 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AMIGO: Sparse Multi-Modal Graph Transformer with Shared-Context Processing for Representation Learning of Giga-pixel Images
Mar 01, 2023
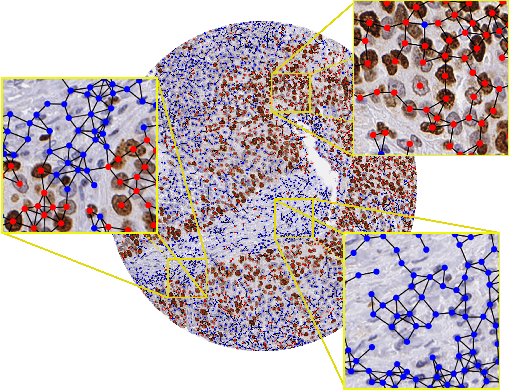
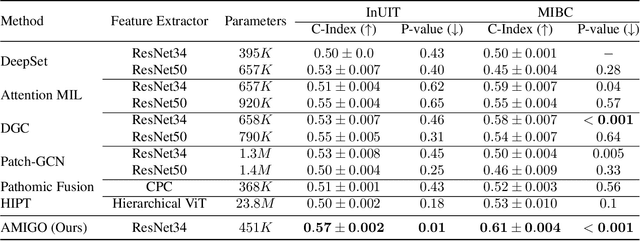
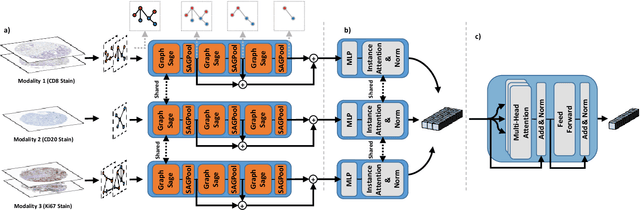
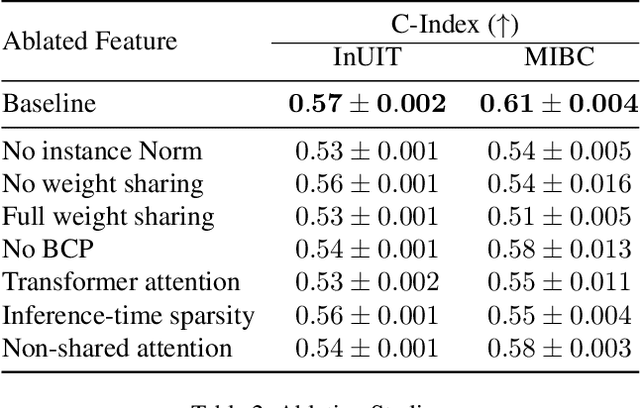
Processing giga-pixel whole slide histopathology images (WSI) is a computationally expensive task. Multiple instance learning (MIL) has become the conventional approach to process WSIs, in which these images are split into smaller patches for further processing. However, MIL-based techniques ignore explicit information about the individual cells within a patch. In this paper, by defining the novel concept of shared-context processing, we designed a multi-modal Graph Transformer (AMIGO) that uses the celluar graph within the tissue to provide a single representation for a patient while taking advantage of the hierarchical structure of the tissue, enabling a dynamic focus between cell-level and tissue-level information. We benchmarked the performance of our model against multiple state-of-the-art methods in survival prediction and showed that ours can significantly outperform all of them including hierarchical Vision Transformer (ViT). More importantly, we show that our model is strongly robust to missing information to an extent that it can achieve the same performance with as low as 20% of the data. Finally, in two different cancer datasets, we demonstrated that our model was able to stratify the patients into low-risk and high-risk groups while other state-of-the-art methods failed to achieve this goal. We also publish a large dataset of immunohistochemistry images (InUIT) containing 1,600 tissue microarray (TMA) cores from 188 patients along with their survival information, making it one of the largest publicly available datasets in this context.
Faster Learning of Temporal Action Proposal via Sparse Multilevel Boundary Generator
Mar 06, 2023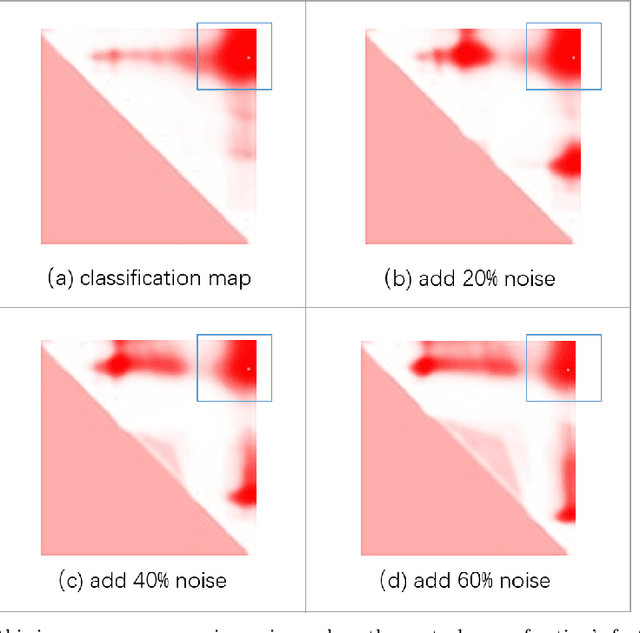
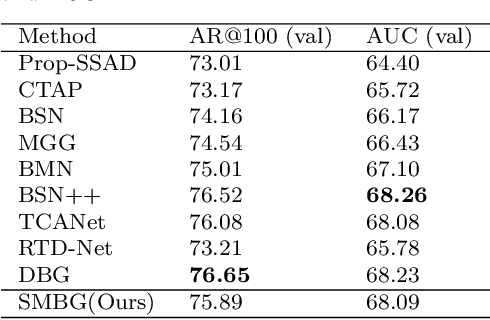
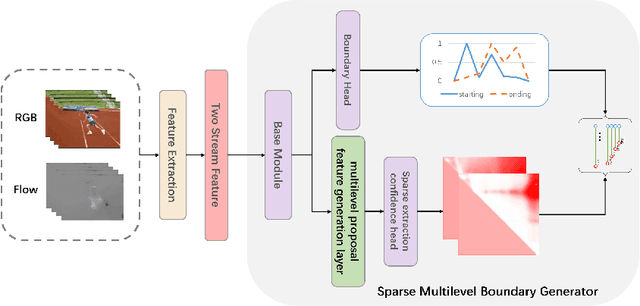
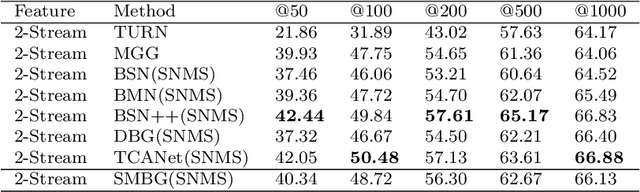
Temporal action localization in videos presents significant challenges in the field of computer vision. While the boundary-sensitive method has been widely adopted, its limitations include incomplete use of intermediate and global information, as well as an inefficient proposal feature generator. To address these challenges, we propose a novel framework, Sparse Multilevel Boundary Generator (SMBG), which enhances the boundary-sensitive method with boundary classification and action completeness regression. SMBG features a multi-level boundary module that enables faster processing by gathering boundary information at different lengths. Additionally, we introduce a sparse extraction confidence head that distinguishes information inside and outside the action, further optimizing the proposal feature generator. To improve the synergy between multiple branches and balance positive and negative samples, we propose a global guidance loss. Our method is evaluated on two popular benchmarks, ActivityNet-1.3 and THUMOS14, and is shown to achieve state-of-the-art performance, with a better inference speed (2.47xBSN++, 2.12xDBG). These results demonstrate that SMBG provides a more efficient and simple solution for generating temporal action proposals. Our proposed framework has the potential to advance the field of computer vision and enhance the accuracy and speed of temporal action localization in video analysis.The code and models are made available at \url{https://github.com/zhouyang-001/SMBG-for-temporal-action-proposal}.
2D Floor Plan Segmentation Based on Down-sampling
Mar 24, 2023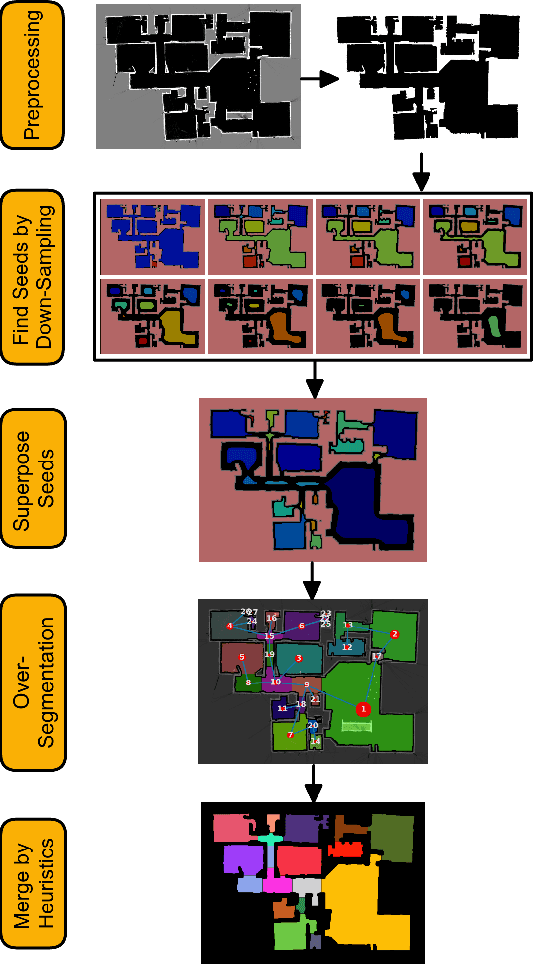
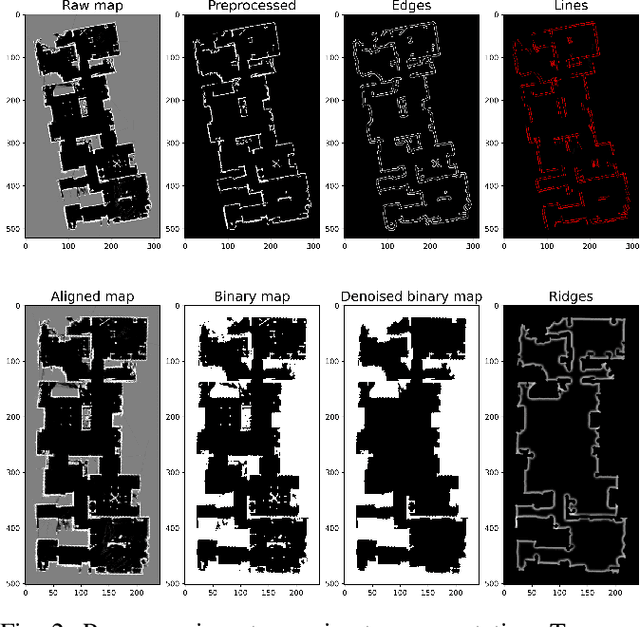
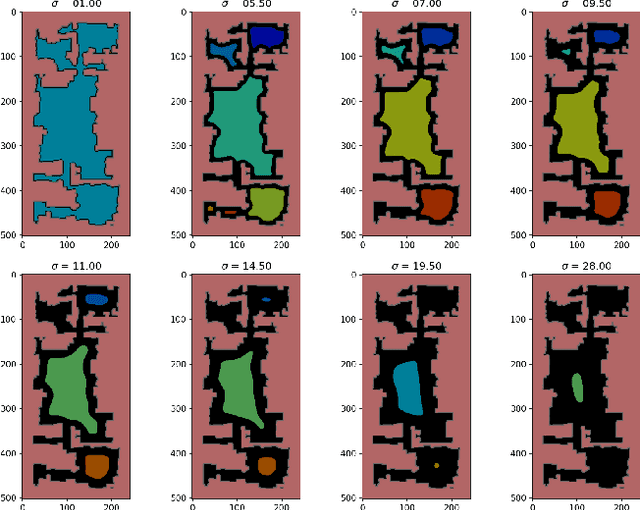
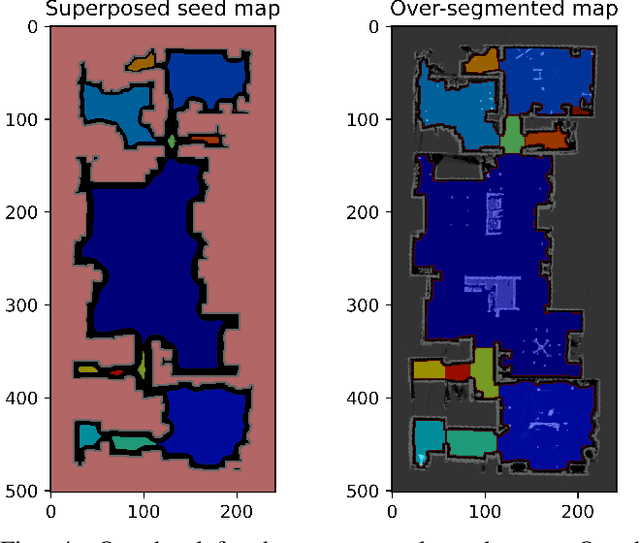
In recent years, floor plan segmentation has gained significant attention due to its wide range of applications in floor plan reconstruction and robotics. In this paper, we propose a novel 2D floor plan segmentation technique based on a down-sampling approach. Our method employs continuous down-sampling on a floor plan to maintain its structural information while reducing its complexity. We demonstrate the effectiveness of our approach by presenting results obtained from both cluttered floor plans generated by a vacuum cleaning robot in unknown environments and a benchmark of floor plans. Our technique considerably reduces the computational and implementation complexity of floor plan segmentation, making it more suitable for real-world applications. Additionally, we discuss the appropriate metric for evaluating segmentation results. Overall, our approach yields promising results for 2D floor plan segmentation in cluttered environments.
Hybrid Augmented Automated Graph Contrastive Learning
Mar 24, 2023
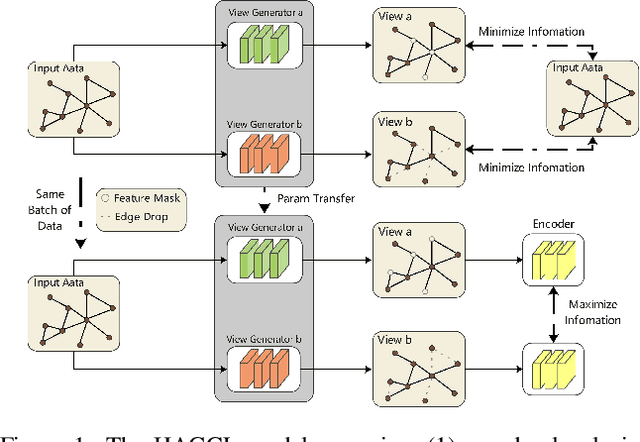
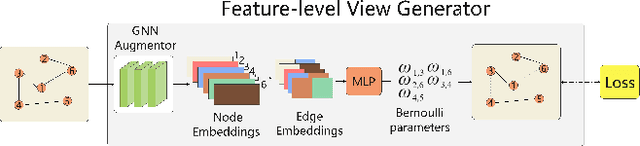
Graph augmentations are essential for graph contrastive learning. Most existing works use pre-defined random augmentations, which are usually unable to adapt to different input graphs and fail to consider the impact of different nodes and edges on graph semantics. To address this issue, we propose a framework called Hybrid Augmented Automated Graph Contrastive Learning (HAGCL). HAGCL consists of a feature-level learnable view generator and an edge-level learnable view generator. The view generators are end-to-end differentiable to learn the probability distribution of views conditioned on the input graph. It insures to learn the most semantically meaningful structure in terms of features and topology, respectively. Furthermore, we propose an improved joint training strategy, which can achieve better results than previous works without resorting to any weak label information in the downstream tasks and extensive evaluation of additional work.
Pedestrain detection for low-light vision proposal
Mar 17, 2023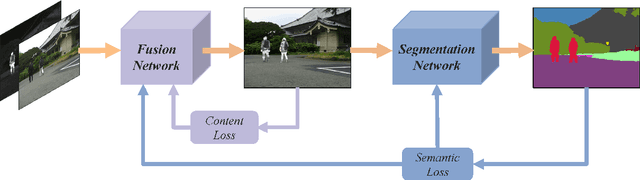
The demand for pedestrian detection has created a challenging problem for various visual tasks such as image fusion. As infrared images can capture thermal radiation information, image fusion between infrared and visible images could significantly improve target detection under environmental limitations. In our project, we would approach by preprocessing our dataset with image fusion technique, then using Vision Transformer model to detect pedestrians from the fused images. During the evaluation procedure, a comparison would be made between YOLOv5 and the revised ViT model performance on our fused images
Diffusion Models for Contrast Harmonization of Magnetic Resonance Images
Mar 14, 2023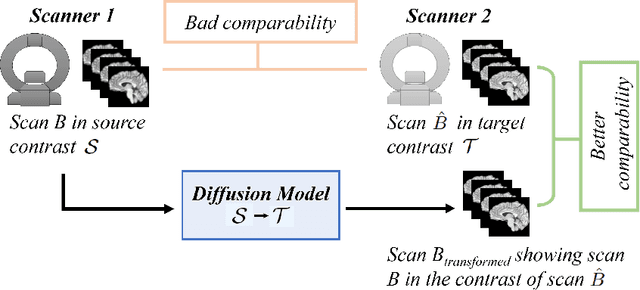
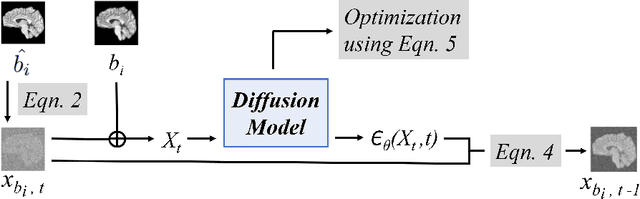
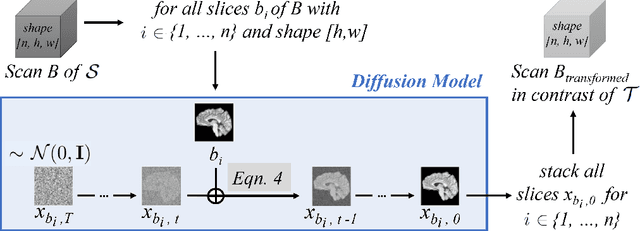

Magnetic resonance (MR) images from multiple sources often show differences in image contrast related to acquisition settings or the used scanner type. For long-term studies, longitudinal comparability is essential but can be impaired by these contrast differences, leading to biased results when using automated evaluation tools. This study presents a diffusion model-based approach for contrast harmonization. We use a data set consisting of scans of 18 Multiple Sclerosis patients and 22 healthy controls. Each subject was scanned in two MR scanners of different magnetic field strengths (1.5 T and 3 T), resulting in a paired data set that shows scanner-inherent differences. We map images from the source contrast to the target contrast for both directions, from 3 T to 1.5 T and from 1.5 T to 3 T. As we only want to change the contrast, not the anatomical information, our method uses the original image to guide the image-to-image translation process by adding structural information. The aim is that the mapped scans display increased comparability with scans of the target contrast for downstream tasks. We evaluate this method for the task of segmentation of cerebrospinal fluid, grey matter and white matter. Our method achieves good and consistent results for both directions of the mapping.
Updated version: A Video Anomaly Detection Framework based on Appearance-Motion Semantics Representation Consistency
Mar 09, 2023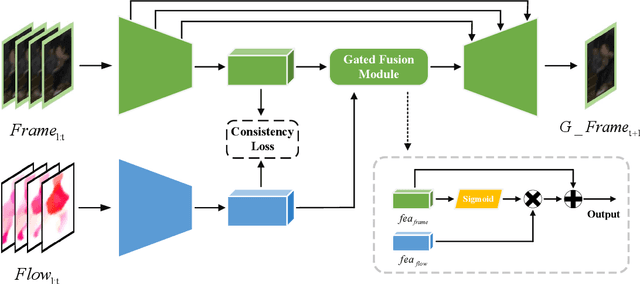
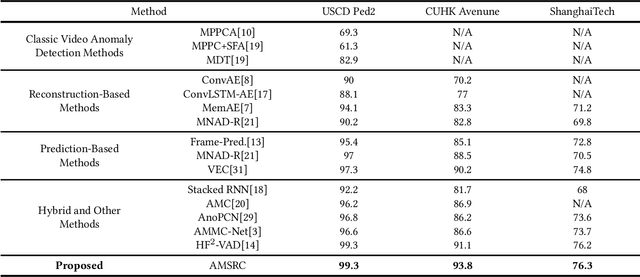
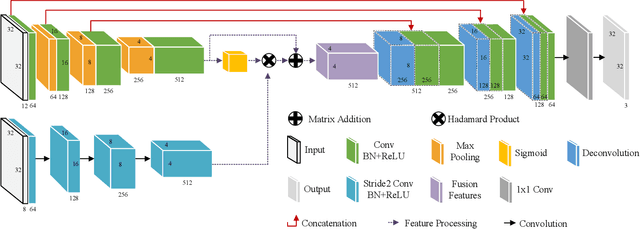
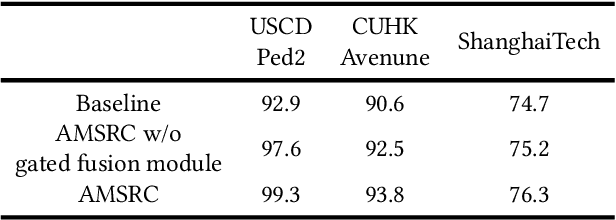
Video anomaly detection is an essential but challenging task. The prevalent methods mainly investigate the reconstruction difference between normal and abnormal patterns but ignore the semantics consistency between appearance and motion information of behavior patterns, making the results highly dependent on the local context of frame sequences and lacking the understanding of behavior semantics. To address this issue, we propose a framework of Appearance-Motion Semantics Representation Consistency that uses the gap of appearance and motion semantic representation consistency between normal and abnormal data. The two-stream structure is designed to encode the appearance and motion information representation of normal samples, and a novel consistency loss is proposed to enhance the consistency of feature semantics so that anomalies with low consistency can be identified. Moreover, the lower consistency features of anomalies can be used to deteriorate the quality of the predicted frame, which makes anomalies easier to spot. Experimental results demonstrate the effectiveness of the proposed method.
Diversity-Measurable Anomaly Detection
Mar 09, 2023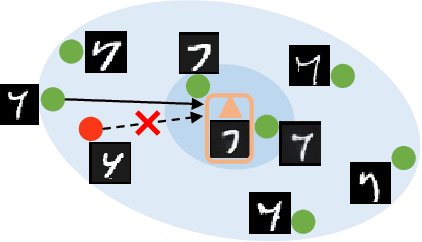


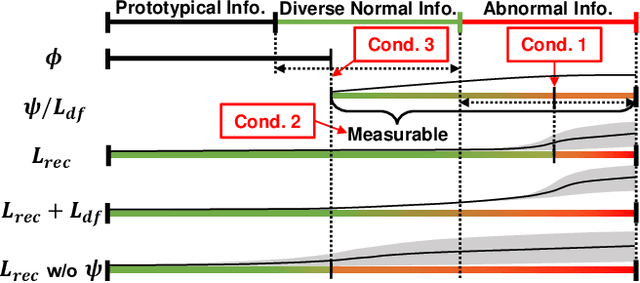
Reconstruction-based anomaly detection models achieve their purpose by suppressing the generalization ability for anomaly. However, diverse normal patterns are consequently not well reconstructed as well. Although some efforts have been made to alleviate this problem by modeling sample diversity, they suffer from shortcut learning due to undesired transmission of abnormal information. In this paper, to better handle the tradeoff problem, we propose Diversity-Measurable Anomaly Detection (DMAD) framework to enhance reconstruction diversity while avoid the undesired generalization on anomalies. To this end, we design Pyramid Deformation Module (PDM), which models diverse normals and measures the severity of anomaly by estimating multi-scale deformation fields from reconstructed reference to original input. Integrated with an information compression module, PDM essentially decouples deformation from prototypical embedding and makes the final anomaly score more reliable. Experimental results on both surveillance videos and industrial images demonstrate the effectiveness of our method. In addition, DMAD works equally well in front of contaminated data and anomaly-like normal samples.
PrefGen: Preference Guided Image Generation with Relative Attributes
Apr 01, 2023

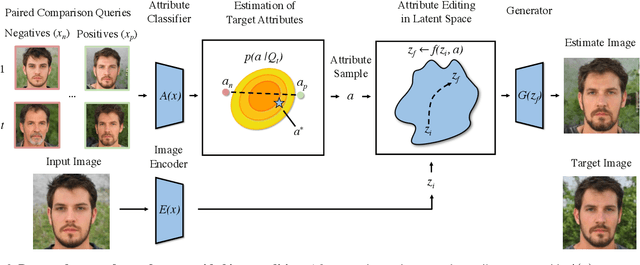
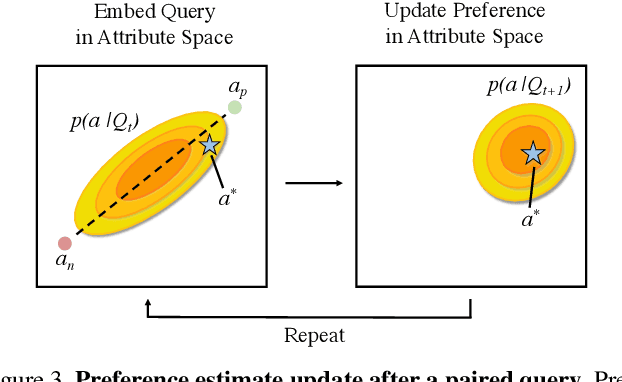
Deep generative models have the capacity to render high fidelity images of content like human faces. Recently, there has been substantial progress in conditionally generating images with specific quantitative attributes, like the emotion conveyed by one's face. These methods typically require a user to explicitly quantify the desired intensity of a visual attribute. A limitation of this method is that many attributes, like how "angry" a human face looks, are difficult for a user to precisely quantify. However, a user would be able to reliably say which of two faces seems "angrier". Following this premise, we develop the $\textit{PrefGen}$ system, which allows users to control the relative attributes of generated images by presenting them with simple paired comparison queries of the form "do you prefer image $a$ or image $b$?" Using information from a sequence of query responses, we can estimate user preferences over a set of image attributes and perform preference-guided image editing and generation. Furthermore, to make preference localization feasible and efficient, we apply an active query selection strategy. We demonstrate the success of this approach using a StyleGAN2 generator on the task of human face editing. Additionally, we demonstrate how our approach can be combined with CLIP, allowing a user to edit the relative intensity of attributes specified by text prompts. Code at https://github.com/helblazer811/PrefGen.
Where did you tweet from? Inferring the origin locations of tweets based on contextual information
Nov 18, 2022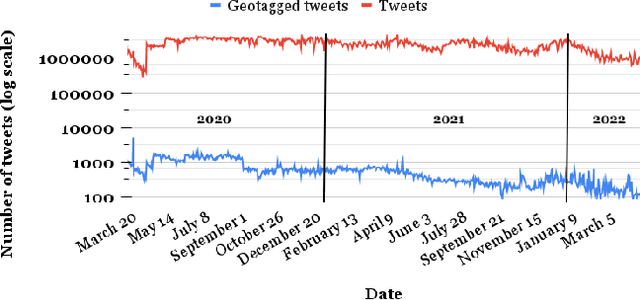
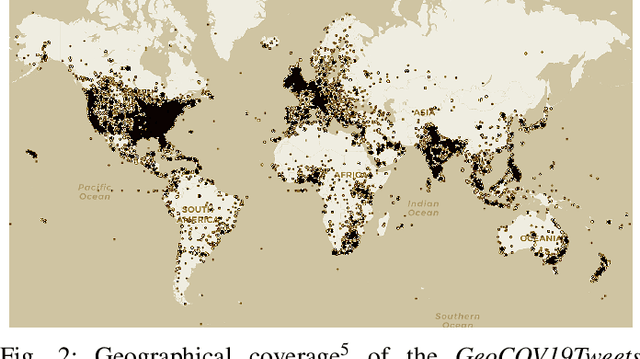
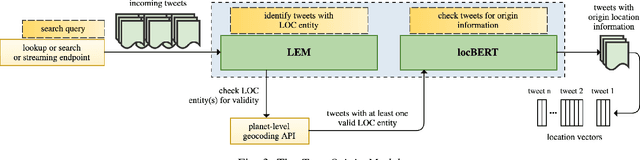
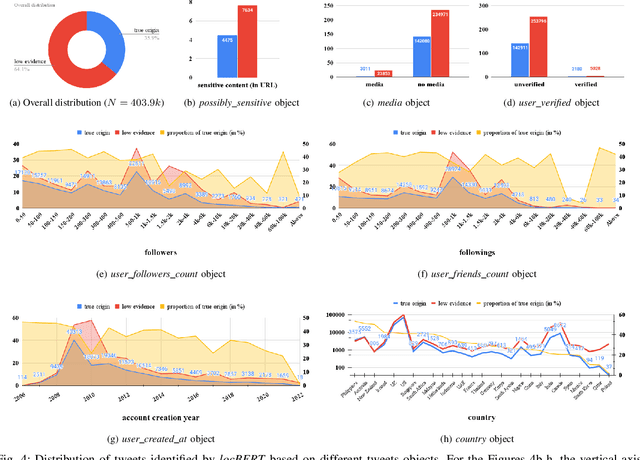
Public conversations on Twitter comprise many pertinent topics including disasters, protests, politics, propaganda, sports, climate change, epidemics/pandemic outbreaks, etc., that can have both regional and global aspects. Spatial discourse analysis rely on geographical data. However, today less than 1% of tweets are geotagged; in both cases--point location or bounding place information. A major issue with tweets is that Twitter users can be at location A and exchange conversations specific to location B, which we call the Location A/B problem. The problem is considered solved if location entities can be classified as either origin locations (Location As) or non-origin locations (Location Bs). In this work, we propose a simple yet effective framework--the True Origin Model--to address the problem that uses machine-level natural language understanding to identify tweets that conceivably contain their origin location information. The model achieves promising accuracy at country (80%), state (67%), city (58%), county (56%) and district (64%) levels with support from a Location Extraction Model as basic as the CoNLL-2003-based RoBERTa. We employ a tweet contexualizer (locBERT) which is one of the core components of the proposed model, to investigate multiple tweets' distributions for understanding Twitter users' tweeting behavior in terms of mentioning origin and non-origin locations. We also highlight a major concern with the currently regarded gold standard test set (ground truth) methodology, introduce a new data set, and identify further research avenues for advancing the area.