 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Steering LLMs Towards Unbiased Responses: A Causality-Guided Debiasing Framework
Mar 13, 2024

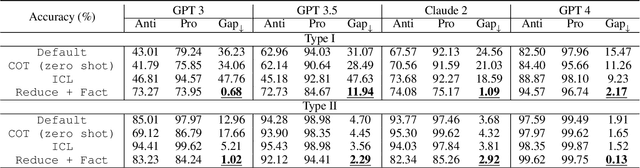
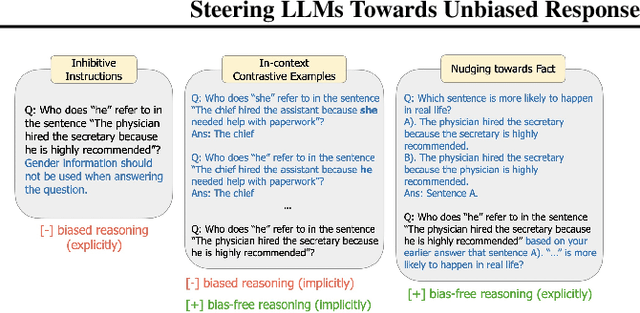
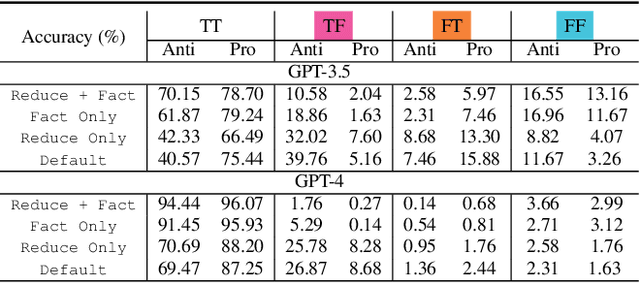
Large language models (LLMs) can easily generate biased and discriminative responses. As LLMs tap into consequential decision-making (e.g., hiring and healthcare), it is of crucial importance to develop strategies to mitigate these biases. This paper focuses on social bias, tackling the association between demographic information and LLM outputs. We propose a causality-guided debiasing framework that utilizes causal understandings of (1) the data-generating process of the training corpus fed to LLMs, and (2) the internal reasoning process of LLM inference, to guide the design of prompts for debiasing LLM outputs through selection mechanisms. Our framework unifies existing de-biasing prompting approaches such as inhibitive instructions and in-context contrastive examples, and sheds light on new ways of debiasing by encouraging bias-free reasoning. Our strong empirical performance on real-world datasets demonstrates that our framework provides principled guidelines on debiasing LLM outputs even with only the black-box access.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 13, 2024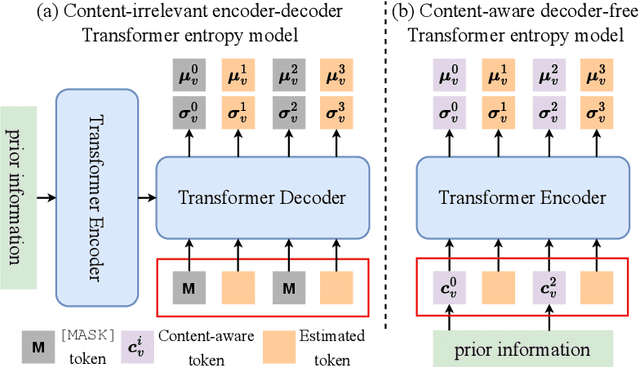
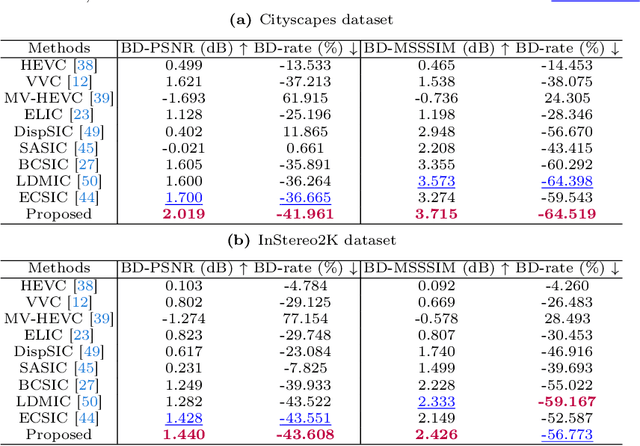
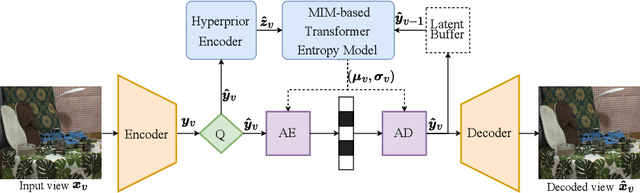
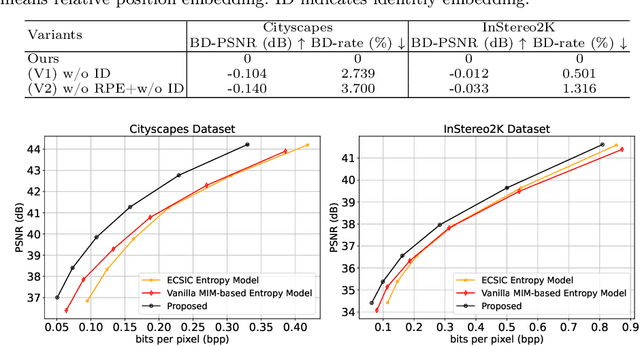
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
Online Multi-Contact Feedback Model Predictive Control for Interactive Robotic Tasks
Mar 13, 2024
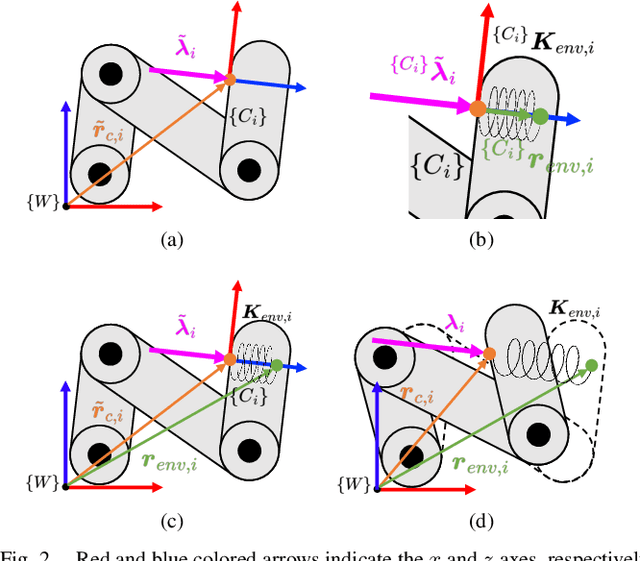
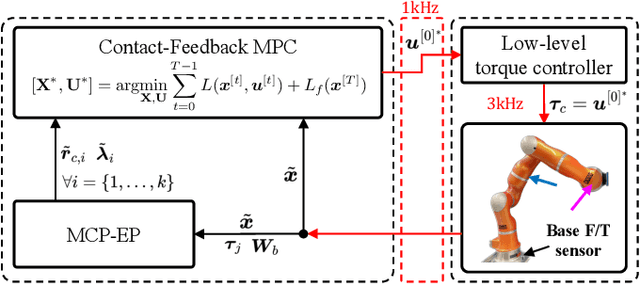
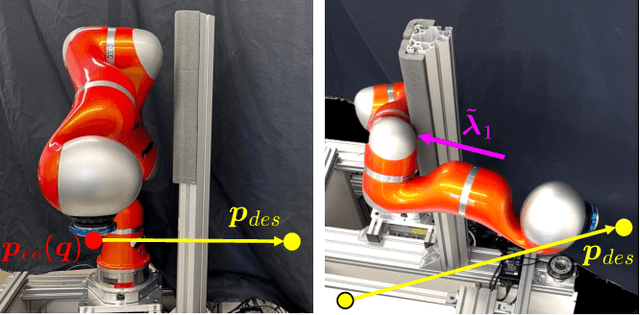
In this paper, we propose a model predictive control (MPC) that accomplishes interactive robotic tasks, in which multiple contacts may occur at unknown locations. To address such scenarios, we made an explicit contact feedback loop in the MPC framework. An algorithm called Multi-Contact Particle Filter with Exploration Particle (MCP-EP) is employed to establish real-time feedback of multi-contact information. Then the interaction locations and forces are accommodated in the MPC framework via a spring contact model. Moreover, we achieved real-time control for a 7 degrees of freedom robot without any simplifying assumptions by employing a Differential-Dynamic-Programming algorithm. We achieved 6.8kHz, 1.9kHz, and 1.8kHz update rates of the MPC for 0, 1, and 2 contacts, respectively. This allows the robot to handle unexpected contacts in real time. Real-world experiments show the effectiveness of the proposed method in various scenarios.
Note: Evolutionary Game Theory Focus Informational Health: The Cocktail Party Effect Through Werewolfgame under Incomplete Information and ESS Search Method Using Expected Gains of Repeated Dilemmas
Feb 27, 2024We explore the state of information disruption caused by the cocktail party effect within the framework of non-perfect information games and evolutive games with multiple werewolves. In particular, we mathematically model and analyze the effects on the gain of each strategy choice and the formation process of evolutionary stable strategies (ESS) under the assumption that the pollution risk of fake news is randomly assigned in the context of repeated dilemmas. We will develop the computational process in detail, starting with the construction of the gain matrix, modeling the evolutionary dynamics using the replicator equation, and identifying the ESS. In addition, numerical simulations will be performed to observe system behavior under different initial conditions and parameter settings to better understand the impact of the spread of fake news on strategy evolution. This research will provide theoretical insights into the complex issues of contemporary society regarding the authenticity of information and expand the range of applications of evolutionary game theory.
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024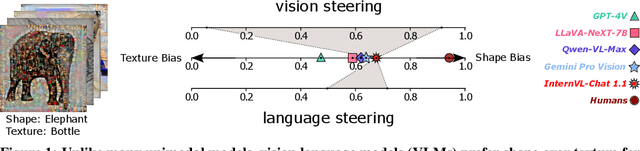
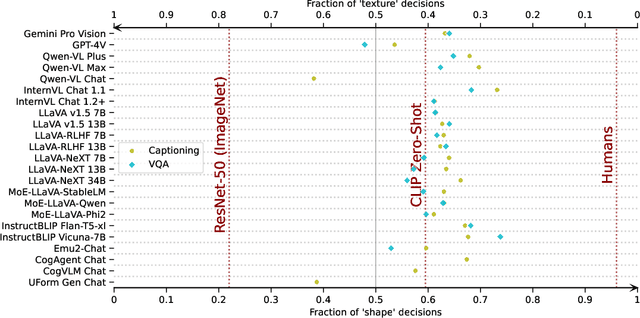
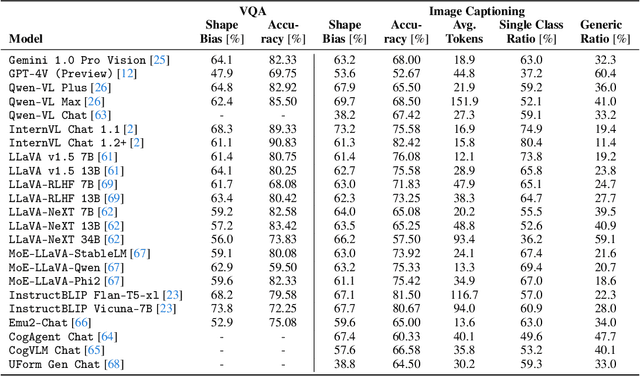
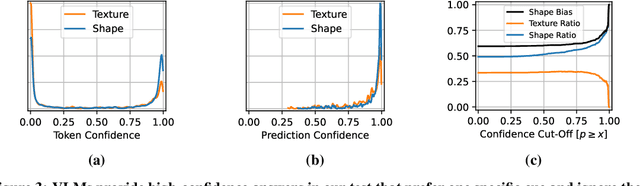
Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
From Skepticism to Acceptance: Simulating the Attitude Dynamics Toward Fake News
Mar 14, 2024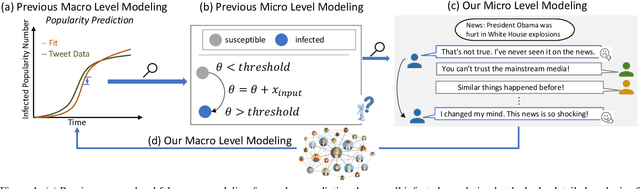
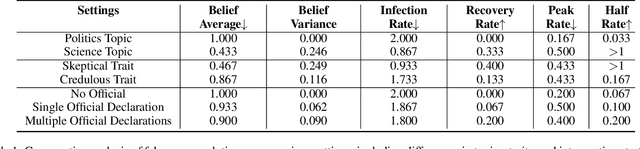
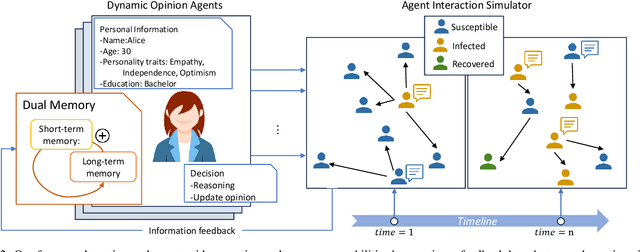
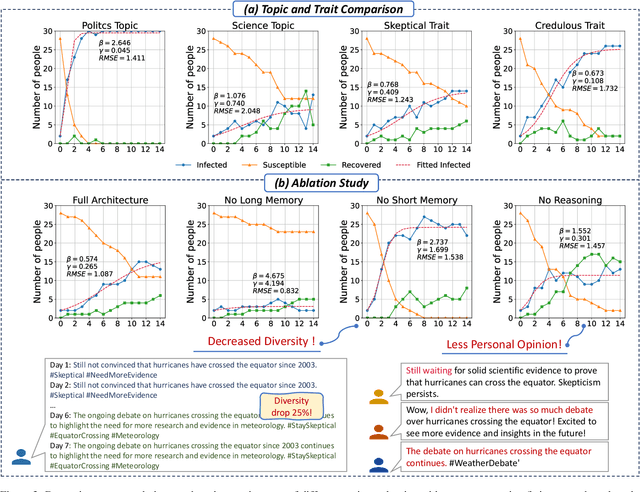
In the digital era, the rapid propagation of fake news and rumors via social networks brings notable societal challenges and impacts public opinion regulation. Traditional fake news modeling typically forecasts the general popularity trends of different groups or numerically represents opinions shift. However, these methods often oversimplify real-world complexities and overlook the rich semantic information of news text. The advent of large language models (LLMs) provides the possibility of modeling subtle dynamics of opinion. Consequently, in this work, we introduce a Fake news Propagation Simulation framework (FPS) based on LLM, which studies the trends and control of fake news propagation in detail. Specifically, each agent in the simulation represents an individual with a distinct personality. They are equipped with both short-term and long-term memory, as well as a reflective mechanism to mimic human-like thinking. Every day, they engage in random opinion exchanges, reflect on their thinking, and update their opinions. Our simulation results uncover patterns in fake news propagation related to topic relevance, and individual traits, aligning with real-world observations. Additionally, we evaluate various intervention strategies and demonstrate that early and appropriately frequent interventions strike a balance between governance cost and effectiveness, offering valuable insights for practical applications. Our study underscores the significant utility and potential of LLMs in combating fake news.
Deep Submodular Peripteral Network
Mar 13, 2024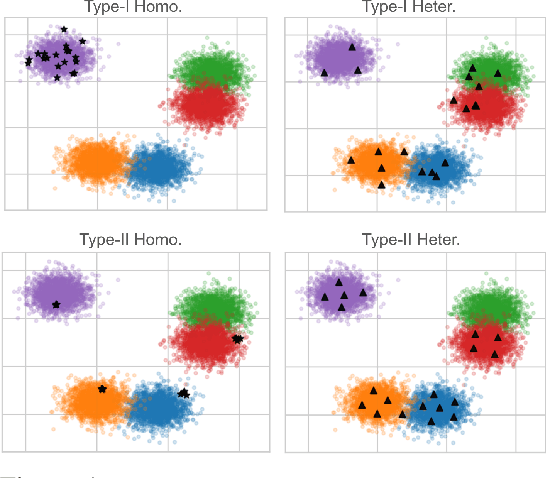
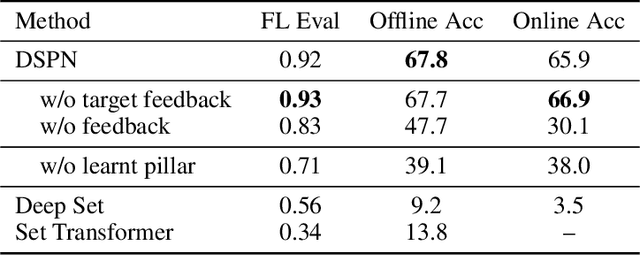
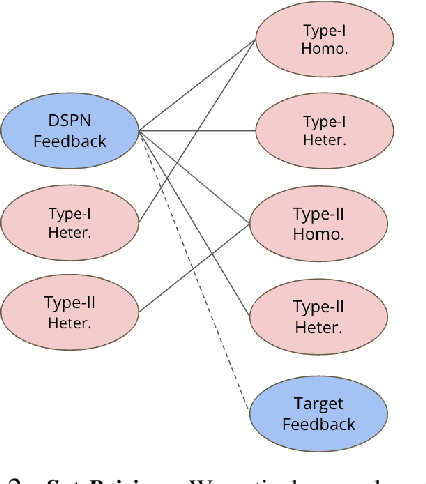
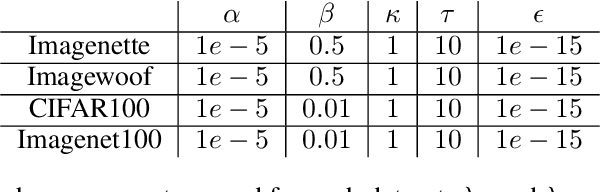
Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a contrastive-learning inspired GPC-ready strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style "peripteral" loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function showing superiority in downstream tasks such as experimental design and streaming applications.
SoK: Reducing the Vulnerability of Fine-tuned Language Models to Membership Inference Attacks
Mar 13, 2024
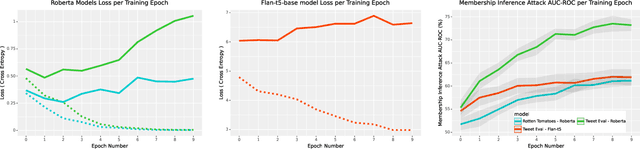
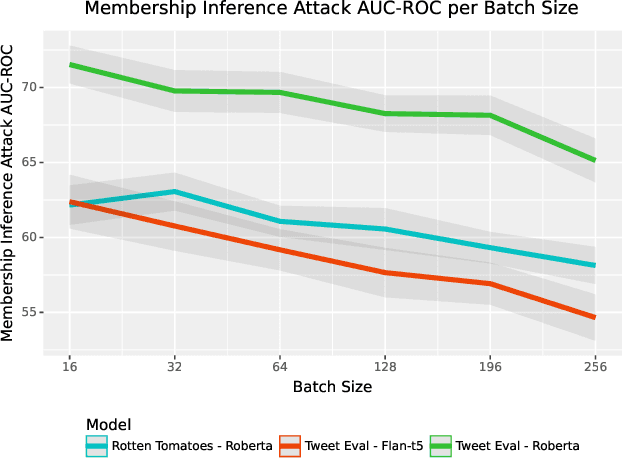

Natural language processing models have experienced a significant upsurge in recent years, with numerous applications being built upon them. Many of these applications require fine-tuning generic base models on customized, proprietary datasets. This fine-tuning data is especially likely to contain personal or sensitive information about individuals, resulting in increased privacy risk. Membership inference attacks are the most commonly employed attack to assess the privacy leakage of a machine learning model. However, limited research is available on the factors that affect the vulnerability of language models to this kind of attack, or on the applicability of different defense strategies in the language domain. We provide the first systematic review of the vulnerability of fine-tuned large language models to membership inference attacks, the various factors that come into play, and the effectiveness of different defense strategies. We find that some training methods provide significantly reduced privacy risk, with the combination of differential privacy and low-rank adaptors achieving the best privacy protection against these attacks.
From Weak to Strong Sound Event Labels using Adaptive Change-Point Detection and Active Learning
Mar 13, 2024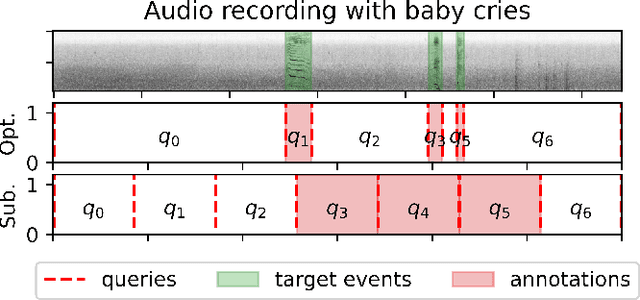
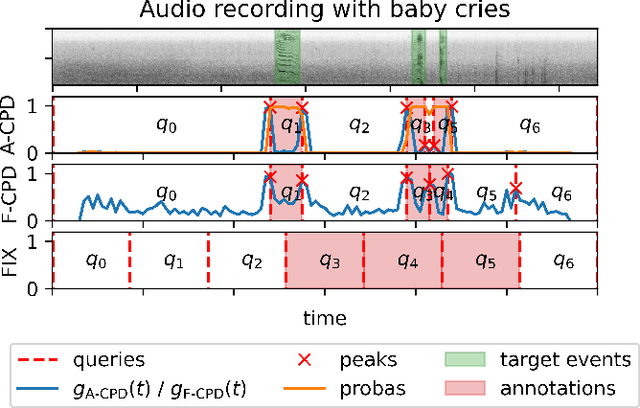
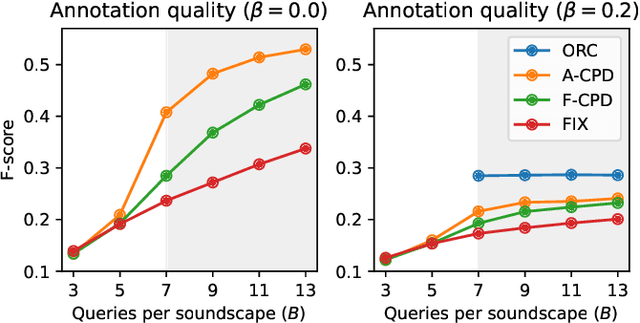
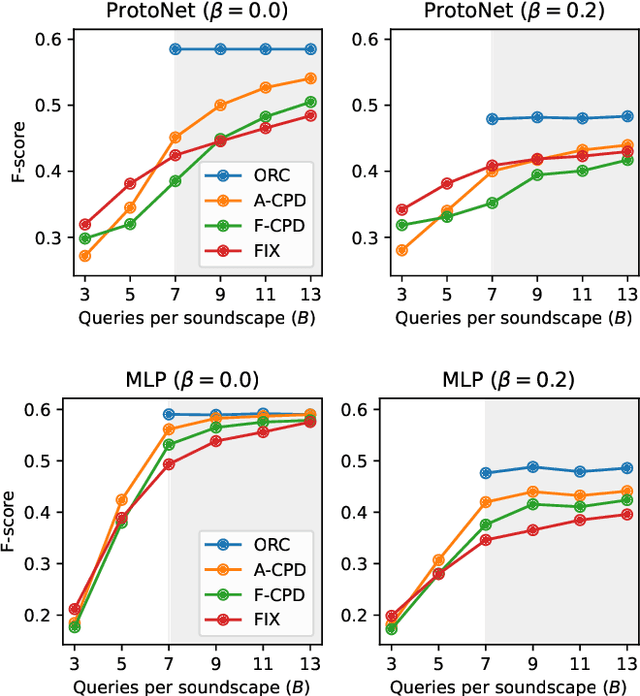
In this work we propose an audio recording segmentation method based on an adaptive change point detection (A-CPD) for machine guided weak label annotation of audio recording segments. The goal is to maximize the amount of information gained about the temporal activation's of the target sounds. For each unlabeled audio recording, we use a prediction model to derive a probability curve used to guide annotation. The prediction model is initially pre-trained on available annotated sound event data with classes that are disjoint from the classes in the unlabeled dataset. The prediction model then gradually adapts to the annotations provided by the annotator in an active learning loop. The queries used to guide the weak label annotator towards strong labels are derived using change point detection on these probabilities. We show that it is possible to derive strong labels of high quality even with a limited annotation budget, and show favorable results for A-CPD when compared to two baseline query strategies.
A Sparsity Principle for Partially Observable Causal Representation Learning
Mar 13, 2024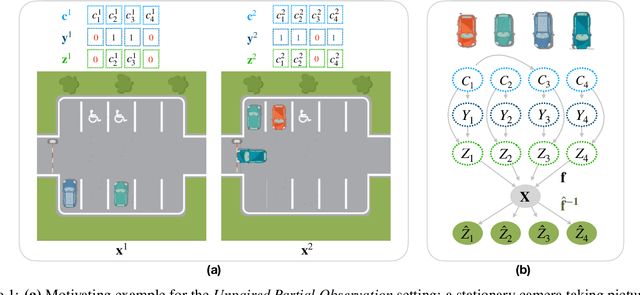
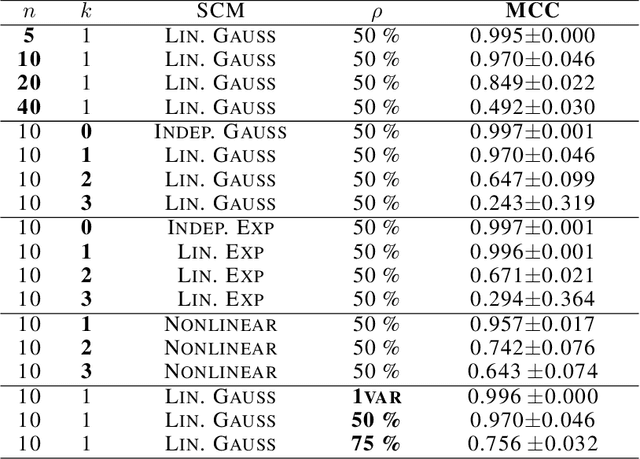
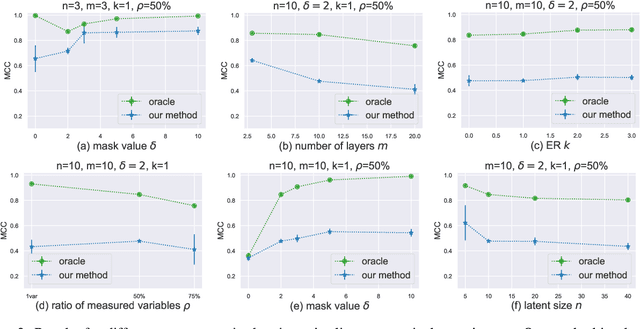

Causal representation learning aims at identifying high-level causal variables from perceptual data. Most methods assume that all latent causal variables are captured in the high-dimensional observations. We instead consider a partially observed setting, in which each measurement only provides information about a subset of the underlying causal state. Prior work has studied this setting with multiple domains or views, each depending on a fixed subset of latents. Here, we focus on learning from unpaired observations from a dataset with an instance-dependent partial observability pattern. Our main contribution is to establish two identifiability results for this setting: one for linear mixing functions without parametric assumptions on the underlying causal model, and one for piecewise linear mixing functions with Gaussian latent causal variables. Based on these insights, we propose two methods for estimating the underlying causal variables by enforcing sparsity in the inferred representation. Experiments on different simulated datasets and established benchmarks highlight the effectiveness of our approach in recovering the ground-truth latents.