 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Do We Really Need Complicated Model Architectures For Temporal Networks?
Feb 22, 2023
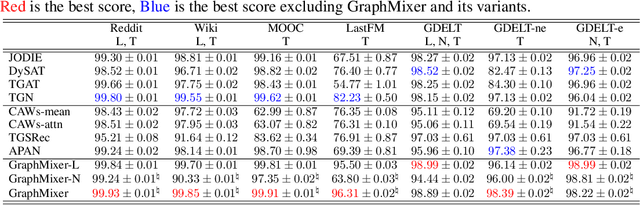
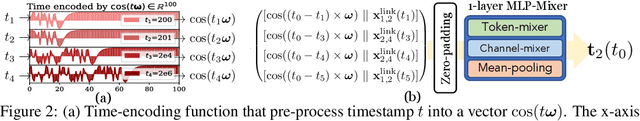

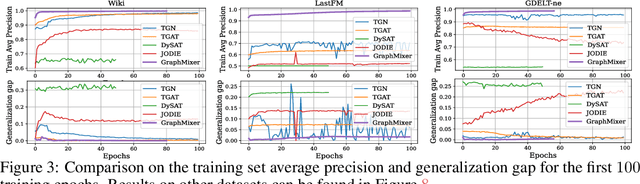
Recurrent neural network (RNN) and self-attention mechanism (SAM) are the de facto methods to extract spatial-temporal information for temporal graph learning. Interestingly, we found that although both RNN and SAM could lead to a good performance, in practice neither of them is always necessary. In this paper, we propose GraphMixer, a conceptually and technically simple architecture that consists of three components: (1) a link-encoder that is only based on multi-layer perceptrons (MLP) to summarize the information from temporal links, (2) a node-encoder that is only based on neighbor mean-pooling to summarize node information, and (3) an MLP-based link classifier that performs link prediction based on the outputs of the encoders. Despite its simplicity, GraphMixer attains an outstanding performance on temporal link prediction benchmarks with faster convergence and better generalization performance. These results motivate us to rethink the importance of simpler model architecture.
Domain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023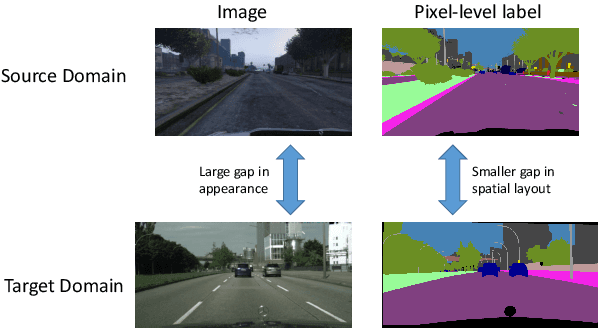
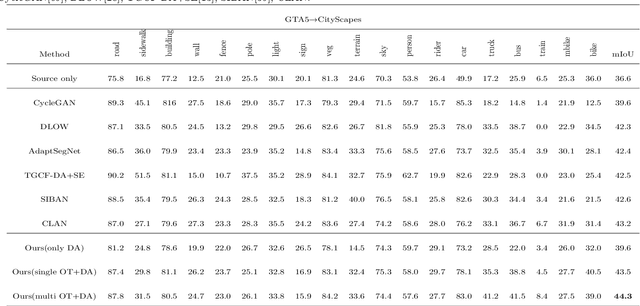
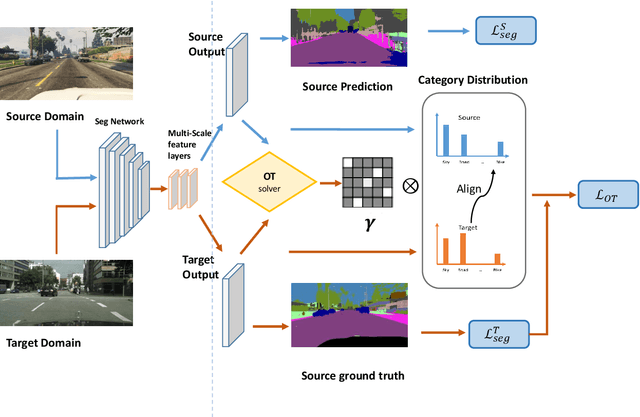
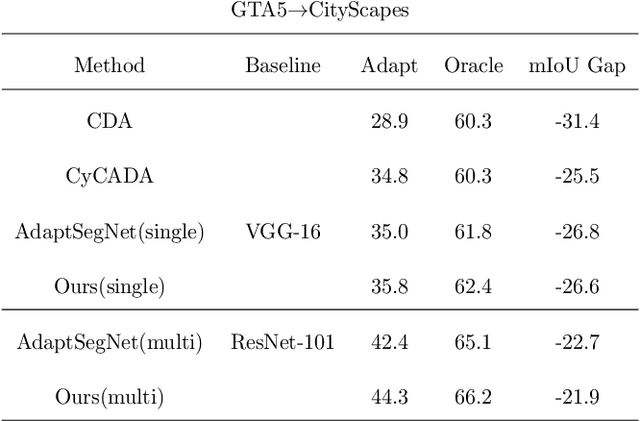
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.
Does Sparsity Help in Learning Misspecified Linear Bandits?
Mar 29, 2023Recently, the study of linear misspecified bandits has generated intriguing implications of the hardness of learning in bandits and reinforcement learning (RL). In particular, Du et al. (2020) show that even if a learner is given linear features in $\mathbb{R}^d$ that approximate the rewards in a bandit or RL with a uniform error of $\varepsilon$, searching for an $O(\varepsilon)$-optimal action requires pulling at least $\Omega(\exp(d))$ queries. Furthermore, Lattimore et al. (2020) show that a degraded $O(\varepsilon\sqrt{d})$-optimal solution can be learned within $\operatorname{poly}(d/\varepsilon)$ queries. Yet it is unknown whether a structural assumption on the ground-truth parameter, such as sparsity, could break the $\varepsilon\sqrt{d}$ barrier. In this paper, we address this question by showing that algorithms can obtain $O(\varepsilon)$-optimal actions by querying $O(\varepsilon^{-s}d^s)$ actions, where $s$ is the sparsity parameter, removing the $\exp(d)$-dependence. We then establish information-theoretical lower bounds, i.e., $\Omega(\exp(s))$, to show that our upper bound on sample complexity is nearly tight if one demands an error $ O(s^{\delta}\varepsilon)$ for $0<\delta<1$. For $\delta\geq 1$, we further show that $\operatorname{poly}(s/\varepsilon)$ queries are possible when the linear features are "good" and even in general settings. These results provide a nearly complete picture of how sparsity can help in misspecified bandit learning and provide a deeper understanding of when linear features are "useful" for bandit and reinforcement learning with misspecification.
Are Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023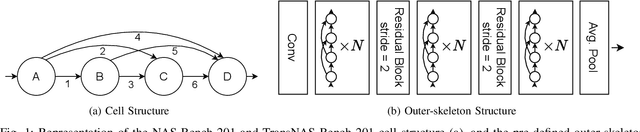

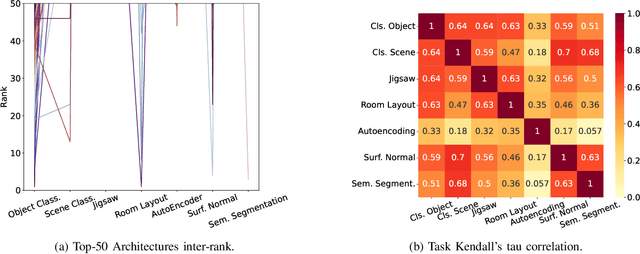
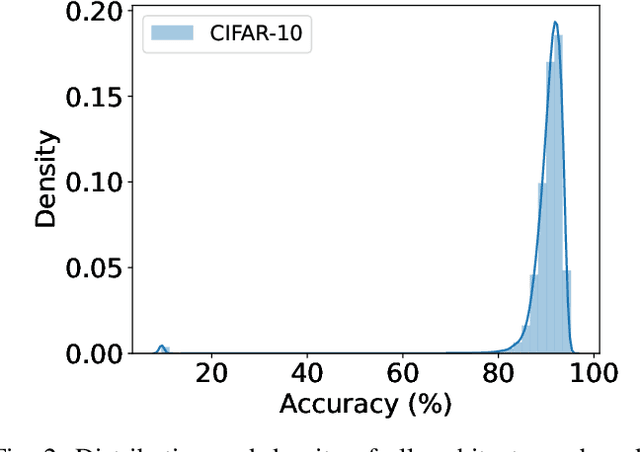
Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.
STILN: A Novel Spatial-Temporal Information Learning Network for EEG-based Emotion Recognition
Nov 22, 2022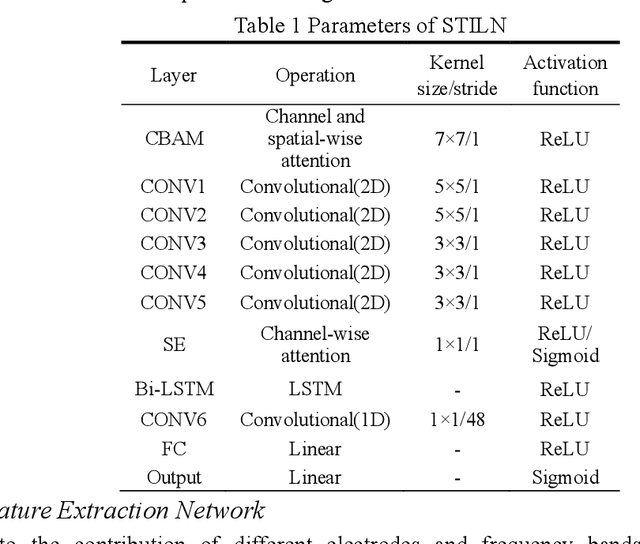
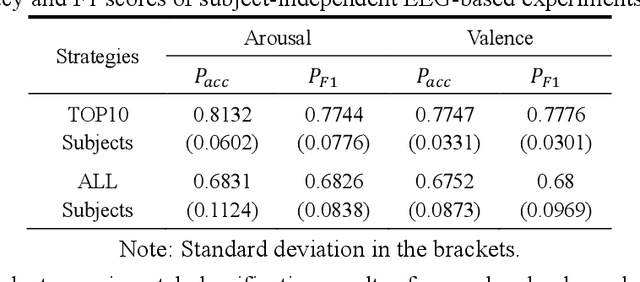
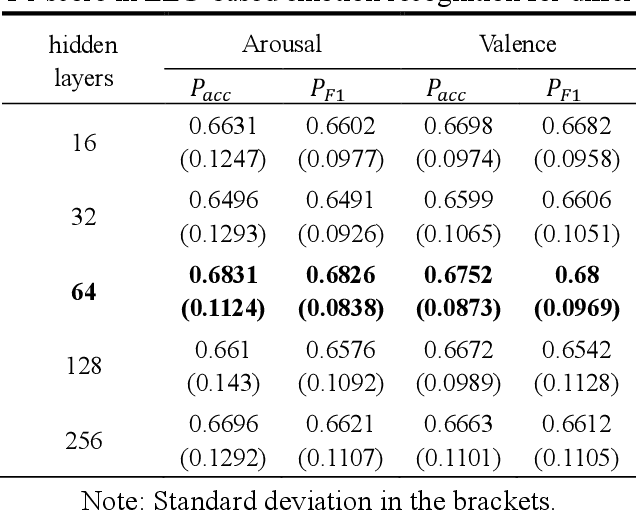
The spatial correlations and the temporal contexts are indispensable in Electroencephalogram (EEG)-based emotion recognition. However, the learning of complex spatial correlations among several channels is a challenging problem. Besides, the temporal contexts learning is beneficial to emphasize the critical EEG frames because the subjects only reach the prospective emotion during part of stimuli. Hence, we propose a novel Spatial-Temporal Information Learning Network (STILN) to extract the discriminative features by capturing the spatial correlations and temporal contexts. Specifically, the generated 2D power topographic maps capture the dependencies among electrodes, and they are fed to the CNN-based spatial feature extraction network. Furthermore, Convolutional Block Attention Module (CBAM) recalibrates the weights of power topographic maps to emphasize the crucial brain regions and frequency bands. Meanwhile, Batch Normalizations (BNs) and Instance Normalizations (INs) are appropriately combined to relieve the individual differences. In the temporal contexts learning, we adopt the Bidirectional Long Short-Term Memory Network (Bi-LSTM) network to capture the dependencies among the EEG frames. To validate the effectiveness of the proposed method, subject-independent experiments are conducted on the public DEAP dataset. The proposed method has achieved the outstanding performance, and the accuracies of arousal and valence classification have reached 0.6831 and 0.6752 respectively.
360BEV: Panoramic Semantic Mapping for Indoor Bird's-Eye View
Mar 22, 2023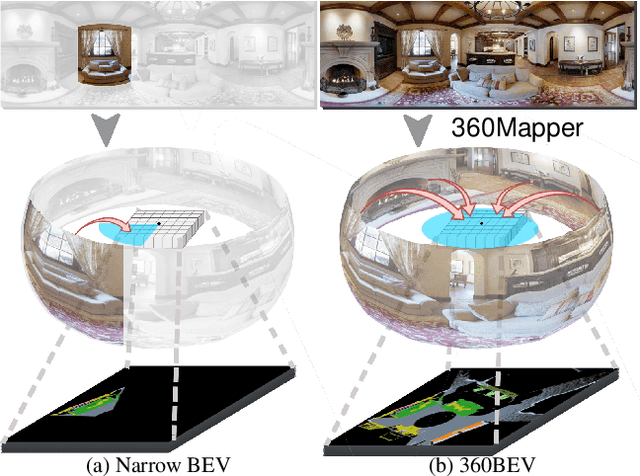
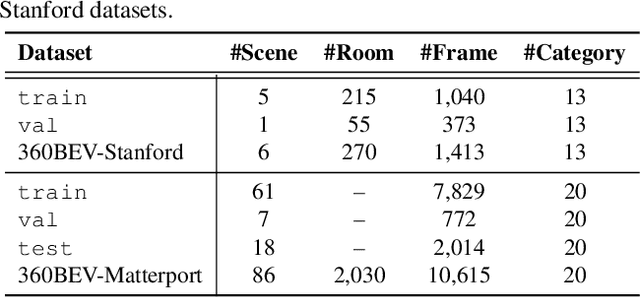
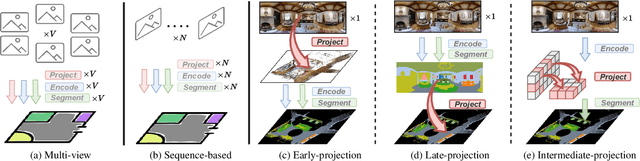
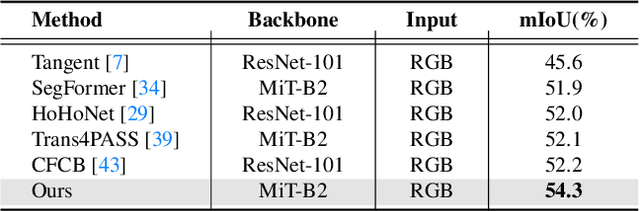
Seeing only a tiny part of the whole is not knowing the full circumstance. Bird's-eye-view (BEV) perception, a process of obtaining allocentric maps from egocentric views, is restricted when using a narrow Field of View (FoV) alone. In this work, mapping from 360{\deg} panoramas to BEV semantics, the 360BEV task, is established for the first time to achieve holistic representations of indoor scenes in a top-down view. Instead of relying on narrow-FoV image sequences, a panoramic image with depth information is sufficient to generate a holistic BEV semantic map. To benchmark 360BEV, we present two indoor datasets, 360BEV-Matterport and 360BEV-Stanford, both of which include egocentric panoramic images and semantic segmentation labels, as well as allocentric semantic maps. Besides delving deep into different mapping paradigms, we propose a dedicated solution for panoramic semantic mapping, namely 360Mapper. Through extensive experiments, our methods achieve 44.32% and 45.78% in mIoU on both datasets respectively, surpassing previous counterparts with gains of +7.60% and +9.70% in mIoU. Code and datasets will be available at: https://jamycheung.github.io/360BEV.html.
ProtoCon: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning
Mar 22, 2023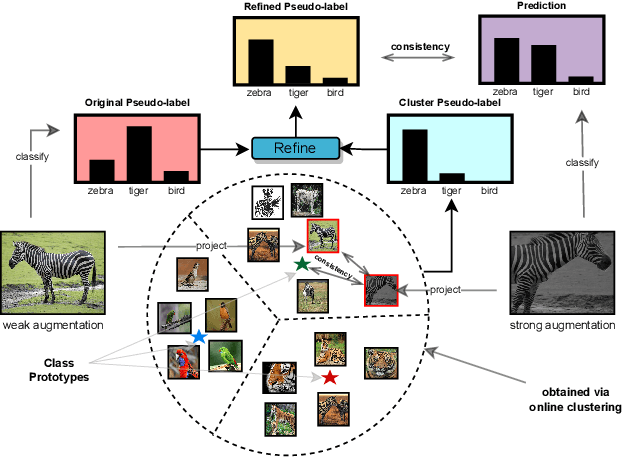
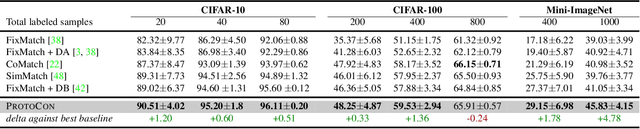
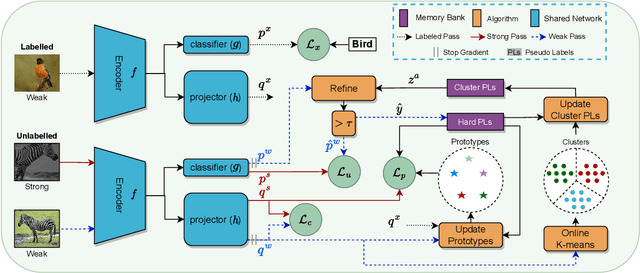
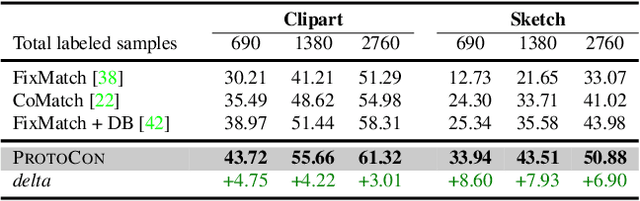
Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours' information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet.
End-to-End Personalized Next Location Recommendation via Contrastive User Preference Modeling
Mar 22, 2023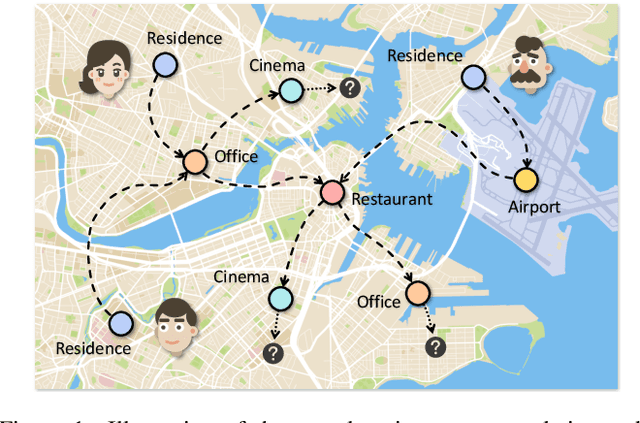
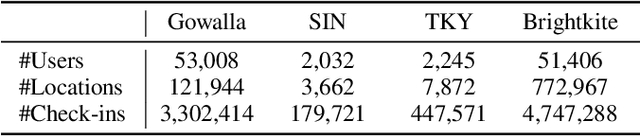
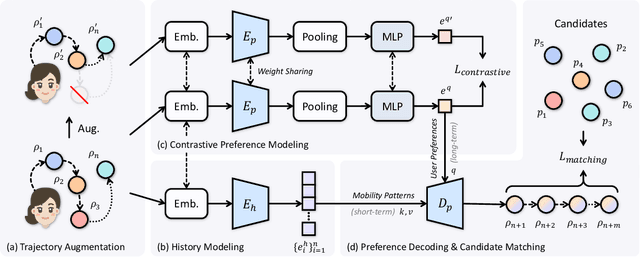
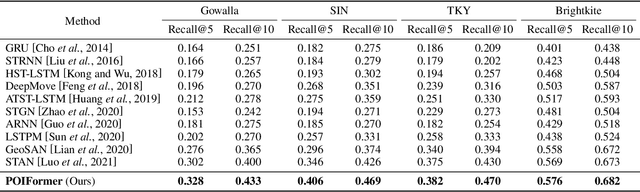
Predicting the next location is a highly valuable and common need in many location-based services such as destination prediction and route planning. The goal of next location recommendation is to predict the next point-of-interest a user might go to based on the user's historical trajectory. Most existing models learn mobility patterns merely from users' historical check-in sequences while overlooking the significance of user preference modeling. In this work, a novel Point-of-Interest Transformer (POIFormer) with contrastive user preference modeling is developed for end-to-end next location recommendation. This model consists of three major modules: history encoder, query generator, and preference decoder. History encoder is designed to model mobility patterns from historical check-in sequences, while query generator explicitly learns user preferences to generate user-specific intention queries. Finally, preference decoder combines the intention queries and historical information to predict the user's next location. Extensive comparisons with representative schemes and ablation studies on four real-world datasets demonstrate the effectiveness and superiority of the proposed scheme under various settings.
WDiscOOD: Out-of-Distribution Detection via Whitened Linear Discriminant Analysis
Mar 22, 2023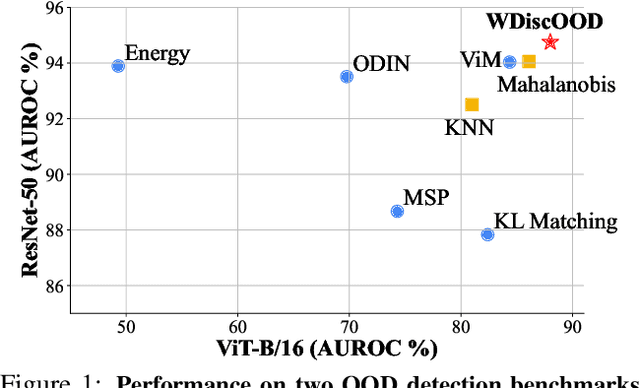
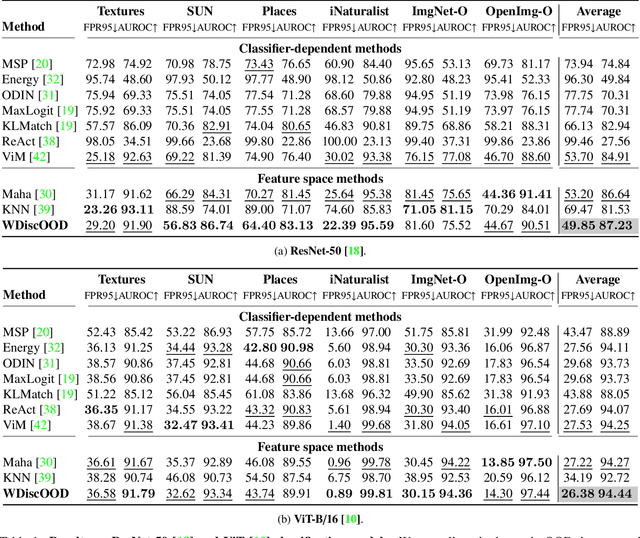
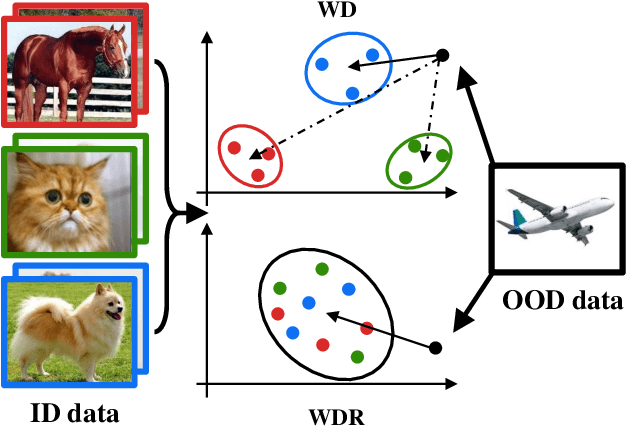

Deep neural networks are susceptible to generating overconfident yet erroneous predictions when presented with data beyond known concepts. This challenge underscores the importance of detecting out-of-distribution (OOD) samples in the open world. In this work, we propose a novel feature-space OOD detection score that jointly reasons with both class-specific and class-agnostic information. Specifically, our approach utilizes Whitened Linear Discriminant Analysis to project features into two subspaces - the discriminative and residual subspaces - in which the ID classes are maximally separated and closely clustered, respectively. The OOD score is then determined by combining the deviation from the input data to the ID distribution in both subspaces. The efficacy of our method, named WDiscOOD, is verified on the large-scale ImageNet-1k benchmark, with six OOD datasets that covers a variety of distribution shifts. WDiscOOD demonstrates superior performance on deep classifiers with diverse backbone architectures, including CNN and vision transformer. Furthermore, we also show that our method can more effectively detect novel concepts in representation space trained with contrastive objectives, including supervised contrastive loss and multi-modality contrastive loss.
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 22, 2023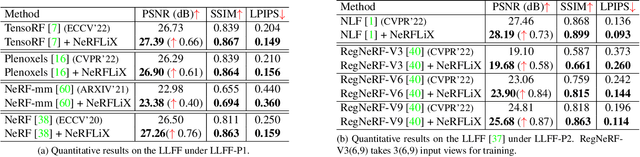
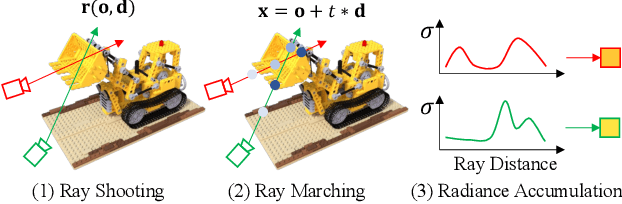
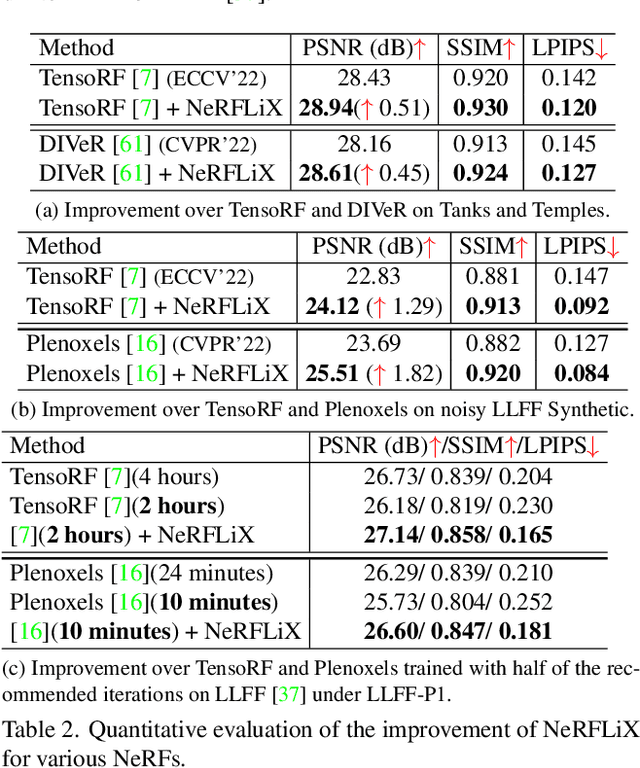
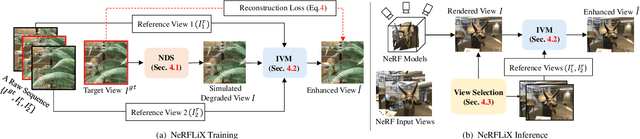
Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.