 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Unsupervised Audio Representation Learning via Adversarial Sample Generation
Mar 15, 2023
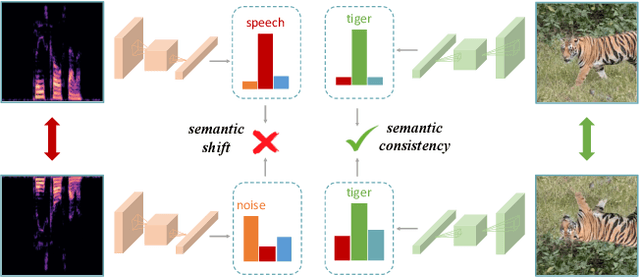
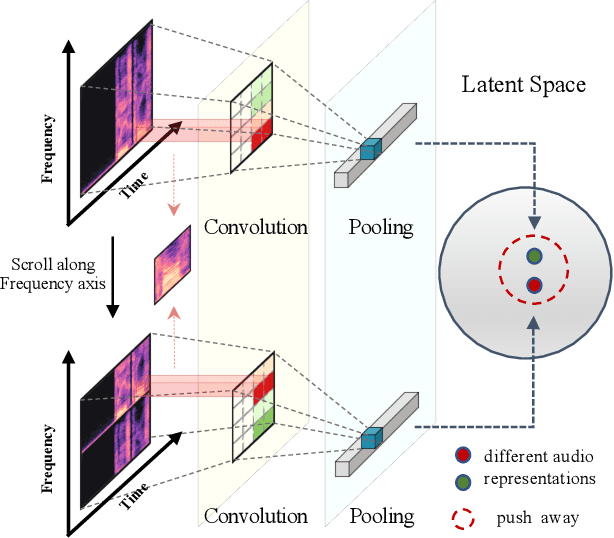
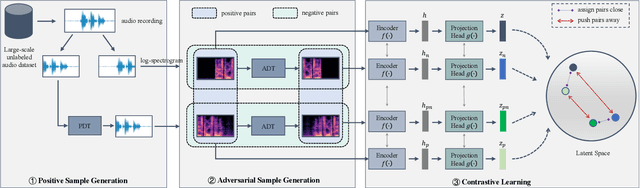
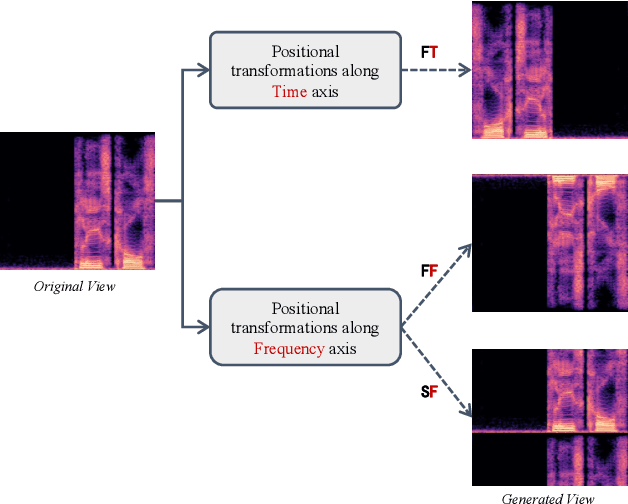
Existing audio analysis methods generally first transform the audio stream to spectrogram, and then feed it into CNN for further analysis. A standard CNN recognizes specific visual patterns over feature map, then pools for high-level representation, which overlooks the positional information of recognized patterns. However, unlike natural image, the semantic of an audio spectrogram is sensitive to positional change, as its vertical and horizontal axes indicate the frequency and temporal information of the audio, instead of naive rectangular coordinates. Thus, the insensitivity of CNN to positional change plays a negative role on audio spectrogram encoding. To address this issue, this paper proposes a new self-supervised learning mechanism, which enhances the audio representation by first generating adversarial samples (\textit{i.e.}, negative samples), then driving CNN to distinguish the embeddings of negative pairs in the latent space. Extensive experiments show that the proposed approach achieves best or competitive results on 9 downstream datasets compared with previous methods, which verifies its effectiveness on audio representation learning.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 15, 2023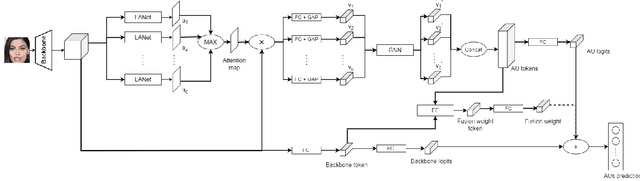

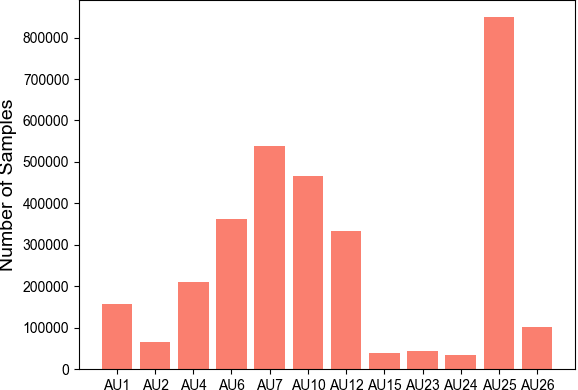
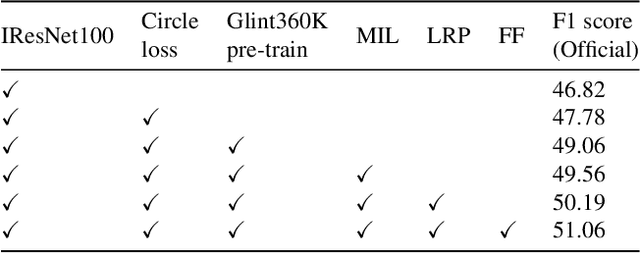
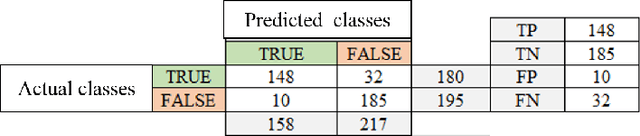
Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.
Building an Effective Email Spam Classification Model with spaCy
Mar 15, 2023

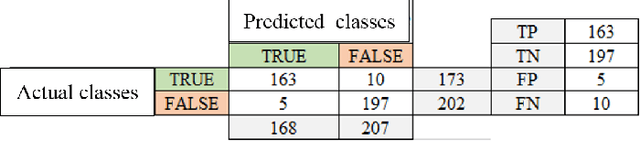
Today, people use email services such as Gmail, Outlook, AOL Mail, etc. to communicate with each other as quickly as possible to send information and official letters. Spam or junk mail is a major challenge to this type of communication, usually sent by botnets with the aim of advertising, harming and stealing information in bulk to different people. Receiving unwanted spam emails on a daily basis fills up the inbox folder. Therefore, spam detection is a fundamental challenge, so far many works have been done to detect spam using clustering and text categorisation methods. In this article, the author has used the spaCy natural language processing library and 3 machine learning (ML) algorithms Naive Bayes (NB), Decision Tree C45 and Multilayer Perceptron (MLP) in the Python programming language to detect spam emails collected from the Gmail service. Observations show the accuracy rate (96%) of the Multilayer Perceptron (MLP) algorithm in spam detection.
Trigger-Level Event Reconstruction for Neutrino Telescopes Using Sparse Submanifold Convolutional Neural Networks
Mar 15, 2023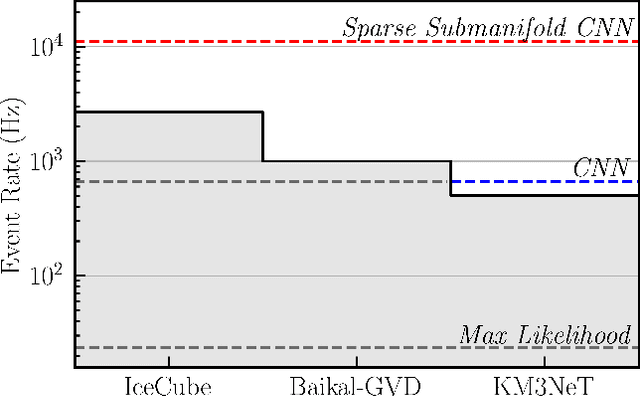
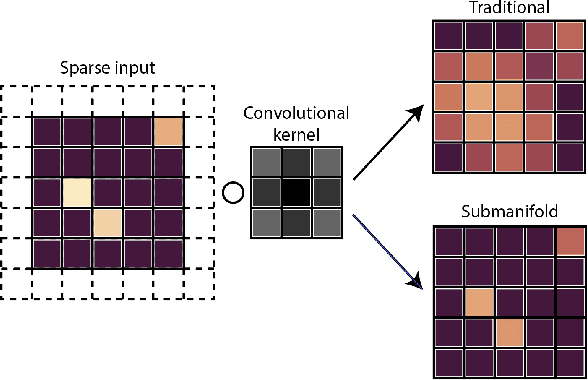
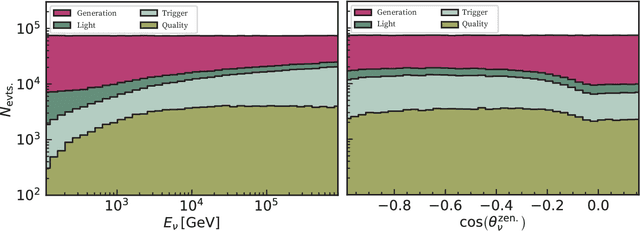

Convolutional neural networks (CNNs) have seen extensive applications in scientific data analysis, including in neutrino telescopes. However, the data from these experiments present numerous challenges to CNNs, such as non-regular geometry, sparsity, and high dimensionality. Consequently, CNNs are highly inefficient on neutrino telescope data, and require significant pre-processing that results in information loss. We propose sparse submanifold convolutions (SSCNNs) as a solution to these issues and show that the SSCNN event reconstruction performance is comparable to or better than traditional and machine learning algorithms. Additionally, our SSCNN runs approximately 16 times faster than a traditional CNN on a GPU. As a result of this speedup, it is expected to be capable of handling the trigger-level event rate of IceCube-scale neutrino telescopes. These networks could be used to improve the first estimation of the neutrino energy and direction to seed more advanced reconstructions, or to provide this information to an alert-sending system to quickly follow-up interesting events.
Autonomous Soundscape Augmentation with Multimodal Fusion of Visual and Participant-linked Inputs
Mar 15, 2023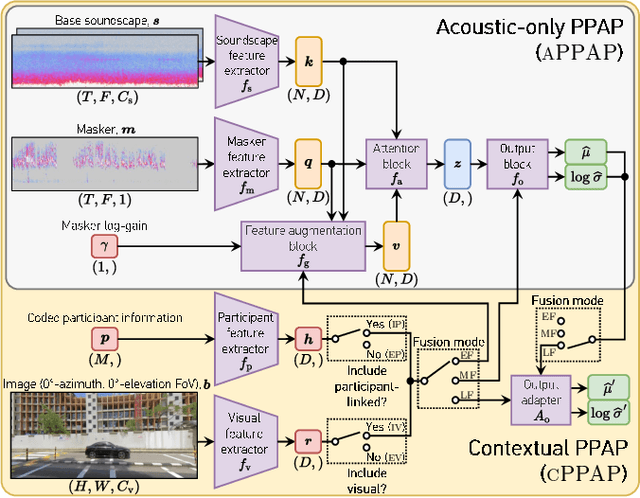
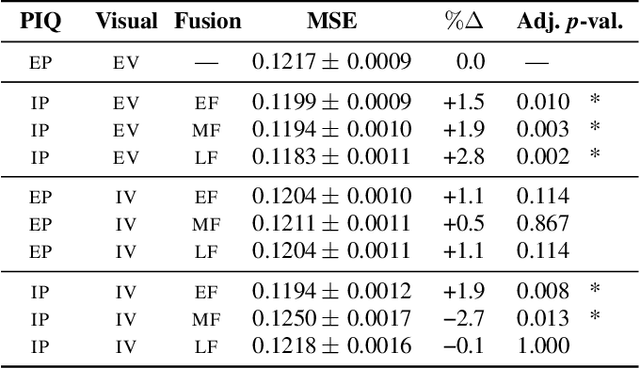
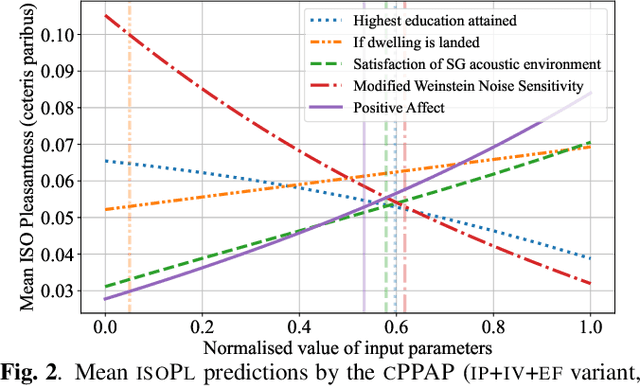
Autonomous soundscape augmentation systems typically use trained models to pick optimal maskers to effect a desired perceptual change. While acoustic information is paramount to such systems, contextual information, including participant demographics and the visual environment, also influences acoustic perception. Hence, we propose modular modifications to an existing attention-based deep neural network, to allow early, mid-level, and late feature fusion of participant-linked, visual, and acoustic features. Ablation studies on module configurations and corresponding fusion methods using the ARAUS dataset show that contextual features improve the model performance in a statistically significant manner on the normalized ISO Pleasantness, to a mean squared error of $0.1194\pm0.0012$ for the best-performing all-modality model, against $0.1217\pm0.0009$ for the audio-only model. Soundscape augmentation systems can thereby leverage multimodal inputs for improved performance. We also investigate the impact of individual participant-linked factors using trained models to illustrate improvements in model explainability.
Data-driven multiscale modeling of subgrid parameterizations in climate models
Mar 24, 2023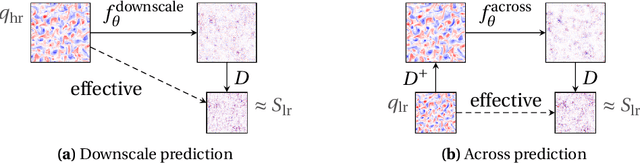
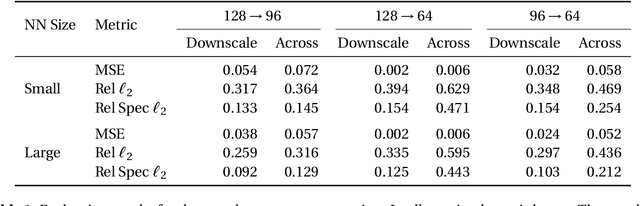
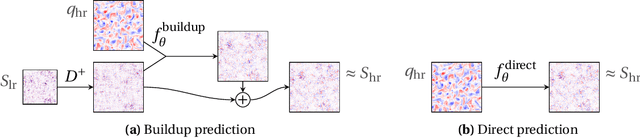
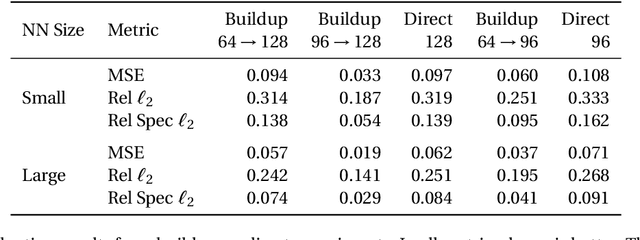
Subgrid parameterizations, which represent physical processes occurring below the resolution of current climate models, are an important component in producing accurate, long-term predictions for the climate. A variety of approaches have been tested to design these components, including deep learning methods. In this work, we evaluate a proof of concept illustrating a multiscale approach to this prediction problem. We train neural networks to predict subgrid forcing values on a testbed model and examine improvements in prediction accuracy that can be obtained by using additional information in both fine-to-coarse and coarse-to-fine directions.
Open-World Object Manipulation using Pre-trained Vision-Language Models
Mar 02, 2023
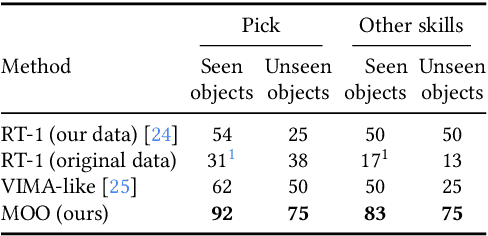
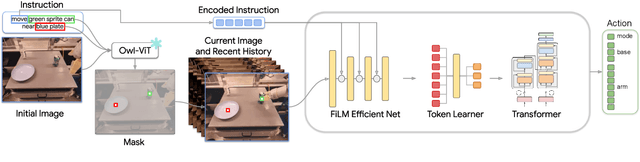
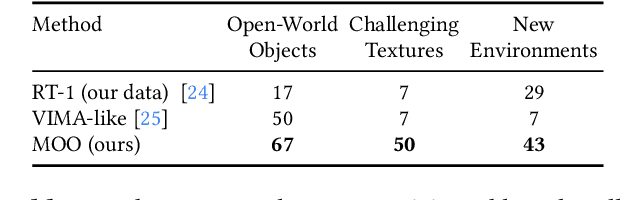
For robots to follow instructions from people, they must be able to connect the rich semantic information in human vocabulary, e.g. "can you get me the pink stuffed whale?" to their sensory observations and actions. This brings up a notably difficult challenge for robots: while robot learning approaches allow robots to learn many different behaviors from first-hand experience, it is impractical for robots to have first-hand experiences that span all of this semantic information. We would like a robot's policy to be able to perceive and pick up the pink stuffed whale, even if it has never seen any data interacting with a stuffed whale before. Fortunately, static data on the internet has vast semantic information, and this information is captured in pre-trained vision-language models. In this paper, we study whether we can interface robot policies with these pre-trained models, with the aim of allowing robots to complete instructions involving object categories that the robot has never seen first-hand. We develop a simple approach, which we call Manipulation of Open-World Objects (MOO), which leverages a pre-trained vision-language model to extract object-identifying information from the language command and image, and conditions the robot policy on the current image, the instruction, and the extracted object information. In a variety of experiments on a real mobile manipulator, we find that MOO generalizes zero-shot to a wide range of novel object categories and environments. In addition, we show how MOO generalizes to other, non-language-based input modalities to specify the object of interest such as finger pointing, and how it can be further extended to enable open-world navigation and manipulation. The project's website and evaluation videos can be found at https://robot-moo.github.io/
Low-complexity Deep Video Compression with A Distributed Coding Architecture
Apr 02, 2023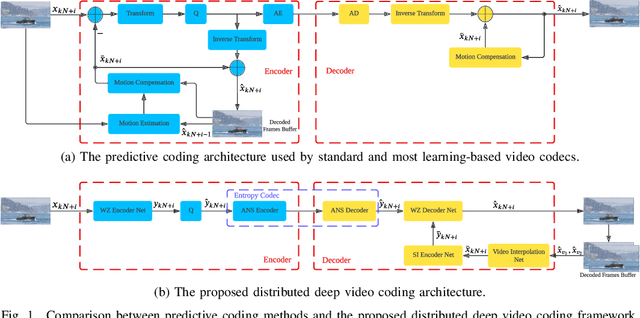
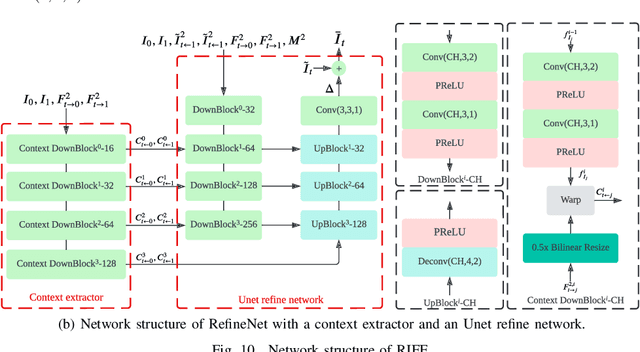
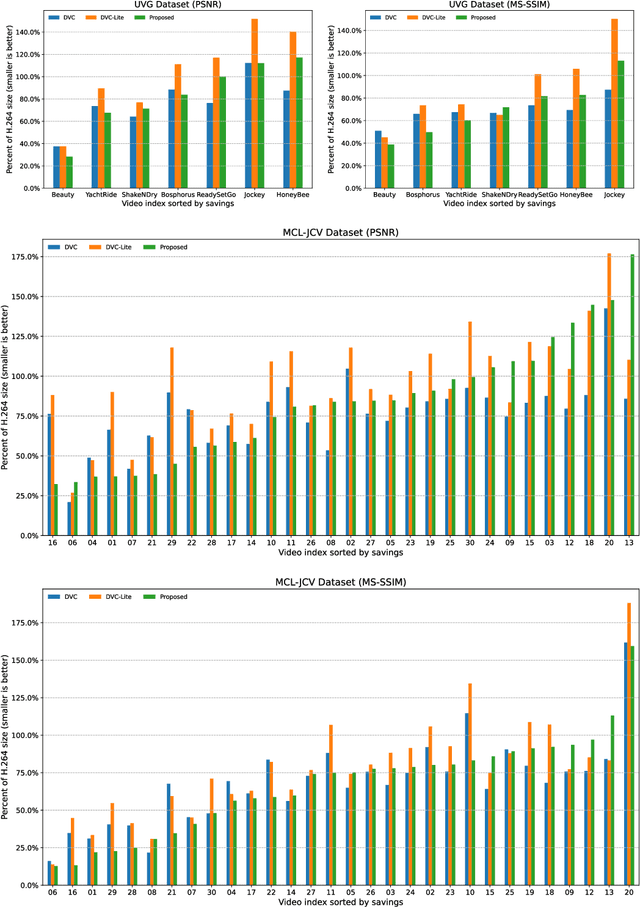

Prevalent predictive coding-based video compression methods rely on a heavy encoder to reduce temporal redundancy, which makes it challenging to deploy them on resource-constrained devices. Since the 1970s, distributed source coding theory has indicated that independent encoding and joint decoding with side information (SI) can achieve high-efficient compression of correlated sources. This has inspired a distributed coding architecture aiming at reducing the encoding complexity. However, traditional distributed coding methods suffer from a substantial performance gap to predictive coding ones. Inspired by the great success of learning-based compression, we propose the first end-to-end distributed deep video compression framework to improve the rate-distortion performance. A key ingredient is an effective SI generation module at the decoder, which helps to effectively exploit inter-frame correlations without computation-intensive encoder-side motion estimation and compensation. Experiments show that our method significantly outperforms conventional distributed video coding and H.264. Meanwhile, it enjoys 6-7x encoding speedup against DVC [1] with comparable compression performance. Code is released at https://github.com/Xinjie-Q/Distributed-DVC.
CNNs with Multi-Level Attention for Domain Generalization
Apr 02, 2023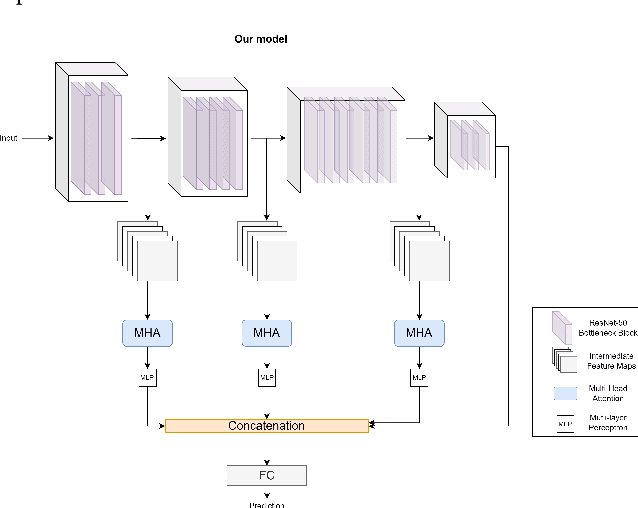
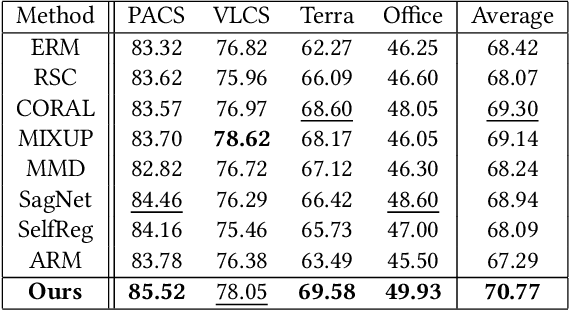
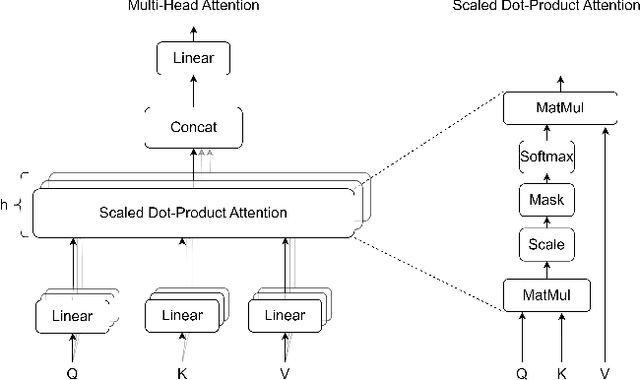
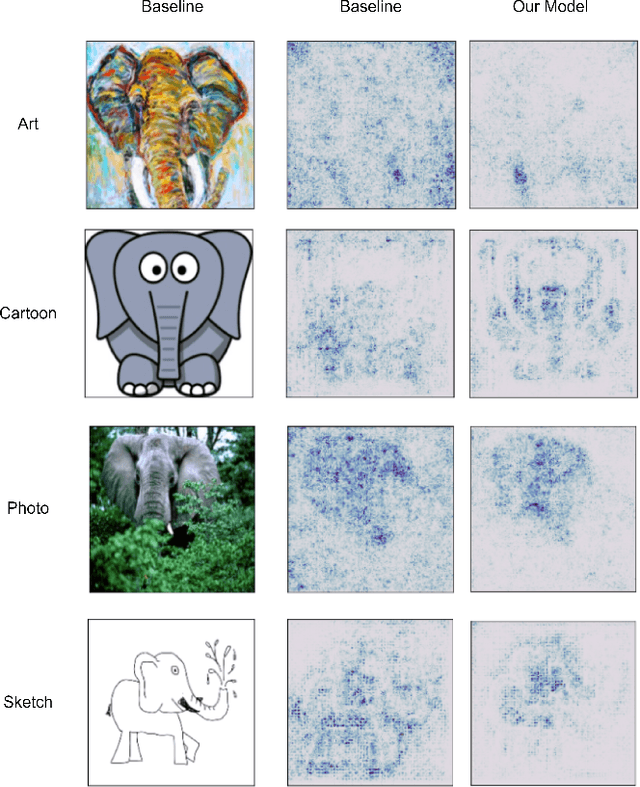
In the past decade, deep convolutional neural networks have achieved significant success in image classification and ranking and have therefore found numerous applications in multimedia content retrieval. Still, these models suffer from performance degradation when neural networks are tested on out-of-distribution scenarios or on data originating from previously unseen data Domains. In the present work, we focus on this problem of Domain Generalization and propose an alternative neural network architecture for robust, out-of-distribution image classification. We attempt to produce a model that focuses on the causal features of the depicted class for robust image classification in the Domain Generalization setting. To achieve this, we propose attending to multiple-levels of information throughout a Convolutional Neural Network and leveraging the most important attributes of an image by employing trainable attention mechanisms. To validate our method, we evaluate our model on four widely accepted Domain Generalization benchmarks, on which our model is able to surpass previously reported baselines in three out of four datasets and achieve the second best score in the fourth one.
One Training for Multiple Deployments: Polar-based Adaptive BEV Perception for Autonomous Driving
Apr 02, 2023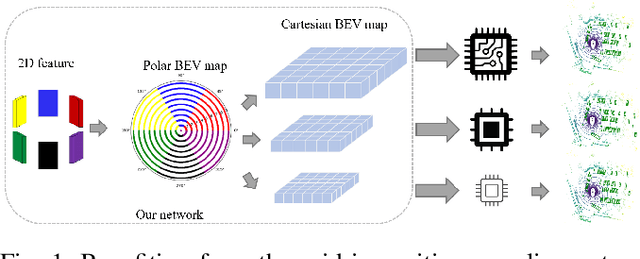
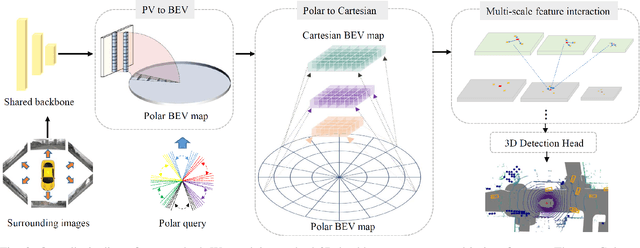
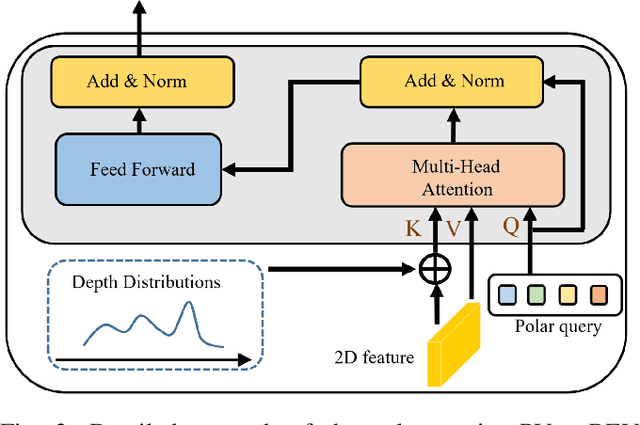
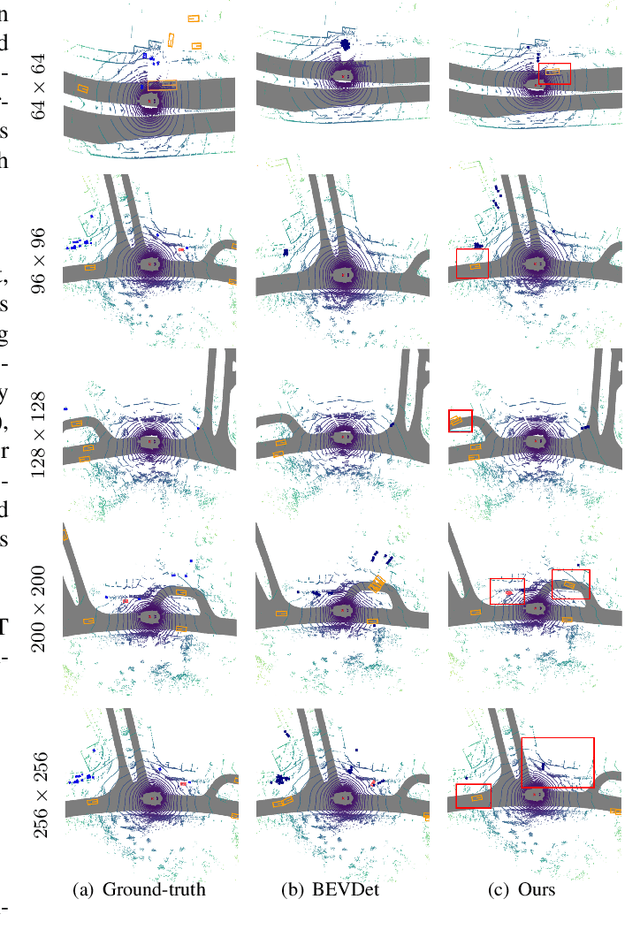
Current on-board chips usually have different computing power, which means multiple training processes are needed for adapting the same learning-based algorithm to different chips, costing huge computing resources. The situation becomes even worse for 3D perception methods with large models. Previous vision-centric 3D perception approaches are trained with regular grid-represented feature maps of fixed resolutions, which is not applicable to adapt to other grid scales, limiting wider deployment. In this paper, we leverage the Polar representation when constructing the BEV feature map from images in order to achieve the goal of training once for multiple deployments. Specifically, the feature along rays in Polar space can be easily adaptively sampled and projected to the feature in Cartesian space with arbitrary resolutions. To further improve the adaptation capability, we make multi-scale contextual information interact with each other to enhance the feature representation. Experiments on a large-scale autonomous driving dataset show that our method outperforms others as for the good property of one training for multiple deployments.