 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DWFormer: Dynamic Window transFormer for Speech Emotion Recognition
Mar 03, 2023
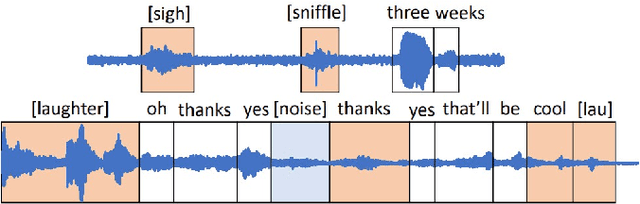
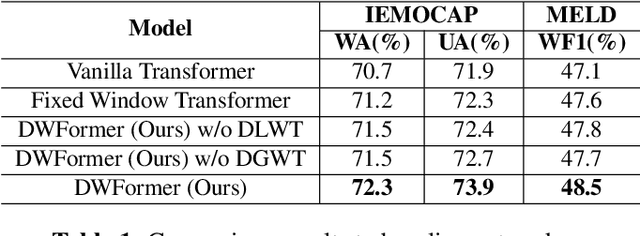
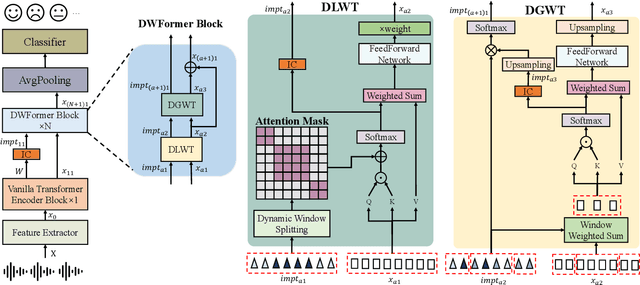
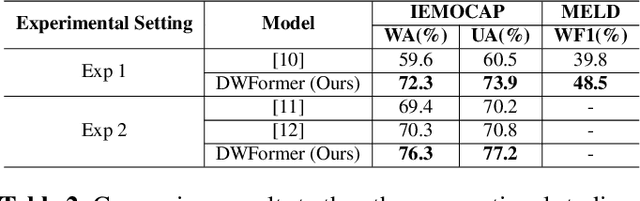
Speech emotion recognition is crucial to human-computer interaction. The temporal regions that represent different emotions scatter in different parts of the speech locally. Moreover, the temporal scales of important information may vary over a large range within and across speech segments. Although transformer-based models have made progress in this field, the existing models could not precisely locate important regions at different temporal scales. To address the issue, we propose Dynamic Window transFormer (DWFormer), a new architecture that leverages temporal importance by dynamically splitting samples into windows. Self-attention mechanism is applied within windows for capturing temporal important information locally in a fine-grained way. Cross-window information interaction is also taken into account for global communication. DWFormer is evaluated on both the IEMOCAP and the MELD datasets. Experimental results show that the proposed model achieves better performance than the previous state-of-the-art methods.
Group Testing with Side Information via Generalized Approximate Message Passing
Nov 07, 2022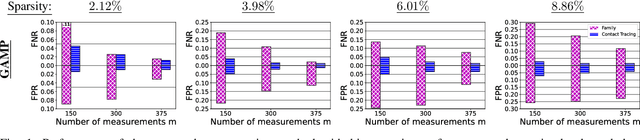
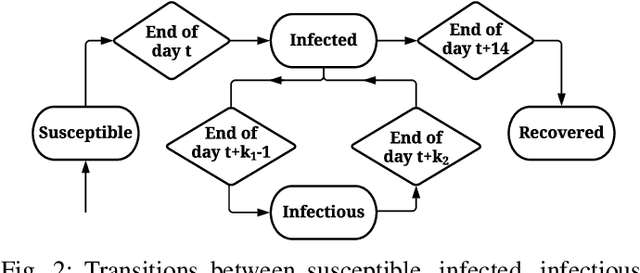
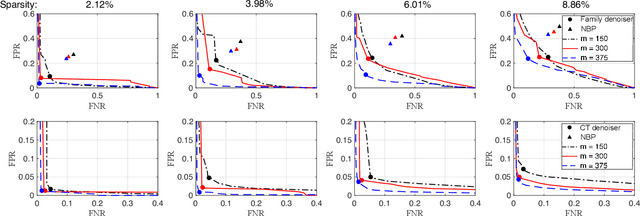
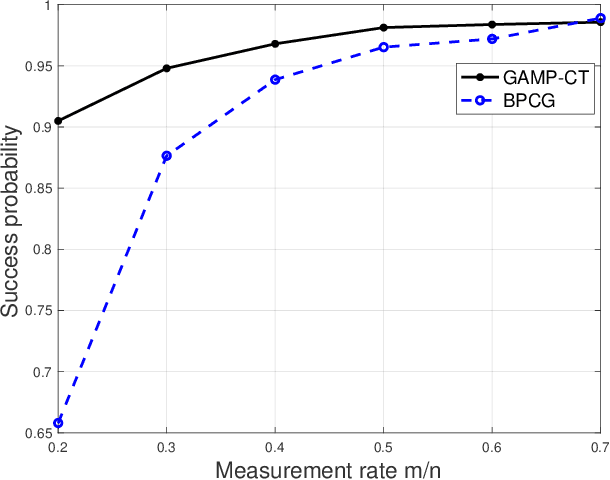
Group testing can help maintain a widespread testing program using fewer resources amid a pandemic. In a group testing setup, we are given n samples, one per individual. Each individual is either infected or uninfected. These samples are arranged into m < n pooled samples, where each pool is obtained by mixing a subset of the n individual samples. Infected individuals are then identified using a group testing algorithm. In this paper, we incorporate side information (SI) collected from contact tracing (CT) into nonadaptive/single-stage group testing algorithms. We generate different types of possible CT SI data by incorporating different possible characteristics of the spread of the disease. These data are fed into a group testing framework based on generalized approximate message passing (GAMP). Numerical results show that our GAMP-based algorithms provide improved accuracy. Compared to a loopy belief propagation algorithm, our proposed framework can increase the success probability by 0.25 for a group testing problem of n = 500 individuals with m = 100 pooled samples.
Beyond Empirical Risk Minimization: Local Structure Preserving Regularization for Improving Adversarial Robustness
Mar 29, 2023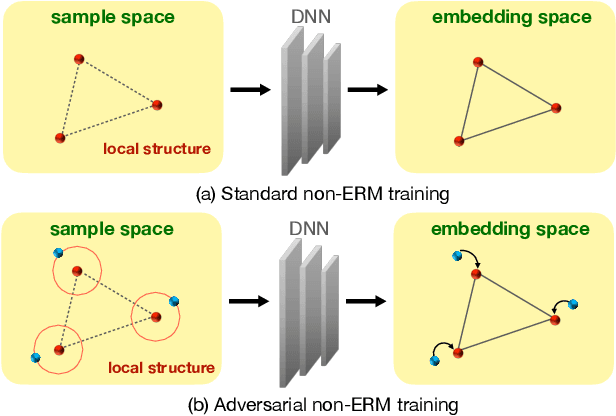

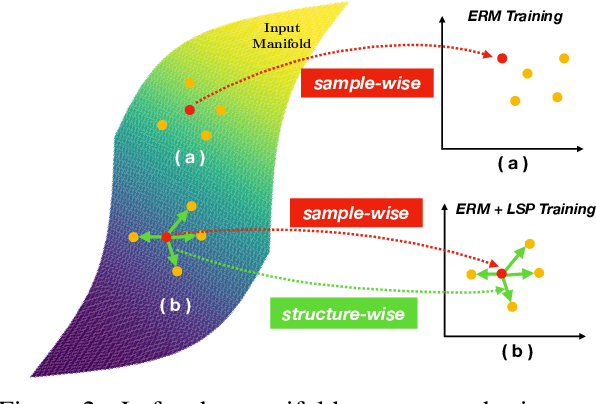

It is broadly known that deep neural networks are susceptible to being fooled by adversarial examples with perturbations imperceptible by humans. Various defenses have been proposed to improve adversarial robustness, among which adversarial training methods are most effective. However, most of these methods treat the training samples independently and demand a tremendous amount of samples to train a robust network, while ignoring the latent structural information among these samples. In this work, we propose a novel Local Structure Preserving (LSP) regularization, which aims to preserve the local structure of the input space in the learned embedding space. In this manner, the attacking effect of adversarial samples lying in the vicinity of clean samples can be alleviated. We show strong empirical evidence that with or without adversarial training, our method consistently improves the performance of adversarial robustness on several image classification datasets compared to the baselines and some state-of-the-art approaches, thus providing promising direction for future research.
AirLine: Efficient Learnable Line Detection with Local Edge Voting
Mar 29, 2023
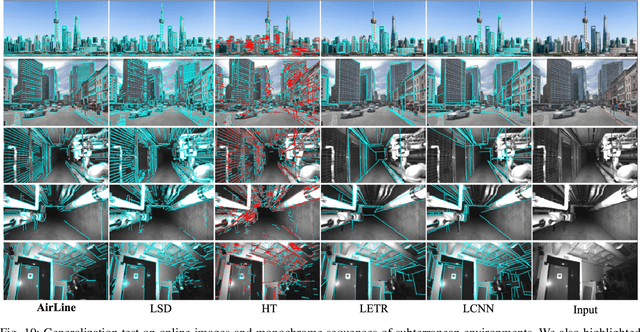

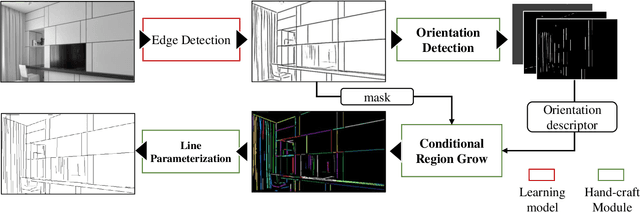
Line detection is widely used in many robotic tasks such as scene recognition, 3D reconstruction, and simultaneous localization and mapping (SLAM). Compared to points, lines can provide both low-level and high-level geometrical information for downstream tasks. In this paper, we propose a novel edge-based line detection algorithm, AirLine, which can be applied to various tasks. In contrast to existing learnable endpoint-based methods which are sensitive to the geometrical condition of environments, AirLine can extract line segments directly from edges, resulting in a better generalization ability for unseen environments. Also to balance efficiency and accuracy, we introduce a region-grow algorithm and local edge voting scheme for line parameterization. To the best of our knowledge, AirLine is one of the first learnable edge-based line detection methods. Our extensive experiments show that it retains state-of-the-art-level precision yet with a 3-80 times runtime acceleration compared to other learning-based methods, which is critical for low-power robots.
Transformer and Snowball Graph Convolution Learning for Biomedical Graph Classification
Mar 28, 2023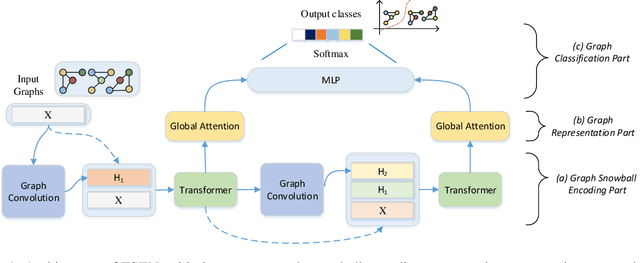
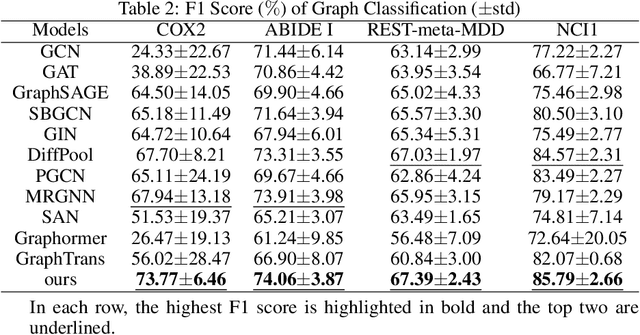

Graph or network has been widely used for describing and modeling complex systems in biomedicine. Deep learning methods, especially graph neural networks (GNNs), have been developed to learn and predict with such structured data. In this paper, we proposed a novel transformer and snowball encoding networks (TSEN) for biomedical graph classification, which introduced transformer architecture with graph snowball connection into GNNs for learning whole-graph representation. TSEN combined graph snowball connection with graph transformer by snowball encoding layers, which enhanced the power to capture multi-scale information and global patterns to learn the whole-graph features. On the other hand, TSEN also used snowball graph convolution as position embedding in transformer structure, which was a simple yet effective method for capturing local patterns naturally. Results of experiments using four graph classification datasets demonstrated that TSEN outperformed the state-of-the-art typical GNN models and the graph-transformer based GNN models.
Robustifying Token Attention for Vision Transformers
Mar 20, 2023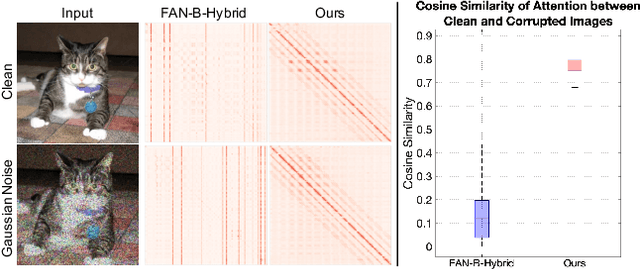
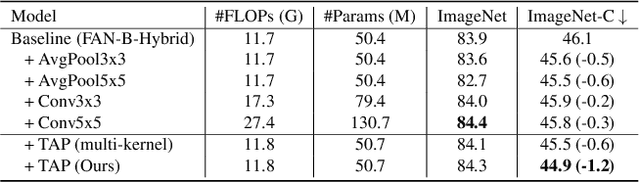
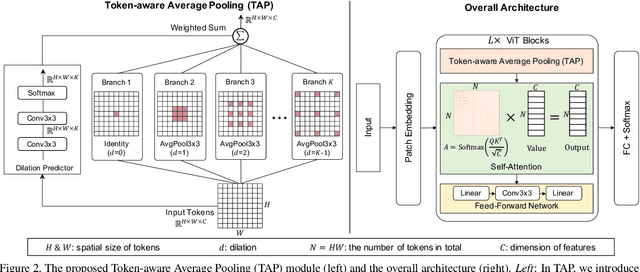
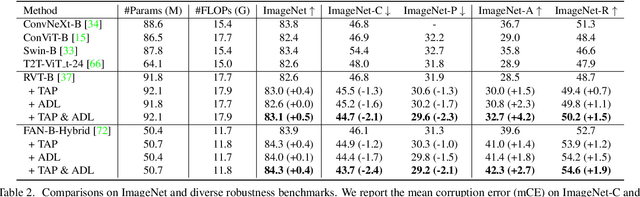
Despite the success of vision transformers (ViTs), they still suffer from significant drops in accuracy in the presence of common corruptions, such as noise or blur. Interestingly, we observe that the attention mechanism of ViTs tends to rely on few important tokens, a phenomenon we call token overfocusing. More critically, these tokens are not robust to corruptions, often leading to highly diverging attention patterns. In this paper, we intend to alleviate this overfocusing issue and make attention more stable through two general techniques: First, our Token-aware Average Pooling (TAP) module encourages the local neighborhood of each token to take part in the attention mechanism. Specifically, TAP learns average pooling schemes for each token such that the information of potentially important tokens in the neighborhood can adaptively be taken into account. Second, we force the output tokens to aggregate information from a diverse set of input tokens rather than focusing on just a few by using our Attention Diversification Loss (ADL). We achieve this by penalizing high cosine similarity between the attention vectors of different tokens. In experiments, we apply our methods to a wide range of transformer architectures and improve robustness significantly. For example, we improve corruption robustness on ImageNet-C by 2.4% while simultaneously improving accuracy by 0.4% based on state-of-the-art robust architecture FAN. Also, when finetuning on semantic segmentation tasks, we improve robustness on CityScapes-C by 2.4% and ACDC by 3.1%.
LFACon: Introducing Anglewise Attention to No-Reference Quality Assessment in Light Field Space
Mar 20, 2023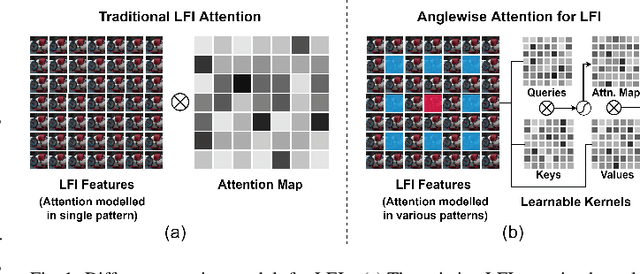
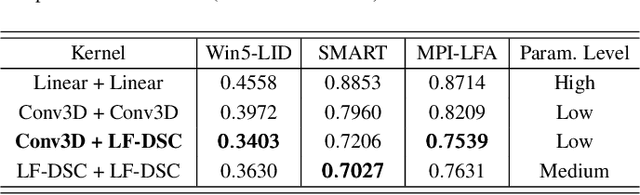
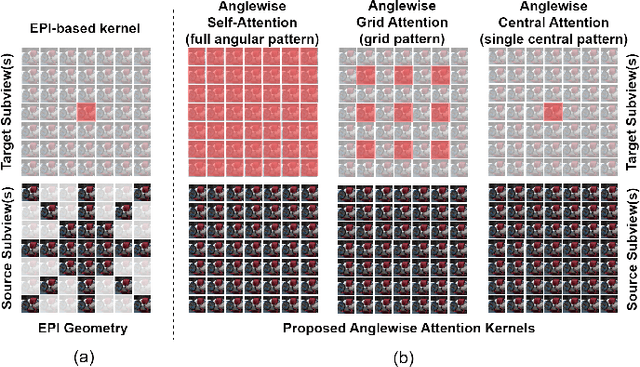
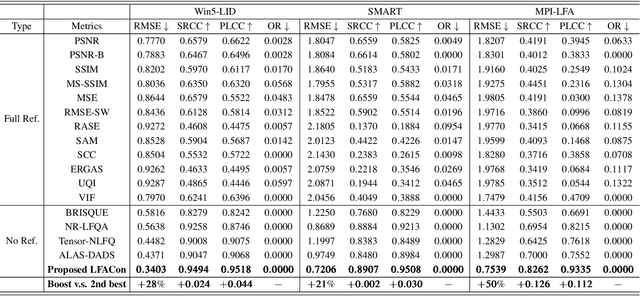
Light field imaging can capture both the intensity information and the direction information of light rays. It naturally enables a six-degrees-of-freedom viewing experience and deep user engagement in virtual reality. Compared to 2D image assessment, light field image quality assessment (LFIQA) needs to consider not only the image quality in the spatial domain but also the quality consistency in the angular domain. However, there is a lack of metrics to effectively reflect the angular consistency and thus the angular quality of a light field image (LFI). Furthermore, the existing LFIQA metrics suffer from high computational costs due to the excessive data volume of LFIs. In this paper, we propose a novel concept of "anglewise attention" by introducing a multihead self-attention mechanism to the angular domain of an LFI. This mechanism better reflects the LFI quality. In particular, we propose three new attention kernels, including anglewise self-attention, anglewise grid attention, and anglewise central attention. These attention kernels can realize angular self-attention, extract multiangled features globally or selectively, and reduce the computational cost of feature extraction. By effectively incorporating the proposed kernels, we further propose our light field attentional convolutional neural network (LFACon) as an LFIQA metric. Our experimental results show that the proposed LFACon metric significantly outperforms the state-of-the-art LFIQA metrics. For the majority of distortion types, LFACon attains the best performance with lower complexity and less computational time.
Good Neighbors Are All You Need for Chinese Grapheme-to-Phoneme Conversion
Mar 14, 2023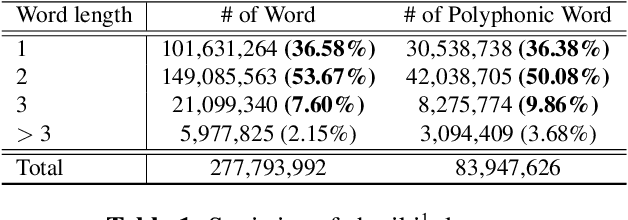
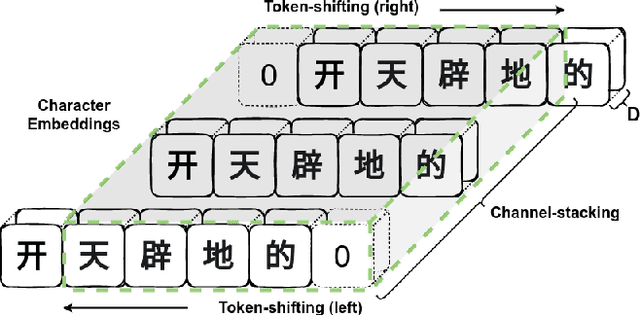
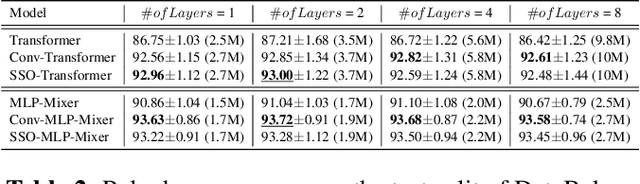

Most Chinese Grapheme-to-Phoneme (G2P) systems employ a three-stage framework that first transforms input sequences into character embeddings, obtains linguistic information using language models, and then predicts the phonemes based on global context about the entire input sequence. However, linguistic knowledge alone is often inadequate. Language models frequently encode overly general structures of a sentence and fail to cover specific cases needed to use phonetic knowledge. Also, a handcrafted post-processing system is needed to address the problems relevant to the tone of the characters. However, the system exhibits inconsistency in the segmentation of word boundaries which consequently degrades the performance of the G2P system. To address these issues, we propose the Reinforcer that provides strong inductive bias for language models by emphasizing the phonological information between neighboring characters to help disambiguate pronunciations. Experimental results show that the Reinforcer boosts the cutting-edge architectures by a large margin. We also combine the Reinforcer with a large-scale pre-trained model and demonstrate the validity of using neighboring context in knowledge transfer scenarios.
MM-BSN: Self-Supervised Image Denoising for Real-World with Multi-Mask based on Blind-Spot Network
Apr 04, 2023

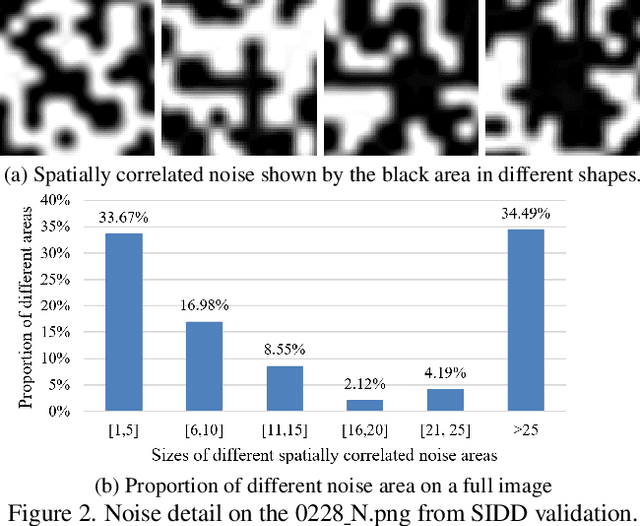
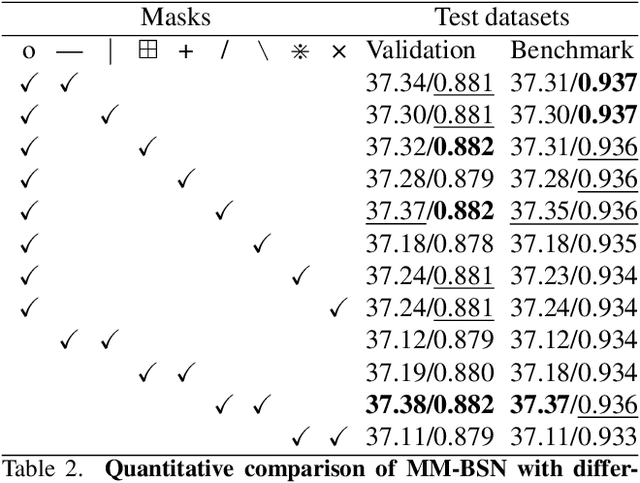
Recent advances in deep learning have been pushing image denoising techniques to a new level. In self-supervised image denoising, blind-spot network (BSN) is one of the most common methods. However, most of the existing BSN algorithms use a dot-based central mask, which is recognized as inefficient for images with large-scale spatially correlated noise. In this paper, we give the definition of large-noise and propose a multi-mask strategy using multiple convolutional kernels masked in different shapes to further break the noise spatial correlation. Furthermore, we propose a novel self-supervised image denoising method that combines the multi-mask strategy with BSN (MM-BSN). We show that different masks can cause significant performance differences, and the proposed MM-BSN can efficiently fuse the features extracted by multi-masked layers, while recovering the texture structures destroyed by multi-masking and information transmission. Our MM-BSN can be used to address the problem of large-noise denoising, which cannot be efficiently handled by other BSN methods. Extensive experiments on public real-world datasets demonstrate that the proposed MM-BSN achieves state-of-the-art performance among self-supervised and even unpaired image denoising methods for sRGB images denoising, without any labelling effort or prior knowledge. Code can be found in https://github.com/dannie125/MM-BSN.
Divided Attention: Unsupervised Multi-Object Discovery with Contextually Separated Slots
Apr 04, 2023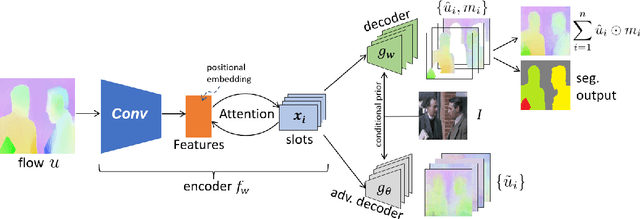
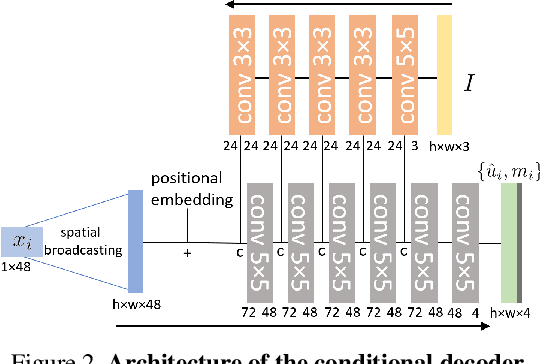
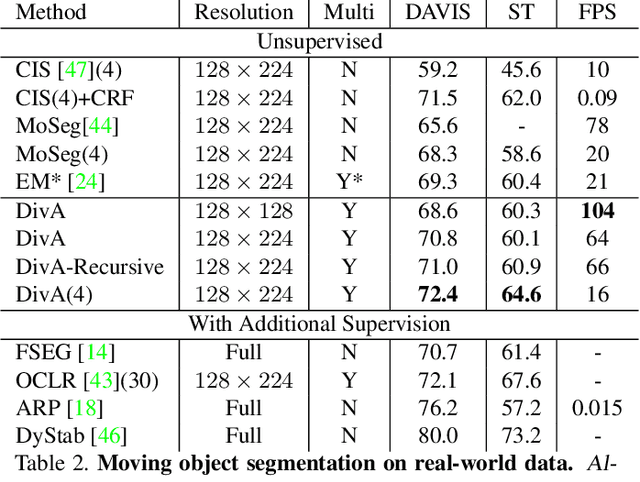

We introduce a method to segment the visual field into independently moving regions, trained with no ground truth or supervision. It consists of an adversarial conditional encoder-decoder architecture based on Slot Attention, modified to use the image as context to decode optical flow without attempting to reconstruct the image itself. In the resulting multi-modal representation, one modality (flow) feeds the encoder to produce separate latent codes (slots), whereas the other modality (image) conditions the decoder to generate the first (flow) from the slots. This design frees the representation from having to encode complex nuisance variability in the image due to, for instance, illumination and reflectance properties of the scene. Since customary autoencoding based on minimizing the reconstruction error does not preclude the entire flow from being encoded into a single slot, we modify the loss to an adversarial criterion based on Contextual Information Separation. The resulting min-max optimization fosters the separation of objects and their assignment to different attention slots, leading to Divided Attention, or DivA. DivA outperforms recent unsupervised multi-object motion segmentation methods while tripling run-time speed up to 104FPS and reducing the performance gap from supervised methods to 12% or less. DivA can handle different numbers of objects and different image sizes at training and test time, is invariant to permutation of object labels, and does not require explicit regularization.