 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Splitting Receiver with Multiple Antennas
Mar 08, 2023
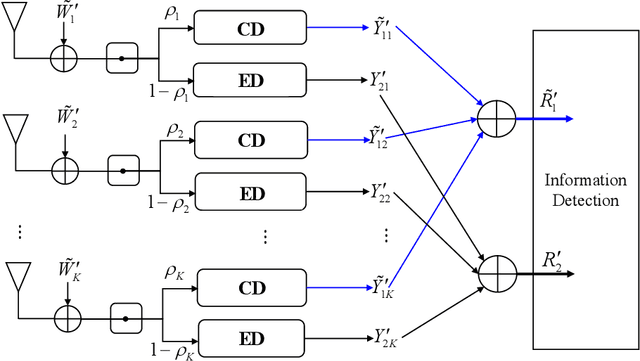
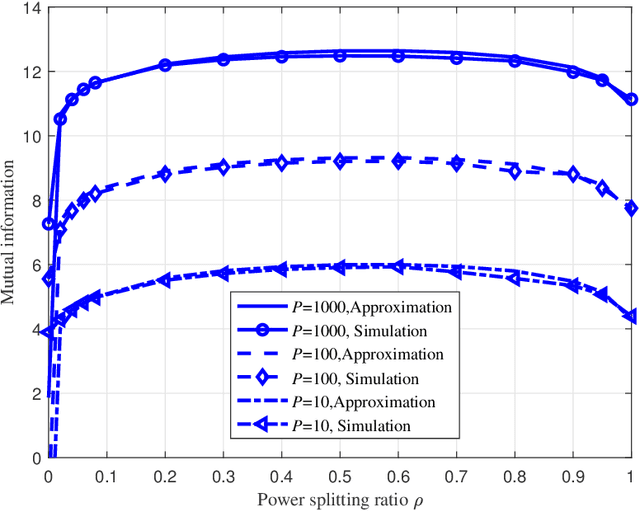
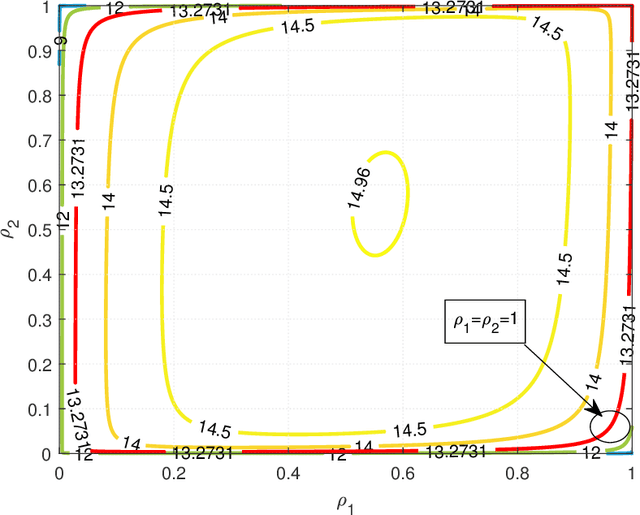
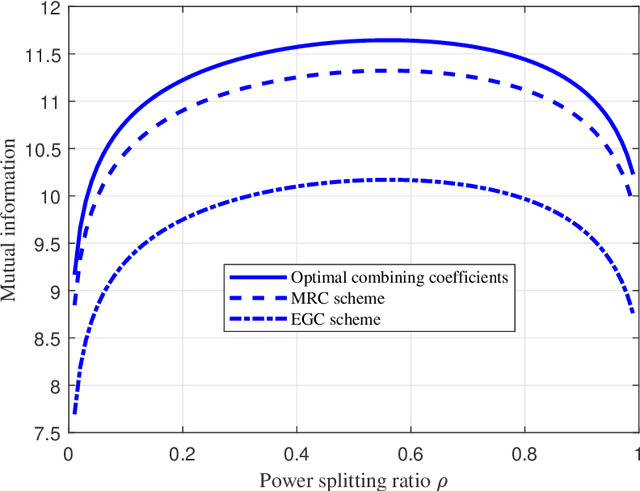
Recently proposed splitting receivers, utilizing both coherently and non-coherently processed signals for detection, have demonstrated remarkable performance gain compared to conventional receivers in the single-antenna scenario. In this paper, we propose a multi-antenna splitting receiver, where the received signal at each antenna is split into an envelope detection (ED) branch and a coherent detection (CD) branch, and the processed signals from both branches of all antennas are then jointly utilized for recovering the transmitted information. We derive a closed-form approximation of the achievable mutual information (MI) in terms of the key receiver design parameters, including the power splitting ratio at each antenna and the signal combining coefficients from all the ED and CD branches. We further optimize these receiver design parameters and demonstrate important design insights for the proposed multi-antenna ED-CD splitting receiver: 1) the optimal splitting ratio is identical at each antenna, and 2) the optimal combining coefficients for the ED and CD branches are the same, and each coefficient is proportional to the corresponding antenna's channel power gain. Our numerical results also demonstrate the MI performance improvement of the proposed receiver over conventional non-splitting receivers.
ProxyFormer: Proxy Alignment Assisted Point Cloud Completion with Missing Part Sensitive Transformer
Feb 28, 2023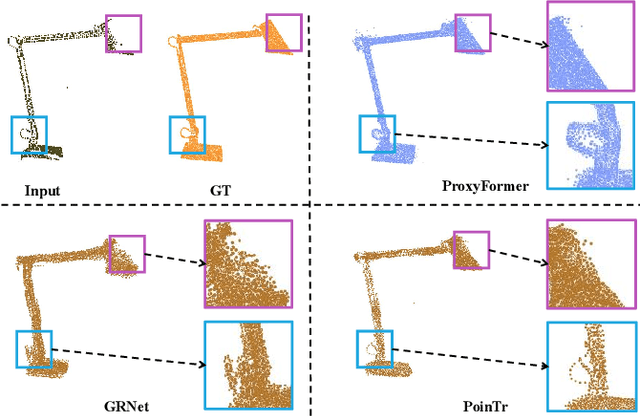
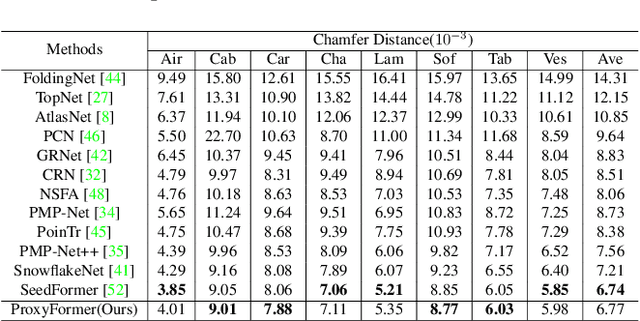

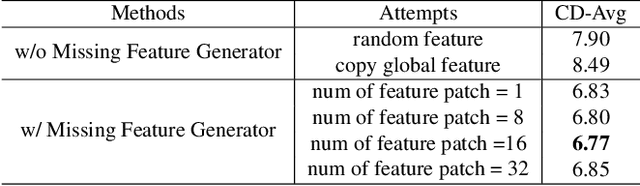
Problems such as equipment defects or limited viewpoints will lead the captured point clouds to be incomplete. Therefore, recovering the complete point clouds from the partial ones plays an vital role in many practical tasks, and one of the keys lies in the prediction of the missing part. In this paper, we propose a novel point cloud completion approach namely ProxyFormer that divides point clouds into existing (input) and missing (to be predicted) parts and each part communicates information through its proxies. Specifically, we fuse information into point proxy via feature and position extractor, and generate features for missing point proxies from the features of existing point proxies. Then, in order to better perceive the position of missing points, we design a missing part sensitive transformer, which converts random normal distribution into reasonable position information, and uses proxy alignment to refine the missing proxies. It makes the predicted point proxies more sensitive to the features and positions of the missing part, and thus make these proxies more suitable for subsequent coarse-to-fine processes. Experimental results show that our method outperforms state-of-the-art completion networks on several benchmark datasets and has the fastest inference speed. Code is available at https://github.com/I2-Multimedia-Lab/ProxyFormer.
Applying unsupervised keyphrase methods on concepts extracted from discharge sheets
Mar 15, 2023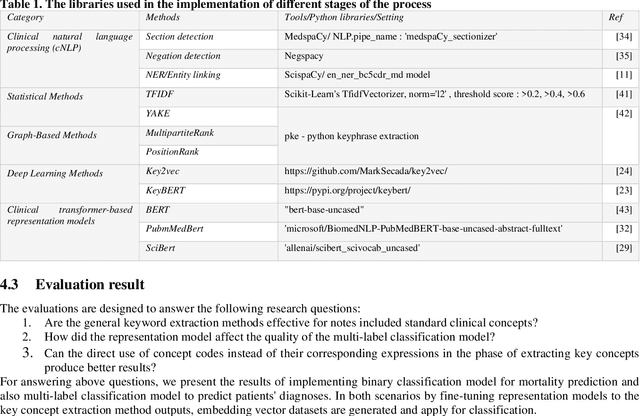
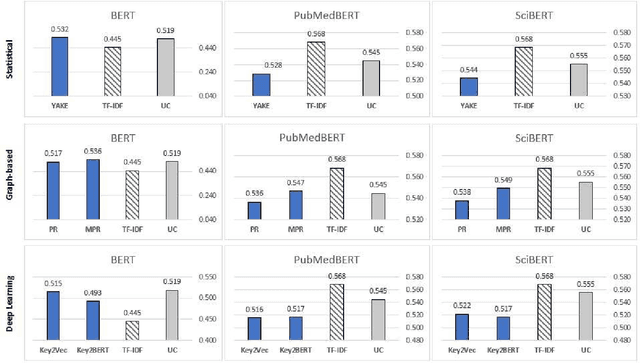
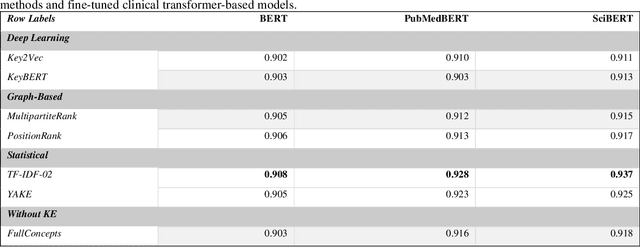
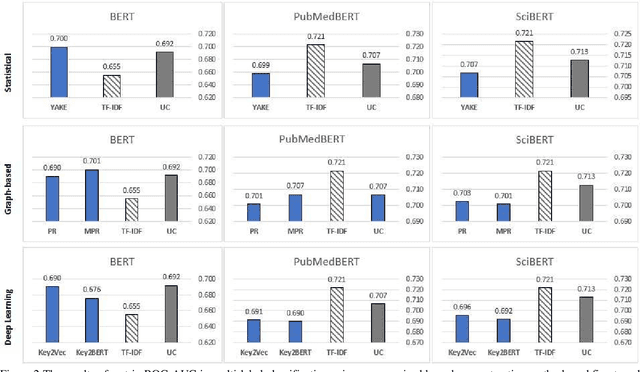
Clinical notes containing valuable patient information are written by different health care providers with various scientific levels and writing styles. It might be helpful for clinicians and researchers to understand what information is essential when dealing with extensive electronic medical records. Entities recognizing and mapping them to standard terminologies is crucial in reducing ambiguity in processing clinical notes. Although named entity recognition and entity linking are critical steps in clinical natural language processing, they can also result in the production of repetitive and low-value concepts. In other hand, all parts of a clinical text do not share the same importance or content in predicting the patient's condition. As a result, it is necessary to identify the section in which each content is recorded and also to identify key concepts to extract meaning from clinical texts. In this study, these challenges have been addressed by using clinical natural language processing techniques. In addition, in order to identify key concepts, a set of popular unsupervised key phrase extraction methods has been verified and evaluated. Considering that most of the clinical concepts are in the form of multi-word expressions and their accurate identification requires the user to specify n-gram range, we have proposed a shortcut method to preserve the structure of the expression based on TF-IDF. In order to evaluate the pre-processing method and select the concepts, we have designed two types of downstream tasks (multiple and binary classification) using the capabilities of transformer-based models. The obtained results show the superiority of proposed method in combination with SciBERT model, also offer an insight into the efficacy of general extracting essential phrase methods for clinical notes.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 15, 2023
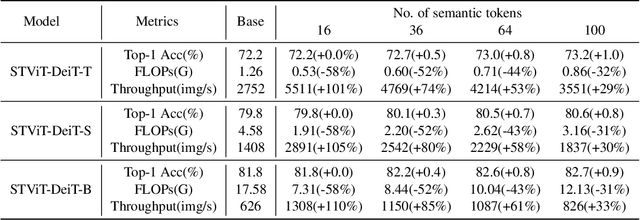
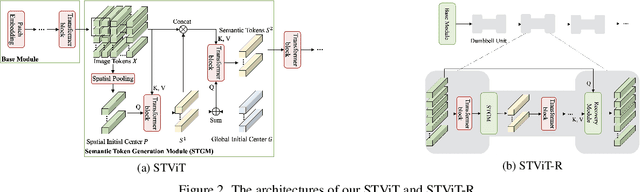
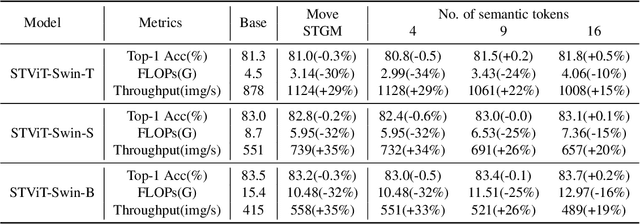
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone.
Self-Asymmetric Invertible Network for Compression-Aware Image Rescaling
Mar 11, 2023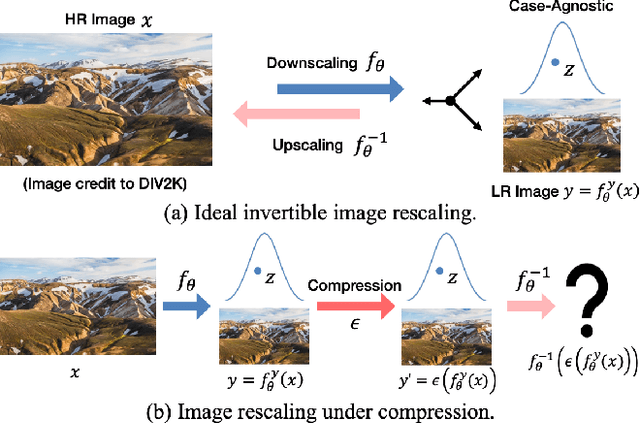
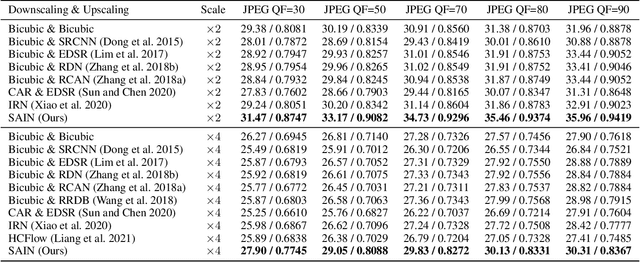
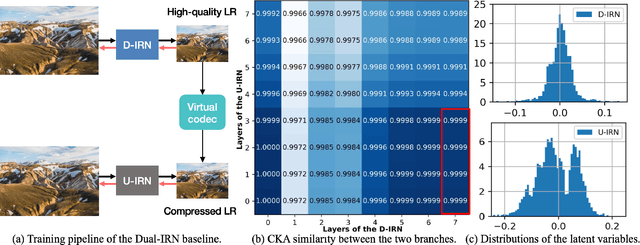
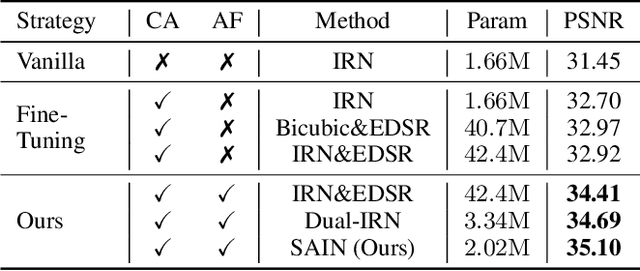
High-resolution (HR) images are usually downscaled to low-resolution (LR) ones for better display and afterward upscaled back to the original size to recover details. Recent work in image rescaling formulates downscaling and upscaling as a unified task and learns a bijective mapping between HR and LR via invertible networks. However, in real-world applications (e.g., social media), most images are compressed for transmission. Lossy compression will lead to irreversible information loss on LR images, hence damaging the inverse upscaling procedure and degrading the reconstruction accuracy. In this paper, we propose the Self-Asymmetric Invertible Network (SAIN) for compression-aware image rescaling. To tackle the distribution shift, we first develop an end-to-end asymmetric framework with two separate bijective mappings for high-quality and compressed LR images, respectively. Then, based on empirical analysis of this framework, we model the distribution of the lost information (including downscaling and compression) using isotropic Gaussian mixtures and propose the Enhanced Invertible Block to derive high-quality/compressed LR images in one forward pass. Besides, we design a set of losses to regularize the learned LR images and enhance the invertibility. Extensive experiments demonstrate the consistent improvements of SAIN across various image rescaling datasets in terms of both quantitative and qualitative evaluation under standard image compression formats (i.e., JPEG and WebP).
Data Fusion for Multipath-Based SLAM: Combing Information from Multiple Propagation Paths
Nov 24, 2022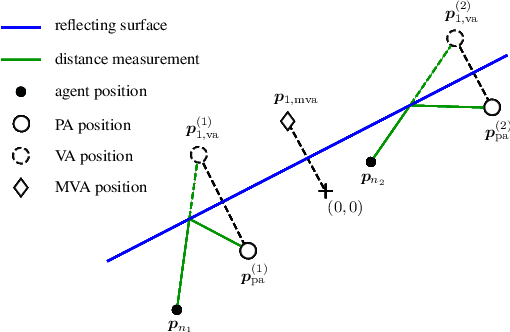
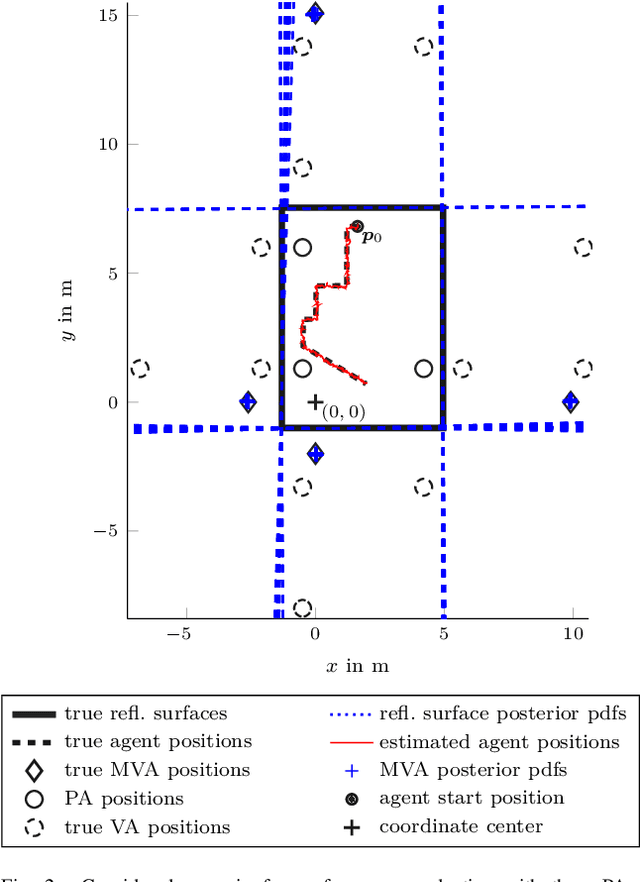
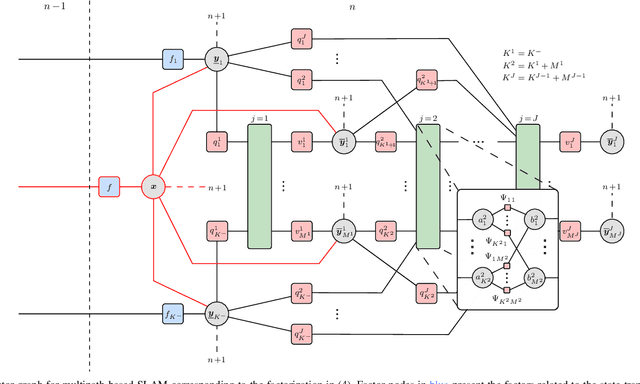
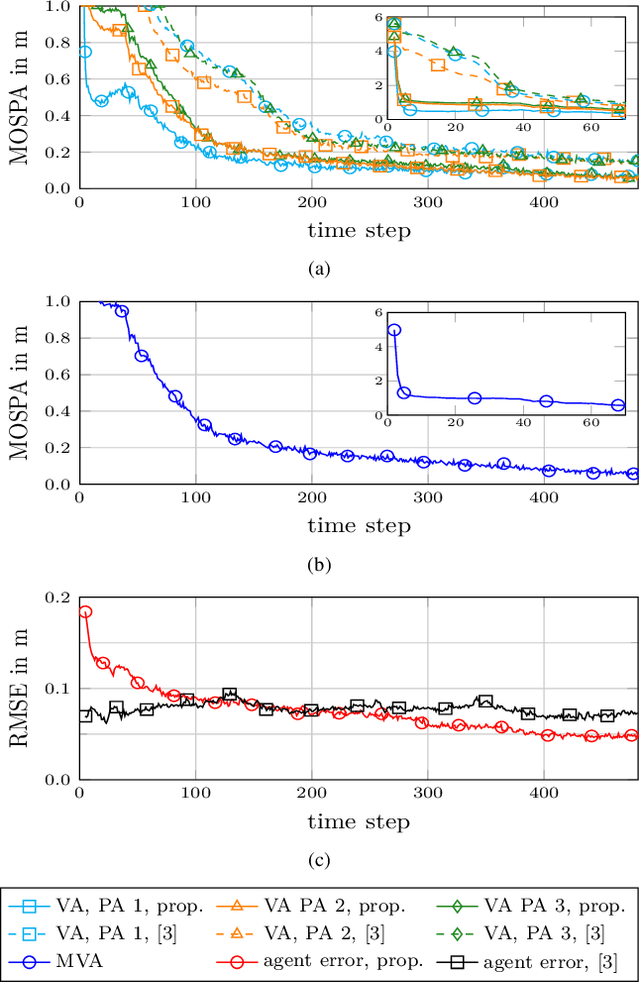
Multipath-based simultaneous localization and mapping (SLAM) is an emerging paradigm for accurate indoor localization with limited resources. The goal of multipath-based SLAM is to detect and localize radio reflective surfaces to support the estimation of time-varying positions of mobile agents. Radio reflective surfaces are typically represented by so-called virtual anchors (VAs), which are mirror images of base stations at the surfaces. In existing multipath-based SLAM methods, a VA is introduced for each propagation path, even if the goal is to map the reflective surfaces. The fact that not every reflective surface but every propagation path is modeled by a VA, complicates a consistent combination "fusion" of statistical information across multiple paths and base stations and thus limits the accuracy and mapping speed of existing multipath-based SLAM methods. In this paper, we introduce an improved statistical model and estimation method that enables data fusion for multipath-based SLAM by representing each surface by a single master virtual anchor (MVA). We further develop a particle-based sum-product algorithm (SPA) that performs probabilistic data association to compute marginal posterior distributions of MVA and agent positions efficiently. A key aspect of the proposed estimation method based on MVAs is to check the availability of single-bounce and double-bounce propagation paths at a specific agent position by means of ray-launching. The availability check is directly integrated into the statistical model by providing detection probabilities for probabilistic data association. Our numerical simulation results demonstrate significant improvements in estimation accuracy and mapping speed compared to state-of-the-art multipath-based SLAM methods.
Speech Privacy Leakage from Shared Gradients in Distributed Learning
Feb 21, 2023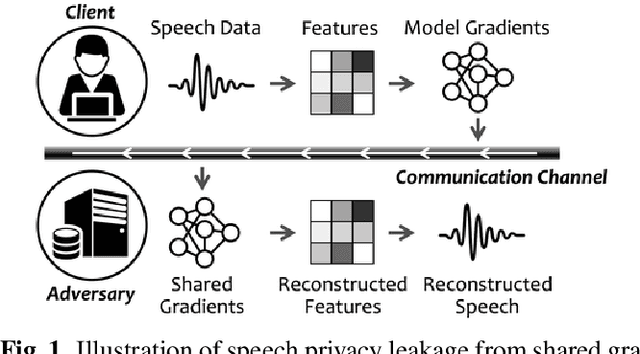
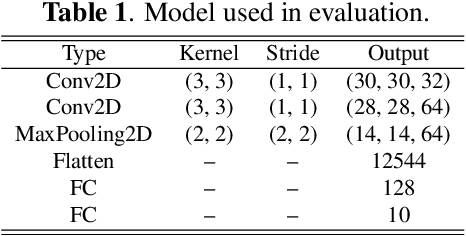
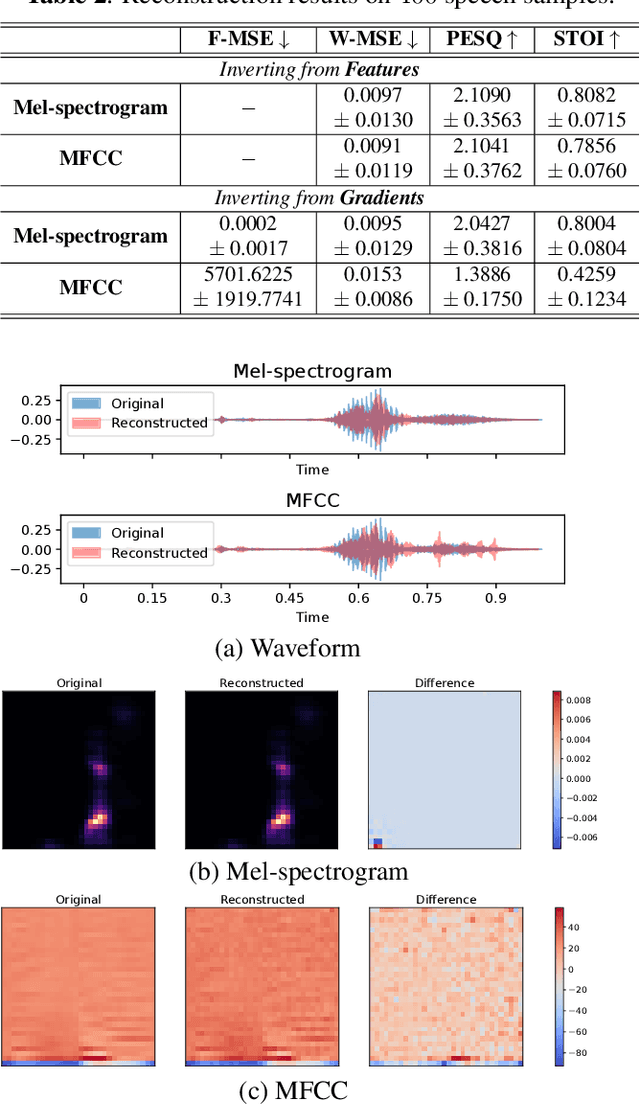
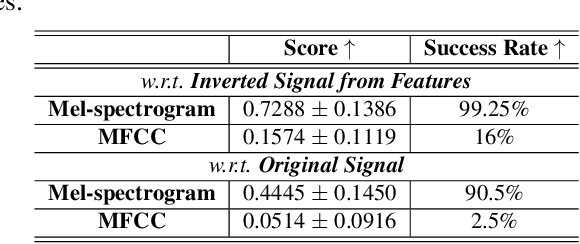
Distributed machine learning paradigms, such as federated learning, have been recently adopted in many privacy-critical applications for speech analysis. However, such frameworks are vulnerable to privacy leakage attacks from shared gradients. Despite extensive efforts in the image domain, the exploration of speech privacy leakage from gradients is quite limited. In this paper, we explore methods for recovering private speech/speaker information from the shared gradients in distributed learning settings. We conduct experiments on a keyword spotting model with two different types of speech features to quantify the amount of leaked information by measuring the similarity between the original and recovered speech signals. We further demonstrate the feasibility of inferring various levels of side-channel information, including speech content and speaker identity, under the distributed learning framework without accessing the user's data.
STILN: A Novel Spatial-Temporal Information Learning Network for EEG-based Emotion Recognition
Nov 22, 2022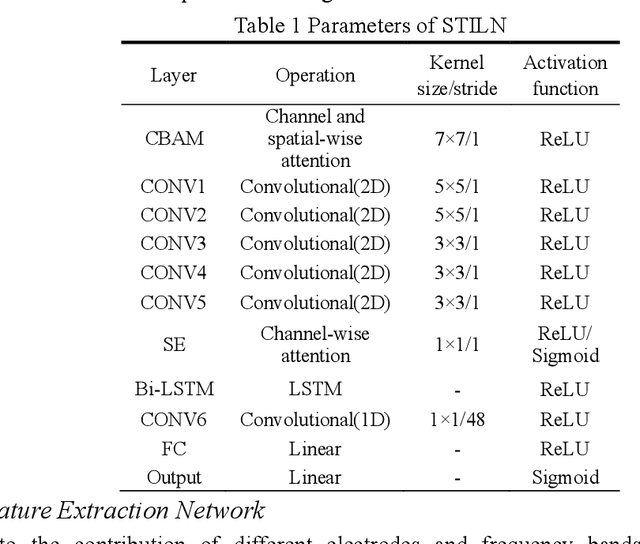
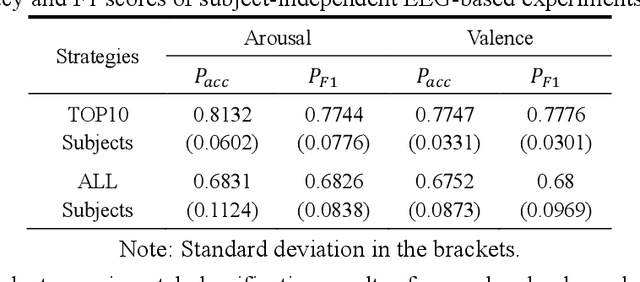
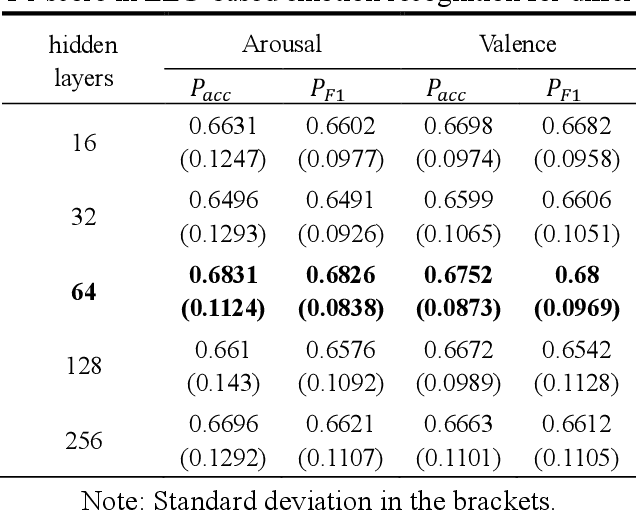
The spatial correlations and the temporal contexts are indispensable in Electroencephalogram (EEG)-based emotion recognition. However, the learning of complex spatial correlations among several channels is a challenging problem. Besides, the temporal contexts learning is beneficial to emphasize the critical EEG frames because the subjects only reach the prospective emotion during part of stimuli. Hence, we propose a novel Spatial-Temporal Information Learning Network (STILN) to extract the discriminative features by capturing the spatial correlations and temporal contexts. Specifically, the generated 2D power topographic maps capture the dependencies among electrodes, and they are fed to the CNN-based spatial feature extraction network. Furthermore, Convolutional Block Attention Module (CBAM) recalibrates the weights of power topographic maps to emphasize the crucial brain regions and frequency bands. Meanwhile, Batch Normalizations (BNs) and Instance Normalizations (INs) are appropriately combined to relieve the individual differences. In the temporal contexts learning, we adopt the Bidirectional Long Short-Term Memory Network (Bi-LSTM) network to capture the dependencies among the EEG frames. To validate the effectiveness of the proposed method, subject-independent experiments are conducted on the public DEAP dataset. The proposed method has achieved the outstanding performance, and the accuracies of arousal and valence classification have reached 0.6831 and 0.6752 respectively.
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 17, 2023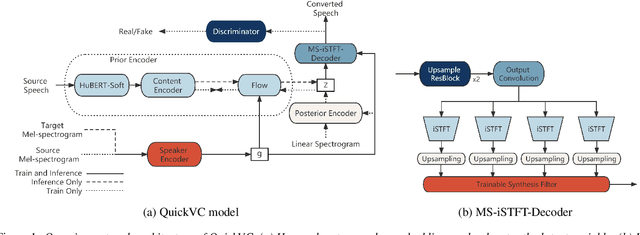
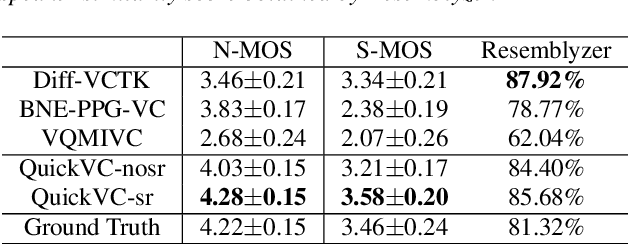

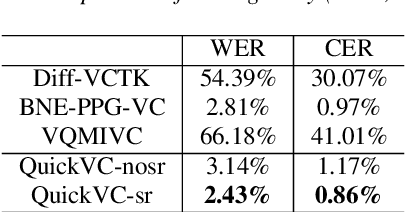
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Efficient Information Sharing in ICT Supply Chain Social Network via Table Structure Recognition
Nov 03, 2022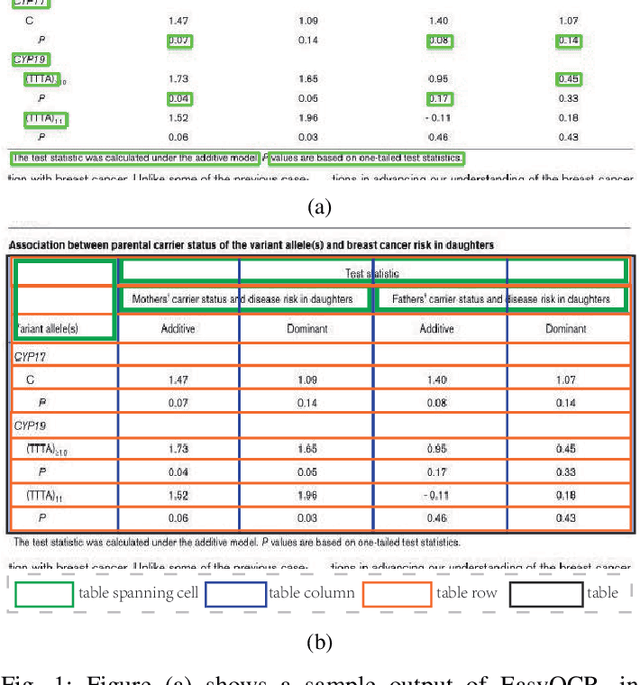
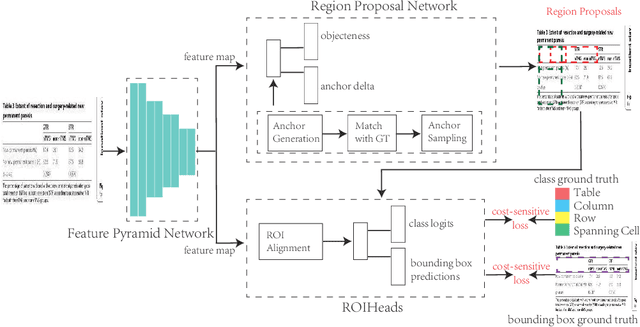
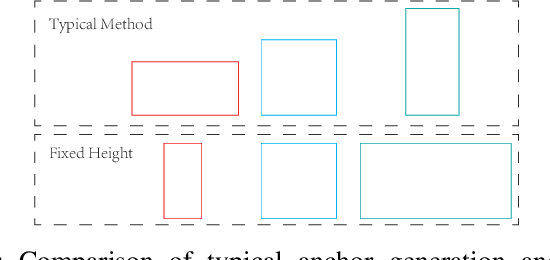
The global Information and Communications Technology (ICT) supply chain is a complex network consisting of all types of participants. It is often formulated as a Social Network to discuss the supply chain network's relations, properties, and development in supply chain management. Information sharing plays a crucial role in improving the efficiency of the supply chain, and datasheets are the most common data format to describe e-component commodities in the ICT supply chain because of human readability. However, with the surging number of electronic documents, it has been far beyond the capacity of human readers, and it is also challenging to process tabular data automatically because of the complex table structures and heterogeneous layouts. Table Structure Recognition (TSR) aims to represent tables with complex structures in a machine-interpretable format so that the tabular data can be processed automatically. In this paper, we formulate TSR as an object detection problem and propose to generate an intuitive representation of a complex table structure to enable structuring of the tabular data related to the commodities. To cope with border-less and small layouts, we propose a cost-sensitive loss function by considering the detection difficulty of each class. Besides, we propose a novel anchor generation method using the character of tables that columns in a table should share an identical height, and rows in a table should share the same width. We implement our proposed method based on Faster-RCNN and achieve 94.79% on mean Average Precision (AP), and consistently improve more than 1.5% AP for different benchmark models.