 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Connected Vehicle Trajectory Data to Evaluate the Effects of Speeding
Mar 29, 2023
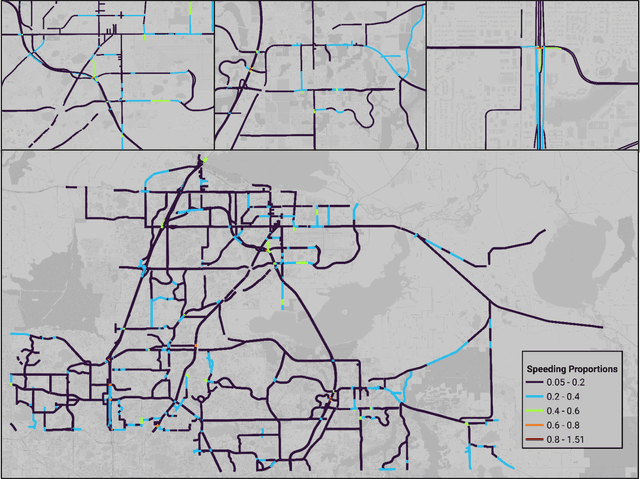
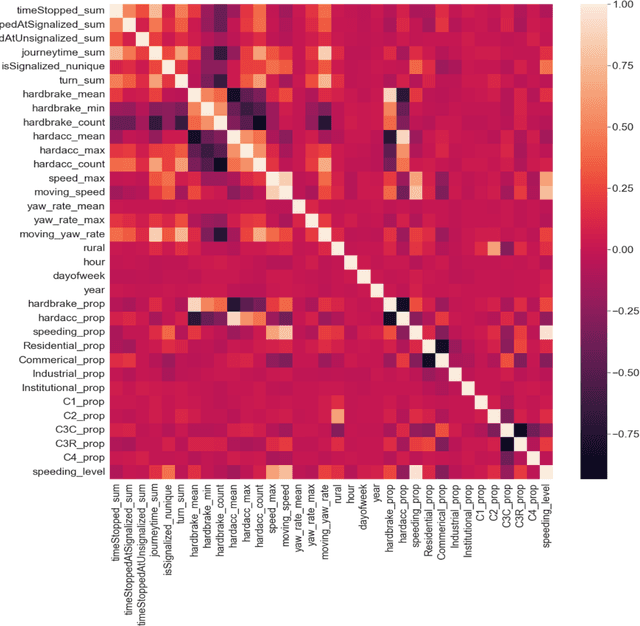
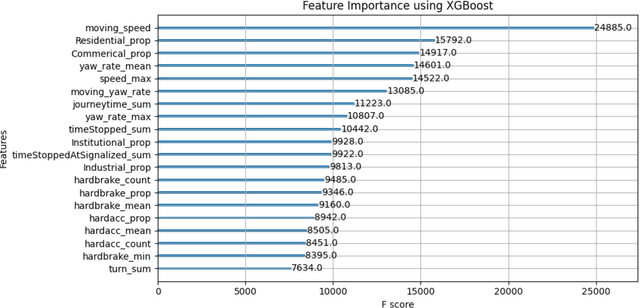
Speeding has been and continues to be a major contributing factor to traffic fatalities. Various transportation agencies have proposed speed management strategies to reduce the amount of speeding on arterials. While there have been various studies done on the analysis of speeding proportions above the speed limit, few studies have considered the effect on the individual's journey. Many studies utilized speed data from detectors, which is limited in that there is no information of the route that the driver took. This study aims to explore the effects of various roadway features an individual experiences for a given journey on speeding proportions. Connected vehicle trajectory data was utilized to identify the path that a driver took, along with the vehicle related variables. The level of speeding proportion is predicted using multiple learning models. The model with the best performance, Extreme Gradient Boosting, achieved an accuracy of 0.756. The proposed model can be used to understand how the environment and vehicle's path effects the drivers' speeding behavior, as well as predict the areas with high levels of speeding proportions. The results suggested that features related to an individual driver's trip, i.e., total travel time, has a significant contribution towards speeding. Features that are related to the environment of the individual driver's trip, i.e., proportion of residential area, also had a significant effect on reducing speeding proportions. It is expected that the findings could help inform transportation agencies more on the factors related to speeding for an individual driver's trip.
Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos
Mar 29, 2023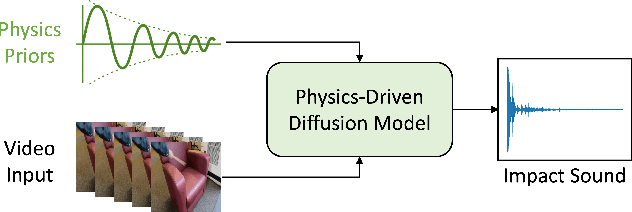
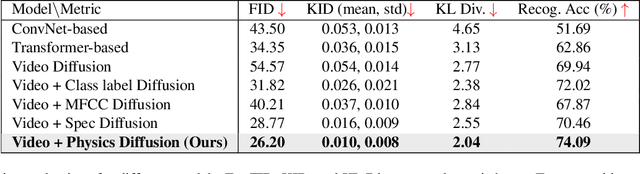
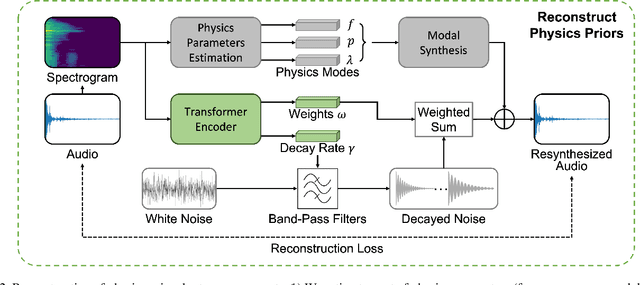
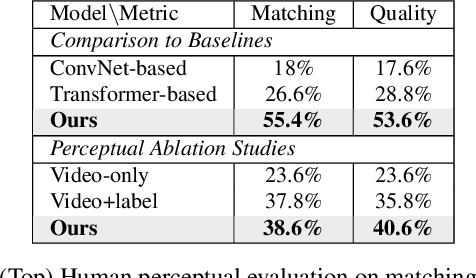
Modeling sounds emitted from physical object interactions is critical for immersive perceptual experiences in real and virtual worlds. Traditional methods of impact sound synthesis use physics simulation to obtain a set of physics parameters that could represent and synthesize the sound. However, they require fine details of both the object geometries and impact locations, which are rarely available in the real world and can not be applied to synthesize impact sounds from common videos. On the other hand, existing video-driven deep learning-based approaches could only capture the weak correspondence between visual content and impact sounds since they lack of physics knowledge. In this work, we propose a physics-driven diffusion model that can synthesize high-fidelity impact sound for a silent video clip. In addition to the video content, we propose to use additional physics priors to guide the impact sound synthesis procedure. The physics priors include both physics parameters that are directly estimated from noisy real-world impact sound examples without sophisticated setup and learned residual parameters that interpret the sound environment via neural networks. We further implement a novel diffusion model with specific training and inference strategies to combine physics priors and visual information for impact sound synthesis. Experimental results show that our model outperforms several existing systems in generating realistic impact sounds. More importantly, the physics-based representations are fully interpretable and transparent, thus enabling us to perform sound editing flexibly.
System theoretic approach of information processing in nested cellular automata
Oct 12, 2022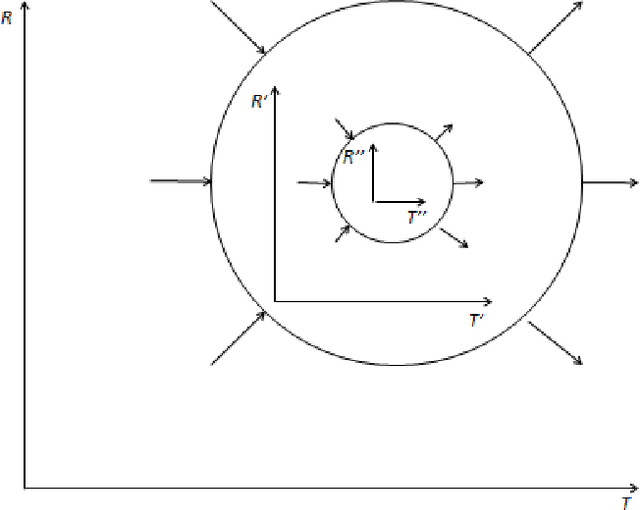
The subject of this paper is the evolution of the concept of information processing in regular structures based on multi-level processing in nested cellular automata. The essence of the proposed model is a discrete space-time containing nested orthogonal space-times at its points. The factorization of the function describing the global behavior of a system is the key element of the mathematical description. Factorization describes the relations of physical connections, signal propagation times and signal processing to global behavior. In the model appear expressions similar to expressions used in the Special Relativity Theory.
Choice Over Control: How Users Write with Large Language Models using Diegetic and Non-Diegetic Prompting
Mar 06, 2023
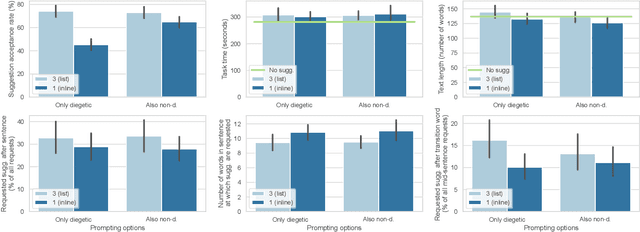

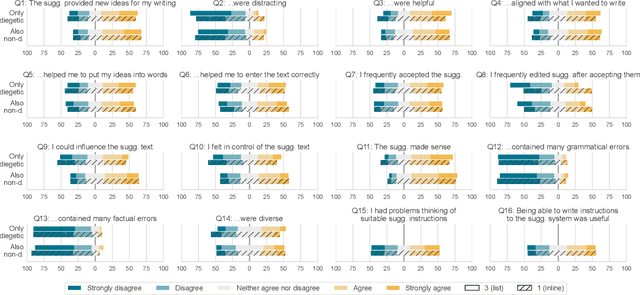
We propose a conceptual perspective on prompts for Large Language Models (LLMs) that distinguishes between (1) diegetic prompts (part of the narrative, e.g. "Once upon a time, I saw a fox..."), and (2) non-diegetic prompts (external, e.g. "Write about the adventures of the fox."). With this lens, we study how 129 crowd workers on Prolific write short texts with different user interfaces (1 vs 3 suggestions, with/out non-diegetic prompts; implemented with GPT-3): When the interface offered multiple suggestions and provided an option for non-diegetic prompting, participants preferred choosing from multiple suggestions over controlling them via non-diegetic prompts. When participants provided non-diegetic prompts it was to ask for inspiration, topics or facts. Single suggestions in particular were guided both with diegetic and non-diegetic information. This work informs human-AI interaction with generative models by revealing that (1) writing non-diegetic prompts requires effort, (2) people combine diegetic and non-diegetic prompting, and (3) they use their draft (i.e. diegetic information) and suggestion timing to strategically guide LLMs.
Learnings from Technological Interventions in a Low Resource Language: Enhancing Information Access in Gondi
Nov 29, 2022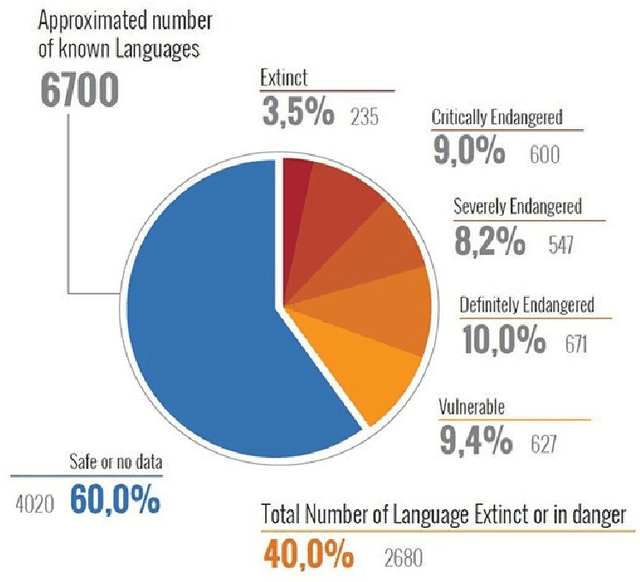
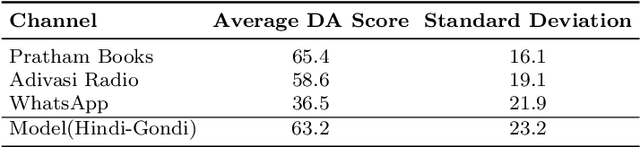

The primary obstacle to developing technologies for low-resource languages is the lack of representative, usable data. In this paper, we report the deployment of technology-driven data collection methods for creating a corpus of more than 60,000 translations from Hindi to Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. During this process, we help expand information access in Gondi across 2 different dimensions (a) The creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, Gondi translations from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform; (b) Enabling its use in the digital domain by developing a Hindi-Gondi machine translation model, which is compressed by nearly 4 times to enable it's edge deployment on low-resource edge devices and in areas of little to no internet connectivity. We also present preliminary evaluations of utilizing the developed machine translation model to provide assistance to volunteers who are involved in collecting more data for the target language. Through these interventions, we not only created a refined and evaluated corpus of 26,240 Hindi-Gondi translations that was used for building the translation model but also engaged nearly 850 community members who can help take Gondi onto the internet.
Mechanism Design for Ad Auctions with Display Prices
Mar 23, 2023In many applications, ads are displayed together with the prices, so as to provide a direct comparison among similar products or services. The price-displaying feature not only influences the consumers' decisions, but also affects the advertisers' bidding behaviors. In this paper, we study ad auctions with display prices from the perspective of mechanism design, in which advertisers are asked to submit both the costs and prices of their products. We provide a characterization for all incentive compatible auctions with display prices, and use it to design auctions under two scenarios. In the former scenario, the display prices are assumed to be exogenously determined. For this setting, we derive the welfare-maximizing and revenue-maximizing auctions for any realization of the price profile. In the latter, advertisers are allowed to strategize display prices in their own interests. We investigate two families of allocation policies within the scenario and identify the equilibrium prices accordingly. Our results reveal that the display prices do affect the design of ad auctions and the platform can leverage such information to optimize the performance of ad delivery.
Improving Generalization with Domain Convex Game
Mar 23, 2023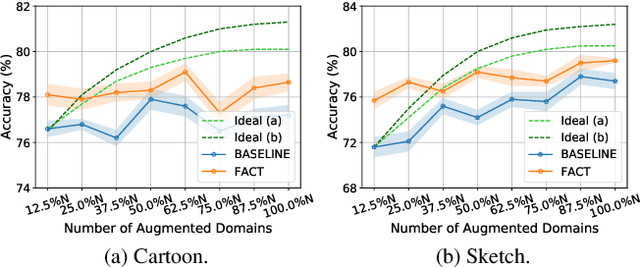

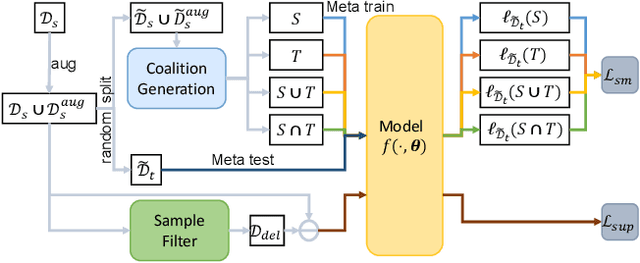
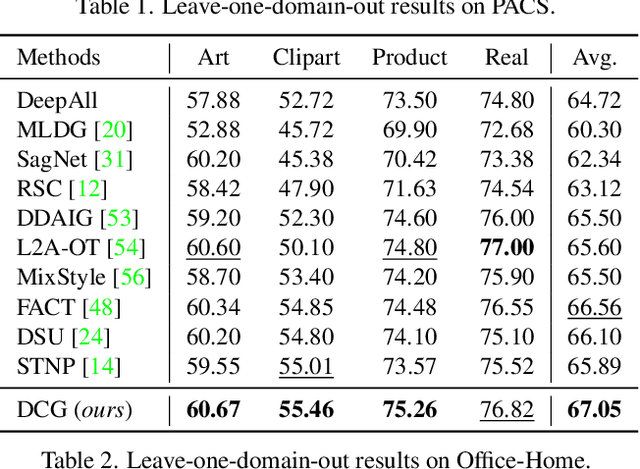
Domain generalization (DG) tends to alleviate the poor generalization capability of deep neural networks by learning model with multiple source domains. A classical solution to DG is domain augmentation, the common belief of which is that diversifying source domains will be conducive to the out-of-distribution generalization. However, these claims are understood intuitively, rather than mathematically. Our explorations empirically reveal that the correlation between model generalization and the diversity of domains may be not strictly positive, which limits the effectiveness of domain augmentation. This work therefore aim to guarantee and further enhance the validity of this strand. To this end, we propose a new perspective on DG that recasts it as a convex game between domains. We first encourage each diversified domain to enhance model generalization by elaborately designing a regularization term based on supermodularity. Meanwhile, a sample filter is constructed to eliminate low-quality samples, thereby avoiding the impact of potentially harmful information. Our framework presents a new avenue for the formal analysis of DG, heuristic analysis and extensive experiments demonstrate the rationality and effectiveness.
Orthogonal Annotation Benefits Barely-supervised Medical Image Segmentation
Mar 23, 2023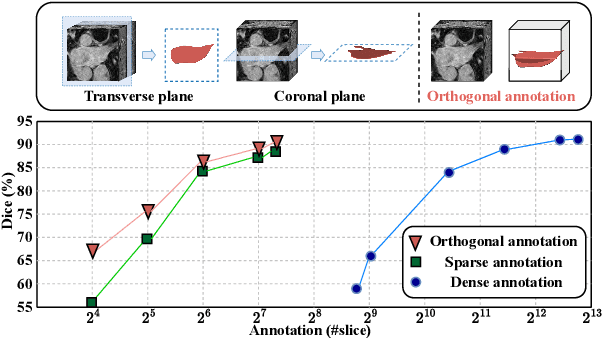
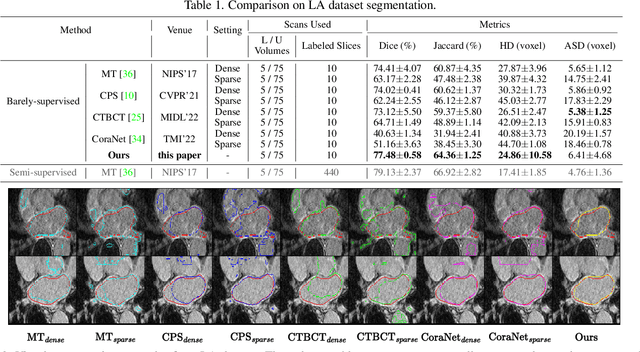
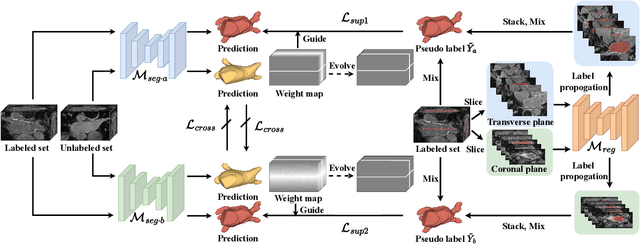
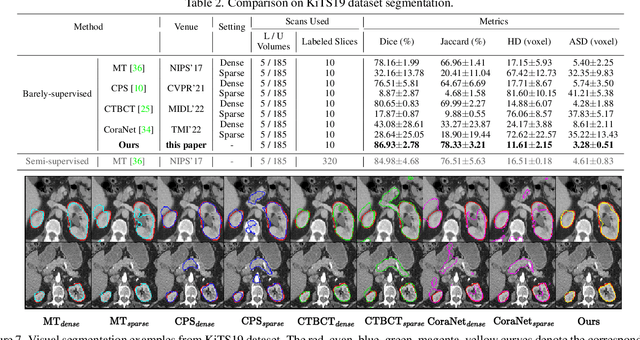
Recent trends in semi-supervised learning have significantly boosted the performance of 3D semi-supervised medical image segmentation. Compared with 2D images, 3D medical volumes involve information from different directions, e.g., transverse, sagittal, and coronal planes, so as to naturally provide complementary views. These complementary views and the intrinsic similarity among adjacent 3D slices inspire us to develop a novel annotation way and its corresponding semi-supervised model for effective segmentation. Specifically, we firstly propose the orthogonal annotation by only labeling two orthogonal slices in a labeled volume, which significantly relieves the burden of annotation. Then, we perform registration to obtain the initial pseudo labels for sparsely labeled volumes. Subsequently, by introducing unlabeled volumes, we propose a dual-network paradigm named Dense-Sparse Co-training (DeSCO) that exploits dense pseudo labels in early stage and sparse labels in later stage and meanwhile forces consistent output of two networks. Experimental results on three benchmark datasets validated our effectiveness in performance and efficiency in annotation. For example, with only 10 annotated slices, our method reaches a Dice up to 86.93% on KiTS19 dataset.
Upper Bound of Real Log Canonical Threshold of Tensor Decomposition and its Application to Bayesian Inference
Mar 10, 2023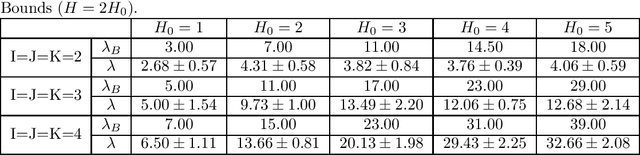
Tensor decomposition is now being used for data analysis, information compression, and knowledge recovery. However, the mathematical property of tensor decomposition is not yet fully clarified because it is one of singular learning machines. In this paper, we give the upper bound of its real log canonical threshold (RLCT) of the tensor decomposition by using an algebraic geometrical method and derive its Bayesian generalization error theoretically. We also give considerations about its mathematical property through numerical experiments.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023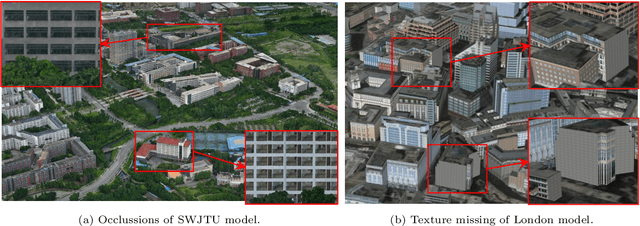
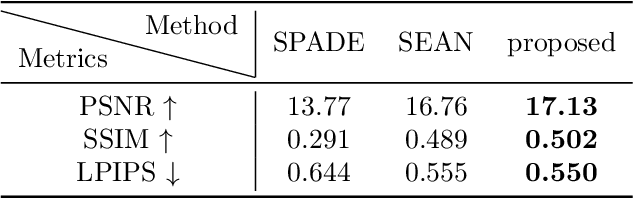
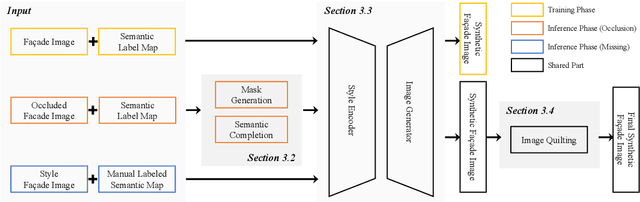

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.