 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023
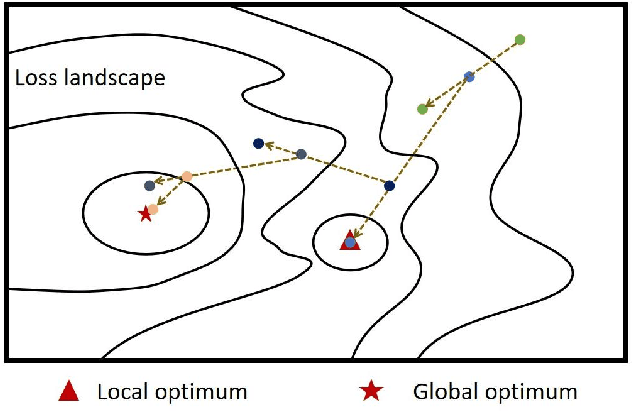
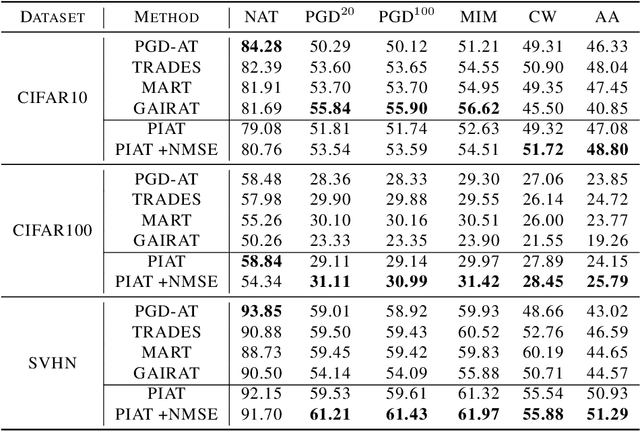
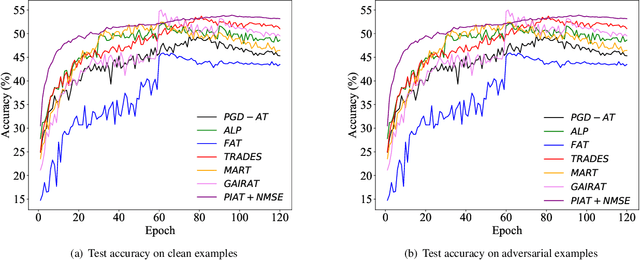
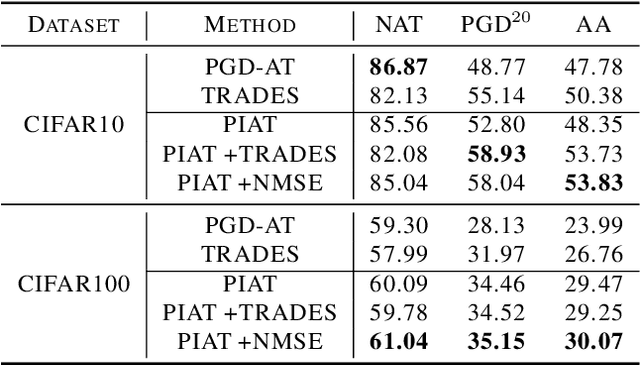
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
Decentralized Multi-Agent Reinforcement Learning for Continuous-Space Stochastic Games
Mar 16, 2023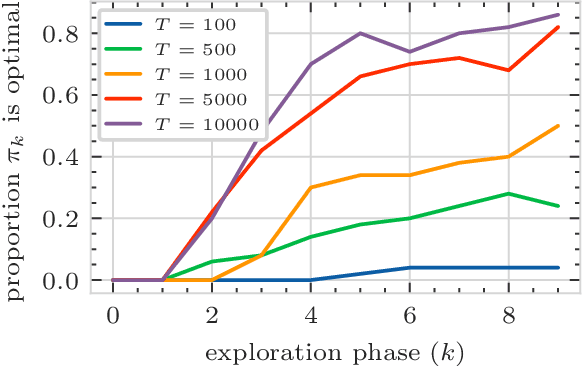
Stochastic games are a popular framework for studying multi-agent reinforcement learning (MARL). Recent advances in MARL have focused primarily on games with finitely many states. In this work, we study multi-agent learning in stochastic games with general state spaces and an information structure in which agents do not observe each other's actions. In this context, we propose a decentralized MARL algorithm and we prove the near-optimality of its policy updates. Furthermore, we study the global policy-updating dynamics for a general class of best-reply based algorithms and derive a closed-form characterization of convergence probabilities over the joint policy space.
Image Quality-aware Diagnosis via Meta-knowledge Co-embedding
Mar 27, 2023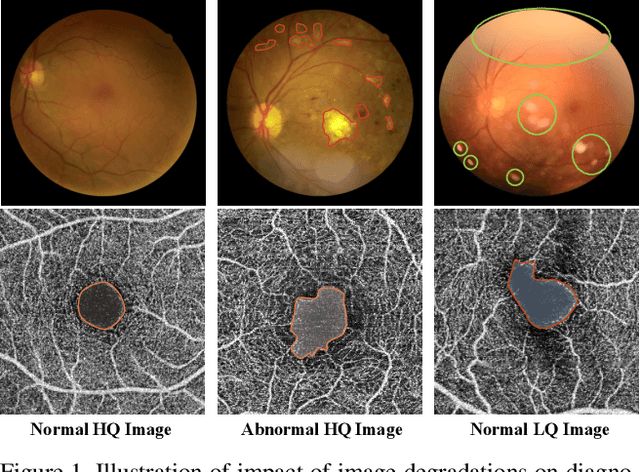
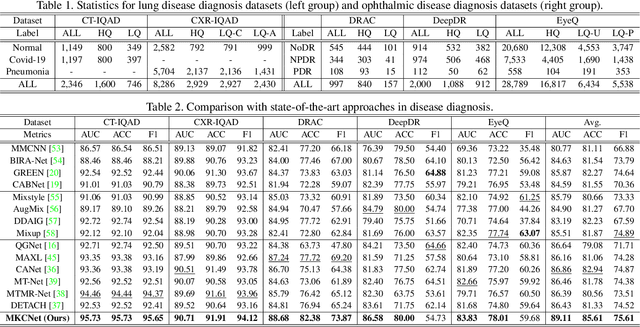
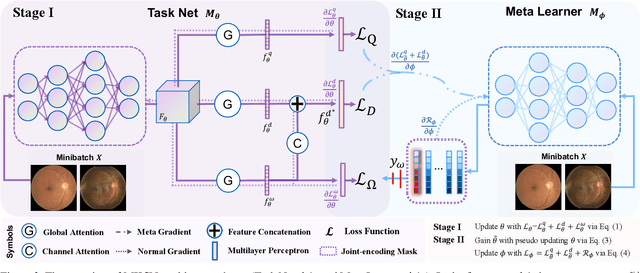
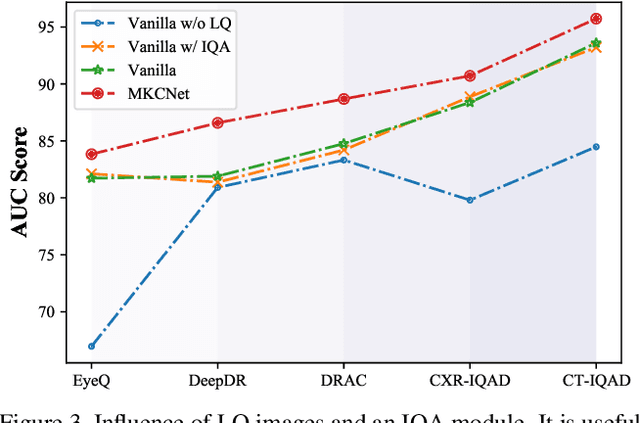
Medical images usually suffer from image degradation in clinical practice, leading to decreased performance of deep learning-based models. To resolve this problem, most previous works have focused on filtering out degradation-causing low-quality images while ignoring their potential value for models. Through effectively learning and leveraging the knowledge of degradations, models can better resist their adverse effects and avoid misdiagnosis. In this paper, we raise the problem of image quality-aware diagnosis, which aims to take advantage of low-quality images and image quality labels to achieve a more accurate and robust diagnosis. However, the diversity of degradations and superficially unrelated targets between image quality assessment and disease diagnosis makes it still quite challenging to effectively leverage quality labels to assist diagnosis. Thus, to tackle these issues, we propose a novel meta-knowledge co-embedding network, consisting of two subnets: Task Net and Meta Learner. Task Net constructs an explicit quality information utilization mechanism to enhance diagnosis via knowledge co-embedding features, while Meta Learner ensures the effectiveness and constrains the semantics of these features via meta-learning and joint-encoding masking. Superior performance on five datasets with four widely-used medical imaging modalities demonstrates the effectiveness and generalizability of our method.
Progressive Semantic-Visual Mutual Adaption for Generalized Zero-Shot Learning
Mar 27, 2023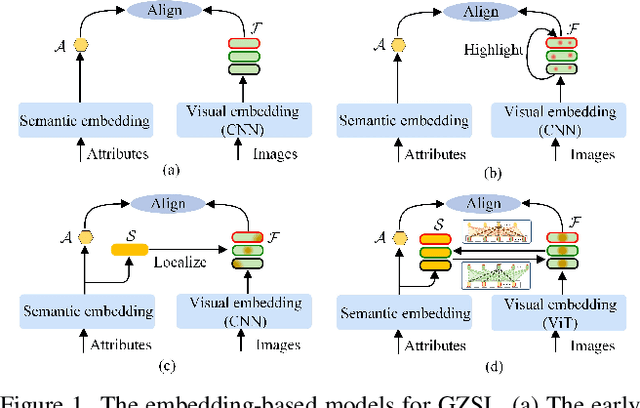
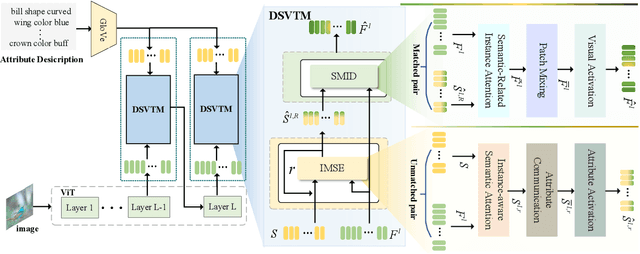
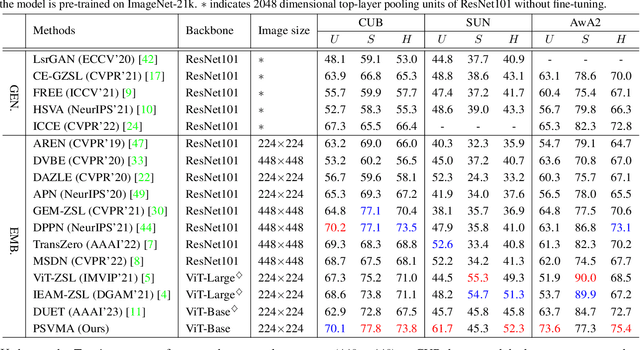
Generalized Zero-Shot Learning (GZSL) identifies unseen categories by knowledge transferred from the seen domain, relying on the intrinsic interactions between visual and semantic information. Prior works mainly localize regions corresponding to the sharing attributes. When various visual appearances correspond to the same attribute, the sharing attributes inevitably introduce semantic ambiguity, hampering the exploration of accurate semantic-visual interactions. In this paper, we deploy the dual semantic-visual transformer module (DSVTM) to progressively model the correspondences between attribute prototypes and visual features, constituting a progressive semantic-visual mutual adaption (PSVMA) network for semantic disambiguation and knowledge transferability improvement. Specifically, DSVTM devises an instance-motivated semantic encoder that learns instance-centric prototypes to adapt to different images, enabling the recast of the unmatched semantic-visual pair into the matched one. Then, a semantic-motivated instance decoder strengthens accurate cross-domain interactions between the matched pair for semantic-related instance adaption, encouraging the generation of unambiguous visual representations. Moreover, to mitigate the bias towards seen classes in GZSL, a debiasing loss is proposed to pursue response consistency between seen and unseen predictions. The PSVMA consistently yields superior performances against other state-of-the-art methods. Code will be available at: https://github.com/ManLiuCoder/PSVMA.
Towards Artistic Image Aesthetics Assessment: a Large-scale Dataset and a New Method
Mar 27, 2023
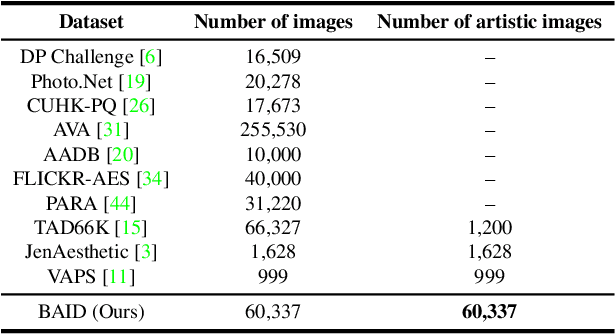
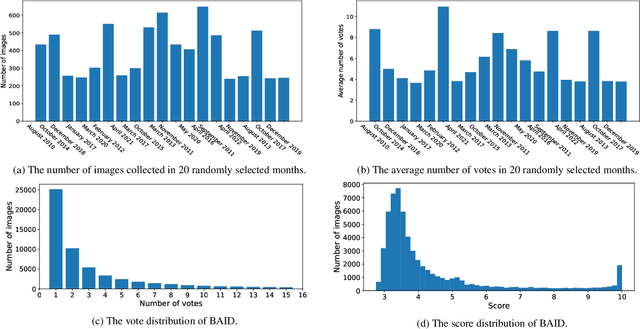

Image aesthetics assessment (IAA) is a challenging task due to its highly subjective nature. Most of the current studies rely on large-scale datasets (e.g., AVA and AADB) to learn a general model for all kinds of photography images. However, little light has been shed on measuring the aesthetic quality of artistic images, and the existing datasets only contain relatively few artworks. Such a defect is a great obstacle to the aesthetic assessment of artistic images. To fill the gap in the field of artistic image aesthetics assessment (AIAA), we first introduce a large-scale AIAA dataset: Boldbrush Artistic Image Dataset (BAID), which consists of 60,337 artistic images covering various art forms, with more than 360,000 votes from online users. We then propose a new method, SAAN (Style-specific Art Assessment Network), which can effectively extract and utilize style-specific and generic aesthetic information to evaluate artistic images. Experiments demonstrate that our proposed approach outperforms existing IAA methods on the proposed BAID dataset according to quantitative comparisons. We believe the proposed dataset and method can serve as a foundation for future AIAA works and inspire more research in this field. Dataset and code are available at: https://github.com/Dreemurr-T/BAID.git
Beyond Accuracy: A Critical Review of Fairness in Machine Learning for Mobile and Wearable Computing
Mar 27, 2023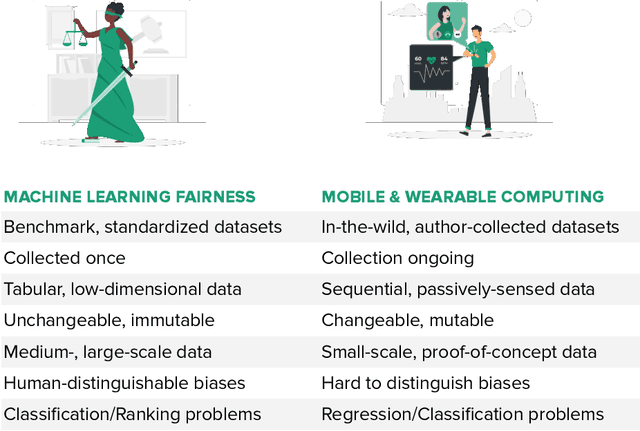
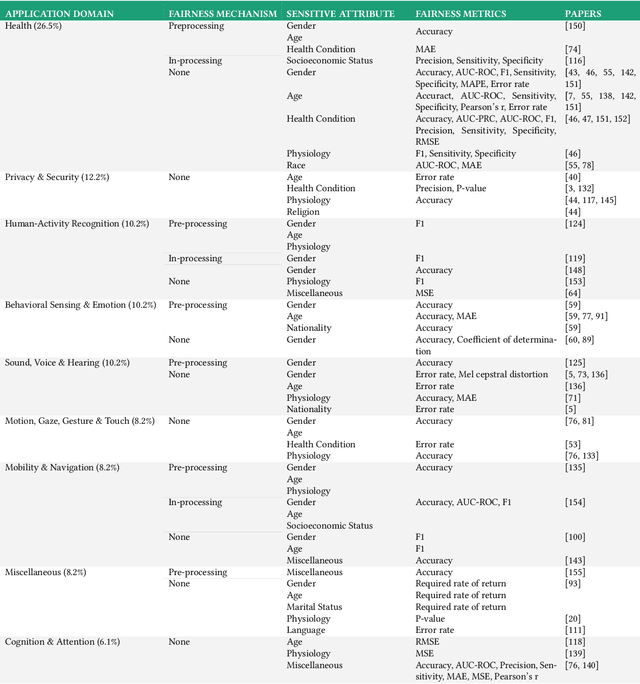
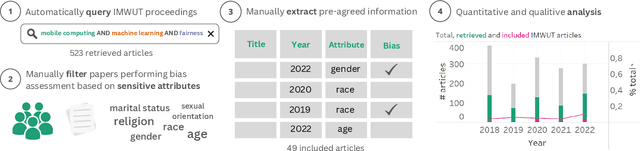

The field of mobile, wearable, and ubiquitous computing (UbiComp) is undergoing a revolutionary integration of machine learning. Devices can now diagnose diseases, predict heart irregularities, and unlock the full potential of human cognition. However, the underlying algorithms are not immune to biases with respect to sensitive attributes (e.g., gender, race), leading to discriminatory outcomes. The research communities of HCI and AI-Ethics have recently started to explore ways of reporting information about datasets to surface and, eventually, counter those biases. The goal of this work is to explore the extent to which the UbiComp community has adopted such ways of reporting and highlight potential shortcomings. Through a systematic review of papers published in the Proceedings of the ACM Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) journal over the past 5 years (2018-2022), we found that progress on algorithmic fairness within the UbiComp community lags behind. Our findings show that only a small portion (5%) of published papers adheres to modern fairness reporting, while the overwhelming majority thereof focuses on accuracy or error metrics. In light of these findings, our work provides practical guidelines for the design and development of ubiquitous technologies that not only strive for accuracy but also for fairness.
Target Defense against Periodically Arriving Intruders
Mar 09, 2023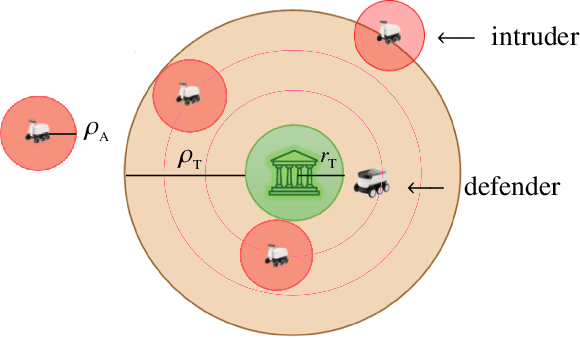
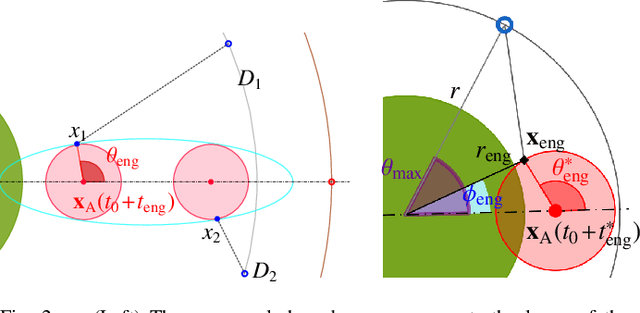
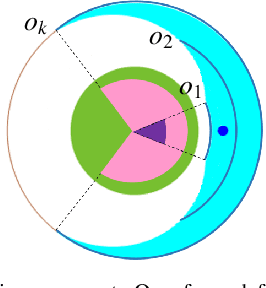
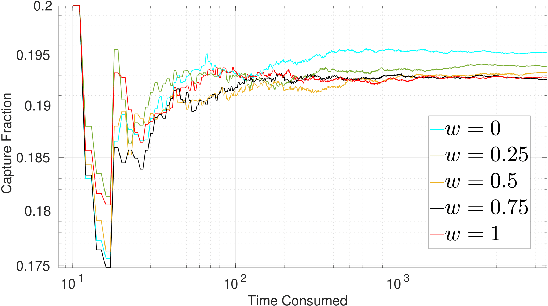
We consider a variant of pursuit-evasion games where a single defender is tasked to defend a static target from a sequence of periodically arriving intruders. The intruders' objective is to breach the boundary of a circular target without being captured and the defender's objective is to capture as many intruders as possible. At the beginning of each period, a new intruder appears at a random location on the perimeter of a fixed circle surrounding the target and moves radially towards the target center to breach the target. The intruders are slower in speed compared to the defender and they have their own sensing footprint through which they can perfectly detect the defender if it is within their sensing range. Considering the speed and sensing limitations of the agents, we analyze the entire game by dividing it into partial information and full information phases. We address the defender's capturability using the notions of engagement surface and capture circle. We develop and analyze three efficient strategies for the defender and derive a lower bound on the capture fraction. Finally, we conduct a series of simulations and numerical experiments to compare and contrast the three proposed approaches.
Hybrid Traffic Control and Coordination from Pixels
Feb 17, 2023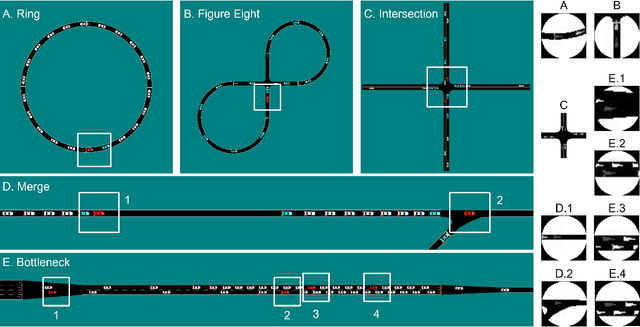

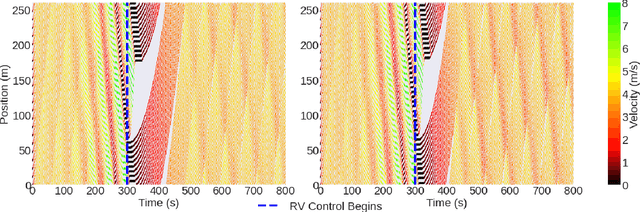

Traffic congestion is a persistent problem in our society. Existing methods for traffic control have proven futile in alleviating current congestion levels leading researchers to explore ideas with robot vehicles given the increased emergence of vehicles with different levels of autonomy on our roads. This gives rise to hybrid traffic control, where robot vehicles regulate human-driven vehicles, through reinforcement learning (RL). However, most existing studies use precise observations that involve global information, such as network throughput, as well as local information, such as vehicle positions and velocities. Obtaining this information requires updating existing road infrastructure with vast sensor networks and communication to potentially unwilling human drivers. We consider image observations as the alternative for hybrid traffic control via RL: 1) images are readily available through satellite imagery, in-car camera systems, and traffic monitoring systems; 2) Images do not require a complete re-imagination of the observation space from network to network; and 3) images only require communication to equipment. In this work, we show that robot vehicles using image observations can achieve similar performance to using precise information on networks, including ring, figure eight, merge, bottleneck, and intersections. We also demonstrate increased performance (up to 26%) in certain cases on tested networks, despite only using local traffic information as opposed to global traffic information.
GrapeQA: GRaph Augmentation and Pruning to Enhance Question-Answering
Mar 22, 2023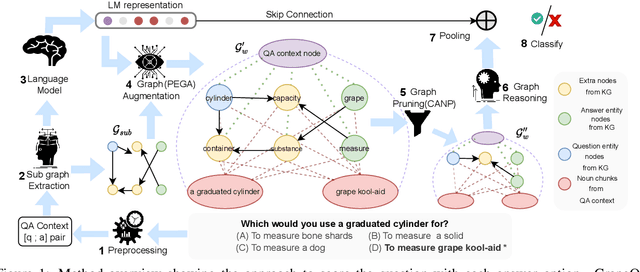
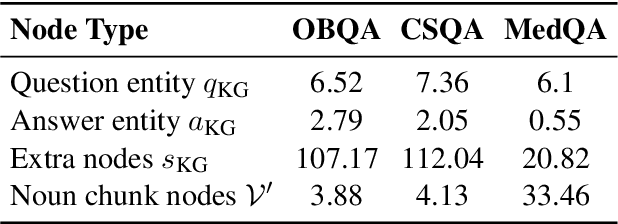
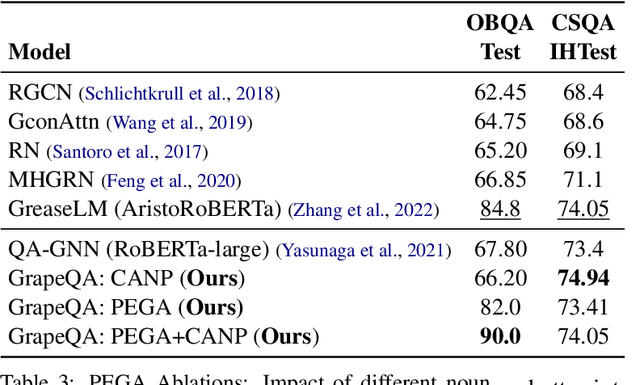

Commonsense question-answering (QA) methods combine the power of pre-trained Language Models (LM) with the reasoning provided by Knowledge Graphs (KG). A typical approach collects nodes relevant to the QA pair from a KG to form a Working Graph (WG) followed by reasoning using Graph Neural Networks(GNNs). This faces two major challenges: (i) it is difficult to capture all the information from the QA in the WG, and (ii) the WG contains some irrelevant nodes from the KG. To address these, we propose GrapeQA with two simple improvements on the WG: (i) Prominent Entities for Graph Augmentation identifies relevant text chunks from the QA pair and augments the WG with corresponding latent representations from the LM, and (ii) Context-Aware Node Pruning removes nodes that are less relevant to the QA pair. We evaluate our results on OpenBookQA, CommonsenseQA and MedQA-USMLE and see that GrapeQA shows consistent improvements over its LM + KG predecessor (QA-GNN in particular) and large improvements on OpenBookQA.
LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
Mar 22, 2023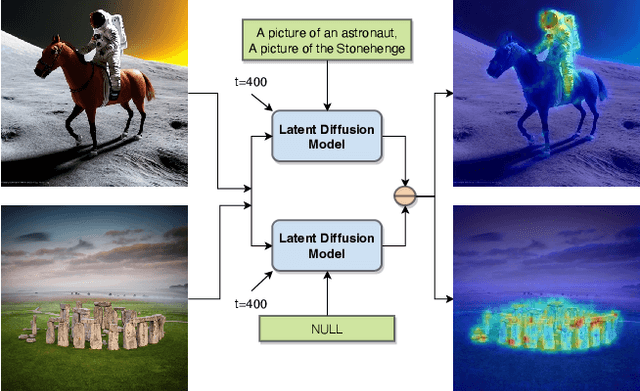
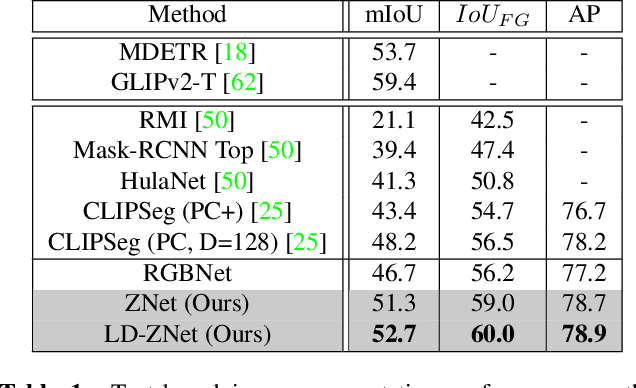
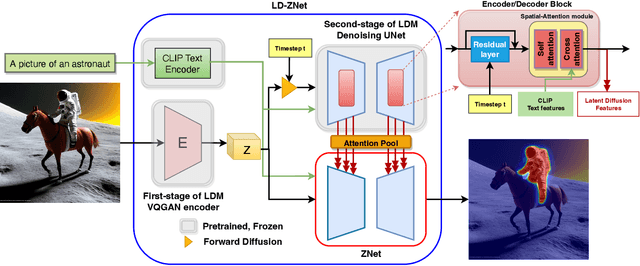
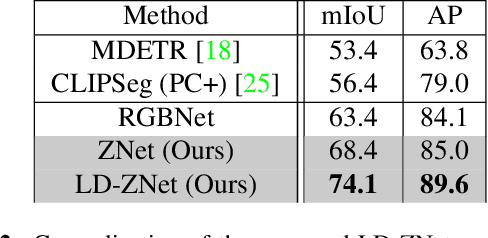
We present a technique for segmenting real and AI-generated images using latent diffusion models (LDMs) trained on internet-scale datasets. First, we show that the latent space of LDMs (z-space) is a better input representation compared to other feature representations like RGB images or CLIP encodings for text-based image segmentation. By training the segmentation models on the latent z-space, which creates a compressed representation across several domains like different forms of art, cartoons, illustrations, and photographs, we are also able to bridge the domain gap between real and AI-generated images. We show that the internal features of LDMs contain rich semantic information and present a technique in the form of LD-ZNet to further boost the performance of text-based segmentation. Overall, we show up to 6% improvement over standard baselines for text-to-image segmentation on natural images. For AI-generated imagery, we show close to 20% improvement compared to state-of-the-art techniques.