 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Asservissement visuel 3D direct dans le domaine spectral
Apr 03, 2023
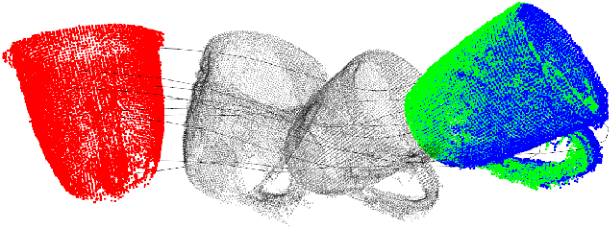

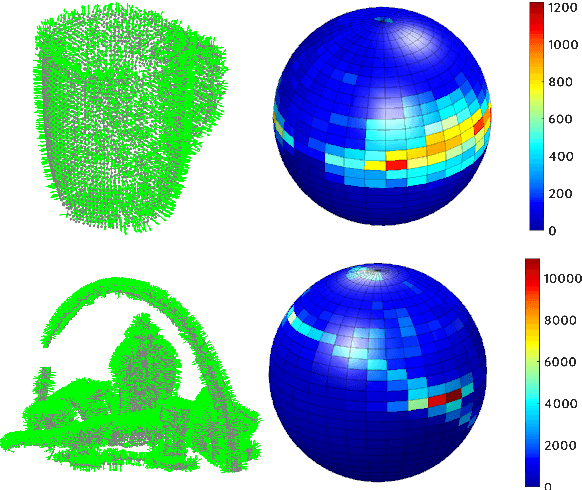
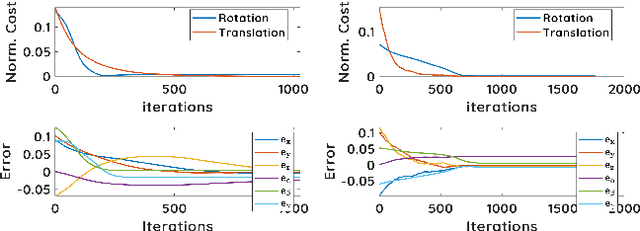
This paper presents a direct 3D visual servo scheme for the automatic alignment of point clouds (respectively, objects) using visual information in the spectral domain. Specifically, we propose an alignment method for 3D models/point clouds that works by estimating the global transformation between a reference point cloud and a target point cloud using harmonic domain data analysis. A 3D discrete Fourier transform (DFT) in $\mathbb{R}^3$ is used for translation estimation and real spherical harmonics in $SO(3)$ are used for rotation estimation. This approach allows us to derive a decoupled visual servo controller with 6 degrees of freedom. We then show how this approach can be used as a controller for a robotic arm to perform a positioning task. Unlike existing 3D visual servo methods, our method works well with partial point clouds and in cases of large initial transformations between the initial and desired position. Additionally, using spectral data (instead of spatial data) for the transformation estimation makes our method robust to sensor-induced noise and partial occlusions. Our method has been successfully validated experimentally on point clouds obtained with a depth camera mounted on a robotic arm.
IELM: An Open Information Extraction Benchmark for Pre-Trained Language Models
Oct 25, 2022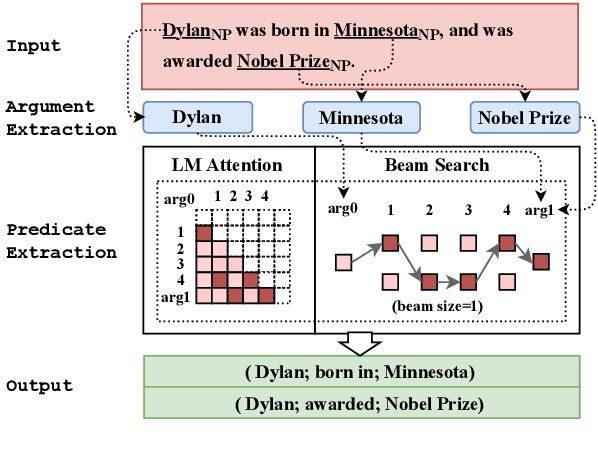
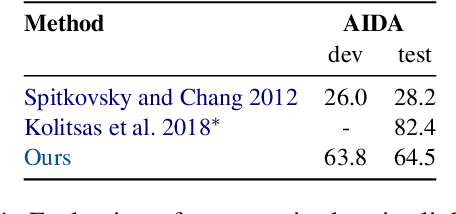
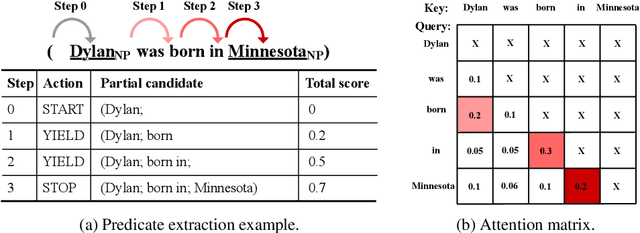
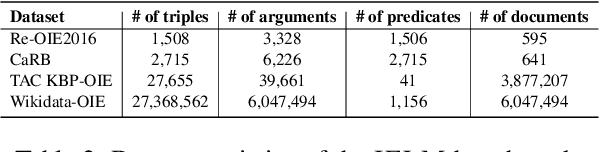
We introduce a new open information extraction (OIE) benchmark for pre-trained language models (LM). Recent studies have demonstrated that pre-trained LMs, such as BERT and GPT, may store linguistic and relational knowledge. In particular, LMs are able to answer ``fill-in-the-blank'' questions when given a pre-defined relation category. Instead of focusing on pre-defined relations, we create an OIE benchmark aiming to fully examine the open relational information present in the pre-trained LMs. We accomplish this by turning pre-trained LMs into zero-shot OIE systems. Surprisingly, pre-trained LMs are able to obtain competitive performance on both standard OIE datasets (CaRB and Re-OIE2016) and two new large-scale factual OIE datasets (TAC KBP-OIE and Wikidata-OIE) that we establish via distant supervision. For instance, the zero-shot pre-trained LMs outperform the F1 score of the state-of-the-art supervised OIE methods on our factual OIE datasets without needing to use any training sets. Our code and datasets are available at https://github.com/cgraywang/IELM
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023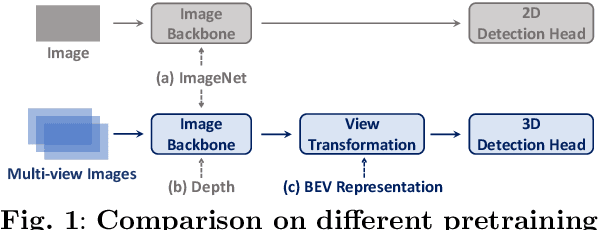
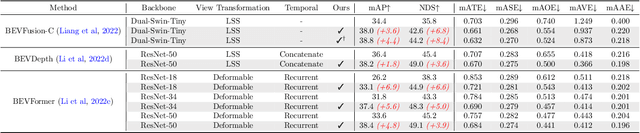
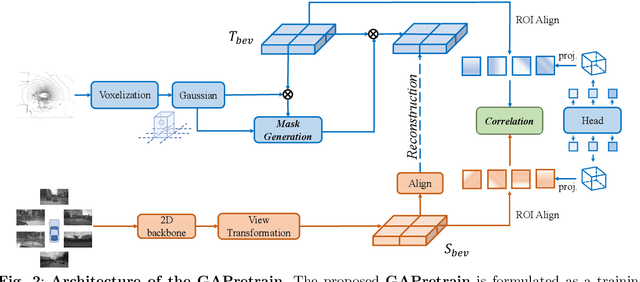
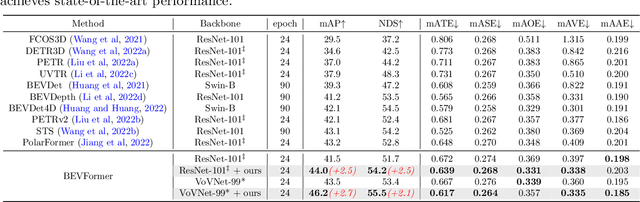
Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
BS-GAT Behavior Similarity Based Graph Attention Network for Network Intrusion Detection
Apr 07, 2023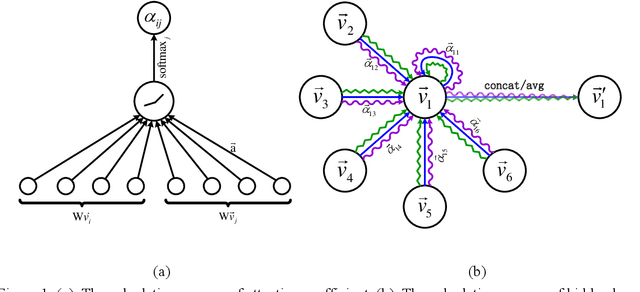
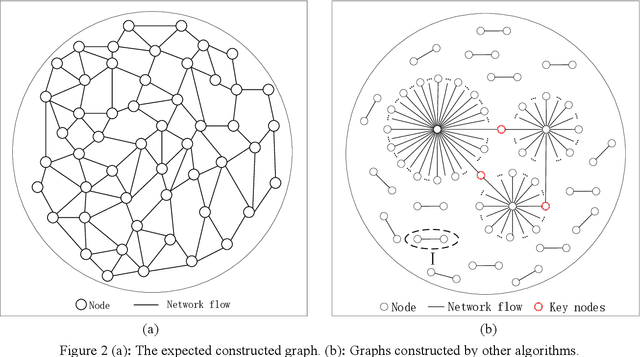
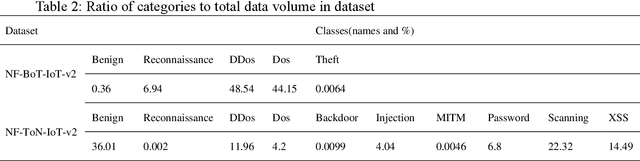
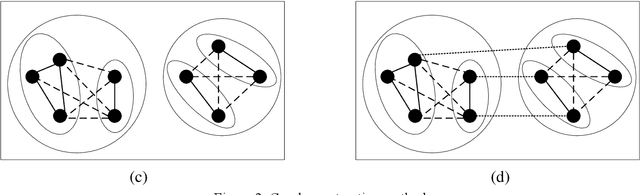
With the development of the Internet of Things (IoT), network intrusion detection is becoming more complex and extensive. It is essential to investigate an intelligent, automated, and robust network intrusion detection method. Graph neural networks based network intrusion detection methods have been proposed. However, it still needs further studies because the graph construction method of the existing methods does not fully adapt to the characteristics of the practical network intrusion datasets. To address the above issue, this paper proposes a graph neural network algorithm based on behavior similarity (BS-GAT) using graph attention network. First, a novel graph construction method is developed using the behavior similarity by analyzing the characteristics of the practical datasets. The data flows are treated as nodes in the graph, and the behavior rules of nodes are used as edges in the graph, constructing a graph with a relatively uniform number of neighbors for each node. Then, the edge behavior relationship weights are incorporated into the graph attention network to utilize the relationship between data flows and the structure information of the graph, which is used to improve the performance of the network intrusion detection. Finally, experiments are conducted based on the latest datasets to evaluate the performance of the proposed behavior similarity based graph attention network for the network intrusion detection. The results show that the proposed method is effective and has superior performance comparing to existing solutions.
Event Fusion Photometric Stereo Network
Mar 11, 2023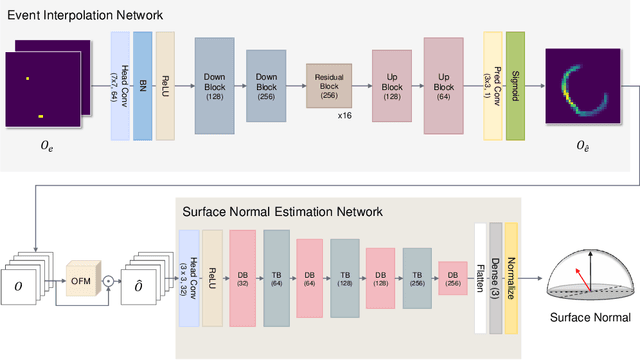
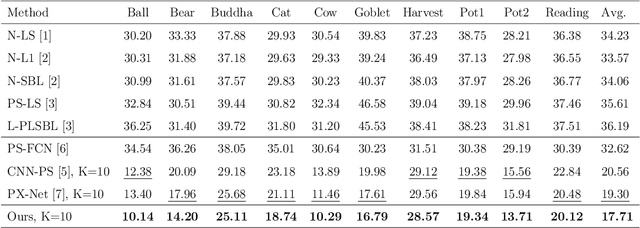
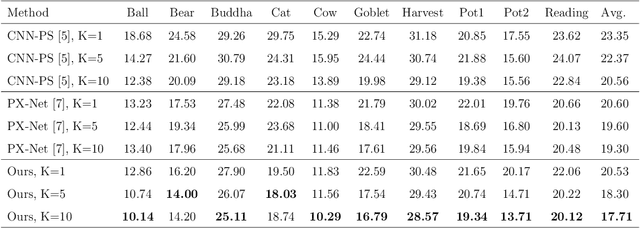
We present a novel method to estimate the surface normal of an object in an ambient light environment using RGB and event cameras. Modern photometric stereo methods rely on an RGB camera, mainly in a dark room, to avoid ambient illumination. To alleviate the limitations of the darkroom environment and to use essential light information, we employ an event camera with a high dynamic range and low latency. This is the first study that uses an event camera for the photometric stereo task, which works on continuous light sources and ambient light environment. In this work, we also curate a novel photometric stereo dataset that is constructed by capturing objects with event and RGB cameras under numerous ambient lights environment. Additionally, we propose a novel framework named Event Fusion Photometric Stereo Network~(EFPS-Net), which estimates the surface normals of an object using both RGB frames and event signals. Our proposed method interpolates event observation maps that generate light information with sparse event signals to acquire fluent light information. Subsequently, the event-interpolated observation maps are fused with the RGB observation maps. Our numerous experiments showed that EFPS-Net outperforms state-of-the-art methods on a dataset captured in the real world where ambient lights exist. Consequently, we demonstrate that incorporating additional modalities with EFPS-Net alleviates the limitations that occurred from ambient illumination.
Graph Neural Networks for Multi-Robot Active Information Acquisition
Sep 24, 2022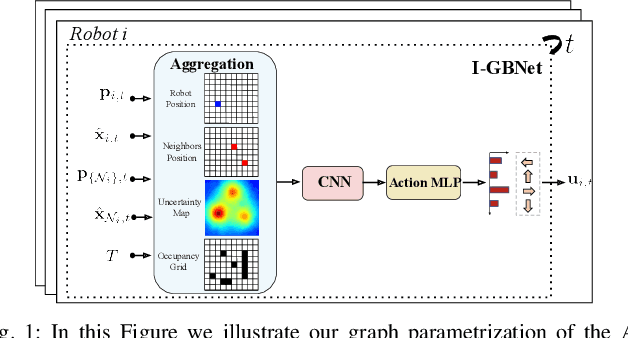
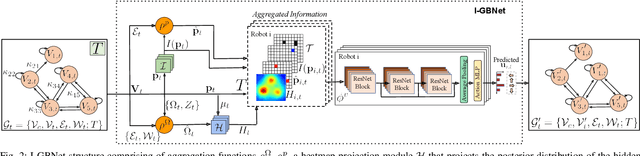
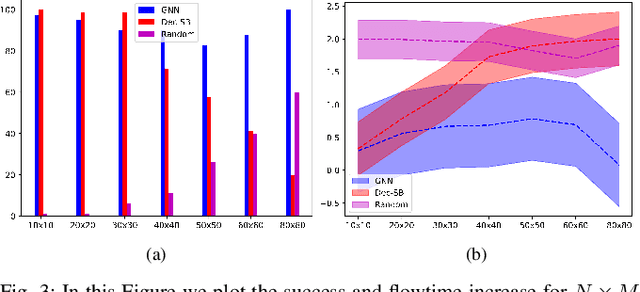
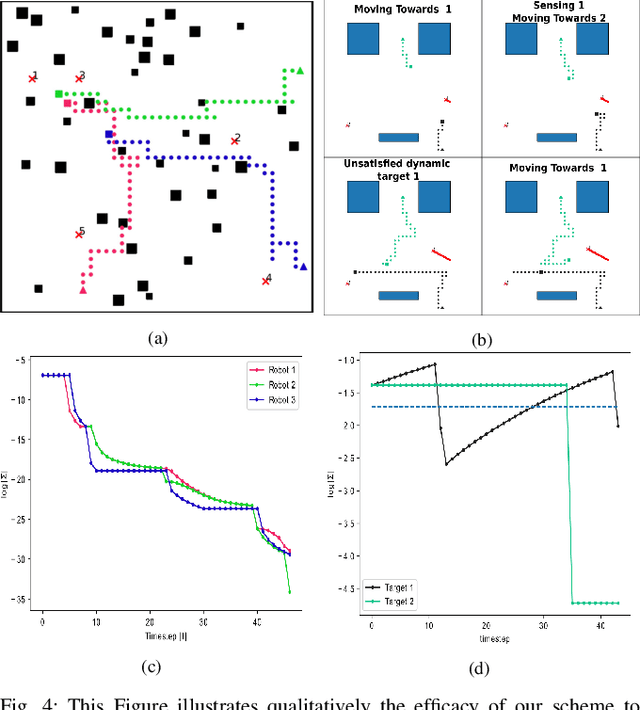
This paper addresses the Multi-Robot Active Information Acquisition (AIA) problem, where a team of mobile robots, communicating through an underlying graph, estimates a hidden state expressing a phenomenon of interest. Applications like target tracking, coverage and SLAM can be expressed in this framework. Existing approaches, though, are either not scalable, unable to handle dynamic phenomena or not robust to changes in the communication graph. To counter these shortcomings, we propose an Information-aware Graph Block Network (I-GBNet), an AIA adaptation of Graph Neural Networks, that aggregates information over the graph representation and provides sequential-decision making in a distributed manner. The I-GBNet, trained via imitation learning with a centralized sampling-based expert solver, exhibits permutation equivariance and time invariance, while harnessing the superior scalability, robustness and generalizability to previously unseen environments and robot configurations. Experiments on significantly larger graphs and dimensionality of the hidden state and more complex environments than those seen in training validate the properties of the proposed architecture and its efficacy in the application of localization and tracking of dynamic targets.
Don't PANIC: Prototypical Additive Neural Network for Interpretable Classification of Alzheimer's Disease
Mar 14, 2023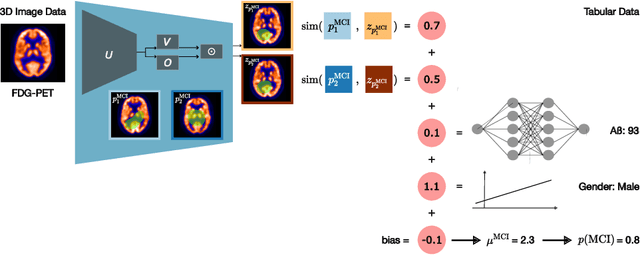
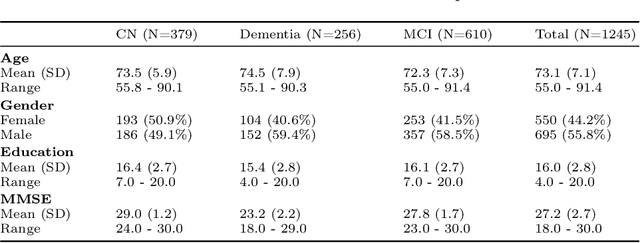
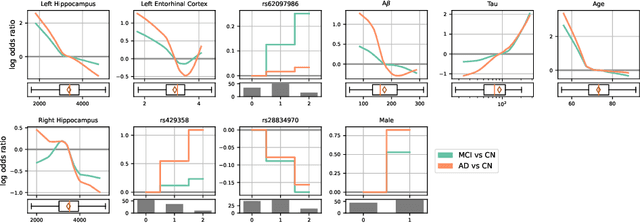
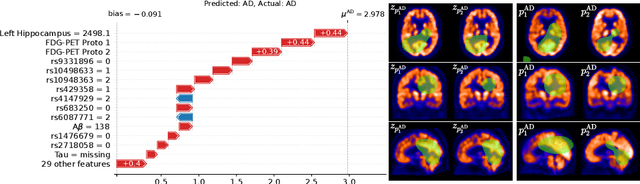
Alzheimer's disease (AD) has a complex and multifactorial etiology, which requires integrating information about neuroanatomy, genetics, and cerebrospinal fluid biomarkers for accurate diagnosis. Hence, recent deep learning approaches combined image and tabular information to improve diagnostic performance. However, the black-box nature of such neural networks is still a barrier for clinical applications, in which understanding the decision of a heterogeneous model is integral. We propose PANIC, a prototypical additive neural network for interpretable AD classification that integrates 3D image and tabular data. It is interpretable by design and, thus, avoids the need for post-hoc explanations that try to approximate the decision of a network. Our results demonstrate that PANIC achieves state-of-the-art performance in AD classification, while directly providing local and global explanations. Finally, we show that PANIC extracts biologically meaningful signatures of AD, and satisfies a set of desirable desiderata for trustworthy machine learning. Our implementation is available at https://github.com/ai-med/PANIC .
Dual-Attention Deep Reinforcement Learning for Multi-MAP 3D Trajectory Optimization in Dynamic 5G Networks
Mar 14, 2023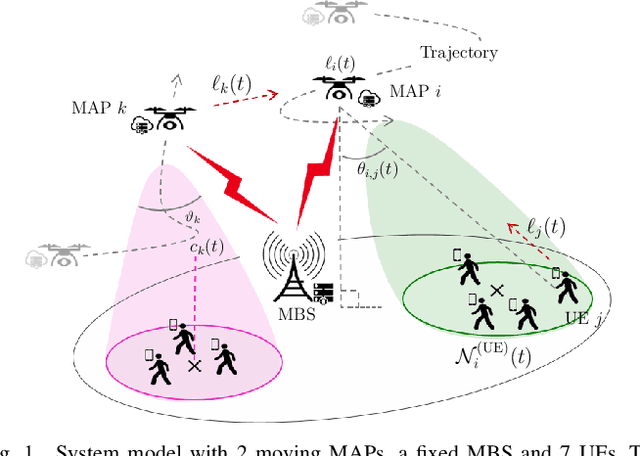
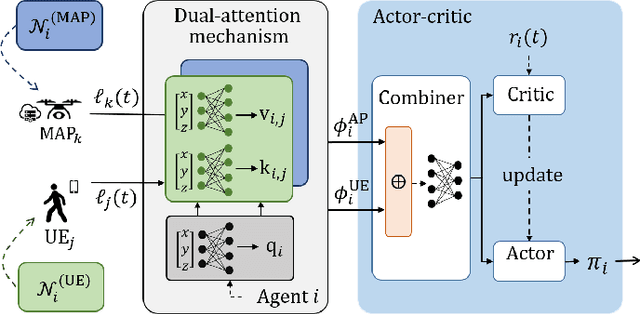
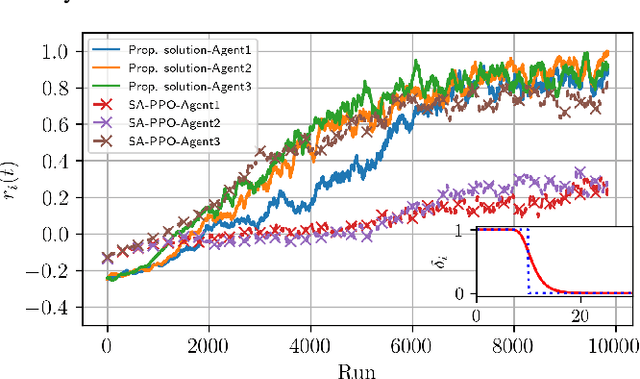
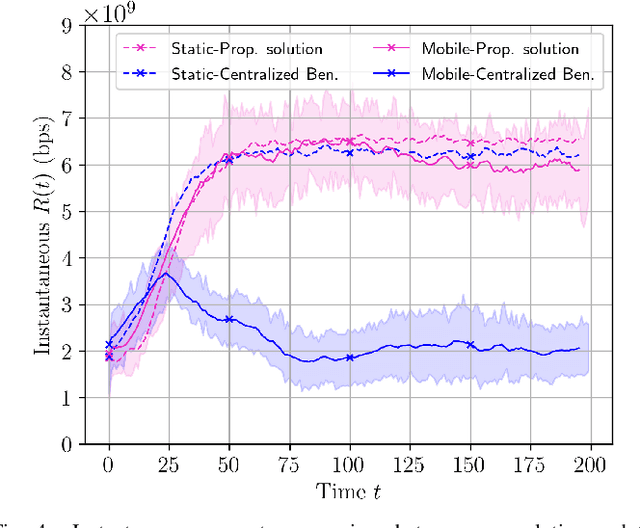
5G and beyond networks need to provide dynamic and efficient infrastructure management to better adapt to time-varying user behaviors (e.g., user mobility, interference, user traffic and evolution of the network topology). In this paper, we propose to manage the trajectory of Mobile Access Points (MAPs) under all these dynamic constraints with reduced complexity. We first formulate the placement problem to manage MAPs over time. Our solution addresses time-varying user traffic and user mobility through a Multi-Agent Deep Reinforcement Learning (MADRL). To achieve real-time behavior, the proposed solution learns to perform distributed assignment of MAP-user positions and schedules the MAP path among all users without centralized user's clustering feedback. Our solution exploits a dual-attention MADRL model via proximal policy optimization to dynamically move MAPs in 3D. The dual-attention takes into account information from both users and MAPs. The cooperation mechanism of our solution allows to manage different scenarios, without a priory information and without re-training, which significantly reduces complexity.
Co-Salient Object Detection with Co-Representation Purification
Mar 14, 2023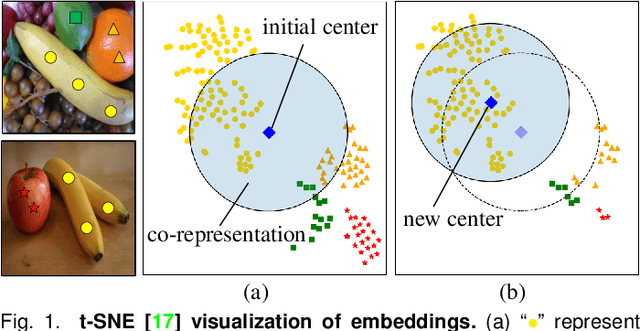
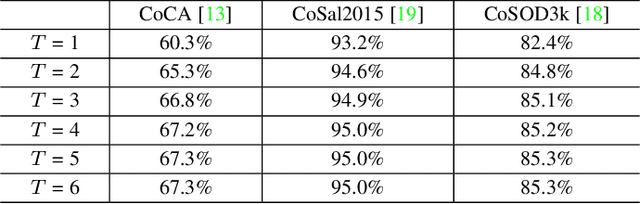
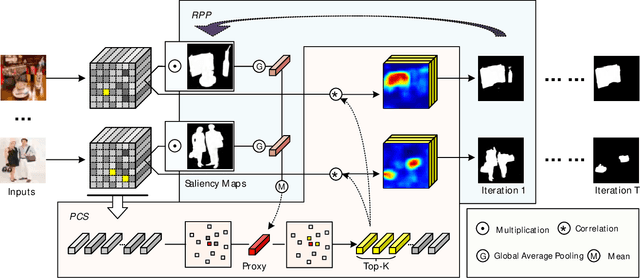
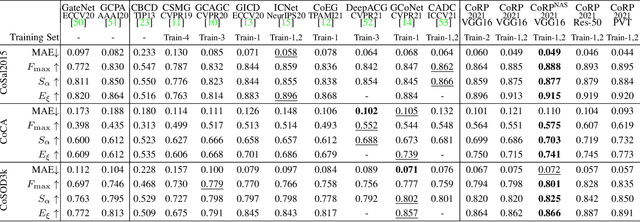
Co-salient object detection (Co-SOD) aims at discovering the common objects in a group of relevant images. Mining a co-representation is essential for locating co-salient objects. Unfortunately, the current Co-SOD method does not pay enough attention that the information not related to the co-salient object is included in the co-representation. Such irrelevant information in the co-representation interferes with its locating of co-salient objects. In this paper, we propose a Co-Representation Purification (CoRP) method aiming at searching noise-free co-representation. We search a few pixel-wise embeddings probably belonging to co-salient regions. These embeddings constitute our co-representation and guide our prediction. For obtaining purer co-representation, we use the prediction to iteratively reduce irrelevant embeddings in our co-representation. Experiments on three datasets demonstrate that our CoRP achieves state-of-the-art performances on the benchmark datasets. Our source code is available at https://github.com/ZZY816/CoRP.
Deep Prototypical-Parts Ease Morphological Kidney Stone Identification and are Competitively Robust to Photometric Perturbations
Apr 08, 2023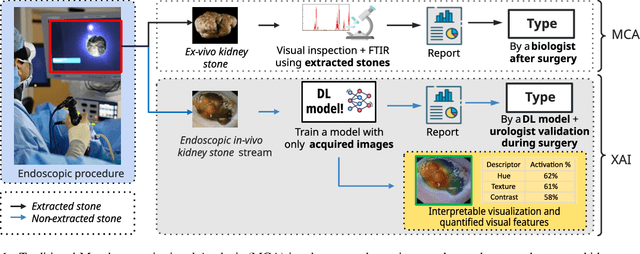
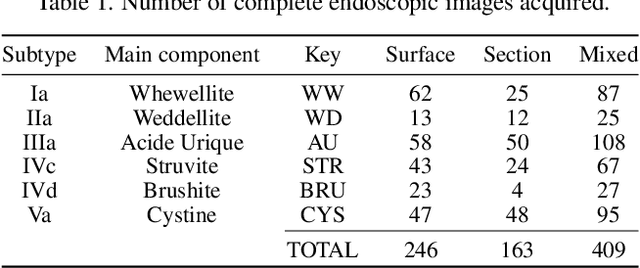

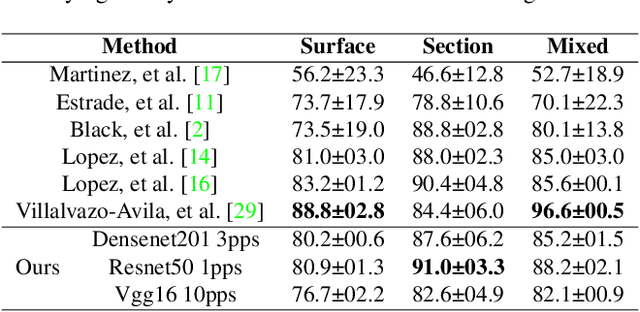
Identifying the type of kidney stones can allow urologists to determine their cause of formation, improving the prescription of appropriate treatments to diminish future relapses. Currently, the associated ex-vivo diagnosis (known as Morpho-constitutional Analysis, MCA) is time-consuming, expensive and requires a great deal of experience, as it requires a visual analysis component that is highly operator dependant. Recently, machine learning methods have been developed for in-vivo endoscopic stone recognition. Deep Learning (DL) based methods outperform non-DL methods in terms of accuracy but lack explainability. Despite this trade-off, when it comes to making high-stakes decisions, it's important to prioritize understandable Computer-Aided Diagnosis (CADx) that suggests a course of action based on reasonable evidence, rather than a model prescribing a course of action. In this proposal, we learn Prototypical Parts (PPs) per kidney stone subtype, which are used by the DL model to generate an output classification. Using PPs in the classification task enables case-based reasoning explanations for such output, thus making the model interpretable. In addition, we modify global visual characteristics to describe their relevance to the PPs and the sensitivity of our model's performance. With this, we provide explanations with additional information at the sample, class and model levels in contrast to previous works. Although our implementation's average accuracy is lower than state-of-the-art (SOTA) non-interpretable DL models by 1.5 %, our models perform 2.8% better on perturbed images with a lower standard deviation, without adversarial training. Thus, Learning PPs has the potential to create more robust DL models.