 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Context Interaction Network for Few-Shot Segmentation
Mar 11, 2023
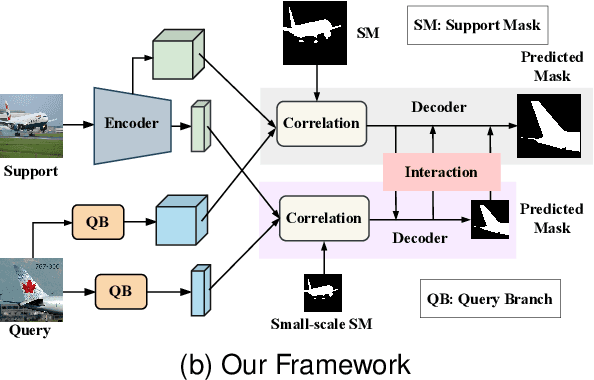
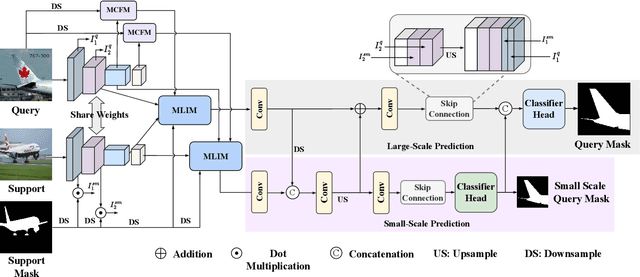
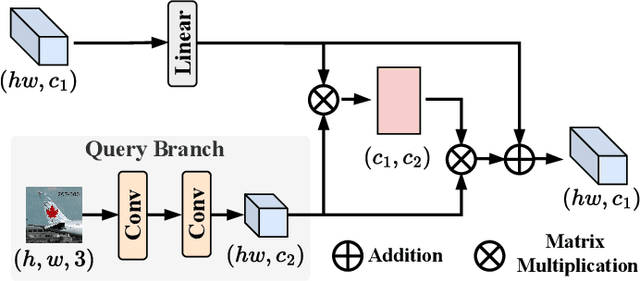
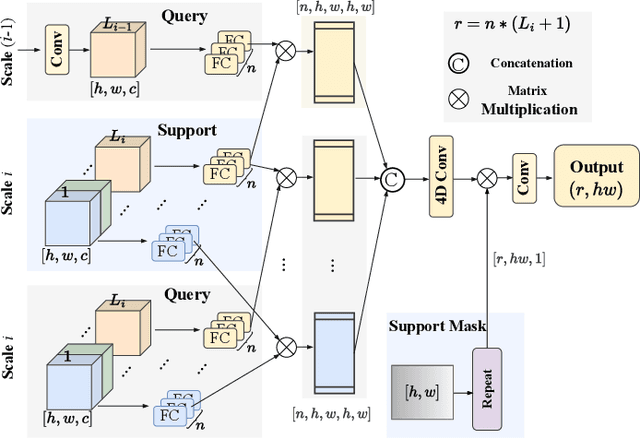
Few-Shot Segmentation (FSS) is challenging for limited support images and large intra-class appearance discrepancies. Due to the huge difference between support and query samples, most existing approaches focus on extracting high-level representations of the same layers for support-query correlations but neglect the shift issue between different layers and scales. In this paper, we propose a Multi-Context Interaction Network (MCINet) to remedy this issue by fully exploiting and interacting with the multi-scale contextual information contained in the support-query pairs. Specifically, MCINet improves FSS from the perspectives of boosting the query representations by incorporating the low-level structural information from another query branch into the high-level semantic features, enhancing the support-query correlations by exploiting both the same-layer and adjacent-layer features, and refining the predicted results by a multi-scale mask prediction strategy, with which the different scale contents have bidirectionally interacted. Experiments on two benchmarks demonstrate that our approach reaches SOTA performances and outperforms the best competitors with many desirable advantages, especially on the challenging COCO dataset.
MetaViewer: Towards A Unified Multi-View Representation
Mar 11, 2023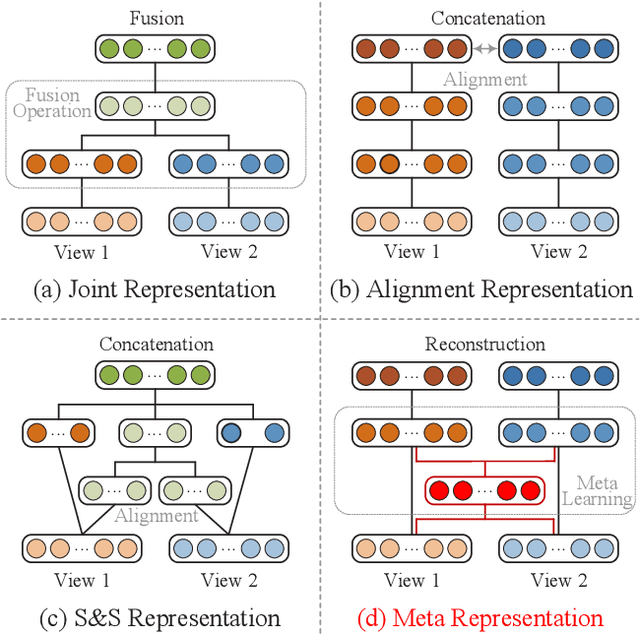
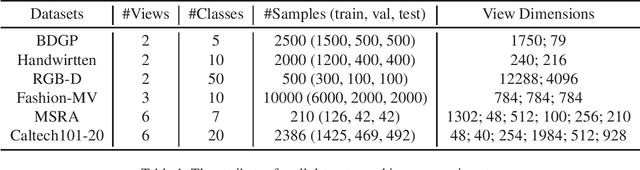
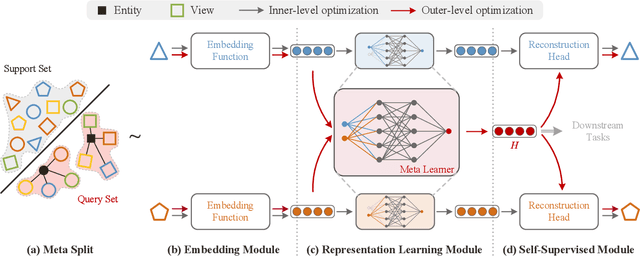
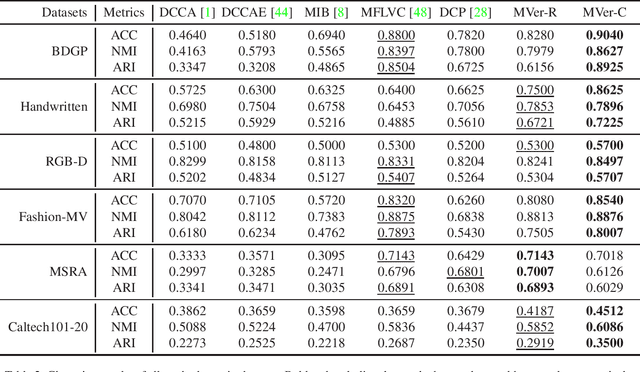
Existing multi-view representation learning methods typically follow a specific-to-uniform pipeline, extracting latent features from each view and then fusing or aligning them to obtain the unified object representation. However, the manually pre-specify fusion functions and view-private redundant information mixed in features potentially degrade the quality of the derived representation. To overcome them, we propose a novel bi-level-optimization-based multi-view learning framework, where the representation is learned in a uniform-to-specific manner. Specifically, we train a meta-learner, namely MetaViewer, to learn fusion and model the view-shared meta representation in outer-level optimization. Start with this meta representation, view-specific base-learners are then required to rapidly reconstruct the corresponding view in inner-level. MetaViewer eventually updates by observing reconstruction processes from uniform to specific over all views, and learns an optimal fusion scheme that separates and filters out view-private information. Extensive experimental results in downstream tasks such as classification and clustering demonstrate the effectiveness of our method.
Leveraging Memory Effects and Gradient Information in Consensus-Based Optimization: On Global Convergence in Mean-Field Law
Nov 22, 2022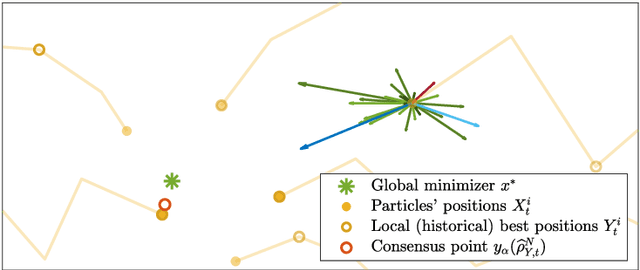
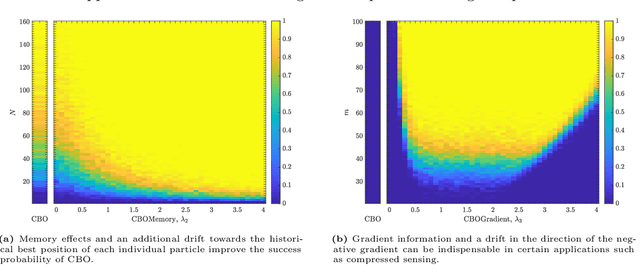
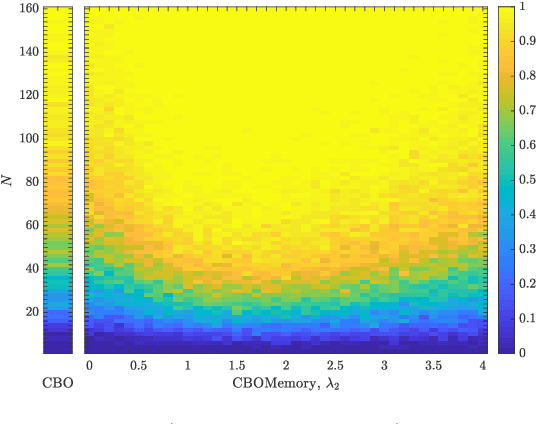

In this paper we study consensus-based optimization (CBO), a versatile, flexibel and customizable optimization method suitable for performing nonconvex and nonsmooth global optimizations in high dimensions. CBO is a multi-particle metaheuristic, which is effective in various applications and at the same time amenable to theoretical analysis thanks to its minimalistic design. The underlying dynamics, however, is flexible enough to incorporate different mechanisms widely used in evolutionary computation and machine learning, as we show by analyzing a variant of CBO which makes use of memory effects and gradient information. We rigorously prove that this dynamics converges to a global minimizer of the objective function in mean-field law for a vast class of functions under minimal assumptions on the initialization of the method. The proof in particular reveals how to leverage further, in some applications advantageous, forces in the dynamics without loosing provable global convergence. To demonstrate the benefit of the herein investigated memory effects and gradient information in certain applications, we present numerical evidence for the superiority of this CBO variant in applications such as machine learning and compressed sensing, which en passant widen the scope of applications of CBO.
Ontology-aware Network for Zero-shot Sketch-based Image Retrieval
Feb 20, 2023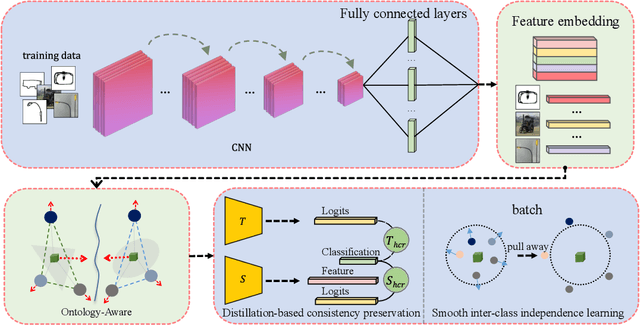
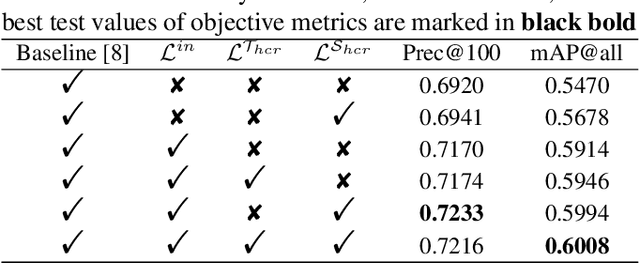
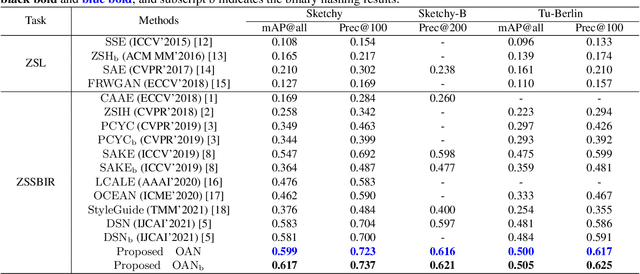
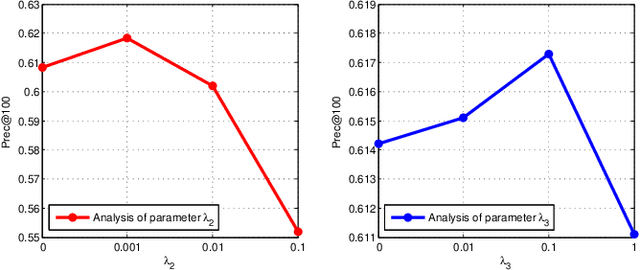
Zero-Shot Sketch-Based Image Retrieval (ZSSBIR) is an emerging task. The pioneering work focused on the modal gap but ignored inter-class information. Although recent work has begun to consider the triplet-based or contrast-based loss to mine inter-class information, positive and negative samples need to be carefully selected, or the model is prone to lose modality-specific information. To respond to these issues, an Ontology-Aware Network (OAN) is proposed. Specifically, the smooth inter-class independence learning mechanism is put forward to maintain inter-class peculiarity. Meanwhile, distillation-based consistency preservation is utilized to keep modality-specific information. Extensive experiments have demonstrated the superior performance of our algorithm on two challenging Sketchy and Tu-Berlin datasets.
Pedestrain detection for low-light vision proposal
Mar 17, 2023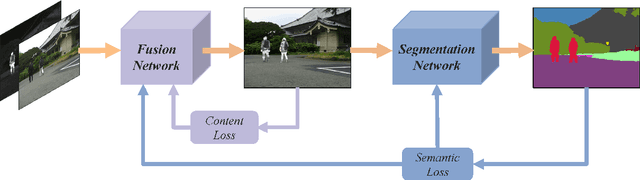
The demand for pedestrian detection has created a challenging problem for various visual tasks such as image fusion. As infrared images can capture thermal radiation information, image fusion between infrared and visible images could significantly improve target detection under environmental limitations. In our project, we would approach by preprocessing our dataset with image fusion technique, then using Vision Transformer model to detect pedestrians from the fused images. During the evaluation procedure, a comparison would be made between YOLOv5 and the revised ViT model performance on our fused images
Faster Learning of Temporal Action Proposal via Sparse Multilevel Boundary Generator
Mar 06, 2023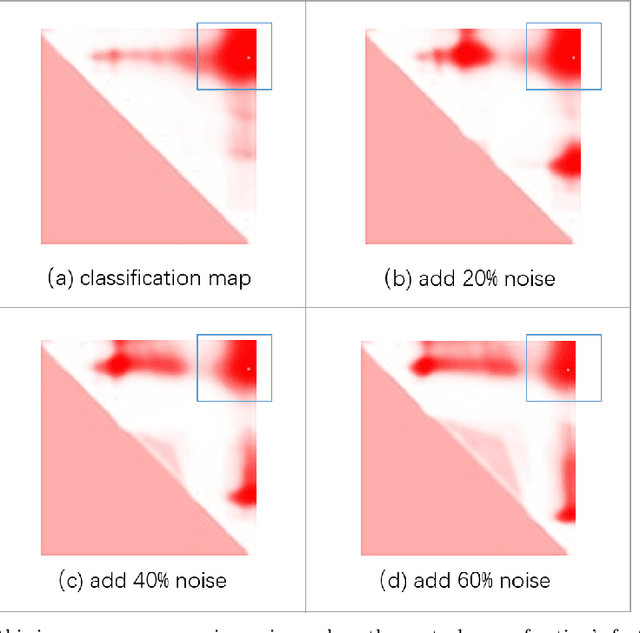
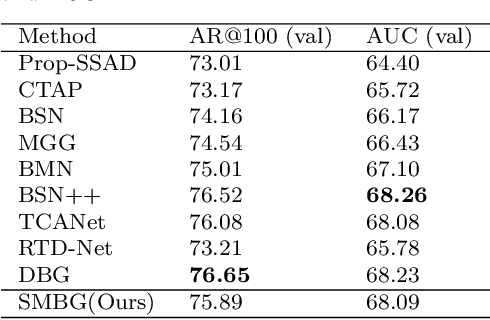
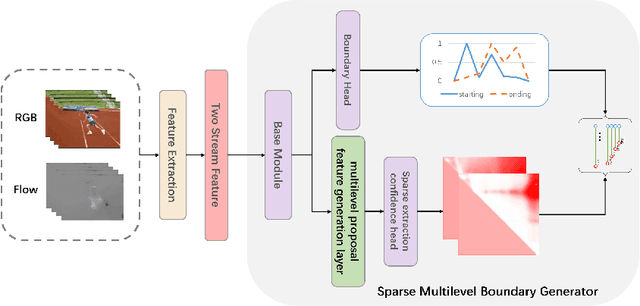
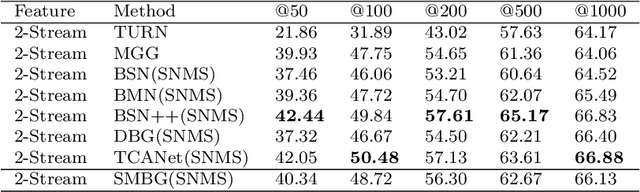
Temporal action localization in videos presents significant challenges in the field of computer vision. While the boundary-sensitive method has been widely adopted, its limitations include incomplete use of intermediate and global information, as well as an inefficient proposal feature generator. To address these challenges, we propose a novel framework, Sparse Multilevel Boundary Generator (SMBG), which enhances the boundary-sensitive method with boundary classification and action completeness regression. SMBG features a multi-level boundary module that enables faster processing by gathering boundary information at different lengths. Additionally, we introduce a sparse extraction confidence head that distinguishes information inside and outside the action, further optimizing the proposal feature generator. To improve the synergy between multiple branches and balance positive and negative samples, we propose a global guidance loss. Our method is evaluated on two popular benchmarks, ActivityNet-1.3 and THUMOS14, and is shown to achieve state-of-the-art performance, with a better inference speed (2.47xBSN++, 2.12xDBG). These results demonstrate that SMBG provides a more efficient and simple solution for generating temporal action proposals. Our proposed framework has the potential to advance the field of computer vision and enhance the accuracy and speed of temporal action localization in video analysis.The code and models are made available at \url{https://github.com/zhouyang-001/SMBG-for-temporal-action-proposal}.
PrefGen: Preference Guided Image Generation with Relative Attributes
Apr 01, 2023

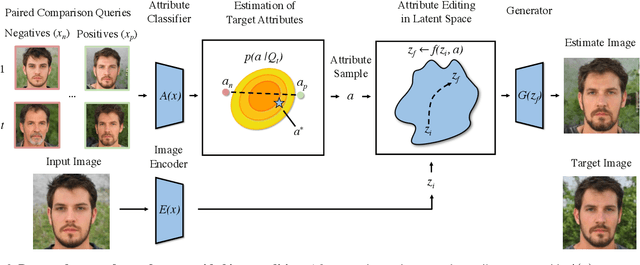
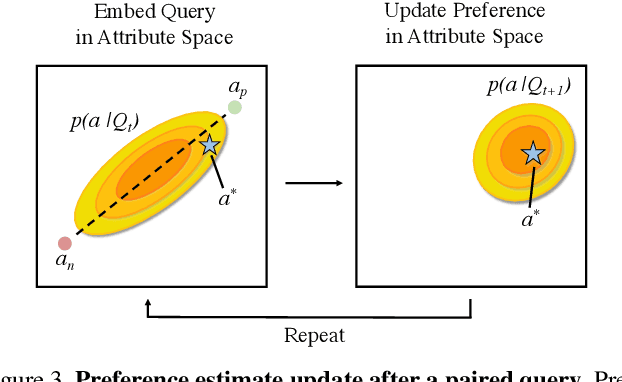
Deep generative models have the capacity to render high fidelity images of content like human faces. Recently, there has been substantial progress in conditionally generating images with specific quantitative attributes, like the emotion conveyed by one's face. These methods typically require a user to explicitly quantify the desired intensity of a visual attribute. A limitation of this method is that many attributes, like how "angry" a human face looks, are difficult for a user to precisely quantify. However, a user would be able to reliably say which of two faces seems "angrier". Following this premise, we develop the $\textit{PrefGen}$ system, which allows users to control the relative attributes of generated images by presenting them with simple paired comparison queries of the form "do you prefer image $a$ or image $b$?" Using information from a sequence of query responses, we can estimate user preferences over a set of image attributes and perform preference-guided image editing and generation. Furthermore, to make preference localization feasible and efficient, we apply an active query selection strategy. We demonstrate the success of this approach using a StyleGAN2 generator on the task of human face editing. Additionally, we demonstrate how our approach can be combined with CLIP, allowing a user to edit the relative intensity of attributes specified by text prompts. Code at https://github.com/helblazer811/PrefGen.
Diffusion Models for Contrast Harmonization of Magnetic Resonance Images
Mar 14, 2023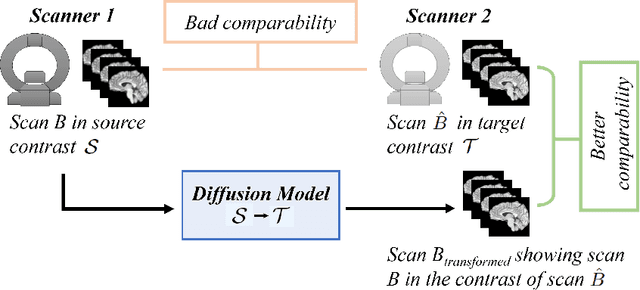
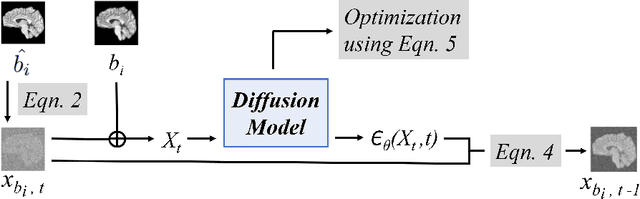
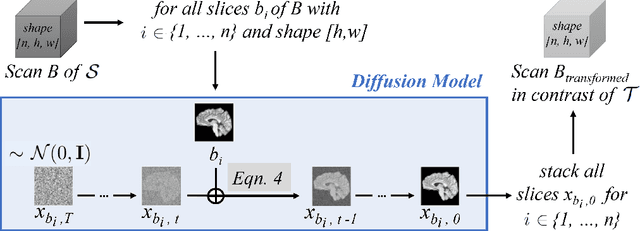

Magnetic resonance (MR) images from multiple sources often show differences in image contrast related to acquisition settings or the used scanner type. For long-term studies, longitudinal comparability is essential but can be impaired by these contrast differences, leading to biased results when using automated evaluation tools. This study presents a diffusion model-based approach for contrast harmonization. We use a data set consisting of scans of 18 Multiple Sclerosis patients and 22 healthy controls. Each subject was scanned in two MR scanners of different magnetic field strengths (1.5 T and 3 T), resulting in a paired data set that shows scanner-inherent differences. We map images from the source contrast to the target contrast for both directions, from 3 T to 1.5 T and from 1.5 T to 3 T. As we only want to change the contrast, not the anatomical information, our method uses the original image to guide the image-to-image translation process by adding structural information. The aim is that the mapped scans display increased comparability with scans of the target contrast for downstream tasks. We evaluate this method for the task of segmentation of cerebrospinal fluid, grey matter and white matter. Our method achieves good and consistent results for both directions of the mapping.
Graph Construction using Principal Axis Trees for Simple Graph Convolution
Mar 01, 2023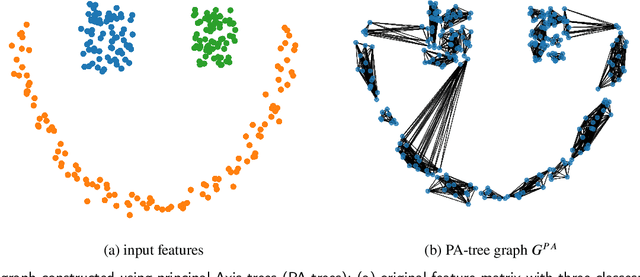


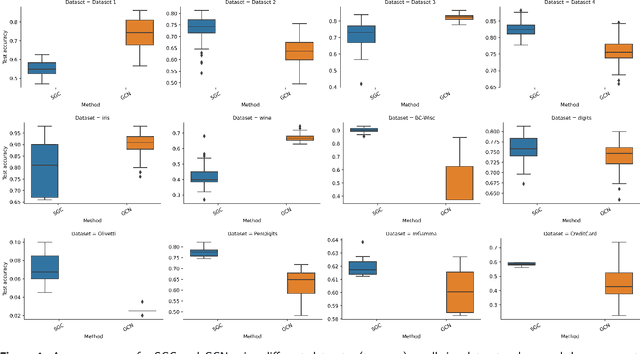
Graph Neural Networks (GNNs) are increasingly becoming the favorite method for graph learning. They exploit the semi-supervised nature of deep learning, and they bypass computational bottlenecks associated with traditional graph learning methods. In addition to the feature matrix $X$, GNNs need an adjacency matrix $A$ to perform feature propagation. In many cases the adjacency matrix $A$ is missing. We introduce a graph construction scheme that construct the adjacency matrix $A$ using unsupervised and supervised information. Unsupervised information characterize the neighborhood around points. We used Principal Axis trees (PA-trees) as a source of unsupervised information, where we create edges between points falling onto the same leaf node. For supervised information, we used the concept of penalty and intrinsic graphs. A penalty graph connects points with different class labels, whereas intrinsic graph connects points with the same class label. We used the penalty and intrinsic graphs to remove or add edges to the graph constructed via PA-tree. This graph construction scheme was tested on two well-known GNNs: 1) Graph Convolutional Network (GCN) and 2) Simple Graph Convolution (SGC). The experiments show that it is better to use SGC because it is faster and delivers better or the same results as GCN. We also test the effect of oversmoothing on both GCN and SGC. We found out that the level of smoothing has to be selected carefully for SGC to avoid oversmoothing.
AMIGO: Sparse Multi-Modal Graph Transformer with Shared-Context Processing for Representation Learning of Giga-pixel Images
Mar 01, 2023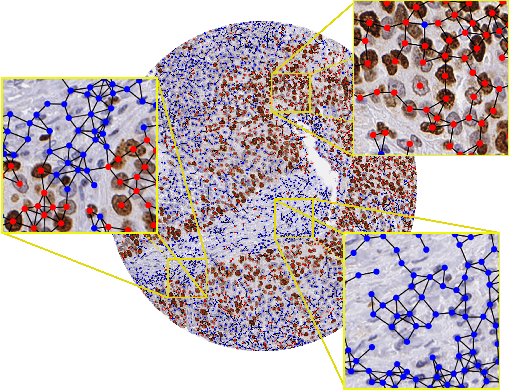
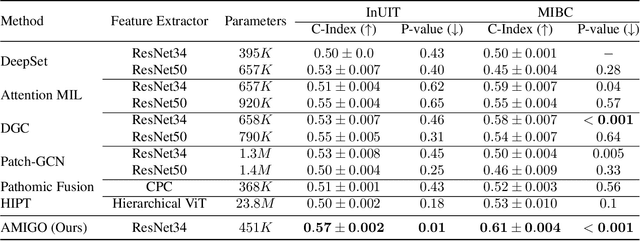
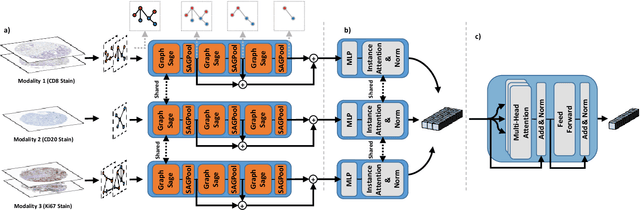
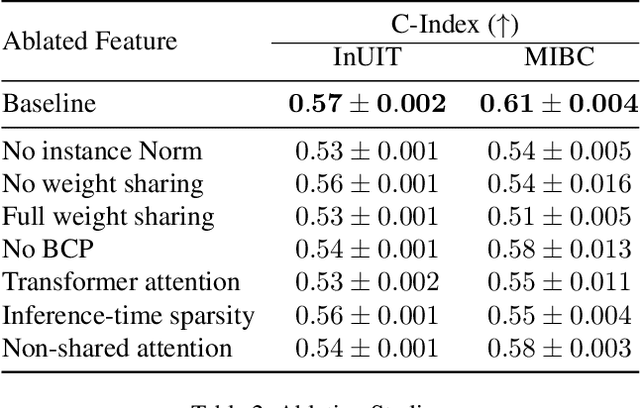
Processing giga-pixel whole slide histopathology images (WSI) is a computationally expensive task. Multiple instance learning (MIL) has become the conventional approach to process WSIs, in which these images are split into smaller patches for further processing. However, MIL-based techniques ignore explicit information about the individual cells within a patch. In this paper, by defining the novel concept of shared-context processing, we designed a multi-modal Graph Transformer (AMIGO) that uses the celluar graph within the tissue to provide a single representation for a patient while taking advantage of the hierarchical structure of the tissue, enabling a dynamic focus between cell-level and tissue-level information. We benchmarked the performance of our model against multiple state-of-the-art methods in survival prediction and showed that ours can significantly outperform all of them including hierarchical Vision Transformer (ViT). More importantly, we show that our model is strongly robust to missing information to an extent that it can achieve the same performance with as low as 20% of the data. Finally, in two different cancer datasets, we demonstrated that our model was able to stratify the patients into low-risk and high-risk groups while other state-of-the-art methods failed to achieve this goal. We also publish a large dataset of immunohistochemistry images (InUIT) containing 1,600 tissue microarray (TMA) cores from 188 patients along with their survival information, making it one of the largest publicly available datasets in this context.