 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EXP-SC: A Semantic Communication Model Based on Information Framework Expansion and Knowledge Collision
Oct 24, 2022
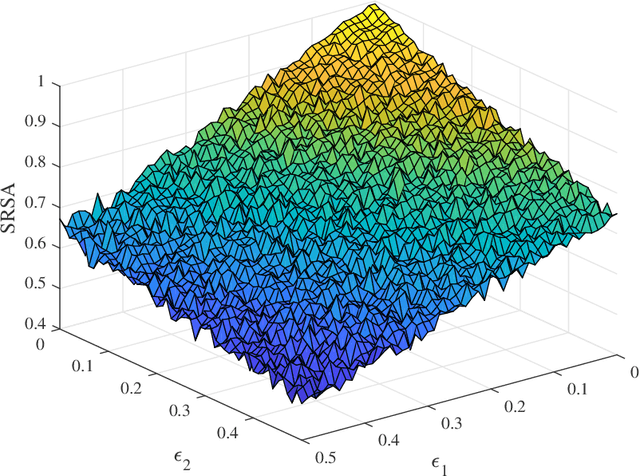
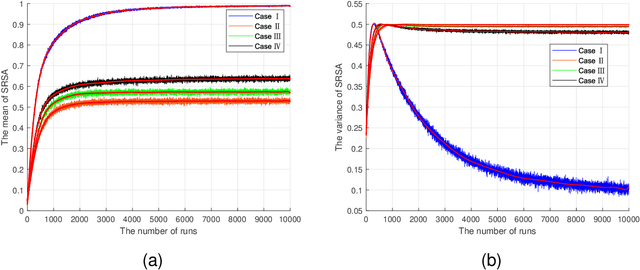
Semantic communication is not obsessed with improving the accuracy of transmitted symbols, but is concerned with expressing the desired meaning that the symbol sequence exactly carried. However, the generation and measurement of semantic messages are still an open problem. Expansions combine simple things into complex systems and even generate intelligence, which is consistent with the evolution of the human language system. We apply this idea to semantic communication system, quantifying and transmitting semantics by symbol sequences, and investigate the semantic information system in a similar way as Shannon did for digital communication systems. This work was the first to propose the concept of semantic expansion and knowledge collision, which may provide a new paradigm for semantic communications. We believe that expansions and collisions will be the cornerstone of semantic information theory.
Continuous emotion recognition based on TCN and Transformer
Mar 15, 2023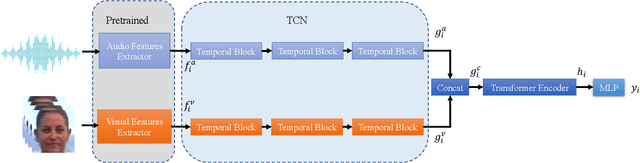


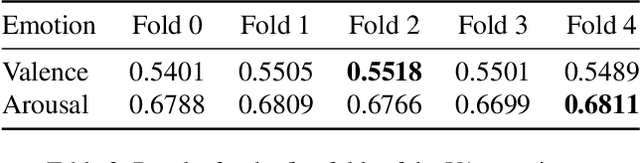
Human emotion recognition plays an important role in human-computer interaction. In this paper, we present our approach to the Valence-Arousal (VA) Estimation Challenge, Expression (Expr) Classification Challenge, and Action Unit (AU) Detection Challenge of the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Specifically, we propose a novel multi-modal fusion model that leverages Temporal Convolutional Networks (TCN) and Transformer to enhance the performance of continuous emotion recognition. Our model aims to effectively integrate visual and audio information for improved accuracy in recognizing emotions. The model is evaluate with Concordance Correlation Coefficient (CCC)
Distributed Solution of the Inverse Rig Problem in Blendshape Facial Animation
Mar 26, 2023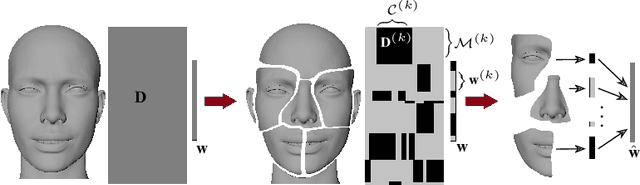
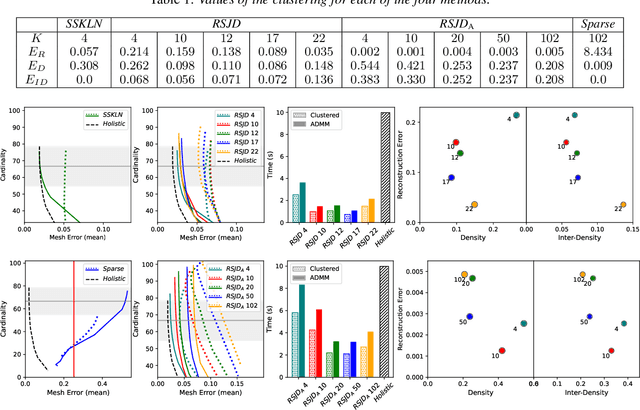

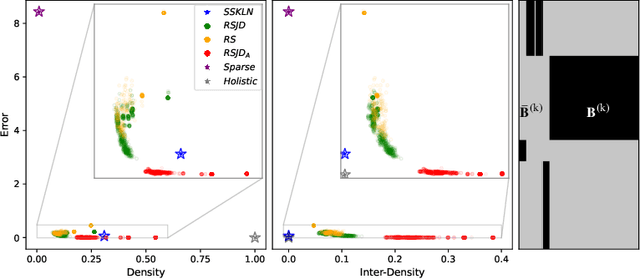
The problem of rig inversion is central in facial animation as it allows for a realistic and appealing performance of avatars. With the increasing complexity of modern blendshape models, execution times increase beyond practically feasible solutions. A possible approach towards a faster solution is clustering, which exploits the spacial nature of the face, leading to a distributed method. In this paper, we go a step further, involving cluster coupling to get more confident estimates of the overlapping components. Our algorithm applies the Alternating Direction Method of Multipliers, sharing the overlapping weights between the subproblems. The results obtained with this technique show a clear advantage over the naive clustered approach, as measured in different metrics of success and visual inspection. The method applies to an arbitrary clustering of the face. We also introduce a novel method for choosing the number of clusters in a data-free manner. The method tends to find a clustering such that the resulting clustering graph is sparse but without losing essential information. Finally, we give a new variant of a data-free clustering algorithm that produces good scores with respect to the mentioned strategy for choosing the optimal clustering.
Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023
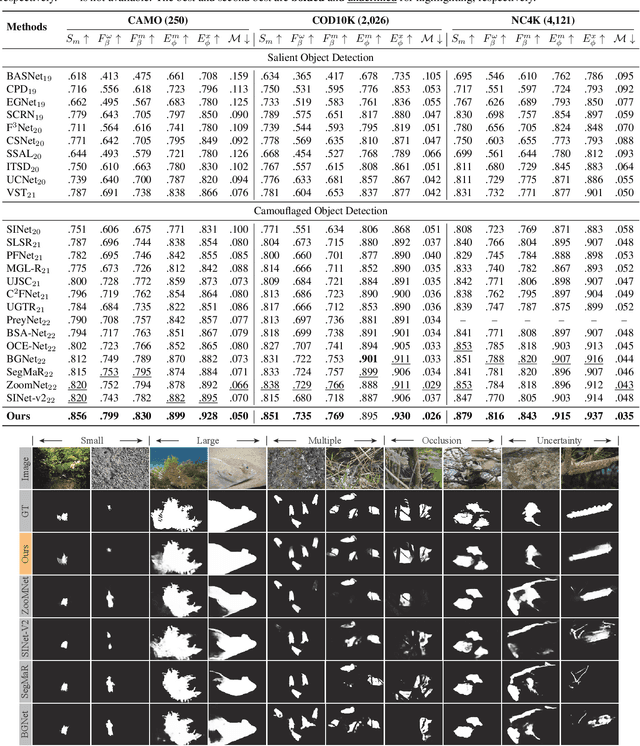

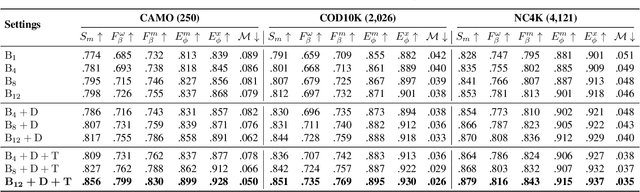
Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
SEM-POS: Grammatically and Semantically Correct Video Captioning
Mar 26, 2023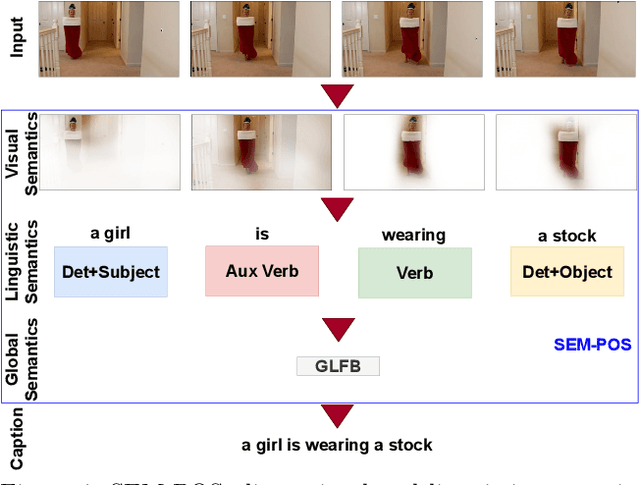
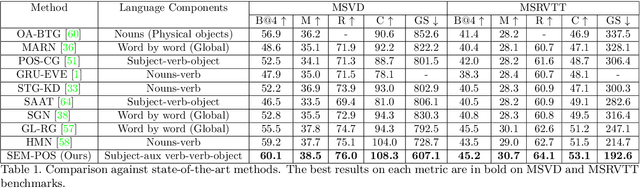
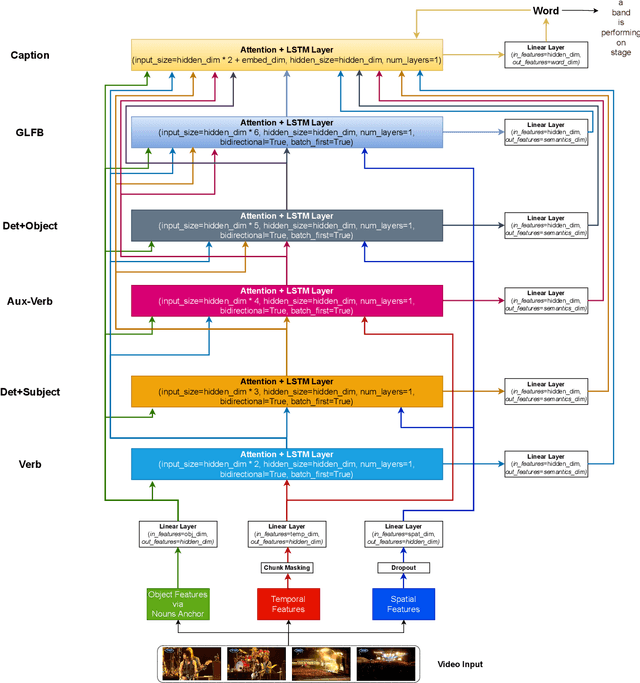
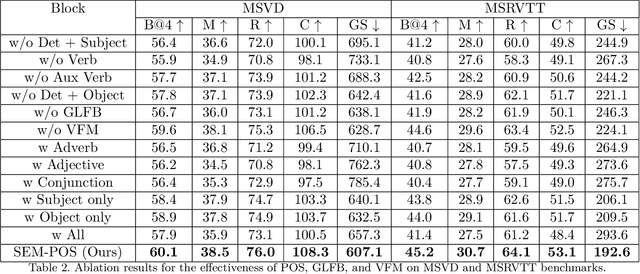
Generating grammatically and semantically correct captions in video captioning is a challenging task. The captions generated from the existing methods are either word-by-word that do not align with grammatical structure or miss key information from the input videos. To address these issues, we introduce a novel global-local fusion network, with a Global-Local Fusion Block (GLFB) that encodes and fuses features from different parts of speech (POS) components with visual-spatial features. We use novel combinations of different POS components - 'determinant + subject', 'auxiliary verb', 'verb', and 'determinant + object' for supervision of the POS blocks - Det + Subject, Aux Verb, Verb, and Det + Object respectively. The novel global-local fusion network together with POS blocks helps align the visual features with language description to generate grammatically and semantically correct captions. Extensive qualitative and quantitative experiments on benchmark MSVD and MSRVTT datasets demonstrate that the proposed approach generates more grammatically and semantically correct captions compared to the existing methods, achieving the new state-of-the-art. Ablations on the POS blocks and the GLFB demonstrate the impact of the contributions on the proposed method.
Context De-confounded Emotion Recognition
Mar 26, 2023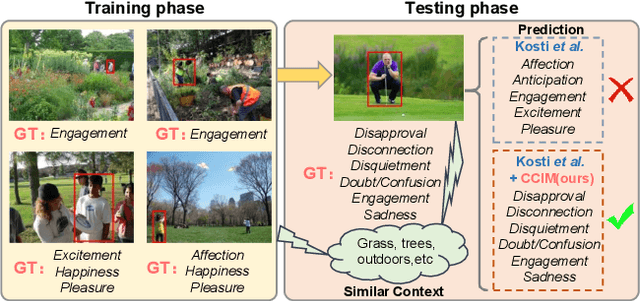
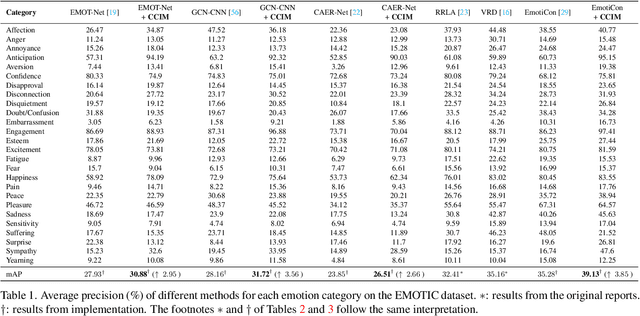
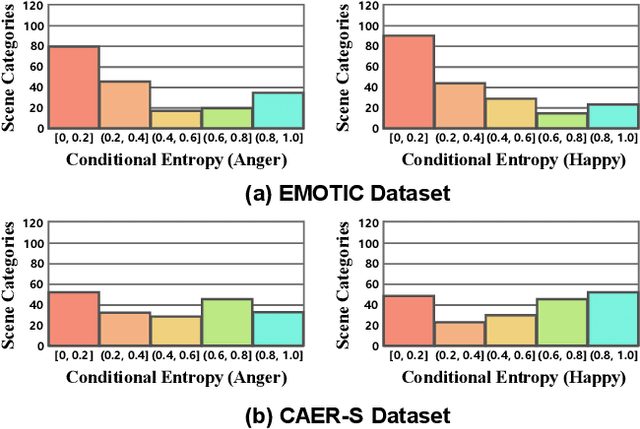

Context-Aware Emotion Recognition (CAER) is a crucial and challenging task that aims to perceive the emotional states of the target person with contextual information. Recent approaches invariably focus on designing sophisticated architectures or mechanisms to extract seemingly meaningful representations from subjects and contexts. However, a long-overlooked issue is that a context bias in existing datasets leads to a significantly unbalanced distribution of emotional states among different context scenarios. Concretely, the harmful bias is a confounder that misleads existing models to learn spurious correlations based on conventional likelihood estimation, significantly limiting the models' performance. To tackle the issue, this paper provides a causality-based perspective to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a tailored causal graph. Then, we propose a Contextual Causal Intervention Module (CCIM) based on the backdoor adjustment to de-confound the confounder and exploit the true causal effect for model training. CCIM is plug-in and model-agnostic, which improves diverse state-of-the-art approaches by considerable margins. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our CCIM and the significance of causal insight.
Enhancing Vital Sign Estimation Performance of FMCW MIMO Radar by Prior Human Shape Recognition
Mar 16, 2023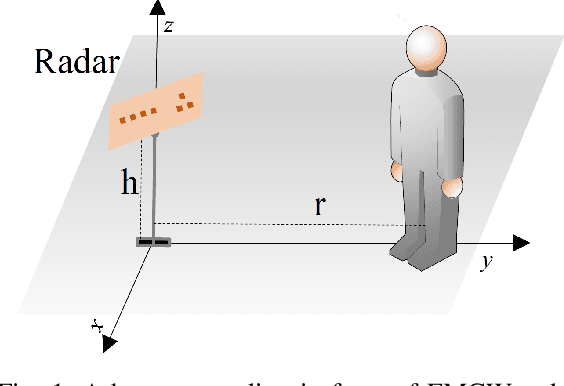
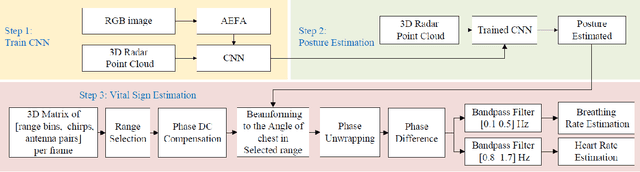
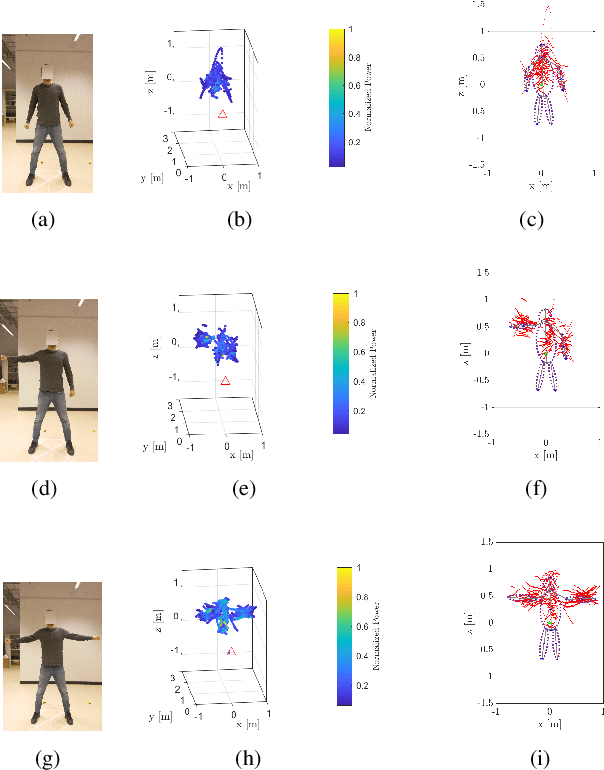
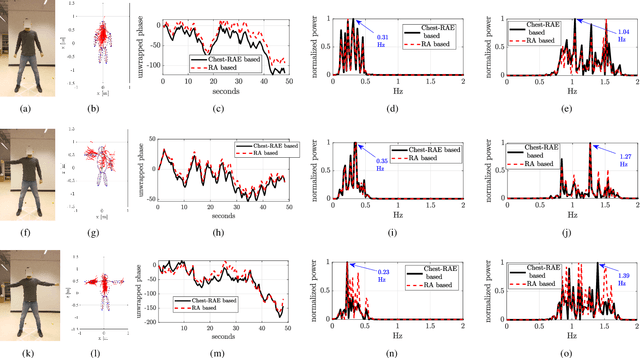
Radio technology enabled contact-free human posture and vital sign estimation is promising for health monitoring. Radio systems at millimeter-wave (mmWave) frequencies advantageously bring large bandwidth, multi-antenna array and beam steering capability. \textit{However}, the human point cloud obtained by mmWave radar and utilized for posture estimation is likely to be sparse and incomplete. Additionally, human's random body movements deteriorate the estimation of breathing and heart rates, therefore the information of the chest location and a narrow radar beam toward the chest are demanded for more accurate vital sign estimation. In this paper, we propose a pipeline aiming to enhance the vital sign estimation performance of mmWave FMCW MIMO radar. The first step is to recognize human body part and posture, where we exploit a trained Convolutional Neural Networks (CNN) to efficiently process the imperfect human form point cloud. The CNN framework outputs the key point of different body parts, and was trained by using RGB image reference and Augmentative Ellipse Fitting Algorithm (AEFA). The next step is to utilize the chest information of the prior estimated human posture for vital sign estimation. While CNN is initially trained based on the frame-by-frame point clouds of human for posture estimation, the vital signs are extracted through beamforming toward the human chest. The numerical results show that this spatial filtering improves the estimation of the vital signs in regard to lowering the level of side harmonics and detecting the harmonics of vital signs efficiently, i.e., peak-to-average power ratio in the harmonics of vital signal is improved up to 0.02 and 0.07dB for the studied cases.
Target Defense against Periodically Arriving Intruders
Mar 09, 2023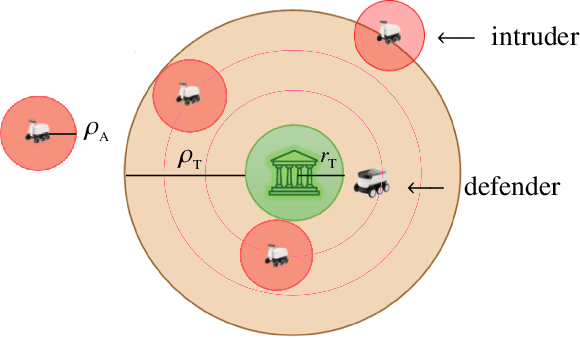
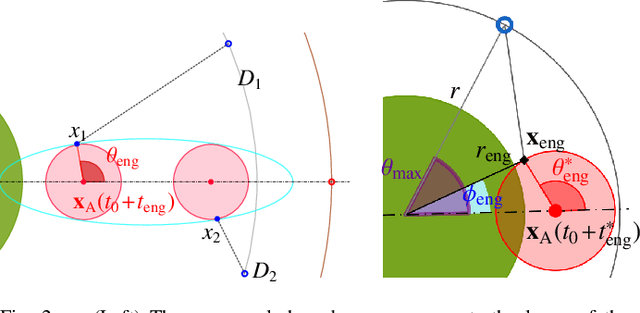
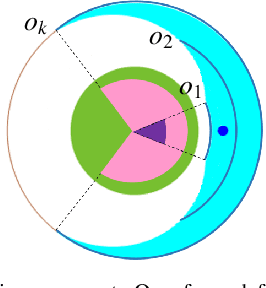
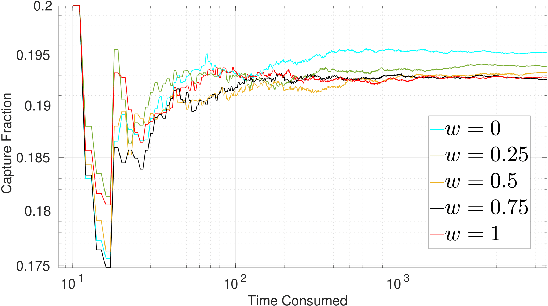
We consider a variant of pursuit-evasion games where a single defender is tasked to defend a static target from a sequence of periodically arriving intruders. The intruders' objective is to breach the boundary of a circular target without being captured and the defender's objective is to capture as many intruders as possible. At the beginning of each period, a new intruder appears at a random location on the perimeter of a fixed circle surrounding the target and moves radially towards the target center to breach the target. The intruders are slower in speed compared to the defender and they have their own sensing footprint through which they can perfectly detect the defender if it is within their sensing range. Considering the speed and sensing limitations of the agents, we analyze the entire game by dividing it into partial information and full information phases. We address the defender's capturability using the notions of engagement surface and capture circle. We develop and analyze three efficient strategies for the defender and derive a lower bound on the capture fraction. Finally, we conduct a series of simulations and numerical experiments to compare and contrast the three proposed approaches.
Sources of Richness and Ineffability for Phenomenally Conscious States
Mar 01, 2023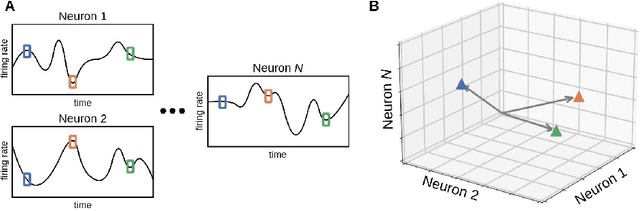
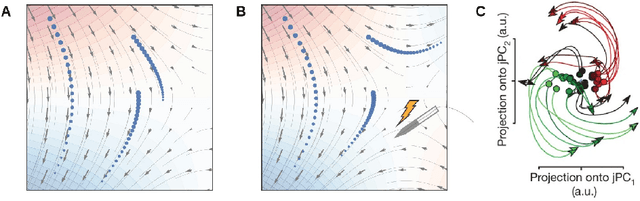
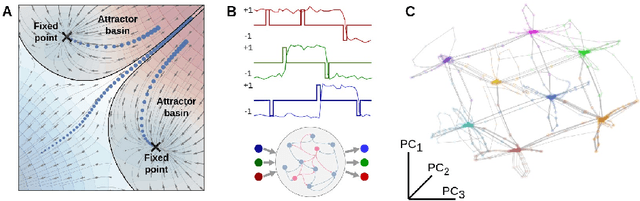
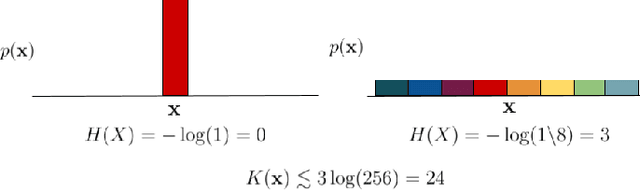
Conscious states (states that there is something it is like to be in) seem both rich or full of detail, and ineffable or hard to fully describe or recall. The problem of ineffability, in particular, is a longstanding issue in philosophy that partly motivates the explanatory gap: the belief that consciousness cannot be reduced to underlying physical processes. Here, we provide an information theoretic dynamical systems perspective on the richness and ineffability of consciousness. In our framework, the richness of conscious experience corresponds to the amount of information in a conscious state and ineffability corresponds to the amount of information lost at different stages of processing. We describe how attractor dynamics in working memory would induce impoverished recollections of our original experiences, how the discrete symbolic nature of language is insufficient for describing the rich and high-dimensional structure of experiences, and how similarity in the cognitive function of two individuals relates to improved communicability of their experiences to each other. While our model may not settle all questions relating to the explanatory gap, it makes progress toward a fully physicalist explanation of the richness and ineffability of conscious experience: two important aspects that seem to be part of what makes qualitative character so puzzling.
Decentralized Multi-Agent Reinforcement Learning for Continuous-Space Stochastic Games
Mar 16, 2023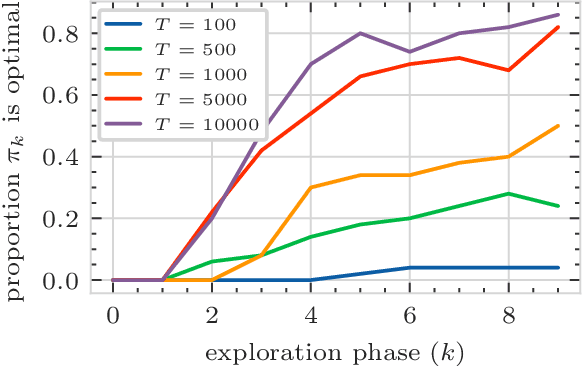
Stochastic games are a popular framework for studying multi-agent reinforcement learning (MARL). Recent advances in MARL have focused primarily on games with finitely many states. In this work, we study multi-agent learning in stochastic games with general state spaces and an information structure in which agents do not observe each other's actions. In this context, we propose a decentralized MARL algorithm and we prove the near-optimality of its policy updates. Furthermore, we study the global policy-updating dynamics for a general class of best-reply based algorithms and derive a closed-form characterization of convergence probabilities over the joint policy space.