 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Complexity of Why-Provenance for Datalog Queries
Mar 22, 2023

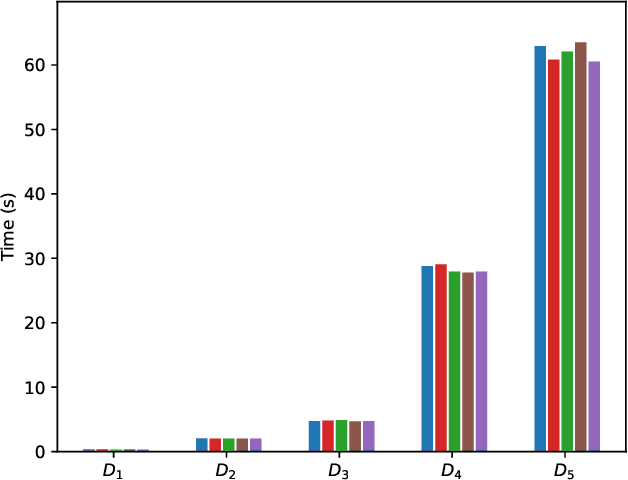
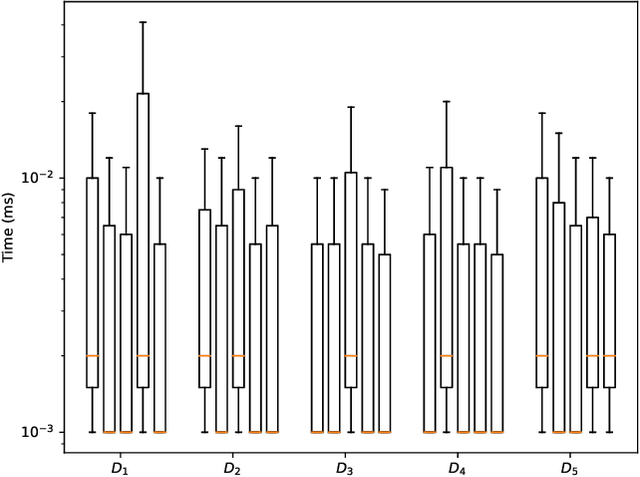
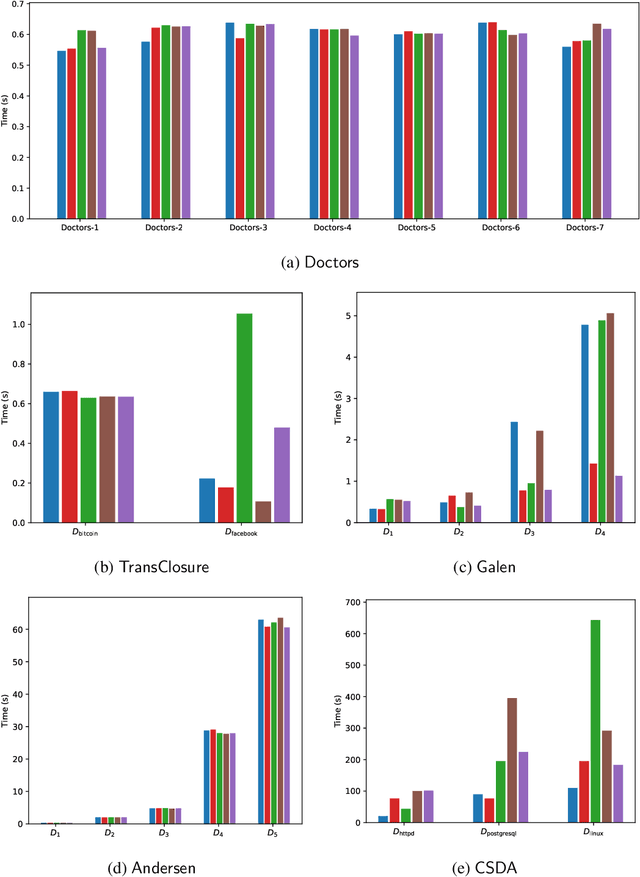
Explaining why a database query result is obtained is an essential task towards the goal of Explainable AI, especially nowadays where expressive database query languages such as Datalog play a critical role in the development of ontology-based applications. A standard way of explaining a query result is the so-called why-provenance, which essentially provides information about the witnesses to a query result in the form of subsets of the input database that are sufficient to derive that result. To our surprise, despite the fact that the notion of why-provenance for Datalog queries has been around for decades and intensively studied, its computational complexity remains unexplored. The goal of this work is to fill this apparent gap in the why-provenance literature. Towards this end, we pinpoint the data complexity of why-provenance for Datalog queries and key subclasses thereof. The takeaway of our work is that why-provenance for recursive queries, even if the recursion is limited to be linear, is an intractable problem, whereas for non-recursive queries is highly tractable. Having said that, we experimentally confirm, by exploiting SAT solvers, that making why-provenance for (recursive) Datalog queries work in practice is not an unrealistic goal.
Coupling Artificial Neurons in BERT and Biological Neurons in the Human Brain
Mar 27, 2023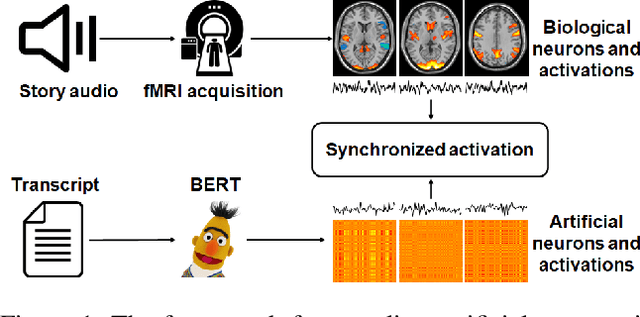
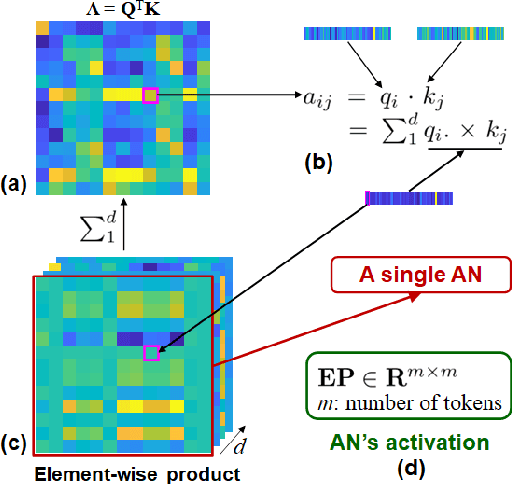
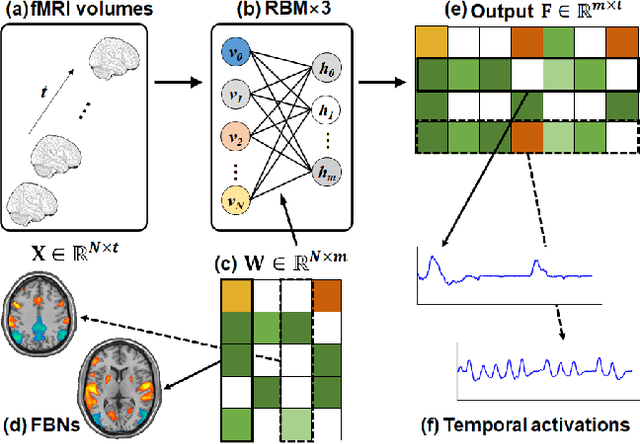
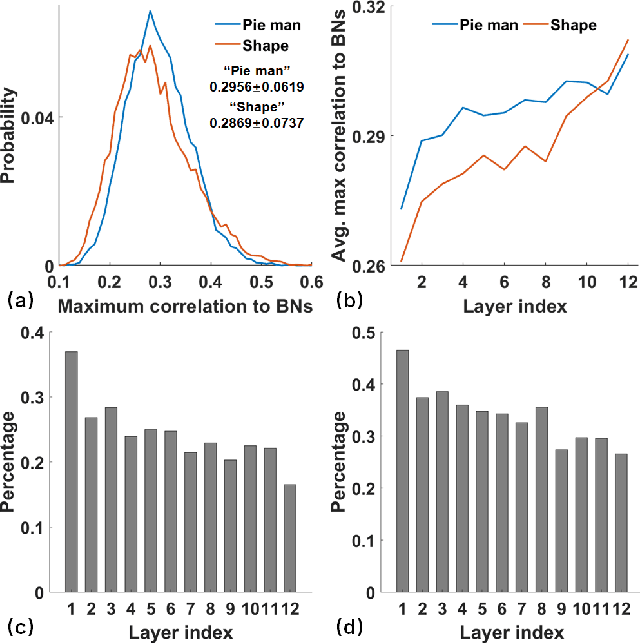
Linking computational natural language processing (NLP) models and neural responses to language in the human brain on the one hand facilitates the effort towards disentangling the neural representations underpinning language perception, on the other hand provides neurolinguistics evidence to evaluate and improve NLP models. Mappings of an NLP model's representations of and the brain activities evoked by linguistic input are typically deployed to reveal this symbiosis. However, two critical problems limit its advancement: 1) The model's representations (artificial neurons, ANs) rely on layer-level embeddings and thus lack fine-granularity; 2) The brain activities (biological neurons, BNs) are limited to neural recordings of isolated cortical unit (i.e., voxel/region) and thus lack integrations and interactions among brain functions. To address those problems, in this study, we 1) define ANs with fine-granularity in transformer-based NLP models (BERT in this study) and measure their temporal activations to input text sequences; 2) define BNs as functional brain networks (FBNs) extracted from functional magnetic resonance imaging (fMRI) data to capture functional interactions in the brain; 3) couple ANs and BNs by maximizing the synchronization of their temporal activations. Our experimental results demonstrate 1) The activations of ANs and BNs are significantly synchronized; 2) the ANs carry meaningful linguistic/semantic information and anchor to their BN signatures; 3) the anchored BNs are interpretable in a neurolinguistic context. Overall, our study introduces a novel, general, and effective framework to link transformer-based NLP models and neural activities in response to language and may provide novel insights for future studies such as brain-inspired evaluation and development of NLP models.
Automatic breach detection during spine pedicle drilling based on vibroacoustic sensing
Mar 27, 2023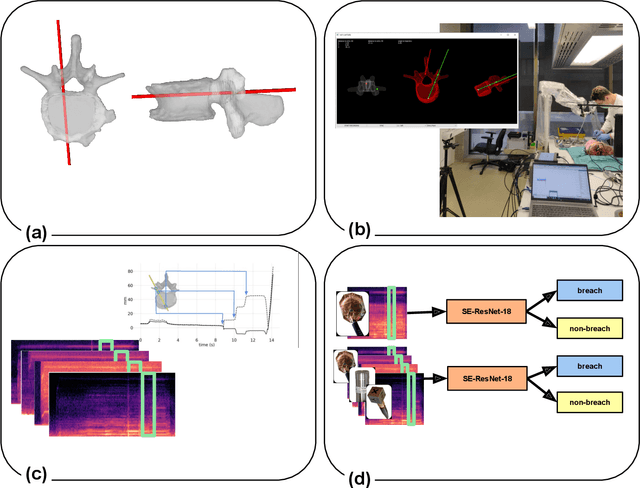
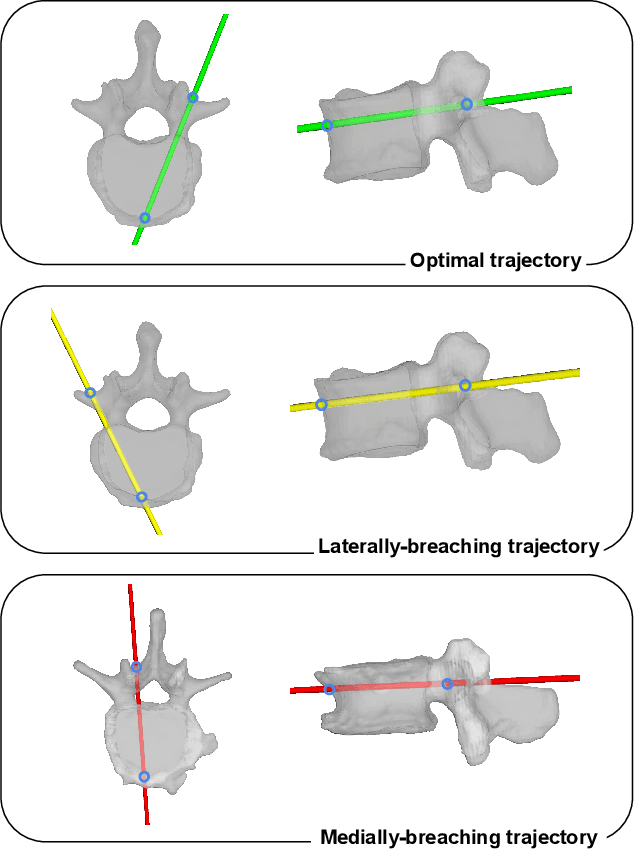

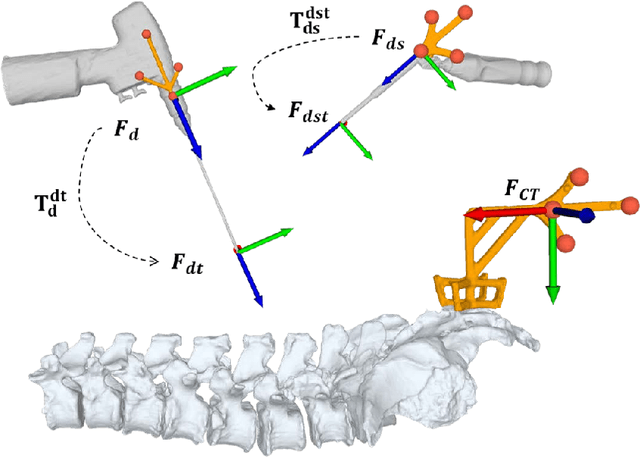
Pedicle drilling is a complex and critical spinal surgery task. Detecting breach or penetration of the surgical tool to the cortical wall during pilot-hole drilling is essential to avoid damage to vital anatomical structures adjacent to the pedicle, such as the spinal cord, blood vessels, and nerves. Currently, the guidance of pedicle drilling is done using image-guided methods that are radiation intensive and limited to the preoperative information. This work proposes a new radiation-free breach detection algorithm leveraging a non-visual sensor setup in combination with deep learning approach. Multiple vibroacoustic sensors, such as a contact microphone, a free-field microphone, a tri-axial accelerometer, a uni-axial accelerometer, and an optical tracking system were integrated into the setup. Data were collected on four cadaveric human spines, ranging from L5 to T10. An experienced spine surgeon drilled the pedicles relying on optical navigation. A new automatic labeling method based on the tracking data was introduced. Labeled data was subsequently fed to the network in mel-spectrograms, classifying the data into breach and non-breach. Different sensor types, sensor positioning, and their combinations were evaluated. The best results in breach recall for individual sensors could be achieved using contact microphones attached to the dorsal skin (85.8\%) and uni-axial accelerometers clamped to the spinous process of the drilled vertebra (81.0\%). The best-performing data fusion model combined the latter two sensors with a breach recall of 98\%. The proposed method shows the great potential of non-visual sensor fusion for avoiding screw misplacement and accidental bone breaches during pedicle drilling and could be extended to further surgical applications.
Adaptive Federated Learning via Entropy Approach
Mar 27, 2023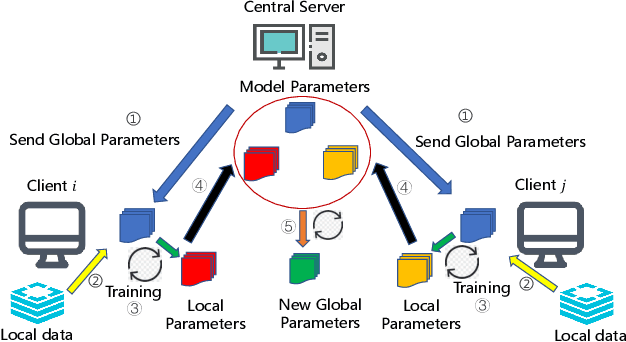
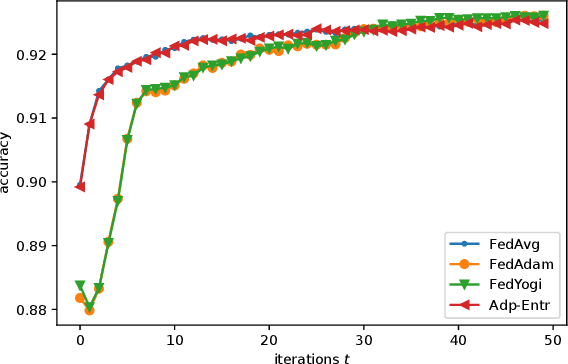
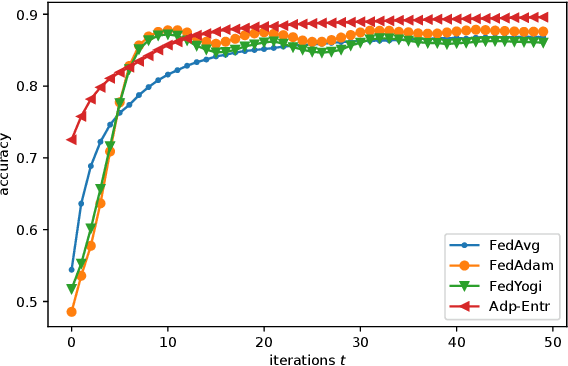
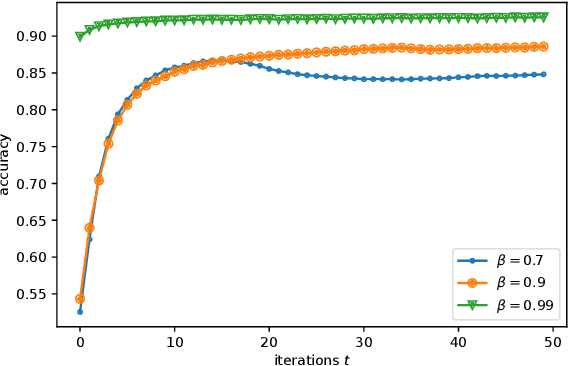
Federated Learning (FL) has recently emerged as a popular framework, which allows resource-constrained discrete clients to cooperatively learn the global model under the orchestration of a central server while storing privacy-sensitive data locally. However, due to the difference in equipment and data divergence of heterogeneous clients, there will be parameter deviation between local models, resulting in a slow convergence rate and a reduction of the accuracy of the global model. The current FL algorithms use the static client learning strategy pervasively and can not adapt to the dynamic training parameters of different clients. In this paper, by considering the deviation between different local model parameters, we propose an adaptive learning rate scheme for each client based on entropy theory to alleviate the deviation between heterogeneous clients and achieve fast convergence of the global model. It's difficult to design the optimal dynamic learning rate for each client as the local information of other clients is unknown, especially during the local training epochs without communications between local clients and the central server. To enable a decentralized learning rate design for each client, we first introduce mean-field schemes to estimate the terms related to other clients' local model parameters. Then the decentralized adaptive learning rate for each client is obtained in closed form by constructing the Hamilton equation. Moreover, we prove that there exist fixed point solutions for the mean-field estimators, and an algorithm is proposed to obtain them. Finally, extensive experimental results on real datasets show that our algorithm can effectively eliminate the deviation between local model parameters compared to other recent FL algorithms.
A large-scale dataset for end-to-end table recognition in the wild
Mar 27, 2023Table recognition (TR) is one of the research hotspots in pattern recognition, which aims to extract information from tables in an image. Common table recognition tasks include table detection (TD), table structure recognition (TSR) and table content recognition (TCR). TD is to locate tables in the image, TCR recognizes text content, and TSR recognizes spatial ogical structure. Currently, the end-to-end TR in real scenarios, accomplishing the three sub-tasks simultaneously, is yet an unexplored research area. One major factor that inhibits researchers is the lack of a benchmark dataset. To this end, we propose a new large-scale dataset named Table Recognition Set (TabRecSet) with diverse table forms sourcing from multiple scenarios in the wild, providing complete annotation dedicated to end-to-end TR research. It is the largest and first bi-lingual dataset for end-to-end TR, with 38.1K tables in which 20.4K are in English\, and 17.7K are in Chinese. The samples have diverse forms, such as the border-complete and -incomplete table, regular and irregular table (rotated, distorted, etc.). The scenarios are multiple in the wild, varying from scanned to camera-taken images, documents to Excel tables, educational test papers to financial invoices. The annotations are complete, consisting of the table body spatial annotation, cell spatial logical annotation and text content for TD, TSR and TCR, respectively. The spatial annotation utilizes the polygon instead of the bounding box or quadrilateral adopted by most datasets. The polygon spatial annotation is more suitable for irregular tables that are common in wild scenarios. Additionally, we propose a visualized and interactive annotation tool named TableMe to improve the efficiency and quality of table annotation.
Age of Information in Downlink Systems: Broadcast or Distributed Transmission?
Oct 28, 2022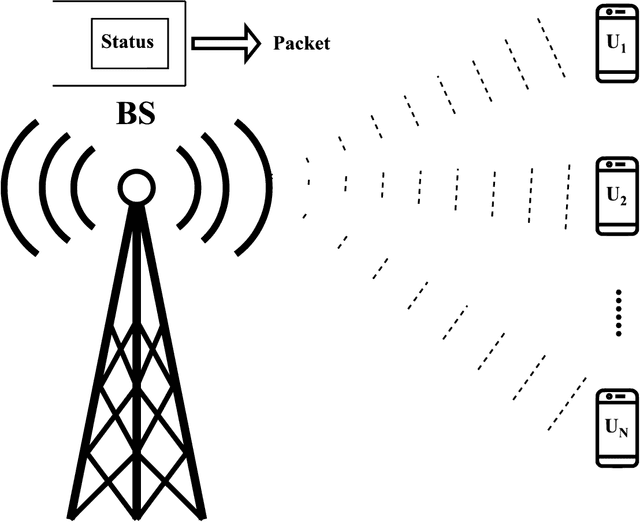
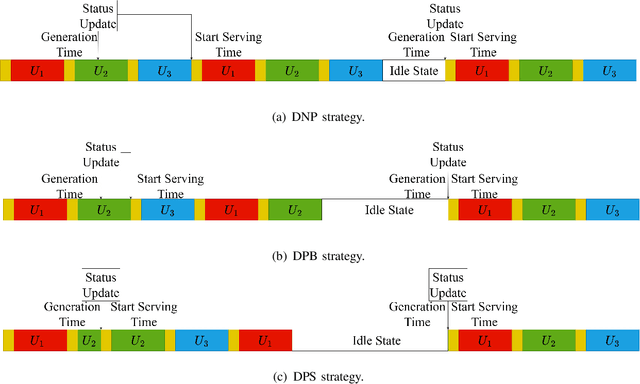
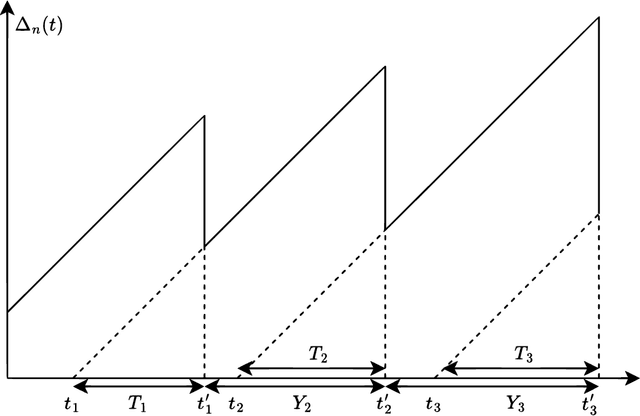
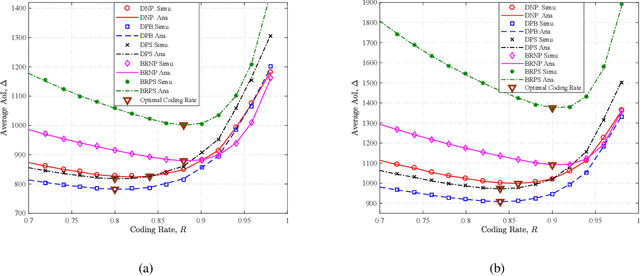
We analytically decide whether the broadcast transmission scheme or the distributed transmission scheme achieves the optimal age of information (AoI) performance of a multiuser system where a base station (BS) generates and transmits status updates to multiple user equipments (UEs). In the broadcast transmission scheme, the status update for all UEs is jointly encoded into a packet for transmission, while in the distributed transmission scheme, the status update for each UE is encoded individually and transmitted by following the round robin policy. For both transmission schemes, we examine three packet management strategies, namely the non-preemption strategy, the preemption in buffer strategy, and the preemption in serving strategy. We first derive new closed-form expressions for the average AoI achieved by two transmission schemes with three packet management strategies. Based on them, we compare the AoI performance of two transmission schemes in two systems, namely, the remote control system and the dynamic system. Aided by simulation results, we verify our analysis and investigate the impact of system parameters on the average AoI. For example, the distributed transmission scheme is more appropriate for the system with a large number UEs. Otherwise, the broadcast transmission scheme is more appropriate.
MODIFY: Model-driven Face Stylization without Style Images
Mar 17, 2023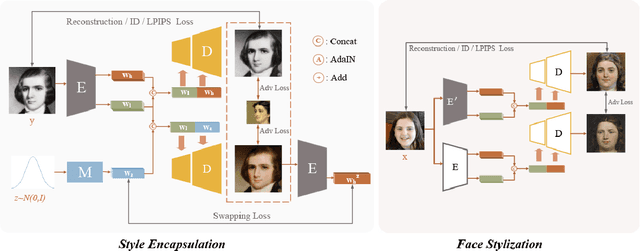
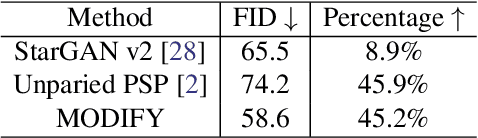


Existing face stylization methods always acquire the presence of the target (style) domain during the translation process, which violates privacy regulations and limits their applicability in real-world systems. To address this issue, we propose a new method called MODel-drIven Face stYlization (MODIFY), which relies on the generative model to bypass the dependence of the target images. Briefly, MODIFY first trains a generative model in the target domain and then translates a source input to the target domain via the provided style model. To preserve the multimodal style information, MODIFY further introduces an additional remapping network, mapping a known continuous distribution into the encoder's embedding space. During translation in the source domain, MODIFY fine-tunes the encoder module within the target style-persevering model to capture the content of the source input as precisely as possible. Our method is extremely simple and satisfies versatile training modes for face stylization. Experimental results on several different datasets validate the effectiveness of MODIFY for unsupervised face stylization.
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
Mar 17, 2023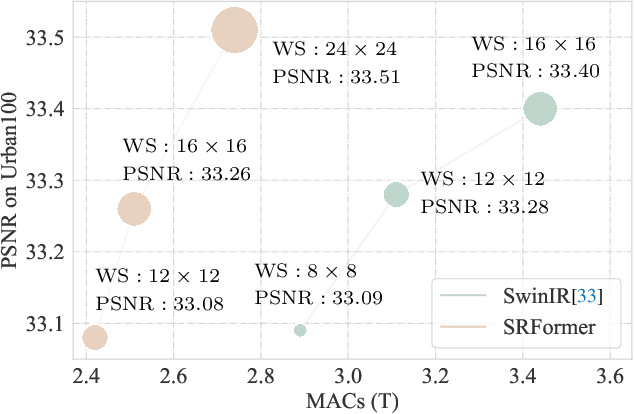
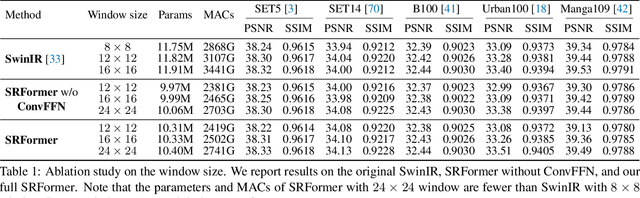

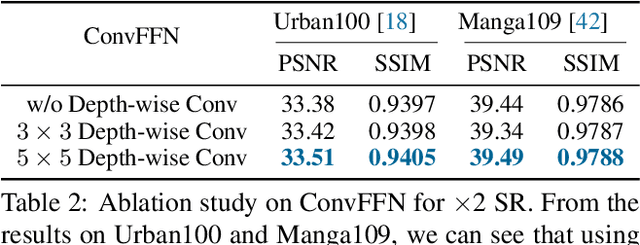
Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance but the computation overhead is also considerable. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Our PSA is simple and can be easily applied to existing super-resolution networks based on window self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. We hope our simple and effective approach can serve as a useful tool for future research in super-resolution model design.
Contrastive Self-supervised Learning in Recommender Systems: A Survey
Mar 17, 2023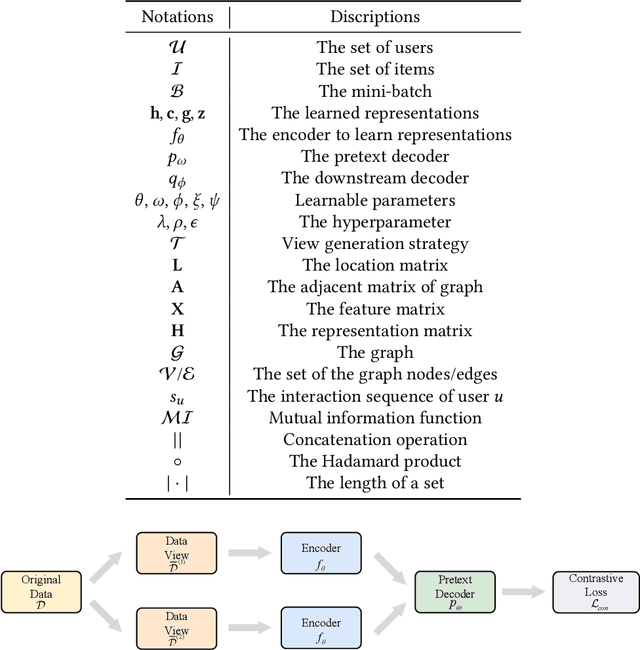
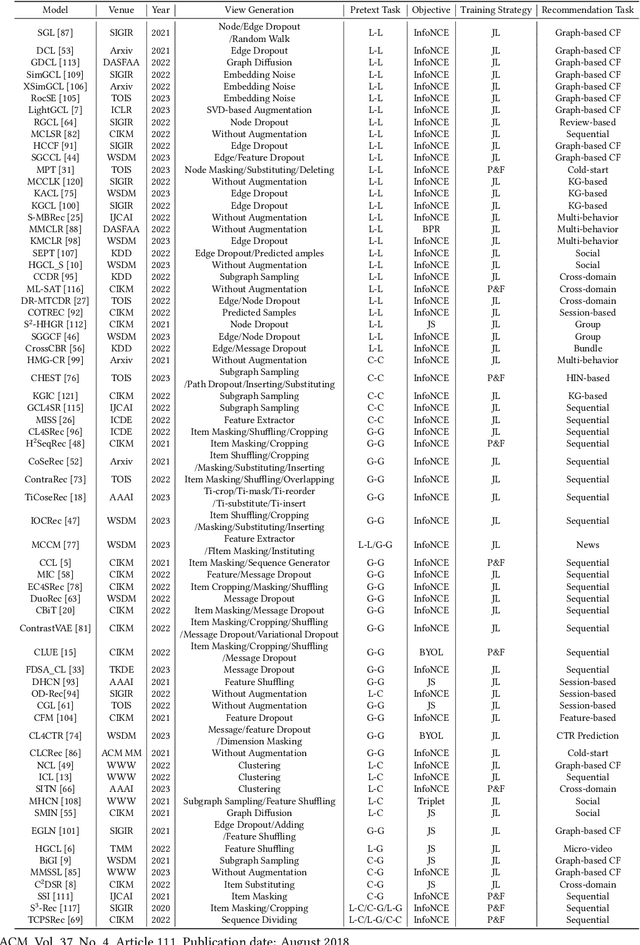
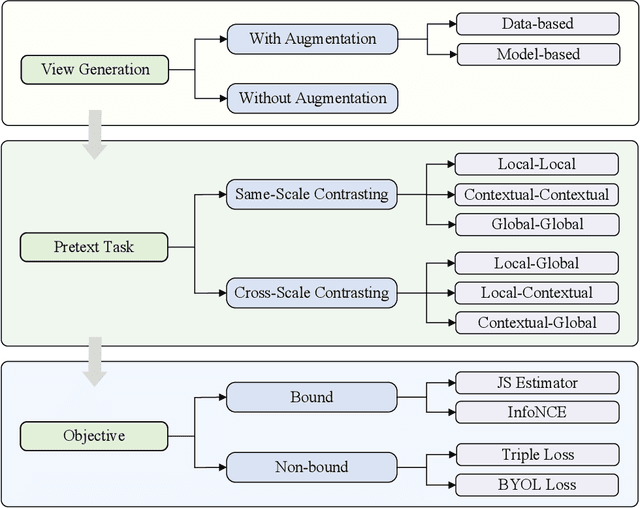
Deep learning-based recommender systems have achieved remarkable success in recent years. However, these methods usually heavily rely on labeled data (i.e., user-item interactions), suffering from problems such as data sparsity and cold-start. Self-supervised learning, an emerging paradigm that extracts information from unlabeled data, provides insights into addressing these problems. Specifically, contrastive self-supervised learning, due to its flexibility and promising performance, has attracted considerable interest and recently become a dominant branch in self-supervised learning-based recommendation methods. In this survey, we provide an up-to-date and comprehensive review of current contrastive self-supervised learning-based recommendation methods. Firstly, we propose a unified framework for these methods. We then introduce a taxonomy based on the key components of the framework, including view generation strategy, contrastive task, and contrastive objective. For each component, we provide detailed descriptions and discussions to guide the choice of the appropriate method. Finally, we outline open issues and promising directions for future research.
Style Transfer for 2D Talking Head Animation
Mar 17, 2023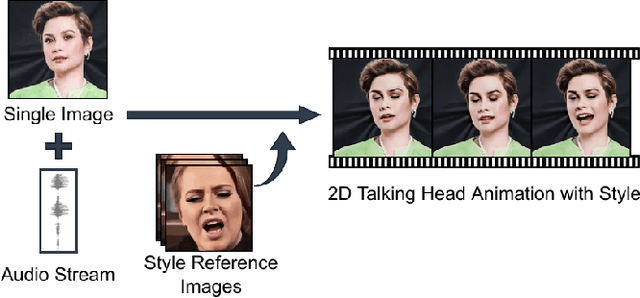
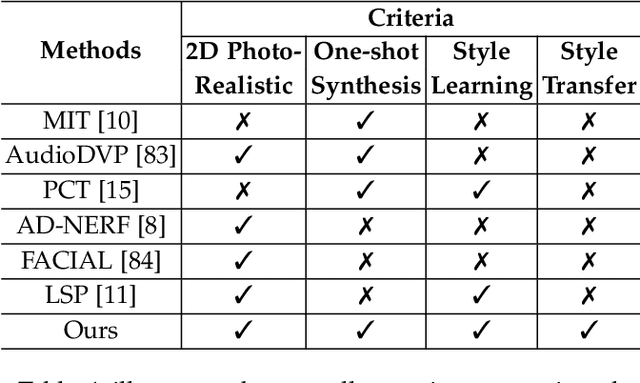
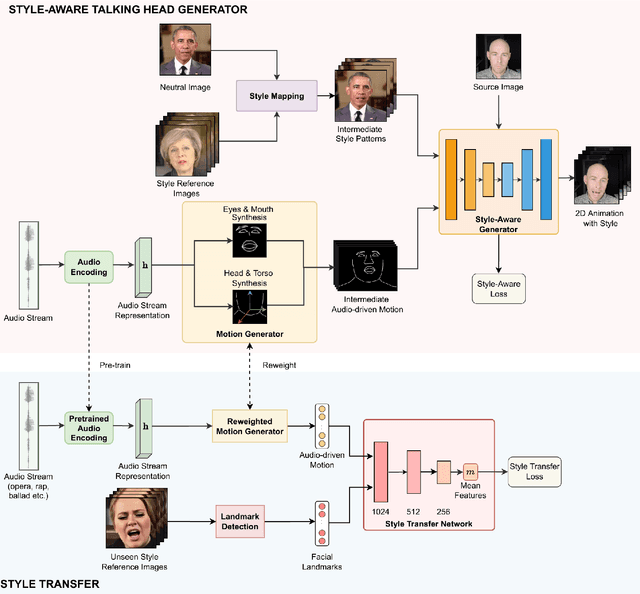
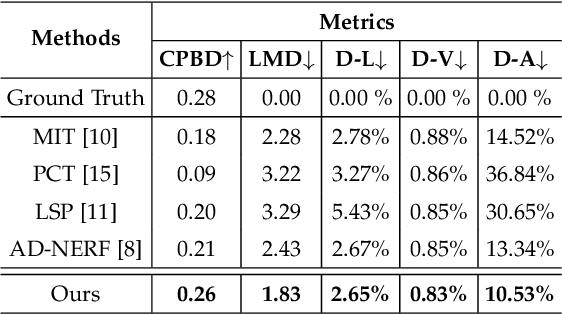
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.