 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LSEH: Semantically Enhanced Hard Negatives for Cross-modal Information Retrieval
Oct 10, 2022

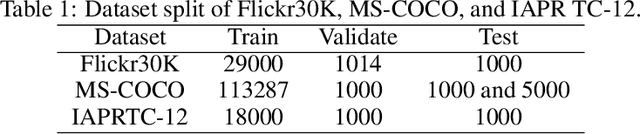
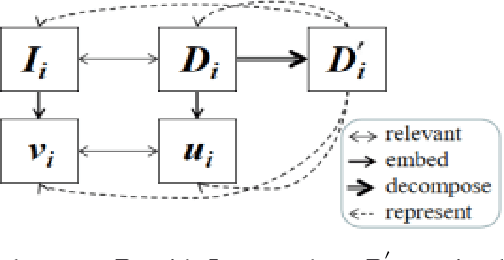
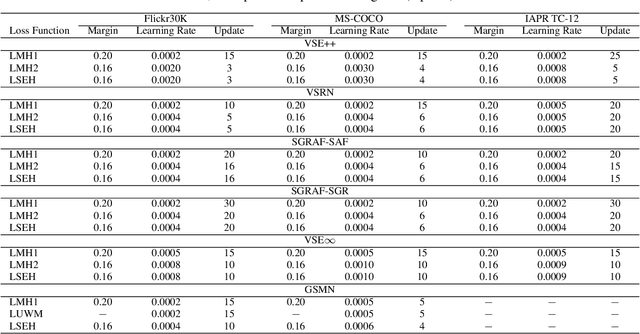
Visual Semantic Embedding (VSE) aims to extract the semantics of images and their descriptions, and embed them into the same latent space for cross-modal information retrieval. Most existing VSE networks are trained by adopting a hard negatives loss function which learns an objective margin between the similarity of relevant and irrelevant image-description embedding pairs. However, the objective margin in the hard negatives loss function is set as a fixed hyperparameter that ignores the semantic differences of the irrelevant image-description pairs. To address the challenge of measuring the optimal similarities between image-description pairs before obtaining the trained VSE networks, this paper presents a novel approach that comprises two main parts: (1) finds the underlying semantics of image descriptions; and (2) proposes a novel semantically enhanced hard negatives loss function, where the learning objective is dynamically determined based on the optimal similarity scores between irrelevant image-description pairs. Extensive experiments were carried out by integrating the proposed methods into five state-of-the-art VSE networks that were applied to three benchmark datasets for cross-modal information retrieval tasks. The results revealed that the proposed methods achieved the best performance and can also be adopted by existing and future VSE networks.
GeoSpark: Sparking up Point Cloud Segmentation with Geometry Clue
Mar 14, 2023
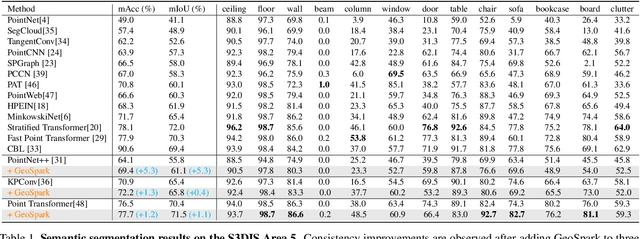
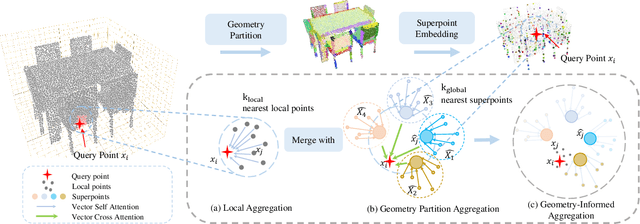
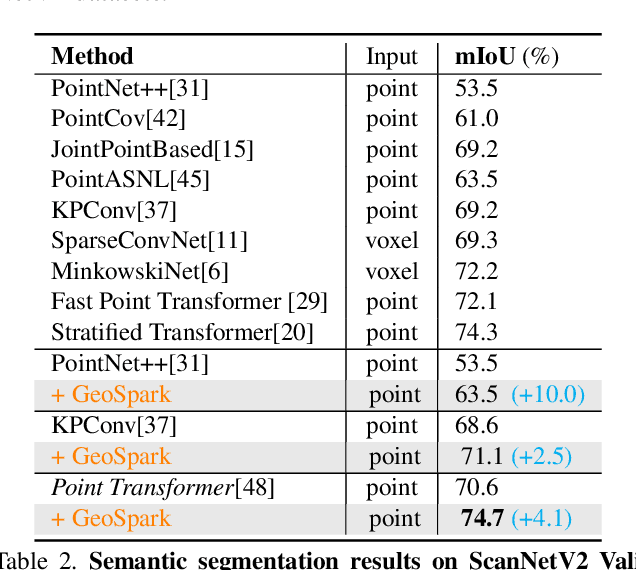
Current point cloud segmentation architectures suffer from limited long-range feature modeling, as they mostly rely on aggregating information with local neighborhoods. Furthermore, in order to learn point features at multiple scales, most methods utilize a data-agnostic sampling approach to decrease the number of points after each stage. Such sampling methods, however, often discard points for small objects in the early stages, leading to inadequate feature learning. We believe these issues are can be mitigated by introducing explicit geometry clues as guidance. To this end, we propose GeoSpark, a Plug-in module that incorporates Geometry clues into the network to Spark up feature learning and downsampling. GeoSpark can be easily integrated into various backbones. For feature aggregation, it improves feature modeling by allowing the network to learn from both local points and neighboring geometry partitions, resulting in an enlarged data-tailored receptive field. Additionally, GeoSpark utilizes geometry partition information to guide the downsampling process, where points with unique features are preserved while redundant points are fused, resulting in better preservation of key points throughout the network. We observed consistent improvements after adding GeoSpark to various backbones including PointNet++, KPConv, and PointTransformer. Notably, when integrated with Point Transformer, our GeoSpark module achieves a 74.7% mIoU on the ScanNetv2 dataset (4.1% improvement) and 71.5% mIoU on the S3DIS Area 5 dataset (1.1% improvement), ranking top on both benchmarks. Code and models will be made publicly available.
Symbolic Synthesis of Neural Networks
Mar 14, 2023
Neural networks adapt very well to distributed and continuous representations, but struggle to generalize from small amounts of data. Symbolic systems commonly achieve data efficient generalization by exploiting modularity to benefit from local and discrete features of a representation. These features allow symbolic programs to be improved one module at a time and to experience combinatorial growth in the values they can successfully process. However, it is difficult to design a component that can be used to form symbolic abstractions and which is adequately overparametrized to learn arbitrary high-dimensional transformations. I present Graph-based Symbolically Synthesized Neural Networks (G-SSNNs), a class of neural modules that operate on representations modified with synthesized symbolic programs to include a fixed set of local and discrete features. I demonstrate that the choice of injected features within a G-SSNN module modulates the data efficiency and generalization of baseline neural models, creating predictable patterns of both heightened and curtailed generalization. By training G-SSNNs, we also derive information about desirable semantics of symbolic programs without manual engineering. This information is compact and amenable to abstraction, but can also be flexibly recontextualized for other high-dimensional settings. In future work, I will investigate data efficient generalization and the transferability of learned symbolic representations in more complex G-SSNN designs based on more complex classes of symbolic programs. Experimental code and data are available at https://github.com/shlomenu/symbolically_synthesized_networks .
You Can Ground Earlier than See: An Effective and Efficient Pipeline for Temporal Sentence Grounding in Compressed Videos
Mar 14, 2023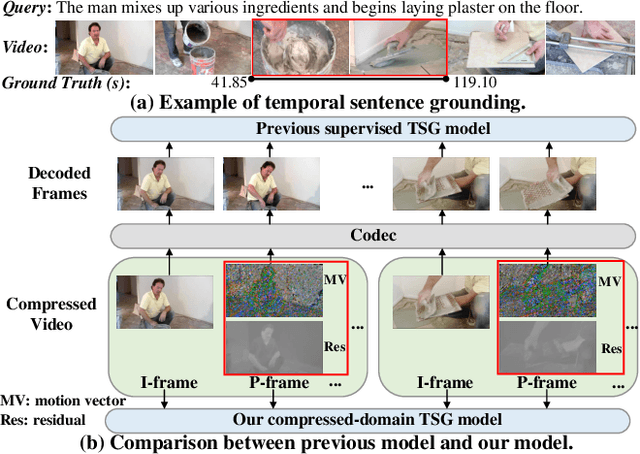
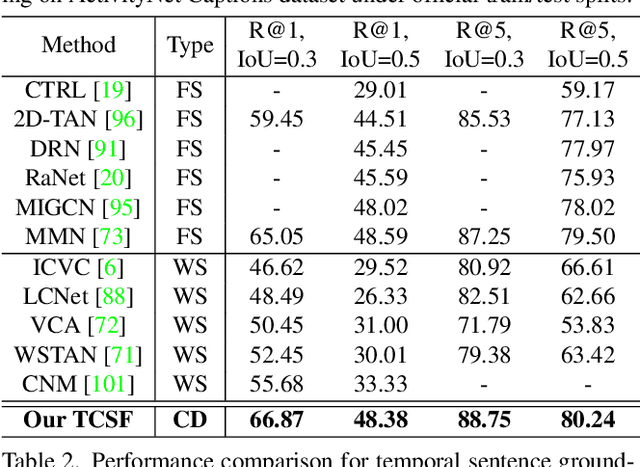
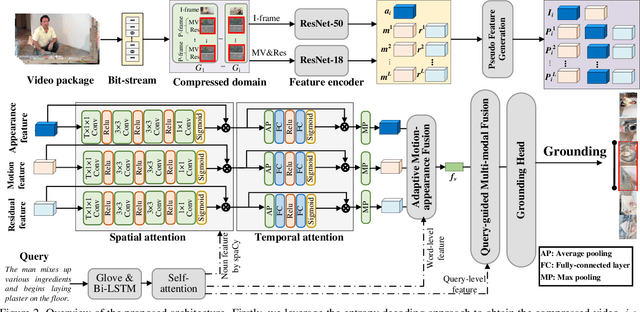
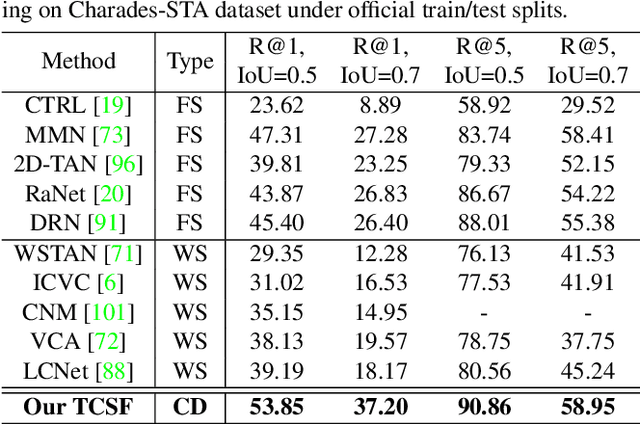
Given an untrimmed video, temporal sentence grounding (TSG) aims to locate a target moment semantically according to a sentence query. Although previous respectable works have made decent success, they only focus on high-level visual features extracted from the consecutive decoded frames and fail to handle the compressed videos for query modelling, suffering from insufficient representation capability and significant computational complexity during training and testing. In this paper, we pose a new setting, compressed-domain TSG, which directly utilizes compressed videos rather than fully-decompressed frames as the visual input. To handle the raw video bit-stream input, we propose a novel Three-branch Compressed-domain Spatial-temporal Fusion (TCSF) framework, which extracts and aggregates three kinds of low-level visual features (I-frame, motion vector and residual features) for effective and efficient grounding. Particularly, instead of encoding the whole decoded frames like previous works, we capture the appearance representation by only learning the I-frame feature to reduce delay or latency. Besides, we explore the motion information not only by learning the motion vector feature, but also by exploring the relations of neighboring frames via the residual feature. In this way, a three-branch spatial-temporal attention layer with an adaptive motion-appearance fusion module is further designed to extract and aggregate both appearance and motion information for the final grounding. Experiments on three challenging datasets shows that our TCSF achieves better performance than other state-of-the-art methods with lower complexity.
Distribution Aligned Diffusion and Prototype-guided network for Unsupervised Domain Adaptive Segmentation
Mar 28, 2023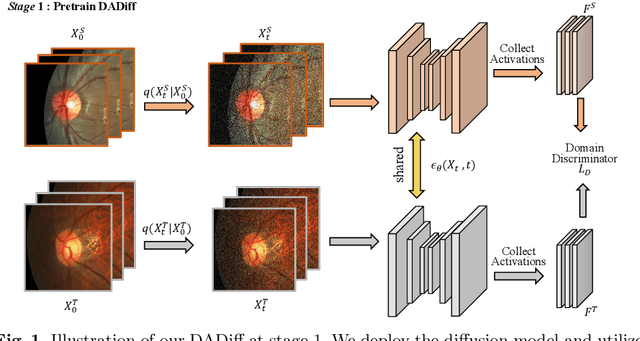
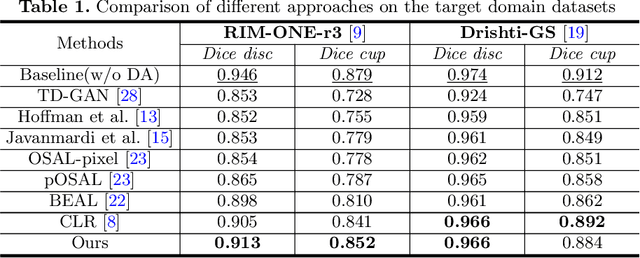
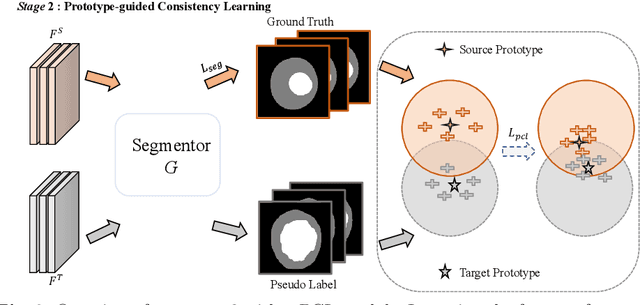
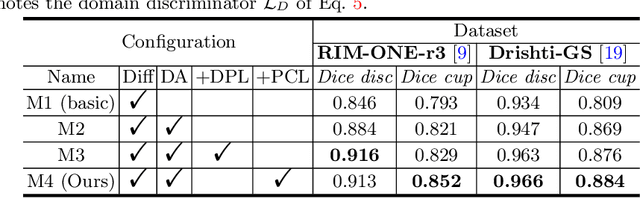
The Diffusion Probabilistic Model (DPM) has emerged as a highly effective generative model in the field of computer vision. Its intermediate latent vectors offer rich semantic information, making it an attractive option for various downstream tasks such as segmentation and detection. In order to explore its potential further, we have taken a step forward and considered a more complex scenario in the medical image domain, specifically, under an unsupervised adaptation condition. To this end, we propose a Diffusion-based and Prototype-guided network (DP-Net) for unsupervised domain adaptive segmentation. Concretely, our DP-Net consists of two stages: 1) Distribution Aligned Diffusion (DADiff), which involves training a domain discriminator to minimize the difference between the intermediate features generated by the DPM, thereby aligning the inter-domain distribution; and 2) Prototype-guided Consistency Learning (PCL), which utilizes feature centroids as prototypes and applies a prototype-guided loss to ensure that the segmentor learns consistent content from both source and target domains. Our approach is evaluated on fundus datasets through a series of experiments, which demonstrate that the performance of the proposed method is reliable and outperforms state-of-the-art methods. Our work presents a promising direction for using DPM in complex medical image scenarios, opening up new possibilities for further research in medical imaging.
Explicit Attention-Enhanced Fusion for RGB-Thermal Perception Tasks
Mar 28, 2023
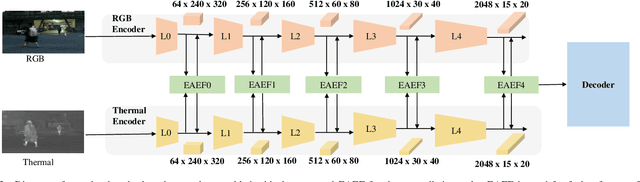
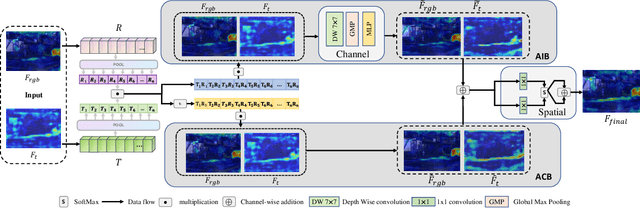

Recently, RGB-Thermal based perception has shown significant advances. Thermal information provides useful clues when visual cameras suffer from poor lighting conditions, such as low light and fog. However, how to effectively fuse RGB images and thermal data remains an open challenge. Previous works involve naive fusion strategies such as merging them at the input, concatenating multi-modality features inside models, or applying attention to each data modality. These fusion strategies are straightforward yet insufficient. In this paper, we propose a novel fusion method named Explicit Attention-Enhanced Fusion (EAEF) that fully takes advantage of each type of data. Specifically, we consider the following cases: i) both RGB data and thermal data, ii) only one of the types of data, and iii) none of them generate discriminative features. EAEF uses one branch to enhance feature extraction for i) and iii) and the other branch to remedy insufficient representations for ii). The outputs of two branches are fused to form complementary features. As a result, the proposed fusion method outperforms state-of-the-art by 1.6\% in mIoU on semantic segmentation, 3.1\% in MAE on salient object detection, 2.3\% in mAP on object detection, and 8.1\% in MAE on crowd counting. The code is available at https://github.com/FreeformRobotics/EAEFNet.
An Experimental Study on Sentiment Classification of Moroccan dialect texts in the web
Mar 28, 2023
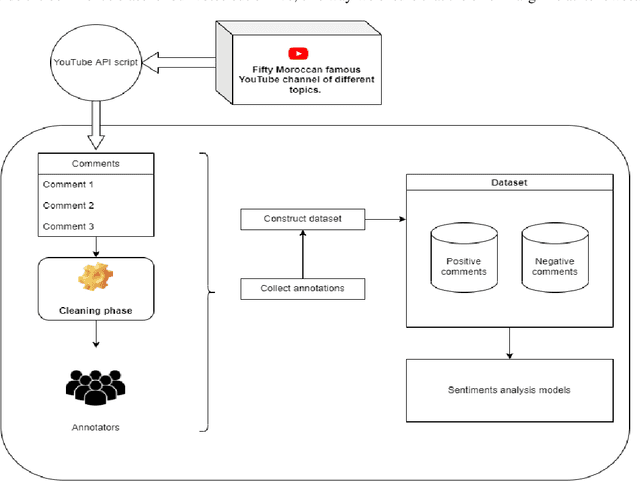
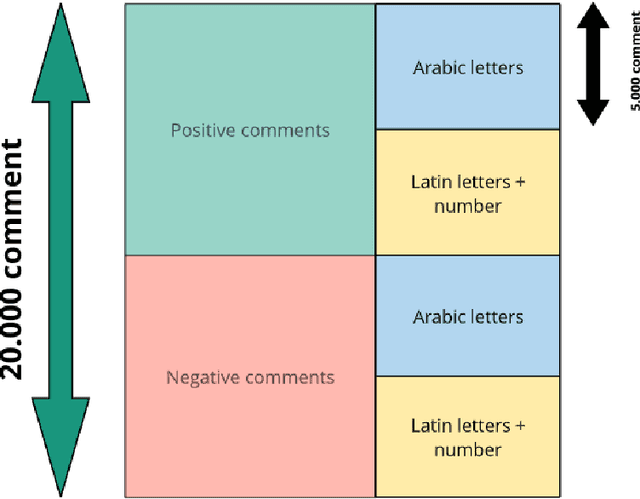
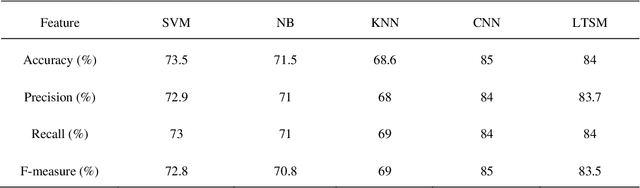
With the rapid growth of the use of social media websites, obtaining the users' feedback automatically became a crucial task to evaluate their tendencies and behaviors online. Despite this great availability of information, and the increasing number of Arabic users only few research has managed to treat Arabic dialects. The purpose of this paper is to study the opinion and emotion expressed in real Moroccan texts precisely in the YouTube comments using some well-known and commonly used methods for sentiment analysis. In this paper, we present our work of Moroccan dialect comments classification using Machine Learning (ML) models and based on our collected and manually annotated YouTube Moroccan dialect dataset. By employing many text preprocessing and data representation techniques we aim to compare our classification results utilizing the most commonly used supervised classifiers: k-nearest neighbors (KNN), Support Vector Machine (SVM), Naive Bayes (NB), and deep learning (DL) classifiers such as Convolutional Neural Network (CNN) and Long Short-Term Memory (LTSM). Experiments were performed using both raw and preprocessed data to show the importance of the preprocessing. In fact, the experimental results prove that DL models have a better performance for Moroccan Dialect than classical approaches and we achieved an accuracy of 90%.
GP3D: Generalized Pose Estimation in 3D Point Clouds: A case study on bin picking
Mar 28, 2023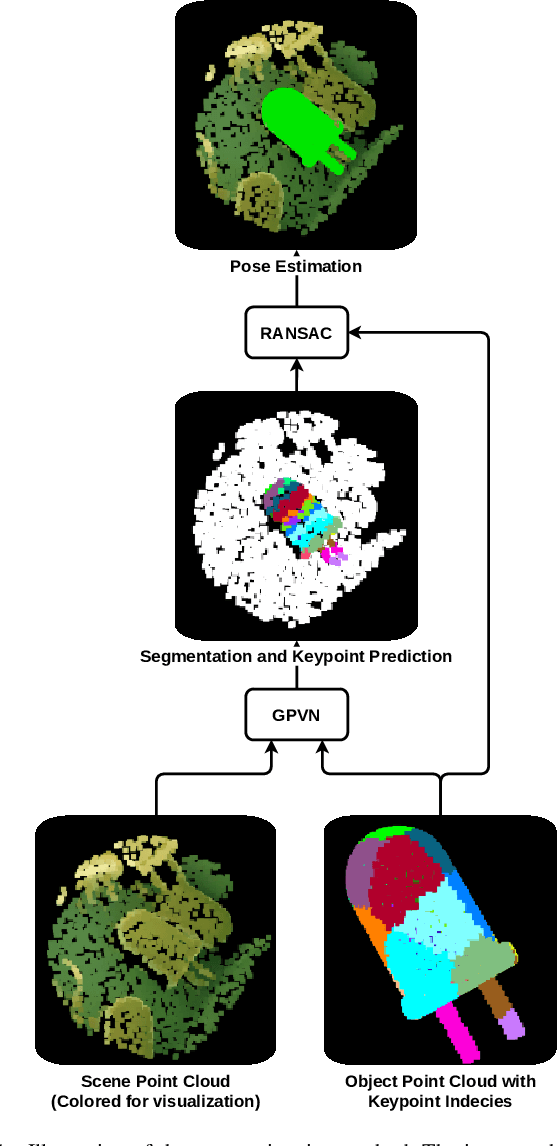
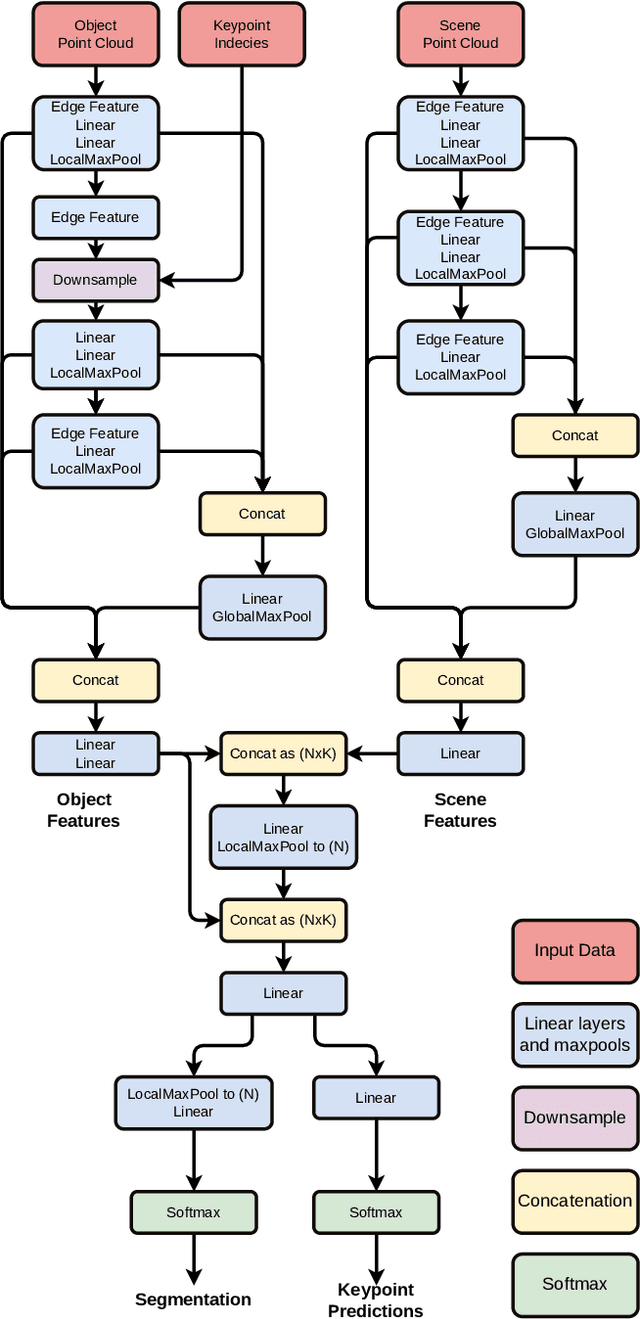
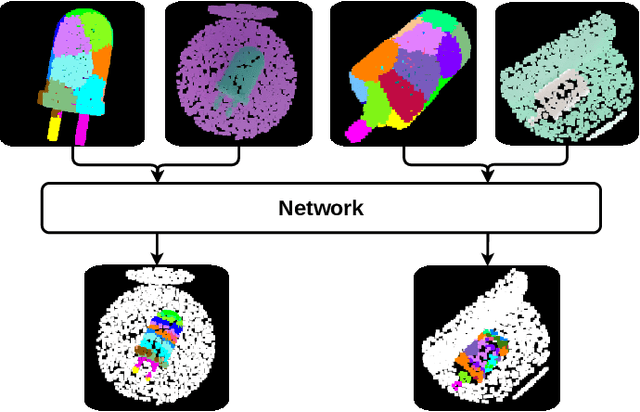

In this paper, we present GP3D, a novel network for generalized pose estimation in 3D point clouds. The method generalizes to new objects by using both the scene point cloud and the object point cloud with keypoint indexes as input. The network is trained to match the object keypoints to scene points. To address the pose estimation of novel objects we also present a new approach for training pose estimation. The typical solution is a single model trained for pose estimation of a specific object in any scenario. This has several drawbacks: training a model for each object is time-consuming, energy consuming, and by excluding the scenario information the task becomes more difficult. In this paper, we present the opposite solution; a scenario-specific pose estimation method for novel objects that do not require retraining. The network is trained on 1500 objects and is able to learn a generalized solution. We demonstrate that the network is able to correctly predict novel objects, and demonstrate the ability of the network to perform outside of the trained class. We believe that the demonstrated method is a valuable solution for many real-world scenarios. Code and trained network will be made available after publication.
Training Language Models with Language Feedback at Scale
Mar 28, 2023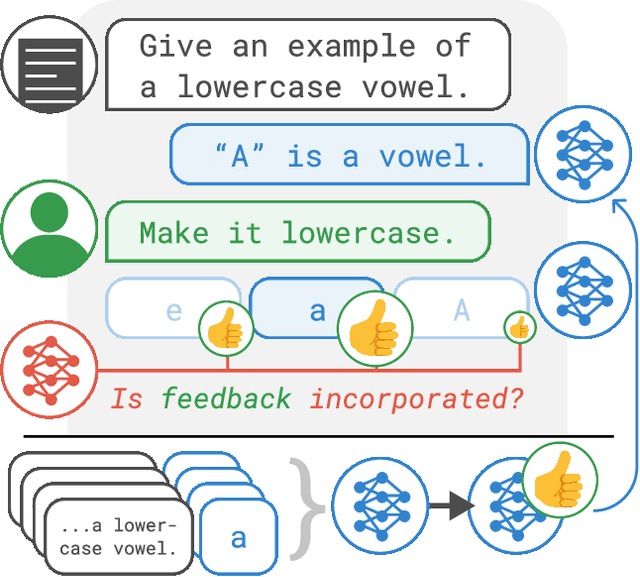


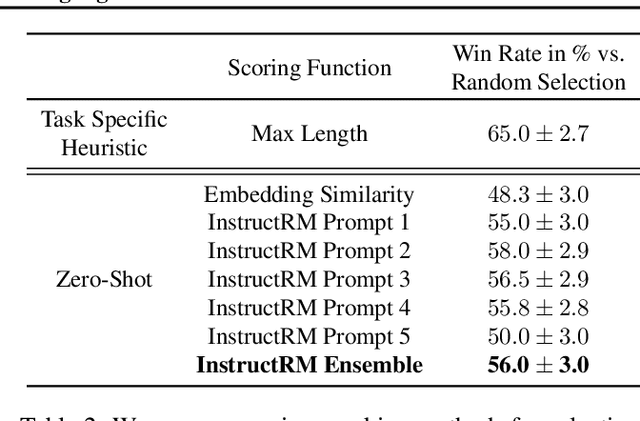
Pretrained language models often generate outputs that are not in line with human preferences, such as harmful text or factually incorrect summaries. Recent work approaches the above issues by learning from a simple form of human feedback: comparisons between pairs of model-generated outputs. However, comparison feedback only conveys limited information about human preferences. In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback. ILF consists of three steps that are applied iteratively: first, conditioning the language model on the input, an initial LM output, and feedback to generate refinements. Second, selecting the refinement incorporating the most feedback. Third, finetuning the language model to maximize the likelihood of the chosen refinement given the input. We show theoretically that ILF can be viewed as Bayesian Inference, similar to Reinforcement Learning from human feedback. We evaluate ILF's effectiveness on a carefully-controlled toy task and a realistic summarization task. Our experiments demonstrate that large language models accurately incorporate feedback and that finetuning with ILF scales well with the dataset size, even outperforming finetuning on human summaries. Learning from both language and comparison feedback outperforms learning from each alone, achieving human-level summarization performance.
Structured Dynamic Pricing: Optimal Regret in a Global Shrinkage Model
Mar 28, 2023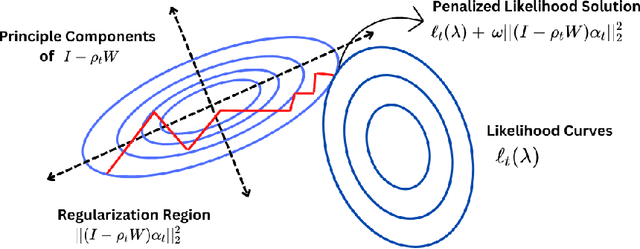
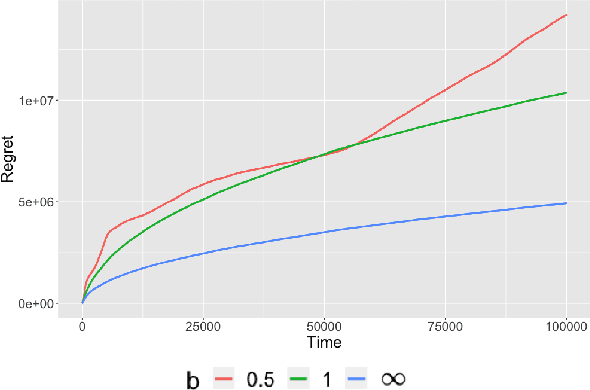
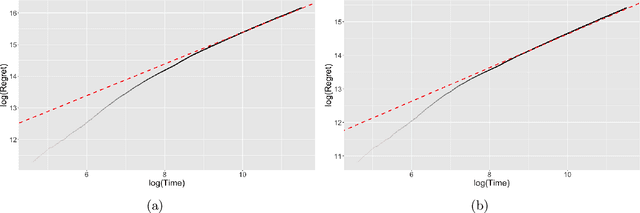
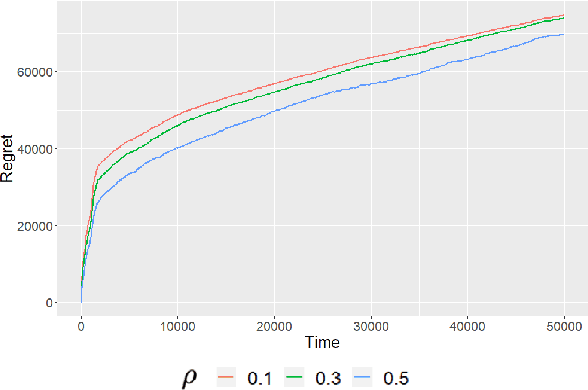
We consider dynamic pricing strategies in a streamed longitudinal data set-up where the objective is to maximize, over time, the cumulative profit across a large number of customer segments. We consider a dynamic probit model with the consumers' preferences as well as price sensitivity varying over time. Building on the well-known finding that consumers sharing similar characteristics act in similar ways, we consider a global shrinkage structure, which assumes that the consumers' preferences across the different segments can be well approximated by a spatial autoregressive (SAR) model. In such a streamed longitudinal set-up, we measure the performance of a dynamic pricing policy via regret, which is the expected revenue loss compared to a clairvoyant that knows the sequence of model parameters in advance. We propose a pricing policy based on penalized stochastic gradient descent (PSGD) and explicitly characterize its regret as functions of time, the temporal variability in the model parameters as well as the strength of the auto-correlation network structure spanning the varied customer segments. Our regret analysis results not only demonstrate asymptotic optimality of the proposed policy but also show that for policy planning it is essential to incorporate available structural information as policies based on unshrunken models are highly sub-optimal in the aforementioned set-up.