 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can LLMs Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
Mar 18, 2024
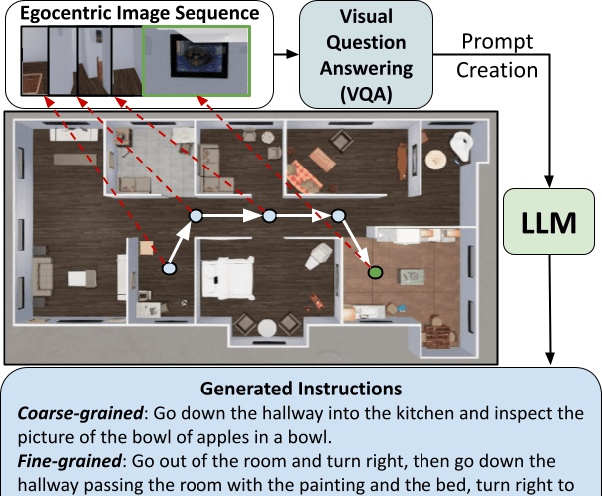

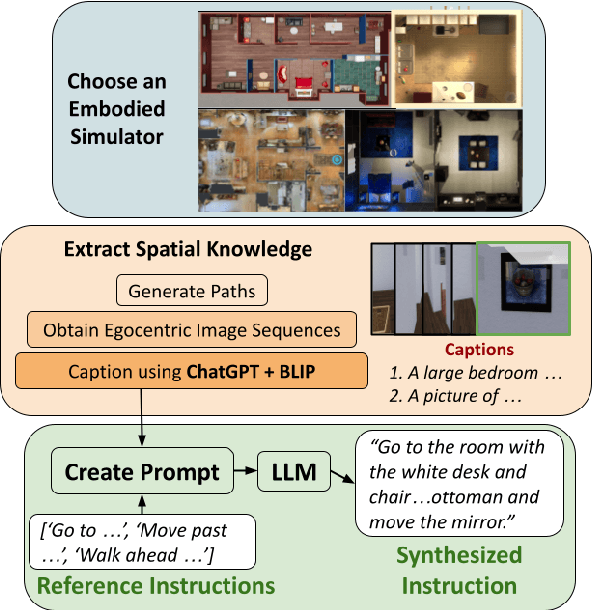

We present a novel approach to automatically synthesize "wayfinding instructions" for an embodied robot agent. In contrast to prior approaches that are heavily reliant on human-annotated datasets designed exclusively for specific simulation platforms, our algorithm uses in-context learning to condition an LLM to generate instructions using just a few references. Using an LLM-based Visual Question Answering strategy, we gather detailed information about the environment which is used by the LLM for instruction synthesis. We implement our approach on multiple simulation platforms including Matterport3D, AI Habitat and ThreeDWorld, thereby demonstrating its platform-agnostic nature. We subjectively evaluate our approach via a user study and observe that 83.3% of users find the synthesized instructions accurately capture the details of the environment and show characteristics similar to those of human-generated instructions. Further, we conduct zero-shot navigation with multiple approaches on the REVERIE dataset using the generated instructions, and observe very close correlation with the baseline on standard success metrics (< 1% change in SR), quantifying the viability of generated instructions in replacing human-annotated data. To the best of our knowledge, ours is the first LLM-driven approach capable of generating "human-like" instructions in a platform-agnostic manner, without requiring any form of training.
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Mar 14, 2024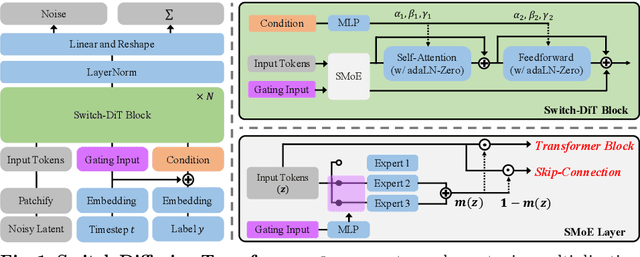
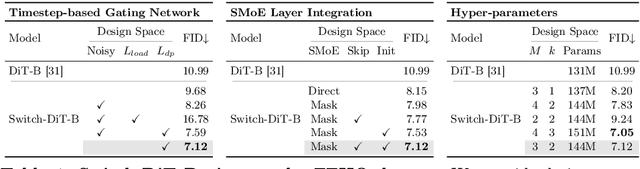
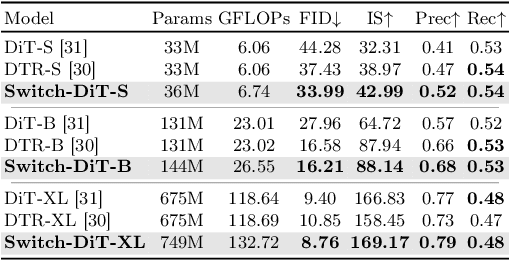
Diffusion models have achieved remarkable success across a range of generative tasks. Recent efforts to enhance diffusion model architectures have reimagined them as a form of multi-task learning, where each task corresponds to a denoising task at a specific noise level. While these efforts have focused on parameter isolation and task routing, they fall short of capturing detailed inter-task relationships and risk losing semantic information, respectively. In response, we introduce Switch Diffusion Transformer (Switch-DiT), which establishes inter-task relationships between conflicting tasks without compromising semantic information. To achieve this, we employ a sparse mixture-of-experts within each transformer block to utilize semantic information and facilitate handling conflicts in tasks through parameter isolation. Additionally, we propose a diffusion prior loss, encouraging similar tasks to share their denoising paths while isolating conflicting ones. Through these, each transformer block contains a shared expert across all tasks, where the common and task-specific denoising paths enable the diffusion model to construct its beneficial way of synergizing denoising tasks. Extensive experiments validate the effectiveness of our approach in improving both image quality and convergence rate, and further analysis demonstrates that Switch-DiT constructs tailored denoising paths across various generation scenarios.
Learning Hierarchical Color Guidance for Depth Map Super-Resolution
Mar 12, 2024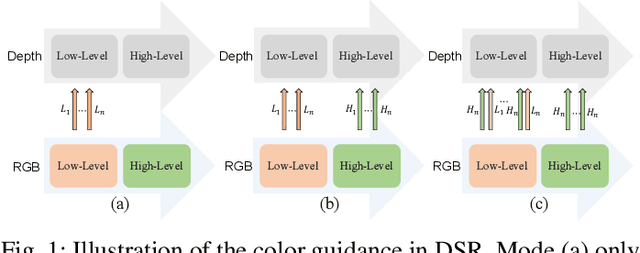

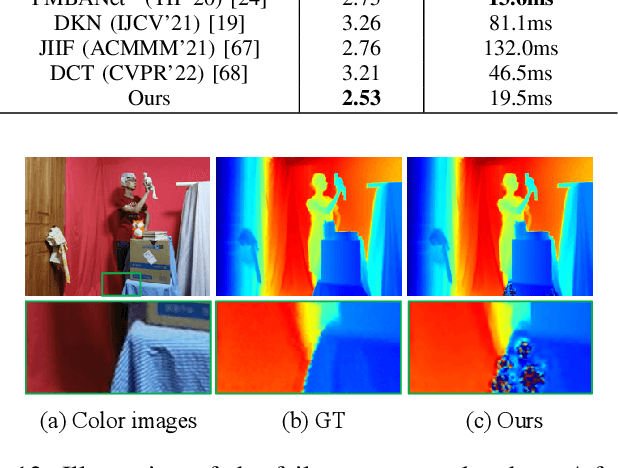
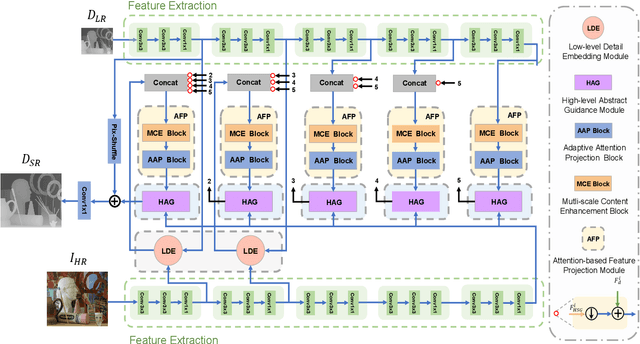
Color information is the most commonly used prior knowledge for depth map super-resolution (DSR), which can provide high-frequency boundary guidance for detail restoration. However, its role and functionality in DSR have not been fully developed. In this paper, we rethink the utilization of color information and propose a hierarchical color guidance network to achieve DSR. On the one hand, the low-level detail embedding module is designed to supplement high-frequency color information of depth features in a residual mask manner at the low-level stages. On the other hand, the high-level abstract guidance module is proposed to maintain semantic consistency in the reconstruction process by using a semantic mask that encodes the global guidance information. The color information of these two dimensions plays a role in the front and back ends of the attention-based feature projection (AFP) module in a more comprehensive form. Simultaneously, the AFP module integrates the multi-scale content enhancement block and adaptive attention projection block to make full use of multi-scale information and adaptively project critical restoration information in an attention manner for DSR. Compared with the state-of-the-art methods on four benchmark datasets, our method achieves more competitive performance both qualitatively and quantitatively.
Learning under Singularity: An Information Criterion improving WBIC and sBIC
Feb 22, 2024We introduce a novel Information Criterion (IC), termed Learning under Singularity (LS), designed to enhance the functionality of the Widely Applicable Bayes Information Criterion (WBIC) and the Singular Bayesian Information Criterion (sBIC). LS is effective without regularity constraints and demonstrates stability. Watanabe defined a statistical model or a learning machine as regular if the mapping from a parameter to a probability distribution is one-to-one and its Fisher information matrix is positive definite. In contrast, models not meeting these conditions are termed singular. Over the past decade, several information criteria for singular cases have been proposed, including WBIC and sBIC. WBIC is applicable in non-regular scenarios but faces challenges with large sample sizes and redundant estimation of known learning coefficients. Conversely, sBIC is limited in its broader application due to its dependence on maximum likelihood estimates. LS addresses these limitations by enhancing the utility of both WBIC and sBIC. It incorporates the empirical loss from the Widely Applicable Information Criterion (WAIC) to represent the goodness of fit to the statistical model, along with a penalty term similar to that of sBIC. This approach offers a flexible and robust method for model selection, free from regularity constraints.
Rethinking Autoencoders for Medical Anomaly Detection from A Theoretical Perspective
Mar 15, 2024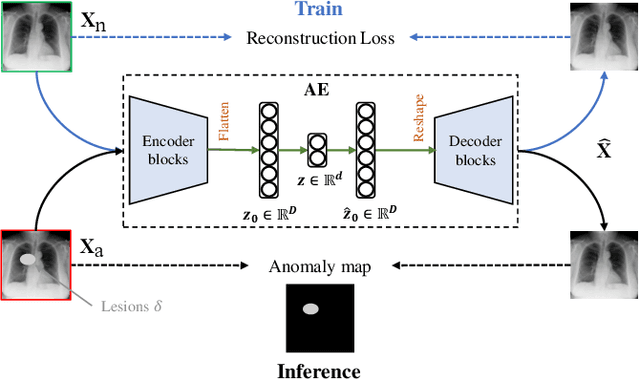
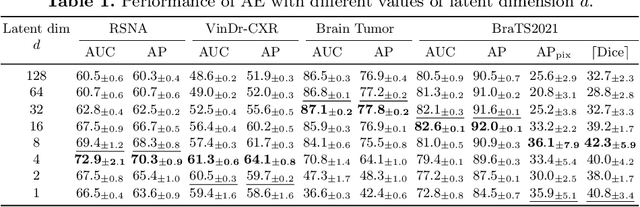
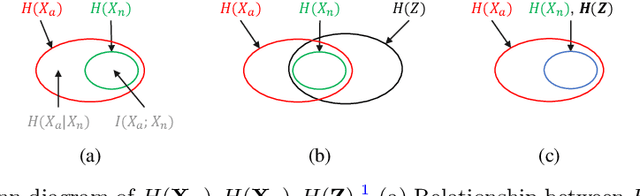
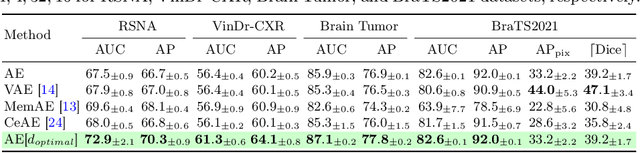
Medical anomaly detection aims to identify abnormal findings using only normal training data, playing a crucial role in health screening and recognizing rare diseases. Reconstruction-based methods, particularly those utilizing autoencoders (AEs), are dominant in this field. They work under the assumption that AEs trained on only normal data cannot reconstruct unseen abnormal regions well, thereby enabling the anomaly detection based on reconstruction errors. However, this assumption does not always hold due to the mismatch between the reconstruction training objective and the anomaly detection task objective, rendering these methods theoretically unsound. This study focuses on providing a theoretical foundation for AE-based reconstruction methods in anomaly detection. By leveraging information theory, we elucidate the principles of these methods and reveal that the key to improving AE in anomaly detection lies in minimizing the information entropy of latent vectors. Experiments on four datasets with two image modalities validate the effectiveness of our theory. To the best of our knowledge, this is the first effort to theoretically clarify the principles and design philosophy of AE for anomaly detection. Code will be available upon acceptance.
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024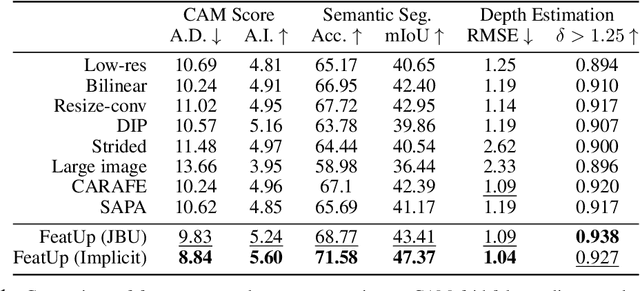
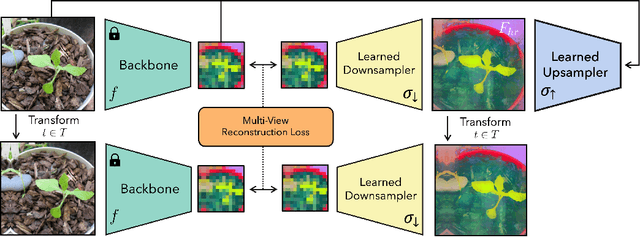
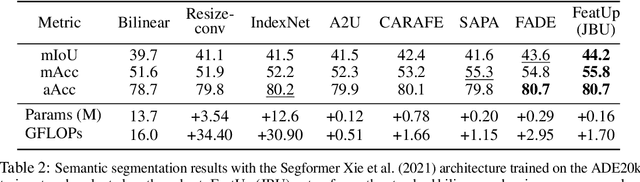

Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
ST-LDM: A Universal Framework for Text-Grounded Object Generation in Real Images
Mar 15, 2024
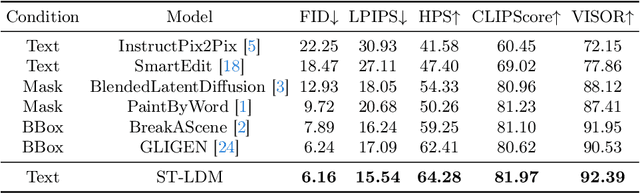
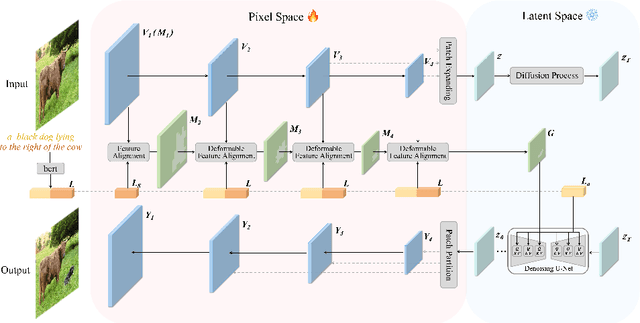
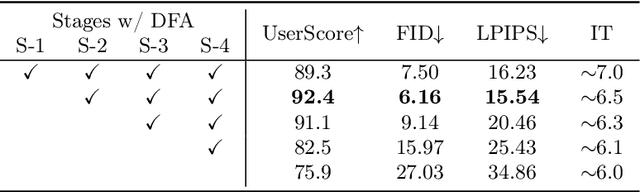
We present a novel image editing scenario termed Text-grounded Object Generation (TOG), defined as generating a new object in the real image spatially conditioned by textual descriptions. Existing diffusion models exhibit limitations of spatial perception in complex real-world scenes, relying on additional modalities to enforce constraints, and TOG imposes heightened challenges on scene comprehension under the weak supervision of linguistic information. We propose a universal framework ST-LDM based on Swin-Transformer, which can be integrated into any latent diffusion model with training-free backward guidance. ST-LDM encompasses a global-perceptual autoencoder with adaptable compression scales and hierarchical visual features, parallel with deformable multimodal transformer to generate region-wise guidance for the subsequent denoising process. We transcend the limitation of traditional attention mechanisms that only focus on existing visual features by introducing deformable feature alignment to hierarchically refine spatial positioning fused with multi-scale visual and linguistic information. Extensive Experiments demonstrate that our model enhances the localization of attention mechanisms while preserving the generative capabilities inherent to diffusion models.
Deep Learning-based Sentiment Analysis in Persian Language
Mar 17, 2024


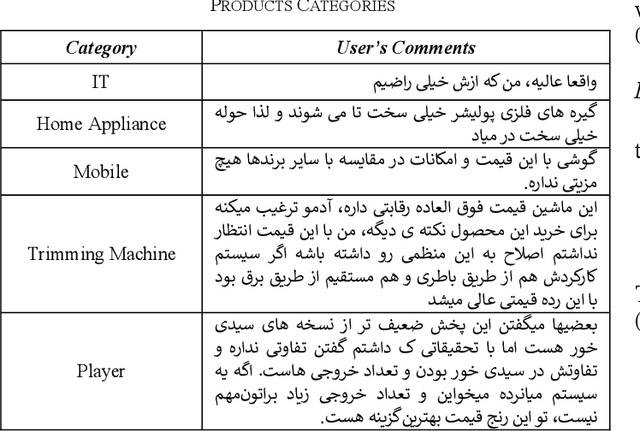
Recently, there has been a growing interest in the use of deep learning techniques for tasks in natural language processing (NLP), with sentiment analysis being one of the most challenging areas, particularly in the Persian language. The vast amounts of content generated by Persian users on thousands of websites, blogs, and social networks such as Telegram, Instagram, and Twitter present a rich resource of information. Deep learning techniques have become increasingly favored for extracting insights from this extensive pool of raw data, although they face several challenges. In this study, we introduced and implemented a hybrid deep learning-based model for sentiment analysis, using customer review data from the Digikala Online Retailer website. We employed a variety of deep learning networks and regularization techniques as classifiers. Ultimately, our hybrid approach yielded an impressive performance, achieving an F1 score of 78.3 across three sentiment categories: positive, negative, and neutral.
ECRC: Emotion-Causality Recognition in Korean Conversation for GCN
Mar 16, 2024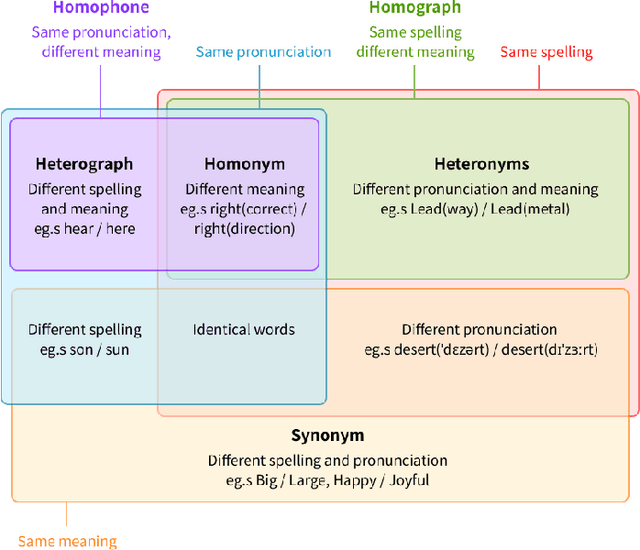
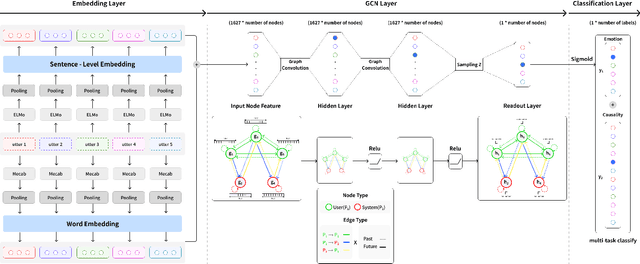
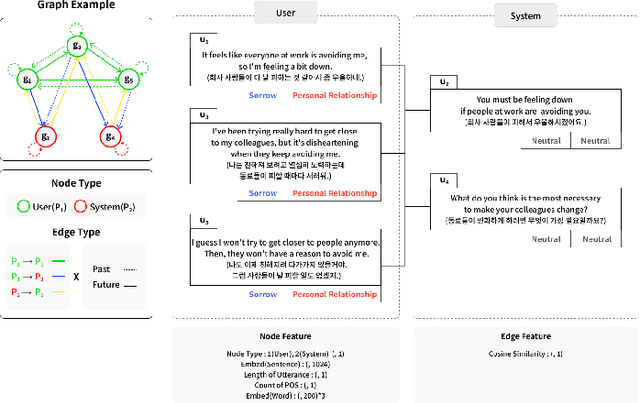
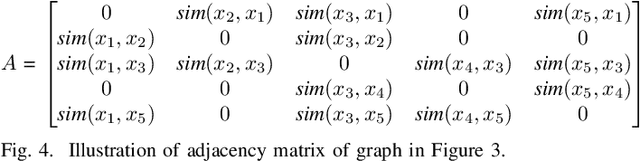
In this multi-task learning study on simultaneous analysis of emotions and their underlying causes in conversational contexts, deep neural network methods were employed to effectively process and train large labeled datasets. However, these approaches are typically limited to conducting context analyses across the entire corpus because they rely on one of the two methods: word- or sentence-level embedding. The former struggles with polysemy and homonyms, whereas the latter causes information loss when processing long sentences. In this study, we overcome the limitations of previous embeddings by utilizing both word- and sentence-level embeddings. Furthermore, we propose the emotion-causality recognition in conversation (ECRC) model, which is based on a novel graph structure, thereby leveraging the strengths of both embedding methods. This model uniquely integrates the bidirectional long short-term memory (Bi-LSTM) and graph neural network (GCN) models for Korean conversation analysis. Compared with models that rely solely on one embedding method, the proposed model effectively structures abstract concepts, such as language features and relationships, thereby minimizing information loss. To assess model performance, we compared the multi-task learning results of three deep neural network models with varying graph structures. Additionally, we evaluated the proposed model using Korean and English datasets. The experimental results show that the proposed model performs better in emotion and causality multi-task learning (74.62% and 75.30%, respectively) when node and edge characteristics are incorporated into the graph structure. Similar results were recorded for the Korean ECC and Wellness datasets (74.62% and 73.44%, respectively) with 71.35% on the IEMOCAP English dataset.
Refining Knowledge Transfer on Audio-Image Temporal Agreement for Audio-Text Cross Retrieval
Mar 16, 2024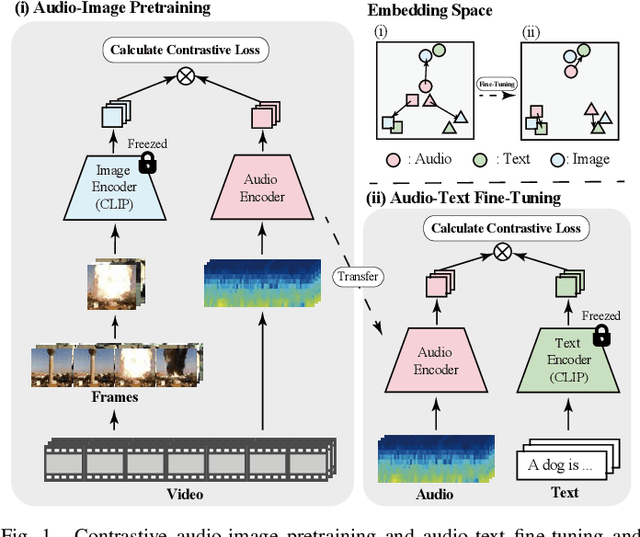
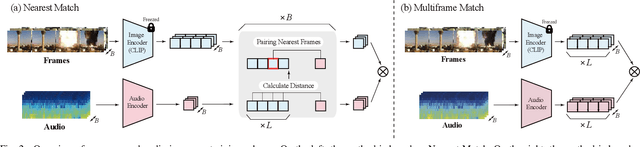
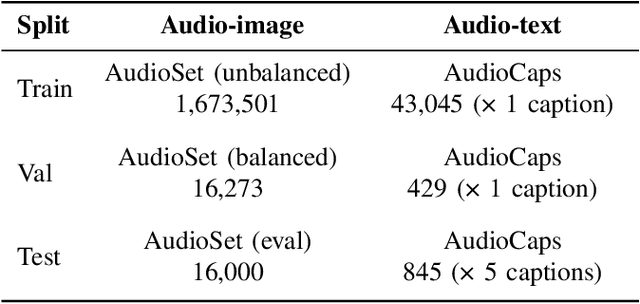
The aim of this research is to refine knowledge transfer on audio-image temporal agreement for audio-text cross retrieval. To address the limited availability of paired non-speech audio-text data, learning methods for transferring the knowledge acquired from a large amount of paired audio-image data to shared audio-text representation have been investigated, suggesting the importance of how audio-image co-occurrence is learned. Conventional approaches in audio-image learning assign a single image randomly selected from the corresponding video stream to the entire audio clip, assuming their co-occurrence. However, this method may not accurately capture the temporal agreement between the target audio and image because a single image can only represent a snapshot of a scene, though the target audio changes from moment to moment. To address this problem, we propose two methods for audio and image matching that effectively capture the temporal information: (i) Nearest Match wherein an image is selected from multiple time frames based on similarity with audio, and (ii) Multiframe Match wherein audio and image pairs of multiple time frames are used. Experimental results show that method (i) improves the audio-text retrieval performance by selecting the nearest image that aligns with the audio information and transferring the learned knowledge. Conversely, method (ii) improves the performance of audio-image retrieval while not showing significant improvements in audio-text retrieval performance. These results indicate that refining audio-image temporal agreement may contribute to better knowledge transfer to audio-text retrieval.