 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
You Can Ground Earlier than See: An Effective and Efficient Pipeline for Temporal Sentence Grounding in Compressed Videos
Mar 14, 2023
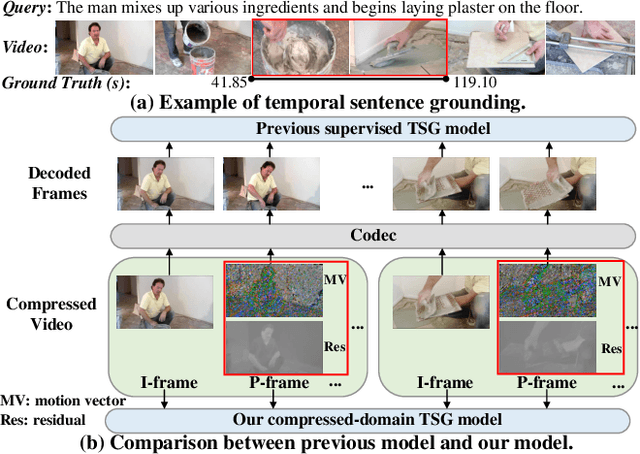
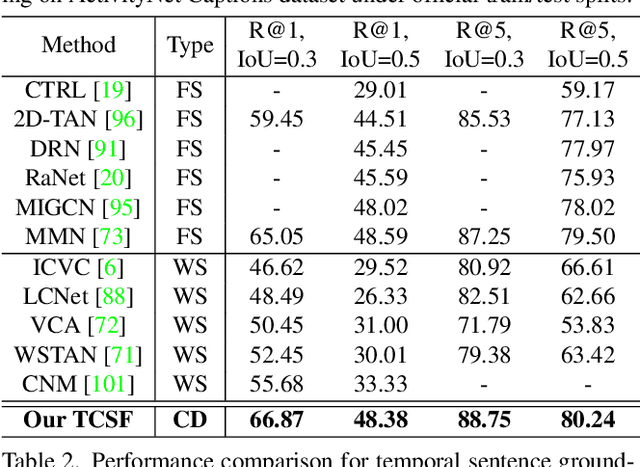
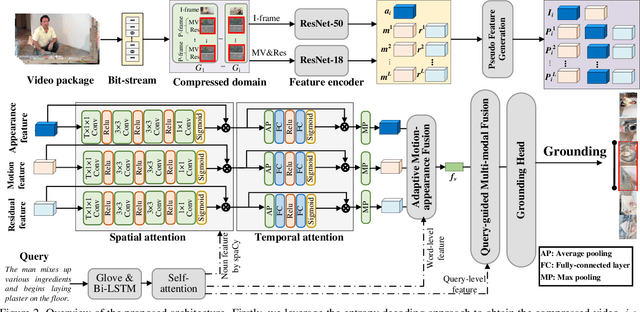
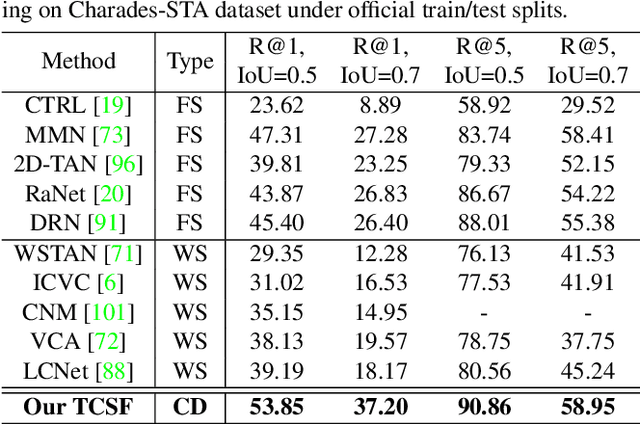
Given an untrimmed video, temporal sentence grounding (TSG) aims to locate a target moment semantically according to a sentence query. Although previous respectable works have made decent success, they only focus on high-level visual features extracted from the consecutive decoded frames and fail to handle the compressed videos for query modelling, suffering from insufficient representation capability and significant computational complexity during training and testing. In this paper, we pose a new setting, compressed-domain TSG, which directly utilizes compressed videos rather than fully-decompressed frames as the visual input. To handle the raw video bit-stream input, we propose a novel Three-branch Compressed-domain Spatial-temporal Fusion (TCSF) framework, which extracts and aggregates three kinds of low-level visual features (I-frame, motion vector and residual features) for effective and efficient grounding. Particularly, instead of encoding the whole decoded frames like previous works, we capture the appearance representation by only learning the I-frame feature to reduce delay or latency. Besides, we explore the motion information not only by learning the motion vector feature, but also by exploring the relations of neighboring frames via the residual feature. In this way, a three-branch spatial-temporal attention layer with an adaptive motion-appearance fusion module is further designed to extract and aggregate both appearance and motion information for the final grounding. Experiments on three challenging datasets shows that our TCSF achieves better performance than other state-of-the-art methods with lower complexity.
Textless Speech-to-Music Retrieval Using Emotion Similarity
Mar 19, 2023
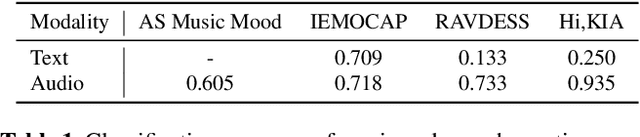
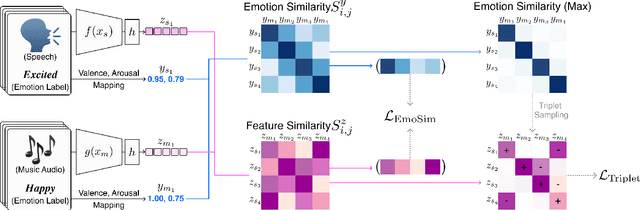

We introduce a framework that recommends music based on the emotions of speech. In content creation and daily life, speech contains information about human emotions, which can be enhanced by music. Our framework focuses on a cross-domain retrieval system to bridge the gap between speech and music via emotion labels. We explore different speech representations and report their impact on different speech types, including acting voice and wake-up words. We also propose an emotion similarity regularization term in cross-domain retrieval tasks. By incorporating the regularization term into training, similar speech-and-music pairs in the emotion space are closer in the joint embedding space. Our comprehensive experimental results show that the proposed model is effective in textless speech-to-music retrieval.
Masked Image Training for Generalizable Deep Image Denoising
Mar 23, 2023
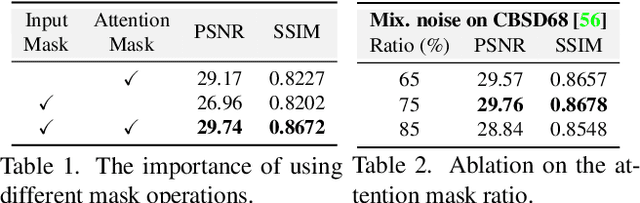


When capturing and storing images, devices inevitably introduce noise. Reducing this noise is a critical task called image denoising. Deep learning has become the de facto method for image denoising, especially with the emergence of Transformer-based models that have achieved notable state-of-the-art results on various image tasks. However, deep learning-based methods often suffer from a lack of generalization ability. For example, deep models trained on Gaussian noise may perform poorly when tested on other noise distributions. To address this issue, we present a novel approach to enhance the generalization performance of denoising networks, known as masked training. Our method involves masking random pixels of the input image and reconstructing the missing information during training. We also mask out the features in the self-attention layers to avoid the impact of training-testing inconsistency. Our approach exhibits better generalization ability than other deep learning models and is directly applicable to real-world scenarios. Additionally, our interpretability analysis demonstrates the superiority of our method.
V2V-based Collision-avoidance Decision Strategy for Autonomous Vehicles Interacting with Fully Occluded Pedestrians at Midblock on Multilane Roadways
Mar 23, 2023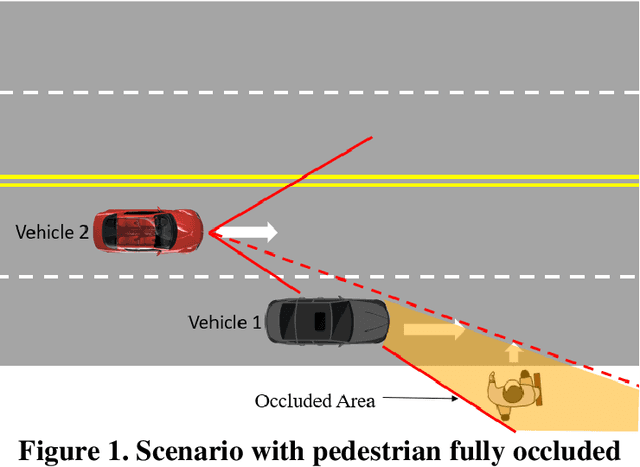

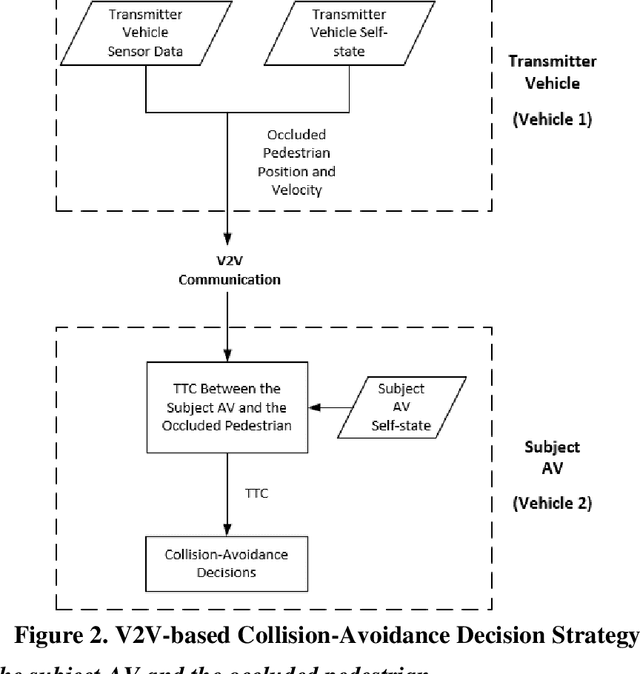
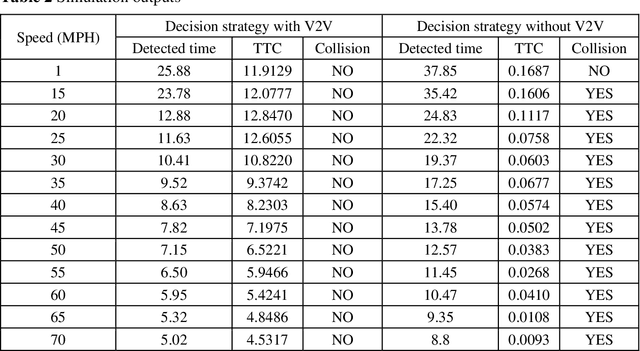
Pedestrian occlusion is challenging for autonomous vehicles (AVs) at midblock locations on multilane roadways because an AV cannot detect crossing pedestrians that are fully occluded by downstream vehicles in adjacent lanes. This paper tests the capability of vehicle-to-vehicle (V2V) communication between an AV and its downstream vehicles to share midblock pedestrian crossings information. The researchers developed a V2V-based collision-avoidance decision strategy and compared it to a base scenario (i.e., decision strategy without the utilization of V2V). Simulation results showed that for the base scenario, the near-zero time-to-collision (TTC) indicated no time for the AV to take appropriate action and resulted in dramatic braking followed by collisions. But the V2V-based collision-avoidance decision strategy allowed for a proportional braking approach to increase the TTC allowing the pedestrian to cross safely. To conclude, the V2V-based collision-avoidance decision strategy has higher safety benefits for an AV interacting with fully occluded pedestrians at midblock locations on multilane roadways.
Retrieval-Augmented Classification with Decoupled Representation
Mar 23, 2023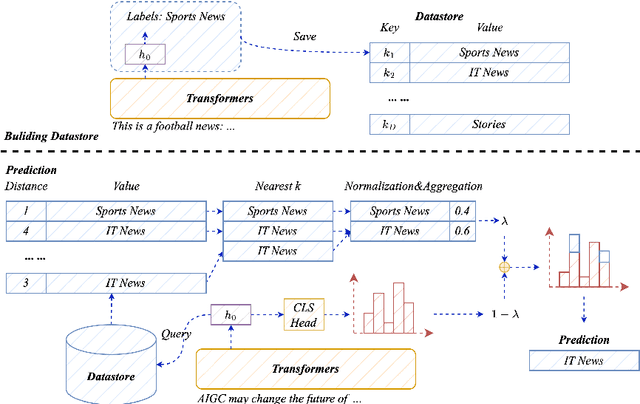
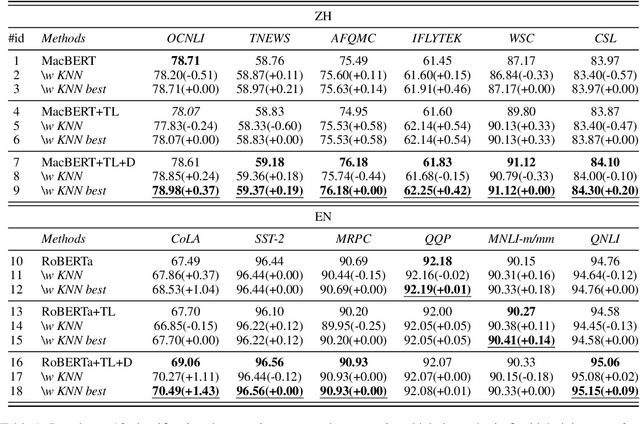
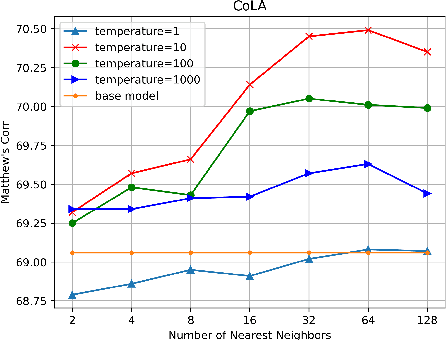
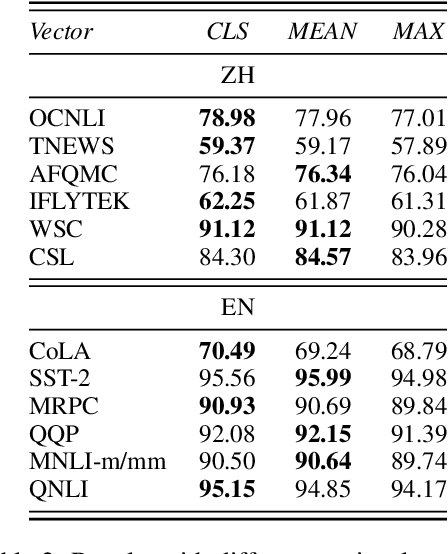
Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code has been released here~\footnote{\url{https://github.com/xnliang98/MigBERT}} and you can download our model here~\footnote{\url{https://huggingface.co/xnliang/MigBERT-large/}}.
Practical Realization of Bessel's Correction for a Bias-Free Estimation of the Auto-Covariance and the Cross-Covariance Functions
Mar 20, 2023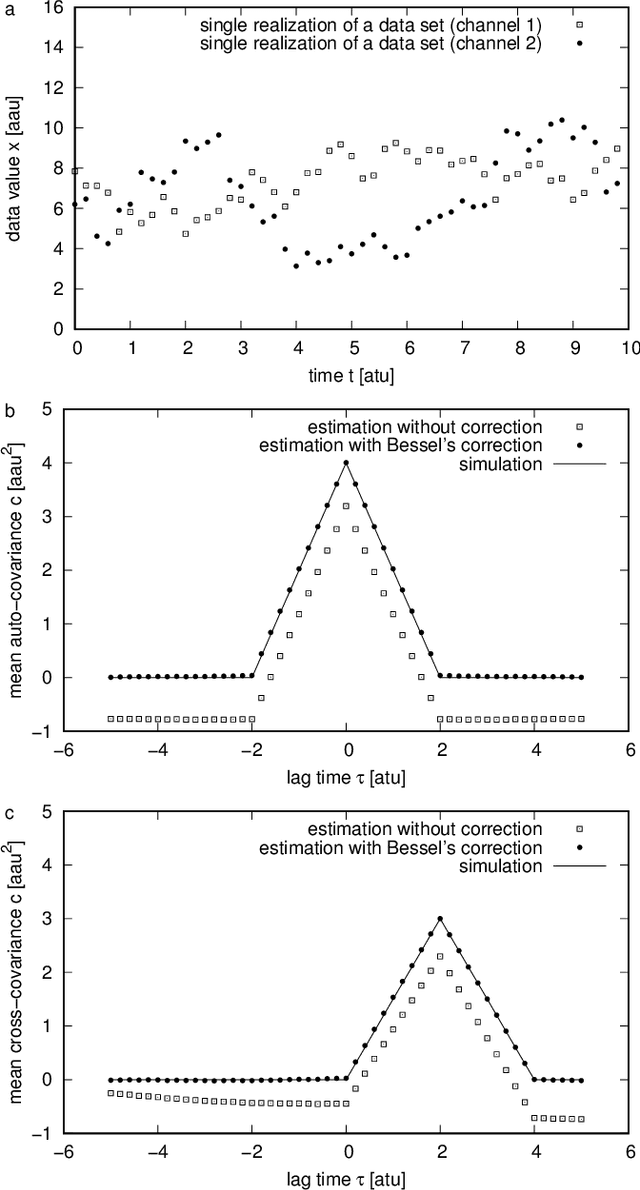
To derive the auto-covariance function from a sampled and time-limited signal or the cross-covariance function from two such signals, the mean values must be estimated and removed from the signals. If no a priori information about the correct mean values is available and the mean values must be derived from the time series themselves, the estimates will be biased. For the estimation of the variance from independent data the appropriate correction is widely known as Bessel's correction. Similar corrections for the auto-covariance and for the cross-covariance functions are shown here, including individual weighting of the samples. The corrected estimates then can be used to correct also the variance estimate in the case of correlated data. The programs used here are available online at http://sigproc.nambis.de/programs.
Character, Word, or Both? Revisiting the Segmentation Granularity for Chinese Pre-trained Language Models
Mar 22, 2023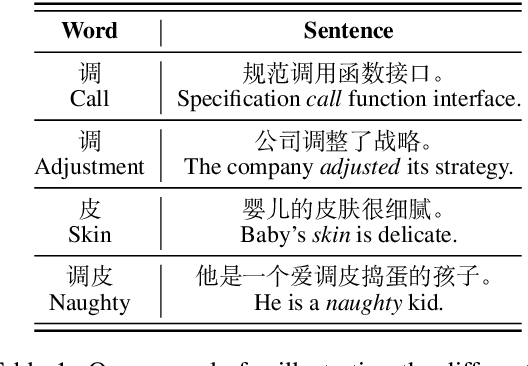
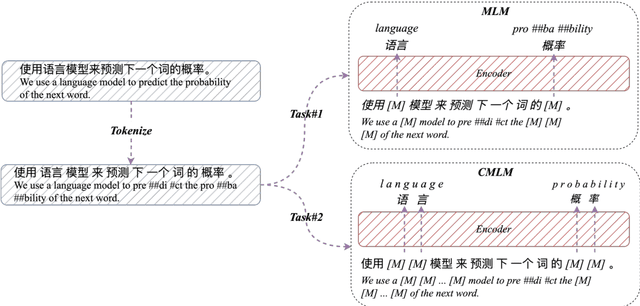

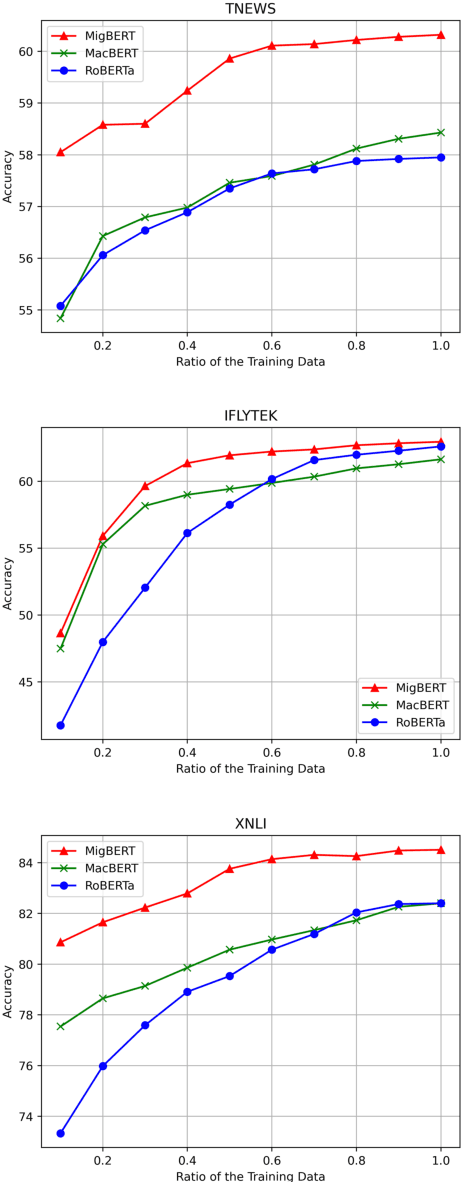
Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code and model have been released here~\footnote{https://github.com/xnliang98/MigBERT}.
Feature Reduction Method Comparison Towards Explainability and Efficiency in Cybersecurity Intrusion Detection Systems
Mar 22, 2023
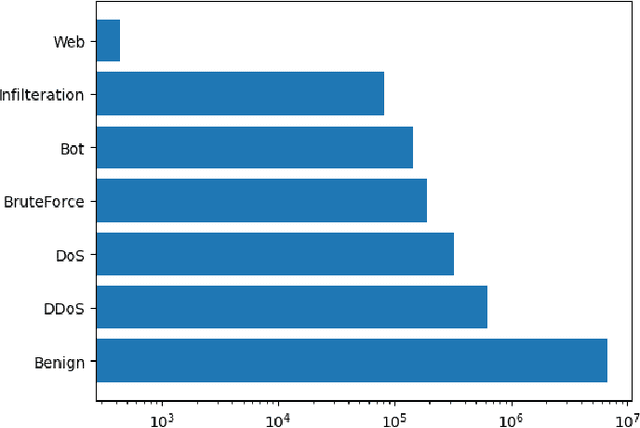
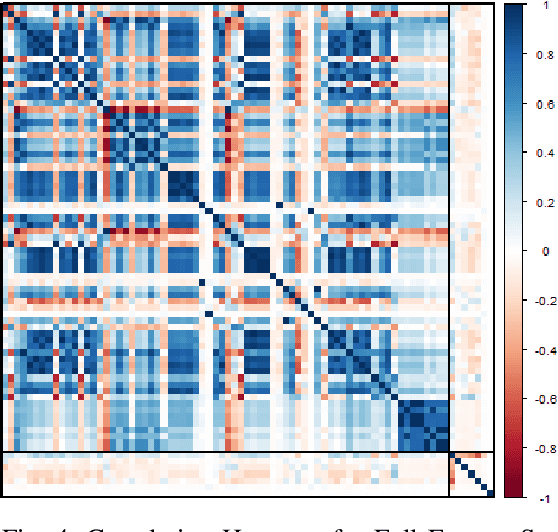
In the realm of cybersecurity, intrusion detection systems (IDS) detect and prevent attacks based on collected computer and network data. In recent research, IDS models have been constructed using machine learning (ML) and deep learning (DL) methods such as Random Forest (RF) and deep neural networks (DNN). Feature selection (FS) can be used to construct faster, more interpretable, and more accurate models. We look at three different FS techniques; RF information gain (RF-IG), correlation feature selection using the Bat Algorithm (CFS-BA), and CFS using the Aquila Optimizer (CFS-AO). Our results show CFS-BA to be the most efficient of the FS methods, building in 55% of the time of the best RF-IG model while achieving 99.99% of its accuracy. This reinforces prior contributions attesting to CFS-BA's accuracy while building upon the relationship between subset size, CFS score, and RF-IG score in final results.
* Published in 2022 21st IEEE International Conference on Machine Learning and Applications. 8 pages. 5 figures
Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection
Mar 21, 2023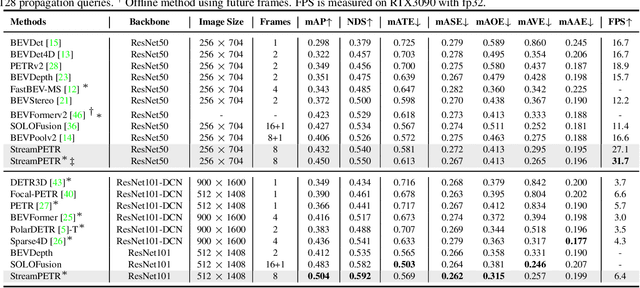
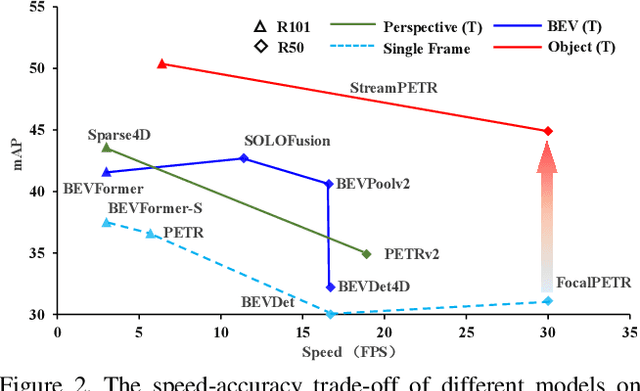
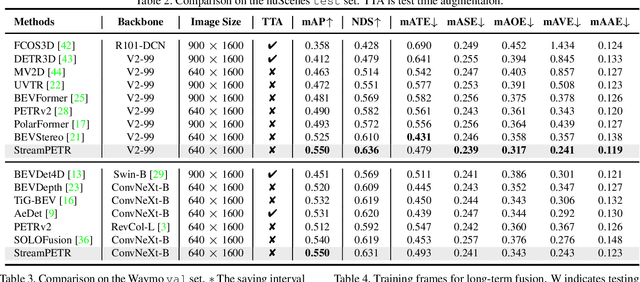
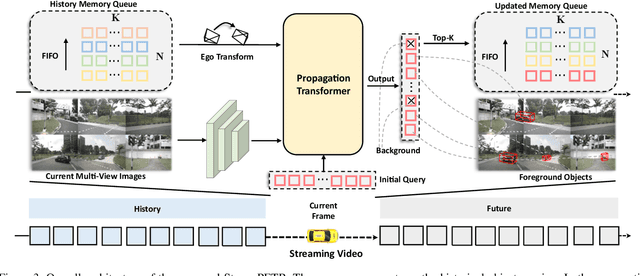
In this paper, we propose a long-sequence modeling framework, named StreamPETR, for multi-view 3D object detection. Built upon the sparse query design in the PETR series, we systematically develop an object-centric temporal mechanism. The model is performed in an online manner and the long-term historical information is propagated through object queries frame by frame. Besides, we introduce a motion-aware layer normalization to model the movement of the objects. StreamPETR achieves significant performance improvements only with negligible computation cost, compared to the single-frame baseline. On the standard nuScenes benchmark, it reaches a new state-of-the-art performance (63.6% NDS). The lightweight version realizes 45.0% mAP and 31.7 FPS, outperforming the state-of-the-art method (SOLOFusion) by 2.3% mAP and 1.8x faster FPS. Code will be available at https://github.com/exiawsh/StreamPETR.git.
Hybrid Traffic Control and Coordination from Pixels
Feb 17, 2023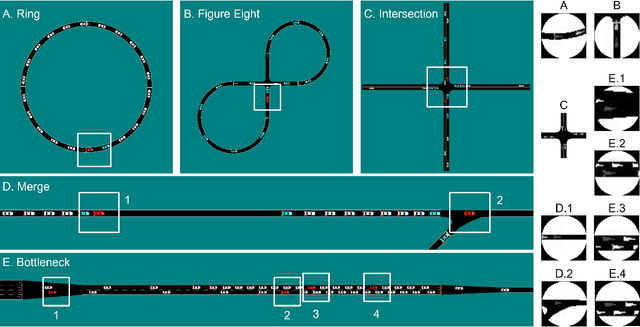

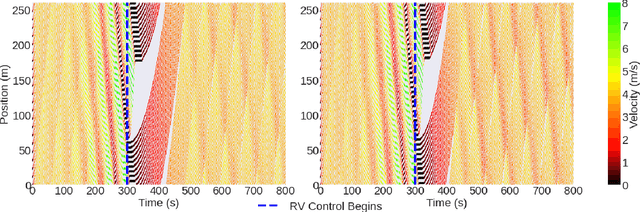

Traffic congestion is a persistent problem in our society. Existing methods for traffic control have proven futile in alleviating current congestion levels leading researchers to explore ideas with robot vehicles given the increased emergence of vehicles with different levels of autonomy on our roads. This gives rise to hybrid traffic control, where robot vehicles regulate human-driven vehicles, through reinforcement learning (RL). However, most existing studies use precise observations that involve global information, such as network throughput, as well as local information, such as vehicle positions and velocities. Obtaining this information requires updating existing road infrastructure with vast sensor networks and communication to potentially unwilling human drivers. We consider image observations as the alternative for hybrid traffic control via RL: 1) images are readily available through satellite imagery, in-car camera systems, and traffic monitoring systems; 2) Images do not require a complete re-imagination of the observation space from network to network; and 3) images only require communication to equipment. In this work, we show that robot vehicles using image observations can achieve similar performance to using precise information on networks, including ring, figure eight, merge, bottleneck, and intersections. We also demonstrate increased performance (up to 26%) in certain cases on tested networks, despite only using local traffic information as opposed to global traffic information.