 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Xformer: Hybrid X-Shaped Transformer for Image Denoising
Mar 11, 2023
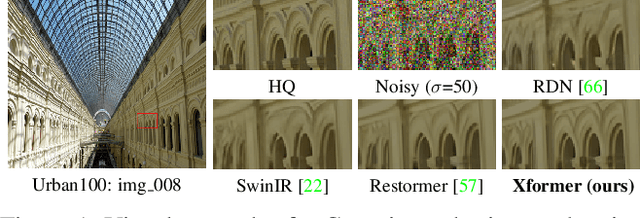
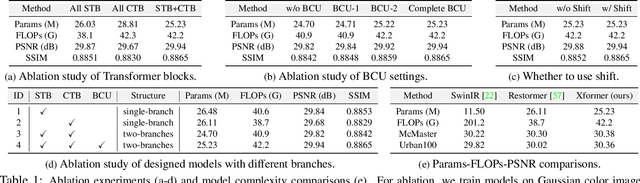
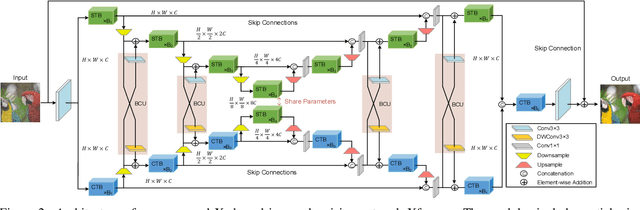
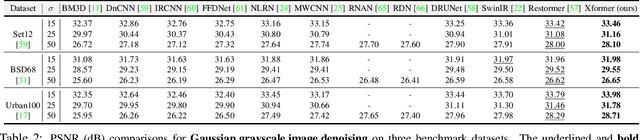
In this paper, we present a hybrid X-shaped vision Transformer, named Xformer, which performs notably on image denoising tasks. We explore strengthening the global representation of tokens from different scopes. In detail, we adopt two types of Transformer blocks. The spatial-wise Transformer block performs fine-grained local patches interactions across tokens defined by spatial dimension. The channel-wise Transformer block performs direct global context interactions across tokens defined by channel dimension. Based on the concurrent network structure, we design two branches to conduct these two interaction fashions. Within each branch, we employ an encoder-decoder architecture to capture multi-scale features. Besides, we propose the Bidirectional Connection Unit (BCU) to couple the learned representations from these two branches while providing enhanced information fusion. The joint designs make our Xformer powerful to conduct global information modeling in both spatial and channel dimensions. Extensive experiments show that Xformer, under the comparable model complexity, achieves state-of-the-art performance on the synthetic and real-world image denoising tasks.
Multi-Context Interaction Network for Few-Shot Segmentation
Mar 11, 2023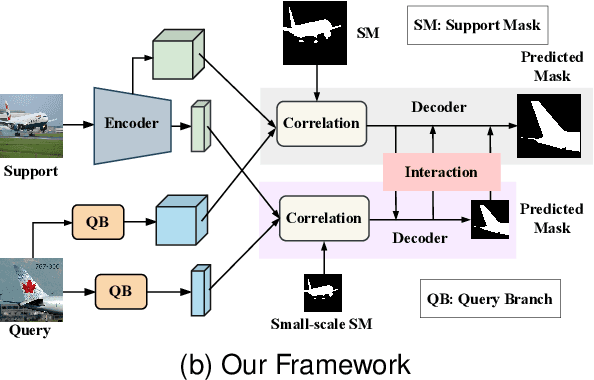
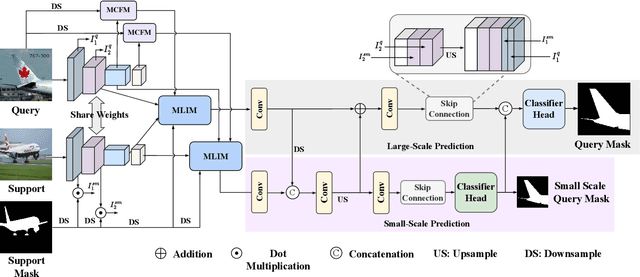
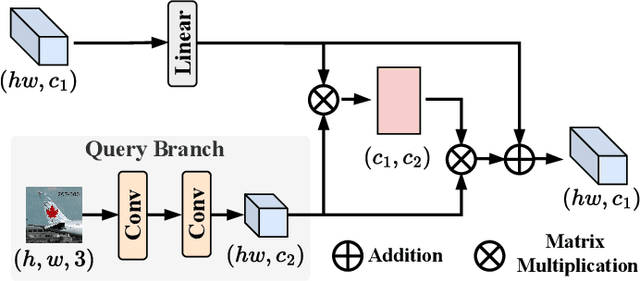
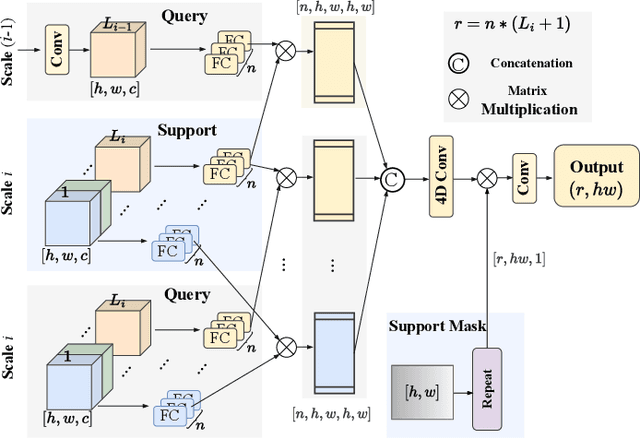
Few-Shot Segmentation (FSS) is challenging for limited support images and large intra-class appearance discrepancies. Due to the huge difference between support and query samples, most existing approaches focus on extracting high-level representations of the same layers for support-query correlations but neglect the shift issue between different layers and scales. In this paper, we propose a Multi-Context Interaction Network (MCINet) to remedy this issue by fully exploiting and interacting with the multi-scale contextual information contained in the support-query pairs. Specifically, MCINet improves FSS from the perspectives of boosting the query representations by incorporating the low-level structural information from another query branch into the high-level semantic features, enhancing the support-query correlations by exploiting both the same-layer and adjacent-layer features, and refining the predicted results by a multi-scale mask prediction strategy, with which the different scale contents have bidirectionally interacted. Experiments on two benchmarks demonstrate that our approach reaches SOTA performances and outperforms the best competitors with many desirable advantages, especially on the challenging COCO dataset.
MetaViewer: Towards A Unified Multi-View Representation
Mar 11, 2023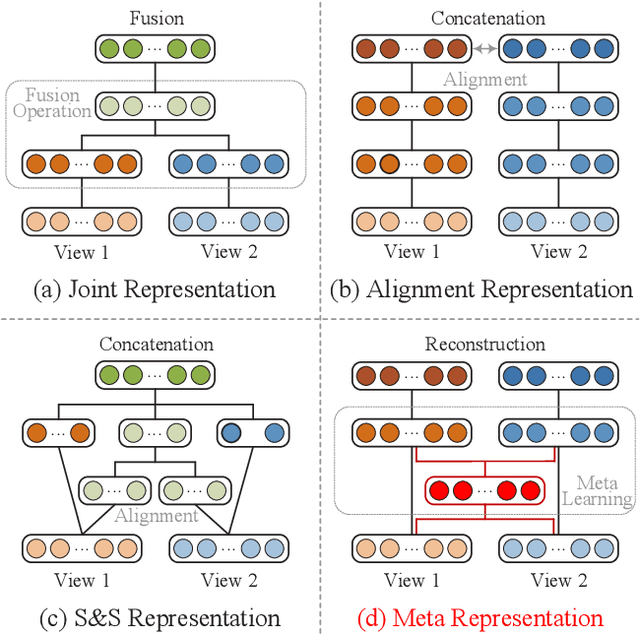
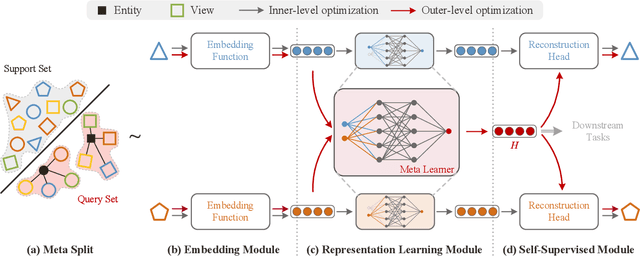
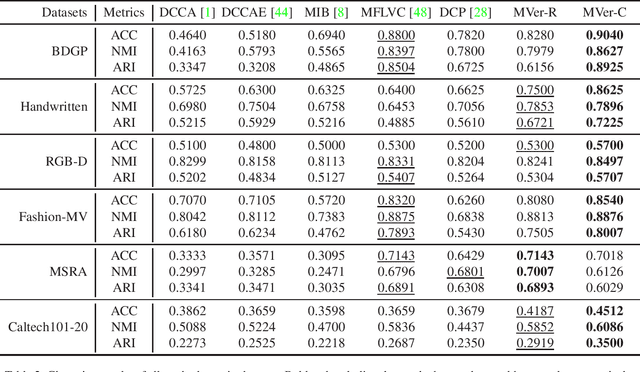
Existing multi-view representation learning methods typically follow a specific-to-uniform pipeline, extracting latent features from each view and then fusing or aligning them to obtain the unified object representation. However, the manually pre-specify fusion functions and view-private redundant information mixed in features potentially degrade the quality of the derived representation. To overcome them, we propose a novel bi-level-optimization-based multi-view learning framework, where the representation is learned in a uniform-to-specific manner. Specifically, we train a meta-learner, namely MetaViewer, to learn fusion and model the view-shared meta representation in outer-level optimization. Start with this meta representation, view-specific base-learners are then required to rapidly reconstruct the corresponding view in inner-level. MetaViewer eventually updates by observing reconstruction processes from uniform to specific over all views, and learns an optimal fusion scheme that separates and filters out view-private information. Extensive experimental results in downstream tasks such as classification and clustering demonstrate the effectiveness of our method.
Inverse Reinforcement Learning without Reinforcement Learning
Mar 26, 2023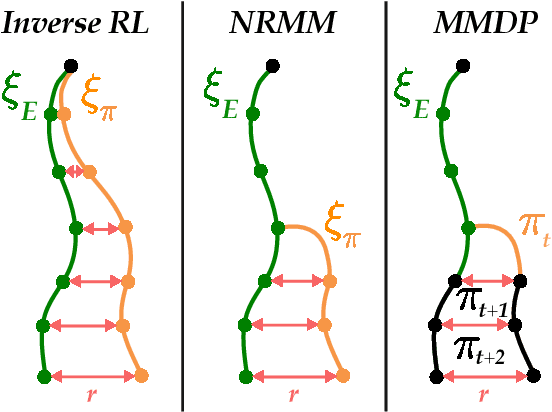
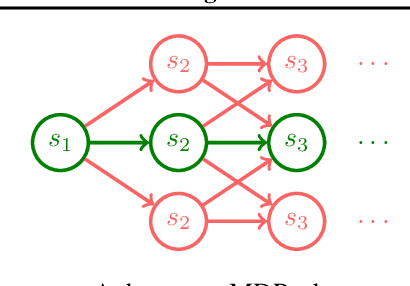
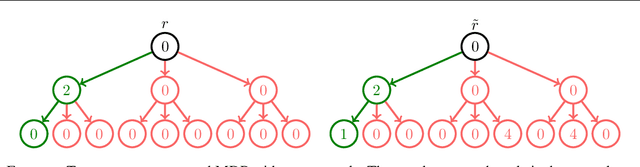
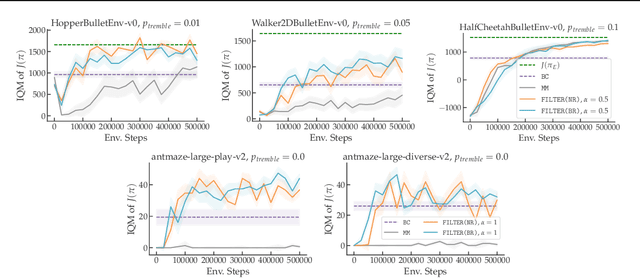
Inverse Reinforcement Learning (IRL) is a powerful set of techniques for imitation learning that aims to learn a reward function that rationalizes expert demonstrations. Unfortunately, traditional IRL methods suffer from a computational weakness: they require repeatedly solving a hard reinforcement learning (RL) problem as a subroutine. This is counter-intuitive from the viewpoint of reductions: we have reduced the easier problem of imitation learning to repeatedly solving the harder problem of RL. Another thread of work has proved that access to the side-information of the distribution of states where a strong policy spends time can dramatically reduce the sample and computational complexities of solving an RL problem. In this work, we demonstrate for the first time a more informed imitation learning reduction where we utilize the state distribution of the expert to alleviate the global exploration component of the RL subroutine, providing an exponential speedup in theory. In practice, we find that we are able to significantly speed up the prior art on continuous control tasks.
Attention-based Learning for Sleep Apnea and Limb Movement Detection using Wi-Fi CSI Signals
Mar 26, 2023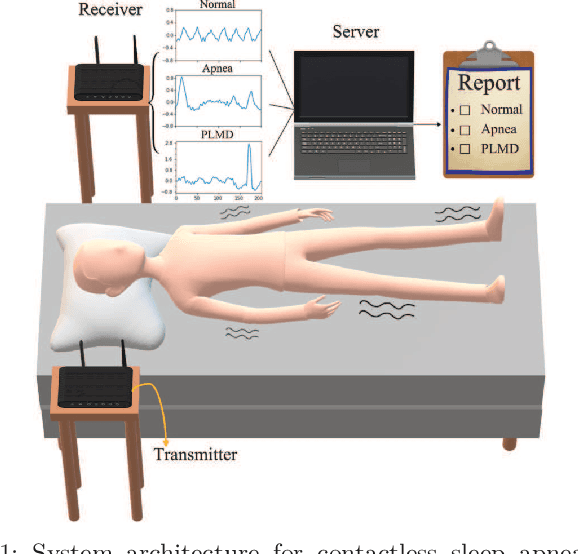
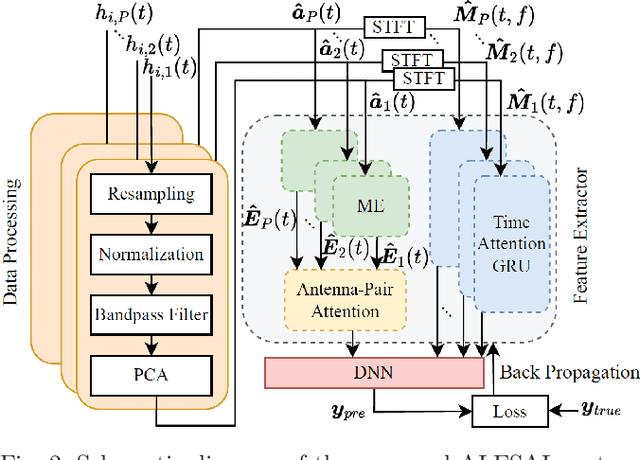
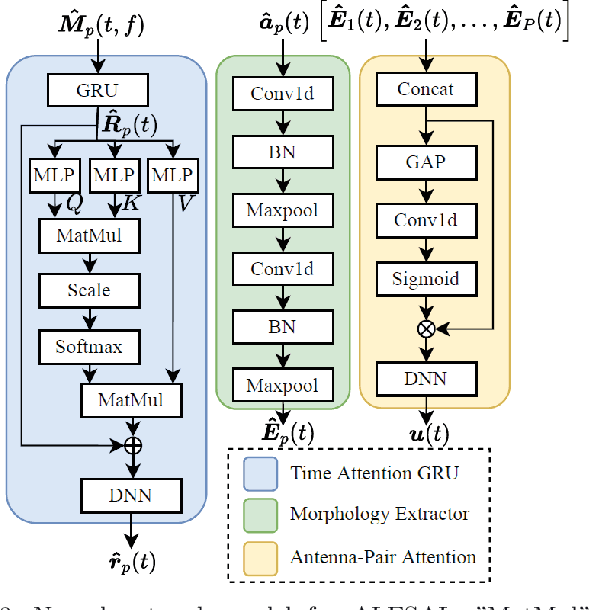
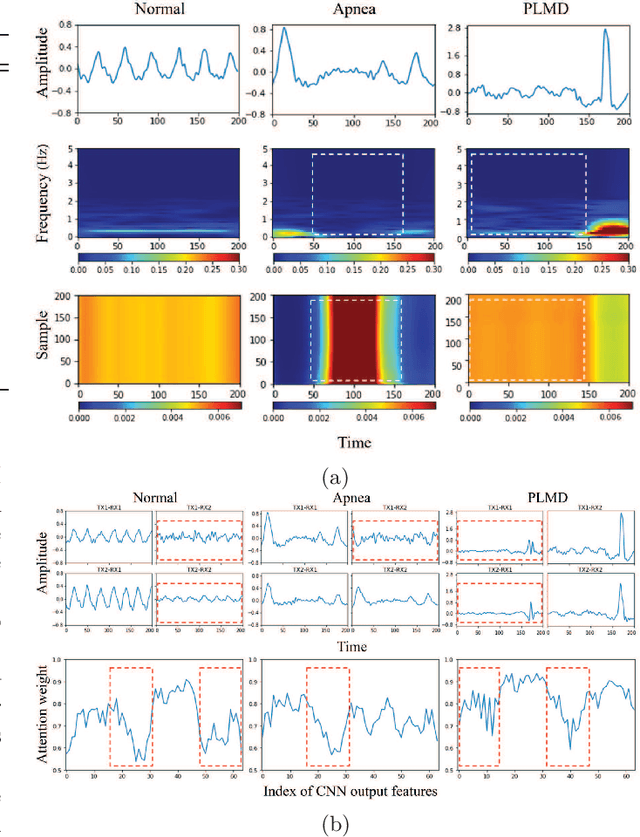
Wi-Fi channel state information (CSI) has become a promising solution for non-invasive breathing and body motion monitoring during sleep. Sleep disorders of apnea and periodic limb movement disorder (PLMD) are often unconscious and fatal. The existing researches detect abnormal sleep disorders in impractically controlled environments. Moreover, it leads to compelling challenges to classify complex macro- and micro-scales of sleep movements as well as entangled similar waveforms of cases of apnea and PLMD. In this paper, we propose the attention-based learning for sleep apnea and limb movement detection (ALESAL) system that can jointly detect sleep apnea and PLMD under different sleep postures across a variety of patients. ALESAL contains antenna-pair and time attention mechanisms for mitigating the impact of modest antenna pairs and emphasizing the duration of interest, respectively. Performance results show that our proposed ALESAL system can achieve a weighted F1-score of 84.33, outperforming the other existing non-attention based methods of support vector machine and deep multilayer perceptron.
Generalization with quantum geometry for learning unitaries
Mar 23, 2023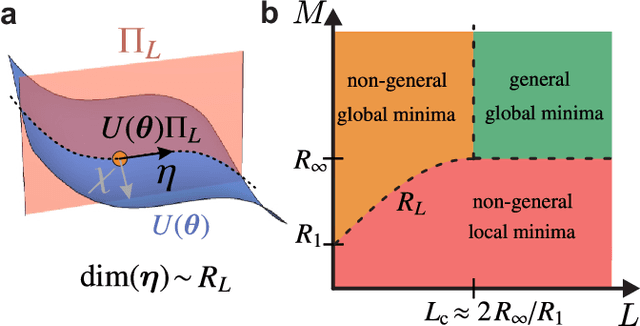
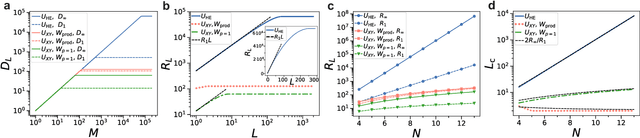
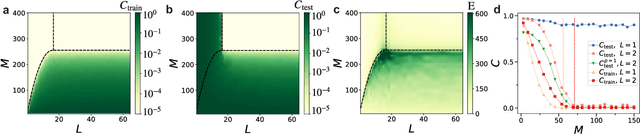
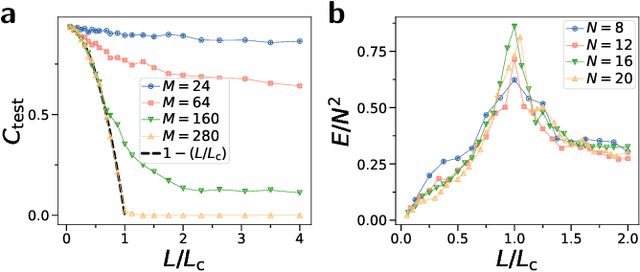
Generalization is the ability of quantum machine learning models to make accurate predictions on new data by learning from training data. Here, we introduce the data quantum Fisher information metric (DQFIM) to determine when a model can generalize. For variational learning of unitaries, the DQFIM quantifies the amount of circuit parameters and training data needed to successfully train and generalize. We apply the DQFIM to explain when a constant number of training states and polynomial number of parameters are sufficient for generalization. Further, we can improve generalization by removing symmetries from training data. Finally, we show that out-of-distribution generalization, where training and testing data are drawn from different data distributions, can be better than using the same distribution. Our work opens up new approaches to improve generalization in quantum machine learning.
Skip Connections in Spiking Neural Networks: An Analysis of Their Effect on Network Training
Mar 23, 2023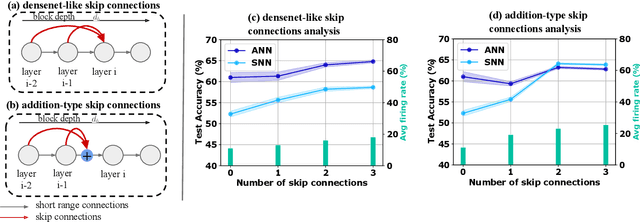

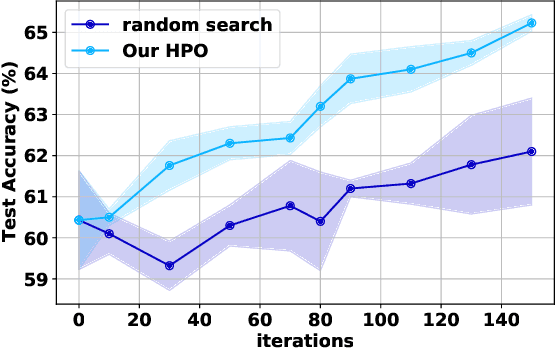
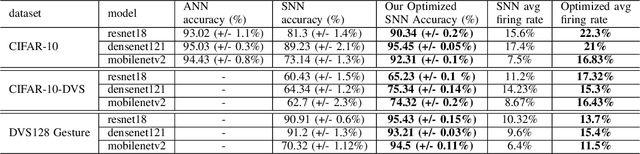
Spiking neural networks (SNNs) have gained attention as a promising alternative to traditional artificial neural networks (ANNs) due to their potential for energy efficiency and their ability to model spiking behavior in biological systems. However, the training of SNNs is still a challenging problem, and new techniques are needed to improve their performance. In this paper, we study the impact of skip connections on SNNs and propose a hyperparameter optimization technique that adapts models from ANN to SNN. We demonstrate that optimizing the position, type, and number of skip connections can significantly improve the accuracy and efficiency of SNNs by enabling faster convergence and increasing information flow through the network. Our results show an average +8% accuracy increase on CIFAR-10-DVS and DVS128 Gesture datasets adaptation of multiple state-of-the-art models.
Regret Bounds for Learning Decentralized Linear Quadratic Regulator with Partially Nested Information Structure
Oct 17, 2022
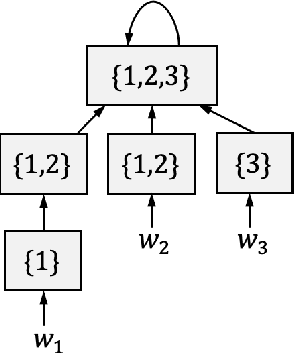
We study the problem of learning decentralized linear quadratic regulator under a partially nested information constraint, when the system model is unknown a priori. We propose an online learning algorithm that adaptively designs a control policy as new data samples from a single system trajectory become available. Our algorithm design uses a disturbance-feedback representation of state-feedback controllers coupled with online convex optimization with memory and delayed feedback. We show that our online algorithm yields a controller that satisfies the desired information constraint and enjoys an expected regret that scales as $\sqrt{T}$ with the time horizon $T$.
Lecture Notes on Neural Information Retrieval
Jul 27, 2022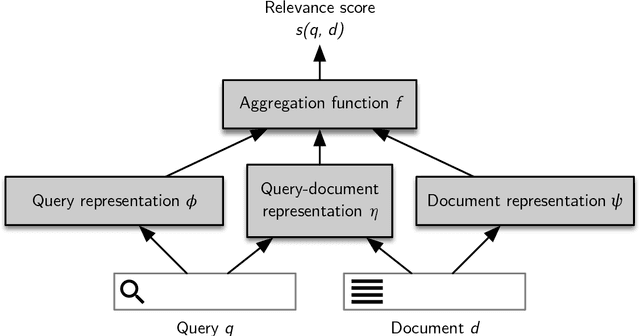
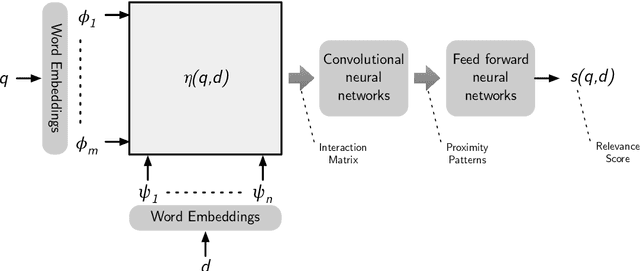

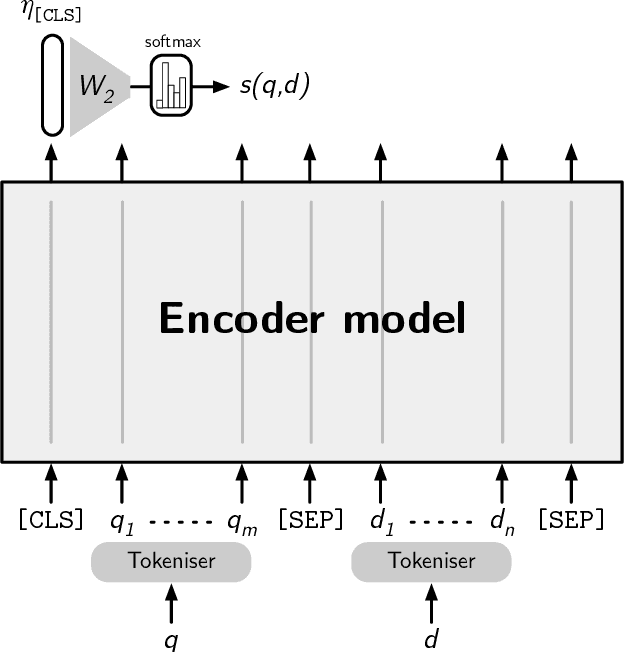
These lecture notes focus on the recent advancements in neural information retrieval, with particular emphasis on the systems and models exploiting transformer networks. These networks, originally proposed by Google in 2017, have seen a large success in many natural language processing and information retrieval tasks. While there are many fantastic textbook on information retrieval and natural language processing as well as specialised books for a more advanced audience, these lecture notes target people aiming at developing a basic understanding of the main information retrieval techniques and approaches based on deep learning. These notes have been prepared for a IR graduate course of the MSc program in Artificial Intelligence and Data Engineering at the University of Pisa, Italy.
Graph Construction using Principal Axis Trees for Simple Graph Convolution
Mar 01, 2023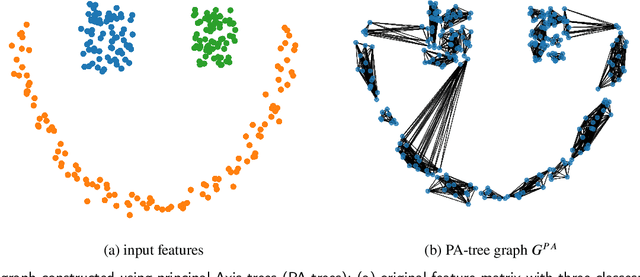


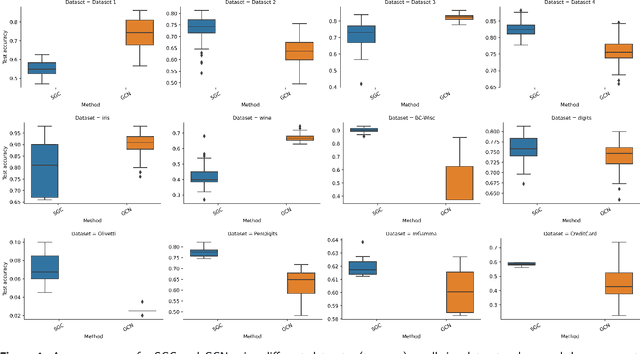
Graph Neural Networks (GNNs) are increasingly becoming the favorite method for graph learning. They exploit the semi-supervised nature of deep learning, and they bypass computational bottlenecks associated with traditional graph learning methods. In addition to the feature matrix $X$, GNNs need an adjacency matrix $A$ to perform feature propagation. In many cases the adjacency matrix $A$ is missing. We introduce a graph construction scheme that construct the adjacency matrix $A$ using unsupervised and supervised information. Unsupervised information characterize the neighborhood around points. We used Principal Axis trees (PA-trees) as a source of unsupervised information, where we create edges between points falling onto the same leaf node. For supervised information, we used the concept of penalty and intrinsic graphs. A penalty graph connects points with different class labels, whereas intrinsic graph connects points with the same class label. We used the penalty and intrinsic graphs to remove or add edges to the graph constructed via PA-tree. This graph construction scheme was tested on two well-known GNNs: 1) Graph Convolutional Network (GCN) and 2) Simple Graph Convolution (SGC). The experiments show that it is better to use SGC because it is faster and delivers better or the same results as GCN. We also test the effect of oversmoothing on both GCN and SGC. We found out that the level of smoothing has to be selected carefully for SGC to avoid oversmoothing.