 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Construction using Principal Axis Trees for Simple Graph Convolution
Feb 22, 2023
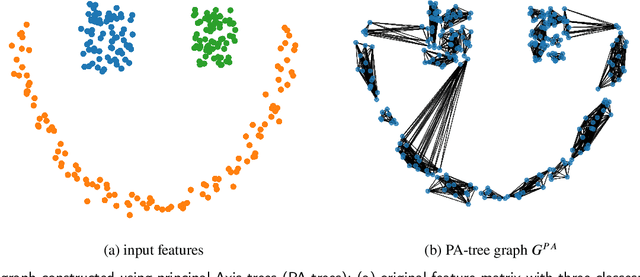


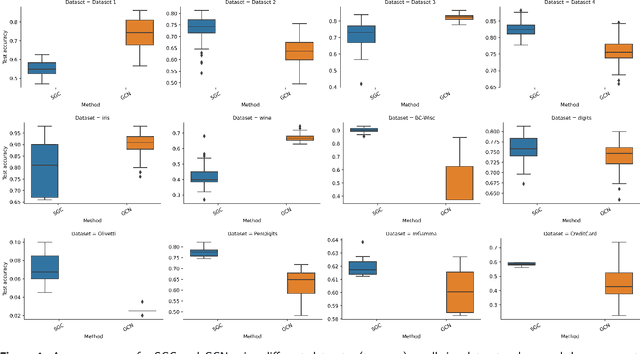
Graph Neural Networks (GNNs) are increasingly becoming the favorite method for graph learning. They exploit the semi-supervised nature of deep learning, and they bypass computational bottlenecks associated with traditional graph learning methods. In addition to the feature matrix $X$, GNNs need an adjacency matrix $A$ to perform feature propagation. In many cases the adjacency matrix $A$ is missing. We introduce a graph construction scheme that construct the adjacency matrix $A$ using unsupervised and supervised information. Unsupervised information characterize the neighborhood around points. We used Principal Axis trees (PA-trees) as a source of unsupervised information, where we create edges between points falling onto the same leaf node. For supervised information, we used the concept of penalty and intrinsic graphs. A penalty graph connects points with different class labels, whereas intrinsic graph connects points with the same class label. We used the penalty and intrinsic graphs to remove or add edges to the graph constructed via PA-tree. This graph construction scheme was tested on two well-known GNNs: 1) Graph Convolutional Network (GCN) and 2) Simple Graph Convolution (SGC). The experiments show that it is better to use SGC because it is faster and delivers better or the same results as GCN. We also test the effect of oversmoothing on both GCN and SGC. We found out that the level of smoothing has to be selected carefully for SGC to avoid oversmoothing.
Asynchronous Trajectory Matching-Based Multimodal Maritime Data Fusion for Vessel Traffic Surveillance in Inland Waterways
Feb 22, 2023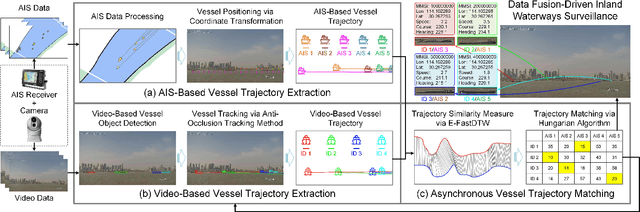
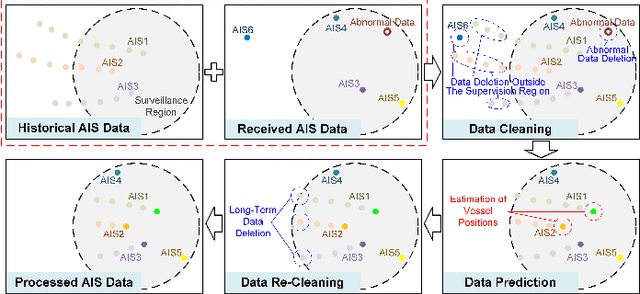
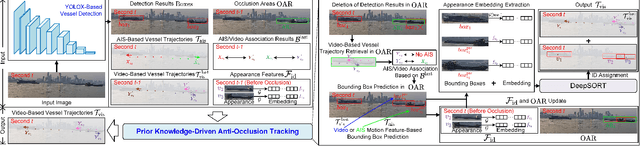

The automatic identification system (AIS) and video cameras have been widely exploited for vessel traffic surveillance in inland waterways. The AIS data could provide the vessel identity and dynamic information on vessel position and movements. In contrast, the video data could describe the visual appearances of moving vessels, but without knowing the information on identity, position and movements, etc. To further improve vessel traffic surveillance, it becomes necessary to fuse the AIS and video data to simultaneously capture the visual features, identity and dynamic information for the vessels of interest. However, traditional data fusion methods easily suffer from several potential limitations, e.g., asynchronous messages, missing data, random outliers, etc. In this work, we first extract the AIS- and video-based vessel trajectories, and then propose a deep learning-enabled asynchronous trajectory matching method (named DeepSORVF) to fuse the AIS-based vessel information with the corresponding visual targets. In addition, by combining the AIS- and video-based movement features, we also present a prior knowledge-driven anti-occlusion method to yield accurate and robust vessel tracking results under occlusion conditions. To validate the efficacy of our DeepSORVF, we have also constructed a new benchmark dataset (termed FVessel) for vessel detection, tracking, and data fusion. It consists of many videos and the corresponding AIS data collected in various weather conditions and locations. The experimental results have demonstrated that our method is capable of guaranteeing high-reliable data fusion and anti-occlusion vessel tracking.
FormLM: Recommending Creation Ideas for Online Forms by Modelling Semantic and Structural Information
Nov 10, 2022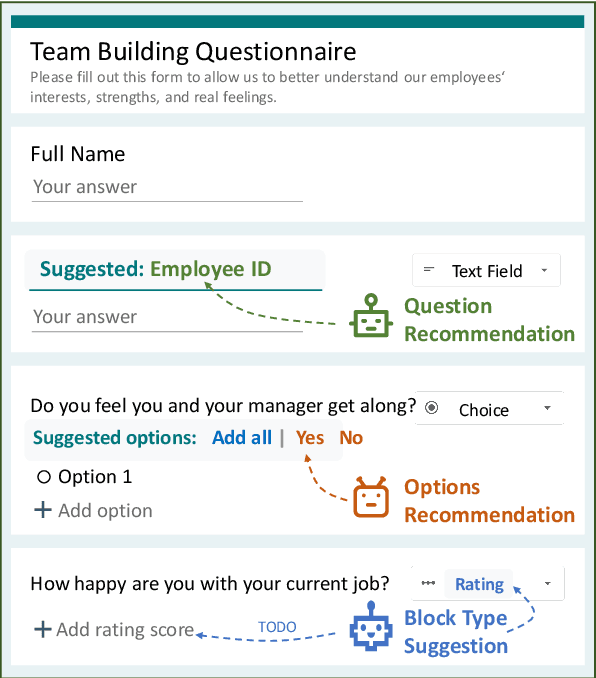
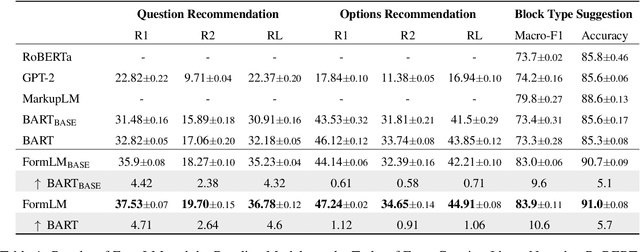
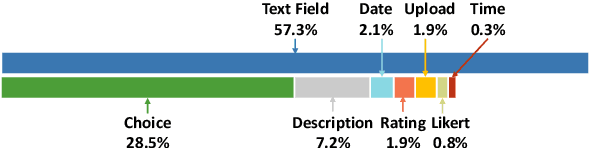
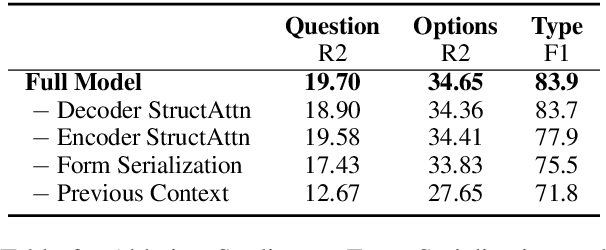
Online forms are widely used to collect data from human and have a multi-billion market. Many software products provide online services for creating semi-structured forms where questions and descriptions are organized by pre-defined structures. However, the design and creation process of forms is still tedious and requires expert knowledge. To assist form designers, in this work we present FormLM to model online forms (by enhancing pre-trained language model with form structural information) and recommend form creation ideas (including question / options recommendations and block type suggestion). For model training and evaluation, we collect the first public online form dataset with 62K online forms. Experiment results show that FormLM significantly outperforms general-purpose language models on all tasks, with an improvement by 4.71 on Question Recommendation and 10.6 on Block Type Suggestion in terms of ROUGE-1 and Macro-F1, respectively.
Adaptive Graph Convolution Module for Salient Object Detection
Mar 17, 2023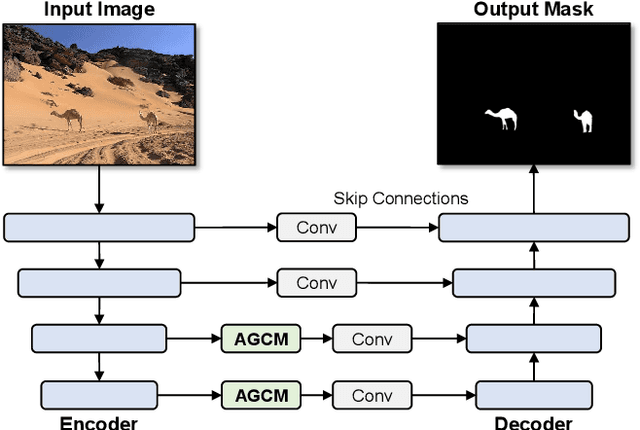
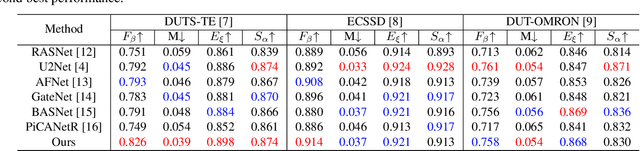
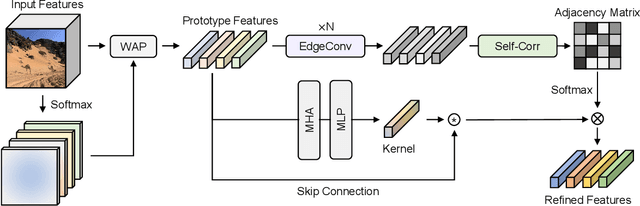
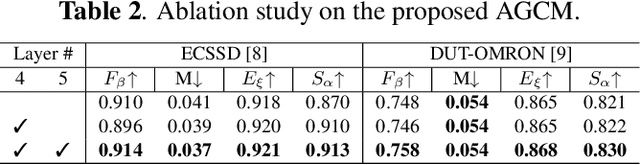
Salient object detection (SOD) is a task that involves identifying and segmenting the most visually prominent object in an image. Existing solutions can accomplish this use a multi-scale feature fusion mechanism to detect the global context of an image. However, as there is no consideration of the structures in the image nor the relations between distant pixels, conventional methods cannot deal with complex scenes effectively. In this paper, we propose an adaptive graph convolution module (AGCM) to overcome these limitations. Prototype features are initially extracted from the input image using a learnable region generation layer that spatially groups features in the image. The prototype features are then refined by propagating information between them based on a graph architecture, where each feature is regarded as a node. Experimental results show that the proposed AGCM dramatically improves the SOD performance both quantitatively and quantitatively.
CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis
Mar 07, 2023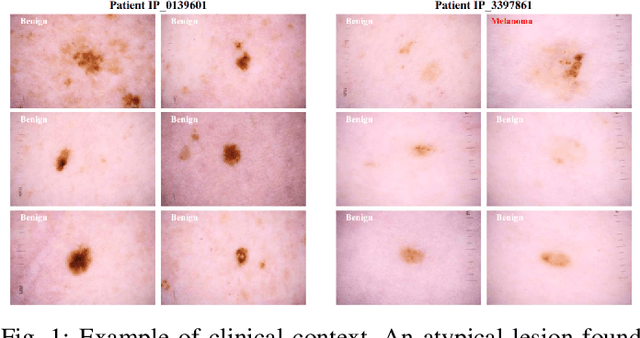
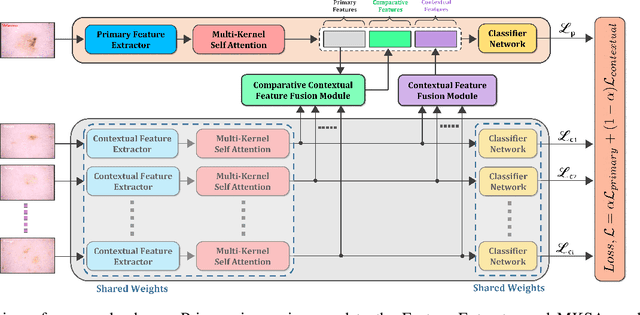
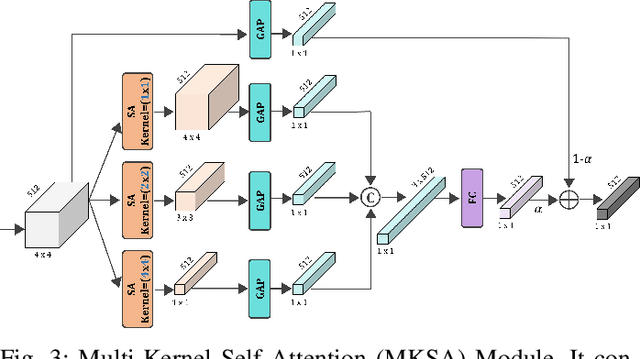
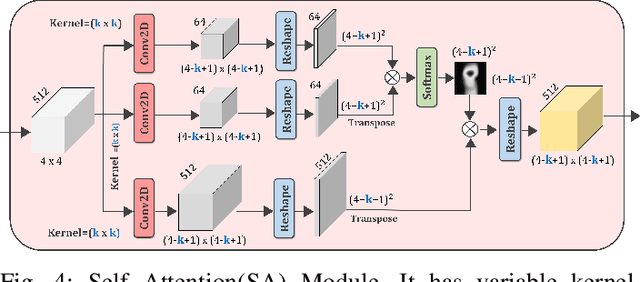
Melanoma is considered to be the deadliest variant of skin cancer causing around 75\% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
Category-level Shape Estimation for Densely Cluttered Objects
Feb 23, 2023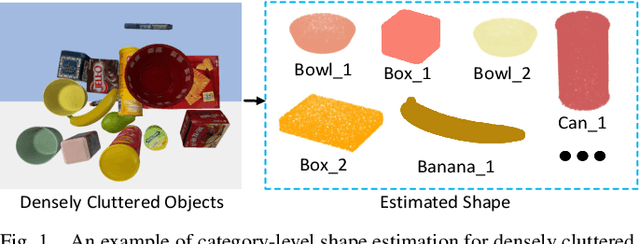
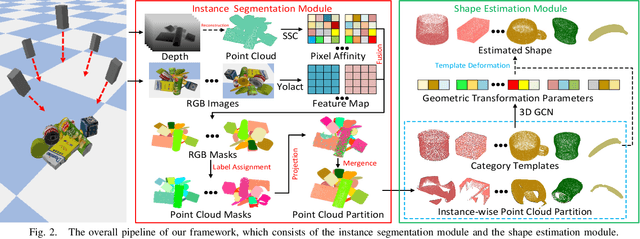
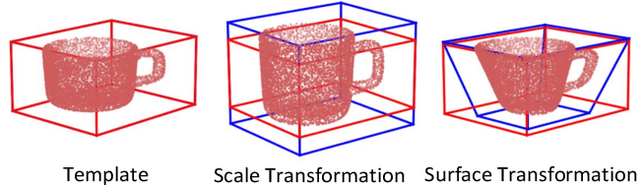
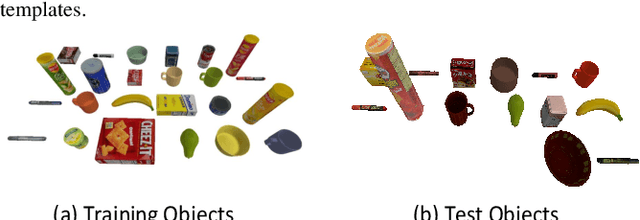
Accurately estimating the shape of objects in dense clutters makes important contribution to robotic packing, because the optimal object arrangement requires the robot planner to acquire shape information of all existed objects. However, the objects for packing are usually piled in dense clutters with severe occlusion, and the object shape varies significantly across different instances for the same category. They respectively cause large object segmentation errors and inaccurate shape recovery on unseen instances, which both degrade the performance of shape estimation during deployment. In this paper, we propose a category-level shape estimation method for densely cluttered objects. Our framework partitions each object in the clutter via the multi-view visual information fusion to achieve high segmentation accuracy, and the instance shape is recovered by deforming the category templates with diverse geometric transformations to obtain strengthened generalization ability. Specifically, we first collect the multi-view RGB-D images of the object clutters for point cloud reconstruction. Then we fuse the feature maps representing the visual information of multi-view RGB images and the pixel affinity learned from the clutter point cloud, where the acquired instance segmentation masks of multi-view RGB images are projected to partition the clutter point cloud. Finally, the instance geometry information is obtained from the partially observed instance point cloud and the corresponding category template, and the deformation parameters regarding the template are predicted for shape estimation. Experiments in the simulated environment and real world show that our method achieves high shape estimation accuracy for densely cluttered everyday objects with various shapes.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023

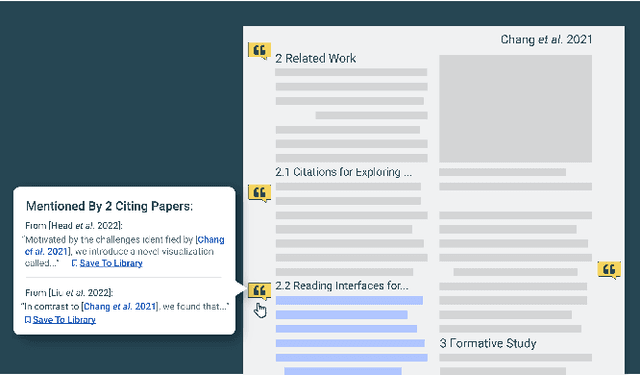
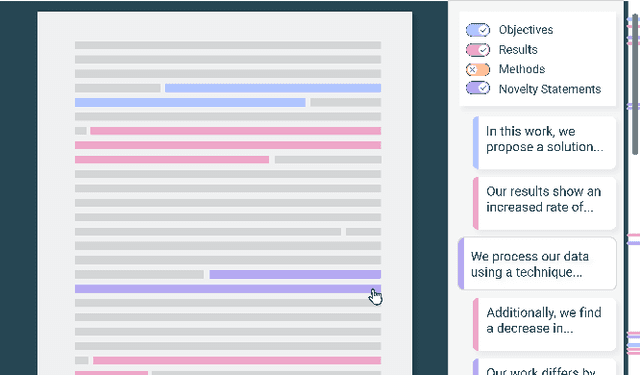
Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
A Survey on Model-based, Heuristic, and Machine Learning Optimization Approaches in RIS-aided Wireless Networks
Mar 25, 2023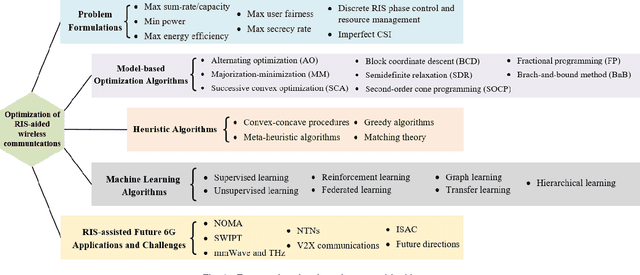
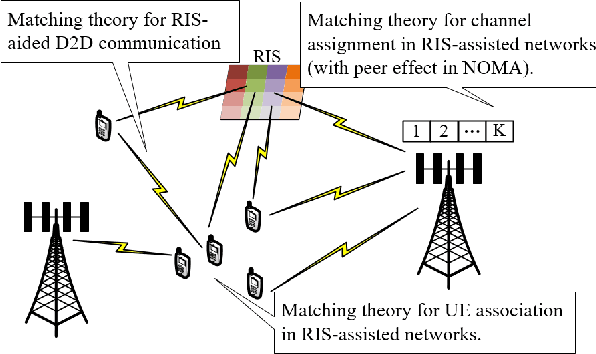
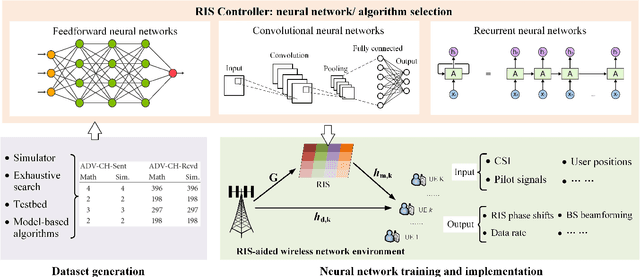
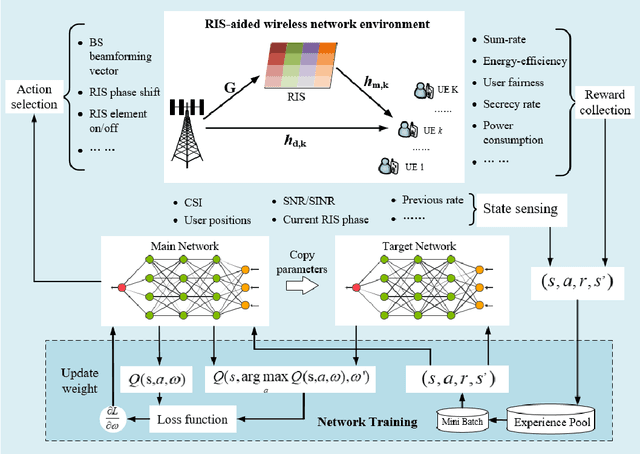
Reconfigurable intelligent surfaces (RISs) have received considerable attention as a key enabler for envisioned 6G networks, for the purpose of improving the network capacity, coverage, efficiency, and security with low energy consumption and low hardware cost. However, integrating RISs into the existing infrastructure greatly increases the network management complexity, especially for controlling a significant number of RIS elements. To unleash the full potential of RISs, efficient optimization approaches are of great importance. This work provides a comprehensive survey on optimization techniques for RIS-aided wireless communications, including model-based, heuristic, and machine learning (ML) algorithms. In particular, we first summarize the problem formulations in the literature with diverse objectives and constraints, e.g., sum-rate maximization, power minimization, and imperfect channel state information constraints. Then, we introduce model-based algorithms that have been used in the literature, such as alternating optimization, the majorization-minimization method, and successive convex approximation. Next, heuristic optimization is discussed, which applies heuristic rules for obtaining low-complexity solutions. Moreover, we present state-of-the-art ML algorithms and applications towards RISs, i.e., supervised and unsupervised learning, reinforcement learning, federated learning, graph learning, transfer learning, and hierarchical learning-based approaches. Model-based, heuristic, and ML approaches are compared in terms of stability, robustness, optimality and so on, providing a systematic understanding of these techniques. Finally, we highlight RIS-aided applications towards 6G networks and identify future challenges.
OVeNet: Offset Vector Network for Semantic Segmentation
Mar 25, 2023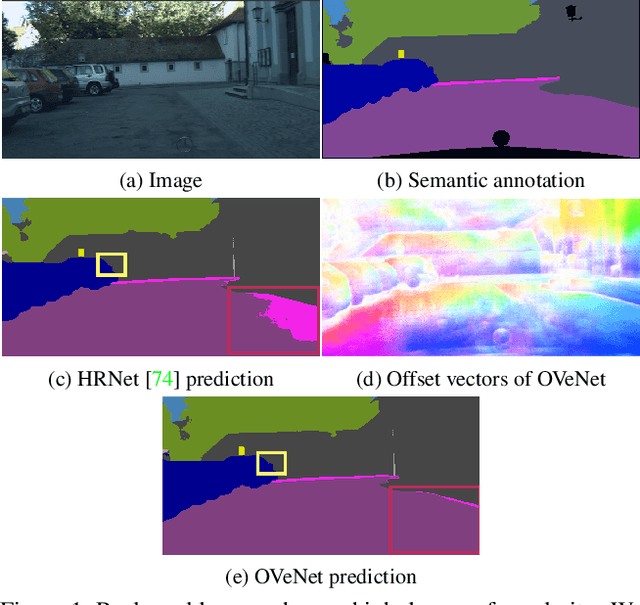
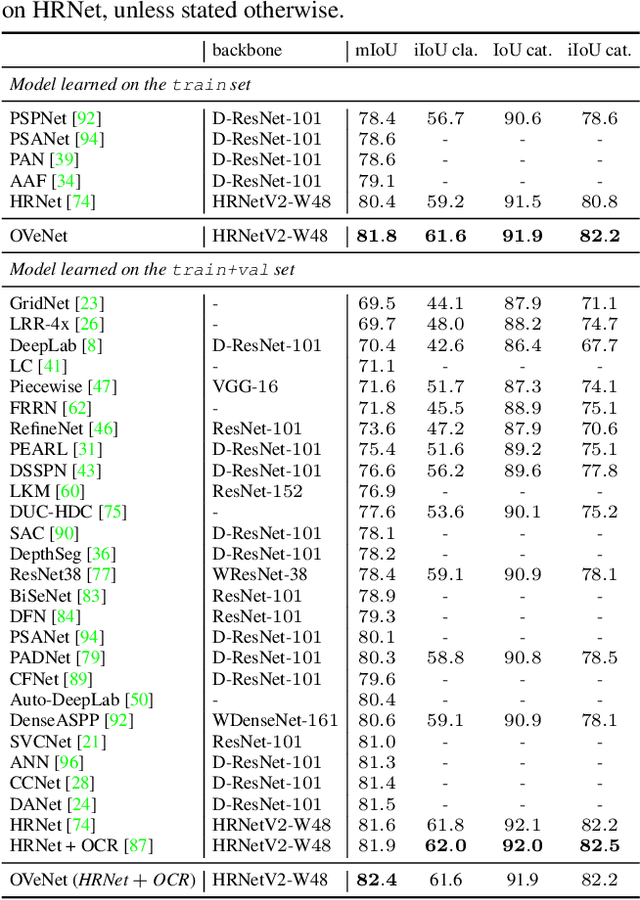
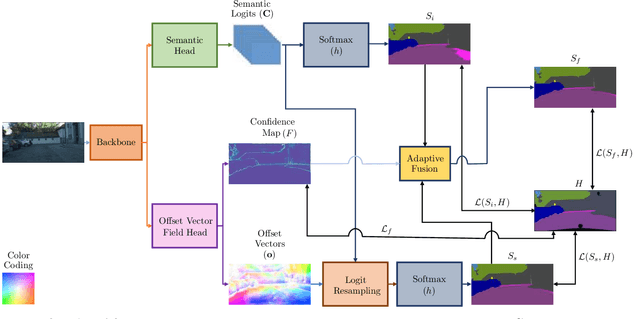

Semantic segmentation is a fundamental task in visual scene understanding. We focus on the supervised setting, where ground-truth semantic annotations are available. Based on knowledge about the high regularity of real-world scenes, we propose a method for improving class predictions by learning to selectively exploit information from neighboring pixels. In particular, our method is based on the prior that for each pixel, there is a seed pixel in its close neighborhood sharing the same prediction with the former. Motivated by this prior, we design a novel two-head network, named Offset Vector Network (OVeNet), which generates both standard semantic predictions and a dense 2D offset vector field indicating the offset from each pixel to the respective seed pixel, which is used to compute an alternative, seed-based semantic prediction. The two predictions are adaptively fused at each pixel using a learnt dense confidence map for the predicted offset vector field. We supervise offset vectors indirectly via optimizing the seed-based prediction and via a novel loss on the confidence map. Compared to the baseline state-of-the-art architectures HRNet and HRNet+OCR on which OVeNet is built, the latter achieves significant performance gains on two prominent benchmarks for semantic segmentation of driving scenes, namely Cityscapes and ACDC. Code is available at https://github.com/stamatisalex/OVeNet
Distributed Multi-Agent Deep Q-Learning for Fast Roaming in IEEE 802.11ax Wi-Fi Systems
Mar 25, 2023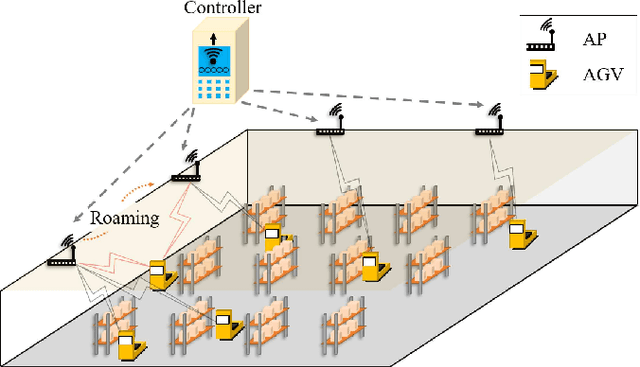
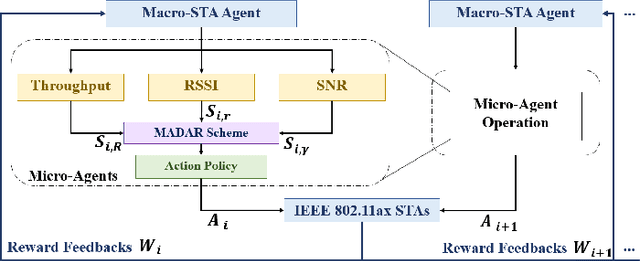
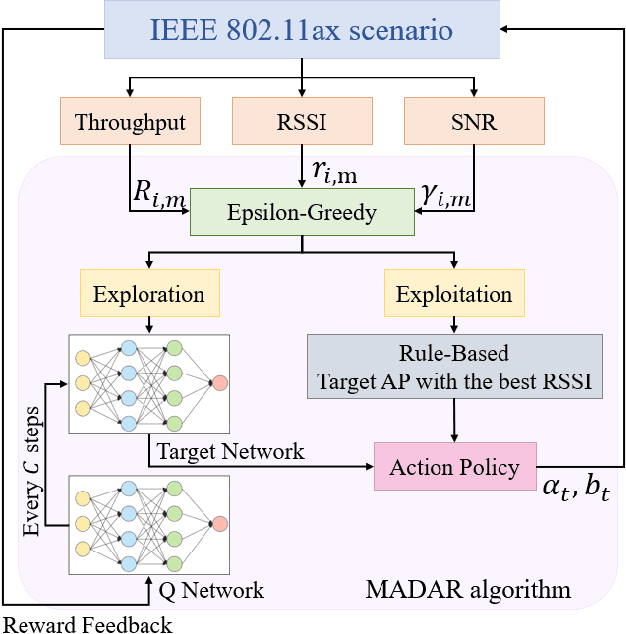
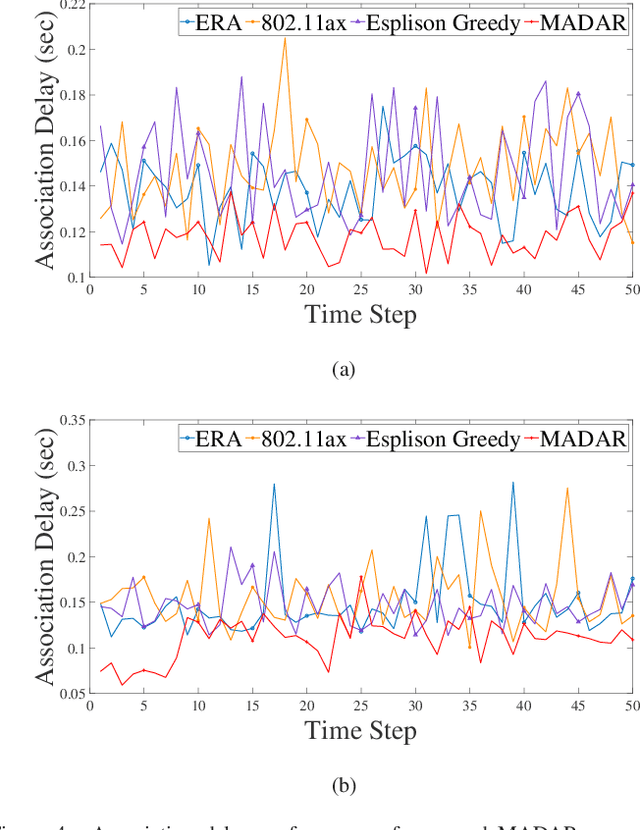
The innovation of Wi-Fi 6, IEEE 802.11ax, was be approved as the next sixth-generation (6G) technology of wireless local area networks (WLANs) by improving the fundamental performance of latency, throughput, and so on. The main technical feature of orthogonal frequency division multiple access (OFDMA) supports multi-users to transmit respective data concurrently via the corresponding access points (APs). However, the conventional IEEE 802.11 protocol for Wi-Fi roaming selects the target AP only depending on received signal strength indication (RSSI) which is obtained by the received Response frame from the APs. In the long term, it may lead to congestion in a single channel under the scenarios of dense users further increasing the association delay and packet drop rate, even reducing the quality of service (QoS) of the overall system. In this paper, we propose a multi-agent deep Q-learning for fast roaming (MADAR) algorithm to effectively minimize the latency during the station roaming for Smart Warehouse in Wi-Fi 6 system. The MADAR algorithm considers not only RSSI but also channel state information (CSI), and through online neural network learning and weighting adjustments to maximize the reward of the action selected from Epsilon-Greedy. Compared to existing benchmark methods, the MADAR algorithm has been demonstrated for improved roaming latency by analyzing the simulation result and realistic dataset.