 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Making Vision Transformers Efficient from A Token Sparsification View
Mar 15, 2023

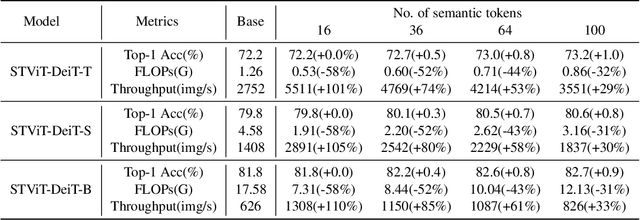
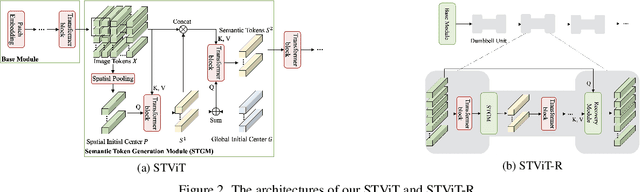
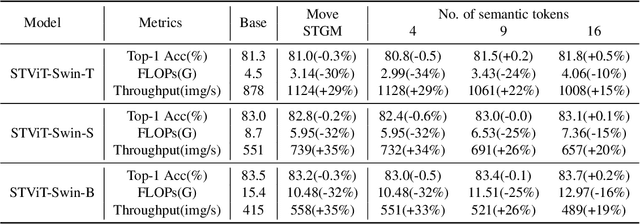
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone.
Applying unsupervised keyphrase methods on concepts extracted from discharge sheets
Mar 15, 2023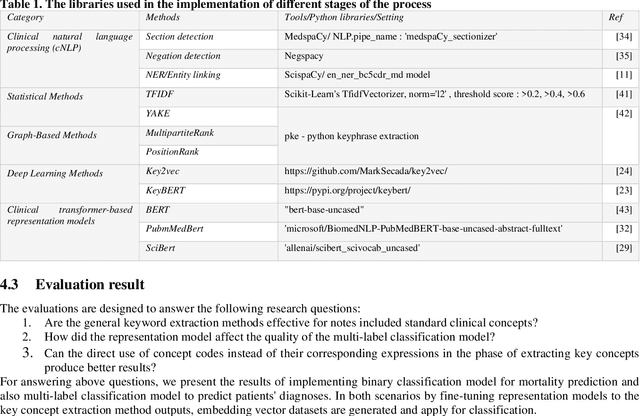
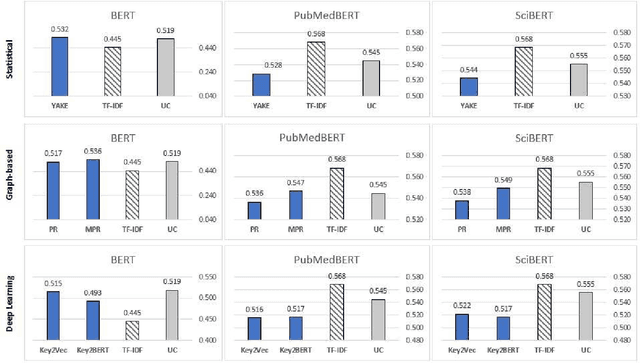
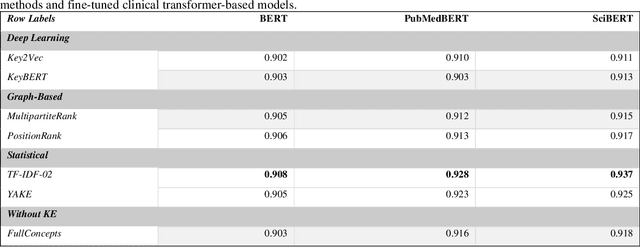
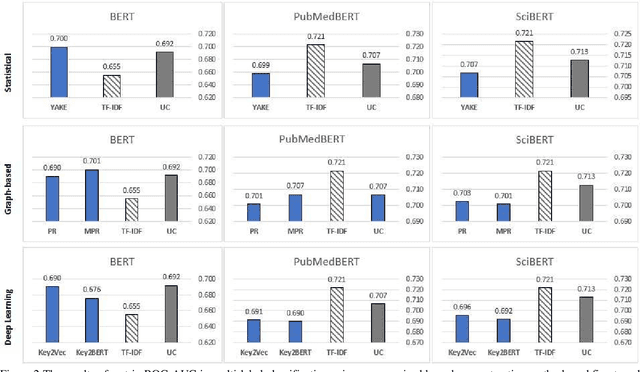
Clinical notes containing valuable patient information are written by different health care providers with various scientific levels and writing styles. It might be helpful for clinicians and researchers to understand what information is essential when dealing with extensive electronic medical records. Entities recognizing and mapping them to standard terminologies is crucial in reducing ambiguity in processing clinical notes. Although named entity recognition and entity linking are critical steps in clinical natural language processing, they can also result in the production of repetitive and low-value concepts. In other hand, all parts of a clinical text do not share the same importance or content in predicting the patient's condition. As a result, it is necessary to identify the section in which each content is recorded and also to identify key concepts to extract meaning from clinical texts. In this study, these challenges have been addressed by using clinical natural language processing techniques. In addition, in order to identify key concepts, a set of popular unsupervised key phrase extraction methods has been verified and evaluated. Considering that most of the clinical concepts are in the form of multi-word expressions and their accurate identification requires the user to specify n-gram range, we have proposed a shortcut method to preserve the structure of the expression based on TF-IDF. In order to evaluate the pre-processing method and select the concepts, we have designed two types of downstream tasks (multiple and binary classification) using the capabilities of transformer-based models. The obtained results show the superiority of proposed method in combination with SciBERT model, also offer an insight into the efficacy of general extracting essential phrase methods for clinical notes.
Brain subtle anomaly detection based on auto-encoders latent space analysis : application to de novo parkinson patients
Feb 27, 2023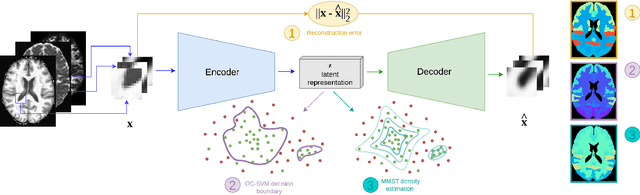
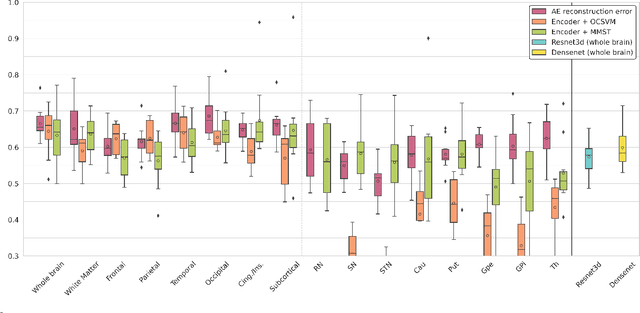
Neural network-based anomaly detection remains challenging in clinical applications with little or no supervised information and subtle anomalies such as hardly visible brain lesions. Among unsupervised methods, patch-based auto-encoders with their efficient representation power provided by their latent space, have shown good results for visible lesion detection. However, the commonly used reconstruction error criterion may limit their performance when facing less obvious lesions. In this work, we design two alternative detection criteria. They are derived from multivariate analysis and can more directly capture information from latent space representations. Their performance compares favorably with two additional supervised learning methods, on a difficult de novo Parkinson Disease (PD) classification task.
LSEH: Semantically Enhanced Hard Negatives for Cross-modal Information Retrieval
Oct 10, 2022
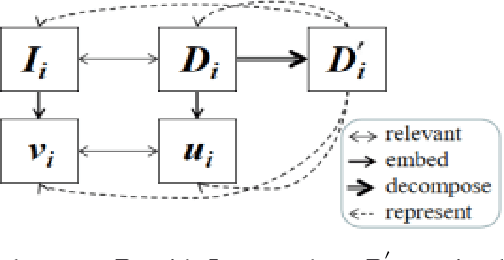
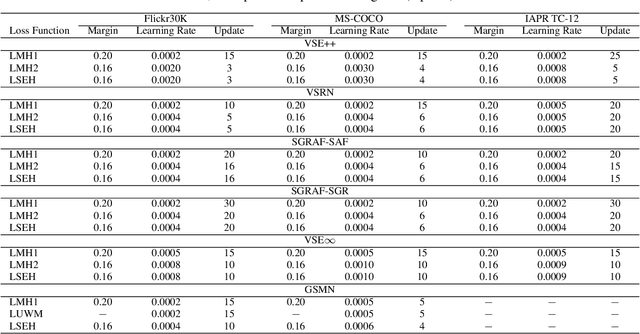
Visual Semantic Embedding (VSE) aims to extract the semantics of images and their descriptions, and embed them into the same latent space for cross-modal information retrieval. Most existing VSE networks are trained by adopting a hard negatives loss function which learns an objective margin between the similarity of relevant and irrelevant image-description embedding pairs. However, the objective margin in the hard negatives loss function is set as a fixed hyperparameter that ignores the semantic differences of the irrelevant image-description pairs. To address the challenge of measuring the optimal similarities between image-description pairs before obtaining the trained VSE networks, this paper presents a novel approach that comprises two main parts: (1) finds the underlying semantics of image descriptions; and (2) proposes a novel semantically enhanced hard negatives loss function, where the learning objective is dynamically determined based on the optimal similarity scores between irrelevant image-description pairs. Extensive experiments were carried out by integrating the proposed methods into five state-of-the-art VSE networks that were applied to three benchmark datasets for cross-modal information retrieval tasks. The results revealed that the proposed methods achieved the best performance and can also be adopted by existing and future VSE networks.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023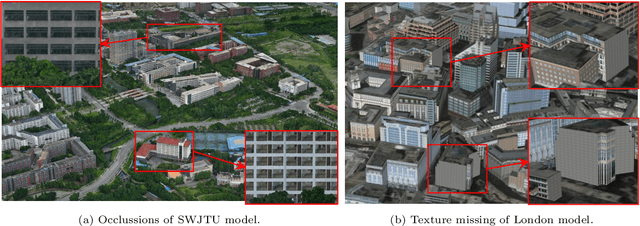
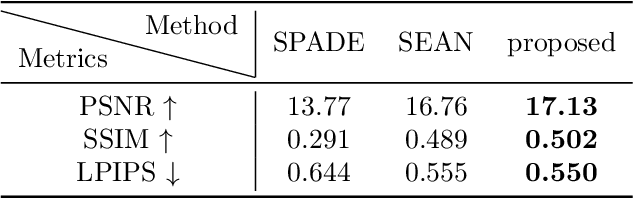
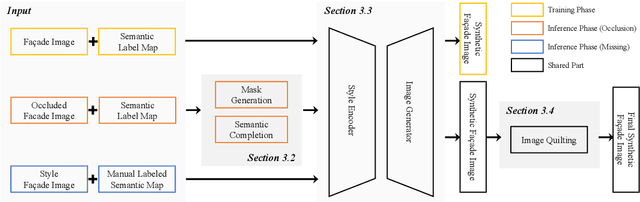

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Online Ensemble of Models for Optimal Predictive Performance with Applications to Sector Rotation Strategy
Mar 30, 2023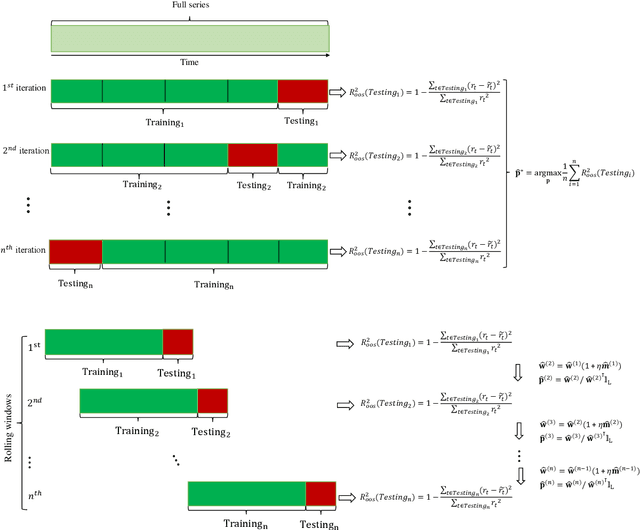

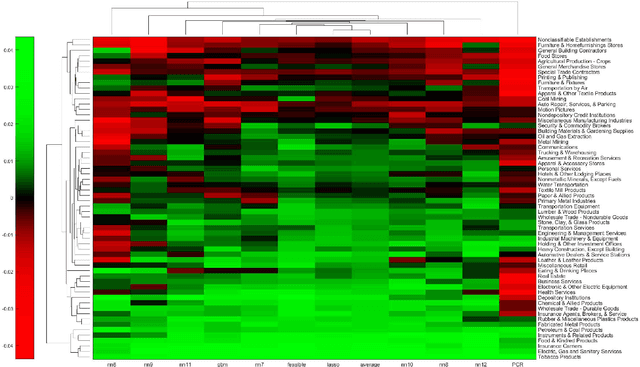
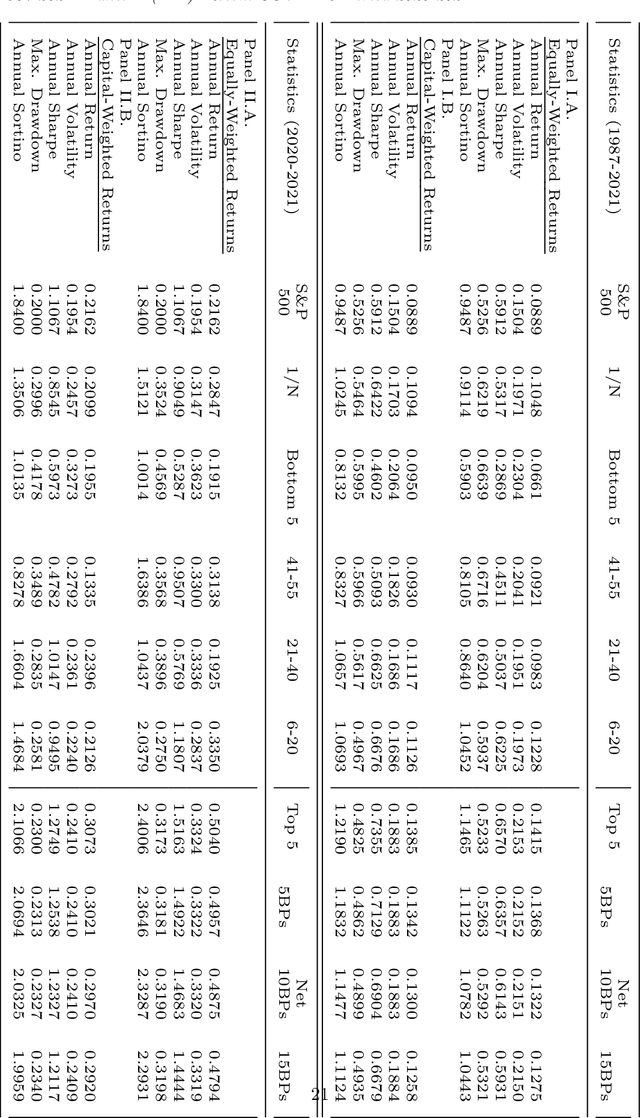
Asset-specific factors are commonly used to forecast financial returns and quantify asset-specific risk premia. Using various machine learning models, we demonstrate that the information contained in these factors leads to even larger economic gains in terms of forecasts of sector returns and the measurement of sector-specific risk premia. To capitalize on the strong predictive results of individual models for the performance of different sectors, we develop a novel online ensemble algorithm that learns to optimize predictive performance. The algorithm continuously adapts over time to determine the optimal combination of individual models by solely analyzing their most recent prediction performance. This makes it particularly suited for time series problems, rolling window backtesting procedures, and systems of potentially black-box models. We derive the optimal gain function, express the corresponding regret bounds in terms of the out-of-sample R-squared measure, and derive optimal learning rate for the algorithm. Empirically, the new ensemble outperforms both individual machine learning models and their simple averages in providing better measurements of sector risk premia. Moreover, it allows for performance attribution of different factors across various sectors, without conditioning on a specific model. Finally, by utilizing monthly predictions from our ensemble, we develop a sector rotation strategy that significantly outperforms the market. The strategy remains robust against various financial factors, periods of financial distress, and conservative transaction costs. Notably, the strategy's efficacy persists over time, exhibiting consistent improvement throughout an extended backtesting period and yielding substantial profits during the economic turbulence of the COVID-19 pandemic.
Self-Asymmetric Invertible Network for Compression-Aware Image Rescaling
Mar 11, 2023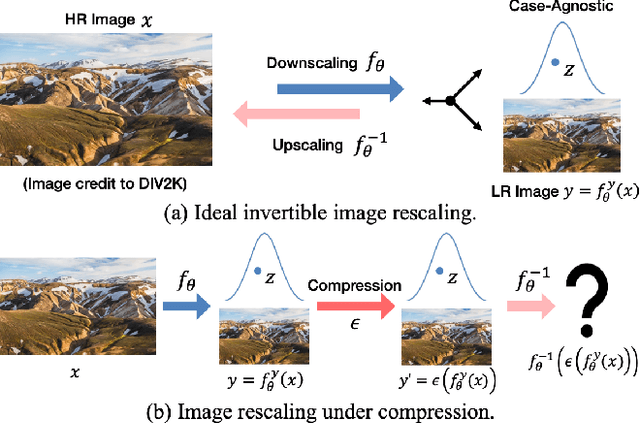
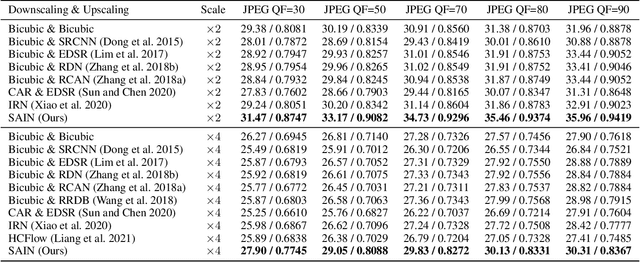
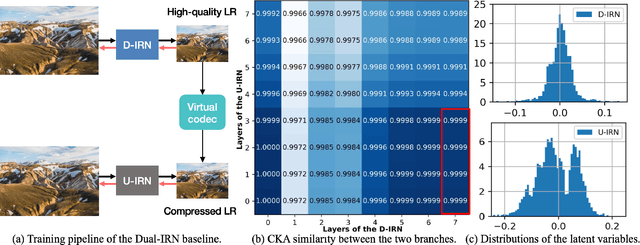
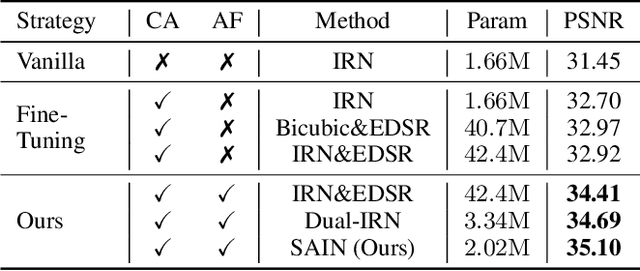
High-resolution (HR) images are usually downscaled to low-resolution (LR) ones for better display and afterward upscaled back to the original size to recover details. Recent work in image rescaling formulates downscaling and upscaling as a unified task and learns a bijective mapping between HR and LR via invertible networks. However, in real-world applications (e.g., social media), most images are compressed for transmission. Lossy compression will lead to irreversible information loss on LR images, hence damaging the inverse upscaling procedure and degrading the reconstruction accuracy. In this paper, we propose the Self-Asymmetric Invertible Network (SAIN) for compression-aware image rescaling. To tackle the distribution shift, we first develop an end-to-end asymmetric framework with two separate bijective mappings for high-quality and compressed LR images, respectively. Then, based on empirical analysis of this framework, we model the distribution of the lost information (including downscaling and compression) using isotropic Gaussian mixtures and propose the Enhanced Invertible Block to derive high-quality/compressed LR images in one forward pass. Besides, we design a set of losses to regularize the learned LR images and enhance the invertibility. Extensive experiments demonstrate the consistent improvements of SAIN across various image rescaling datasets in terms of both quantitative and qualitative evaluation under standard image compression formats (i.e., JPEG and WebP).
Dynamic Spatial-temporal Hypergraph Convolutional Network for Skeleton-based Action Recognition
Feb 17, 2023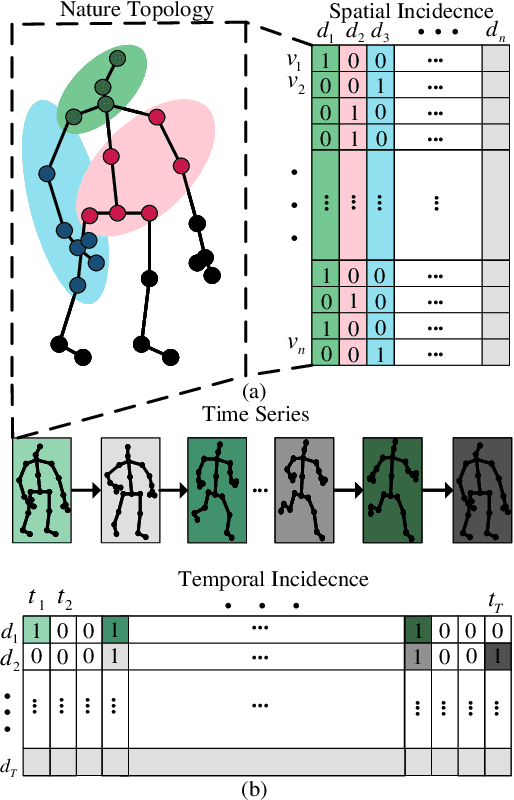
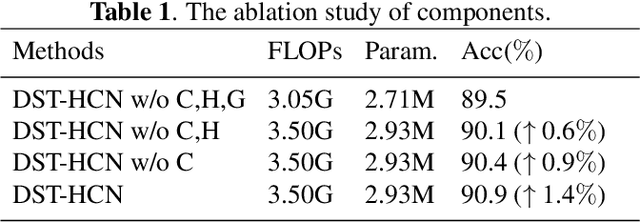
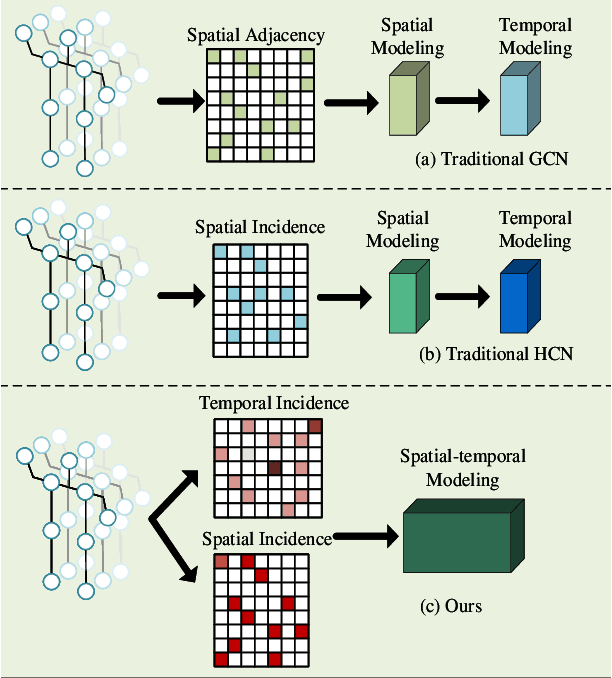

Skeleton-based action recognition relies on the extraction of spatial-temporal topological information. Hypergraphs can establish prior unnatural dependencies for the skeleton. However, the existing methods only focus on the construction of spatial topology and ignore the time-point dependence. This paper proposes a dynamic spatial-temporal hypergraph convolutional network (DST-HCN) to capture spatial-temporal information for skeleton-based action recognition. DST-HCN introduces a time-point hypergraph (TPH) to learn relationships at time points. With multiple spatial static hypergraphs and dynamic TPH, our network can learn more complete spatial-temporal features. In addition, we use the high-order information fusion module (HIF) to fuse spatial-temporal information synchronously. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets show that our model achieves state-of-the-art, especially compared with hypergraph methods.
Splitting Receiver with Multiple Antennas
Mar 08, 2023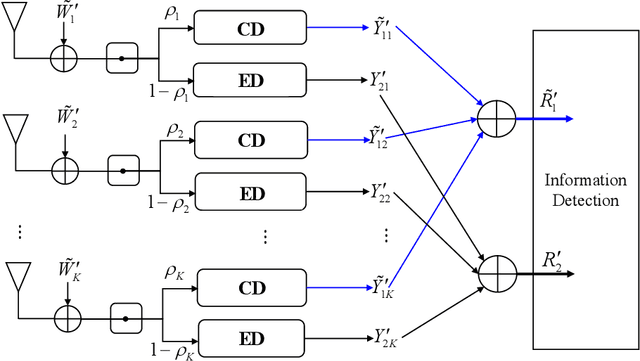
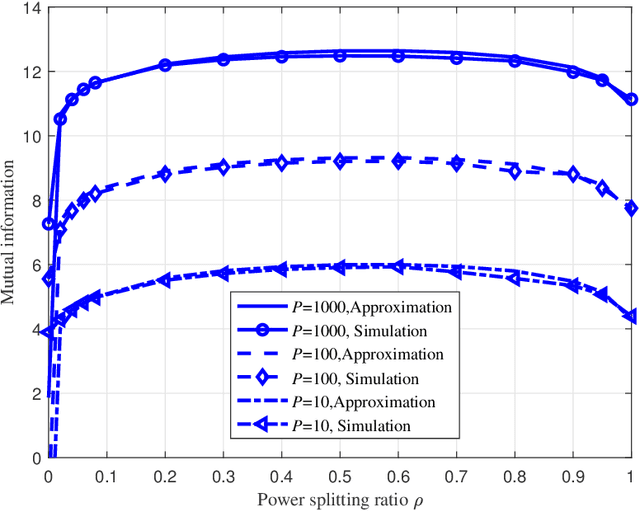
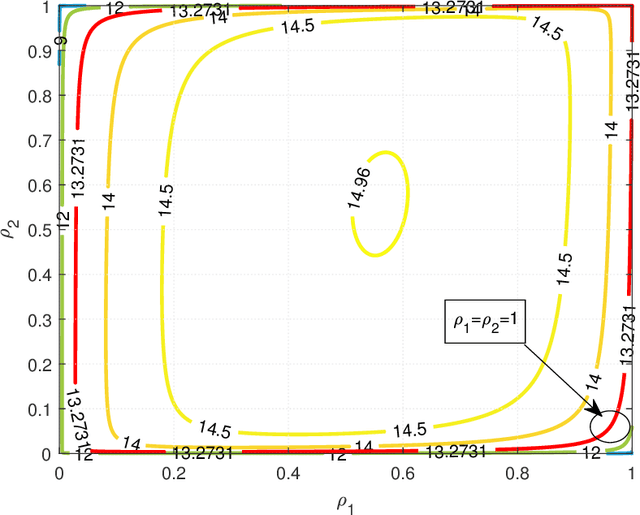
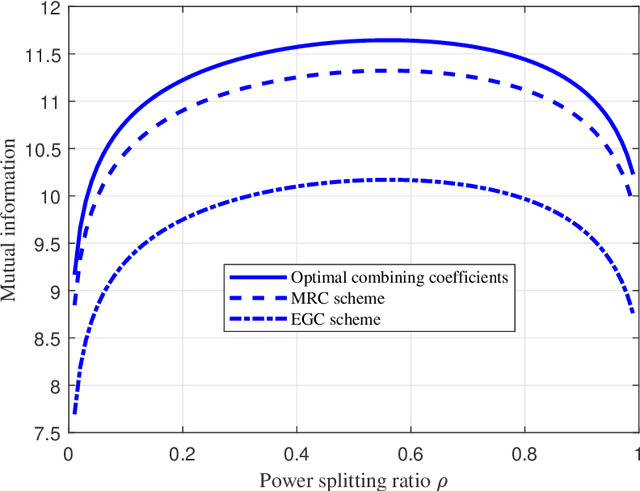
Recently proposed splitting receivers, utilizing both coherently and non-coherently processed signals for detection, have demonstrated remarkable performance gain compared to conventional receivers in the single-antenna scenario. In this paper, we propose a multi-antenna splitting receiver, where the received signal at each antenna is split into an envelope detection (ED) branch and a coherent detection (CD) branch, and the processed signals from both branches of all antennas are then jointly utilized for recovering the transmitted information. We derive a closed-form approximation of the achievable mutual information (MI) in terms of the key receiver design parameters, including the power splitting ratio at each antenna and the signal combining coefficients from all the ED and CD branches. We further optimize these receiver design parameters and demonstrate important design insights for the proposed multi-antenna ED-CD splitting receiver: 1) the optimal splitting ratio is identical at each antenna, and 2) the optimal combining coefficients for the ED and CD branches are the same, and each coefficient is proportional to the corresponding antenna's channel power gain. Our numerical results also demonstrate the MI performance improvement of the proposed receiver over conventional non-splitting receivers.
Improving Generalization with Domain Convex Game
Mar 23, 2023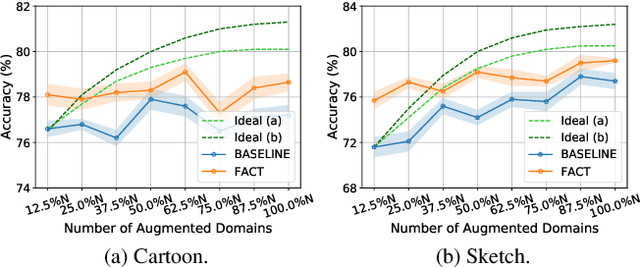

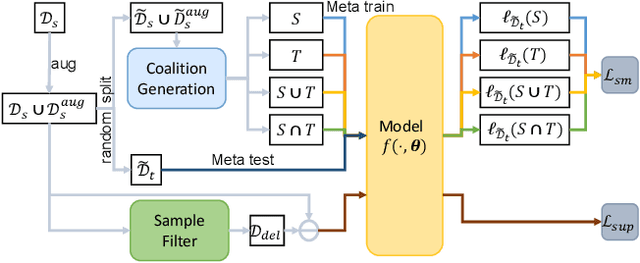
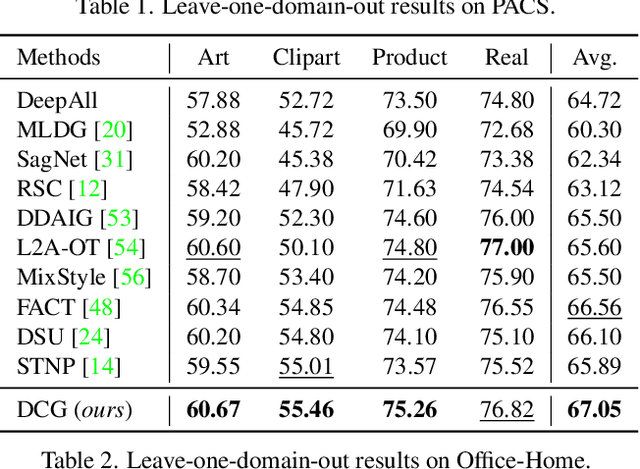
Domain generalization (DG) tends to alleviate the poor generalization capability of deep neural networks by learning model with multiple source domains. A classical solution to DG is domain augmentation, the common belief of which is that diversifying source domains will be conducive to the out-of-distribution generalization. However, these claims are understood intuitively, rather than mathematically. Our explorations empirically reveal that the correlation between model generalization and the diversity of domains may be not strictly positive, which limits the effectiveness of domain augmentation. This work therefore aim to guarantee and further enhance the validity of this strand. To this end, we propose a new perspective on DG that recasts it as a convex game between domains. We first encourage each diversified domain to enhance model generalization by elaborately designing a regularization term based on supermodularity. Meanwhile, a sample filter is constructed to eliminate low-quality samples, thereby avoiding the impact of potentially harmful information. Our framework presents a new avenue for the formal analysis of DG, heuristic analysis and extensive experiments demonstrate the rationality and effectiveness.