 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Best of Both Worlds: Multimodal Contrastive Learning with Tabular and Imaging Data
Mar 30, 2023
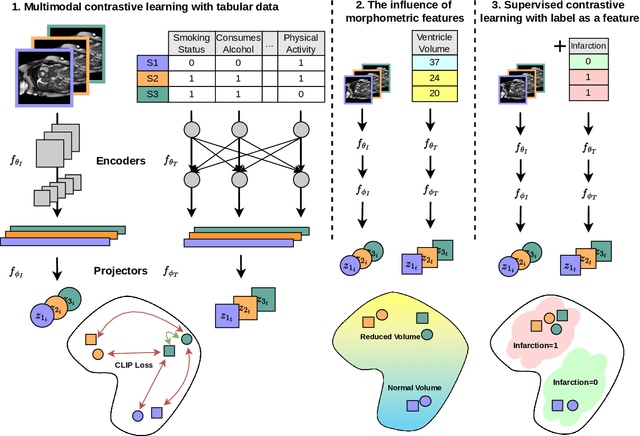
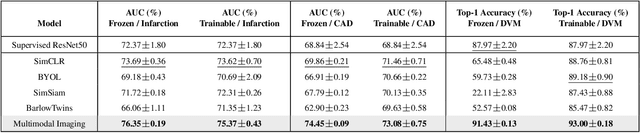
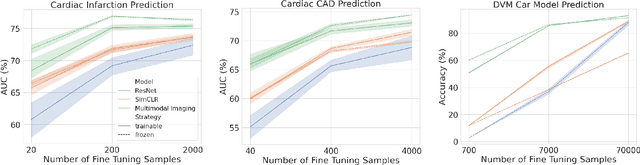

Medical datasets and especially biobanks, often contain extensive tabular data with rich clinical information in addition to images. In practice, clinicians typically have less data, both in terms of diversity and scale, but still wish to deploy deep learning solutions. Combined with increasing medical dataset sizes and expensive annotation costs, the necessity for unsupervised methods that can pretrain multimodally and predict unimodally has risen. To address these needs, we propose the first self-supervised contrastive learning framework that takes advantage of images and tabular data to train unimodal encoders. Our solution combines SimCLR and SCARF, two leading contrastive learning strategies, and is simple and effective. In our experiments, we demonstrate the strength of our framework by predicting risks of myocardial infarction and coronary artery disease (CAD) using cardiac MR images and 120 clinical features from 40,000 UK Biobank subjects. Furthermore, we show the generalizability of our approach to natural images using the DVM car advertisement dataset. We take advantage of the high interpretability of tabular data and through attribution and ablation experiments find that morphometric tabular features, describing size and shape, have outsized importance during the contrastive learning process and improve the quality of the learned embeddings. Finally, we introduce a novel form of supervised contrastive learning, label as a feature (LaaF), by appending the ground truth label as a tabular feature during multimodal pretraining, outperforming all supervised contrastive baselines.
Task-Oriented Multi-Modal Mutual Leaning for Vision-Language Models
Mar 30, 2023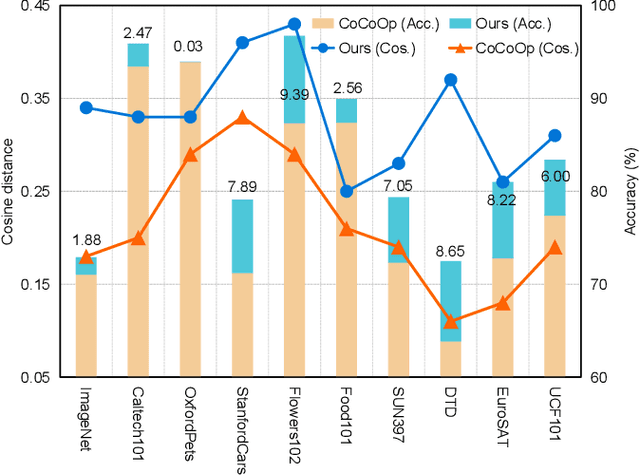
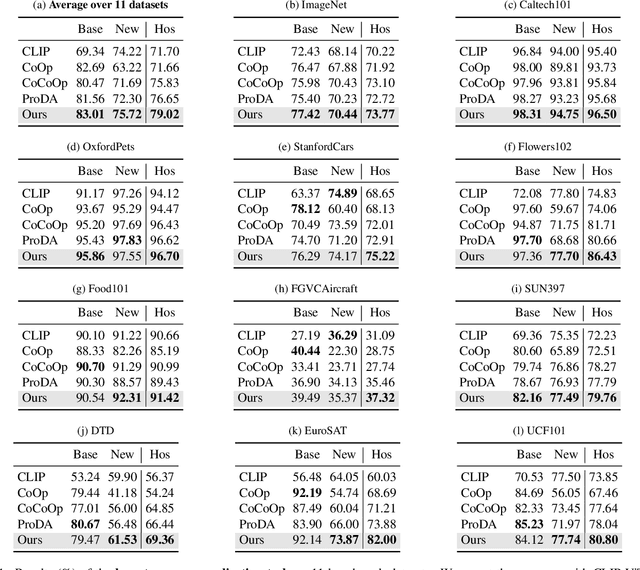
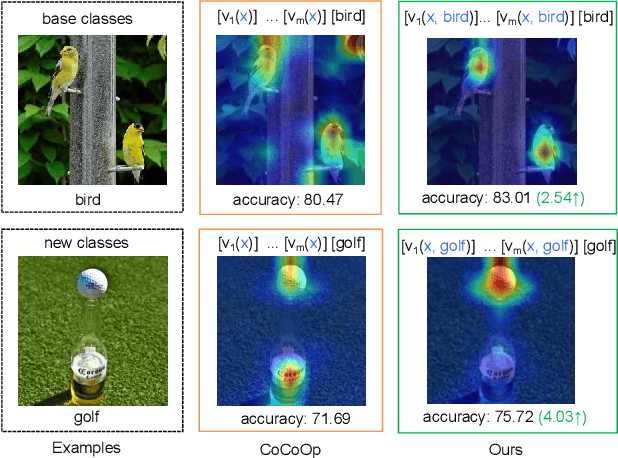
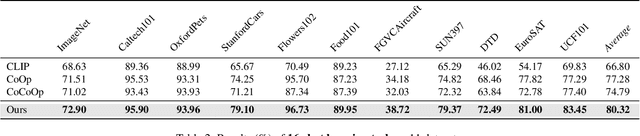
Prompt learning has become one of the most efficient paradigms for adapting large pre-trained vision-language models to downstream tasks. Current state-of-the-art methods, like CoOp and ProDA, tend to adopt soft prompts to learn an appropriate prompt for each specific task. Recent CoCoOp further boosts the base-to-new generalization performance via an image-conditional prompt. However, it directly fuses identical image semantics to prompts of different labels and significantly weakens the discrimination among different classes as shown in our experiments. Motivated by this observation, we first propose a class-aware text prompt (CTP) to enrich generated prompts with label-related image information. Unlike CoCoOp, CTP can effectively involve image semantics and avoid introducing extra ambiguities into different prompts. On the other hand, instead of reserving the complete image representations, we propose text-guided feature tuning (TFT) to make the image branch attend to class-related representation. A contrastive loss is employed to align such augmented text and image representations on downstream tasks. In this way, the image-to-text CTP and text-to-image TFT can be mutually promoted to enhance the adaptation of VLMs for downstream tasks. Extensive experiments demonstrate that our method outperforms the existing methods by a significant margin. Especially, compared to CoCoOp, we achieve an average improvement of 4.03% on new classes and 3.19% on harmonic-mean over eleven classification benchmarks.
A novel dual skip connection mechanism in U-Nets for building footprint extraction
Mar 16, 2023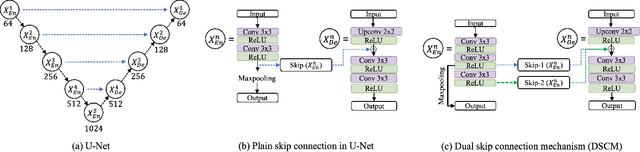
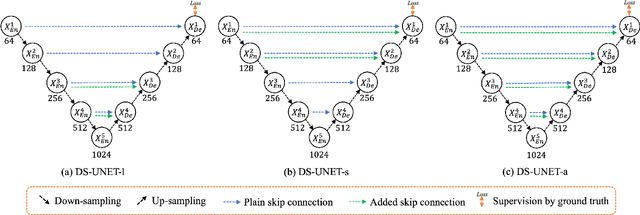
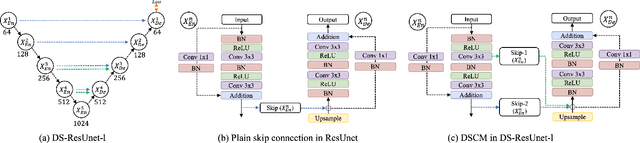
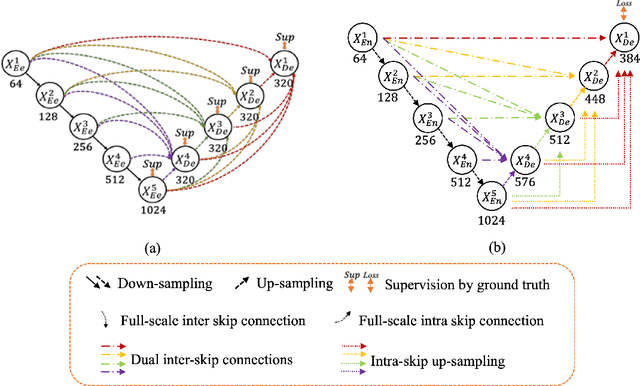
The importance of building footprints and their inventory has been recognised as an enabler for multiple societal problems. Extracting urban building footprint is complex and requires semantic segmentation of very high-resolution (VHR) earth observation (EO) images. U-Net is a common deep learning architecture for such segmentation. It has seen several re-incarnation including U-Net++ and U-Net3+ with a focus on multi-scale feature aggregation with re-designed skip connections. However, the exploitation of multi-scale information is still evolving. In this paper, we propose a dual skip connection mechanism (DSCM) for U-Net and a dual full-scale skip connection mechanism (DFSCM) for U-Net3+. The DSCM in U-Net doubles the features in the encoder and passes them to the decoder for precise localisation. Similarly, the DFSCM incorporates increased low-level context information with high-level semantics from feature maps in different scales. The DSCM is further tested in ResUnet and different scales of U-Net. The proposed mechanisms, therefore, produce several novel networks that are evaluated in a benchmark WHU building dataset and a multi-resolution dataset that we develop for the City of Melbourne. The results on the benchmark dataset demonstrate 17.7% and 18.4% gain in F1 score and Intersection over Union (IoU) compared to the state-of-the-art vanilla U-Net3+. In the same experimental setup, DSCM on U-Net and ResUnet provides a gain in five accuracy measures against the original networks. The codes will be available in a GitHub link after peer review.
Implementing engrams from a machine learning perspective: matching for prediction
Mar 01, 2023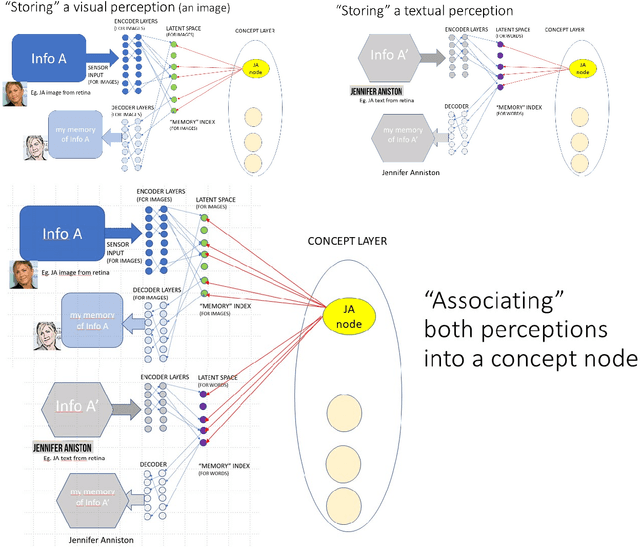
Despite evidence for the existence of engrams as memory support structures in our brains, there is no consensus framework in neuroscience as to what their physical implementation might be. Here we propose how we might design a computer system to implement engrams using neural networks, with the main aim of exploring new ideas using machine learning techniques, guided by challenges in neuroscience. Building on autoencoders, we propose latent neural spaces as indexes for storing and retrieving information in a compressed format. We consider this technique as a first step towards predictive learning: autoencoders are designed to compare reconstructed information with the original information received, providing a kind of predictive ability, which is an attractive evolutionary argument. We then consider how different states in latent neural spaces corresponding to different types of sensory input could be linked by synchronous activation, providing the basis for a sparse implementation of memory using concept neurons. Finally, we list some of the challenges and questions that link neuroscience and data science and that could have implications for both fields, and conclude that a more interdisciplinary approach is needed, as many scientists have already suggested.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 2023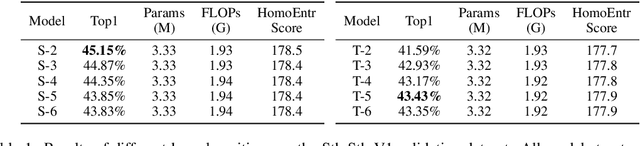
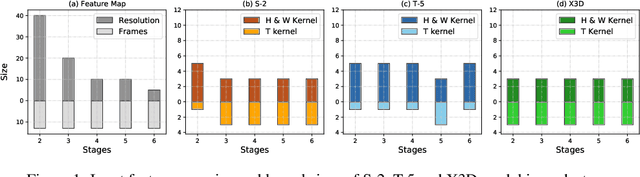
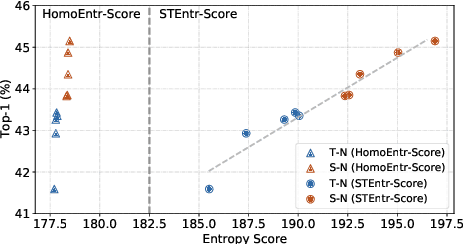
3D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.
3D Human Mesh Estimation from Virtual Markers
Mar 27, 2023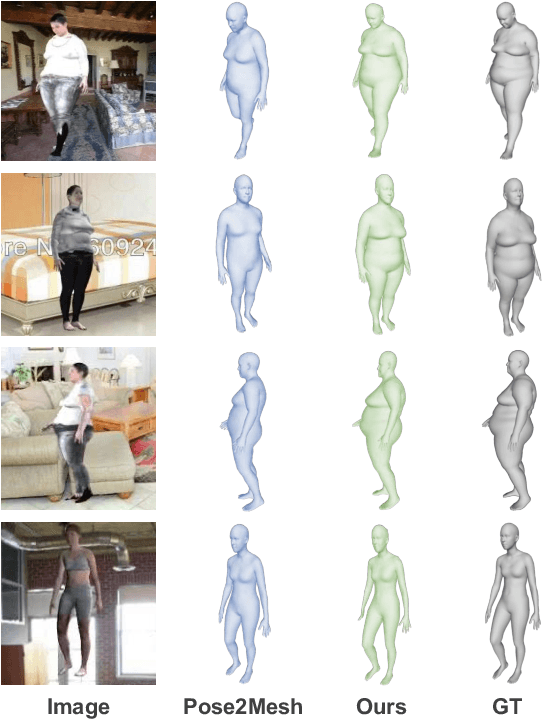
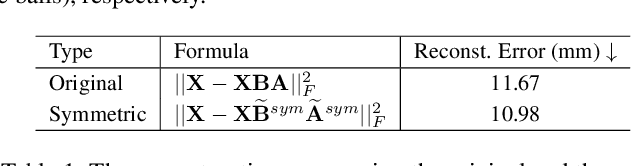

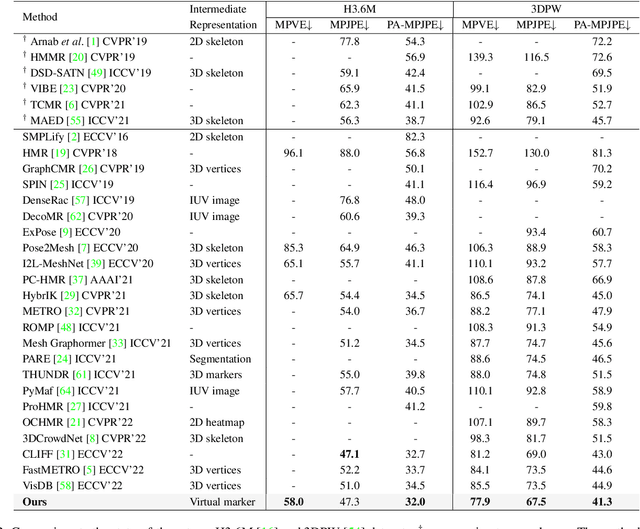
Inspired by the success of volumetric 3D pose estimation, some recent human mesh estimators propose to estimate 3D skeletons as intermediate representations, from which, the dense 3D meshes are regressed by exploiting the mesh topology. However, body shape information is lost in extracting skeletons, leading to mediocre performance. The advanced motion capture systems solve the problem by placing dense physical markers on the body surface, which allows to extract realistic meshes from their non-rigid motions. However, they cannot be applied to wild images without markers. In this work, we present an intermediate representation, named virtual markers, which learns 64 landmark keypoints on the body surface based on the large-scale mocap data in a generative style, mimicking the effects of physical markers. The virtual markers can be accurately detected from wild images and can reconstruct the intact meshes with realistic shapes by simple interpolation. Our approach outperforms the state-of-the-art methods on three datasets. In particular, it surpasses the existing methods by a notable margin on the SURREAL dataset, which has diverse body shapes. Code is available at https://github.com/ShirleyMaxx/VirtualMarker.
Vision Transformer with Quadrangle Attention
Mar 27, 2023

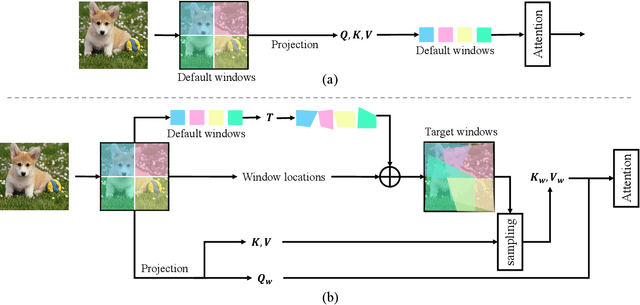
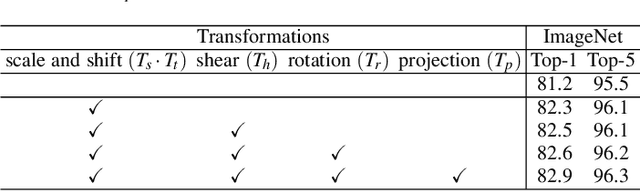
Window-based attention has become a popular choice in vision transformers due to its superior performance, lower computational complexity, and less memory footprint. However, the design of hand-crafted windows, which is data-agnostic, constrains the flexibility of transformers to adapt to objects of varying sizes, shapes, and orientations. To address this issue, we propose a novel quadrangle attention (QA) method that extends the window-based attention to a general quadrangle formulation. Our method employs an end-to-end learnable quadrangle regression module that predicts a transformation matrix to transform default windows into target quadrangles for token sampling and attention calculation, enabling the network to model various targets with different shapes and orientations and capture rich context information. We integrate QA into plain and hierarchical vision transformers to create a new architecture named QFormer, which offers minor code modifications and negligible extra computational cost. Extensive experiments on public benchmarks demonstrate that QFormer outperforms existing representative vision transformers on various vision tasks, including classification, object detection, semantic segmentation, and pose estimation. The code will be made publicly available at \href{https://github.com/ViTAE-Transformer/QFormer}{QFormer}.
Exemplar-based Video Colorization with Long-term Spatiotemporal Dependency
Mar 27, 2023
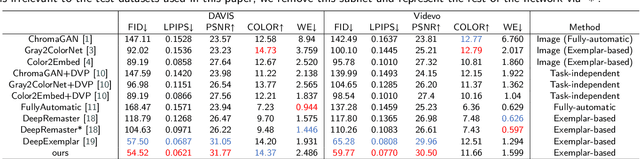
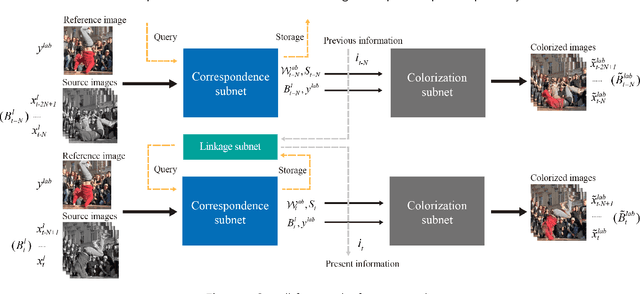

Exemplar-based video colorization is an essential technique for applications like old movie restoration. Although recent methods perform well in still scenes or scenes with regular movement, they always lack robustness in moving scenes due to their weak ability in modeling long-term dependency both spatially and temporally, leading to color fading, color discontinuity or other artifacts. To solve this problem, we propose an exemplar-based video colorization framework with long-term spatiotemporal dependency. To enhance the long-term spatial dependency, a parallelized CNN-Transformer block and a double head non-local operation are designed. The proposed CNN-Transformer block can better incorporate long-term spatial dependency with local texture and structural features, and the double head non-local operation further leverages the performance of augmented feature. While for long-term temporal dependency enhancement, we further introduce the novel linkage subnet. The linkage subnet propagate motion information across adjacent frame blocks and help to maintain temporal continuity. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively. Also, our model can generate more colorful, realistic and stabilized results, especially for scenes where objects change greatly and irregularly.
Regularized EM algorithm
Mar 27, 2023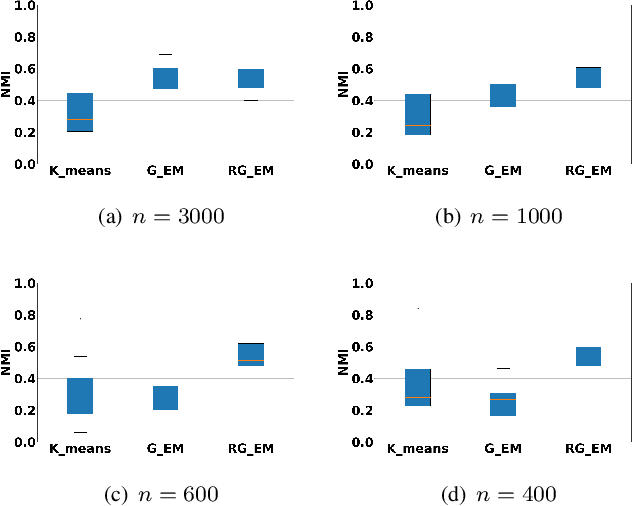
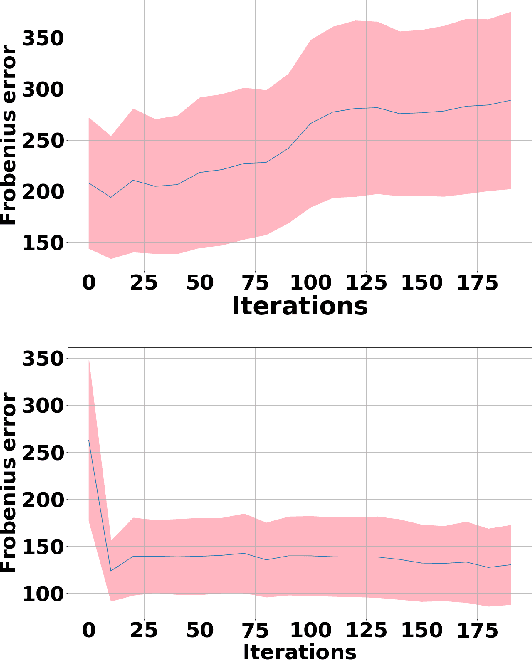
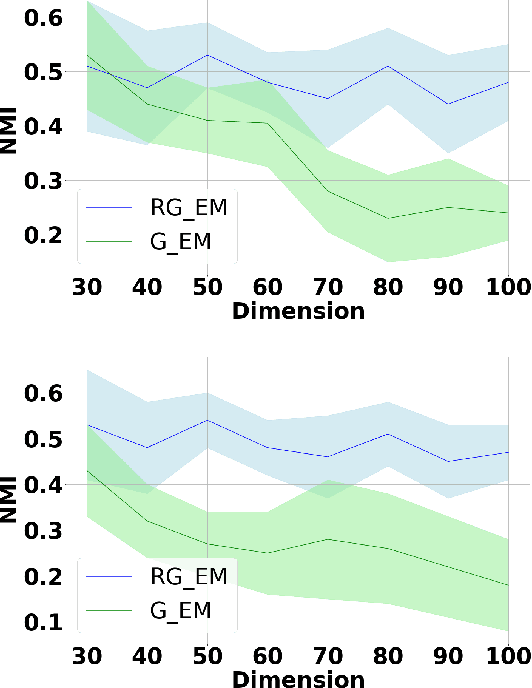
Expectation-Maximization (EM) algorithm is a widely used iterative algorithm for computing (local) maximum likelihood estimate (MLE). It can be used in an extensive range of problems, including the clustering of data based on the Gaussian mixture model (GMM). Numerical instability and convergence problems may arise in situations where the sample size is not much larger than the data dimensionality. In such low sample support (LSS) settings, the covariance matrix update in the EM-GMM algorithm may become singular or poorly conditioned, causing the algorithm to crash. On the other hand, in many signal processing problems, a priori information can be available indicating certain structures for different cluster covariance matrices. In this paper, we present a regularized EM algorithm for GMM-s that can make efficient use of such prior knowledge as well as cope with LSS situations. The method aims to maximize a penalized GMM likelihood where regularized estimation may be used to ensure positive definiteness of covariance matrix updates and shrink the estimators towards some structured target covariance matrices. We show that the theoretical guarantees of convergence hold, leading to better performing EM algorithm for structured covariance matrix models or with low sample settings.
Transformer-based Multi-Instance Learning for Weakly Supervised Object Detection
Mar 27, 2023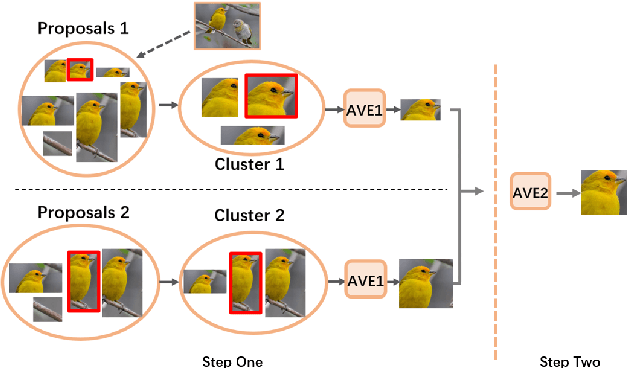
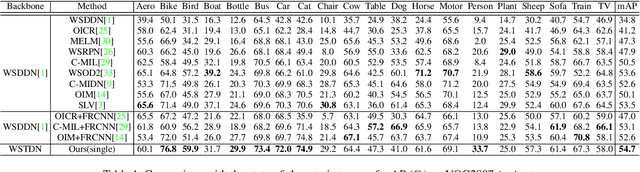
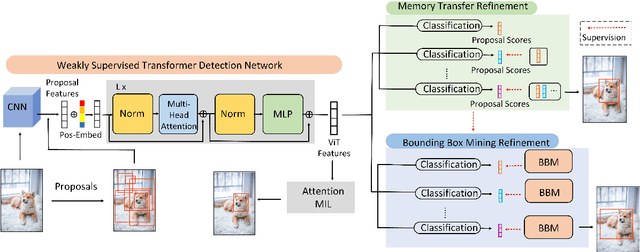
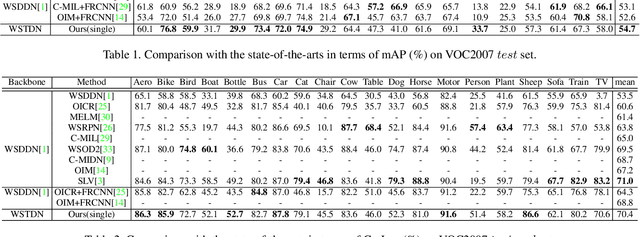
Weakly Supervised Object Detection (WSOD) enables the training of object detection models using only image-level annotations. State-of-the-art WSOD detectors commonly rely on multi-instance learning (MIL) as the backbone of their detectors and assume that the bounding box proposals of an image are independent of each other. However, since such approaches only utilize the highest score proposal and discard the potentially useful information from other proposals, their independent MIL backbone often limits models to salient parts of an object or causes them to detect only one object per class. To solve the above problems, we propose a novel backbone for WSOD based on our tailored Vision Transformer named Weakly Supervised Transformer Detection Network (WSTDN). Our algorithm is not only the first to demonstrate that self-attention modules that consider inter-instance relationships are effective backbones for WSOD, but also we introduce a novel bounding box mining method (BBM) integrated with a memory transfer refinement (MTR) procedure to utilize the instance dependencies for facilitating instance refinements. Experimental results on PASCAL VOC2007 and VOC2012 benchmarks demonstrate the effectiveness of our proposed WSTDN and modified instance refinement modules.