 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Best of Both Worlds: Multimodal Contrastive Learning with Tabular and Imaging Data
Mar 27, 2023
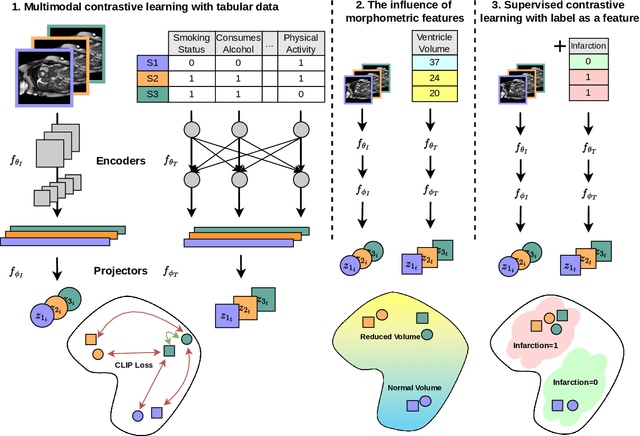
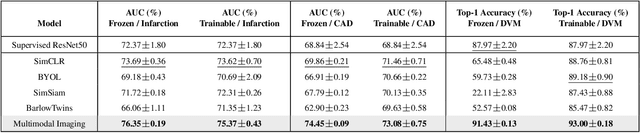
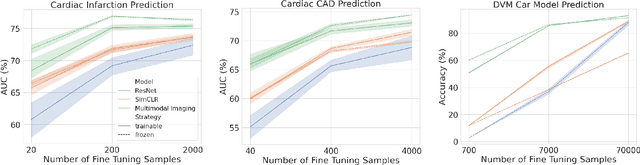

Medical datasets and especially biobanks, often contain extensive tabular data with rich clinical information in addition to images. In practice, clinicians typically have less data, both in terms of diversity and scale, but still wish to deploy deep learning solutions. Combined with increasing medical dataset sizes and expensive annotation costs, the necessity for unsupervised methods that can pretrain multimodally and predict unimodally has risen. To address these needs, we propose the first self-supervised contrastive learning framework that takes advantage of images and tabular data to train unimodal encoders. Our solution combines SimCLR and SCARF, two leading contrastive learning strategies, and is simple and effective. In our experiments, we demonstrate the strength of our framework by predicting risks of myocardial infarction and coronary artery disease (CAD) using cardiac MR images and 120 clinical features from 40,000 UK Biobank subjects. Furthermore, we show the generalizability of our approach to natural images using the DVM car advertisement dataset. We take advantage of the high interpretability of tabular data and through attribution and ablation experiments find that morphometric tabular features, describing size and shape, have outsized importance during the contrastive learning process and improve the quality of the learned embeddings. Finally, we introduce a novel form of supervised contrastive learning, label as a feature (LaaF), by appending the ground truth label as a tabular feature during multimodal pretraining, outperforming all supervised contrastive baselines.
Phone and speaker spatial organization in self-supervised speech representations
Feb 24, 2023
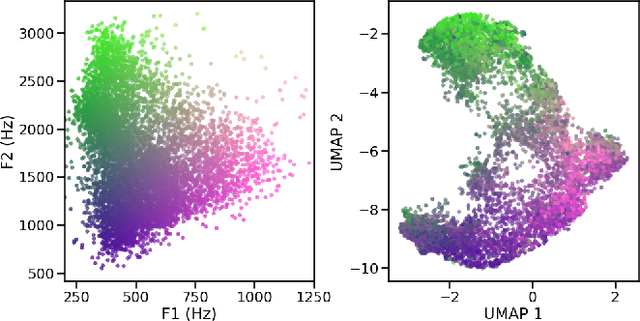
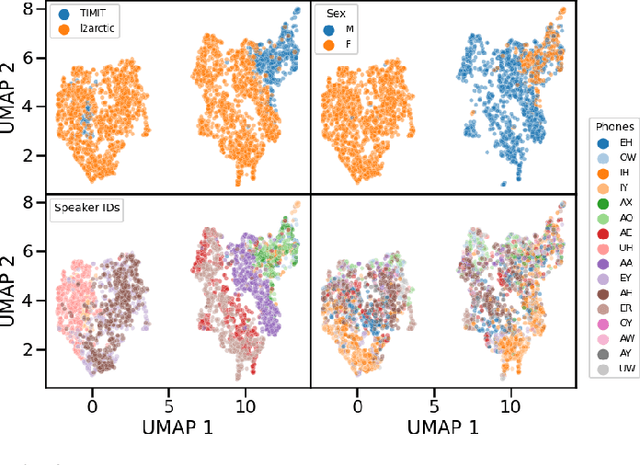
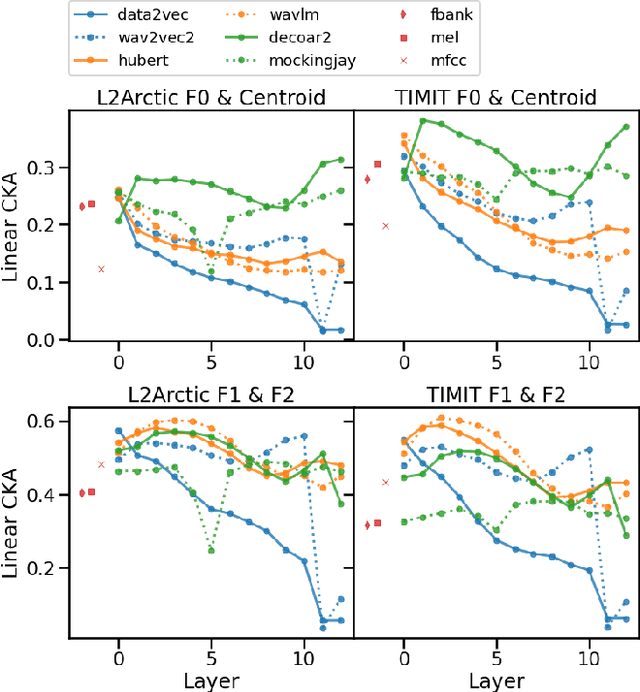
Self-supervised representations of speech are currently being widely used for a large number of applications. Recently, some efforts have been made in trying to analyze the type of information present in each of these representations. Most such work uses downstream models to test whether the representations can be successfully used for a specific task. The downstream models, though, typically perform nonlinear operations on the representation extracting information that may not have been readily available in the original representation. In this work, we analyze the spatial organization of phone and speaker information in several state-of-the-art speech representations using methods that do not require a downstream model. We measure how different layers encode basic acoustic parameters such as formants and pitch using representation similarity analysis. Further, we study the extent to which each representation clusters the speech samples by phone or speaker classes using non-parametric statistical testing. Our results indicate that models represent these speech attributes differently depending on the target task used during pretraining.
Towards better traffic volume estimation: Tackling both underdetermined and non-equilibrium problems via a correlation-adaptive graph convolution network
Mar 14, 2023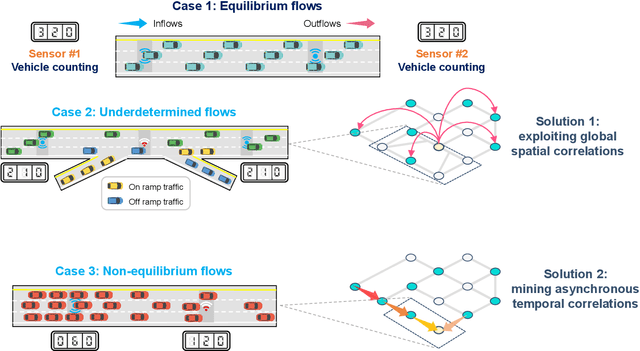
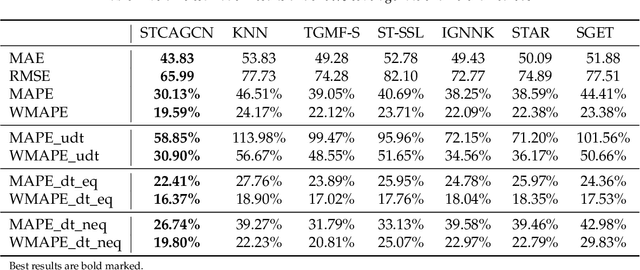
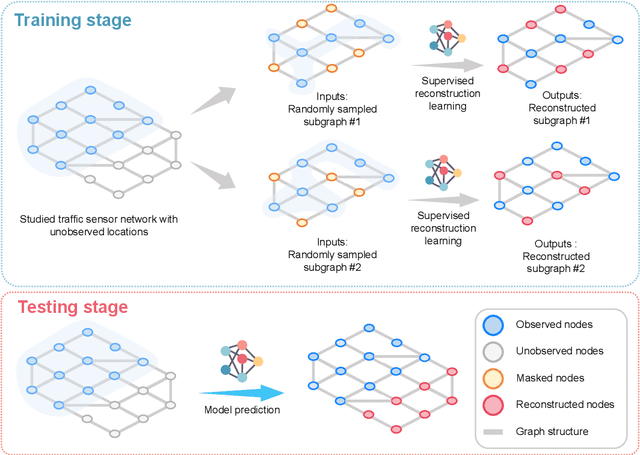
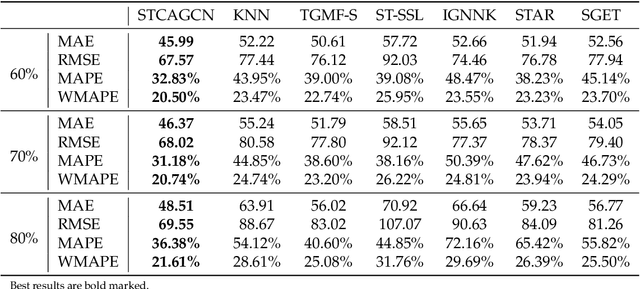
Traffic volume is an indispensable ingredient to provide fine-grained information for traffic management and control. However, due to limited deployment of traffic sensors, obtaining full-scale volume information is far from easy. Existing works on this topic primarily focus on improving the overall estimation accuracy of a particular method and ignore the underlying challenges of volume estimation, thereby having inferior performances on some critical tasks. This paper studies two key problems with regard to traffic volume estimation: (1) underdetermined traffic flows caused by undetected movements, and (2) non-equilibrium traffic flows arise from congestion propagation. Here we demonstrate a graph-based deep learning method that can offer a data-driven, model-free and correlation adaptive approach to tackle the above issues and perform accurate network-wide traffic volume estimation. Particularly, in order to quantify the dynamic and nonlinear relationships between traffic speed and volume for the estimation of underdetermined flows, a speed patternadaptive adjacent matrix based on graph attention is developed and integrated into the graph convolution process, to capture non-local correlations between sensors. To measure the impacts of non-equilibrium flows, a temporal masked and clipped attention combined with a gated temporal convolution layer is customized to capture time-asynchronous correlations between upstream and downstream sensors. We then evaluate our model on a real-world highway traffic volume dataset and compare it with several benchmark models. It is demonstrated that the proposed model achieves high estimation accuracy even under 20% sensor coverage rate and outperforms other baselines significantly, especially on underdetermined and non-equilibrium flow locations. Furthermore, comprehensive quantitative model analysis are also carried out to justify the model designs.
Few Shot Medical Image Segmentation with Cross Attention Transformer
Mar 24, 2023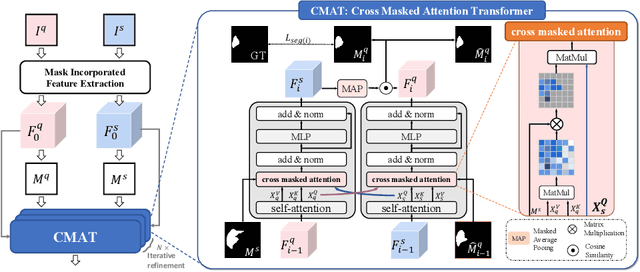
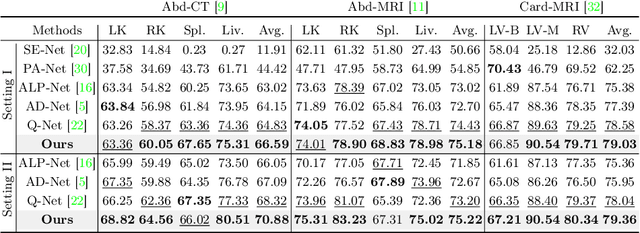
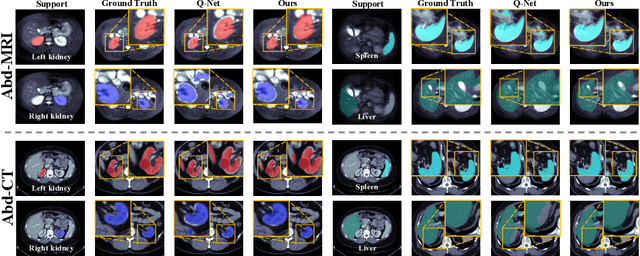
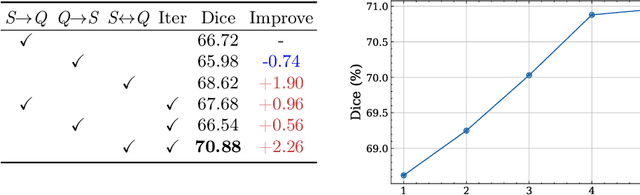
Medical image segmentation has made significant progress in recent years. Deep learning-based methods are recognized as data-hungry techniques, requiring large amounts of data with manual annotations. However, manual annotation is expensive in the field of medical image analysis, which requires domain-specific expertise. To address this challenge, few-shot learning has the potential to learn new classes from only a few examples. In this work, we propose a novel framework for few-shot medical image segmentation, termed CAT-Net, based on cross masked attention Transformer. Our proposed network mines the correlations between the support image and query image, limiting them to focus only on useful foreground information and boosting the representation capacity of both the support prototype and query features. We further design an iterative refinement framework that refines the query image segmentation iteratively and promotes the support feature in turn. We validated the proposed method on three public datasets: Abd-CT, Abd-MRI, and Card-MRI. Experimental results demonstrate the superior performance of our method compared to state-of-the-art methods and the effectiveness of each component. we will release the source codes of our method upon acceptance.
Feature Separation and Recalibration for Adversarial Robustness
Mar 24, 2023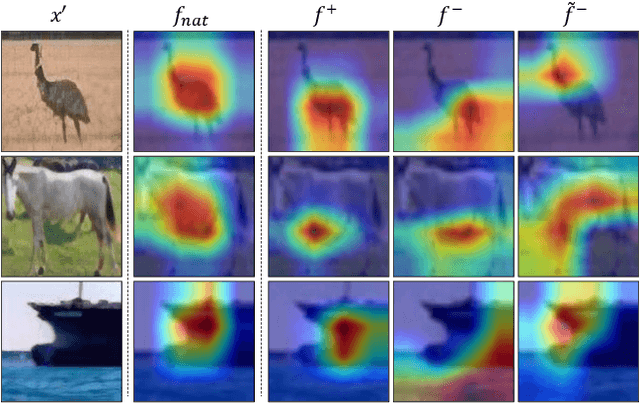

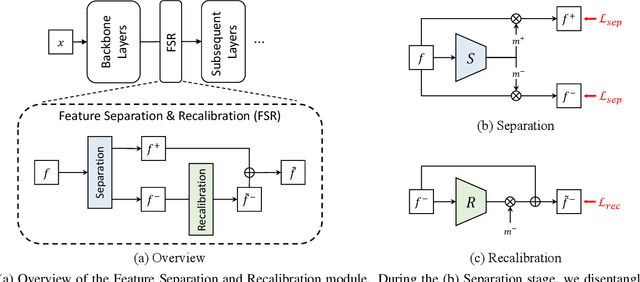

Deep neural networks are susceptible to adversarial attacks due to the accumulation of perturbations in the feature level, and numerous works have boosted model robustness by deactivating the non-robust feature activations that cause model mispredictions. However, we claim that these malicious activations still contain discriminative cues and that with recalibration, they can capture additional useful information for correct model predictions. To this end, we propose a novel, easy-to-plugin approach named Feature Separation and Recalibration (FSR) that recalibrates the malicious, non-robust activations for more robust feature maps through Separation and Recalibration. The Separation part disentangles the input feature map into the robust feature with activations that help the model make correct predictions and the non-robust feature with activations that are responsible for model mispredictions upon adversarial attack. The Recalibration part then adjusts the non-robust activations to restore the potentially useful cues for model predictions. Extensive experiments verify the superiority of FSR compared to traditional deactivation techniques and demonstrate that it improves the robustness of existing adversarial training methods by up to 8.57% with small computational overhead. Codes are available at https://github.com/wkim97/FSR.
UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields
Mar 24, 2023
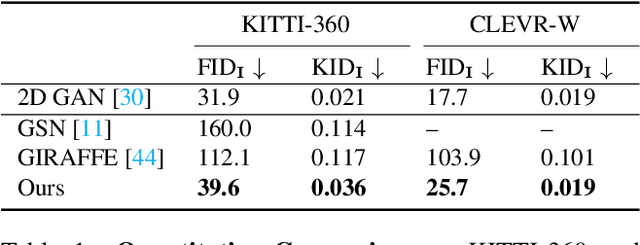
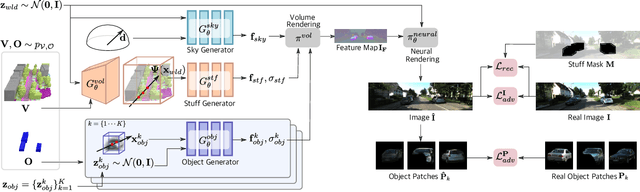
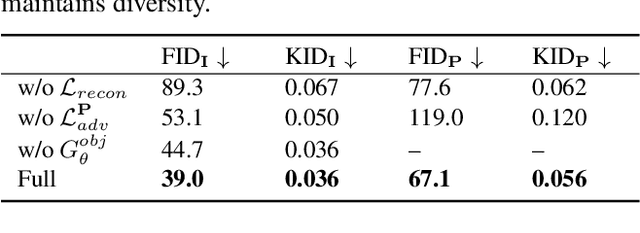
Generating photorealistic images with controllable camera pose and scene contents is essential for many applications including AR/VR and simulation. Despite the fact that rapid progress has been made in 3D-aware generative models, most existing methods focus on object-centric images and are not applicable to generating urban scenes for free camera viewpoint control and scene editing. To address this challenging task, we propose UrbanGIRAFFE, which uses a coarse 3D panoptic prior, including the layout distribution of uncountable stuff and countable objects, to guide a 3D-aware generative model. Our model is compositional and controllable as it breaks down the scene into stuff, objects, and sky. Using stuff prior in the form of semantic voxel grids, we build a conditioned stuff generator that effectively incorporates the coarse semantic and geometry information. The object layout prior further allows us to learn an object generator from cluttered scenes. With proper loss functions, our approach facilitates photorealistic 3D-aware image synthesis with diverse controllability, including large camera movement, stuff editing, and object manipulation. We validate the effectiveness of our model on both synthetic and real-world datasets, including the challenging KITTI-360 dataset.
Starting Conversations with Search Engines -- Interfaces that Elicit Natural Language Queries
Feb 13, 2023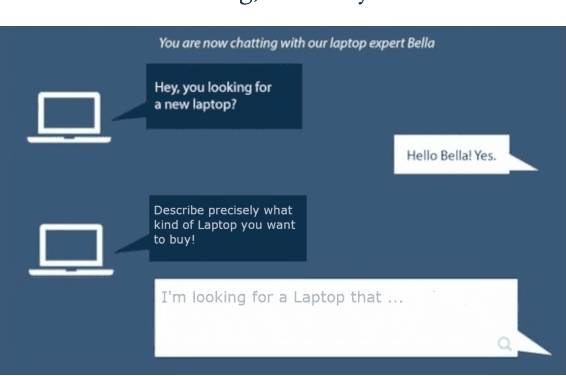
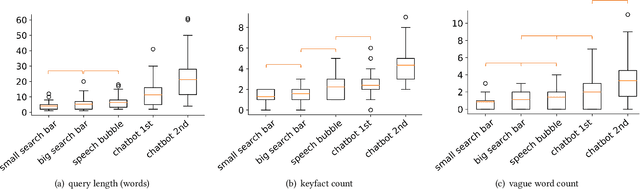
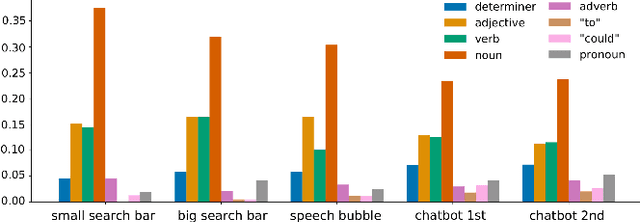
Search systems on the Web rely on user input to generate relevant results. Since early information retrieval systems, users are trained to issue keyword searches and adapt to the language of the system. Recent research has shown that users often withhold detailed information about their initial information need, although they are able to express it in natural language. We therefore conduct a user study (N = 139) to investigate how four different design variants of search interfaces can encourage the user to reveal more information. Our results show that a chatbot-inspired search interface can increase the number of mentioned product attributes by 84% and promote natural language formulations by 139% in comparison to a standard search bar interface.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022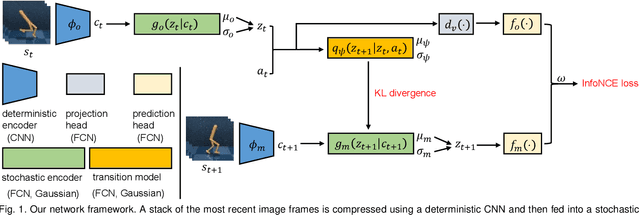
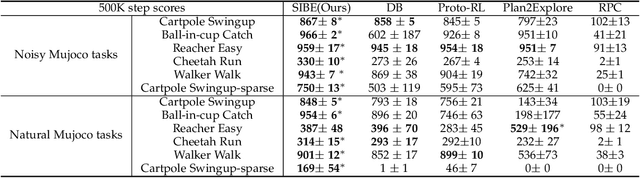
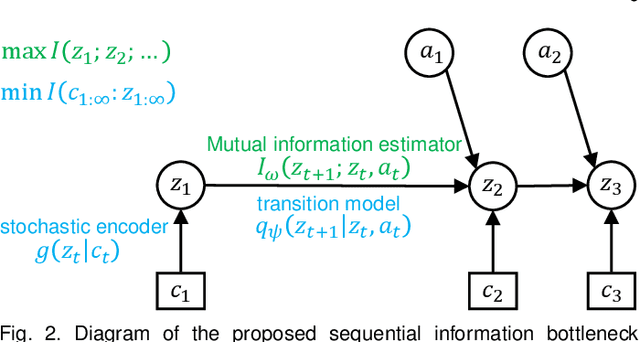

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
Grounding Graph Network Simulators using Physical Sensor Observations
Feb 23, 2023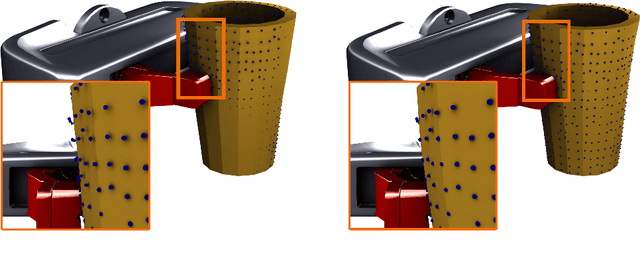

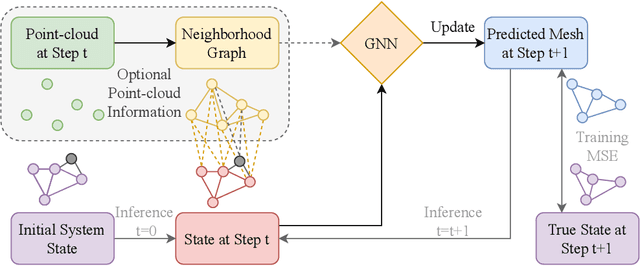
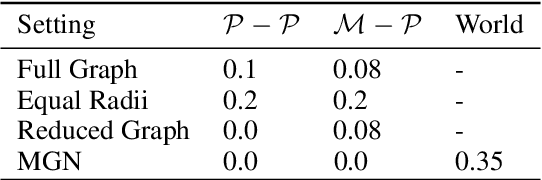
Physical simulations that accurately model reality are crucial for many engineering disciplines such as mechanical engineering and robotic motion planning. In recent years, learned Graph Network Simulators produced accurate mesh-based simulations while requiring only a fraction of the computational cost of traditional simulators. Yet, the resulting predictors are confined to learning from data generated by existing mesh-based simulators and thus cannot include real world sensory information such as point cloud data. As these predictors have to simulate complex physical systems from only an initial state, they exhibit a high error accumulation for long-term predictions. In this work, we integrate sensory information to ground Graph Network Simulators on real world observations. In particular, we predict the mesh state of deformable objects by utilizing point cloud data. The resulting model allows for accurate predictions over longer time horizons, even under uncertainties in the simulation, such as unknown material properties. Since point clouds are usually not available for every time step, especially in online settings, we employ an imputation-based model. The model can make use of such additional information only when provided, and resorts to a standard Graph Network Simulator, otherwise. We experimentally validate our approach on a suite of prediction tasks for mesh-based interactions between soft and rigid bodies. Our method results in utilization of additional point cloud information to accurately predict stable simulations where existing Graph Network Simulators fail.
HopFIR: Hop-wise GraphFormer with Intragroup Joint Refinement for 3D Human Pose Estimation
Feb 28, 2023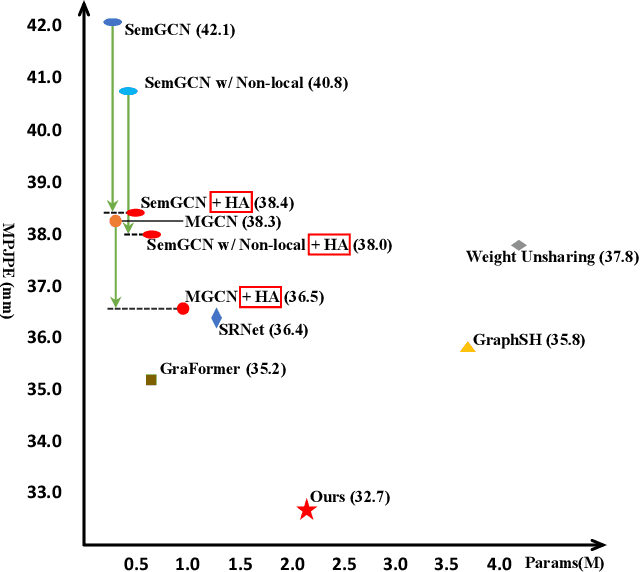
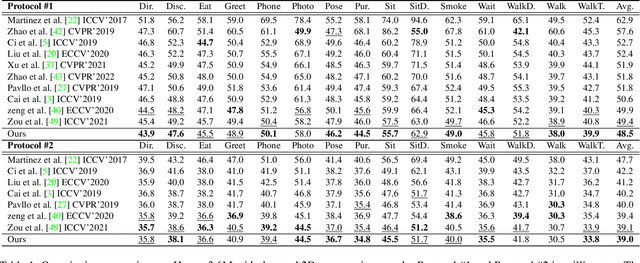
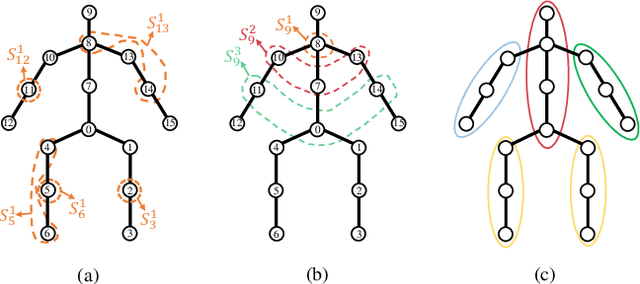
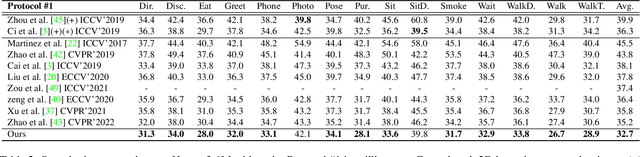
2D-to-3D human pose lifting is fundamental for 3D human pose estimation (HPE). Graph Convolutional Network (GCN) has been proven inherently suitable to model the human skeletal topology. However, current GCN-based 3D HPE methods update the node features by aggregating their neighbors' information without considering the interaction of joints in different motion patterns. Although some studies import limb information to learn the movement patterns, the latent synergies among joints, such as maintaining balance in the motion are seldom investigated. We propose a hop-wise GraphFormer with intragroup joint refinement (HopFIR) to tackle the 3D HPE problem. The HopFIR mainly consists of a novel Hop-wise GraphFormer(HGF) module and an Intragroup Joint Refinement(IJR) module which leverages the prior limb information for peripheral joints refinement. The HGF module groups the joints by $k$-hop neighbors and utilizes a hop-wise transformer-like attention mechanism among these groups to discover latent joint synergy. Extensive experimental results show that HopFIR outperforms the SOTA methods with a large margin (on the Human3.6M dataset, the mean per joint position error (MPJPE) is 32.67mm). Furthermore, it is also demonstrated that previous SOTA GCN-based methods can benefit from the proposed hop-wise attention mechanism efficiently with significant performance promotion, such as SemGCN and MGCN are improved by 8.9% and 4.5%, respectively.