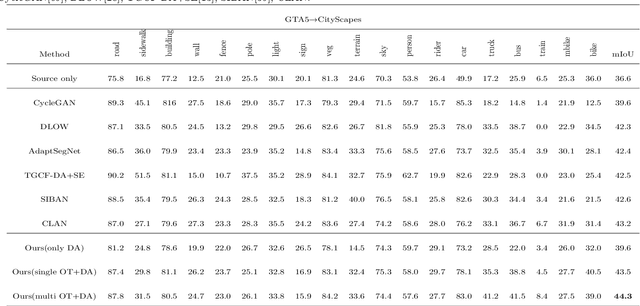
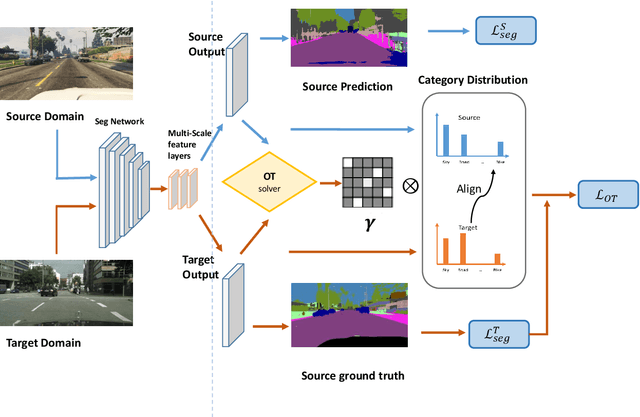
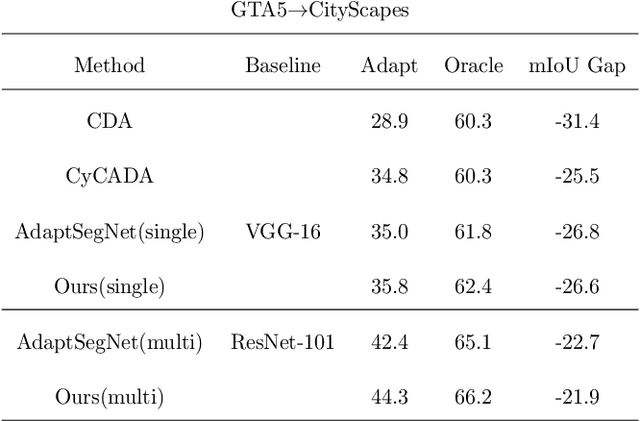
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.
Does Sparsity Help in Learning Misspecified Linear Bandits?
Mar 29, 2023Recently, the study of linear misspecified bandits has generated intriguing implications of the hardness of learning in bandits and reinforcement learning (RL). In particular, Du et al. (2020) show that even if a learner is given linear features in $\mathbb{R}^d$ that approximate the rewards in a bandit or RL with a uniform error of $\varepsilon$, searching for an $O(\varepsilon)$-optimal action requires pulling at least $\Omega(\exp(d))$ queries. Furthermore, Lattimore et al. (2020) show that a degraded $O(\varepsilon\sqrt{d})$-optimal solution can be learned within $\operatorname{poly}(d/\varepsilon)$ queries. Yet it is unknown whether a structural assumption on the ground-truth parameter, such as sparsity, could break the $\varepsilon\sqrt{d}$ barrier. In this paper, we address this question by showing that algorithms can obtain $O(\varepsilon)$-optimal actions by querying $O(\varepsilon^{-s}d^s)$ actions, where $s$ is the sparsity parameter, removing the $\exp(d)$-dependence. We then establish information-theoretical lower bounds, i.e., $\Omega(\exp(s))$, to show that our upper bound on sample complexity is nearly tight if one demands an error $ O(s^{\delta}\varepsilon)$ for $0<\delta<1$. For $\delta\geq 1$, we further show that $\operatorname{poly}(s/\varepsilon)$ queries are possible when the linear features are "good" and even in general settings. These results provide a nearly complete picture of how sparsity can help in misspecified bandit learning and provide a deeper understanding of when linear features are "useful" for bandit and reinforcement learning with misspecification.
Are Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023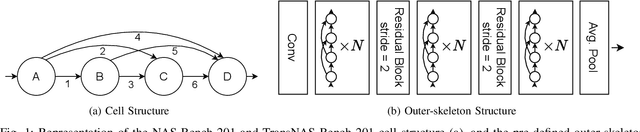

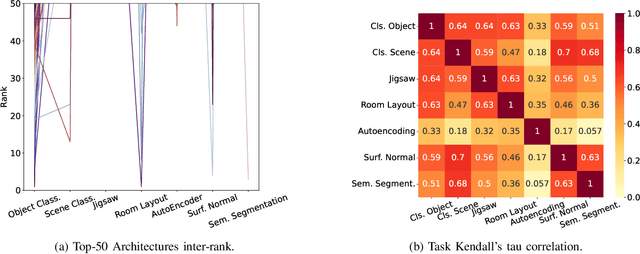
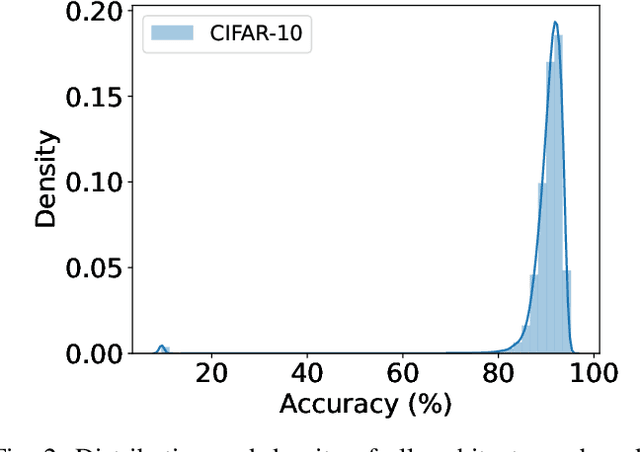
Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.
Toward Zero-Shot Sim-to-Real Transfer Learning for Pneumatic Soft Robot 3D Proprioceptive Sensing
Mar 08, 2023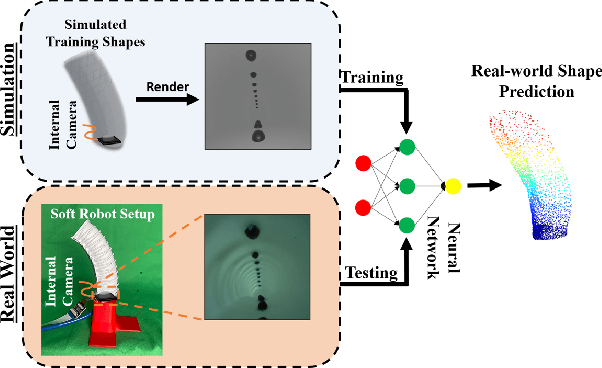
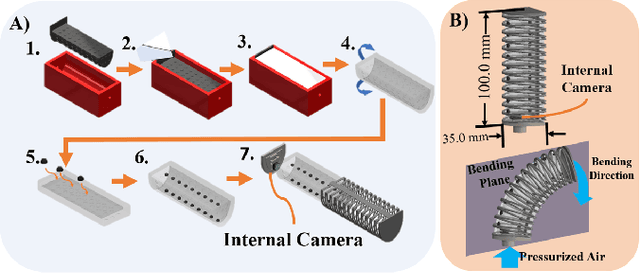
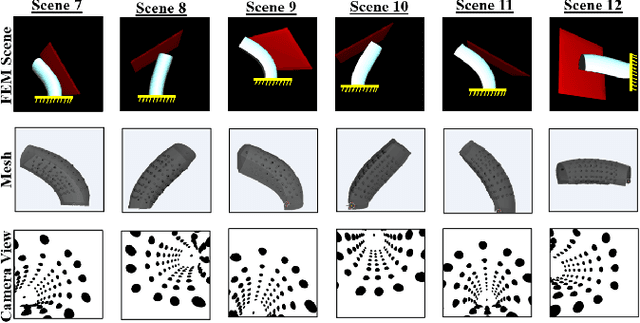
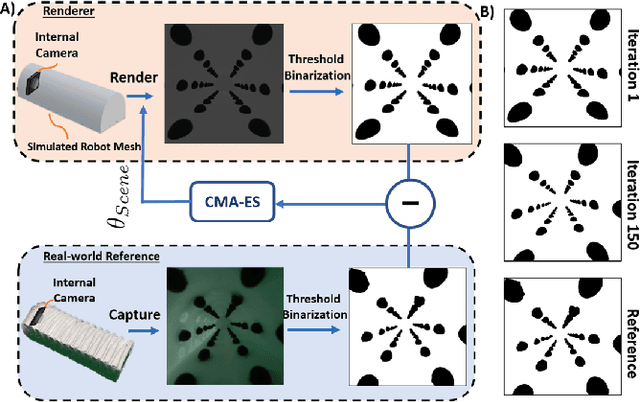
Pneumatic soft robots present many advantages in manipulation tasks. Notably, their inherent compliance makes them safe and reliable in unstructured and fragile environments. However, full-body shape sensing for pneumatic soft robots is challenging because of their high degrees of freedom and complex deformation behaviors. Vision-based proprioception sensing methods relying on embedded cameras and deep learning provide a good solution to proprioception sensing by extracting the full-body shape information from the high-dimensional sensing data. But the current training data collection process makes it difficult for many applications. To address this challenge, we propose and demonstrate a robust sim-to-real pipeline that allows the collection of the soft robot's shape information in high-fidelity point cloud representation. The model trained on simulated data was evaluated with real internal camera images. The results show that the model performed with averaged Chamfer distance of 8.85 mm and tip position error of 10.12 mm even with external perturbation for a pneumatic soft robot with a length of 100.0 mm. We also demonstrated the sim-to-real pipeline's potential for exploring different configurations of visual patterns to improve vision-based reconstruction results. The code and dataset are available at https://github.com/DeepSoRo/DeepSoRoSim2Real.
Extracting Digital Biomarkers for Unobtrusive Stress State Screening from Multimodal Wearable Data
Mar 08, 2023
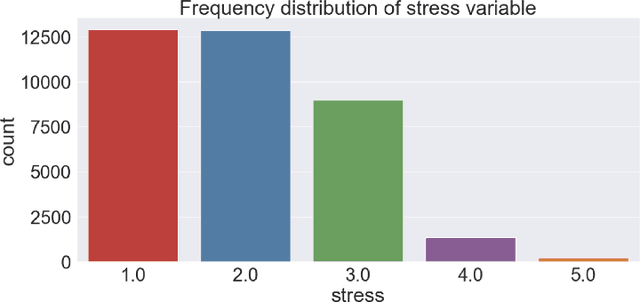
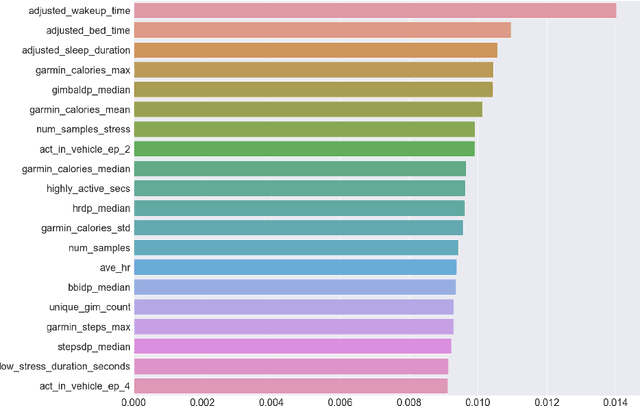
With the development of wearable technologies, a new kind of healthcare data has become valuable as medical information. These data provide meaningful information regarding an individual's physiological and psychological states, such as activity level, mood, stress, and cognitive health. These biomarkers are named digital since they are collected from digital devices integrated with various sensors. In this study, we explore digital biomarkers related to stress modality by examining data collected from mobile phones and smartwatches. We utilize machine learning techniques on the Tesserae dataset, precisely Random Forest, to extract stress biomarkers. Using feature selection techniques, we utilize weather, activity, heart rate (HR), stress, sleep, and location (work-home) measurements from wearables to determine the most important stress-related biomarkers. We believe we contribute to interpreting stress biomarkers with a high range of features from different devices. In addition, we classify the $5$ different stress levels with the most important features, and our results show that we can achieve $85\%$ overall class accuracy by adjusting class imbalance and adding extra features related to personality characteristics. We perform similar and even better results in recognizing stress states with digital biomarkers in a daily-life scenario targeting a higher number of classes compared to the related studies.
Computational Spectral Imaging: A Contemporary Overview
Mar 08, 2023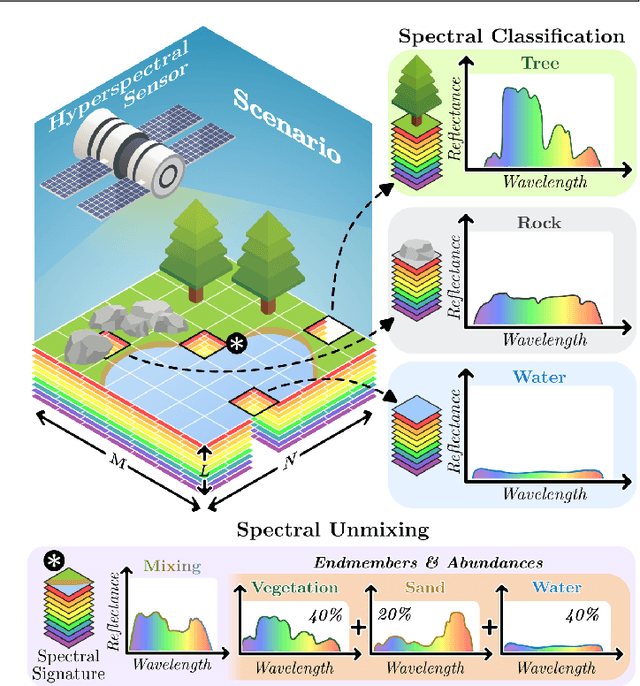
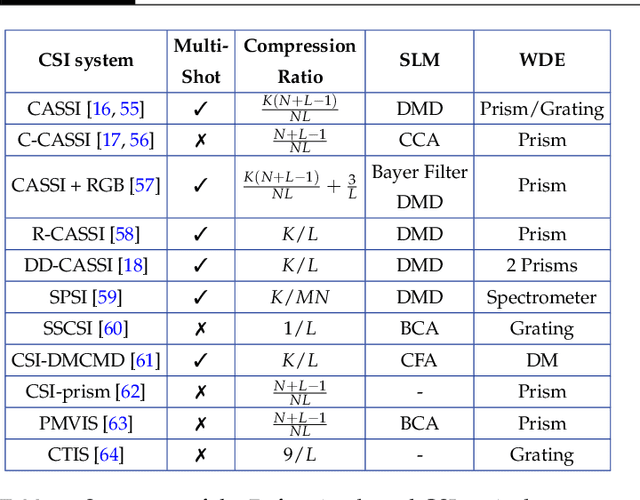
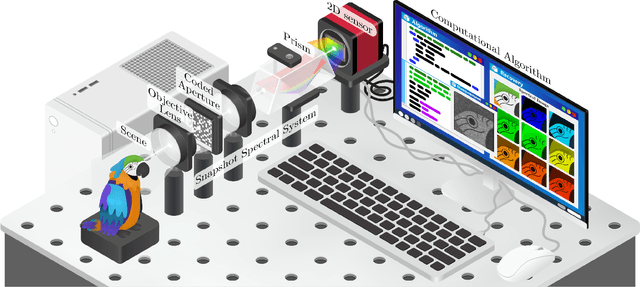
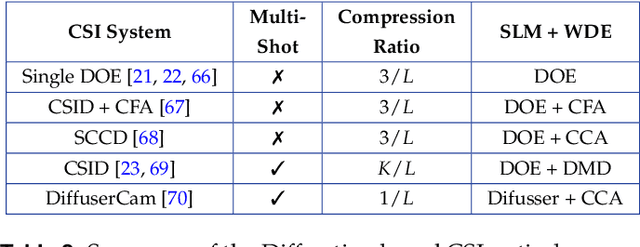
Spectral imaging collects and processes information along spatial and spectral coordinates quantified in discrete voxels, which can be treated as a 3D spectral data cube. The spectral images (SIs) allow identifying objects, crops, and materials in the scene through their spectral behavior. Since most spectral optical systems can only employ 1D or maximum 2D sensors, it is challenging to directly acquire the 3D information from available commercial sensors. As an alternative, computational spectral imaging (CSI) has emerged as a sensing tool where the 3D data can be obtained using 2D encoded projections. Then, a computational recovery process must be employed to retrieve the SI. CSI enables the development of snapshot optical systems that reduce acquisition time and provide low computational storage costs compared to conventional scanning systems. Recent advances in deep learning (DL) have allowed the design of data-driven CSI to improve the SI reconstruction or, even more, perform high-level tasks such as classification, unmixing, or anomaly detection directly from 2D encoded projections. This work summarises the advances in CSI, starting with SI and its relevance; continuing with the most relevant compressive spectral optical systems. Then, CSI with DL will be introduced, and the recent advances in combining the physical optical design with computational DL algorithms to solve high-level tasks.