 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Affordance Diffusion: Synthesizing Hand-Object Interactions
Mar 21, 2023

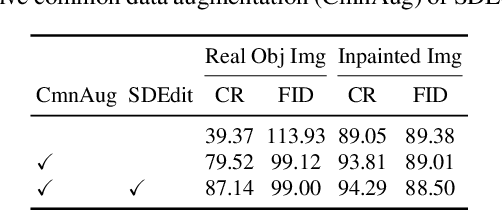
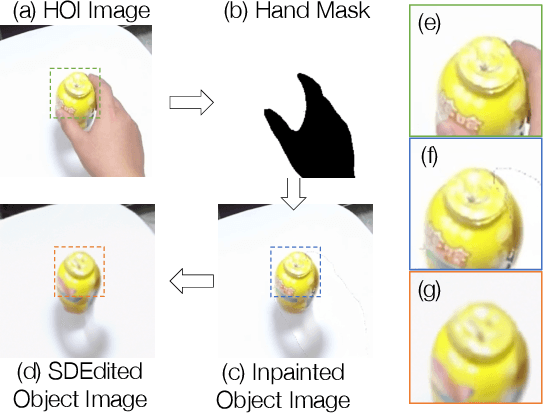

Recent successes in image synthesis are powered by large-scale diffusion models. However, most methods are currently limited to either text- or image-conditioned generation for synthesizing an entire image, texture transfer or inserting objects into a user-specified region. In contrast, in this work we focus on synthesizing complex interactions (ie, an articulated hand) with a given object. Given an RGB image of an object, we aim to hallucinate plausible images of a human hand interacting with it. We propose a two-step generative approach: a LayoutNet that samples an articulation-agnostic hand-object-interaction layout, and a ContentNet that synthesizes images of a hand grasping the object given the predicted layout. Both are built on top of a large-scale pretrained diffusion model to make use of its latent representation. Compared to baselines, the proposed method is shown to generalize better to novel objects and perform surprisingly well on out-of-distribution in-the-wild scenes of portable-sized objects. The resulting system allows us to predict descriptive affordance information, such as hand articulation and approaching orientation. Project page: https://judyye.github.io/affordiffusion-www
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023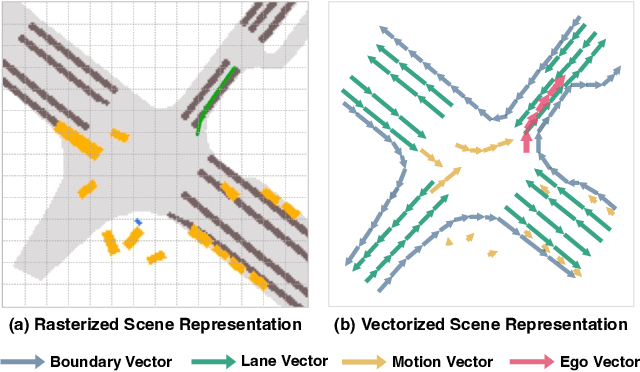
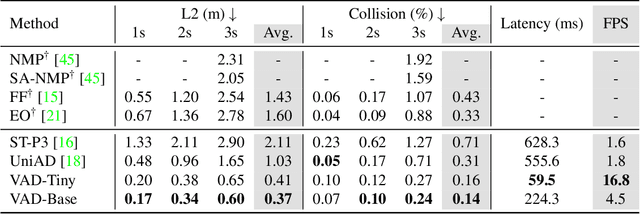
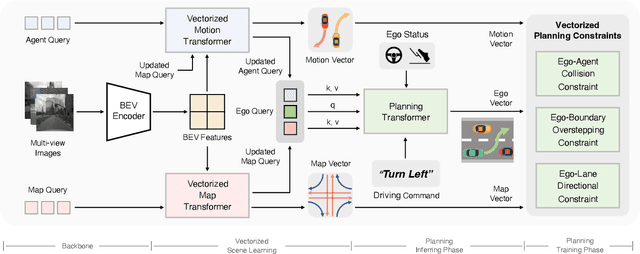
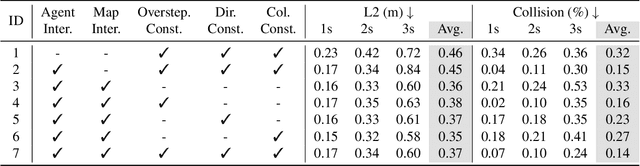
Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Community detection in complex networks via node similarity, graph representation learning, and hierarchical clustering
Mar 21, 2023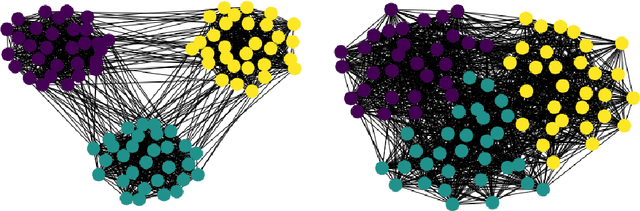
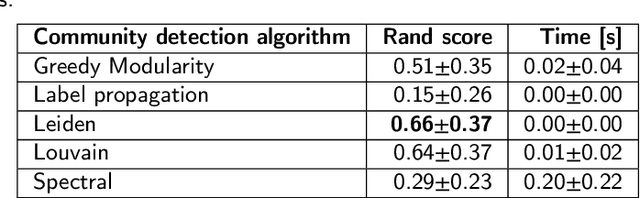
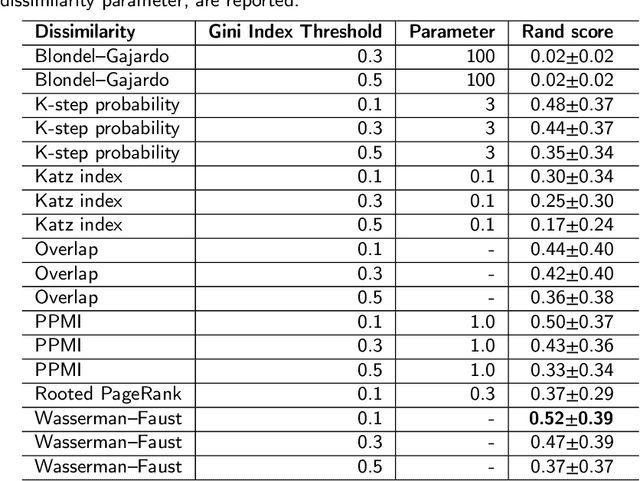
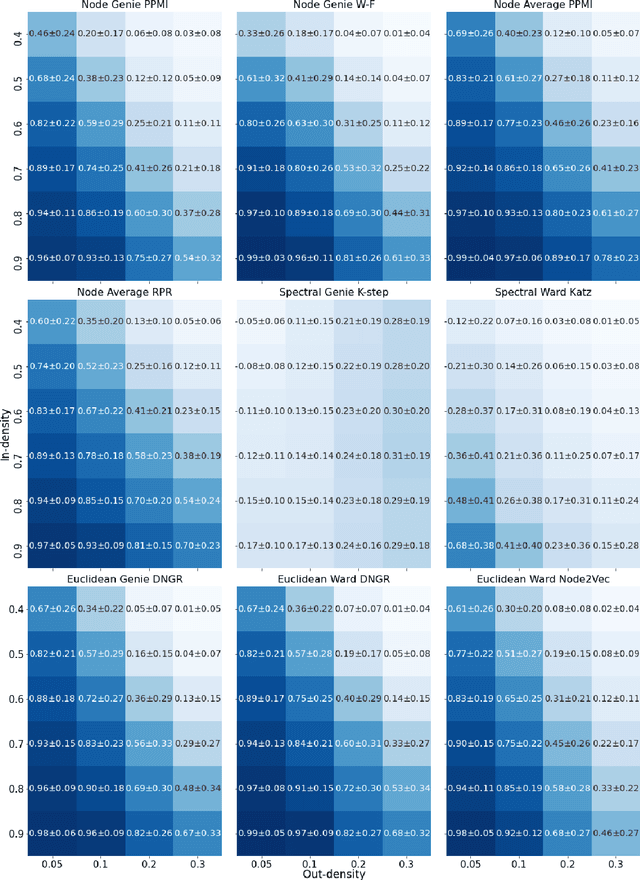
Community detection is a critical challenge in the analysis of real-world graphs and complex networks, including social, transportation, citation, cybersecurity networks, and food webs. Motivated by many similarities between community detection and clustering in Euclidean spaces, we propose three algorithm frameworks to apply hierarchical clustering methods for community detection in graphs. We show that using our methods, it is possible to apply various linkage-based (single-, complete-, average- linkage, Ward, Genie) clustering algorithms to find communities based on vertex similarity matrices, eigenvector matrices thereof, and Euclidean vector representations of nodes. We convey a comprehensive analysis of choices for each framework, including state-of-the-art graph representation learning algorithms, such as Deep Neural Graph Representation, and a vertex proximity matrix known to yield high-quality results in machine learning -- Positive Pointwise Mutual Information. Overall, we test over a hundred combinations of framework components and show that some -- including Wasserman-Faust and PPMI proximity, DNGR representation -- can compete with algorithms such as state-of-the-art Leiden and Louvain and easily outperform other known community detection algorithms. Notably, our algorithms remain hierarchical and allow the user to specify any number of clusters a priori.
Reconfigurable Intelligent Surface Aided Hybrid Beamforming: Optimal Placement and Beamforming Design
Mar 21, 2023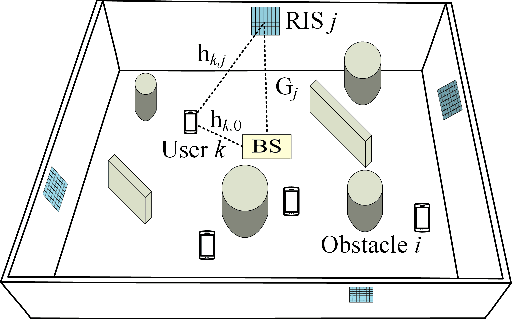
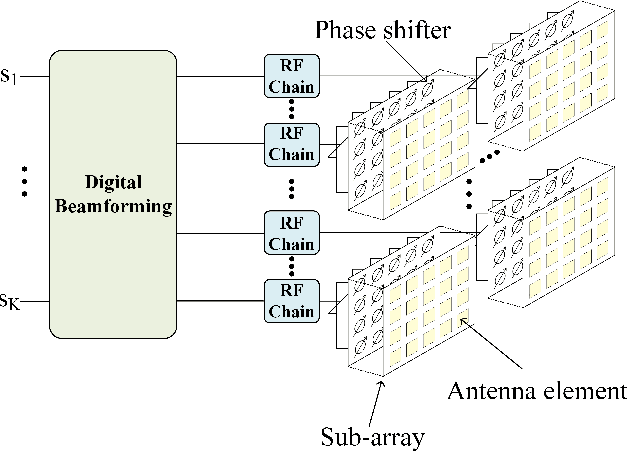
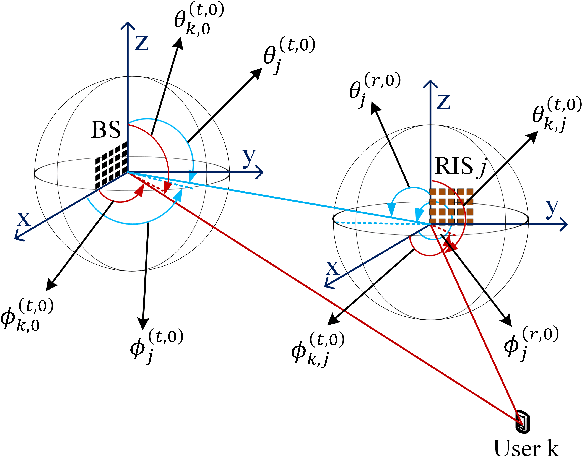
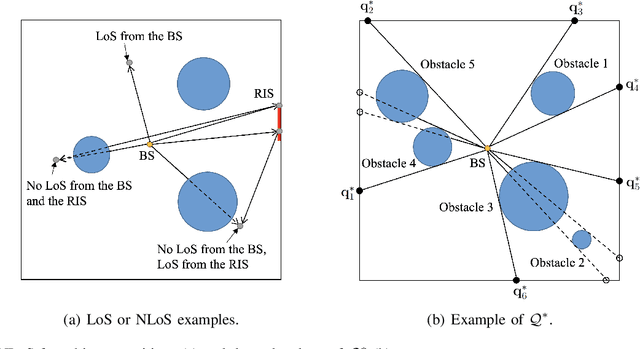
We consider reconfigurable intelligent surface (RIS) aided sixth-generation (6G) terahertz (THz) communications for indoor environment in which a base station (BS) wishes to send independent messages to its serving users with the help of multiple RISs. For indoor environment, various obstacles such as pillars, walls, and other objects can result in no line-of-sight signal path between the BS and a user, which can significantly degrade performance. To overcome such limitation of indoor THz communication, we firstly optimize the placement of RISs to maximize the coverage area. Under the optimized RIS placement, we propose 3D hybrid beamforming at the BS and phase adjustment at RISs, which are jointly performed at the BS and RISs via codebook-based 3D beam scanning with low complexity. Numerical simulations demonstrate that the proposed scheme significantly improves the average sum rate compared to the cases of no RIS and randomly deployed RISs. It is further shown that the proposed codebook-based 3D beam scanning efficiently aligns analog beams between BS--user links or BS--RIS--user links and, as a consequence, achieves the average sum rate close to that of coherent beam alignment requiring global channel state information.
Focused and Collaborative Feedback Integration for Interactive Image Segmentation
Mar 21, 2023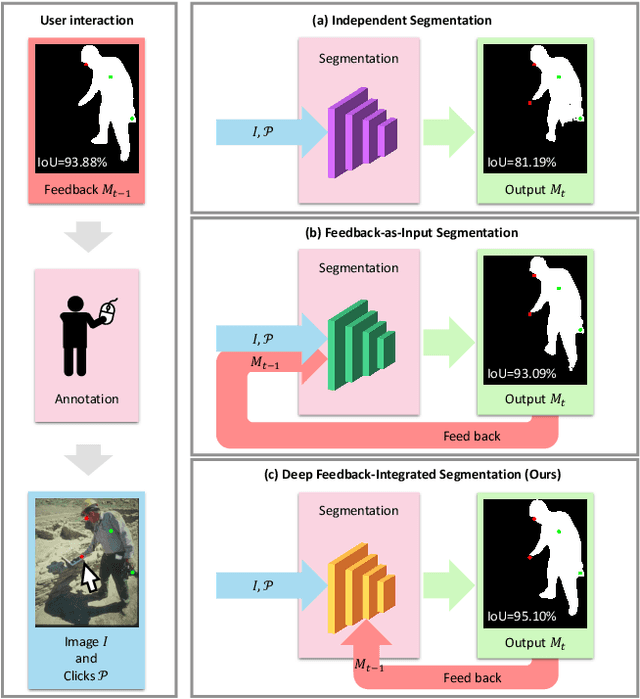
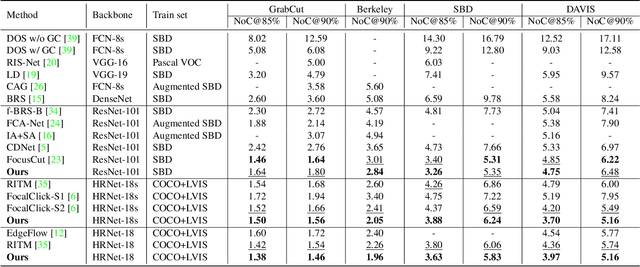
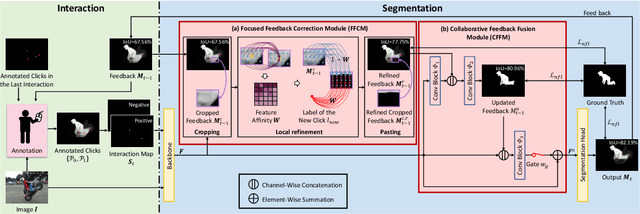
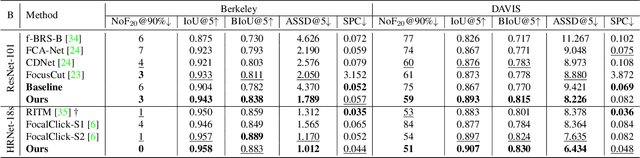
Interactive image segmentation aims at obtaining a segmentation mask for an image using simple user annotations. During each round of interaction, the segmentation result from the previous round serves as feedback to guide the user's annotation and provides dense prior information for the segmentation model, effectively acting as a bridge between interactions. Existing methods overlook the importance of feedback or simply concatenate it with the original input, leading to underutilization of feedback and an increase in the number of required annotations. To address this, we propose an approach called Focused and Collaborative Feedback Integration (FCFI) to fully exploit the feedback for click-based interactive image segmentation. FCFI first focuses on a local area around the new click and corrects the feedback based on the similarities of high-level features. It then alternately and collaboratively updates the feedback and deep features to integrate the feedback into the features. The efficacy and efficiency of FCFI were validated on four benchmarks, namely GrabCut, Berkeley, SBD, and DAVIS. Experimental results show that FCFI achieved new state-of-the-art performance with less computational overhead than previous methods. The source code is available at https://github.com/veizgyauzgyauz/FCFI.
Hyneter: Hybrid Network Transformer for Object Detection
Feb 18, 2023
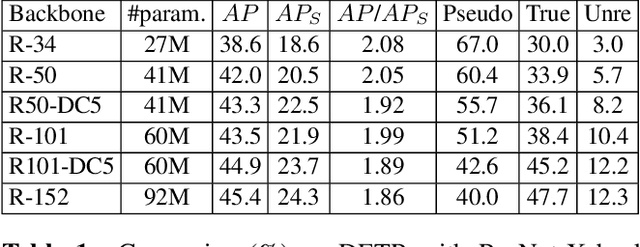
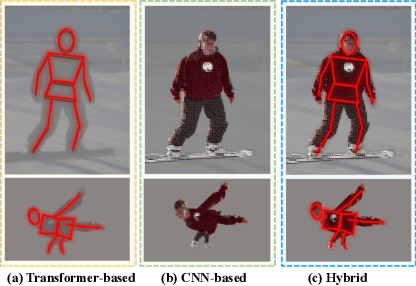
In this paper, we point out that the essential differences between CNN-based and Transformer-based detectors, which cause the worse performance of small objects in Transformer-based methods, are the gap between local information and global dependencies in feature extraction and propagation. To address these differences, we propose a new vision Transformer, called Hybrid Network Transformer (Hyneter), after pre-experiments that indicate the gap causes CNN-based and Transformer-based methods to increase size-different objects result unevenly. Different from the divide and conquer strategy in previous methods, Hyneters consist of Hybrid Network Backbone (HNB) and Dual Switching module (DS), which integrate local information and global dependencies, and transfer them simultaneously. Based on the balance strategy, HNB extends the range of local information by embedding convolution layers into Transformer blocks, and DS adjusts excessive reliance on global dependencies outside the patch.
Ultra-High-Resolution Detector Simulation with Intra-Event Aware GAN and Self-Supervised Relational Reasoning
Mar 07, 2023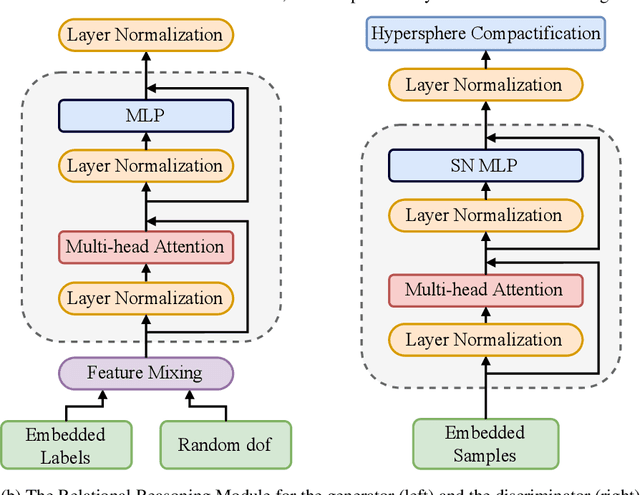

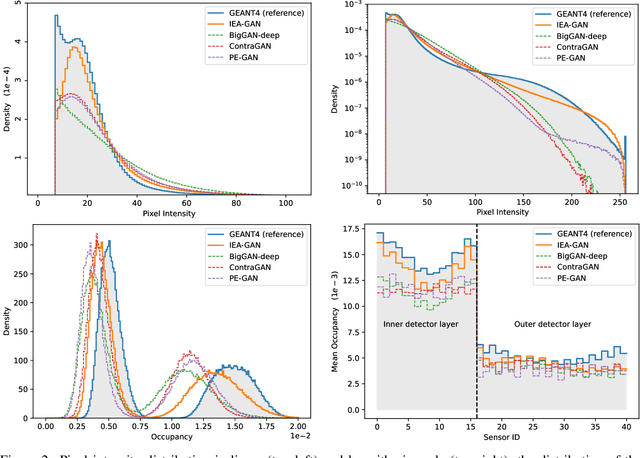
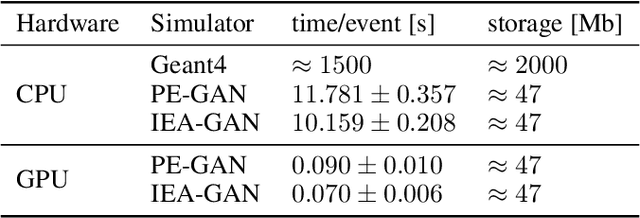
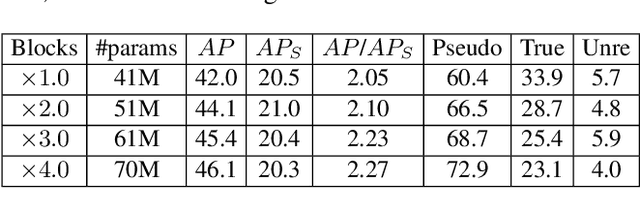
Simulating high-resolution detector responses is a storage-costly and computationally intensive process that has long been challenging in particle physics. Despite the ability of deep generative models to make this process more cost-efficient, ultra-high-resolution detector simulation still proves to be difficult as it contains correlated and fine-grained mutual information within an event. To overcome these limitations, we propose Intra-Event Aware GAN (IEA-GAN), a novel fusion of Self-Supervised Learning and Generative Adversarial Networks. IEA-GAN presents a Relational Reasoning Module that approximates the concept of an ''event'' in detector simulation, allowing for the generation of correlated layer-dependent contextualized images for high-resolution detector responses with a proper relational inductive bias. IEA-GAN also introduces a new intra-event aware loss and a Uniformity loss, resulting in significant enhancements to image fidelity and diversity. We demonstrate IEA-GAN's application in generating sensor-dependent images for the high-granularity Pixel Vertex Detector (PXD), with more than 7.5M information channels and a non-trivial geometry, at the Belle II Experiment. Applications of this work include controllable simulation-based inference and event generation, high-granularity detector simulation such as at the HL-LHC (High Luminosity LHC), and fine-grained density estimation and sampling. To the best of our knowledge, IEA-GAN is the first algorithm for faithful ultra-high-resolution detector simulation with event-based reasoning.
G-Signatures: Global Graph Propagation With Randomized Signatures
Feb 17, 2023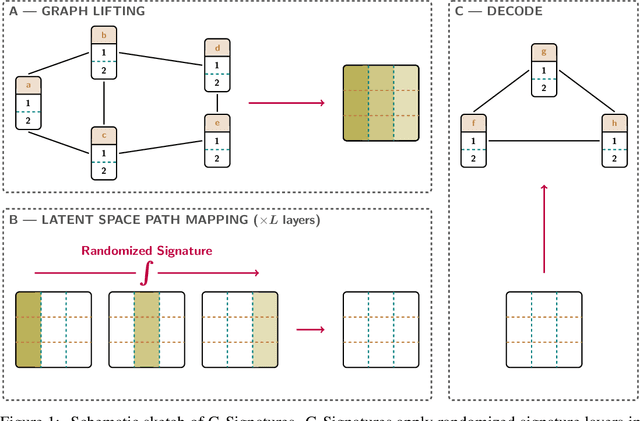

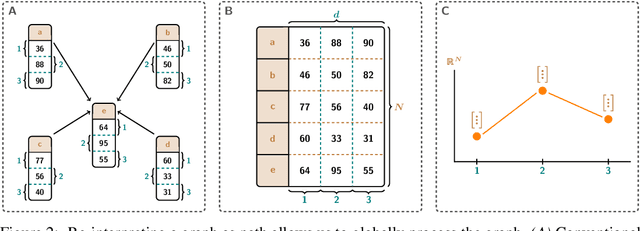

Graph neural networks (GNNs) have evolved into one of the most popular deep learning architectures. However, GNNs suffer from over-smoothing node information and, therefore, struggle to solve tasks where global graph properties are relevant. We introduce G-Signatures, a novel graph learning method that enables global graph propagation via randomized signatures. G-Signatures use a new graph lifting concept to embed graph structured information, which can be interpreted as path in latent space. We further introduce the idea of latent space path mapping, which allows us to repetitively traverse latent space paths, and, thus globally process information. G-Signatures excel at extracting and processing global graph properties, and effectively scale to large graph problems. Empirically, we confirm the advantages of our G-Signatures at several classification and regression tasks.
Age of Information in Downlink Systems: Broadcast or Distributed Transmission?
Oct 28, 2022
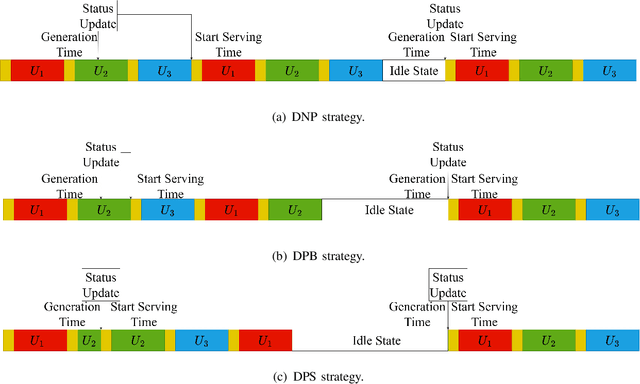
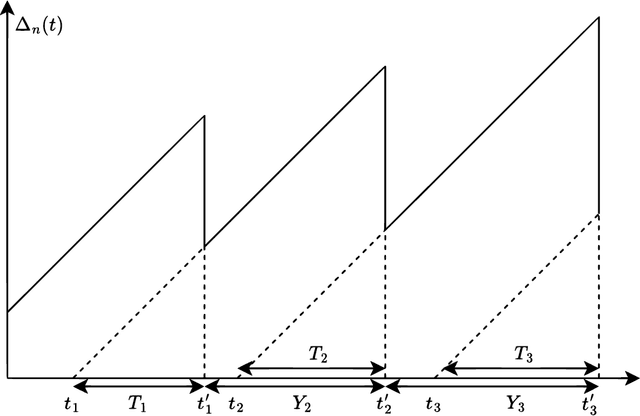
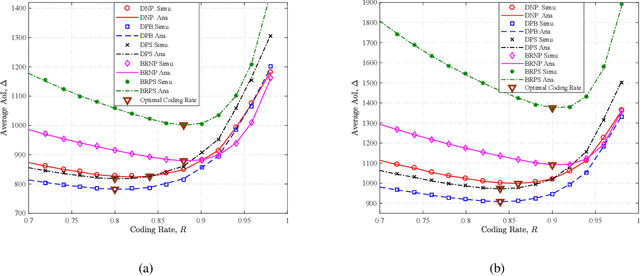
We analytically decide whether the broadcast transmission scheme or the distributed transmission scheme achieves the optimal age of information (AoI) performance of a multiuser system where a base station (BS) generates and transmits status updates to multiple user equipments (UEs). In the broadcast transmission scheme, the status update for all UEs is jointly encoded into a packet for transmission, while in the distributed transmission scheme, the status update for each UE is encoded individually and transmitted by following the round robin policy. For both transmission schemes, we examine three packet management strategies, namely the non-preemption strategy, the preemption in buffer strategy, and the preemption in serving strategy. We first derive new closed-form expressions for the average AoI achieved by two transmission schemes with three packet management strategies. Based on them, we compare the AoI performance of two transmission schemes in two systems, namely, the remote control system and the dynamic system. Aided by simulation results, we verify our analysis and investigate the impact of system parameters on the average AoI. For example, the distributed transmission scheme is more appropriate for the system with a large number UEs. Otherwise, the broadcast transmission scheme is more appropriate.
Large Language Models Can Be Easily Distracted by Irrelevant Context
Feb 13, 2023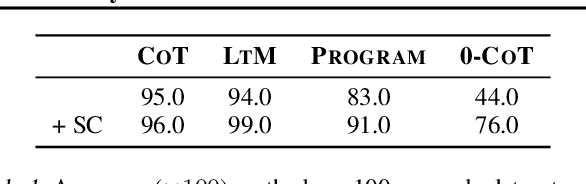
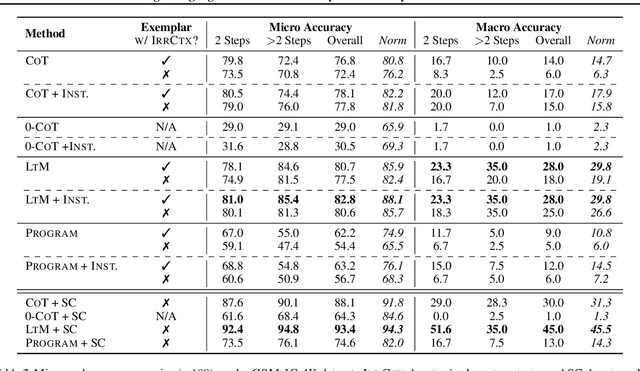

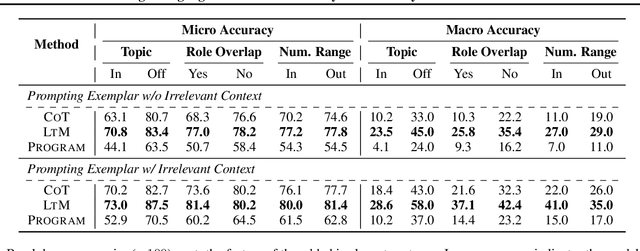
Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.