 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepVecFont-v2: Exploiting Transformers to Synthesize Vector Fonts with Higher Quality
Mar 25, 2023
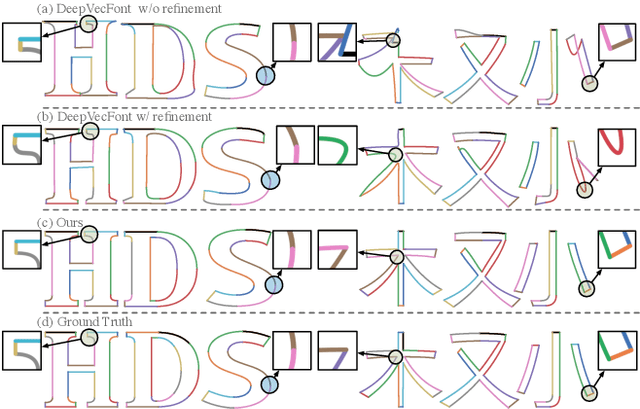

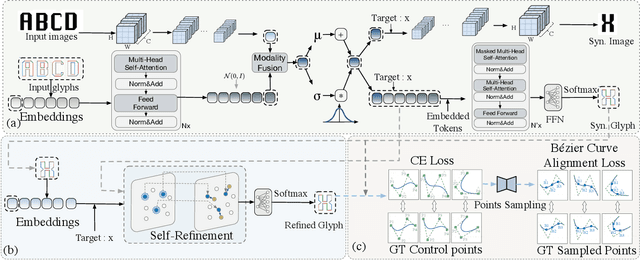
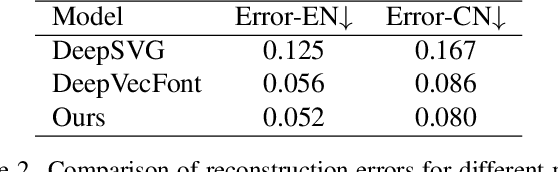
Vector font synthesis is a challenging and ongoing problem in the fields of Computer Vision and Computer Graphics. The recently-proposed DeepVecFont achieved state-of-the-art performance by exploiting information of both the image and sequence modalities of vector fonts. However, it has limited capability for handling long sequence data and heavily relies on an image-guided outline refinement post-processing. Thus, vector glyphs synthesized by DeepVecFont still often contain some distortions and artifacts and cannot rival human-designed results. To address the above problems, this paper proposes an enhanced version of DeepVecFont mainly by making the following three novel technical contributions. First, we adopt Transformers instead of RNNs to process sequential data and design a relaxation representation for vector outlines, markedly improving the model's capability and stability of synthesizing long and complex outlines. Second, we propose to sample auxiliary points in addition to control points to precisely align the generated and target B\'ezier curves or lines. Finally, to alleviate error accumulation in the sequential generation process, we develop a context-based self-refinement module based on another Transformer-based decoder to remove artifacts in the initially synthesized glyphs. Both qualitative and quantitative results demonstrate that the proposed method effectively resolves those intrinsic problems of the original DeepVecFont and outperforms existing approaches in generating English and Chinese vector fonts with complicated structures and diverse styles.
Self-Correctable and Adaptable Inference for Generalizable Human Pose Estimation
Mar 25, 2023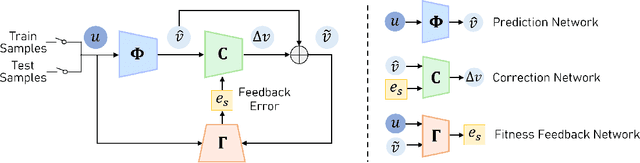
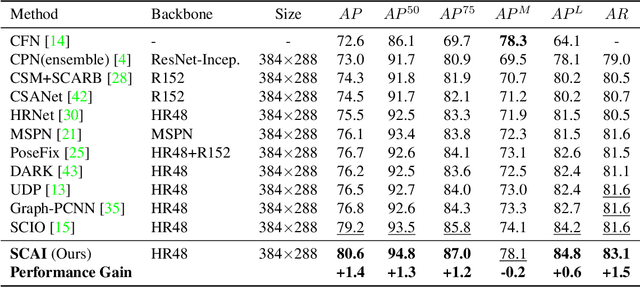
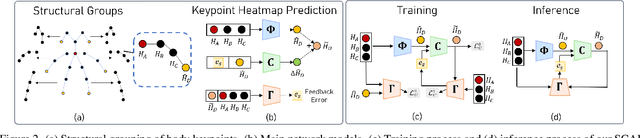
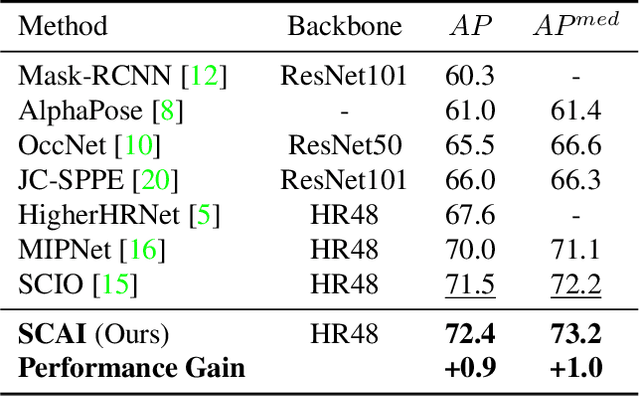
A central challenge in human pose estimation, as well as in many other machine learning and prediction tasks, is the generalization problem. The learned network does not have the capability to characterize the prediction error, generate feedback information from the test sample, and correct the prediction error on the fly for each individual test sample, which results in degraded performance in generalization. In this work, we introduce a self-correctable and adaptable inference (SCAI) method to address the generalization challenge of network prediction and use human pose estimation as an example to demonstrate its effectiveness and performance. We learn a correction network to correct the prediction result conditioned by a fitness feedback error. This feedback error is generated by a learned fitness feedback network which maps the prediction result to the original input domain and compares it against the original input. Interestingly, we find that this self-referential feedback error is highly correlated with the actual prediction error. This strong correlation suggests that we can use this error as feedback to guide the correction process. It can be also used as a loss function to quickly adapt and optimize the correction network during the inference process. Our extensive experimental results on human pose estimation demonstrate that the proposed SCAI method is able to significantly improve the generalization capability and performance of human pose estimation.
Shapley-based Explainable AI for Clustering Applications in Fault Diagnosis and Prognosis
Mar 25, 2023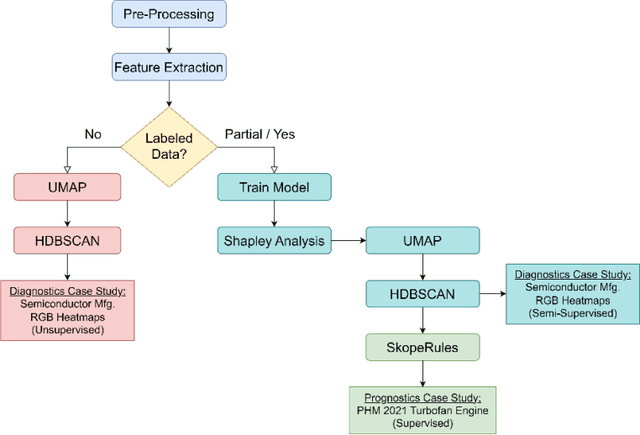
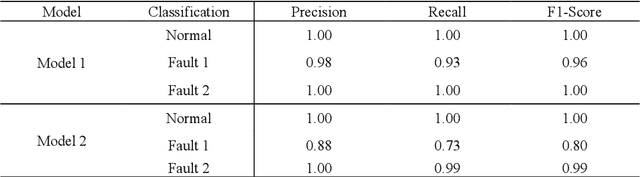
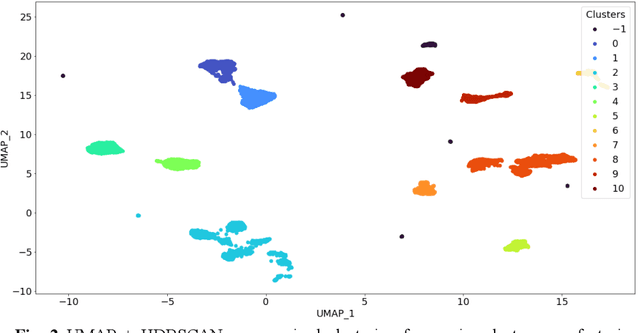
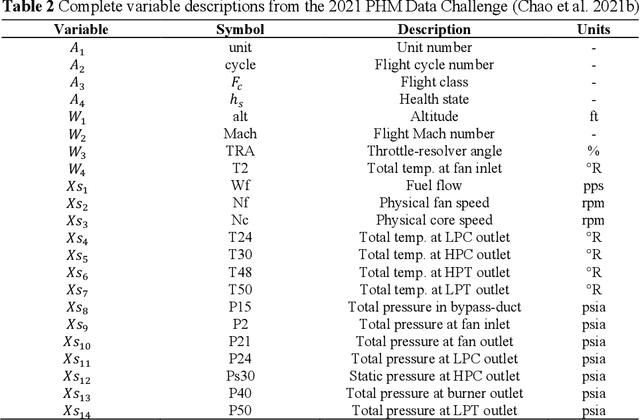
Data-driven artificial intelligence models require explainability in intelligent manufacturing to streamline adoption and trust in modern industry. However, recently developed explainable artificial intelligence (XAI) techniques that estimate feature contributions on a model-agnostic level such as SHapley Additive exPlanations (SHAP) have not yet been evaluated for semi-supervised fault diagnosis and prognosis problems characterized by class imbalance and weakly labeled datasets. This paper explores the potential of utilizing Shapley values for a new clustering framework compatible with semi-supervised learning problems, loosening the strict supervision requirement of current XAI techniques. This broad methodology is validated on two case studies: a heatmap image dataset obtained from a semiconductor manufacturing process featuring class imbalance, and a benchmark dataset utilized in the 2021 Prognostics and Health Management (PHM) Data Challenge. Semi-supervised clustering based on Shapley values significantly improves upon clustering quality compared to the fully unsupervised case, deriving information-dense and meaningful clusters that relate to underlying fault diagnosis model predictions. These clusters can also be characterized by high-precision decision rules in terms of original feature values, as demonstrated in the second case study. The rules, limited to 1-2 terms utilizing original feature scales, describe 12 out of the 16 derived equipment failure clusters with precision exceeding 0.85, showcasing the promising utility of the explainable clustering framework for intelligent manufacturing applications.
Intelligent Load Balancing and Resource Allocation in O-RAN: A Multi-Agent Multi-Armed Bandit Approach
Mar 25, 2023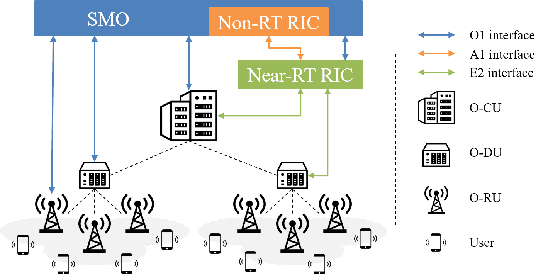
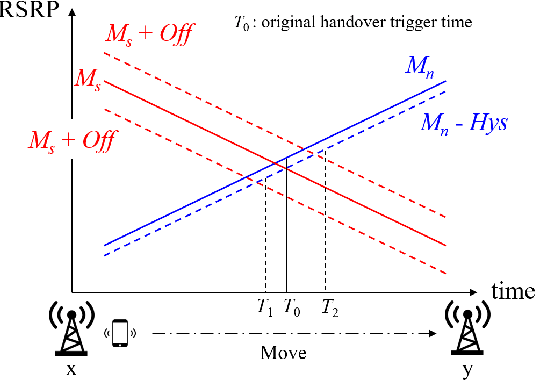
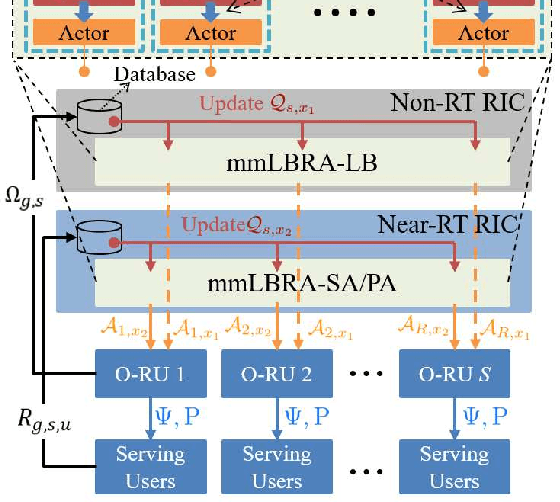
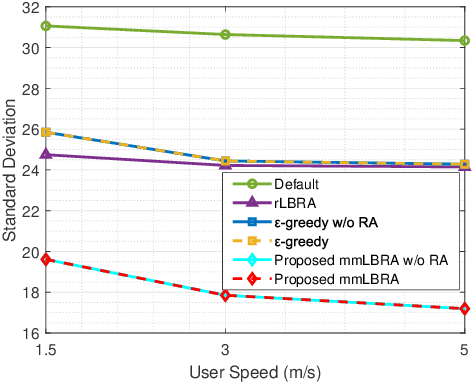
The open radio access network (O-RAN) architecture offers a cost-effective and scalable solution for internet service providers to optimize their networks using machine learning algorithms. The architecture's open interfaces enable network function virtualization, with the O-RAN serving as the primary communication device for users. However, the limited frequency resources and information explosion make it difficult to achieve an optimal network experience without effective traffic control or resource allocation. To address this, we consider mobility-aware load balancing to evenly distribute loads across the network, preventing network congestion and user outages caused by excessive load concentration on open radio unit (O-RU) governed by a single open distributed unit (O-DU). We have proposed a multi-agent multi-armed bandit for load balancing and resource allocation (mmLBRA) scheme, designed to both achieve load balancing and improve the effective sum-rate performance of the O-RAN network. We also present the mmLBRA-LB and mmLBRA-RA sub-schemes that can operate independently in non-realtime RAN intelligent controller (Non-RT RIC) and near-RT RIC, respectively, providing a solution with moderate loads and high-rate in O-RUs. Simulation results show that the proposed mmLBRA scheme significantly increases the effective network sum-rate while achieving better load balancing across O-RUs compared to rule-based and other existing heuristic methods in open literature.
Simultaneous Acquisition of High Quality RGB Image and Polarization Information using a Sparse Polarization Sensor
Sep 27, 2022
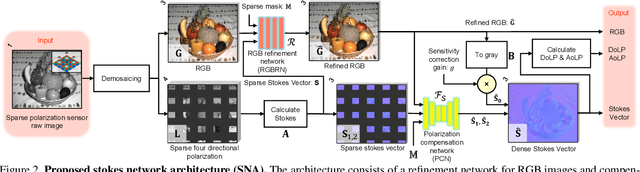
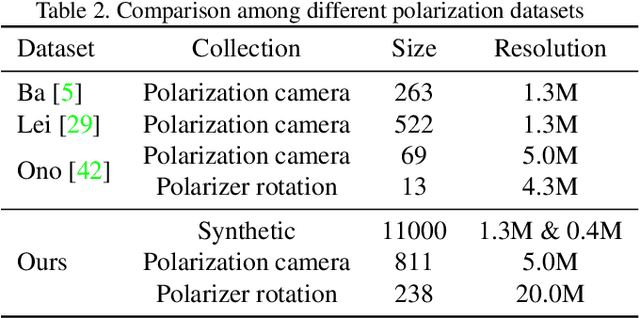
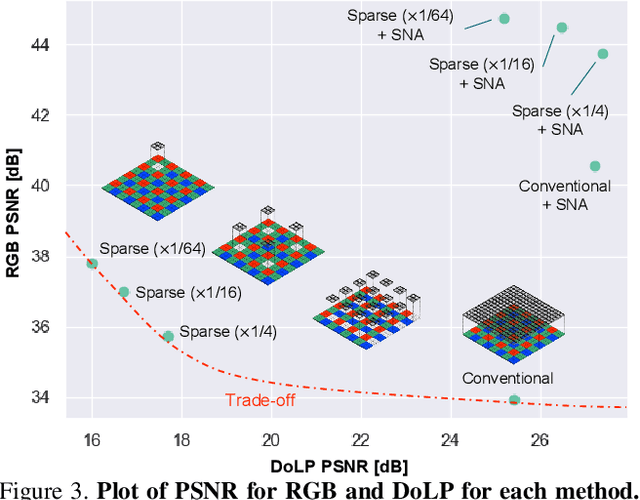
This paper proposes a novel polarization sensor structure and network architecture to obtain a high-quality RGB image and polarization information. Conventional polarization sensors can simultaneously acquire RGB images and polarization information, but the polarizers on the sensor degrade the quality of the RGB images. There is a trade-off between the quality of the RGB image and polarization information as fewer polarization pixels reduce the degradation of the RGB image but decrease the resolution of polarization information. Therefore, we propose an approach that resolves the trade-off by sparsely arranging polarization pixels on the sensor and compensating for low-resolution polarization information with higher resolution using the RGB image as a guide. Our proposed network architecture consists of an RGB image refinement network and a polarization information compensation network. We confirmed the superiority of our proposed network in compensating the differential component of polarization intensity by comparing its performance with state-of-the-art methods for similar tasks: depth completion. Furthermore, we confirmed that our approach could simultaneously acquire higher quality RGB images and polarization information than conventional polarization sensors, resolving the trade-off between the quality of RGB images and polarization information. The baseline code and newly generated real and synthetic large-scale polarization image datasets are available for further research and development.
Fine-grained Visual Classification with High-temperature Refinement and Background Suppression
Mar 11, 2023
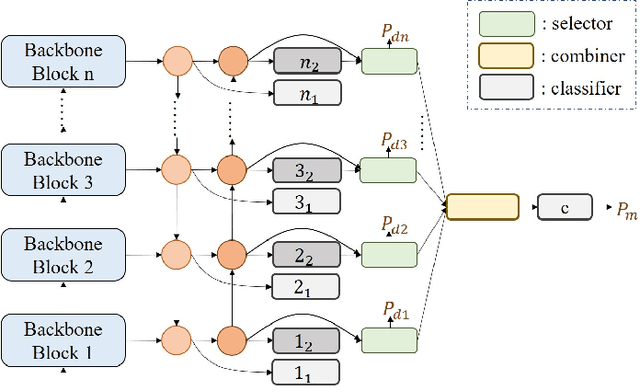
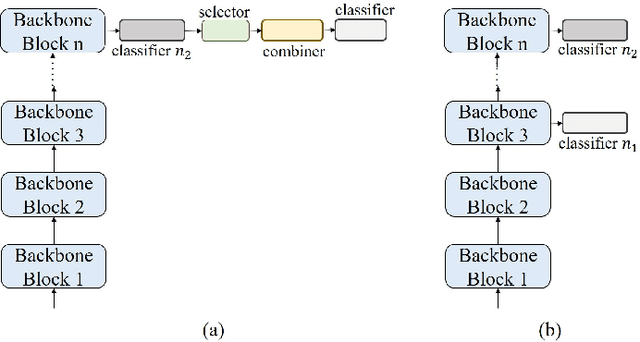
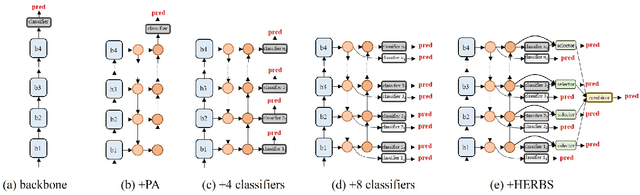
Fine-grained visual classification is a challenging task due to the high similarity between categories and distinct differences among data within one single category. To address the challenges, previous strategies have focused on localizing subtle discrepancies between categories and enhencing the discriminative features in them. However, the background also provides important information that can tell the model which features are unnecessary or even harmful for classification, and models that rely too heavily on subtle features may overlook global features and contextual information. In this paper, we propose a novel network called ``High-temperaturE Refinement and Background Suppression'' (HERBS), which consists of two modules, namely, the high-temperature refinement module and the background suppression module, for extracting discriminative features and suppressing background noise, respectively. The high-temperature refinement module allows the model to learn the appropriate feature scales by refining the features map at different scales and improving the learning of diverse features. And, the background suppression module first splits the features map into foreground and background using classification confidence scores and suppresses feature values in low-confidence areas while enhancing discriminative features. The experimental results show that the proposed HERBS effectively fuses features of varying scales, suppresses background noise, discriminative features at appropriate scales for fine-grained visual classification.The proposed method achieves state-of-the-art performance on the CUB-200-2011 and NABirds benchmarks, surpassing 93% accuracy on both datasets. Thus, HERBS presents a promising solution for improving the performance of fine-grained visual classification tasks. code will be available: soon
Edgeformers: Graph-Empowered Transformers for Representation Learning on Textual-Edge Networks
Feb 21, 2023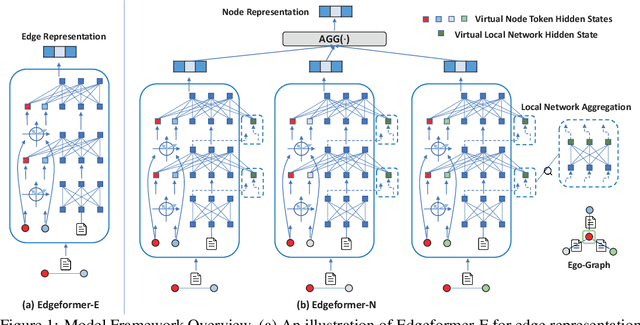

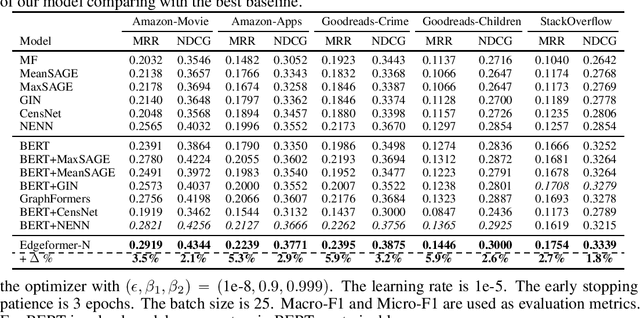
Edges in many real-world social/information networks are associated with rich text information (e.g., user-user communications or user-product reviews). However, mainstream network representation learning models focus on propagating and aggregating node attributes, lacking specific designs to utilize text semantics on edges. While there exist edge-aware graph neural networks, they directly initialize edge attributes as a feature vector, which cannot fully capture the contextualized text semantics of edges. In this paper, we propose Edgeformers, a framework built upon graph-enhanced Transformers, to perform edge and node representation learning by modeling texts on edges in a contextualized way. Specifically, in edge representation learning, we inject network information into each Transformer layer when encoding edge texts; in node representation learning, we aggregate edge representations through an attention mechanism within each node's ego-graph. On five public datasets from three different domains, Edgeformers consistently outperform state-of-the-art baselines in edge classification and link prediction, demonstrating the efficacy in learning edge and node representations, respectively.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 21, 2023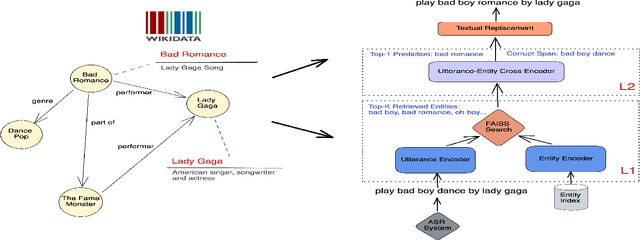

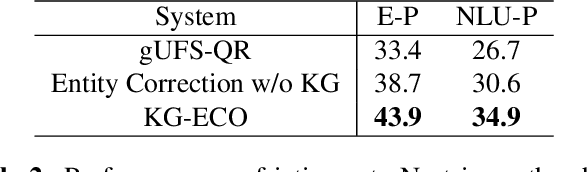
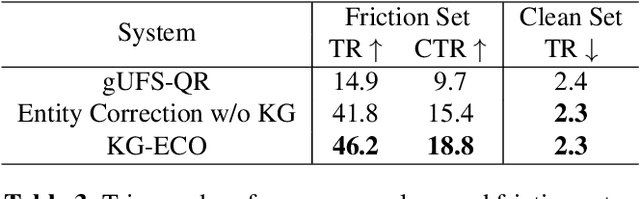
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities.To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
N-best T5: Robust ASR Error Correction using Multiple Input Hypotheses and Constrained Decoding Space
Mar 01, 2023
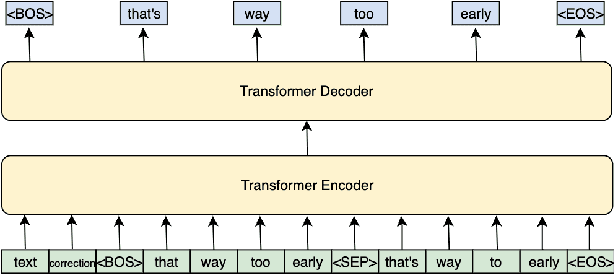
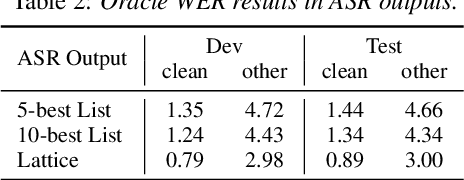
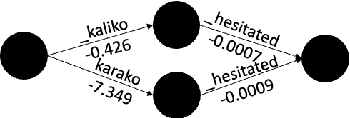
Error correction models form an important part of Automatic Speech Recognition (ASR) post-processing to improve the readability and quality of transcriptions. Most prior works use the 1-best ASR hypothesis as input and therefore can only perform correction by leveraging the context within one sentence. In this work, we propose a novel N-best T5 model for this task, which is fine-tuned from a T5 model and utilizes ASR N-best lists as model input. By transferring knowledge from the pre-trained language model and obtaining richer information from the ASR decoding space, the proposed approach outperforms a strong Conformer-Transducer baseline. Another issue with standard error correction is that the generation process is not well-guided. To address this a constrained decoding process, either based on the N-best list or an ASR lattice, is used which allows additional information to be propagated.
Salient Span Masking for Temporal Understanding
Mar 22, 2023
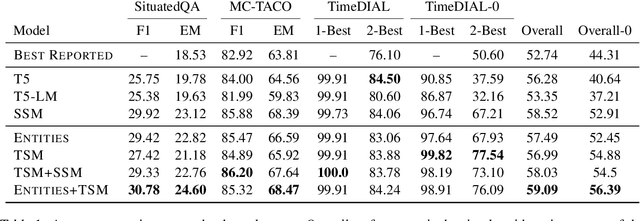
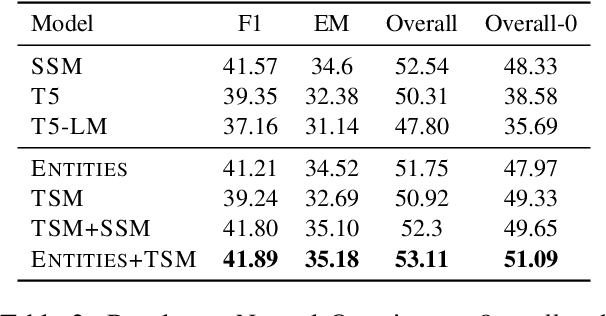
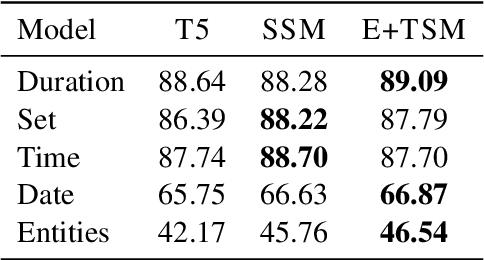
Salient Span Masking (SSM) has shown itself to be an effective strategy to improve closed-book question answering performance. SSM extends general masked language model pretraining by creating additional unsupervised training sentences that mask a single entity or date span, thus oversampling factual information. Despite the success of this paradigm, the span types and sampling strategies are relatively arbitrary and not widely studied for other tasks. Thus, we investigate SSM from the perspective of temporal tasks, where learning a good representation of various temporal expressions is important. To that end, we introduce Temporal Span Masking (TSM) intermediate training. First, we find that SSM alone improves the downstream performance on three temporal tasks by an avg. +5.8 points. Further, we are able to achieve additional improvements (avg. +0.29 points) by adding the TSM task. These comprise the new best reported results on the targeted tasks. Our analysis suggests that the effectiveness of SSM stems from the sentences chosen in the training data rather than the mask choice: sentences with entities frequently also contain temporal expressions. Nonetheless, the additional targeted spans of TSM can still improve performance, especially in a zero-shot context.