 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 17, 2023
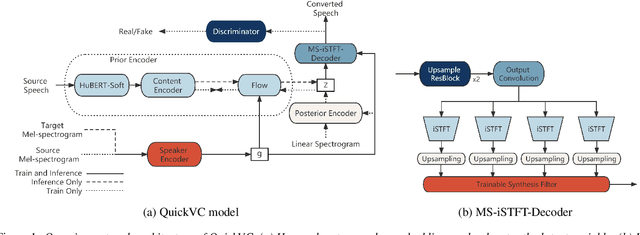
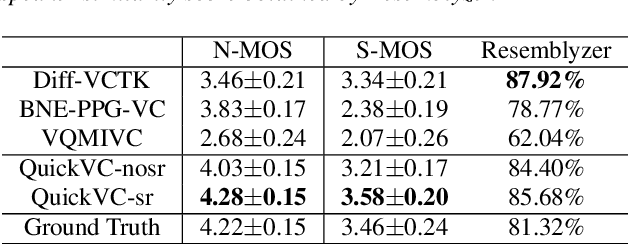

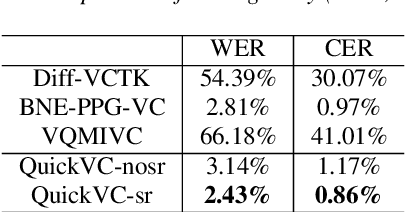
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Efficient solutions to the relative pose of three calibrated cameras from four points using virtual correspondences
Mar 28, 2023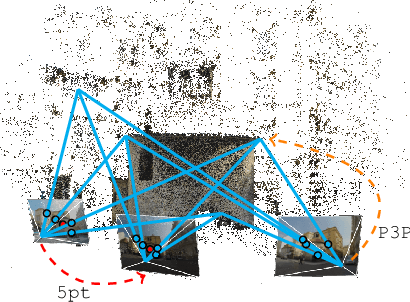
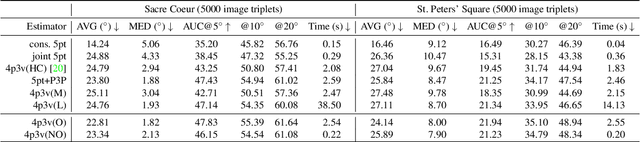
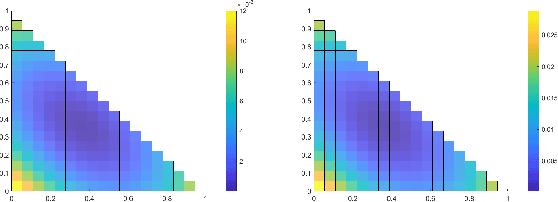

We study the challenging problem of estimating the relative pose of three calibrated cameras. We propose two novel solutions to the notoriously difficult configuration of four points in three views, known as the 4p3v problem. Our solutions are based on the simple idea of generating one additional virtual point correspondence in two views by using the information from the locations of the four input correspondences in the three views. For the first solver, we train a network to predict this point correspondence. The second solver uses a much simpler and more efficient strategy based on the mean points of three corresponding input points. The new solvers are efficient and easy to implement since they are based on the existing efficient minimal solvers, i.e., the well-known 5-point relative pose and the P3P solvers. The solvers achieve state-of-the-art results on real data. The idea of solving minimal problems using virtual correspondences is general and can be applied to other problems, e.g., the 5-point relative pose problem. In this way, minimal problems can be solved using simpler non-minimal solvers or even using sub-minimal samples inside RANSAC. In addition, we compare different variants of 4p3v solvers with the baseline solver for the minimal configuration consisting of three triplets of points and two points visible in two views. We discuss which configuration of points is potentially the most practical in real applications.
SottoVoce: An Ultrasound Imaging-Based Silent Speech Interaction Using Deep Neural Networks
Mar 03, 2023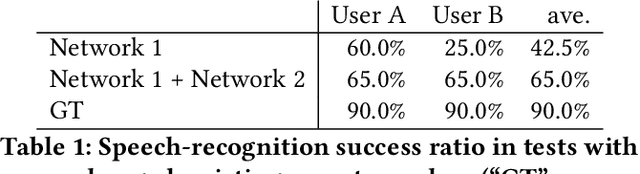
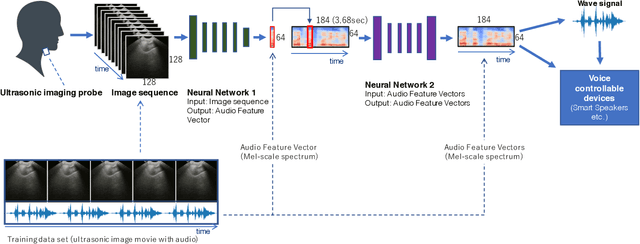
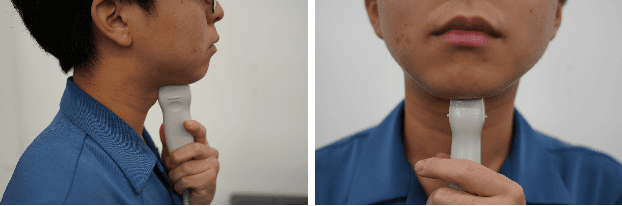
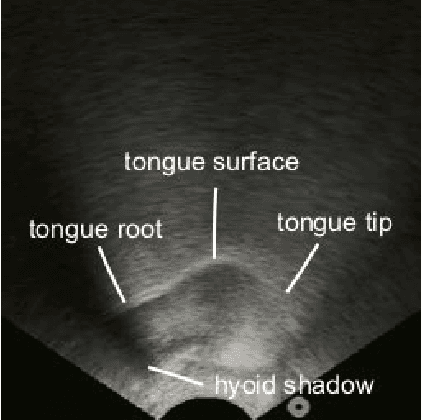
The availability of digital devices operated by voice is expanding rapidly. However, the applications of voice interfaces are still restricted. For example, speaking in public places becomes an annoyance to the surrounding people, and secret information should not be uttered. Environmental noise may reduce the accuracy of speech recognition. To address these limitations, a system to detect a user's unvoiced utterance is proposed. From internal information observed by an ultrasonic imaging sensor attached to the underside of the jaw, our proposed system recognizes the utterance contents without the user's uttering voice. Our proposed deep neural network model is used to obtain acoustic features from a sequence of ultrasound images. We confirmed that audio signals generated by our system can control the existing smart speakers. We also observed that a user can adjust their oral movement to learn and improve the accuracy of their voice recognition.
* ACM CHI 2019 paper
Towards better traffic volume estimation: Tackling both underdetermined and non-equilibrium problems via a correlation-adaptive graph convolution network
Mar 14, 2023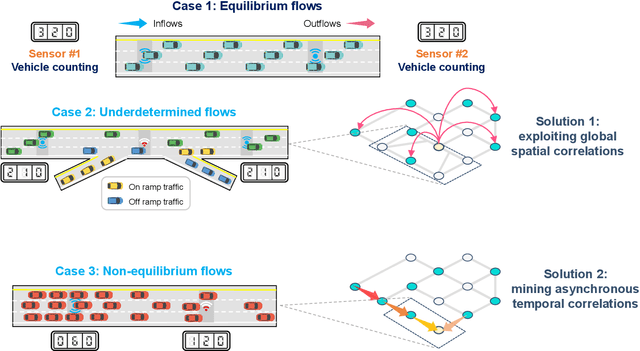
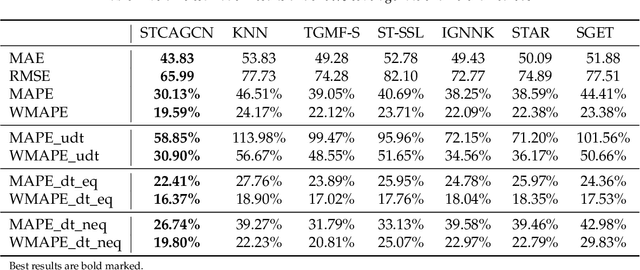
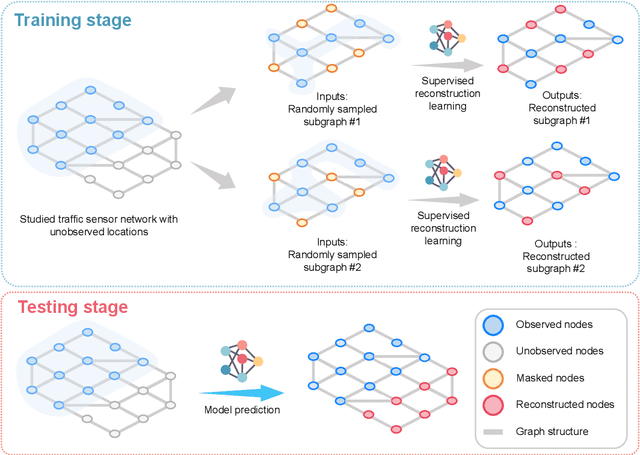
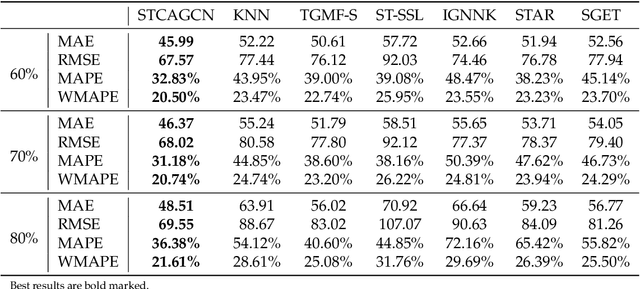
Traffic volume is an indispensable ingredient to provide fine-grained information for traffic management and control. However, due to limited deployment of traffic sensors, obtaining full-scale volume information is far from easy. Existing works on this topic primarily focus on improving the overall estimation accuracy of a particular method and ignore the underlying challenges of volume estimation, thereby having inferior performances on some critical tasks. This paper studies two key problems with regard to traffic volume estimation: (1) underdetermined traffic flows caused by undetected movements, and (2) non-equilibrium traffic flows arise from congestion propagation. Here we demonstrate a graph-based deep learning method that can offer a data-driven, model-free and correlation adaptive approach to tackle the above issues and perform accurate network-wide traffic volume estimation. Particularly, in order to quantify the dynamic and nonlinear relationships between traffic speed and volume for the estimation of underdetermined flows, a speed patternadaptive adjacent matrix based on graph attention is developed and integrated into the graph convolution process, to capture non-local correlations between sensors. To measure the impacts of non-equilibrium flows, a temporal masked and clipped attention combined with a gated temporal convolution layer is customized to capture time-asynchronous correlations between upstream and downstream sensors. We then evaluate our model on a real-world highway traffic volume dataset and compare it with several benchmark models. It is demonstrated that the proposed model achieves high estimation accuracy even under 20% sensor coverage rate and outperforms other baselines significantly, especially on underdetermined and non-equilibrium flow locations. Furthermore, comprehensive quantitative model analysis are also carried out to justify the model designs.
Speaker-Aware Anti-Spoofing
Mar 02, 2023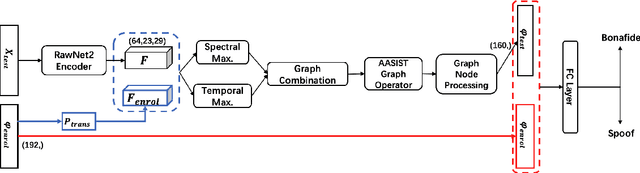
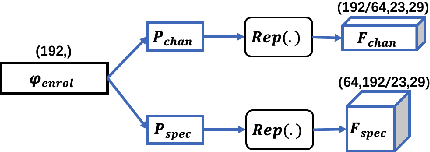
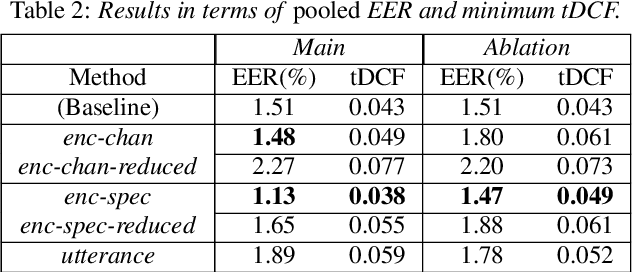
We address speaker-aware anti-spoofing, where prior knowledge of the target speaker is incorporated into a voice spoofing countermeasure (CM). In contrast to the frequently used speaker-independent solutions, we train the CM in a speaker-conditioned way. As a proof of concept, we consider speaker-aware extension to the state-of-the-art AASIST (audio anti-spoofing using integrated spectro-temporal graph attention networks) model. To this end, we consider two alternative strategies to incorporate target speaker information at the frame and utterance levels, respectively. The experimental results on a custom protocol based on ASVspoof 2019 dataset indicates the efficiency of the speaker information via enrollment: we obtain maximum relative improvements of 25.1% and 11.6% in equal error rate (EER) and minimum tandem detection cost function (t-DCF) over a speaker-independent baseline, respectively.
MetaFill: Text Infilling for Meta-Path Generation on Heterogeneous Information Networks
Oct 14, 2022
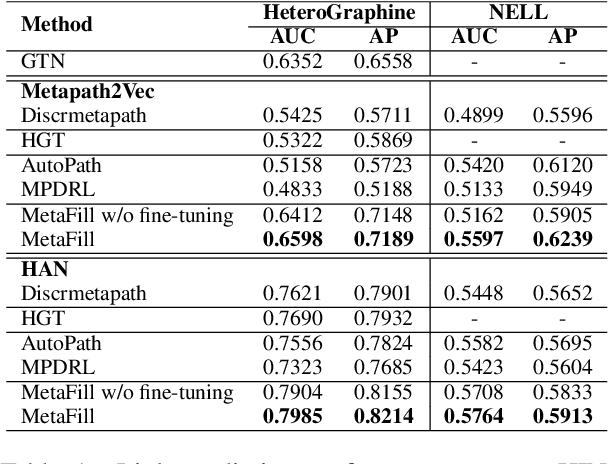
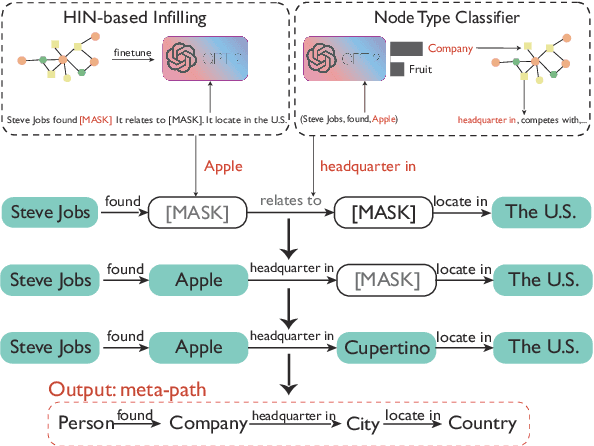

Heterogeneous Information Network (HIN) is essential to study complicated networks containing multiple edge types and node types. Meta-path, a sequence of node types and edge types, is the core technique to embed HINs. Since manually curating meta-paths is time-consuming, there is a pressing need to develop automated meta-path generation approaches. Existing meta-path generation approaches cannot fully exploit the rich textual information in HINs, such as node names and edge type names. To address this problem, we propose MetaFill, a text-infilling-based approach for meta-path generation. The key idea of MetaFill is to formulate meta-path identification problem as a word sequence infilling problem, which can be advanced by Pretrained Language Models (PLMs). We observed the superior performance of MetaFill against existing meta-path generation methods and graph embedding methods that do not leverage meta-paths in both link prediction and node classification on two real-world HIN datasets. We further demonstrated how MetaFill can accurately classify edges in the zero-shot setting, where existing approaches cannot generate any meta-paths. MetaFill exploits PLMs to generate meta-paths for graph embedding, opening up new avenues for language model applications in graph analysis.
Label Attention Network for sequential multi-label classification
Mar 01, 2023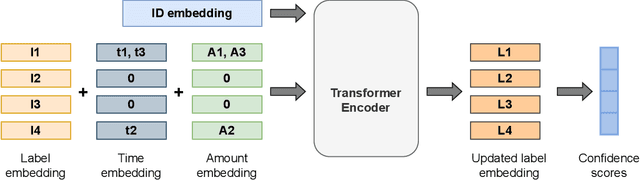
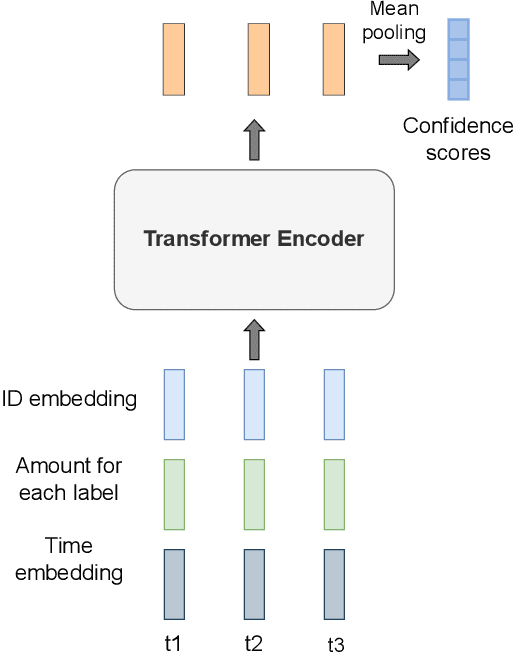
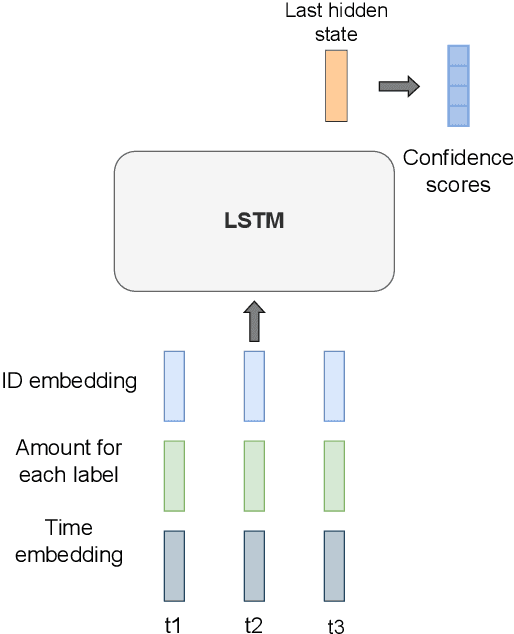
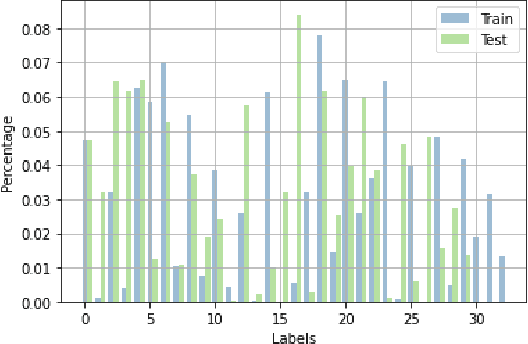
Multi-label classification is a natural problem statement for sequential data. We might be interested in the items of the next order by a customer, or types of financial transactions that will occur tomorrow. Most modern approaches focus on transformer architecture for multi-label classification, introducing self-attention for the elements of a sequence with each element being a multi-label vector and supplementary information. However, in this way we loose local information related to interconnections between particular labels. We propose instead to use a self-attention mechanism over labels preceding the predicted step. Conducted experiments suggest that such architecture improves the model performance and provides meaningful attention between labels. The metric such as micro-AUC of our label attention network is $0.9847$ compared to $0.7390$ for vanilla transformers benchmark.
Domain Adaptive Semantic Segmentation by Optimal Transport
Mar 29, 2023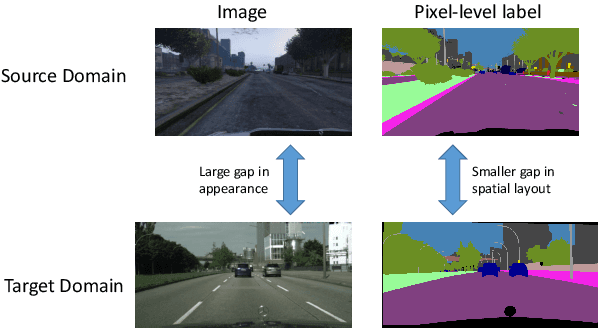
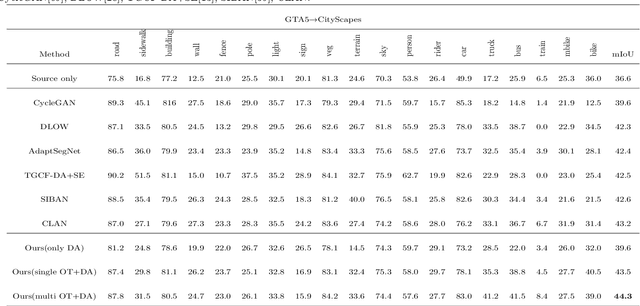
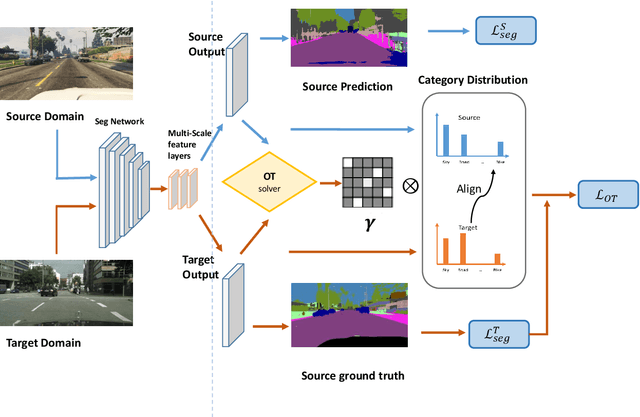
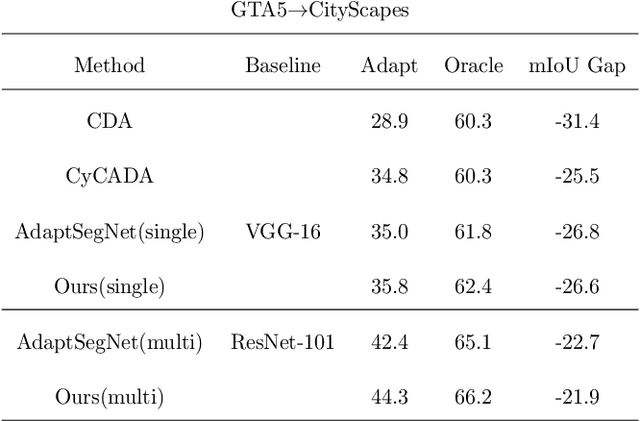
Scene segmentation is widely used in the field of autonomous driving for environment perception, and semantic scene segmentation (3S) has received a great deal of attention due to the richness of the semantic information it contains. It aims to assign labels to pixels in an image, thus enabling automatic image labeling. Current approaches are mainly based on convolutional neural networks (CNN), but they rely on a large number of labels. Therefore, how to use a small size of labeled data to achieve semantic segmentation becomes more and more important. In this paper, we propose a domain adaptation (DA) framework based on optimal transport (OT) and attention mechanism to address this issue. Concretely, first we generate the output space via CNN due to its superiority of feature representation. Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model. In particular, with OT, the number of network parameters has been reduced and the network has been better interpretable. Third, to better describe the multi-scale property of features, we construct a multi-scale segmentation network to perform domain adaptation. Finally, in order to verify the performance of our proposed method, we conduct experimental comparison with three benchmark and four SOTA methods on three scene datasets, and the mean intersection-over-union (mIOU) has been significant improved, and visualization results under multiple domain adaptation scenarios also show that our proposed method has better performance than compared semantic segmentation methods.
Does Sparsity Help in Learning Misspecified Linear Bandits?
Mar 29, 2023Recently, the study of linear misspecified bandits has generated intriguing implications of the hardness of learning in bandits and reinforcement learning (RL). In particular, Du et al. (2020) show that even if a learner is given linear features in $\mathbb{R}^d$ that approximate the rewards in a bandit or RL with a uniform error of $\varepsilon$, searching for an $O(\varepsilon)$-optimal action requires pulling at least $\Omega(\exp(d))$ queries. Furthermore, Lattimore et al. (2020) show that a degraded $O(\varepsilon\sqrt{d})$-optimal solution can be learned within $\operatorname{poly}(d/\varepsilon)$ queries. Yet it is unknown whether a structural assumption on the ground-truth parameter, such as sparsity, could break the $\varepsilon\sqrt{d}$ barrier. In this paper, we address this question by showing that algorithms can obtain $O(\varepsilon)$-optimal actions by querying $O(\varepsilon^{-s}d^s)$ actions, where $s$ is the sparsity parameter, removing the $\exp(d)$-dependence. We then establish information-theoretical lower bounds, i.e., $\Omega(\exp(s))$, to show that our upper bound on sample complexity is nearly tight if one demands an error $ O(s^{\delta}\varepsilon)$ for $0<\delta<1$. For $\delta\geq 1$, we further show that $\operatorname{poly}(s/\varepsilon)$ queries are possible when the linear features are "good" and even in general settings. These results provide a nearly complete picture of how sparsity can help in misspecified bandit learning and provide a deeper understanding of when linear features are "useful" for bandit and reinforcement learning with misspecification.
Are Neural Architecture Search Benchmarks Well Designed? A Deeper Look Into Operation Importance
Mar 29, 2023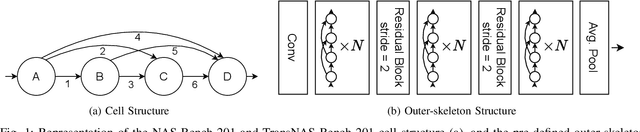

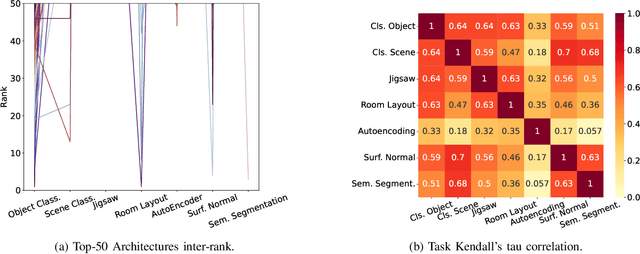
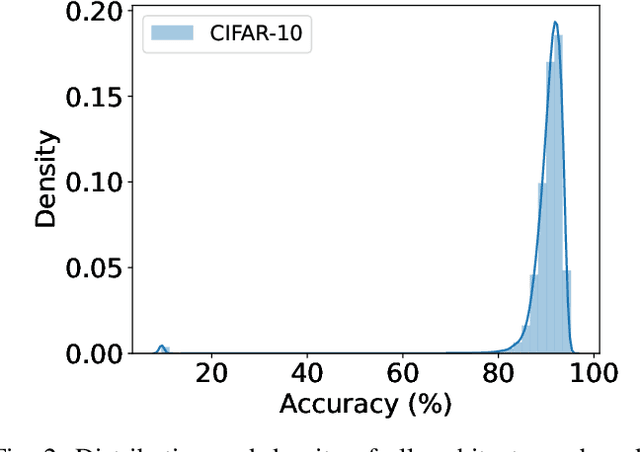
Neural Architecture Search (NAS) benchmarks significantly improved the capability of developing and comparing NAS methods while at the same time drastically reduced the computational overhead by providing meta-information about thousands of trained neural networks. However, tabular benchmarks have several drawbacks that can hinder fair comparisons and provide unreliable results. These usually focus on providing a small pool of operations in heavily constrained search spaces -- usually cell-based neural networks with pre-defined outer-skeletons. In this work, we conducted an empirical analysis of the widely used NAS-Bench-101, NAS-Bench-201 and TransNAS-Bench-101 benchmarks in terms of their generability and how different operations influence the performance of the generated architectures. We found that only a subset of the operation pool is required to generate architectures close to the upper-bound of the performance range. Also, the performance distribution is negatively skewed, having a higher density of architectures in the upper-bound range. We consistently found convolution layers to have the highest impact on the architecture's performance, and that specific combination of operations favors top-scoring architectures. These findings shed insights on the correct evaluation and comparison of NAS methods using NAS benchmarks, showing that directly searching on NAS-Bench-201, ImageNet16-120 and TransNAS-Bench-101 produces more reliable results than searching only on CIFAR-10. Furthermore, with this work we provide suggestions for future benchmark evaluations and design. The code used to conduct the evaluations is available at https://github.com/VascoLopes/NAS-Benchmark-Evaluation.