 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Reinforcement Learning-based Large-scale Robot Exploration
Mar 16, 2024

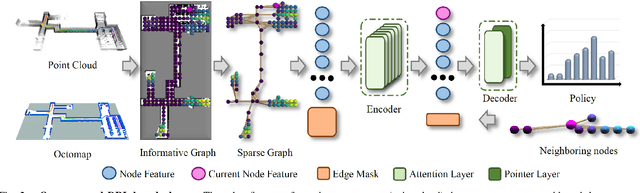
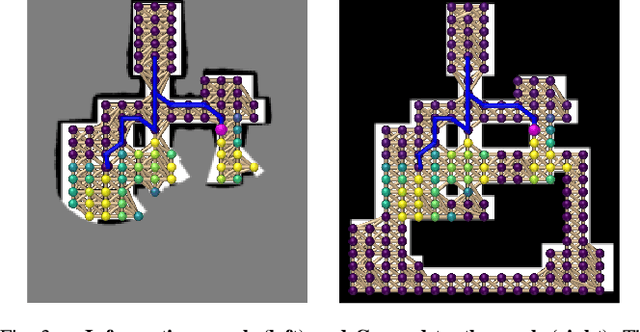
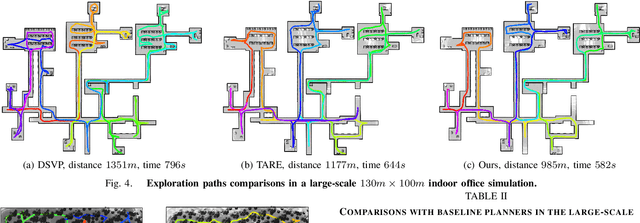
In this work, we propose a deep reinforcement learning (DRL) based reactive planner to solve large-scale Lidar-based autonomous robot exploration problems in 2D action space. Our DRL-based planner allows the agent to reactively plan its exploration path by making implicit predictions about unknown areas, based on a learned estimation of the underlying transition model of the environment. To this end, our approach relies on learned attention mechanisms for their powerful ability to capture long-term dependencies at different spatial scales to reason about the robot's entire belief over known areas. Our approach relies on ground truth information (i.e., privileged learning) to guide the environment estimation during training, as well as on a graph rarefaction algorithm, which allows models trained in small-scale environments to scale to large-scale ones. Simulation results show that our model exhibits better exploration efficiency (12% in path length, 6% in makespan) and lower planning time (60%) than the state-of-the-art planners in a 130m x 100m benchmark scenario. We also validate our learned model on hardware.
HCF-Net: Hierarchical Context Fusion Network for Infrared Small Object Detection
Mar 16, 2024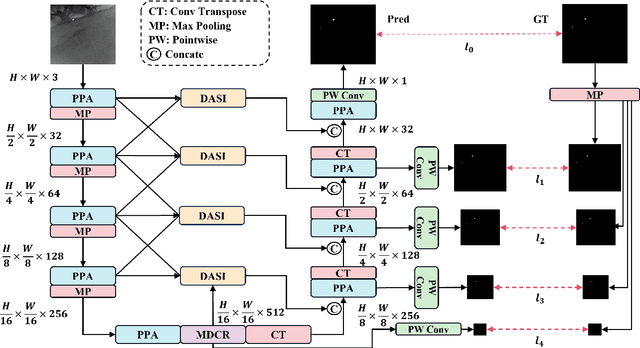
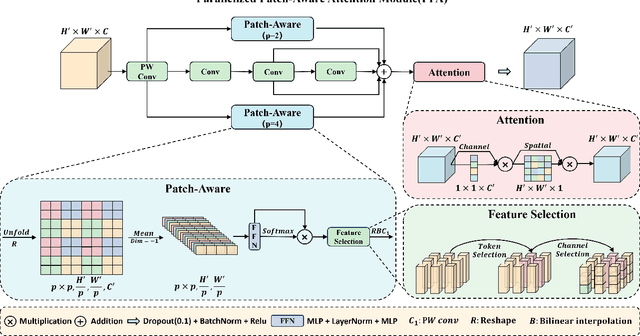
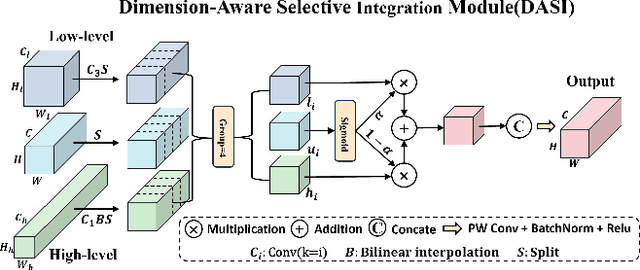
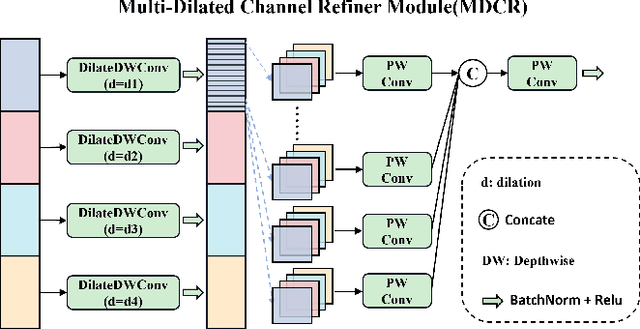
Infrared small object detection is an important computer vision task involving the recognition and localization of tiny objects in infrared images, which usually contain only a few pixels. However, it encounters difficulties due to the diminutive size of the objects and the generally complex backgrounds in infrared images. In this paper, we propose a deep learning method, HCF-Net, that significantly improves infrared small object detection performance through multiple practical modules. Specifically, it includes the parallelized patch-aware attention (PPA) module, dimension-aware selective integration (DASI) module, and multi-dilated channel refiner (MDCR) module. The PPA module uses a multi-branch feature extraction strategy to capture feature information at different scales and levels. The DASI module enables adaptive channel selection and fusion. The MDCR module captures spatial features of different receptive field ranges through multiple depth-separable convolutional layers. Extensive experimental results on the SIRST infrared single-frame image dataset show that the proposed HCF-Net performs well, surpassing other traditional and deep learning models. Code is available at https://github.com/zhengshuchen/HCFNet.
Match-Stereo-Videos: Bidirectional Alignment for Consistent Dynamic Stereo Matching
Mar 16, 2024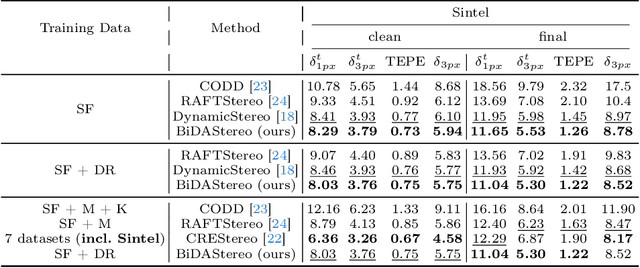
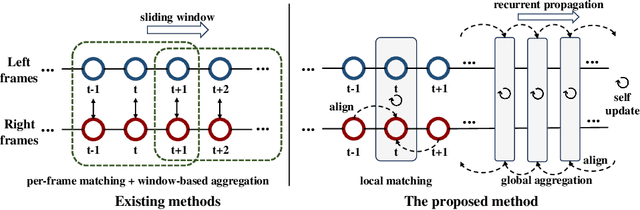
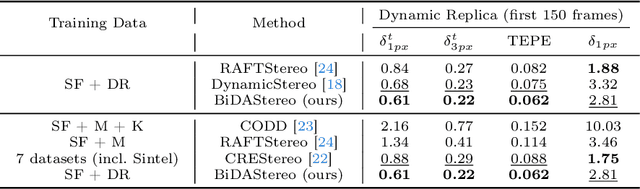
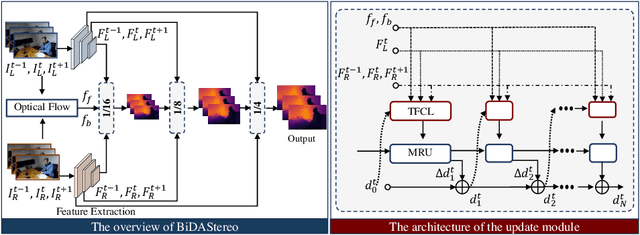
Dynamic stereo matching is the task of estimating consistent disparities from stereo videos with dynamic objects. Recent learning-based methods prioritize optimal performance on a single stereo pair, resulting in temporal inconsistencies. Existing video methods apply per-frame matching and window-based cost aggregation across the time dimension, leading to low-frequency oscillations at the scale of the window size. Towards this challenge, we develop a bidirectional alignment mechanism for adjacent frames as a fundamental operation. We further propose a novel framework, BiDAStereo, that achieves consistent dynamic stereo matching. Unlike the existing methods, we model this task as local matching and global aggregation. Locally, we consider correlation in a triple-frame manner to pool information from adjacent frames and improve the temporal consistency. Globally, to exploit the entire sequence's consistency and extract dynamic scene cues for aggregation, we develop a motion-propagation recurrent unit. Extensive experiments demonstrate the performance of our method, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks.
Integrating Wearable Sensor Data and Self-reported Diaries for Personalized Affect Forecasting
Mar 16, 2024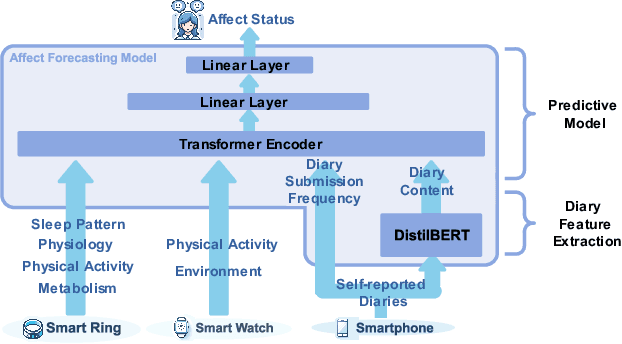
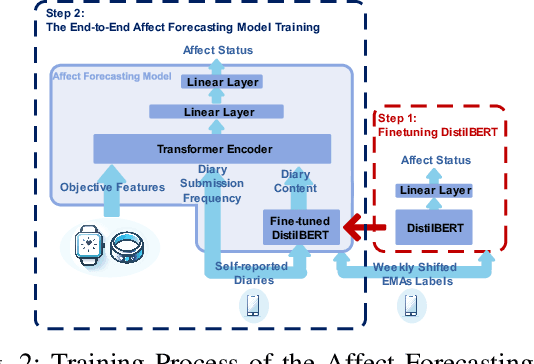
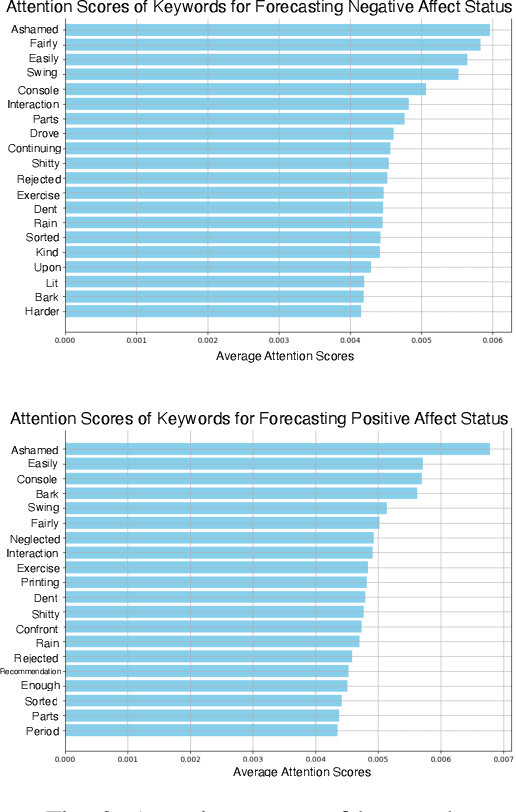
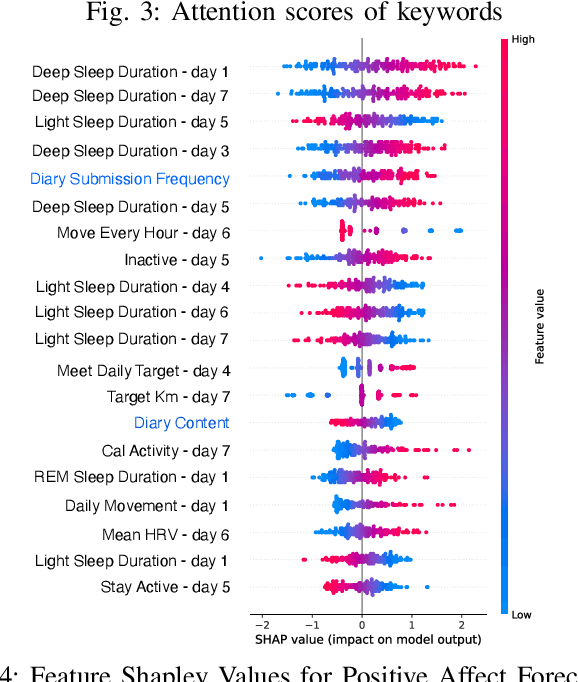
Emotional states, as indicators of affect, are pivotal to overall health, making their accurate prediction before onset crucial. Current studies are primarily centered on immediate short-term affect detection using data from wearable and mobile devices. These studies typically focus on objective sensory measures, often neglecting other forms of self-reported information like diaries and notes. In this paper, we propose a multimodal deep learning model for affect status forecasting. This model combines a transformer encoder with a pre-trained language model, facilitating the integrated analysis of objective metrics and self-reported diaries. To validate our model, we conduct a longitudinal study, enrolling college students and monitoring them over a year, to collect an extensive dataset including physiological, environmental, sleep, metabolic, and physical activity parameters, alongside open-ended textual diaries provided by the participants. Our results demonstrate that the proposed model achieves predictive accuracy of 82.50% for positive affect and 82.76% for negative affect, a full week in advance. The effectiveness of our model is further elevated by its explainability.
Fisher Mask Nodes for Language Model Merging
Mar 14, 2024
Fine-tuning pre-trained models provides significant advantages in downstream performance. The ubiquitous nature of pre-trained models such as BERT and its derivatives in natural language processing has also led to a proliferation of task-specific fine-tuned models. As these models typically only perform one task well, additional training or ensembling is required in multi-task scenarios. The growing field of model merging provides a solution, dealing with the challenge of combining multiple task-specific models into a single multi-task model. In this study, we introduce a novel model merging method for Transformers, combining insights from previous work in Fisher-weighted averaging and the use of Fisher information in model pruning. Utilizing the Fisher information of mask nodes within the Transformer architecture, we devise a computationally efficient weighted-averaging scheme. Our method exhibits a regular and significant performance increase across various models in the BERT family, outperforming full-scale Fisher-weighted averaging in a fraction of the computational cost, with baseline performance improvements of up to +6.5 and a speedup of 57.4x. Our results prove the potential of our method in current multi-task learning environments and suggest its scalability and adaptability to new model architectures and learning scenarios.
PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
Mar 14, 2024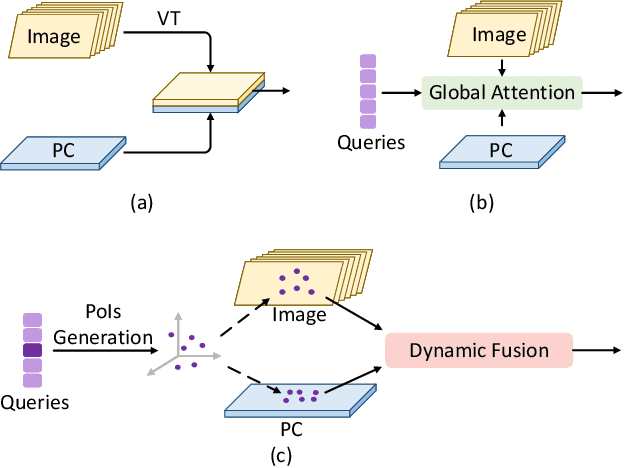
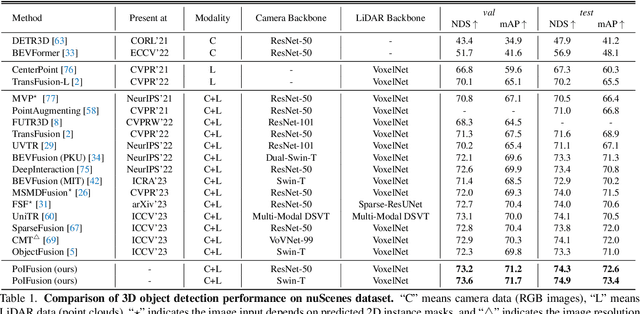
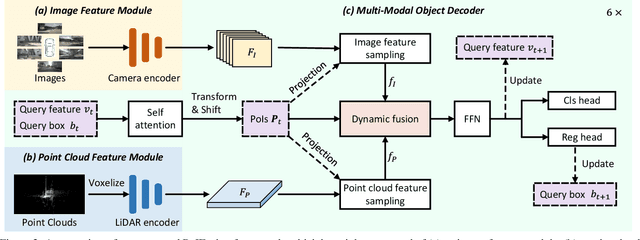
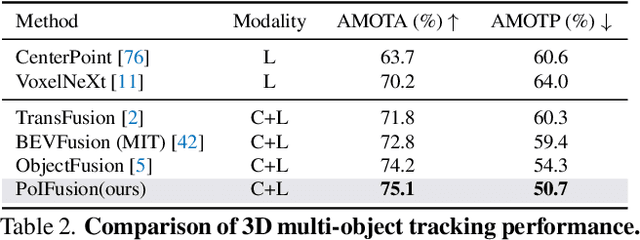
In this work, we present PoIFusion, a simple yet effective multi-modal 3D object detection framework to fuse the information of RGB images and LiDAR point clouds at the point of interest (abbreviated as PoI). Technically, our PoIFusion follows the paradigm of query-based object detection, formulating object queries as dynamic 3D boxes. The PoIs are adaptively generated from each query box on the fly, serving as the keypoints to represent a 3D object and play the role of basic units in multi-modal fusion. Specifically, we project PoIs into the view of each modality to sample the corresponding feature and integrate the multi-modal features at each PoI through a dynamic fusion block. Furthermore, the features of PoIs derived from the same query box are aggregated together to update the query feature. Our approach prevents information loss caused by view transformation and eliminates the computation-intensive global attention, making the multi-modal 3D object detector more applicable. We conducted extensive experiments on the nuScenes dataset to evaluate our approach. Remarkably, our PoIFusion achieves 74.9\% NDS and 73.4\% mAP, setting a state-of-the-art record on the multi-modal 3D object detection benchmark. Codes will be made available via \url{https://djiajunustc.github.io/projects/poifusion}.
Zero-shot and Few-shot Generation Strategies for Artificial Clinical Records
Mar 14, 2024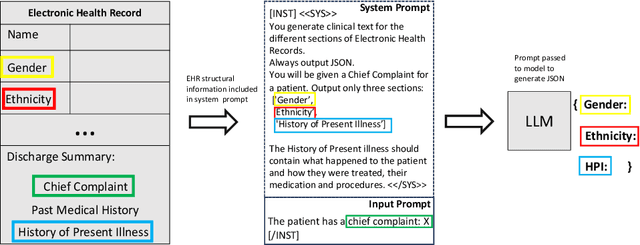

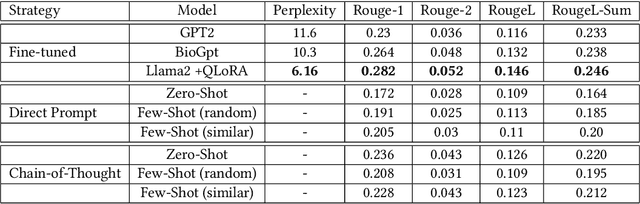
The challenge of accessing historical patient data for clinical research, while adhering to privacy regulations, is a significant obstacle in medical science. An innovative approach to circumvent this issue involves utilising synthetic medical records that mirror real patient data without compromising individual privacy. The creation of these synthetic datasets, particularly without using actual patient data to train Large Language Models (LLMs), presents a novel solution as gaining access to sensitive patient information to train models is also a challenge. This study assesses the capability of the Llama 2 LLM to create synthetic medical records that accurately reflect real patient information, employing zero-shot and few-shot prompting strategies for comparison against fine-tuned methodologies that do require sensitive patient data during training. We focus on generating synthetic narratives for the History of Present Illness section, utilising data from the MIMIC-IV dataset for comparison. In this work introduce a novel prompting technique that leverages a chain-of-thought approach, enhancing the model's ability to generate more accurate and contextually relevant medical narratives without prior fine-tuning. Our findings suggest that this chain-of-thought prompted approach allows the zero-shot model to achieve results on par with those of fine-tuned models, based on Rouge metrics evaluation.
Silico-centric Theory of Mind
Mar 14, 2024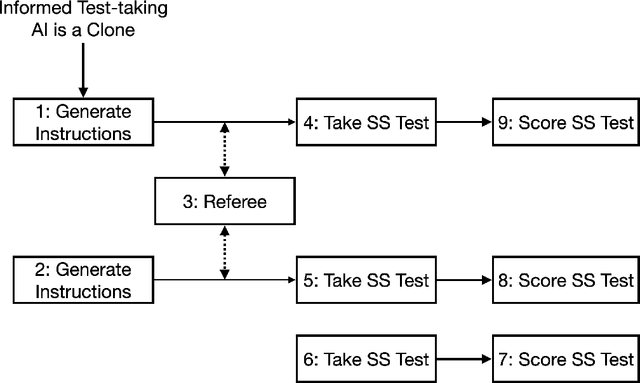
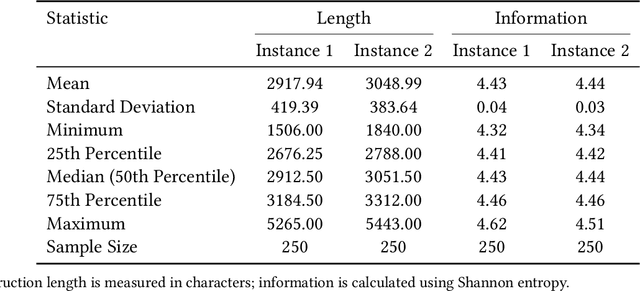
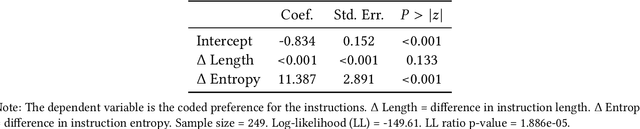
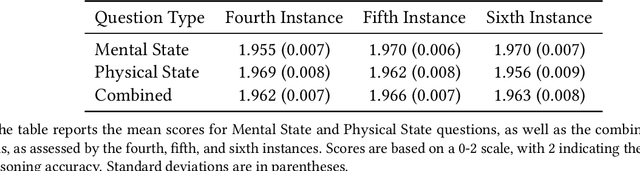
Theory of Mind (ToM) refers to the ability to attribute mental states, such as beliefs, desires, intentions, and knowledge, to oneself and others, and to understand that these mental states can differ from one's own and from reality. We investigate ToM in environments with multiple, distinct, independent AI agents, each possessing unique internal states, information, and objectives. Inspired by human false-belief experiments, we present an AI ('focal AI') with a scenario where its clone undergoes a human-centric ToM assessment. We prompt the focal AI to assess whether its clone would benefit from additional instructions. Concurrently, we give its clones the ToM assessment, both with and without the instructions, thereby engaging the focal AI in higher-order counterfactual reasoning akin to human mentalizing--with respect to humans in one test and to other AI in another. We uncover a discrepancy: Contemporary AI demonstrates near-perfect accuracy on human-centric ToM assessments. Since information embedded in one AI is identically embedded in its clone, additional instructions are redundant. Yet, we observe AI crafting elaborate instructions for their clones, erroneously anticipating a need for assistance. An independent referee AI agrees with these unsupported expectations. Neither the focal AI nor the referee demonstrates ToM in our 'silico-centric' test.
Robust Decision Aggregation with Adversarial Experts
Mar 13, 2024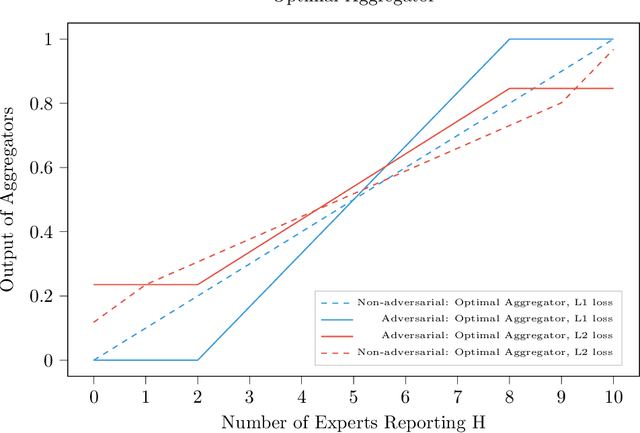

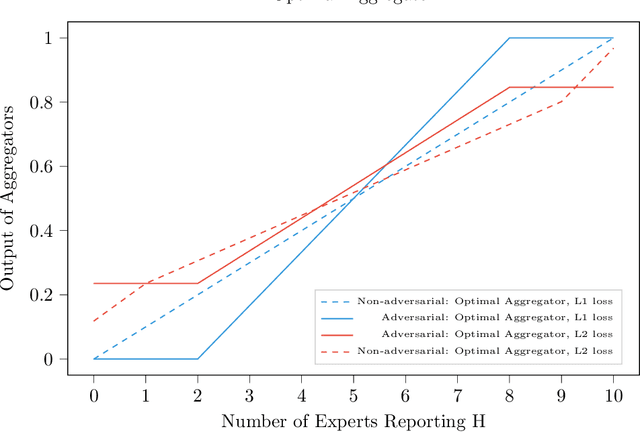
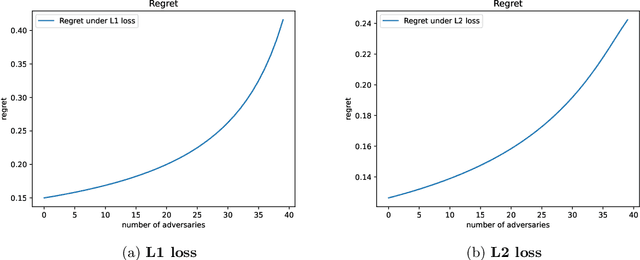
We consider a binary decision aggregation problem in the presence of both truthful and adversarial experts. The truthful experts will report their private signals truthfully with proper incentive, while the adversarial experts can report arbitrarily. The decision maker needs to design a robust aggregator to forecast the true state of the world based on the reports of experts. The decision maker does not know the specific information structure, which is a joint distribution of signals, states, and strategies of adversarial experts. We want to find the optimal aggregator minimizing regret under the worst information structure. The regret is defined by the difference in expected loss between the aggregator and a benchmark who makes the optimal decision given the joint distribution and reports of truthful experts. We prove that when the truthful experts are symmetric and adversarial experts are not too numerous, the truncated mean is optimal, which means that we remove some lowest reports and highest reports and take averaging among the left reports. Moreover, for many settings, the optimal aggregators are in the family of piecewise linear functions. The regret is independent of the total number of experts but only depends on the ratio of adversaries. We evaluate our aggregators by numerical experiment in an ensemble learning task. We also obtain some negative results for the aggregation problem with adversarial experts under some more general information structures and experts' report space.
AutoDFP: Automatic Data-Free Pruning via Channel Similarity Reconstruction
Mar 13, 2024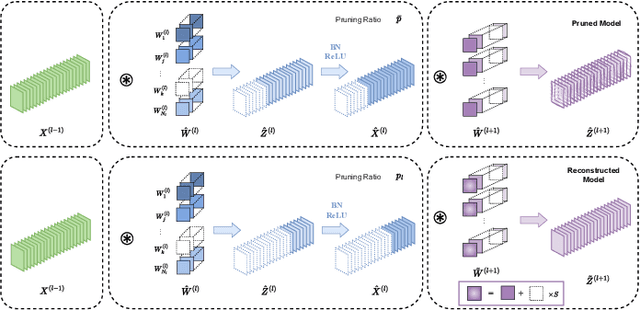
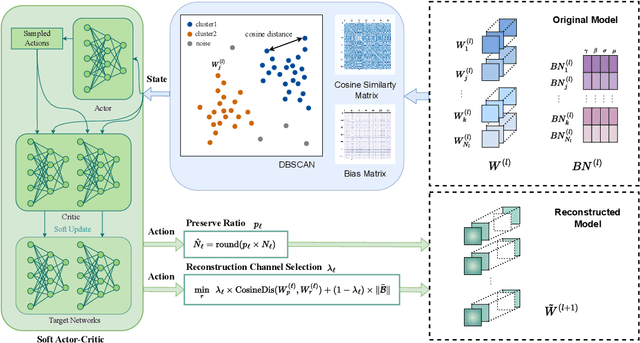
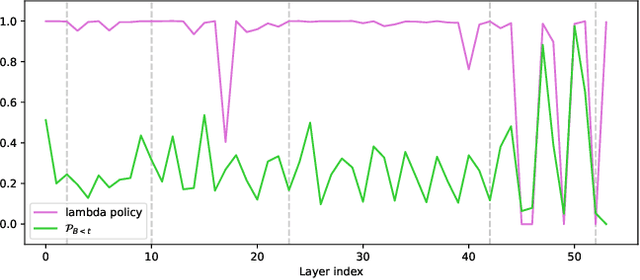
Structured pruning methods are developed to bridge the gap between the massive scale of neural networks and the limited hardware resources. Most current structured pruning methods rely on training datasets to fine-tune the compressed model, resulting in high computational burdens and being inapplicable for scenarios with stringent requirements on privacy and security. As an alternative, some data-free methods have been proposed, however, these methods often require handcraft parameter tuning and can only achieve inflexible reconstruction. In this paper, we propose the Automatic Data-Free Pruning (AutoDFP) method that achieves automatic pruning and reconstruction without fine-tuning. Our approach is based on the assumption that the loss of information can be partially compensated by retaining focused information from similar channels. Specifically, We formulate data-free pruning as an optimization problem, which can be effectively addressed through reinforcement learning. AutoDFP assesses the similarity of channels for each layer and provides this information to the reinforcement learning agent, guiding the pruning and reconstruction process of the network. We evaluate AutoDFP with multiple networks on multiple datasets, achieving impressive compression results. For instance, on the CIFAR-10 dataset, AutoDFP demonstrates a 2.87\% reduction in accuracy loss compared to the recently proposed data-free pruning method DFPC with fewer FLOPs on VGG-16. Furthermore, on the ImageNet dataset, AutoDFP achieves 43.17\% higher accuracy than the SOTA method with the same 80\% preserved ratio on MobileNet-V1.