 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DORT: Modeling Dynamic Objects in Recurrent for Multi-Camera 3D Object Detection and Tracking
Mar 29, 2023
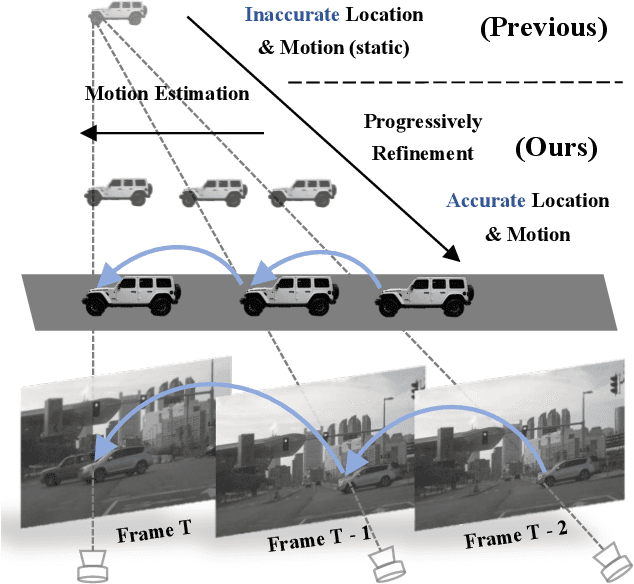
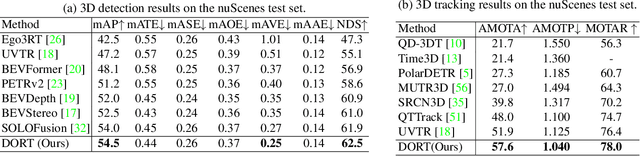
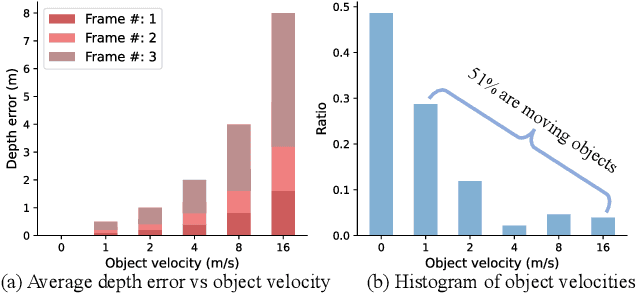
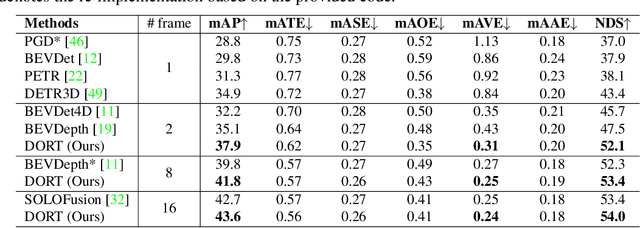
Recent multi-camera 3D object detectors usually leverage temporal information to construct multi-view stereo that alleviates the ill-posed depth estimation. However, they typically assume all the objects are static and directly aggregate features across frames. This work begins with a theoretical and empirical analysis to reveal that ignoring the motion of moving objects can result in serious localization bias. Therefore, we propose to model Dynamic Objects in RecurrenT (DORT) to tackle this problem. In contrast to previous global Bird-Eye-View (BEV) methods, DORT extracts object-wise local volumes for motion estimation that also alleviates the heavy computational burden. By iteratively refining the estimated object motion and location, the preceding features can be precisely aggregated to the current frame to mitigate the aforementioned adverse effects. The simple framework has two significant appealing properties. It is flexible and practical that can be plugged into most camera-based 3D object detectors. As there are predictions of object motion in the loop, it can easily track objects across frames according to their nearest center distances. Without bells and whistles, DORT outperforms all the previous methods on the nuScenes detection and tracking benchmarks with 62.5\% NDS and 57.6\% AMOTA, respectively. The source code will be released.
Self-positioning Point-based Transformer for Point Cloud Understanding
Mar 29, 2023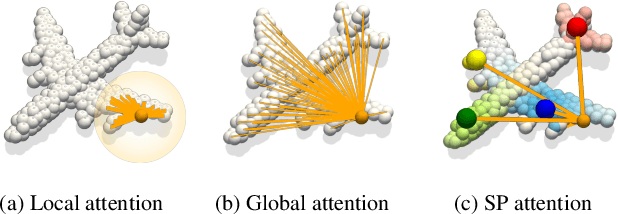
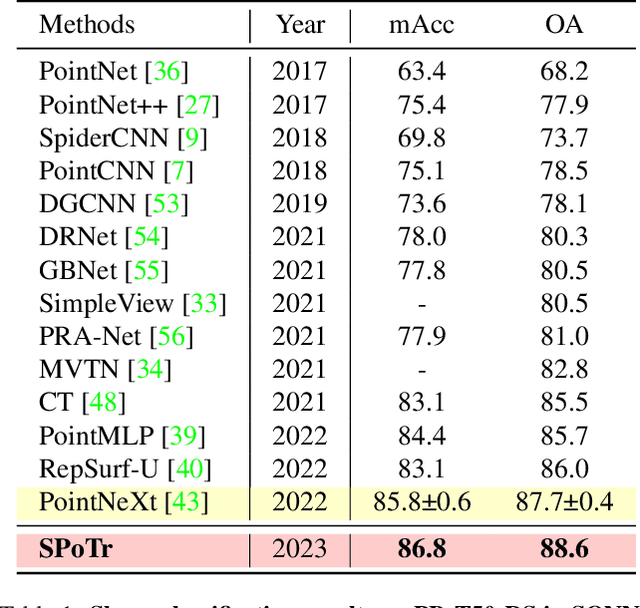
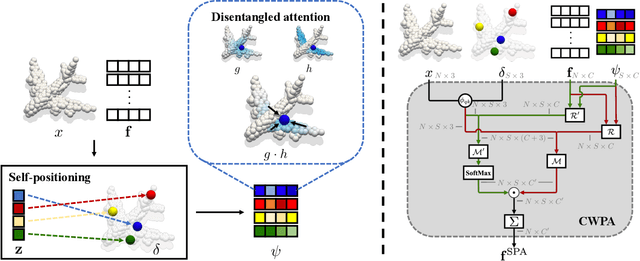
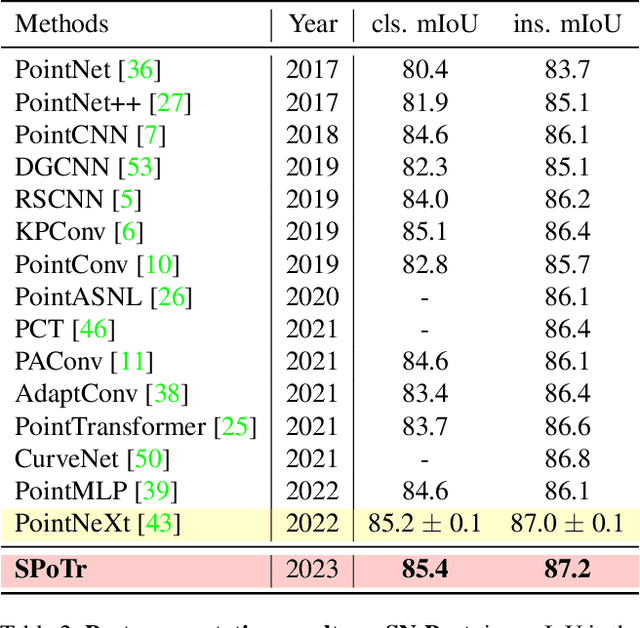
Transformers have shown superior performance on various computer vision tasks with their capabilities to capture long-range dependencies. Despite the success, it is challenging to directly apply Transformers on point clouds due to their quadratic cost in the number of points. In this paper, we present a Self-Positioning point-based Transformer (SPoTr), which is designed to capture both local and global shape contexts with reduced complexity. Specifically, this architecture consists of local self-attention and self-positioning point-based global cross-attention. The self-positioning points, adaptively located based on the input shape, consider both spatial and semantic information with disentangled attention to improve expressive power. With the self-positioning points, we propose a novel global cross-attention mechanism for point clouds, which improves the scalability of global self-attention by allowing the attention module to compute attention weights with only a small set of self-positioning points. Experiments show the effectiveness of SPoTr on three point cloud tasks such as shape classification, part segmentation, and scene segmentation. In particular, our proposed model achieves an accuracy gain of 2.6% over the previous best models on shape classification with ScanObjectNN. We also provide qualitative analyses to demonstrate the interpretability of self-positioning points. The code of SPoTr is available at https://github.com/mlvlab/SPoTr.
PartManip: Learning Cross-Category Generalizable Part Manipulation Policy from Point Cloud Observations
Mar 29, 2023


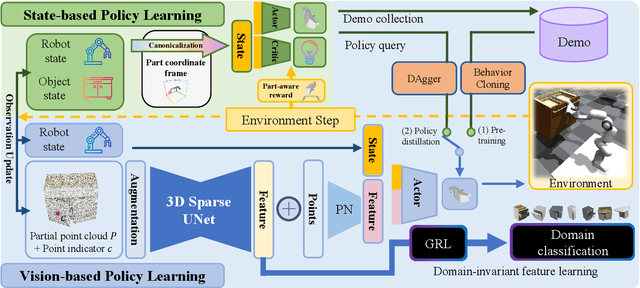
Learning a generalizable object manipulation policy is vital for an embodied agent to work in complex real-world scenes. Parts, as the shared components in different object categories, have the potential to increase the generalization ability of the manipulation policy and achieve cross-category object manipulation. In this work, we build the first large-scale, part-based cross-category object manipulation benchmark, PartManip, which is composed of 11 object categories, 494 objects, and 1432 tasks in 6 task classes. Compared to previous work, our benchmark is also more diverse and realistic, i.e., having more objects and using sparse-view point cloud as input without oracle information like part segmentation. To tackle the difficulties of vision-based policy learning, we first train a state-based expert with our proposed part-based canonicalization and part-aware rewards, and then distill the knowledge to a vision-based student. We also find an expressive backbone is essential to overcome the large diversity of different objects. For cross-category generalization, we introduce domain adversarial learning for domain-invariant feature extraction. Extensive experiments in simulation show that our learned policy can outperform other methods by a large margin, especially on unseen object categories. We also demonstrate our method can successfully manipulate novel objects in the real world.
Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios
Mar 29, 2023
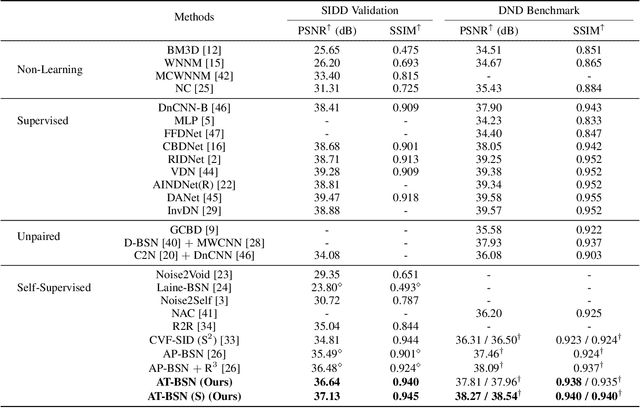
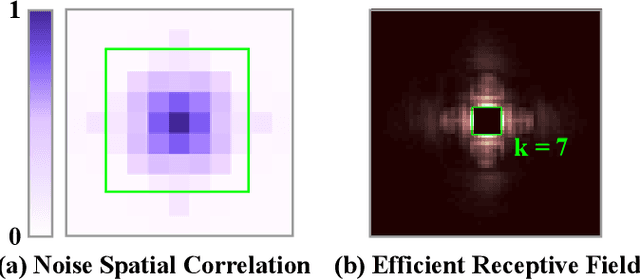
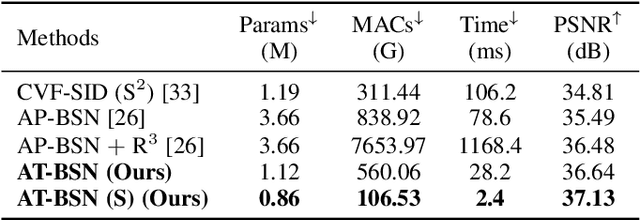
Self-supervised denoising has attracted widespread attention due to its ability to train without clean images. However, noise in real-world scenarios is often spatially correlated, which causes many self-supervised algorithms based on the pixel-wise independent noise assumption to perform poorly on real-world images. Recently, asymmetric pixel-shuffle downsampling (AP) has been proposed to disrupt the spatial correlation of noise. However, downsampling introduces aliasing effects, and the post-processing to eliminate these effects can destroy the spatial structure and high-frequency details of the image, in addition to being time-consuming. In this paper, we systematically analyze downsampling-based methods and propose an Asymmetric Tunable Blind-Spot Network (AT-BSN) to address these issues. We design a blind-spot network with a freely tunable blind-spot size, using a large blind-spot during training to suppress local spatially correlated noise while minimizing damage to the global structure, and a small blind-spot during inference to minimize information loss. Moreover, we propose blind-spot self-ensemble and distillation of non-blind-spot network to further improve performance and reduce computational complexity. Experimental results demonstrate that our method achieves state-of-the-art results while comprehensively outperforming other self-supervised methods in terms of image texture maintaining, parameter count, computation cost, and inference time.
Improving Data Transfer Efficiency for AIs in the DareFightingICE using gRPC
Mar 11, 2023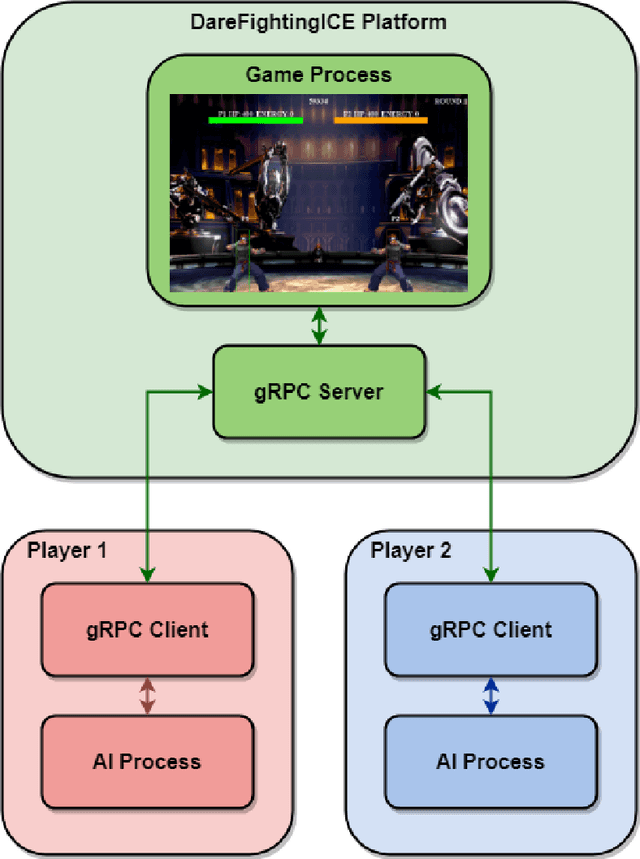
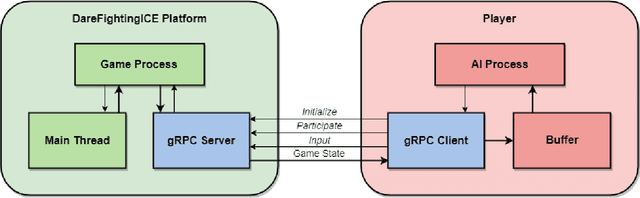
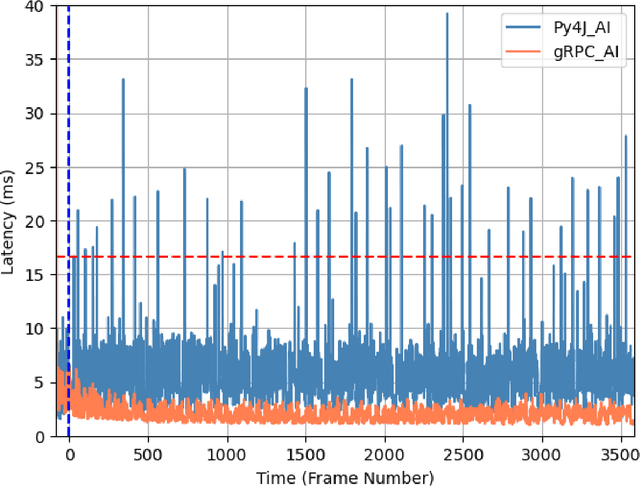
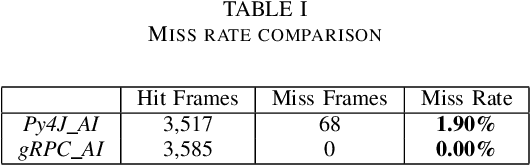
This paper presents a new communication interface for the DareFightingICE platform, a Java-based fighting game focused on implementing AI for controlling a non-player character. The interface uses an open-source remote procedure call, gRPC to improve the efficiency of data transfer between the game and the AI, reducing the time spent on receiving information from the game server. This is important because the main challenge of implementing AI in a fighting game is the need for the AI to select an action to perform within a short response time. The DareFightingICE platform has been integrated with Py4J, allowing developers to create AIs using Python. However, Py4J is less efficient at handling large amounts of data, resulting in excessive latency. In contrast, gRPC is well-suited for transmitting large amounts of data. To evaluate the effectiveness of the new communication interface, we conducted an experiment comparing the latency of gRPC and Py4J, using a rule-based AI that sends a kick command regardless of the information received from the game server. The experiment results showed not only a 65\% reduction in latency but also improved stability and eliminated missed frames compared to the current interface.
Cross-Tool and Cross-Behavior Perceptual Knowledge Transfer for Grounded Object Recognition
Mar 07, 2023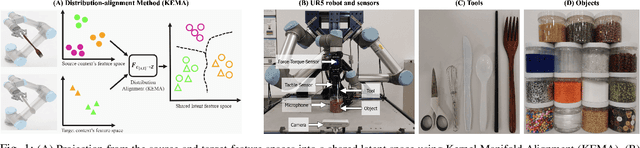
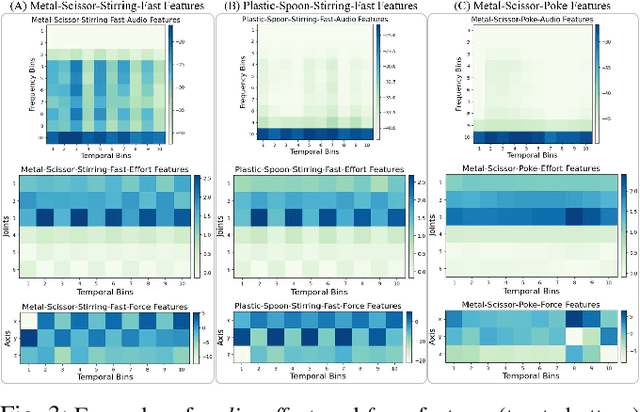
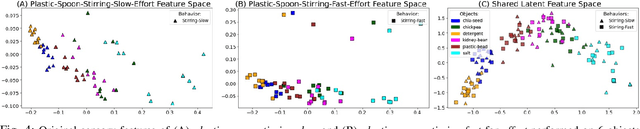
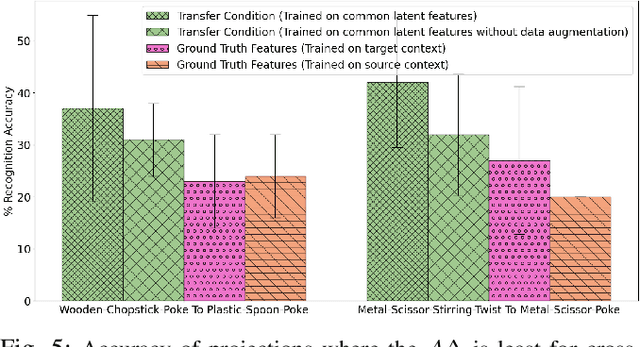
Humans learn about objects via interaction and using multiple perceptions, such as vision, sound, and touch. While vision can provide information about an object's appearance, non-visual sensors, such as audio and haptics, can provide information about its intrinsic properties, such as weight, temperature, hardness, and the object's sound. Using tools to interact with objects can reveal additional object properties that are otherwise hidden (e.g., knives and spoons can be used to examine the properties of food, including its texture and consistency). Robots can use tools to interact with objects and gather information about their implicit properties via non-visual sensors. However, a robot's model for recognizing objects using a tool-mediated behavior does not generalize to a new tool or behavior due to differing observed data distributions. To address this challenge, we propose a framework to enable robots to transfer implicit knowledge about granular objects across different tools and behaviors. The proposed approach learns a shared latent space from multiple robots' contexts produced by respective sensory data while interacting with objects using tools. We collected a dataset using a UR5 robot that performed 5,400 interactions using 6 tools and 6 behaviors on 15 granular objects and tested our method on cross-tool and cross-behavioral transfer tasks. Our results show the less experienced target robot can benefit from the experience gained from the source robot and perform recognition on a set of novel objects. We have released the code, datasets, and additional results: https://github.com/gtatiya/Tool-Knowledge-Transfer.
Energy Efficiency of Rate-Splitting Multiple Access for Multibeam Satellite System
Mar 19, 2023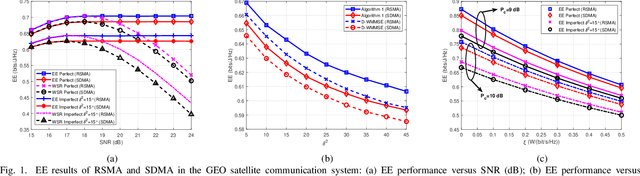

Energy efficiency (EE) problem has become an important and major issue in satellite communications. In this paper, we study the beamforming design strategy to maximize the EE of rate-splitting multiple access (RSMA) for the multibeam satellite communications by considering imperfect channel state information at the transmitter (CSIT). We propose an expectation-based robust beamforming algorithm against the imperfect CSIT scenario. By combining the successive convex approximation (SCA) with the penalty function transformation, the nonconvex EE maximization problem can be solved in an iterative manner. The simulation results demonstrate the effectiveness and superiority of RSMA over traditional space division multiple access (SDMA). Moreover, our proposed beamforming algorithm can achieve better EE performance than the conventional beamforming algorithm.
MATIS: Masked-Attention Transformers for Surgical Instrument Segmentation
Mar 19, 2023
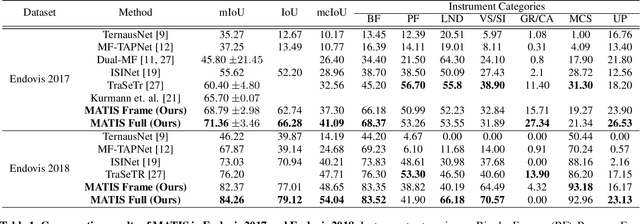
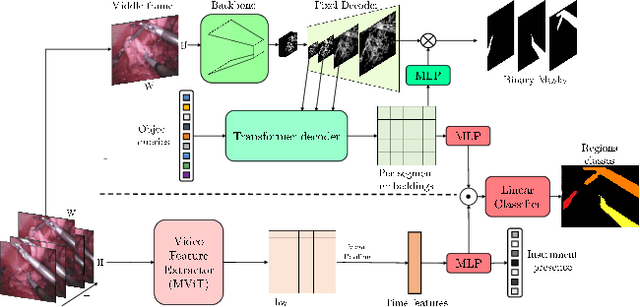

We propose Masked-Attention Transformers for Surgical Instrument Segmentation (MATIS), a two-stage, fully transformer-based method that leverages modern pixel-wise attention mechanisms for instrument segmentation. MATIS exploits the instance-level nature of the task by employing a masked attention module that generates and classifies a set of fine instrument region proposals. Our method incorporates long-term video-level information through video transformers to improve temporal consistency and enhance mask classification. We validate our approach in the two standard public benchmarks, Endovis 2017 and Endovis 2018. Our experiments demonstrate that MATIS' per-frame baseline outperforms previous state-of-the-art methods and that including our temporal consistency module boosts our model's performance further.
Knowledge Graphs: Opportunities and Challenges
Mar 24, 2023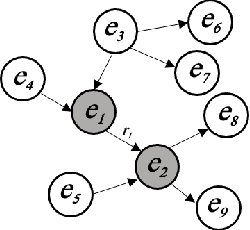
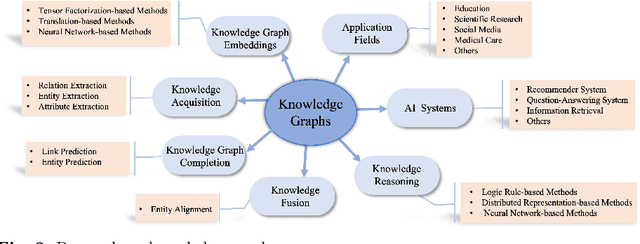
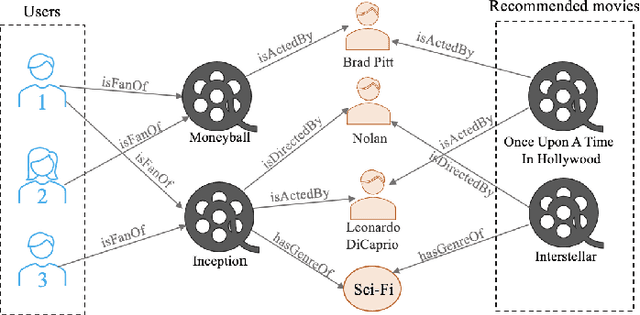
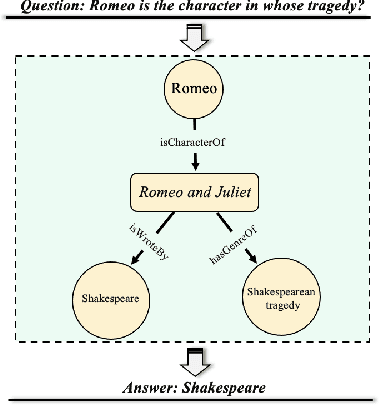
With the explosive growth of artificial intelligence (AI) and big data, it has become vitally important to organize and represent the enormous volume of knowledge appropriately. As graph data, knowledge graphs accumulate and convey knowledge of the real world. It has been well-recognized that knowledge graphs effectively represent complex information; hence, they rapidly gain the attention of academia and industry in recent years. Thus to develop a deeper understanding of knowledge graphs, this paper presents a systematic overview of this field. Specifically, we focus on the opportunities and challenges of knowledge graphs. We first review the opportunities of knowledge graphs in terms of two aspects: (1) AI systems built upon knowledge graphs; (2) potential application fields of knowledge graphs. Then, we thoroughly discuss severe technical challenges in this field, such as knowledge graph embeddings, knowledge acquisition, knowledge graph completion, knowledge fusion, and knowledge reasoning. We expect that this survey will shed new light on future research and the development of knowledge graphs.
Depression detection in social media posts using affective and social norm features
Mar 24, 2023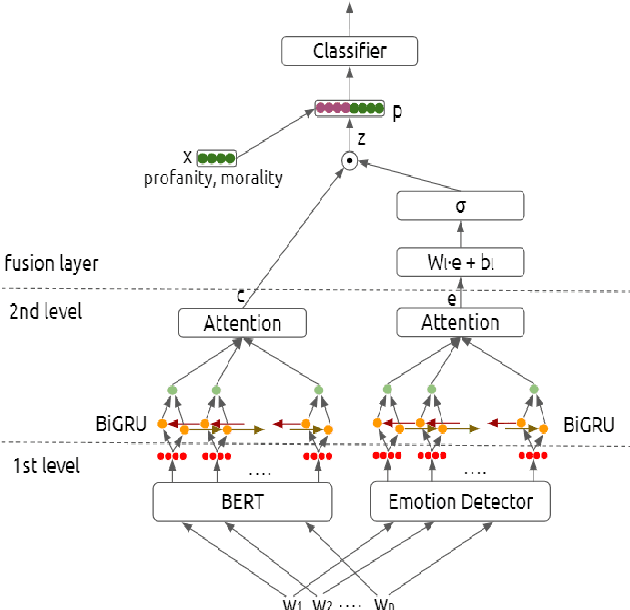


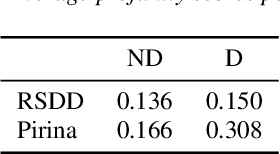
We propose a deep architecture for depression detection from social media posts. The proposed architecture builds upon BERT to extract language representations from social media posts and combines these representations using an attentive bidirectional GRU network. We incorporate affective information, by augmenting the text representations with features extracted from a pretrained emotion classifier. Motivated by psychological literature we propose to incorporate profanity and morality features of posts and words in our architecture using a late fusion scheme. Our analysis indicates that morality and profanity can be important features for depression detection. We apply our model for depression detection on Reddit posts on the Pirina dataset, and further consider the setting of detecting depressed users, given multiple posts per user, proposed in the Reddit RSDD dataset. The inclusion of the proposed features yields state-of-the-art results in both settings, namely 2.65% and 6.73% absolute improvement in F1 score respectively. Index Terms: Depression detection, BERT, Feature fusion, Emotion recognition, profanity, morality