 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimizing Reconfigurable Intelligent Surfaces for Short Transmissions: How Detailed Configurations can be Afforded?
Mar 29, 2023
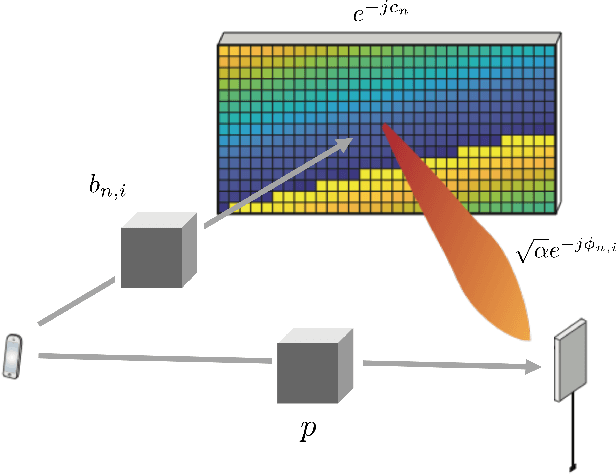
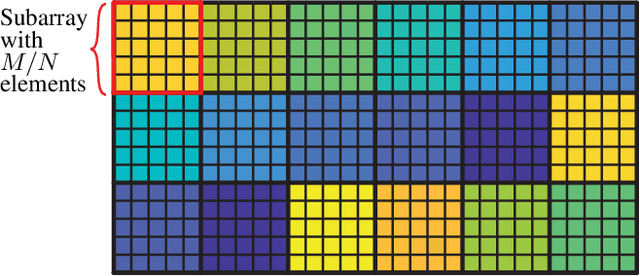
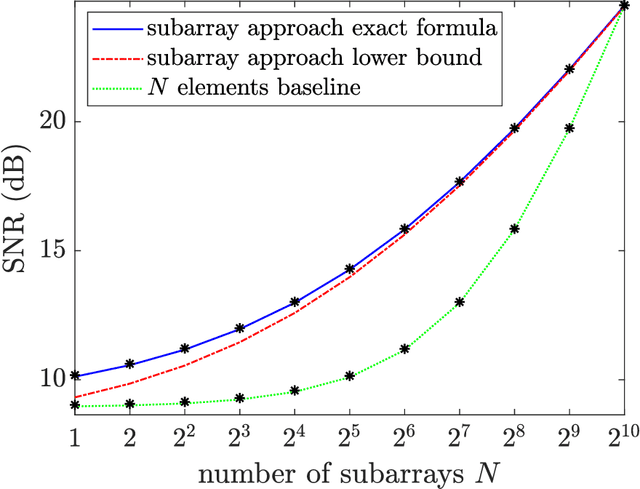
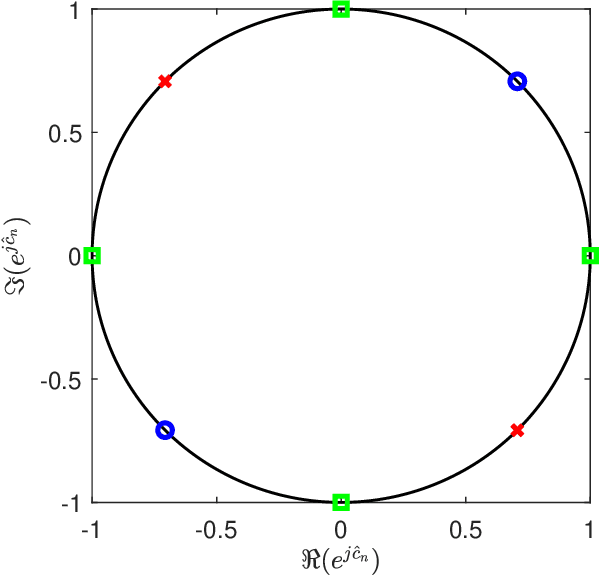
In this paper, we examine how to minimize the total energy consumption of a user equipment (UE) when it transmits a finite-sized data payload of a given length. The receiving base station (BS) controls a reconfigurable intelligent surface (RIS) that can be utilized to improve the channel conditions, but only if additional pilot signals are transmitted to configure the RIS. The challenge is that the pilot resources spent on configuring the RIS increase the energy consumption, especially when small payloads are transmitted, so it must be balanced against the energy savings during data transmission. We derive a formula for the energy consumption, taking both the pilot and data transmission power into account. It also includes the effects of imperfect channel state information, the use of phase-shifts with finite resolution at the RIS, and the passive circuit energy consumption. We also consider how dividing the RIS into subarrays consisting of multiple RIS elements using the same reflection coefficient can shorten the pilot length. In particular, the pilot power and subarray size are tuned to the payload length to minimize the energy consumption while maintaining parts of the aperture gain. Our analytical results show that, for a given geometry and transmission payload length, there exists a unique energy-minimizing subarray size and pilot power. For small payloads and when the channel conditions between the BS and UE are favorable compared to the path to the RIS, the energy consumption is minimized using subarrays with many elements and low pilot transmission power. On the other hand, when the channel conditions to the RIS are better and the data payloads are large, it is preferable to use fewer elements per subarray, potentially configuring each element individually and transmitting the pilot signals with additional power.
Context Understanding in Computer Vision: A Survey
Feb 10, 2023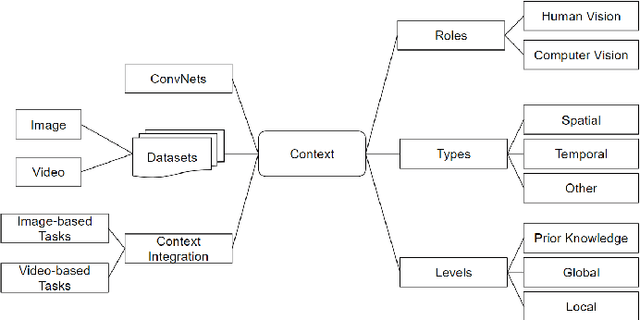
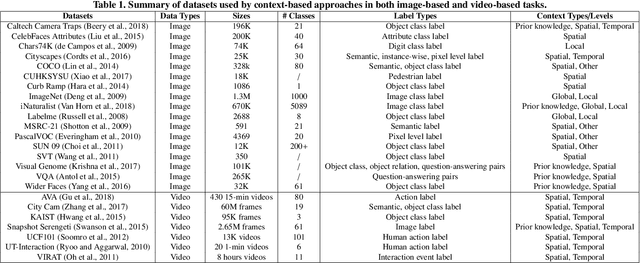

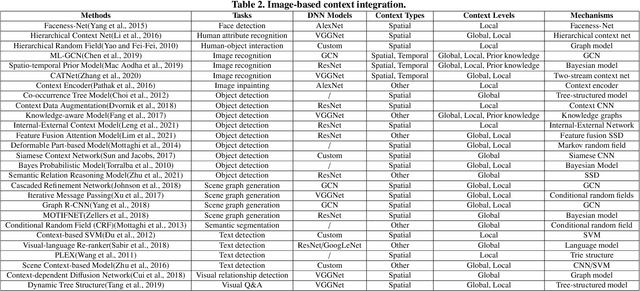
Contextual information plays an important role in many computer vision tasks, such as object detection, video action detection, image classification, etc. Recognizing a single object or action out of context could be sometimes very challenging, and context information may help improve the understanding of a scene or an event greatly. Appearance context information, e.g., colors or shapes of the background of an object can improve the recognition accuracy of the object in the scene. Semantic context (e.g. a keyboard on an empty desk vs. a keyboard next to a desktop computer ) will improve accuracy and exclude unrelated events. Context information that are not in the image itself, such as the time or location of an images captured, can also help to decide whether certain event or action should occur. Other types of context (e.g. 3D structure of a building) will also provide additional information to improve the accuracy. In this survey, different context information that has been used in computer vision tasks is reviewed. We categorize context into different types and different levels. We also review available machine learning models and image/video datasets that can employ context information. Furthermore, we compare context based integration and context-free integration in mainly two classes of tasks: image-based and video-based. Finally, this survey is concluded by a set of promising future directions in context learning and utilization.
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023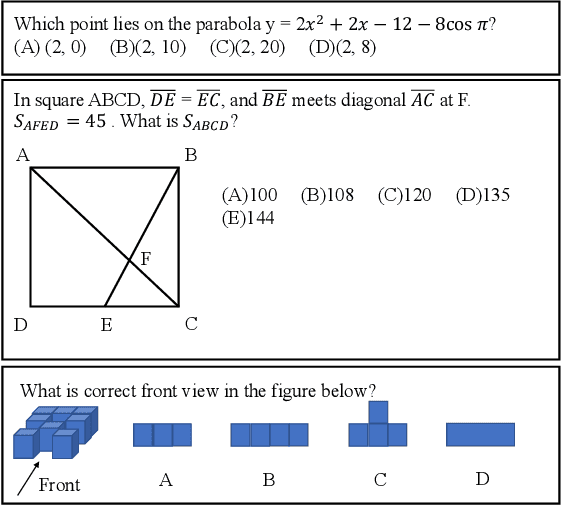

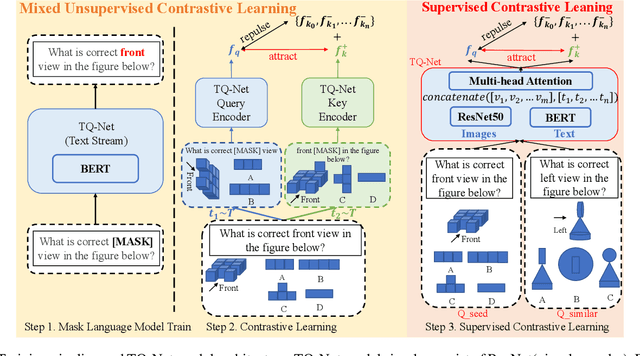
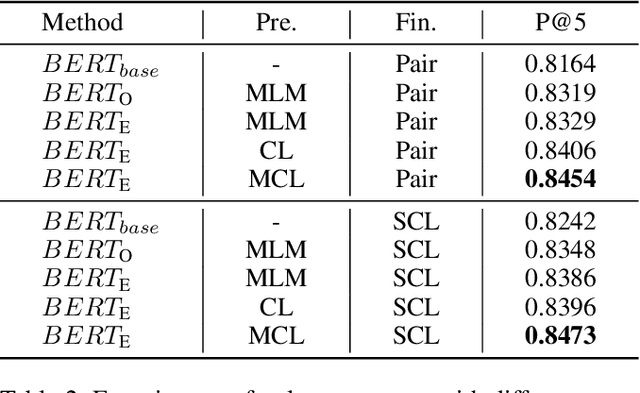
Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.
SSL^2: Self-Supervised Learning meets Semi-Supervised Learning: Multiple Sclerosis Segmentation in 7T-MRI from large-scale 3T-MRI
Mar 09, 2023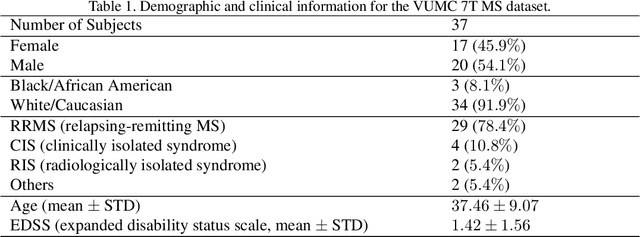
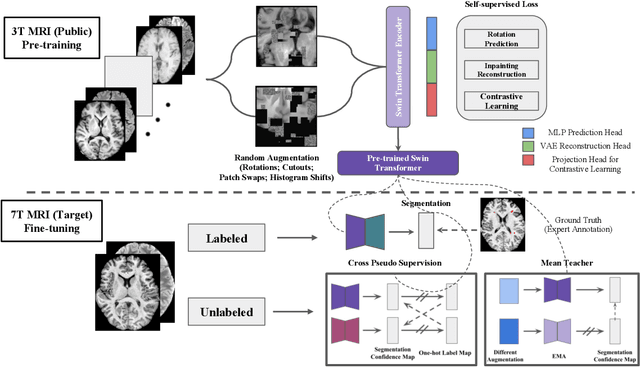
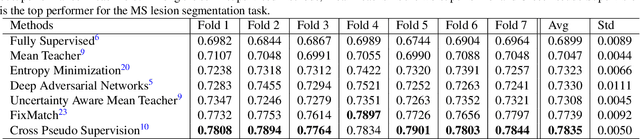
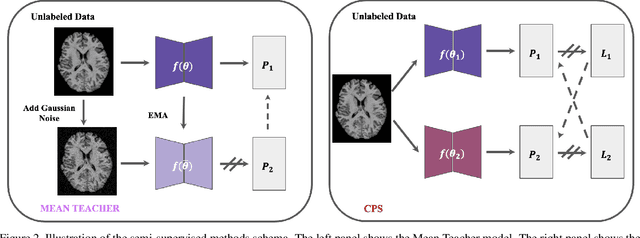
Automated segmentation of multiple sclerosis (MS) lesions from MRI scans is important to quantify disease progression. In recent years, convolutional neural networks (CNNs) have shown top performance for this task when a large amount of labeled data is available. However, the accuracy of CNNs suffers when dealing with few and/or sparsely labeled datasets. A potential solution is to leverage the information available in large public datasets in conjunction with a target dataset which only has limited labeled data. In this paper, we propose a training framework, SSL2 (self-supervised-semi-supervised), for multi-modality MS lesion segmentation with limited supervision. We adopt self-supervised learning to leverage the knowledge from large public 3T datasets to tackle the limitations of a small 7T target dataset. To leverage the information from unlabeled 7T data, we also evaluate state-of-the-art semi-supervised methods for other limited annotation settings, such as small labeled training size and sparse annotations. We use the shifted-window (Swin) transformer1 as our backbone network. The effectiveness of self-supervised and semi-supervised training strategies is evaluated in our in-house 7T MRI dataset. The results indicate that each strategy improves lesion segmentation for both limited training data size and for sparse labeling scenarios. The combined overall framework further improves the performance substantially compared to either of its components alone. Our proposed framework thus provides a promising solution for future data/label-hungry 7T MS studies.
Linked Data Science Powered by Knowledge Graphs
Mar 09, 2023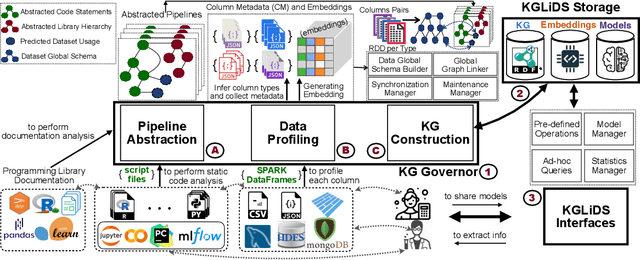
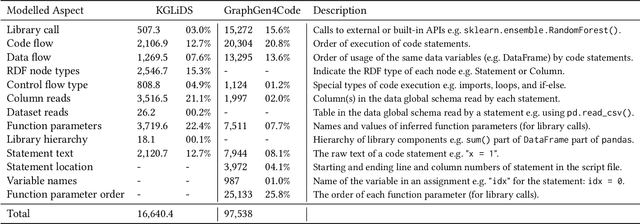
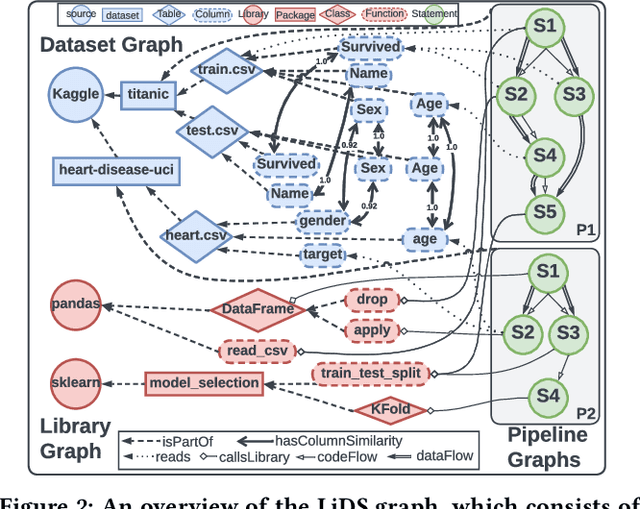
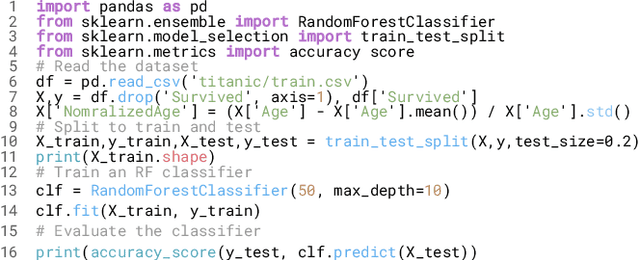
In recent years, we have witnessed a growing interest in data science not only from academia but particularly from companies investing in data science platforms to analyze large amounts of data. In this process, a myriad of data science artifacts, such as datasets and pipeline scripts, are created. Yet, there has so far been no systematic attempt to holistically exploit the collected knowledge and experiences that are implicitly contained in the specification of these pipelines, e.g., compatible datasets, cleansing steps, ML algorithms, parameters, etc. Instead, data scientists still spend a considerable amount of their time trying to recover relevant information and experiences from colleagues, trial and error, lengthy exploration, etc. In this paper, we, therefore, propose a scalable system (KGLiDS) that employs machine learning to extract the semantics of data science pipelines and captures them in a knowledge graph, which can then be exploited to assist data scientists in various ways. This abstraction is the key to enabling Linked Data Science since it allows us to share the essence of pipelines between platforms, companies, and institutions without revealing critical internal information and instead focusing on the semantics of what is being processed and how. Our comprehensive evaluation uses thousands of datasets and more than thirteen thousand pipeline scripts extracted from data discovery benchmarks and the Kaggle portal and shows that KGLiDS significantly outperforms state-of-the-art systems on related tasks, such as dataset recommendation and pipeline classification.
Dual-Attention Model for Aspect-Level Sentiment Classification
Mar 14, 2023
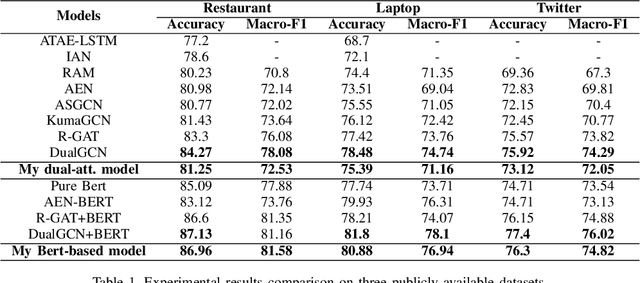
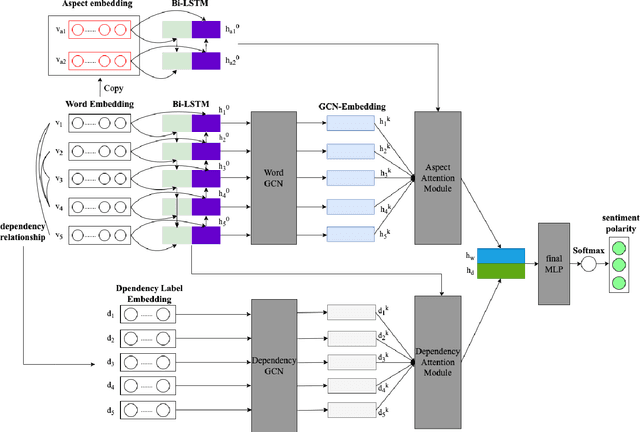

I propose a novel dual-attention model(DAM) for aspect-level sentiment classification. Many methods have been proposed, such as support vector machines for artificial design features, long short-term memory networks based on attention mechanisms, and graph neural networks based on dependency parsing. While these methods all have decent performance, I think they all miss one important piece of syntactic information: dependency labels. Based on this idea, this paper proposes a model using dependency labels for the attention mechanism to do this task. We evaluate the proposed approach on three datasets: laptop and restaurant are from SemEval 2014, and the last one is a twitter dataset. Experimental results show that the dual attention model has good performance on all three datasets.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022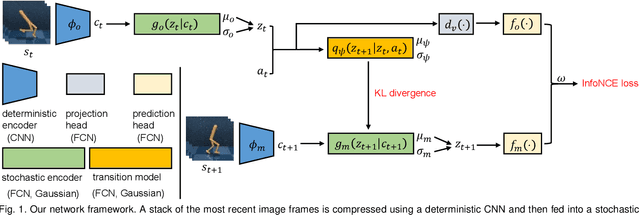
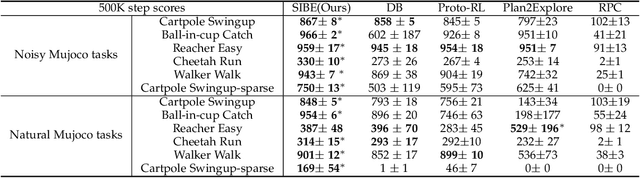
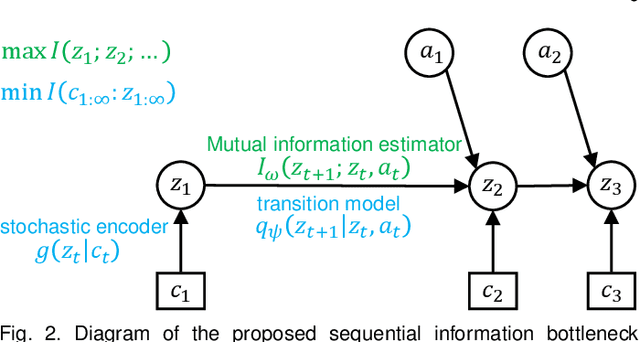

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
ABC: Attention with Bilinear Correlation for Infrared Small Target Detection
Mar 18, 2023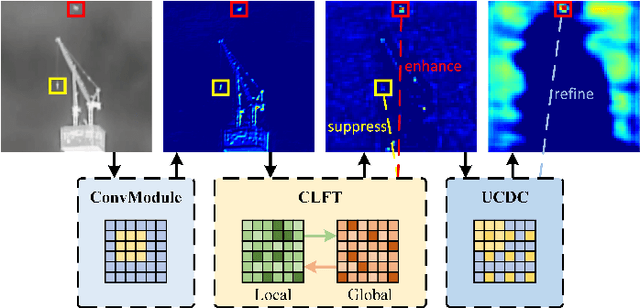
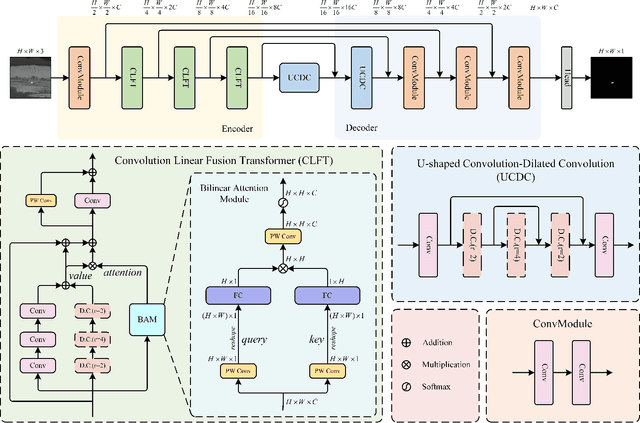
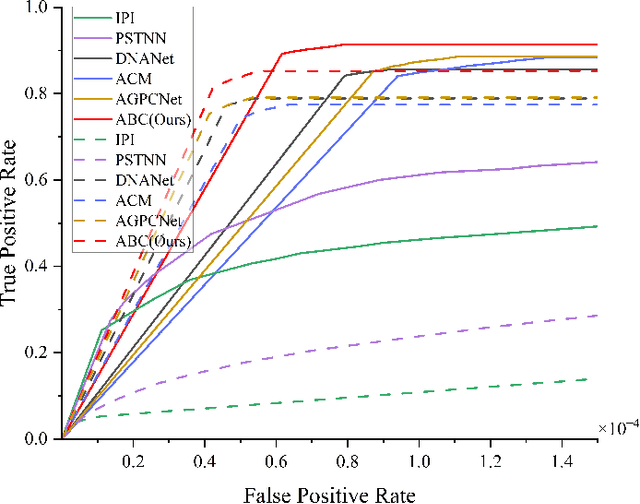
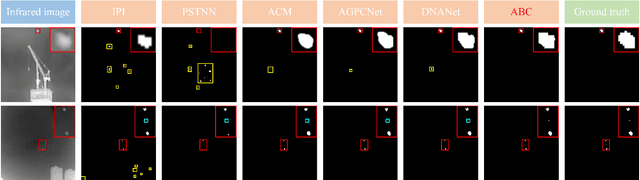
Infrared small target detection (ISTD) has a wide range of applications in early warning, rescue, and guidance. However, CNN based deep learning methods are not effective at segmenting infrared small target (IRST) that it lack of clear contour and texture features, and transformer based methods also struggle to achieve significant results due to the absence of convolution induction bias. To address these issues, we propose a new model called attention with bilinear correlation (ABC), which is based on the transformer architecture and includes a convolution linear fusion transformer (CLFT) module with a novel attention mechanism for feature extraction and fusion, which effectively enhances target features and suppresses noise. Additionally, our model includes a u-shaped convolution-dilated convolution (UCDC) module located deeper layers of the network, which takes advantage of the smaller resolution of deeper features to obtain finer semantic information. Experimental results on public datasets demonstrate that our approach achieves state-of-the-art performance. Code is available at https://github.com/PANPEIWEN/ABC
Stop Words for Processing Software Engineering Documents: Do they Matter?
Mar 18, 2023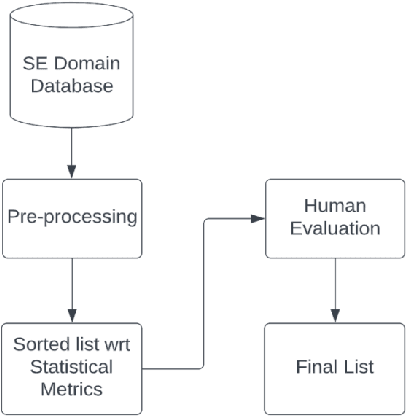
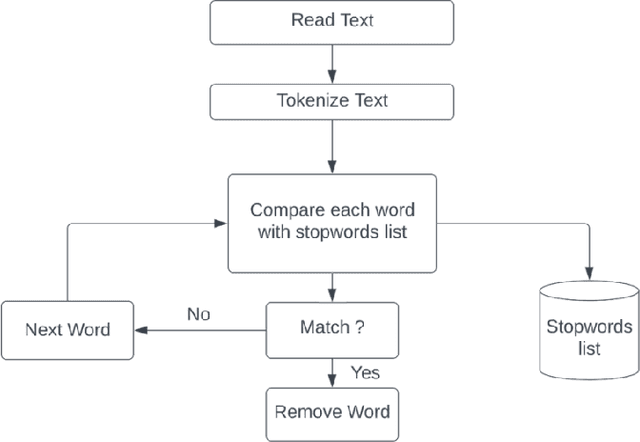

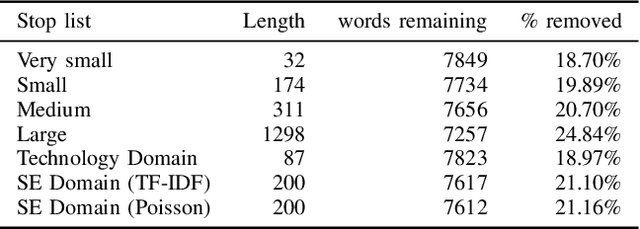
Stop words, which are considered non-predictive, are often eliminated in natural language processing tasks. However, the definition of uninformative vocabulary is vague, so most algorithms use general knowledge-based stop lists to remove stop words. There is an ongoing debate among academics about the usefulness of stop word elimination, especially in domain-specific settings. In this work, we investigate the usefulness of stop word removal in a software engineering context. To do this, we replicate and experiment with three software engineering research tools from related work. Additionally, we construct a corpus of software engineering domain-related text from 10,000 Stack Overflow questions and identify 200 domain-specific stop words using traditional information-theoretic methods. Our results show that the use of domain-specific stop words significantly improved the performance of research tools compared to the use of a general stop list and that 17 out of 19 evaluation measures showed better performance.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023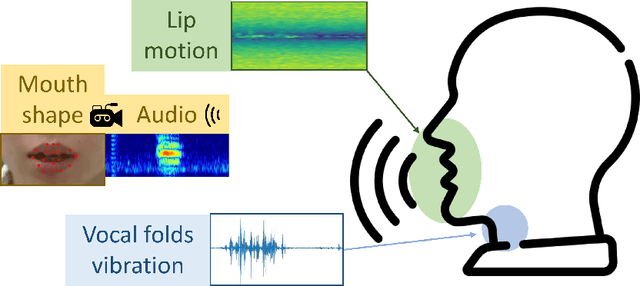

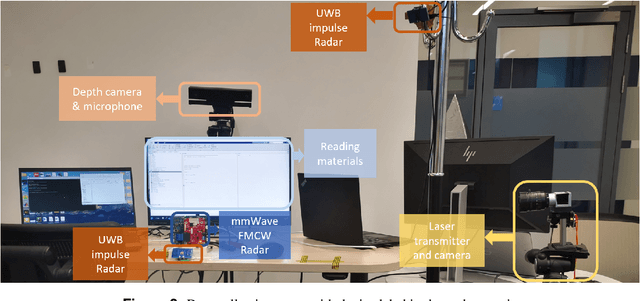
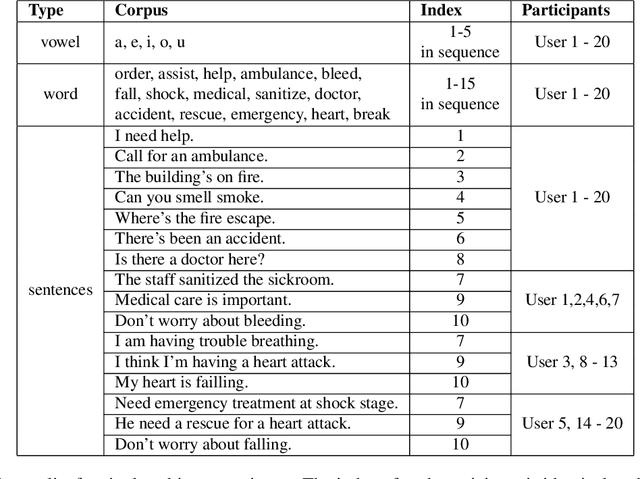
Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.