 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SoftMatch Distance: A Novel Distance for Weakly-Supervised Trend Change Detection in Bi-Temporal Images
Mar 08, 2023
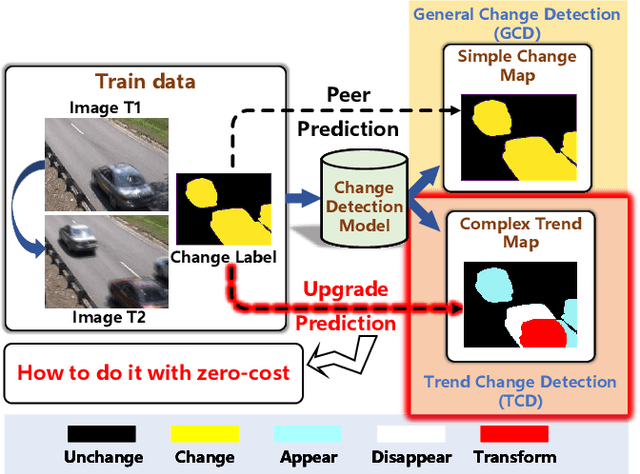
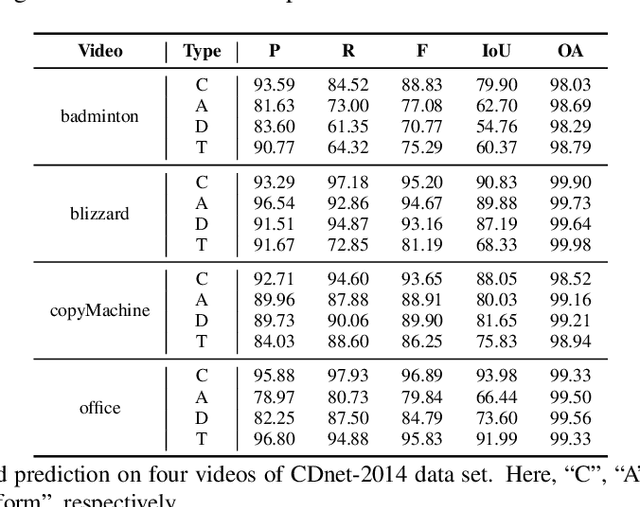
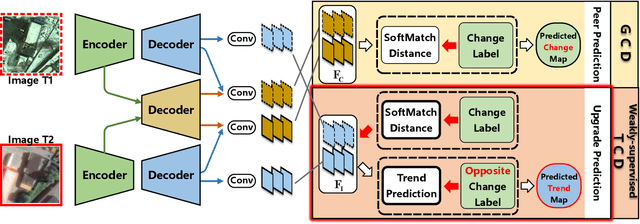
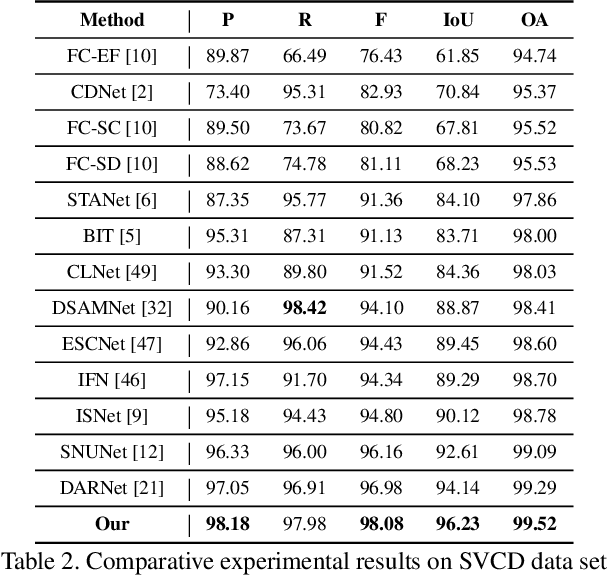
General change detection (GCD) and semantic change detection (SCD) are common methods for identifying changes and distinguishing object categories involved in those changes, respectively. However, the binary changes provided by GCD is often not practical enough, while annotating semantic labels for training SCD models is very expensive. Therefore, there is a novel solution that intuitively dividing changes into three trends (``appear'', ``disappear'' and ``transform'') instead of semantic categories, named it trend change detection (TCD) in this paper. It offers more detailed change information than GCD, while requiring less manual annotation cost than SCD. However, there are limited public data sets with specific trend labels to support TCD application. To address this issue, we propose a softmatch distance which is used to construct a weakly-supervised TCD branch in a simple GCD model, using GCD labels instead of TCD label for training. Furthermore, a strategic approach is presented to successfully explore and extract background information, which is crucial for the weakly-supervised TCD task. The experiment results on four public data sets are highly encouraging, which demonstrates the effectiveness of our proposed model.
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023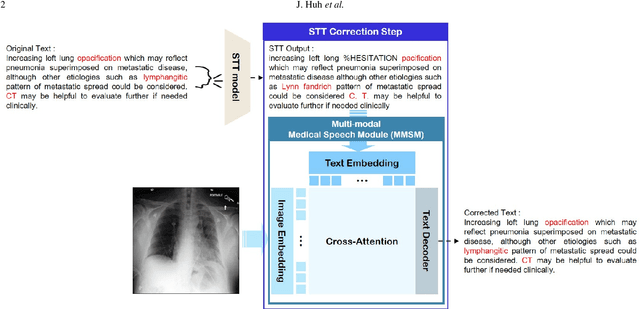

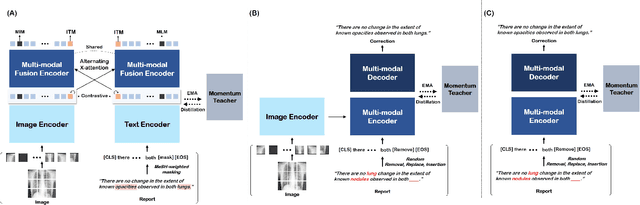
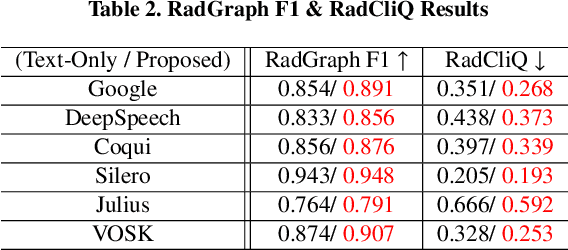
Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
Image-Based Virtual Try-on System With Clothing-Size Adjustment
Feb 27, 2023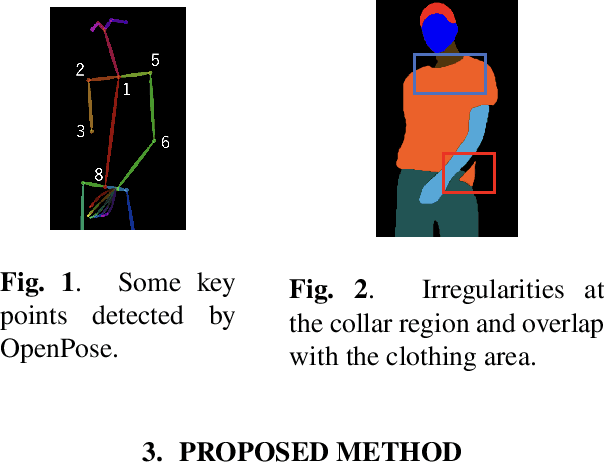
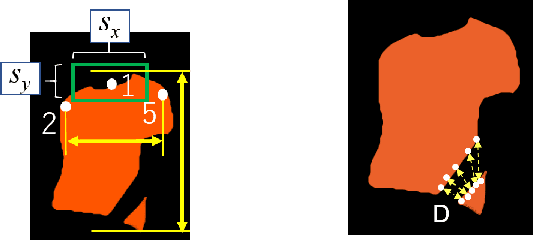
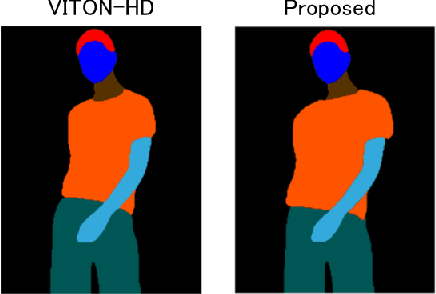
The conventional image-based virtual try-on method cannot generate fitting images that correspond to the clothing size because the system cannot accurately reflect the body information of a person. In this study, an image-based virtual try-on system that could adjust the clothing size was proposed. The size information of the person and clothing were used as the input for the proposed method to visualize the fitting of various clothing sizes in a virtual space. First, the distance between the shoulder width and height of the clothing in the person image is calculated based on the coordinate information of the key points detected by OpenPose. Then, the system changes the size of only the clothing area of the segmentation map, whose layout is estimated using the size of the person measured in the person image based on the ratio of the person and clothing sizes. If the size of the clothing area increases during the drawing, the details in the collar and overlapping areas are corrected to improve visual appearance.
Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023
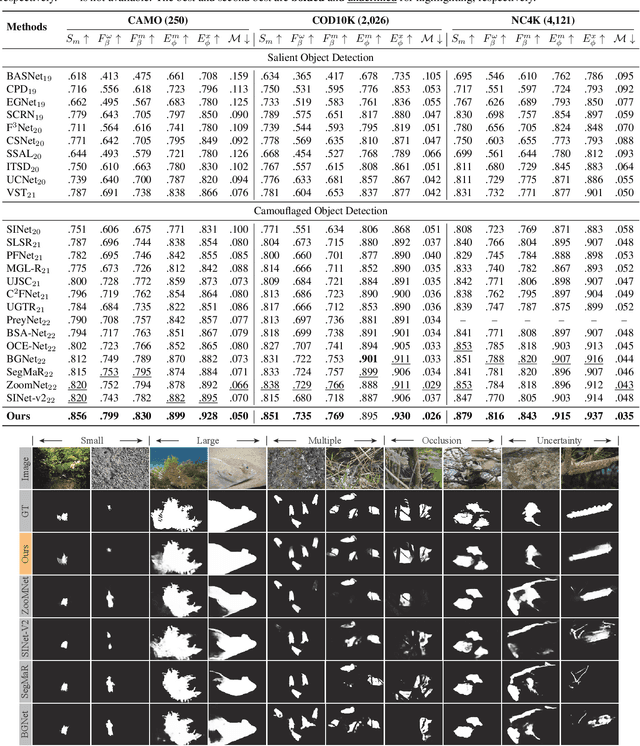

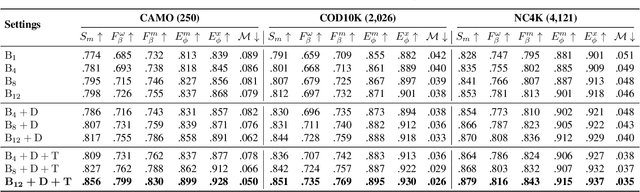
Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
Distributed Solution of the Inverse Rig Problem in Blendshape Facial Animation
Mar 26, 2023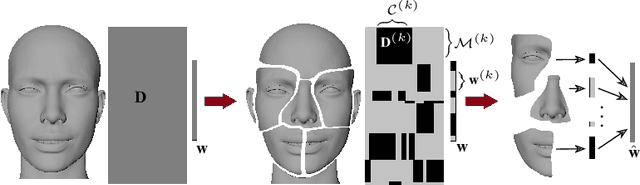
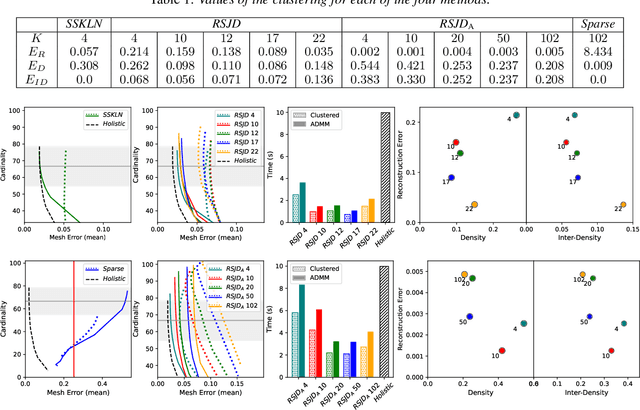

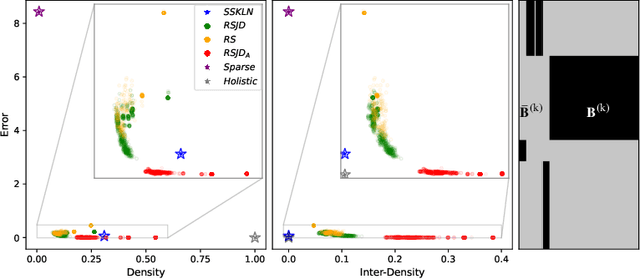
The problem of rig inversion is central in facial animation as it allows for a realistic and appealing performance of avatars. With the increasing complexity of modern blendshape models, execution times increase beyond practically feasible solutions. A possible approach towards a faster solution is clustering, which exploits the spacial nature of the face, leading to a distributed method. In this paper, we go a step further, involving cluster coupling to get more confident estimates of the overlapping components. Our algorithm applies the Alternating Direction Method of Multipliers, sharing the overlapping weights between the subproblems. The results obtained with this technique show a clear advantage over the naive clustered approach, as measured in different metrics of success and visual inspection. The method applies to an arbitrary clustering of the face. We also introduce a novel method for choosing the number of clusters in a data-free manner. The method tends to find a clustering such that the resulting clustering graph is sparse but without losing essential information. Finally, we give a new variant of a data-free clustering algorithm that produces good scores with respect to the mentioned strategy for choosing the optimal clustering.
SEM-POS: Grammatically and Semantically Correct Video Captioning
Mar 26, 2023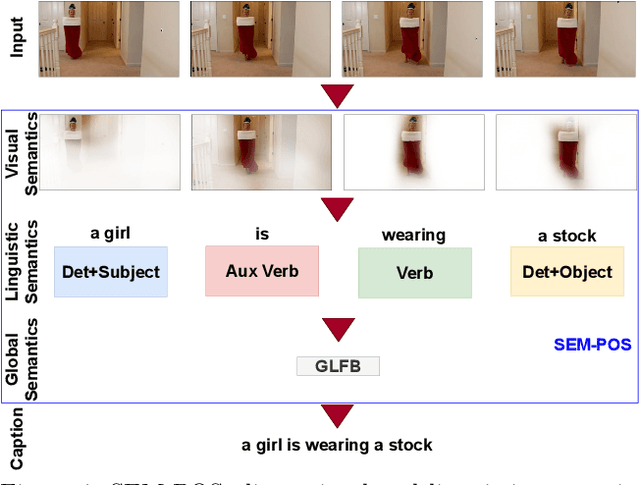
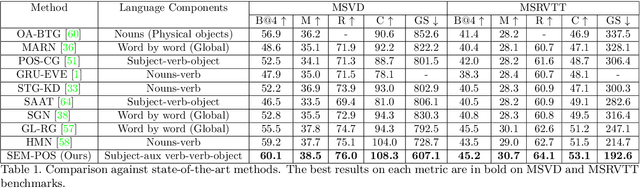
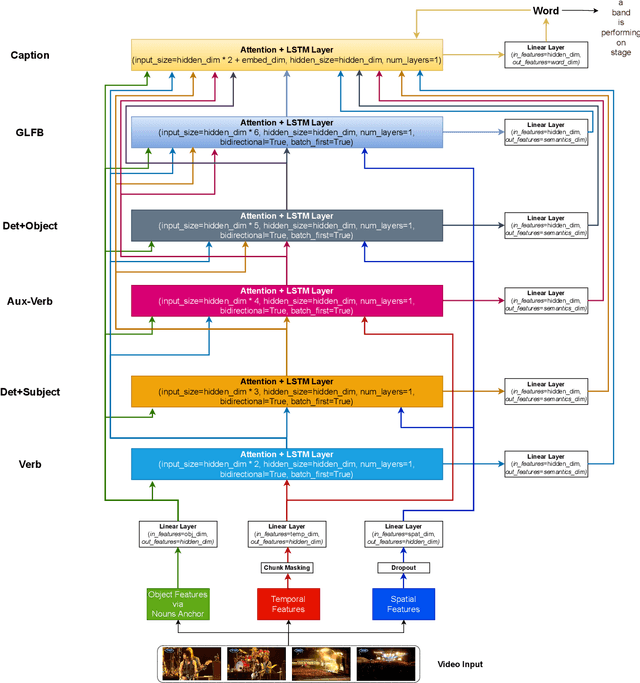
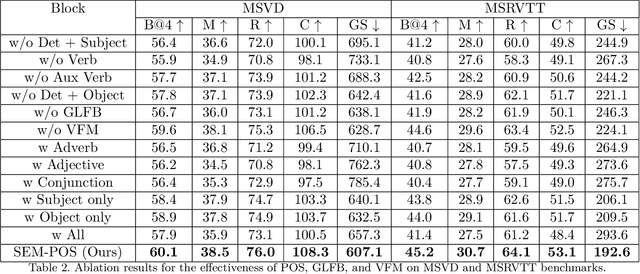
Generating grammatically and semantically correct captions in video captioning is a challenging task. The captions generated from the existing methods are either word-by-word that do not align with grammatical structure or miss key information from the input videos. To address these issues, we introduce a novel global-local fusion network, with a Global-Local Fusion Block (GLFB) that encodes and fuses features from different parts of speech (POS) components with visual-spatial features. We use novel combinations of different POS components - 'determinant + subject', 'auxiliary verb', 'verb', and 'determinant + object' for supervision of the POS blocks - Det + Subject, Aux Verb, Verb, and Det + Object respectively. The novel global-local fusion network together with POS blocks helps align the visual features with language description to generate grammatically and semantically correct captions. Extensive qualitative and quantitative experiments on benchmark MSVD and MSRVTT datasets demonstrate that the proposed approach generates more grammatically and semantically correct captions compared to the existing methods, achieving the new state-of-the-art. Ablations on the POS blocks and the GLFB demonstrate the impact of the contributions on the proposed method.
Context De-confounded Emotion Recognition
Mar 26, 2023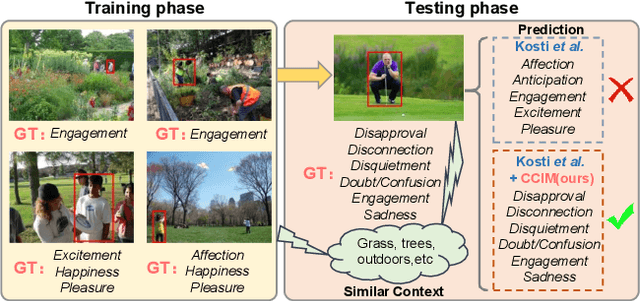
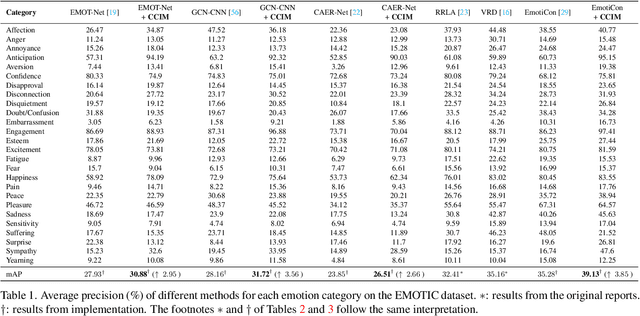
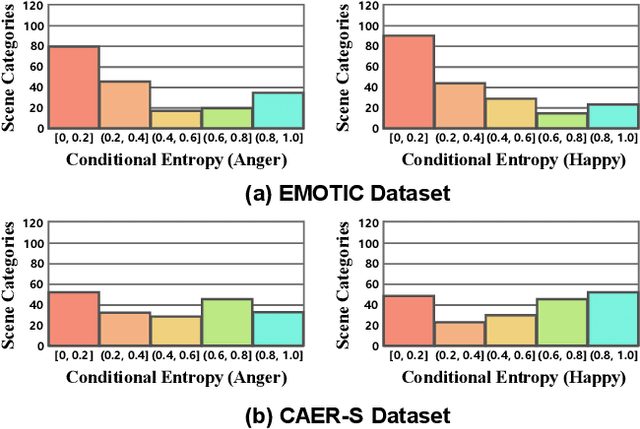

Context-Aware Emotion Recognition (CAER) is a crucial and challenging task that aims to perceive the emotional states of the target person with contextual information. Recent approaches invariably focus on designing sophisticated architectures or mechanisms to extract seemingly meaningful representations from subjects and contexts. However, a long-overlooked issue is that a context bias in existing datasets leads to a significantly unbalanced distribution of emotional states among different context scenarios. Concretely, the harmful bias is a confounder that misleads existing models to learn spurious correlations based on conventional likelihood estimation, significantly limiting the models' performance. To tackle the issue, this paper provides a causality-based perspective to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a tailored causal graph. Then, we propose a Contextual Causal Intervention Module (CCIM) based on the backdoor adjustment to de-confound the confounder and exploit the true causal effect for model training. CCIM is plug-in and model-agnostic, which improves diverse state-of-the-art approaches by considerable margins. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our CCIM and the significance of causal insight.
Implicit Ray-Transformers for Multi-view Remote Sensing Image Segmentation
Mar 15, 2023



The mainstream CNN-based remote sensing (RS) image semantic segmentation approaches typically rely on massive labeled training data. Such a paradigm struggles with the problem of RS multi-view scene segmentation with limited labeled views due to the lack of considering 3D information within the scene. In this paper, we propose ''Implicit Ray-Transformer (IRT)'' based on Implicit Neural Representation (INR), for RS scene semantic segmentation with sparse labels (such as 4-6 labels per 100 images). We explore a new way of introducing multi-view 3D structure priors to the task for accurate and view-consistent semantic segmentation. The proposed method includes a two-stage learning process. In the first stage, we optimize a neural field to encode the color and 3D structure of the remote sensing scene based on multi-view images. In the second stage, we design a Ray Transformer to leverage the relations between the neural field 3D features and 2D texture features for learning better semantic representations. Different from previous methods that only consider 3D prior or 2D features, we incorporate additional 2D texture information and 3D prior by broadcasting CNN features to different point features along the sampled ray. To verify the effectiveness of the proposed method, we construct a challenging dataset containing six synthetic sub-datasets collected from the Carla platform and three real sub-datasets from Google Maps. Experiments show that the proposed method outperforms the CNN-based methods and the state-of-the-art INR-based segmentation methods in quantitative and qualitative metrics.
Spatiotemporal Capsule Neural Network for Vehicle Trajectory Prediction
Mar 06, 2023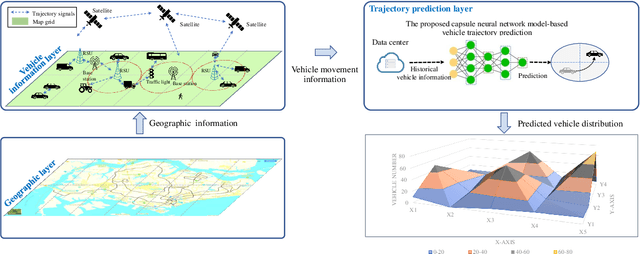
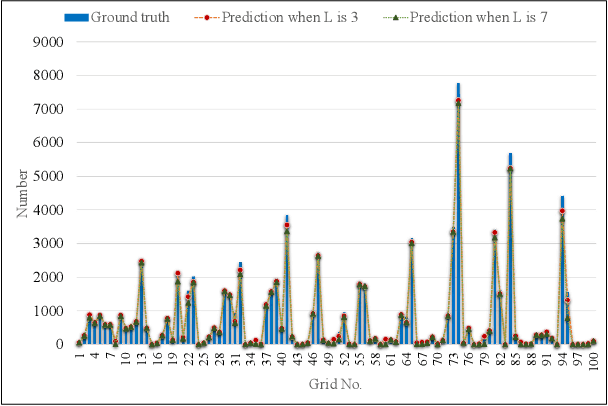
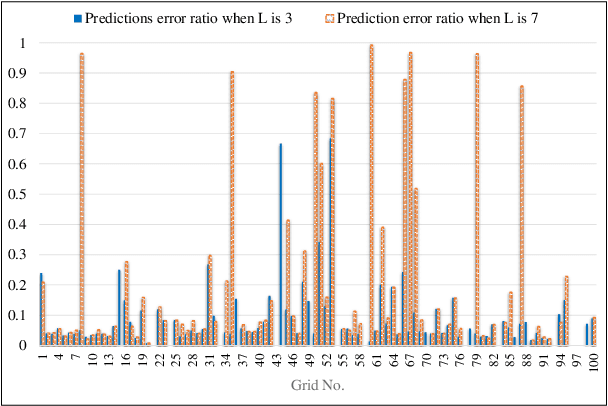

Through advancement of the Vehicle-to-Everything (V2X) network, road safety, energy consumption, and traffic efficiency can be significantly improved. An accurate vehicle trajectory prediction benefits communication traffic management and network resource allocation for the real-time application of the V2X network. Recurrent neural networks and their variants have been reported in recent research to predict vehicle mobility. However, the spatial attribute of vehicle movement behavior has been overlooked, resulting in incomplete information utilization. To bridge this gap, we put forward for the first time a hierarchical trajectory prediction structure using the capsule neural network (CapsNet) with three sequential components. First, the geographic information is transformed into a grid map presentation, describing vehicle mobility distribution spatially and temporally. Second, CapsNet serves as the core model to embed local temporal and global spatial correlation through hierarchical capsules. Finally, extensive experiments conducted on actual taxi mobility data collected in Porto city (Portugal) and Singapore show that the proposed method outperforms the state-of-the-art methods.
Generalization algorithm of multimodal pre-training model based on graph-text self-supervised training
Feb 16, 2023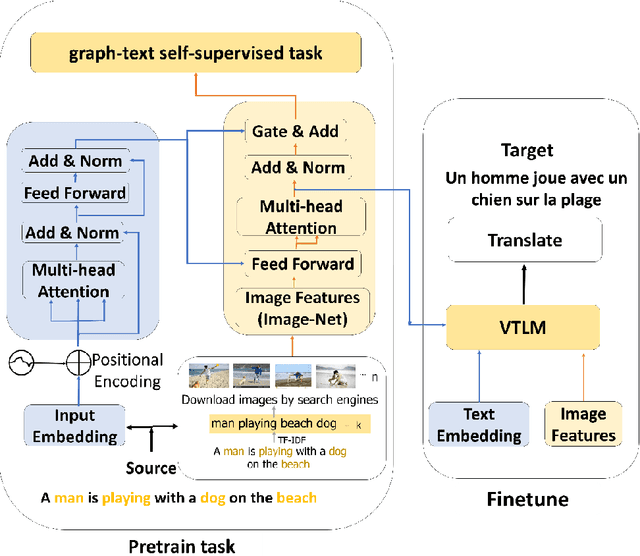
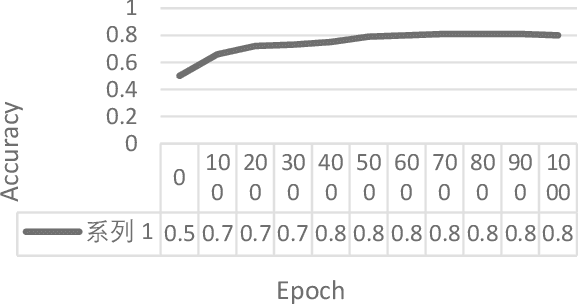


Recently, a large number of studies have shown that the introduction of visual information can effectively improve the effect of neural machine translation (NMT). Its effectiveness largely depends on the availability of a large number of bilingual parallel sentence pairs and manual image annotation. The lack of images and the effectiveness of images have been difficult to solve. In this paper, a multimodal pre-training generalization algorithm for self-supervised training is proposed, which overcomes the lack of visual information and inaccuracy, and thus extends the applicability of images on NMT. Specifically, we will search for many pictures from the existing sentences through the search engine, and then through the relationship between visual information and text, do the self-supervised training task of graphics and text to obtain more effective visual information for text. We show that when the filtered information is used as multimodal machine translation for fine-tuning, the effect of translation in the global voice dataset is 0.5 BLEU higher than the baseline.