 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring the Relevance of Data Privacy-Enhancing Technologies for AI Governance Use Cases
Mar 20, 2023
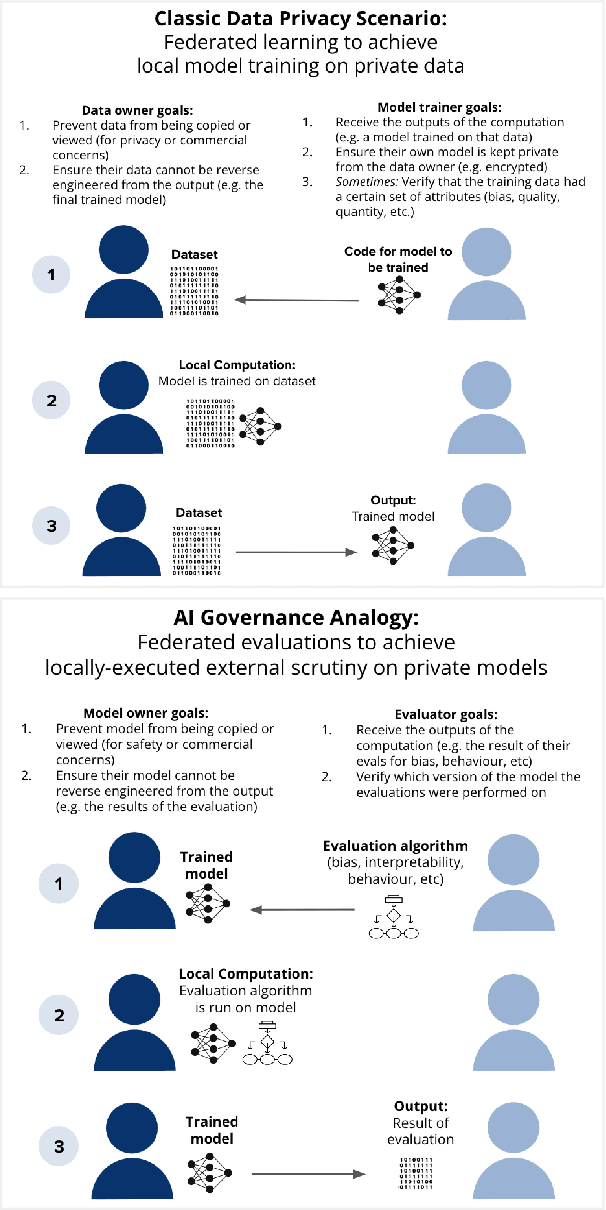
The development of privacy-enhancing technologies has made immense progress in reducing trade-offs between privacy and performance in data exchange and analysis. Similar tools for structured transparency could be useful for AI governance by offering capabilities such as external scrutiny, auditing, and source verification. It is useful to view these different AI governance objectives as a system of information flows in order to avoid partial solutions and significant gaps in governance, as there may be significant overlap in the software stacks needed for the AI governance use cases mentioned in this text. When viewing the system as a whole, the importance of interoperability between these different AI governance solutions becomes clear. Therefore, it is imminently important to look at these problems in AI governance as a system, before these standards, auditing procedures, software, and norms settle into place.
Pluralistic Aging Diffusion Autoencoder
Mar 20, 2023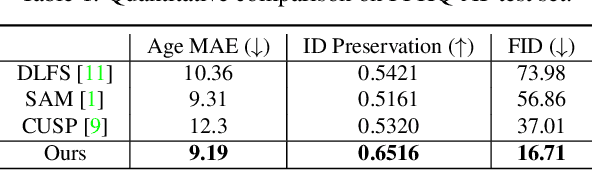

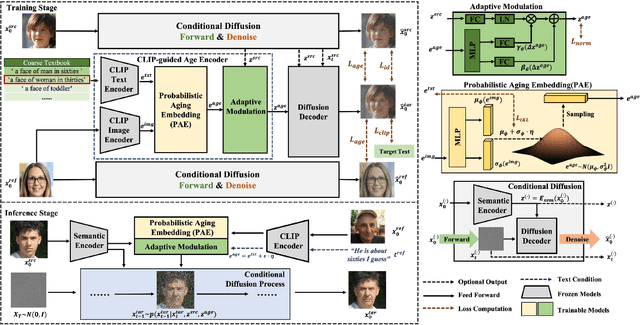
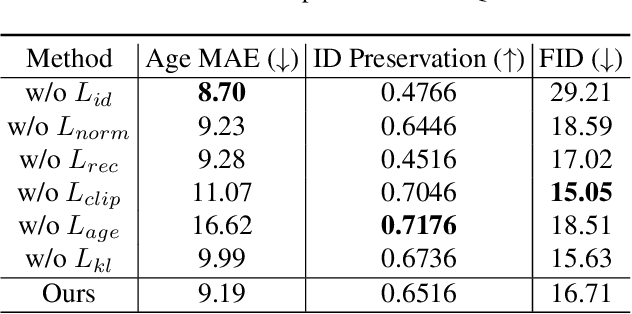
Face aging is an ill-posed problem because multiple plausible aging patterns may correspond to a given input. Most existing methods often produce one deterministic estimation. This paper proposes a novel CLIP-driven Pluralistic Aging Diffusion Autoencoder (PADA) to enhance the diversity of aging patterns. First, we employ diffusion models to generate diverse low-level aging details via a sequential denoising reverse process. Second, we present Probabilistic Aging Embedding (PAE) to capture diverse high-level aging patterns, which represents age information as probabilistic distributions in the common CLIP latent space. A text-guided KL-divergence loss is designed to guide this learning. Our method can achieve pluralistic face aging conditioned on open-world aging texts and arbitrary unseen face images. Qualitative and quantitative experiments demonstrate that our method can generate more diverse and high-quality plausible aging results.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022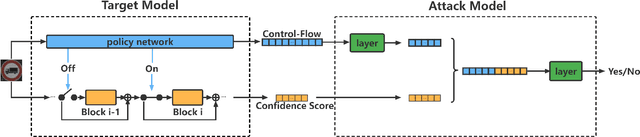
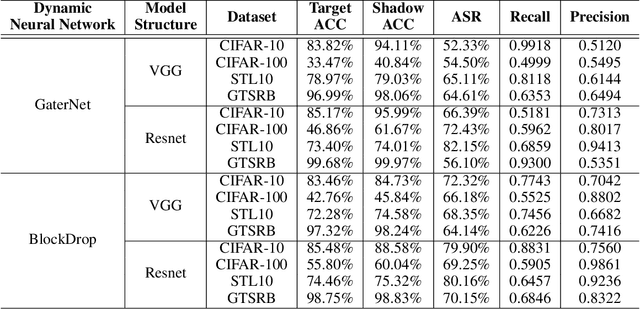
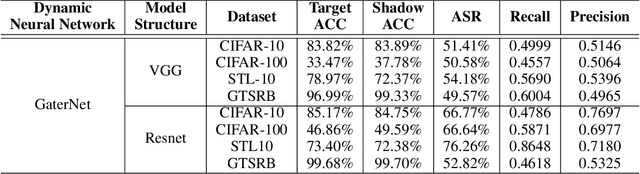

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
Enabling Inter-organizational Analytics in Business Networks Through Meta Machine Learning
Mar 28, 2023
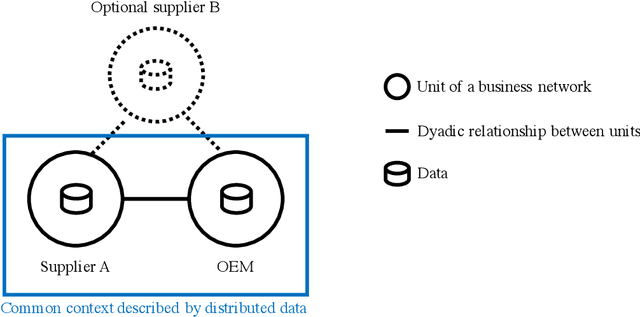
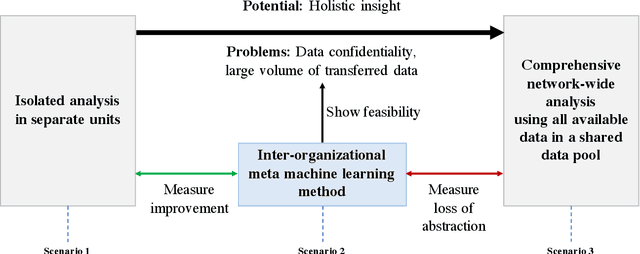

Successful analytics solutions that provide valuable insights often hinge on the connection of various data sources. While it is often feasible to generate larger data pools within organizations, the application of analytics within (inter-organizational) business networks is still severely constrained. As data is distributed across several legal units, potentially even across countries, the fear of disclosing sensitive information as well as the sheer volume of the data that would need to be exchanged are key inhibitors for the creation of effective system-wide solutions -- all while still reaching superior prediction performance. In this work, we propose a meta machine learning method that deals with these obstacles to enable comprehensive analyses within a business network. We follow a design science research approach and evaluate our method with respect to feasibility and performance in an industrial use case. First, we show that it is feasible to perform network-wide analyses that preserve data confidentiality as well as limit data transfer volume. Second, we demonstrate that our method outperforms a conventional isolated analysis and even gets close to a (hypothetical) scenario where all data could be shared within the network. Thus, we provide a fundamental contribution for making business networks more effective, as we remove a key obstacle to tap the huge potential of learning from data that is scattered throughout the network.
Affordance Diffusion: Synthesizing Hand-Object Interactions
Mar 25, 2023
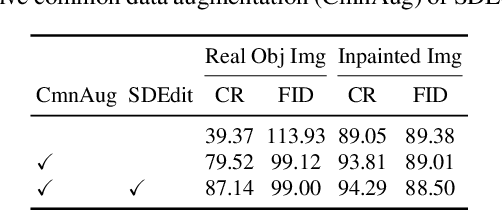
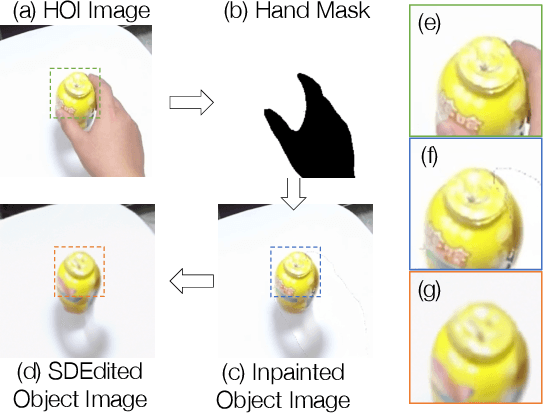

Recent successes in image synthesis are powered by large-scale diffusion models. However, most methods are currently limited to either text- or image-conditioned generation for synthesizing an entire image, texture transfer or inserting objects into a user-specified region. In contrast, in this work we focus on synthesizing complex interactions (ie, an articulated hand) with a given object. Given an RGB image of an object, we aim to hallucinate plausible images of a human hand interacting with it. We propose a two-step generative approach: a LayoutNet that samples an articulation-agnostic hand-object-interaction layout, and a ContentNet that synthesizes images of a hand grasping the object given the predicted layout. Both are built on top of a large-scale pretrained diffusion model to make use of its latent representation. Compared to baselines, the proposed method is shown to generalize better to novel objects and perform surprisingly well on out-of-distribution in-the-wild scenes of portable-sized objects. The resulting system allows us to predict descriptive affordance information, such as hand articulation and approaching orientation. Project page: https://judyye.github.io/affordiffusion-www
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
Mar 25, 2023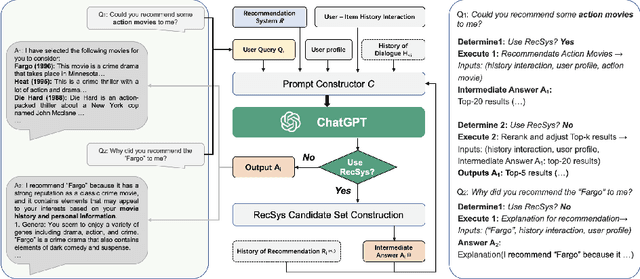


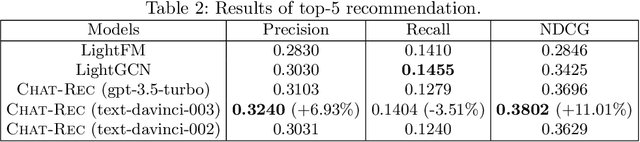
Large language models (LLMs) have demonstrated their significant potential to be applied for addressing various application tasks. However, traditional recommender systems continue to face great challenges such as poor interactivity and explainability, which actually also hinder their broad deployment in real-world systems. To address these limitations, this paper proposes a novel paradigm called Chat-Rec (ChatGPT Augmented Recommender System) that innovatively augments LLMs for building conversational recommender systems by converting user profiles and historical interactions into prompts. Chat-Rec is demonstrated to be effective in learning user preferences and establishing connections between users and products through in-context learning, which also makes the recommendation process more interactive and explainable. What's more, within the Chat-Rec framework, user's preferences can transfer to different products for cross-domain recommendations, and prompt-based injection of information into LLMs can also handle the cold-start scenarios with new items. In our experiments, Chat-Rec effectively improve the results of top-k recommendations and performs better in zero-shot rating prediction task. Chat-Rec offers a novel approach to improving recommender systems and presents new practical scenarios for the implementation of AIGC (AI generated content) in recommender system studies.
DPPMask: Masked Image Modeling with Determinantal Point Processes
Mar 25, 2023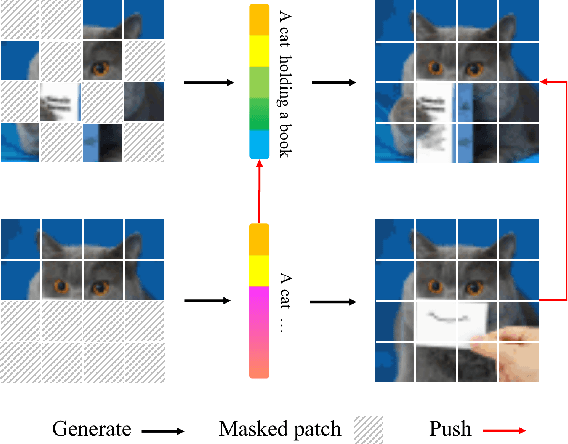
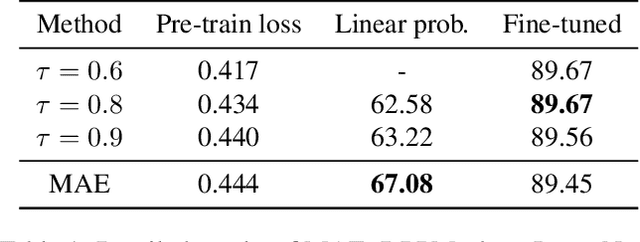
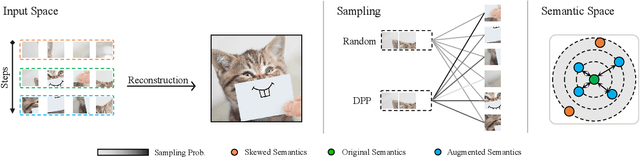
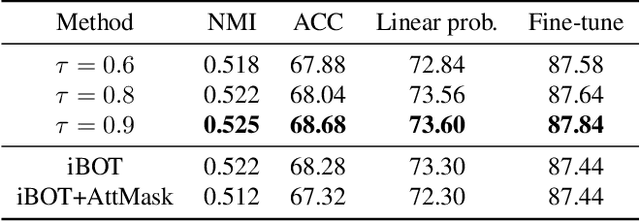
Masked Image Modeling (MIM) has achieved impressive representative performance with the aim of reconstructing randomly masked images. Despite the empirical success, most previous works have neglected the important fact that it is unreasonable to force the model to reconstruct something beyond recovery, such as those masked objects. In this work, we show that uniformly random masking widely used in previous works unavoidably loses some key objects and changes original semantic information, resulting in a misalignment problem and hurting the representative learning eventually. To address this issue, we augment MIM with a new masking strategy namely the DPPMask by substituting the random process with Determinantal Point Process (DPPs) to reduce the semantic change of the image after masking. Our method is simple yet effective and requires no extra learnable parameters when implemented within various frameworks. In particular, we evaluate our method on two representative MIM frameworks, MAE and iBOT. We show that DPPMask surpassed random sampling under both lower and higher masking ratios, indicating that DPPMask makes the reconstruction task more reasonable. We further test our method on the background challenge and multi-class classification tasks, showing that our method is more robust at various tasks.
Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images
Mar 25, 2023
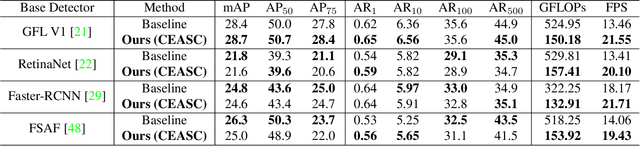
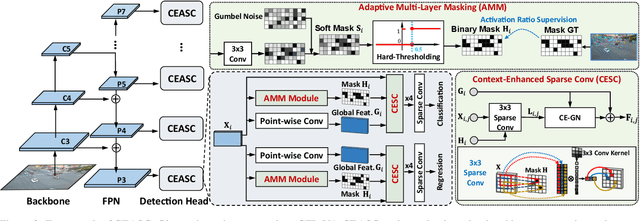
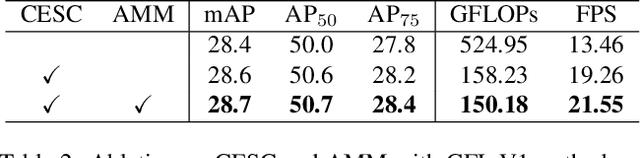
Object detection on drone images with low-latency is an important but challenging task on the resource-constrained unmanned aerial vehicle (UAV) platform. This paper investigates optimizing the detection head based on the sparse convolution, which proves effective in balancing the accuracy and efficiency. Nevertheless, it suffers from inadequate integration of contextual information of tiny objects as well as clumsy control of the mask ratio in the presence of foreground with varying scales. To address the issues above, we propose a novel global context-enhanced adaptive sparse convolutional network (CEASC). It first develops a context-enhanced group normalization (CE-GN) layer, by replacing the statistics based on sparsely sampled features with the global contextual ones, and then designs an adaptive multi-layer masking strategy to generate optimal mask ratios at distinct scales for compact foreground coverage, promoting both the accuracy and efficiency. Extensive experimental results on two major benchmarks, i.e. VisDrone and UAVDT, demonstrate that CEASC remarkably reduces the GFLOPs and accelerates the inference procedure when plugging into the typical state-of-the-art detection frameworks (e.g. RetinaNet and GFL V1) with competitive performance. Code is available at https://github.com/Cuogeihong/CEASC.
DejaVu: Conditional Regenerative Learning to Enhance Dense Prediction
Mar 02, 2023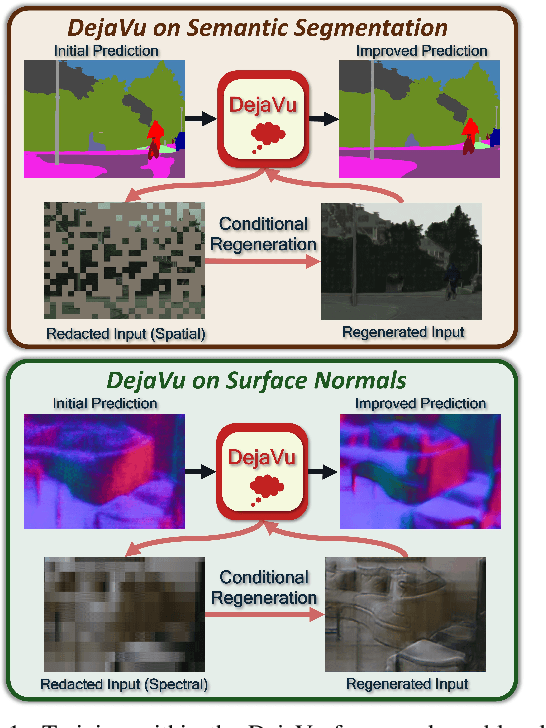
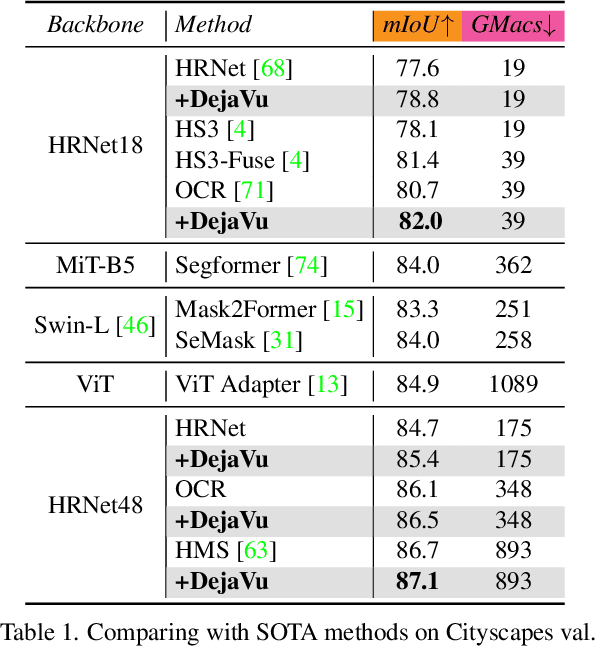
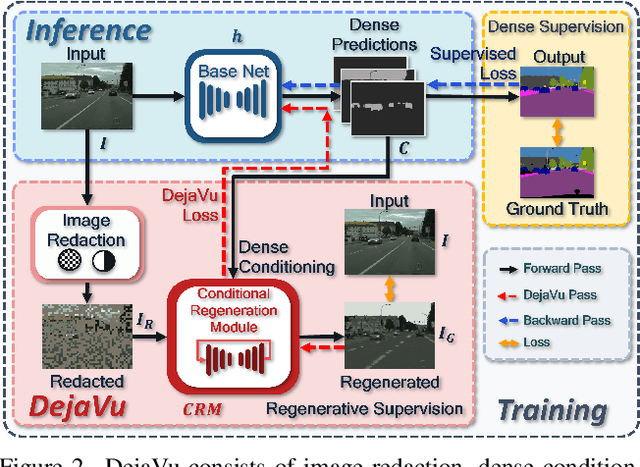
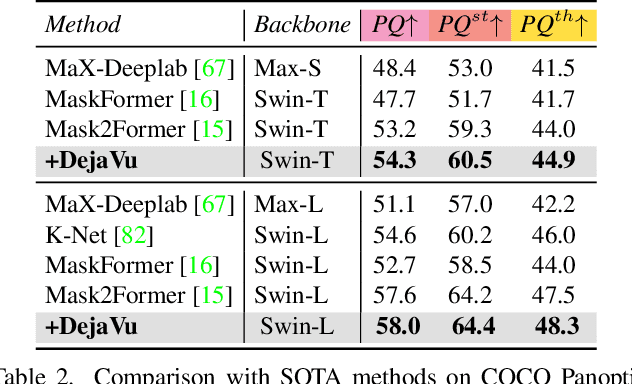
We present DejaVu, a novel framework which leverages conditional image regeneration as additional supervision during training to improve deep networks for dense prediction tasks such as segmentation, depth estimation, and surface normal prediction. First, we apply redaction to the input image, which removes certain structural information by sparse sampling or selective frequency removal. Next, we use a conditional regenerator, which takes the redacted image and the dense predictions as inputs, and reconstructs the original image by filling in the missing structural information. In the redacted image, structural attributes like boundaries are broken while semantic context is largely preserved. In order to make the regeneration feasible, the conditional generator will then require the structure information from the other input source, i.e., the dense predictions. As such, by including this conditional regeneration objective during training, DejaVu encourages the base network to learn to embed accurate scene structure in its dense prediction. This leads to more accurate predictions with clearer boundaries and better spatial consistency. When it is feasible to leverage additional computation, DejaVu can be extended to incorporate an attention-based regeneration module within the dense prediction network, which further improves accuracy. Through extensive experiments on multiple dense prediction benchmarks such as Cityscapes, COCO, ADE20K, NYUD-v2, and KITTI, we demonstrate the efficacy of employing DejaVu during training, as it outperforms SOTA methods at no added computation cost.
InstMove: Instance Motion for Object-centric Video Segmentation
Mar 14, 2023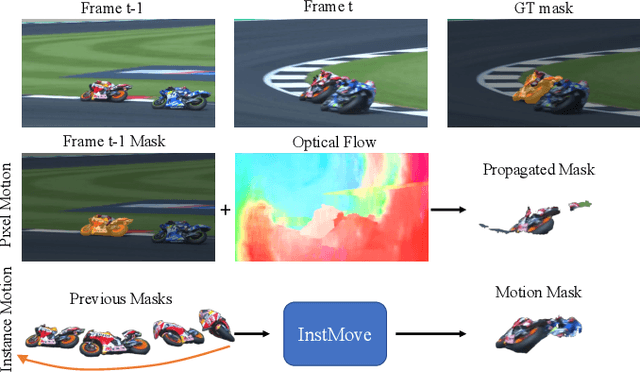
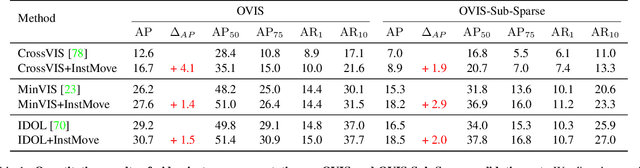
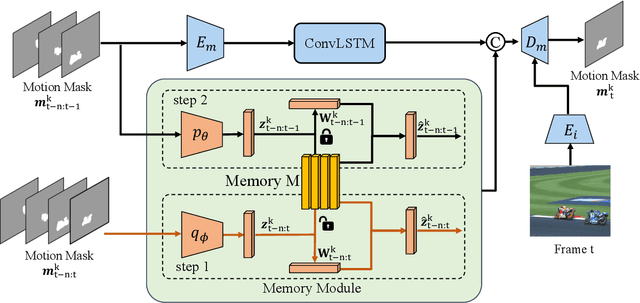

Despite significant efforts, cutting-edge video segmentation methods still remain sensitive to occlusion and rapid movement, due to their reliance on the appearance of objects in the form of object embeddings, which are vulnerable to these disturbances. A common solution is to use optical flow to provide motion information, but essentially it only considers pixel-level motion, which still relies on appearance similarity and hence is often inaccurate under occlusion and fast movement. In this work, we study the instance-level motion and present InstMove, which stands for Instance Motion for Object-centric Video Segmentation. In comparison to pixel-wise motion, InstMove mainly relies on instance-level motion information that is free from image feature embeddings, and features physical interpretations, making it more accurate and robust toward occlusion and fast-moving objects. To better fit in with the video segmentation tasks, InstMove uses instance masks to model the physical presence of an object and learns the dynamic model through a memory network to predict its position and shape in the next frame. With only a few lines of code, InstMove can be integrated into current SOTA methods for three different video segmentation tasks and boost their performance. Specifically, we improve the previous arts by 1.5 AP on OVIS dataset, which features heavy occlusions, and 4.9 AP on YouTubeVIS-Long dataset, which mainly contains fast-moving objects. These results suggest that instance-level motion is robust and accurate, and hence serving as a powerful solution in complex scenarios for object-centric video segmentation.