 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalization in Visual Reinforcement Learning with the Reward Sequence Distribution
Feb 19, 2023
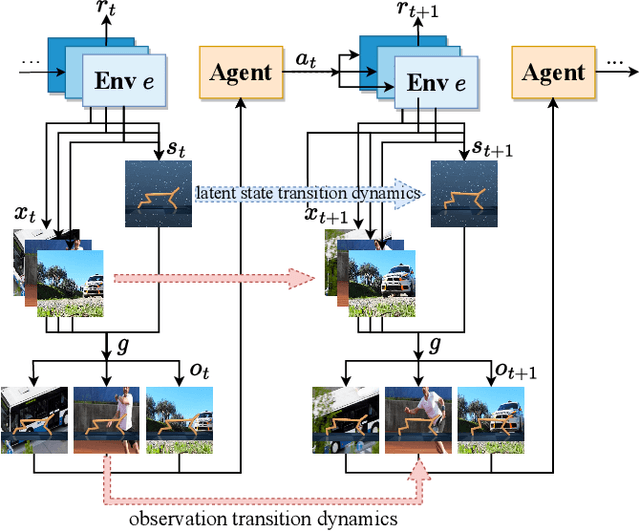
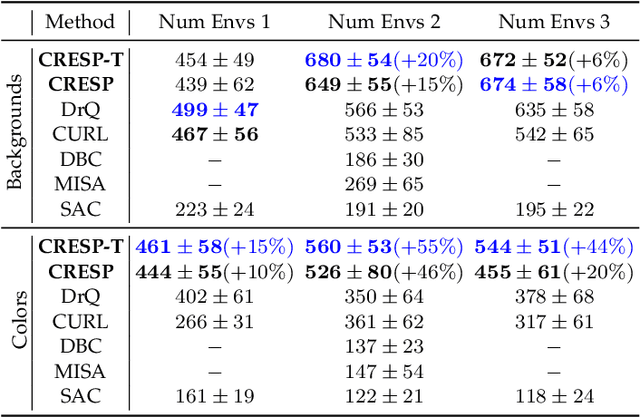
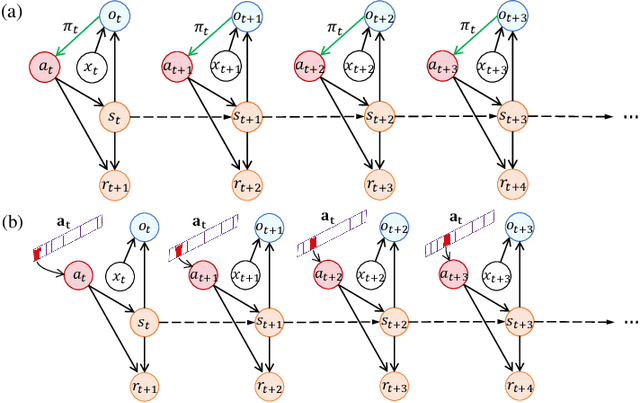
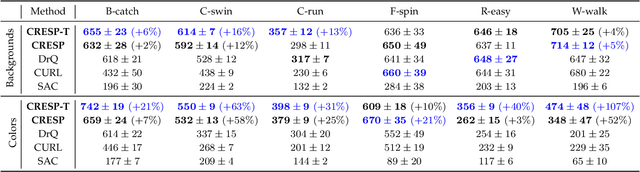
Generalization in partially observed markov decision processes (POMDPs) is critical for successful applications of visual reinforcement learning (VRL) in real scenarios. A widely used idea is to learn task-relevant representations that encode task-relevant information of common features in POMDPs, i.e., rewards and transition dynamics. As transition dynamics in the latent state space -- which are task-relevant and invariant to visual distractions -- are unknown to the agents, existing methods alternatively use transition dynamics in the observation space to extract task-relevant information in transition dynamics. However, such transition dynamics in the observation space involve task-irrelevant visual distractions, degrading the generalization performance of VRL methods. To tackle this problem, we propose the reward sequence distribution conditioned on the starting observation and the predefined subsequent action sequence (RSD-OA). The appealing features of RSD-OA include that: (1) RSD-OA is invariant to visual distractions, as it is conditioned on the predefined subsequent action sequence without task-irrelevant information from transition dynamics, and (2) the reward sequence captures long-term task-relevant information in both rewards and transition dynamics. Experiments demonstrate that our representation learning approach based on RSD-OA significantly improves the generalization performance on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with visual distractions.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022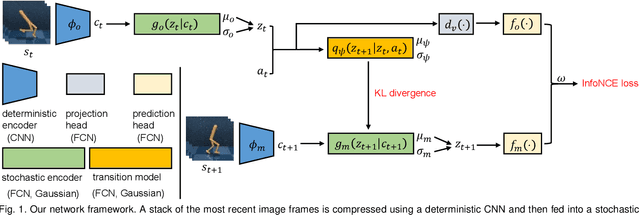
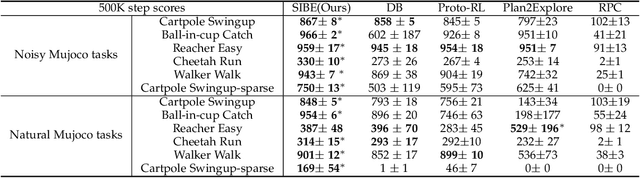
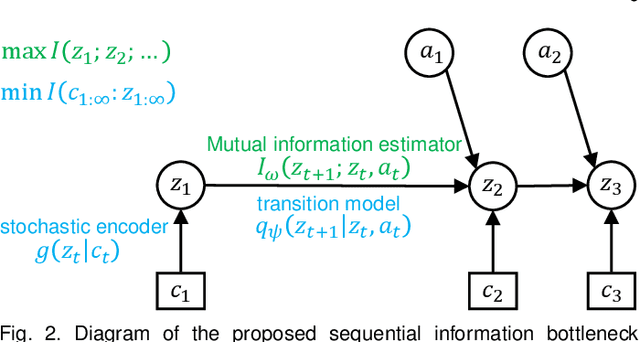

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Mar 20, 2023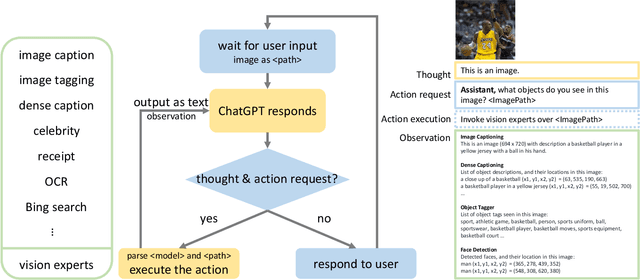



We propose MM-REACT, a system paradigm that integrates ChatGPT with a pool of vision experts to achieve multimodal reasoning and action. In this paper, we define and explore a comprehensive list of advanced vision tasks that are intriguing to solve, but may exceed the capabilities of existing vision and vision-language models. To achieve such advanced visual intelligence, MM-REACT introduces a textual prompt design that can represent text descriptions, textualized spatial coordinates, and aligned file names for dense visual signals such as images and videos. MM-REACT's prompt design allows language models to accept, associate, and process multimodal information, thereby facilitating the synergetic combination of ChatGPT and various vision experts. Zero-shot experiments demonstrate MM-REACT's effectiveness in addressing the specified capabilities of interests and its wide application in different scenarios that require advanced visual understanding. Furthermore, we discuss and compare MM-REACT's system paradigm with an alternative approach that extends language models for multimodal scenarios through joint finetuning. Code, demo, video, and visualization are available at https://multimodal-react.github.io/
Long-Term Indoor Localization with Metric-Semantic Mapping using a Floor Plan Prior
Mar 20, 2023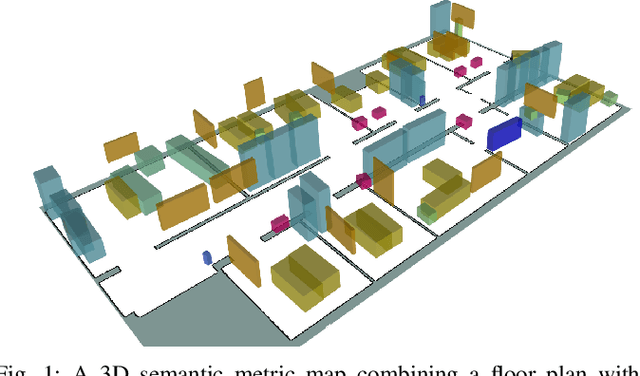
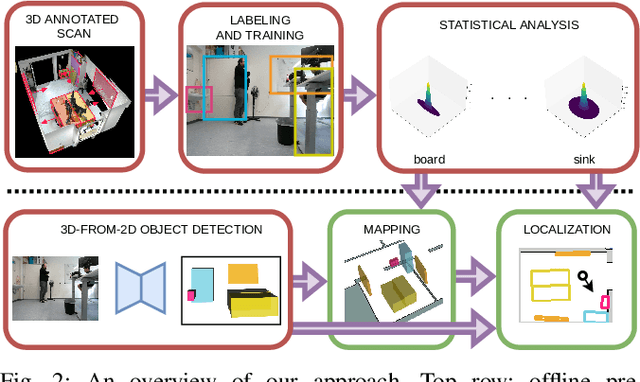

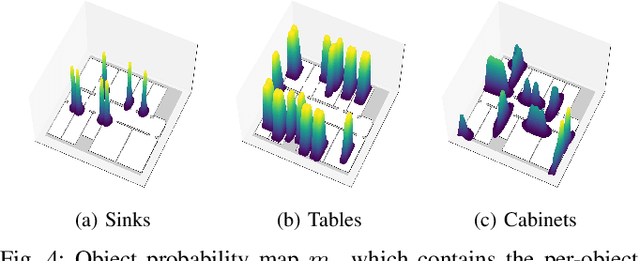
Object-based maps are relevant for scene understanding since they integrate geometric and semantic information of the environment, allowing autonomous robots to robustly localize and interact with on objects. In this paper, we address the task of constructing a metric-semantic map for the purpose of long-term object-based localization. We exploit 3D object detections from monocular RGB frames for both, the object-based map construction, and for globally localizing in the constructed map. To tailor the approach to a target environment, we propose an efficient way of generating 3D annotations to finetune the 3D object detection model. We evaluate our map construction in an office building, and test our long-term localization approach on challenging sequences recorded in the same environment over nine months. The experiments suggest that our approach is suitable for constructing metric-semantic maps, and that our localization approach is robust to long-term changes. Both, the mapping algorithm and the localization pipeline can run online on an onboard computer. We will release an open-source C++/ROS implementation of our approach.
Urban Regional Function Guided Traffic Flow Prediction
Mar 20, 2023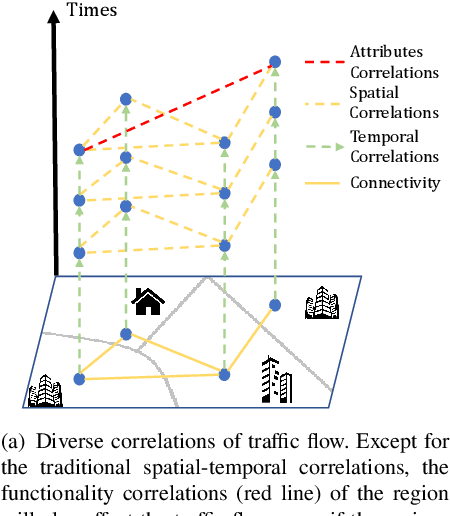
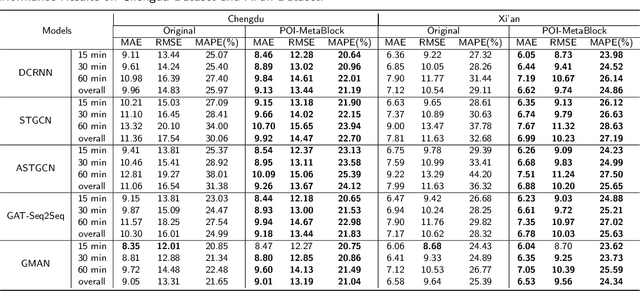
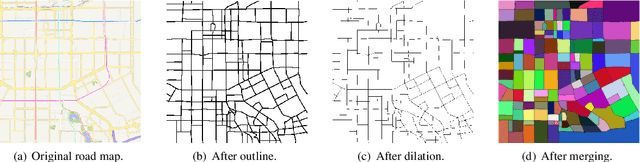

The prediction of traffic flow is a challenging yet crucial problem in spatial-temporal analysis, which has recently gained increasing interest. In addition to spatial-temporal correlations, the functionality of urban areas also plays a crucial role in traffic flow prediction. However, the exploration of regional functional attributes mainly focuses on adding additional topological structures, ignoring the influence of functional attributes on regional traffic patterns. Different from the existing works, we propose a novel module named POI-MetaBlock, which utilizes the functionality of each region (represented by Point of Interest distribution) as metadata to further mine different traffic characteristics in areas with different functions. Specifically, the proposed POI-MetaBlock employs a self-attention architecture and incorporates POI and time information to generate dynamic attention parameters for each region, which enables the model to fit different traffic patterns of various areas at different times. Furthermore, our lightweight POI-MetaBlock can be easily integrated into conventional traffic flow prediction models. Extensive experiments demonstrate that our module significantly improves the performance of traffic flow prediction and outperforms state-of-the-art methods that use metadata.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminative Analysis
Mar 20, 2023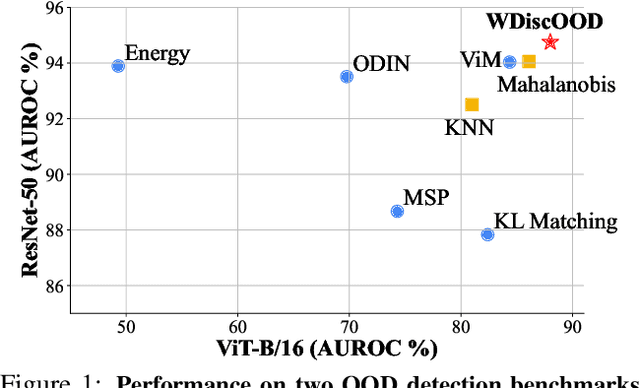
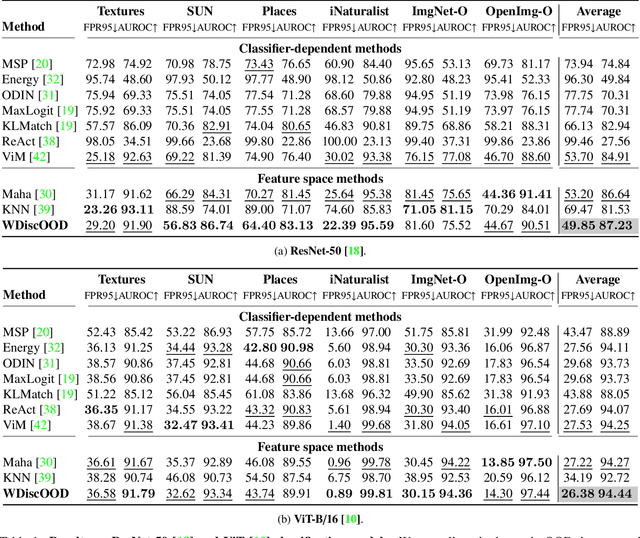
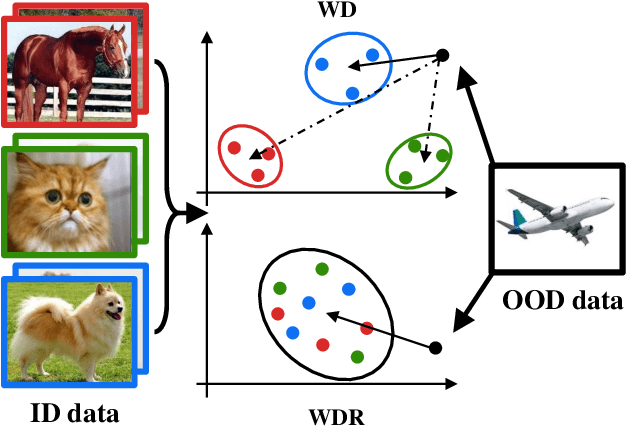

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminative Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
Self-Supervised Learning for Multimodal Non-Rigid 3D Shape Matching
Mar 20, 2023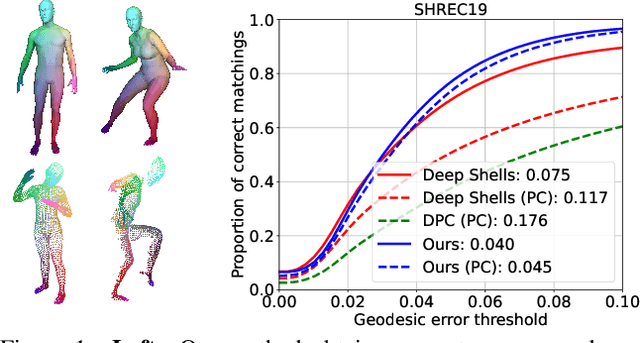

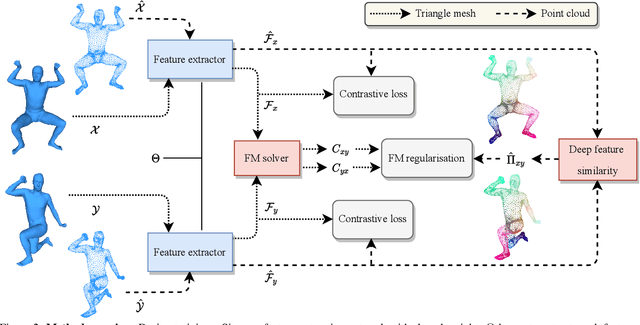
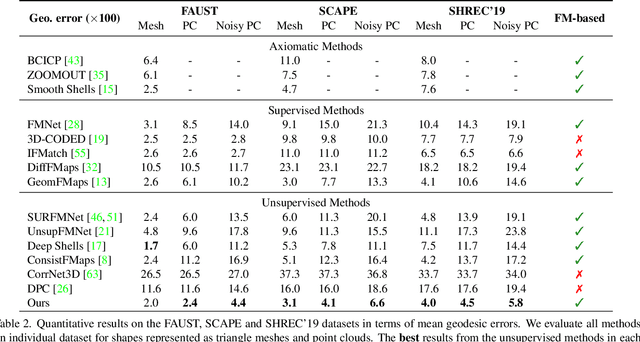
The matching of 3D shapes has been extensively studied for shapes represented as surface meshes, as well as for shapes represented as point clouds. While point clouds are a common representation of raw real-world 3D data (e.g. from laser scanners), meshes encode rich and expressive topological information, but their creation typically requires some form of (often manual) curation. In turn, methods that purely rely on point clouds are unable to meet the matching quality of mesh-based methods that utilise the additional topological structure. In this work we close this gap by introducing a self-supervised multimodal learning strategy that combines mesh-based functional map regularisation with a contrastive loss that couples mesh and point cloud data. Our shape matching approach allows to obtain intramodal correspondences for triangle meshes, complete point clouds, and partially observed point clouds, as well as correspondences across these data modalities. We demonstrate that our method achieves state-of-the-art results on several challenging benchmark datasets even in comparison to recent supervised methods, and that our method reaches previously unseen cross-dataset generalisation ability.
Make Landscape Flatter in Differentially Private Federated Learning
Mar 20, 2023
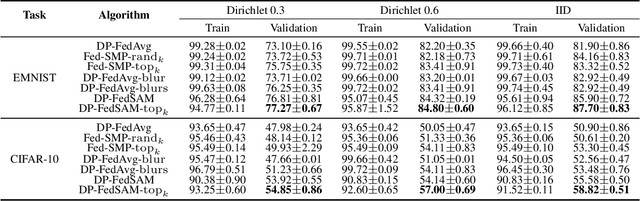
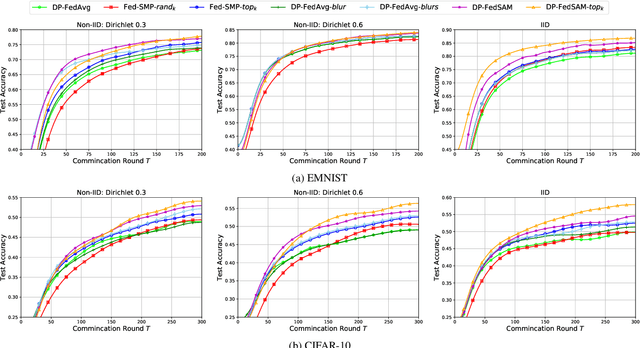
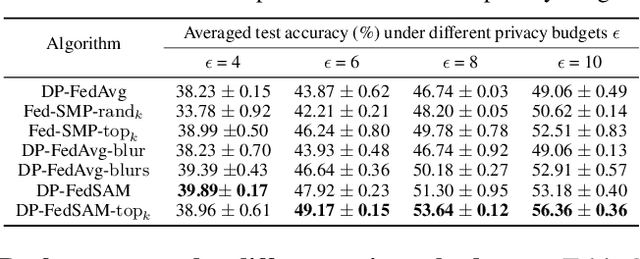
To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharper loss landscape and have poorer weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with better stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. From the theoretical perspective, we analyze in detail how DP-FedSAM mitigates the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP and present the sensitivity analysis of local updates. At last, we empirically confirm that our algorithm achieves state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.
Deep Learning-Based Detection of Motion-Affected k-Space Lines for T2*-Weighted MRI
Mar 20, 2023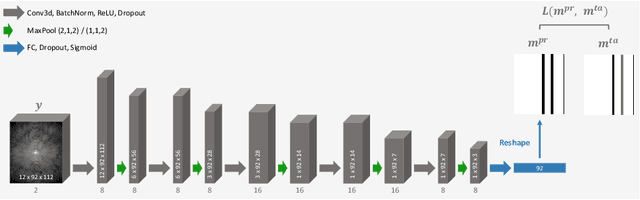
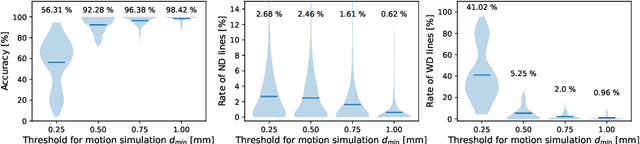
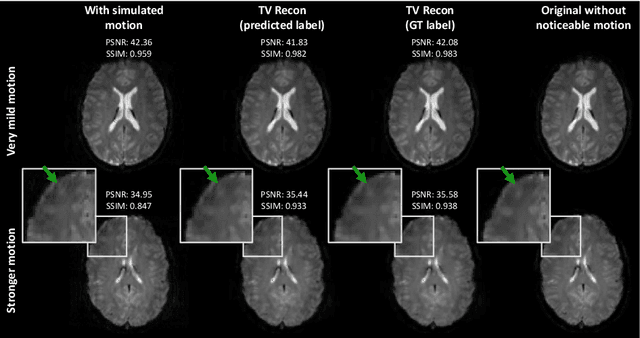
T2*-weighted gradient echo MR imaging is strongly impacted by subject head motion due to motion-related changes in B0 inhomogeneities. Within the oxygenation-sensitive mqBOLD protocol, even mild motion during the acquisition of the T2*-weighted data propagates into errors in derived quantitative parameter maps. In order to correct these images without the need of repeated measurements, we propose to learn a classification of motion-affected k-space lines. To test this, we perform realistic motion simulations including motion-induced field inhomogeneity changes for supervised training. To detect the presence of motion in each phase encoding line, we train a convolutional neural network, leveraging the multi-echo information of the T2*-weighted images. The proposed network accurately detects motion-affected k-space lines for simulated displacements of $\geq$ 0.5mm (accuracy on test set: 92.5%). Finally, we show example reconstructions where we include these classification labels as weights in the data consistency term of an iterative reconstruction procedure, opening up exciting opportunities of k-space line detection in combination with more powerful reconstruction methods.
Six-degree-of-freedom Localization Under Multiple Permanent Magnets Actuation
Mar 20, 2023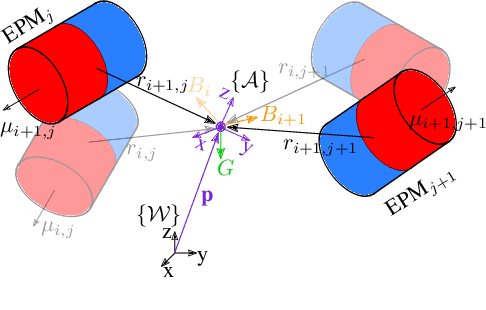
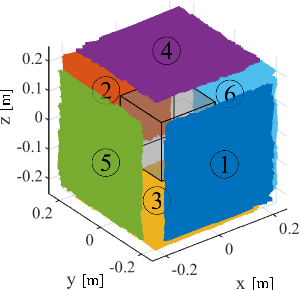
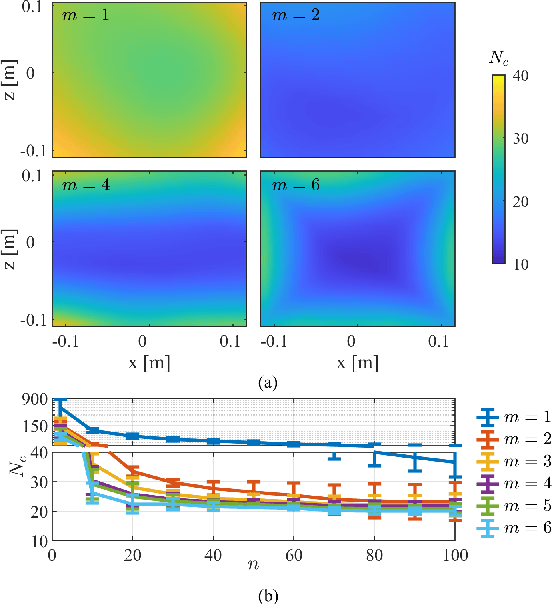
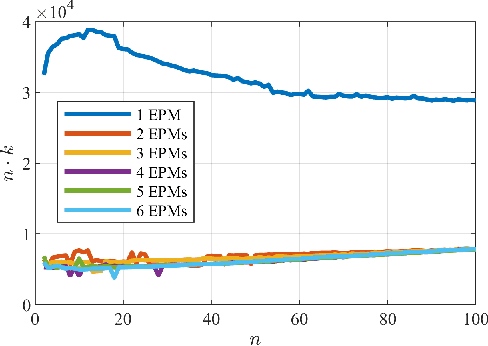
Localization of magnetically actuated medical robots is essential for accurate actuation, closed loop control and delivery of functionality. Despite extensive progress in the use of magnetic field and inertial measurements for pose estimation, these have been either under single external permanent magnet actuation or coil systems. With the advent of new magnetic actuation systems comprised of multiple external permanent magnets for increased control and manipulability, new localization techniques are necessary to account for and leverage the additional magnetic field sources. In this letter, we introduce a novel magnetic localization technique in the Special Euclidean Group SE(3) for multiple external permanent magnetic field actuation and control systems. The method relies on a milli-meter scale three-dimensional accelerometer and a three-dimensional magnetic field sensor and is able to estimate the full 6 degree-of-freedom pose without any prior pose information. We demonstrated the localization system with two external permanent magnets and achieved localization errors of 8.5 ? 2.4 mm in position norm and 3.7 ? 3.6? in orientation, across a cubic workspace with 20 cm length.