 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Impact of Voice Anonymization on Speech-Based COVID-19 Detection
Apr 05, 2023
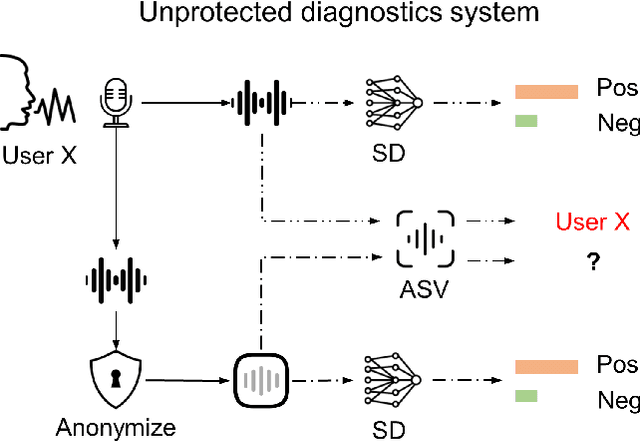
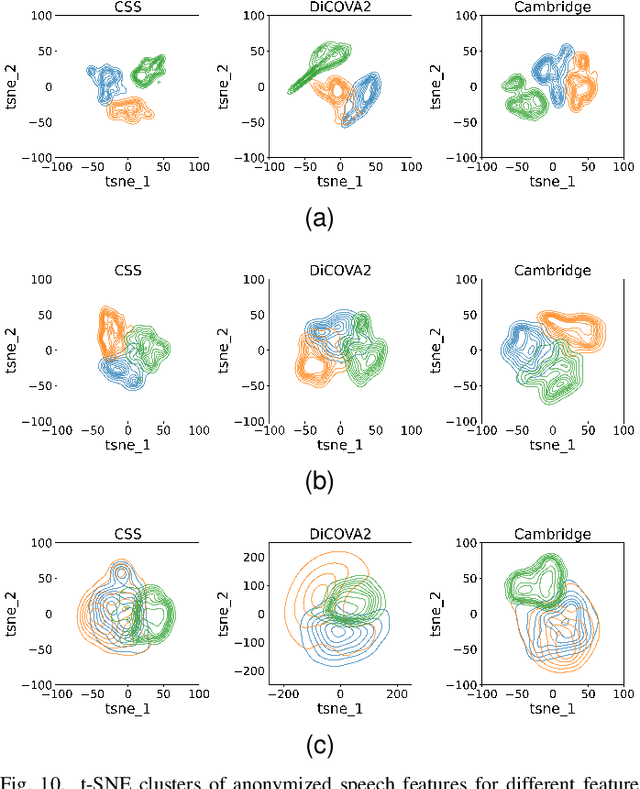
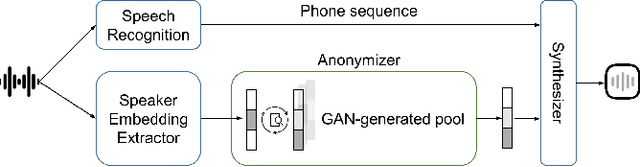
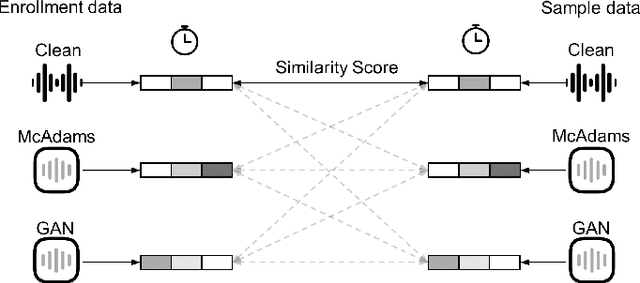
With advances seen in deep learning, voice-based applications are burgeoning, ranging from personal assistants, affective computing, to remote disease diagnostics. As the voice contains both linguistic and paralinguistic information (e.g., vocal pitch, intonation, speech rate, loudness), there is growing interest in voice anonymization to preserve speaker privacy and identity. Voice privacy challenges have emerged over the last few years and focus has been placed on removing speaker identity while keeping linguistic content intact. For affective computing and disease monitoring applications, however, the paralinguistic content may be more critical. Unfortunately, the effects that anonymization may have on these systems are still largely unknown. In this paper, we fill this gap and focus on one particular health monitoring application: speech-based COVID-19 diagnosis. We test two popular anonymization methods and their impact on five different state-of-the-art COVID-19 diagnostic systems using three public datasets. We validate the effectiveness of the anonymization methods, compare their computational complexity, and quantify the impact across different testing scenarios for both within- and across-dataset conditions. Lastly, we show the benefits of anonymization as a data augmentation tool to help recover some of the COVID-19 diagnostic accuracy loss seen with anonymized data.
To ChatGPT, or not to ChatGPT: That is the question!
Apr 05, 2023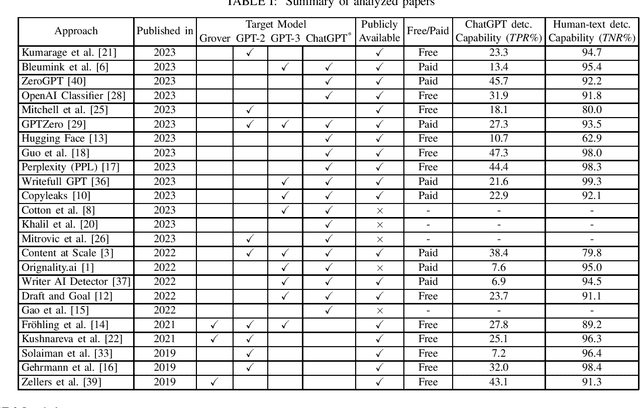
ChatGPT has become a global sensation. As ChatGPT and other Large Language Models (LLMs) emerge, concerns of misusing them in various ways increase, such as disseminating fake news, plagiarism, manipulating public opinion, cheating, and fraud. Hence, distinguishing AI-generated from human-generated becomes increasingly essential. Researchers have proposed various detection methodologies, ranging from basic binary classifiers to more complex deep-learning models. Some detection techniques rely on statistical characteristics or syntactic patterns, while others incorporate semantic or contextual information to improve accuracy. The primary objective of this study is to provide a comprehensive and contemporary assessment of the most recent techniques in ChatGPT detection. Additionally, we evaluated other AI-generated text detection tools that do not specifically claim to detect ChatGPT-generated content to assess their performance in detecting ChatGPT-generated content. For our evaluation, we have curated a benchmark dataset consisting of prompts from ChatGPT and humans, including diverse questions from medical, open Q&A, and finance domains and user-generated responses from popular social networking platforms. The dataset serves as a reference to assess the performance of various techniques in detecting ChatGPT-generated content. Our evaluation results demonstrate that none of the existing methods can effectively detect ChatGPT-generated content.
Conceptual Reinforcement Learning for Language-Conditioned Tasks
Mar 09, 2023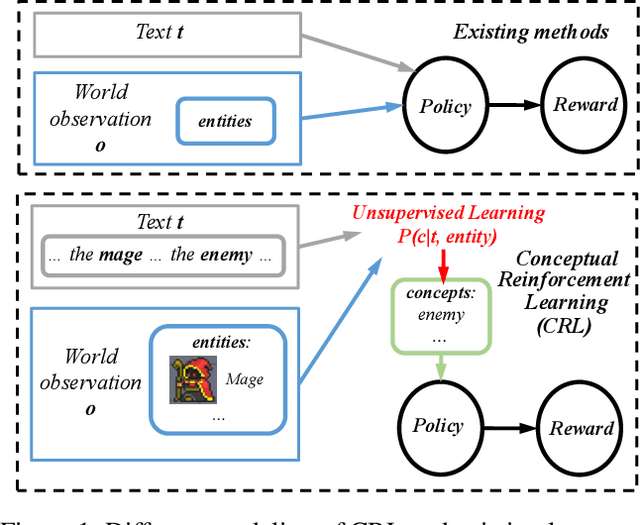
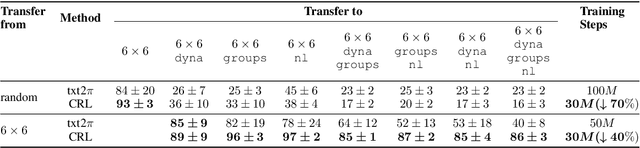
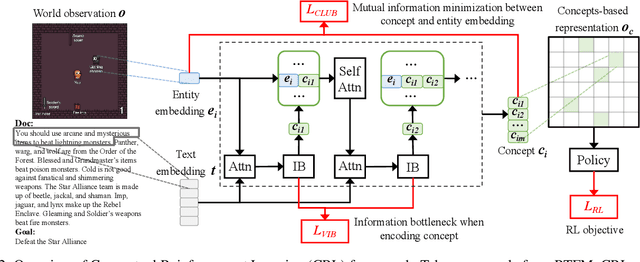
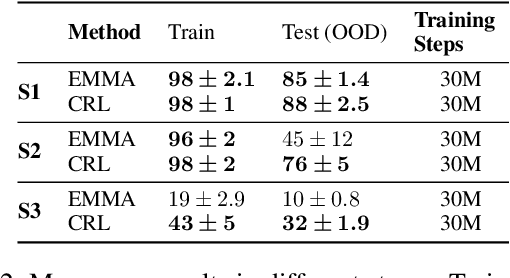
Despite the broad application of deep reinforcement learning (RL), transferring and adapting the policy to unseen but similar environments is still a significant challenge. Recently, the language-conditioned policy is proposed to facilitate policy transfer through learning the joint representation of observation and text that catches the compact and invariant information across environments. Existing studies of language-conditioned RL methods often learn the joint representation as a simple latent layer for the given instances (episode-specific observation and text), which inevitably includes noisy or irrelevant information and cause spurious correlations that are dependent on instances, thus hurting generalization performance and training efficiency. To address this issue, we propose a conceptual reinforcement learning (CRL) framework to learn the concept-like joint representation for language-conditioned policy. The key insight is that concepts are compact and invariant representations in human cognition through extracting similarities from numerous instances in real-world. In CRL, we propose a multi-level attention encoder and two mutual information constraints for learning compact and invariant concepts. Verified in two challenging environments, RTFM and Messenger, CRL significantly improves the training efficiency (up to 70%) and generalization ability (up to 30%) to the new environment dynamics.
Multi-view knowledge distillation transformer for human action recognition
Mar 25, 2023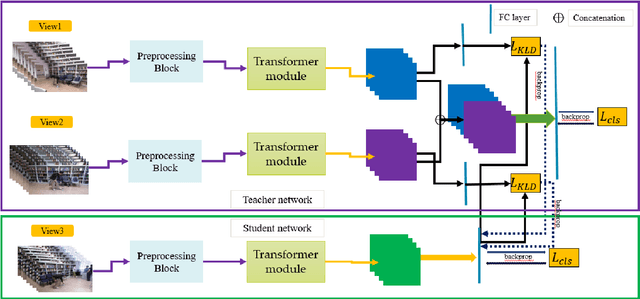

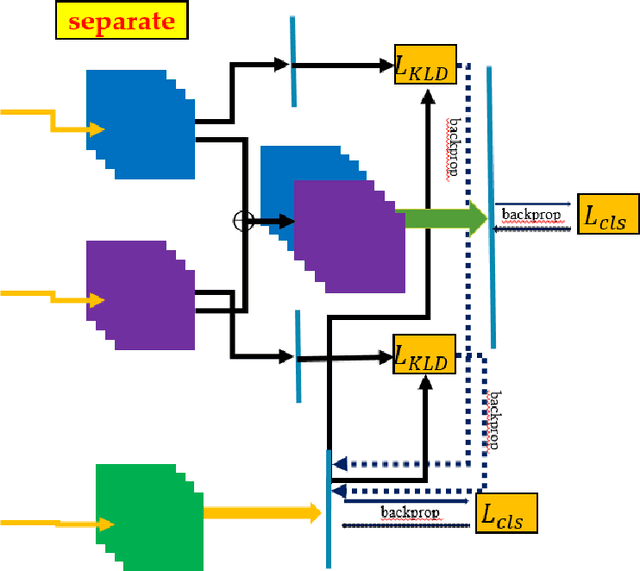

Recently, Transformer-based methods have been utilized to improve the performance of human action recognition. However, most of these studies assume that multi-view data is complete, which may not always be the case in real-world scenarios. Therefore, this paper presents a novel Multi-view Knowledge Distillation Transformer (MKDT) framework that consists of a teacher network and a student network. This framework aims to handle incomplete human action problems in real-world applications. Specifically, the multi-view knowledge distillation transformer uses a hierarchical vision transformer with shifted windows to capture more spatial-temporal information. Experimental results demonstrate that our framework outperforms the CNN-based method on three public datasets.
The Multiscale Surface Vision Transformer
Mar 21, 2023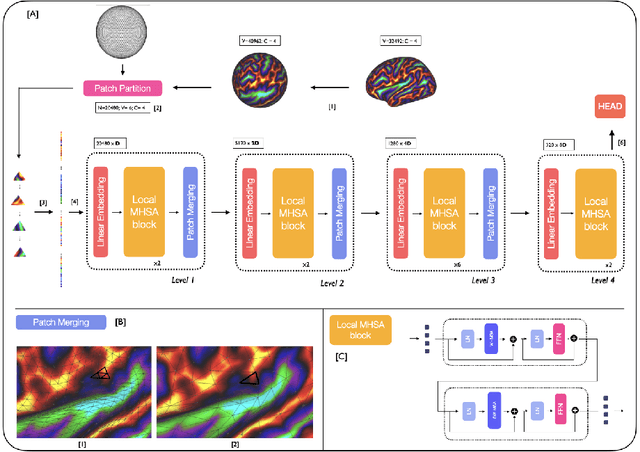
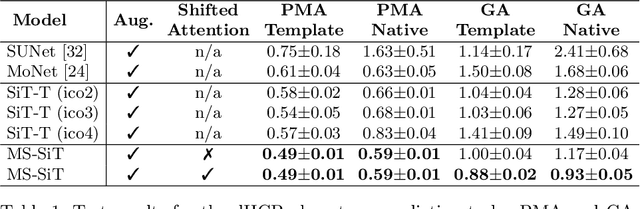
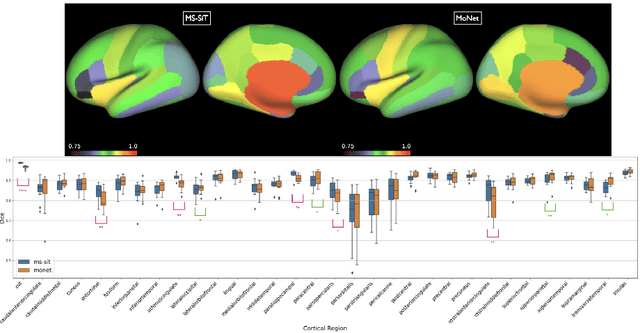
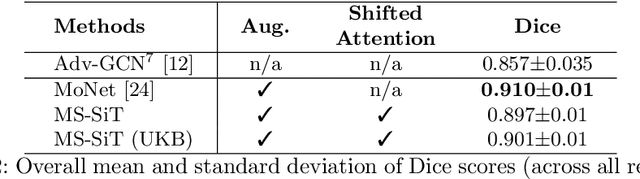
Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion
Mar 14, 2023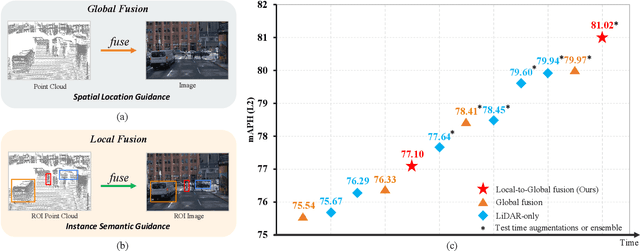
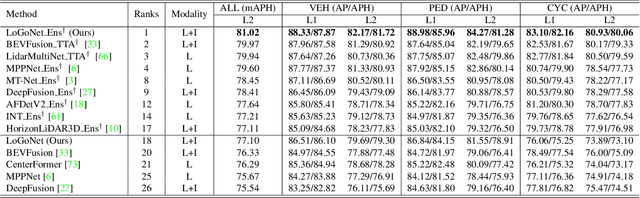
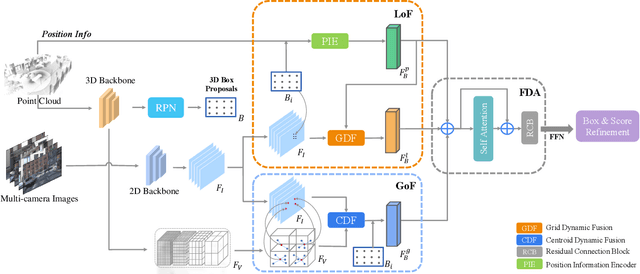
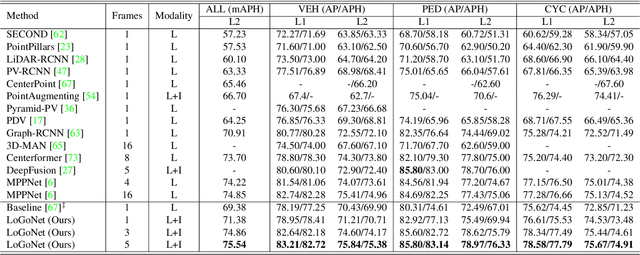
LiDAR-camera fusion methods have shown impressive performance in 3D object detection. Recent advanced multi-modal methods mainly perform global fusion, where image features and point cloud features are fused across the whole scene. Such practice lacks fine-grained region-level information, yielding suboptimal fusion performance. In this paper, we present the novel Local-to-Global fusion network (LoGoNet), which performs LiDAR-camera fusion at both local and global levels. Concretely, the Global Fusion (GoF) of LoGoNet is built upon previous literature, while we exclusively use point centroids to more precisely represent the position of voxel features, thus achieving better cross-modal alignment. As to the Local Fusion (LoF), we first divide each proposal into uniform grids and then project these grid centers to the images. The image features around the projected grid points are sampled to be fused with position-decorated point cloud features, maximally utilizing the rich contextual information around the proposals. The Feature Dynamic Aggregation (FDA) module is further proposed to achieve information interaction between these locally and globally fused features, thus producing more informative multi-modal features. Extensive experiments on both Waymo Open Dataset (WOD) and KITTI datasets show that LoGoNet outperforms all state-of-the-art 3D detection methods. Notably, LoGoNet ranks 1st on Waymo 3D object detection leaderboard and obtains 81.02 mAPH (L2) detection performance. It is noteworthy that, for the first time, the detection performance on three classes surpasses 80 APH (L2) simultaneously. Code will be available at \url{https://github.com/sankin97/LoGoNet}.
WebQAmGaze: A Multilingual Webcam Eye-Tracking-While-Reading Dataset
Mar 31, 2023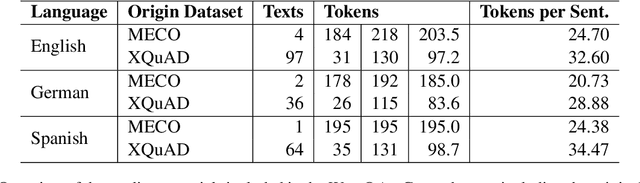
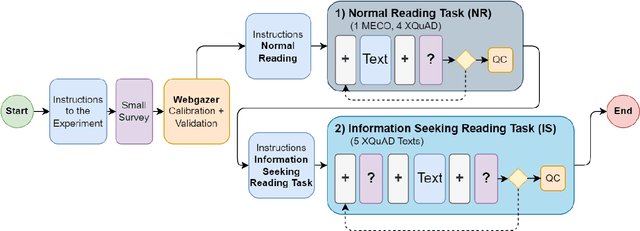
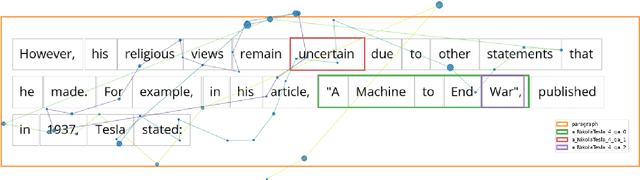
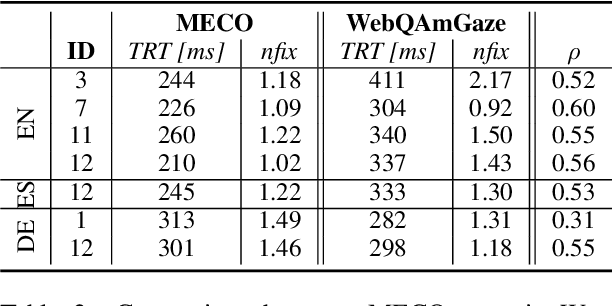
We create WebQAmGaze, a multilingual low-cost eye-tracking-while-reading dataset, designed to support the development of fair and transparent NLP models. WebQAmGaze includes webcam eye-tracking data from 332 participants naturally reading English, Spanish, and German texts. Each participant performs two reading tasks composed of five texts, a normal reading and an information-seeking task. After preprocessing the data, we find that fixations on relevant spans seem to indicate correctness when answering the comprehension questions. Additionally, we perform a comparative analysis of the data collected to high-quality eye-tracking data. The results show a moderate correlation between the features obtained with the webcam-ET compared to those of a commercial ET device. We believe this data can advance webcam-based reading studies and open a way to cheaper and more accessible data collection. WebQAmGaze is useful to learn about the cognitive processes behind question answering (QA) and to apply these insights to computational models of language understanding.
VDN-NeRF: Resolving Shape-Radiance Ambiguity via View-Dependence Normalization
Mar 31, 2023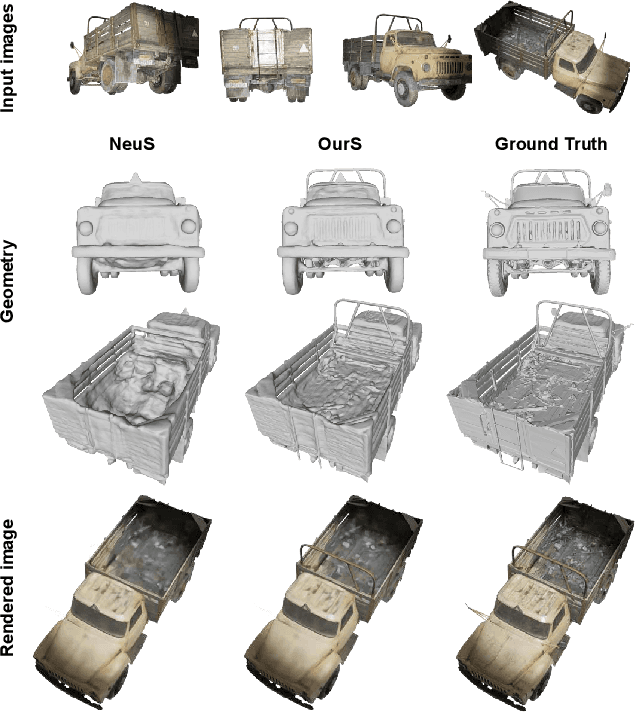

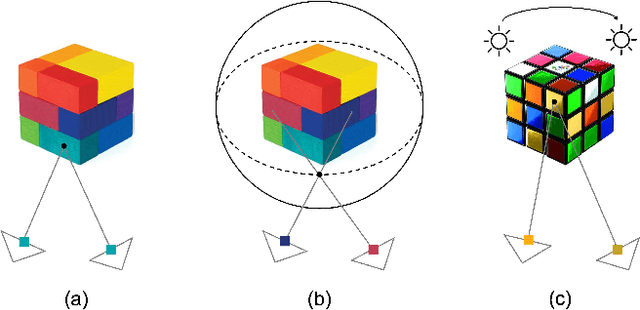
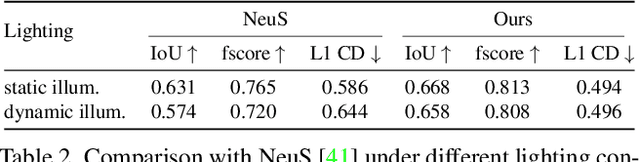
We propose VDN-NeRF, a method to train neural radiance fields (NeRFs) for better geometry under non-Lambertian surface and dynamic lighting conditions that cause significant variation in the radiance of a point when viewed from different angles. Instead of explicitly modeling the underlying factors that result in the view-dependent phenomenon, which could be complex yet not inclusive, we develop a simple and effective technique that normalizes the view-dependence by distilling invariant information already encoded in the learned NeRFs. We then jointly train NeRFs for view synthesis with view-dependence normalization to attain quality geometry. Our experiments show that even though shape-radiance ambiguity is inevitable, the proposed normalization can minimize its effect on geometry, which essentially aligns the optimal capacity needed for explaining view-dependent variations. Our method applies to various baselines and significantly improves geometry without changing the volume rendering pipeline, even if the data is captured under a moving light source. Code is available at: https://github.com/BoifZ/VDN-NeRF.
Identifying TBI Physiological States by Clustering of Multivariate Clinical Time-Series
Mar 30, 2023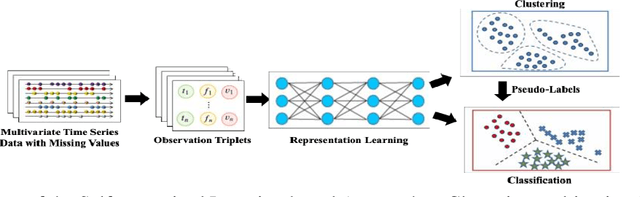
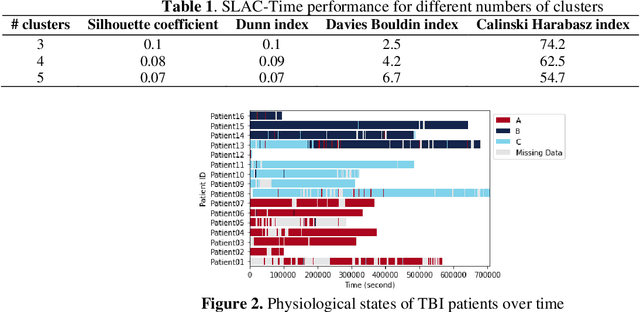


Determining clinically relevant physiological states from multivariate time series data with missing values is essential for providing appropriate treatment for acute conditions such as Traumatic Brain Injury (TBI), respiratory failure, and heart failure. Utilizing non-temporal clustering or data imputation and aggregation techniques may lead to loss of valuable information and biased analyses. In our study, we apply the SLAC-Time algorithm, an innovative self-supervision-based approach that maintains data integrity by avoiding imputation or aggregation, offering a more useful representation of acute patient states. By using SLAC-Time to cluster data in a large research dataset, we identified three distinct TBI physiological states and their specific feature profiles. We employed various clustering evaluation metrics and incorporated input from a clinical domain expert to validate and interpret the identified physiological states. Further, we discovered how specific clinical events and interventions can influence patient states and state transitions.
DRIP: Deep Regularizers for Inverse Problems
Mar 30, 2023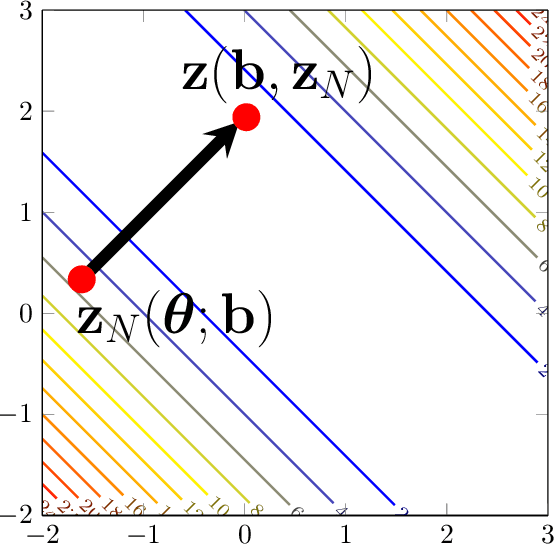
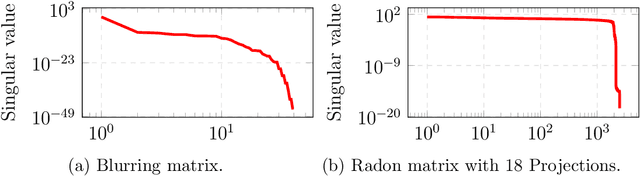

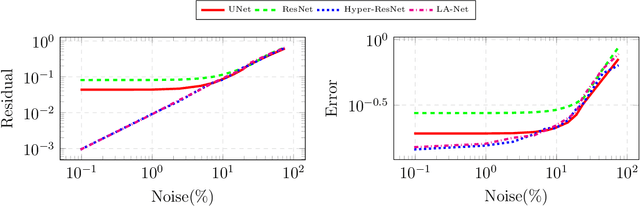
Inverse problems are mathematically ill-posed. Thus, given some (noisy) data, there is more than one solution that fits the data. In recent years, deep neural techniques that find the most appropriate solution, in the sense that it contains a-priori information, were developed. However, they suffer from several shortcomings. First, most techniques cannot guarantee that the solution fits the data at inference. Second, while the derivation of the techniques is inspired by the existence of a valid scalar regularization function, such techniques do not in practice rely on such a function, and therefore veer away from classical variational techniques. In this work we introduce a new family of neural regularizers for the solution of inverse problems. These regularizers are based on a variational formulation and are guaranteed to fit the data. We demonstrate their use on a number of highly ill-posed problems, from image deblurring to limited angle tomography.