 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mobile Edge Adversarial Detection for Digital Twinning to the Metaverse with Deep Reinforcement Learning
Mar 18, 2023
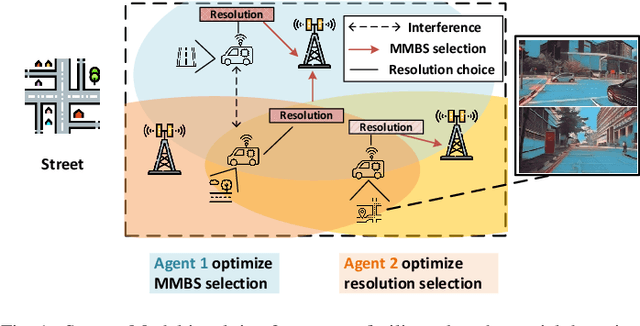

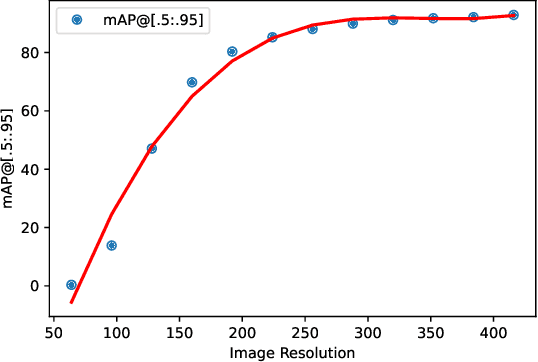
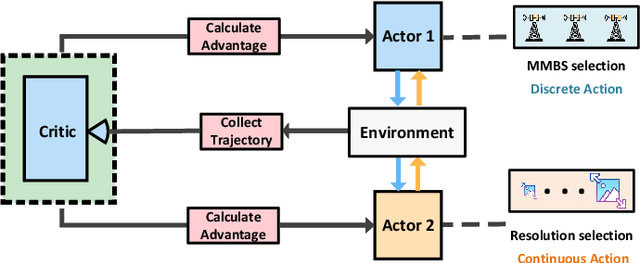
Real-time Digital Twinning of physical world scenes onto the Metaverse is necessary for a myriad of applications such as augmented-reality (AR) assisted driving. In AR assisted driving, physical environment scenes are first captured by Internet of Vehicles (IoVs) and are uploaded to the Metaverse. A central Metaverse Map Service Provider (MMSP) will aggregate information from all IoVs to develop a central Metaverse Map. Information from the Metaverse Map can then be downloaded into individual IoVs on demand and be delivered as AR scenes to the driver. However, the growing interest in developing AR assisted driving applications which relies on digital twinning invites adversaries. These adversaries may place physical adversarial patches on physical world objects such as cars, signboards, or on roads, seeking to contort the virtual world digital twin. Hence, there is a need to detect these physical world adversarial patches. Nevertheless, as real-time, accurate detection of adversarial patches is compute-intensive, these physical world scenes have to be offloaded to the Metaverse Map Base Stations (MMBS) for computation. Hence in our work, we considered an environment with moving Internet of Vehicles (IoV), uploading real-time physical world scenes to the MMBSs. We formulated a realistic joint variable optimization problem where the MMSPs' objective is to maximize adversarial patch detection mean average precision (mAP), while minimizing the computed AR scene up-link transmission latency and IoVs' up-link transmission idle count, through optimizing the IoV-MMBS allocation and IoV up-link scene resolution selection. We proposed a Heterogeneous Action Proximal Policy Optimization (HAPPO) (discrete-continuous) algorithm to tackle the proposed problem. Extensive experiments shows HAPPO outperforms baseline models when compared against key metrics.
Cross-Tool and Cross-Behavior Perceptual Knowledge Transfer for Grounded Object Recognition
Mar 07, 2023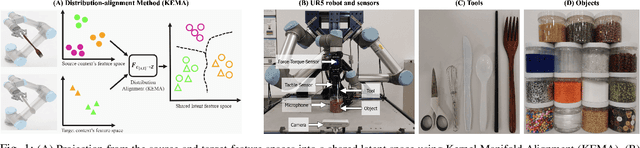
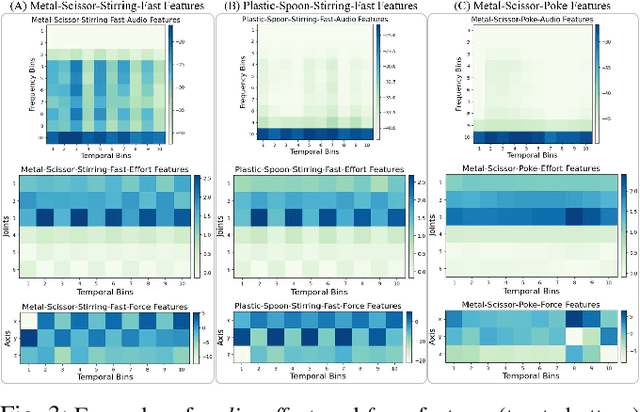
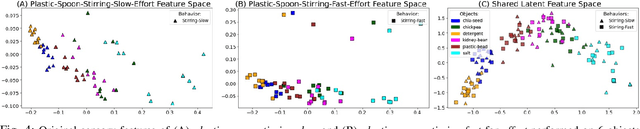
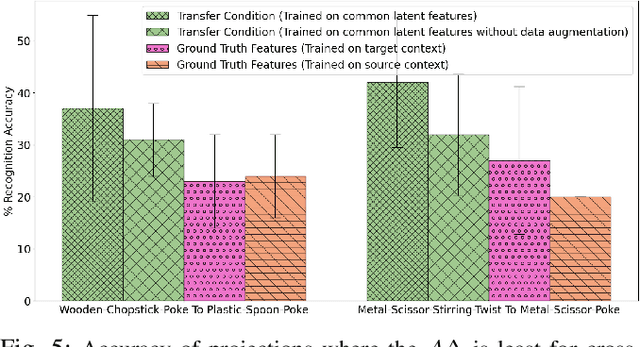
Humans learn about objects via interaction and using multiple perceptions, such as vision, sound, and touch. While vision can provide information about an object's appearance, non-visual sensors, such as audio and haptics, can provide information about its intrinsic properties, such as weight, temperature, hardness, and the object's sound. Using tools to interact with objects can reveal additional object properties that are otherwise hidden (e.g., knives and spoons can be used to examine the properties of food, including its texture and consistency). Robots can use tools to interact with objects and gather information about their implicit properties via non-visual sensors. However, a robot's model for recognizing objects using a tool-mediated behavior does not generalize to a new tool or behavior due to differing observed data distributions. To address this challenge, we propose a framework to enable robots to transfer implicit knowledge about granular objects across different tools and behaviors. The proposed approach learns a shared latent space from multiple robots' contexts produced by respective sensory data while interacting with objects using tools. We collected a dataset using a UR5 robot that performed 5,400 interactions using 6 tools and 6 behaviors on 15 granular objects and tested our method on cross-tool and cross-behavioral transfer tasks. Our results show the less experienced target robot can benefit from the experience gained from the source robot and perform recognition on a set of novel objects. We have released the code, datasets, and additional results: https://github.com/gtatiya/Tool-Knowledge-Transfer.
Improving Data Transfer Efficiency for AIs in the DareFightingICE using gRPC
Mar 11, 2023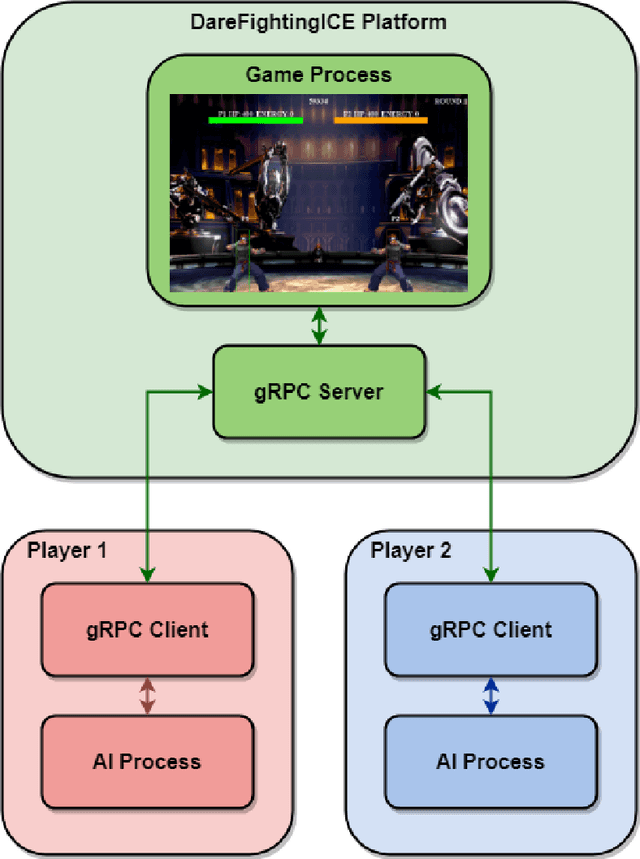
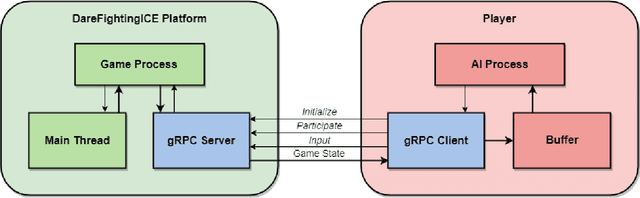
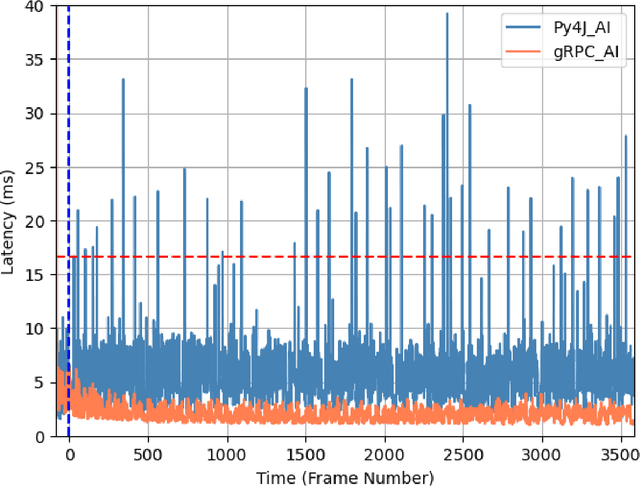
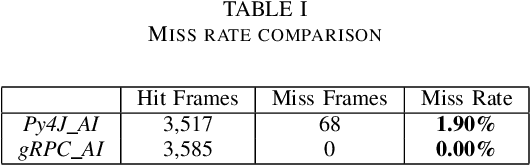
This paper presents a new communication interface for the DareFightingICE platform, a Java-based fighting game focused on implementing AI for controlling a non-player character. The interface uses an open-source remote procedure call, gRPC to improve the efficiency of data transfer between the game and the AI, reducing the time spent on receiving information from the game server. This is important because the main challenge of implementing AI in a fighting game is the need for the AI to select an action to perform within a short response time. The DareFightingICE platform has been integrated with Py4J, allowing developers to create AIs using Python. However, Py4J is less efficient at handling large amounts of data, resulting in excessive latency. In contrast, gRPC is well-suited for transmitting large amounts of data. To evaluate the effectiveness of the new communication interface, we conducted an experiment comparing the latency of gRPC and Py4J, using a rule-based AI that sends a kick command regardless of the information received from the game server. The experiment results showed not only a 65\% reduction in latency but also improved stability and eliminated missed frames compared to the current interface.
MetaAID 2.0: An Extensible Framework for Developing Metaverse Applications via Human-controllable Pre-trained Models
Feb 25, 2023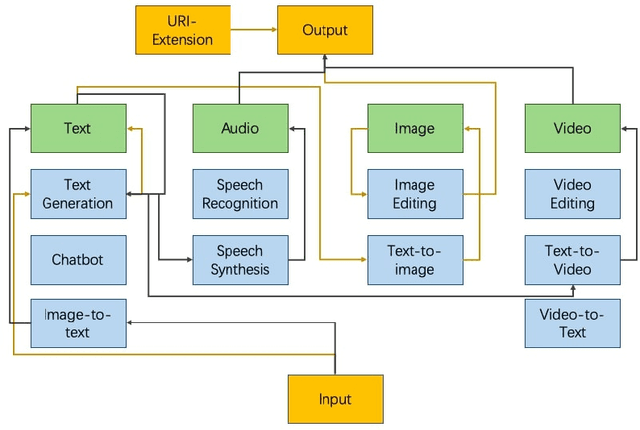



Pre-trained models (PM) have achieved promising results in content generation. However, the space for human creativity and imagination is endless, and it is still unclear whether the existing models can meet the needs. Model-generated content faces uncontrollable responsibility and potential unethical problems. This paper presents the MetaAID 2.0 framework, dedicated to human-controllable PM information flow. Through the PM information flow, humans can autonomously control their creativity. Through the Universal Resource Identifier extension (URI-extension), the responsibility of the model outputs can be controlled. Our framework includes modules for handling multimodal data and supporting transformation and generation. The URI-extension consists of URI, detailed description, and URI embeddings, and supports fuzzy retrieval of model outputs. Based on this framework, we conduct experiments on PM information flow and URI embeddings, and the results demonstrate the good performance of our system.
Speaker Recognition in Realistic Scenario Using Multimodal Data
Feb 25, 2023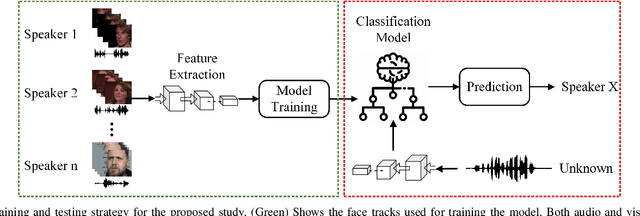
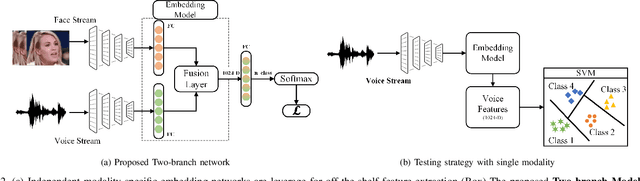
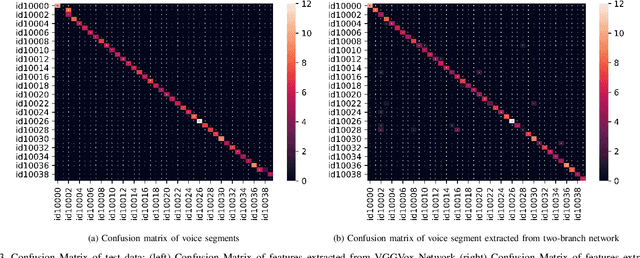
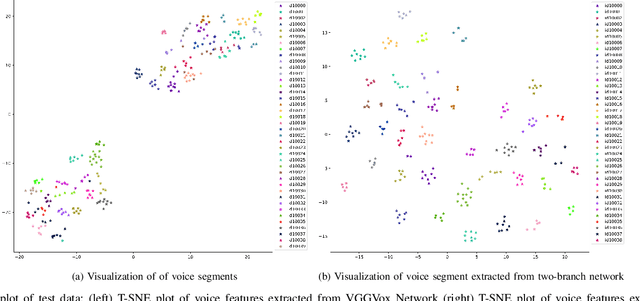
In recent years, an association is established between faces and voices of celebrities leveraging large scale audio-visual information from YouTube. The availability of large scale audio-visual datasets is instrumental in developing speaker recognition methods based on standard Convolutional Neural Networks. Thus, the aim of this paper is to leverage large scale audio-visual information to improve speaker recognition task. To achieve this task, we proposed a two-branch network to learn joint representations of faces and voices in a multimodal system. Afterwards, features are extracted from the two-branch network to train a classifier for speaker recognition. We evaluated our proposed framework on a large scale audio-visual dataset named VoxCeleb$1$. Our results show that addition of facial information improved the performance of speaker recognition. Moreover, our results indicate that there is an overlap between face and voice.
Asymptotically Optimal Generalization Error Bounds for Noisy, Iterative Algorithms
Feb 28, 2023We adopt an information-theoretic framework to analyze the generalization behavior of the class of iterative, noisy learning algorithms. This class is particularly suitable for study under information-theoretic metrics as the algorithms are inherently randomized, and it includes commonly used algorithms such as Stochastic Gradient Langevin Dynamics (SGLD). Herein, we use the maximal leakage (equivalently, the Sibson mutual information of order infinity) metric, as it is simple to analyze, and it implies both bounds on the probability of having a large generalization error and on its expected value. We show that, if the update function (e.g., gradient) is bounded in $L_2$-norm, then adding isotropic Gaussian noise leads to optimal generalization bounds: indeed, the input and output of the learning algorithm in this case are asymptotically statistically independent. Furthermore, we demonstrate how the assumptions on the update function affect the optimal (in the sense of minimizing the induced maximal leakage) choice of the noise. Finally, we compute explicit tight upper bounds on the induced maximal leakage for several scenarios of interest.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 26, 2023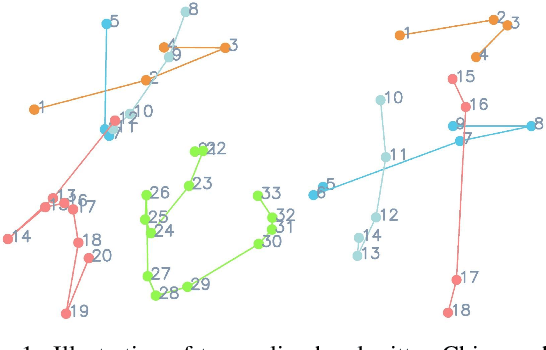
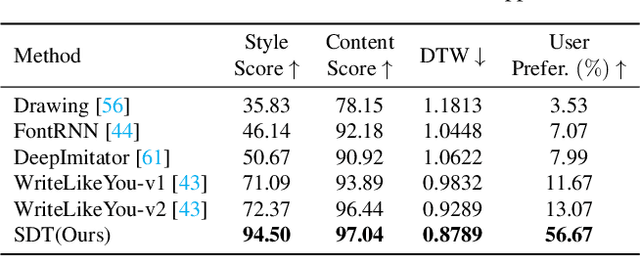

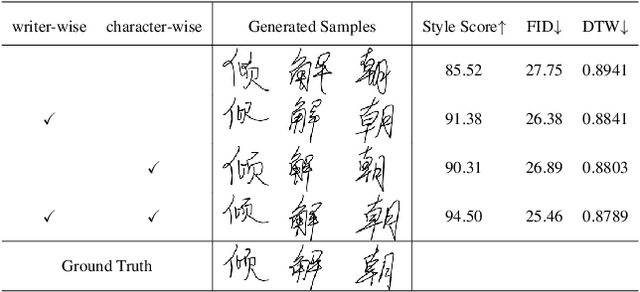
Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Multi-Frame Self-Supervised Depth Estimation with Multi-Scale Feature Fusion in Dynamic Scenes
Mar 26, 2023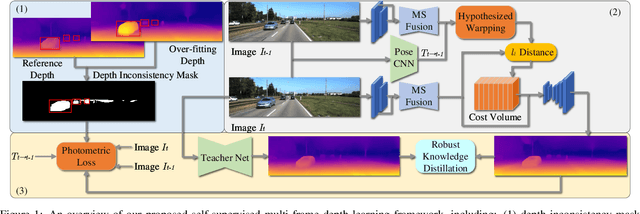
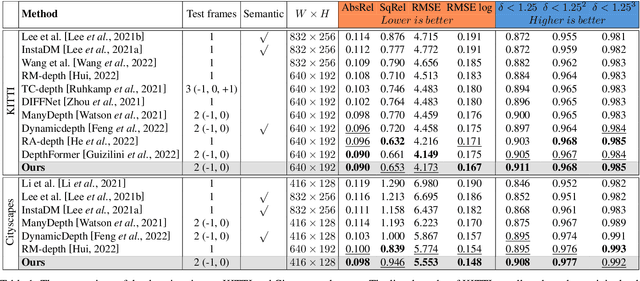
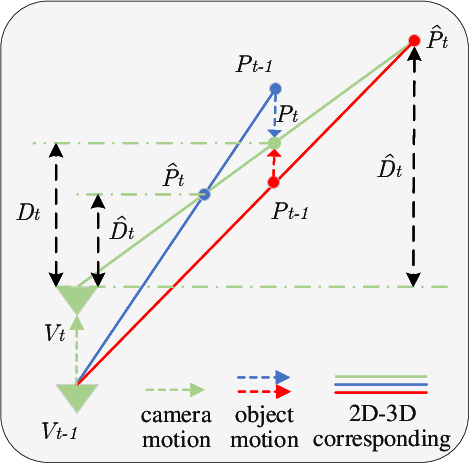
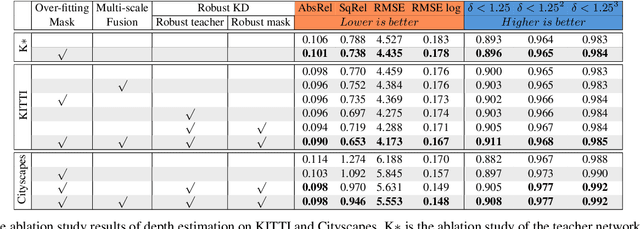
Multi-frame methods improve monocular depth estimation over single-frame approaches by aggregating spatial-temporal information via feature matching. However, the spatial-temporal feature leads to accuracy degradation in dynamic scenes. To enhance the performance, recent methods tend to propose complex architectures for feature matching and dynamic scenes. In this paper, we show that a simple learning framework, together with designed feature augmentation, leads to superior performance. (1) A novel dynamic objects detecting method with geometry explainability is proposed. The detected dynamic objects are excluded during training, which guarantees the static environment assumption and relieves the accuracy degradation problem of the multi-frame depth estimation. (2) Multi-scale feature fusion is proposed for feature matching in the multi-frame depth network, which improves feature matching, especially between frames with large camera motion. (3) The robust knowledge distillation with a robust teacher network and reliability guarantee is proposed, which improves the multi-frame depth estimation without computation complexity increase during the test. The experiments show that our proposed methods achieve great performance improvement on the multi-frame depth estimation.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023
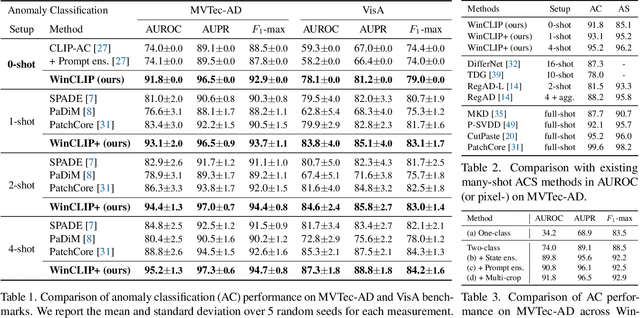

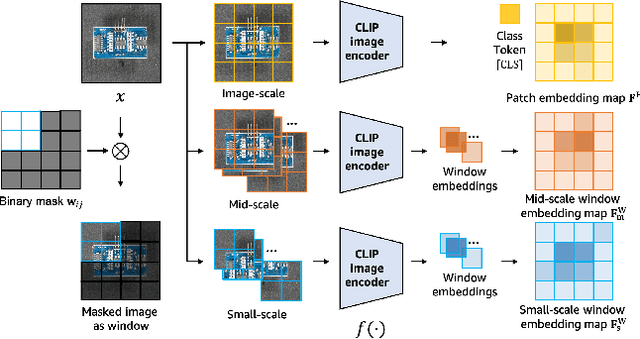
Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
Sector Patch Embedding: An Embedding Module Conforming to The Distortion Pattern of Fisheye Image
Mar 26, 2023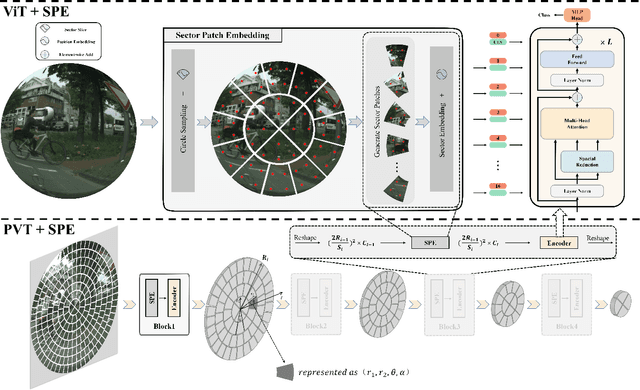
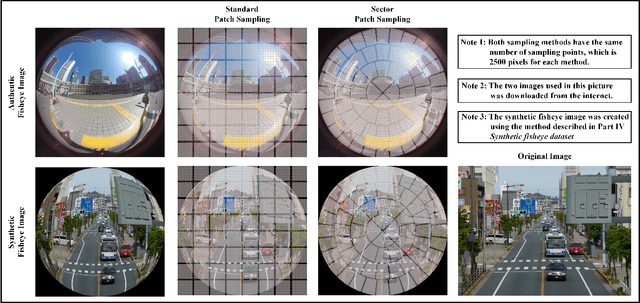
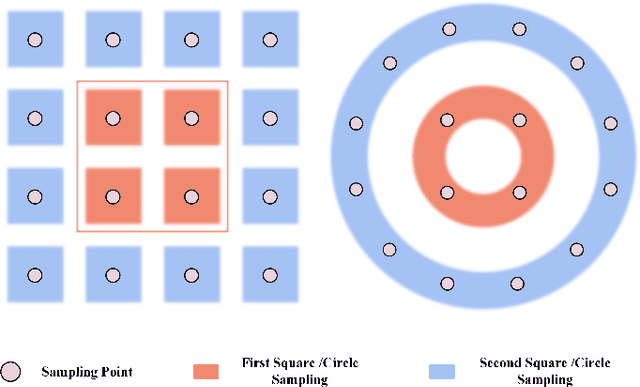
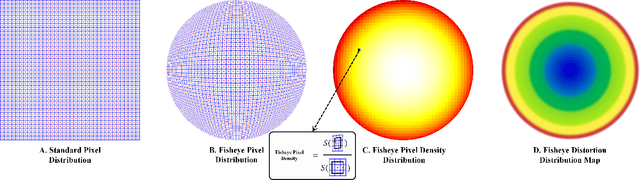
Fisheye cameras suffer from image distortion while having a large field of view(LFOV). And this fact leads to poor performance on some fisheye vision tasks. One of the solutions is to optimize the current vision algorithm for fisheye images. However, most of the CNN-based methods and the Transformer-based methods lack the capability of leveraging distortion information efficiently. In this work, we propose a novel patch embedding method called Sector Patch Embedding(SPE), conforming to the distortion pattern of the fisheye image. Furthermore, we put forward a synthetic fisheye dataset based on the ImageNet-1K and explore the performance of several Transformer models on the dataset. The classification top-1 accuracy of ViT and PVT is improved by 0.75% and 2.8% with SPE respectively. The experiments show that the proposed sector patch embedding method can better perceive distortion and extract features on the fisheye images. Our method can be easily adopted to other Transformer-based models. Source code is at https://github.com/IN2-ViAUn/Sector-Patch-Embedding.