 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
InsCL: A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions
Mar 18, 2024
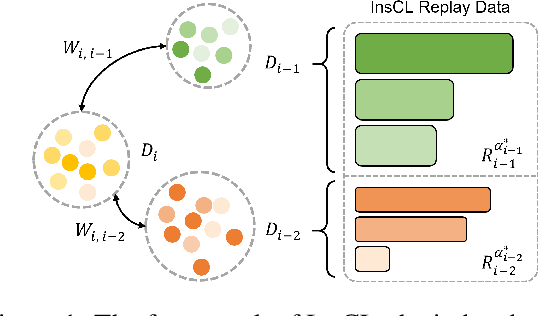

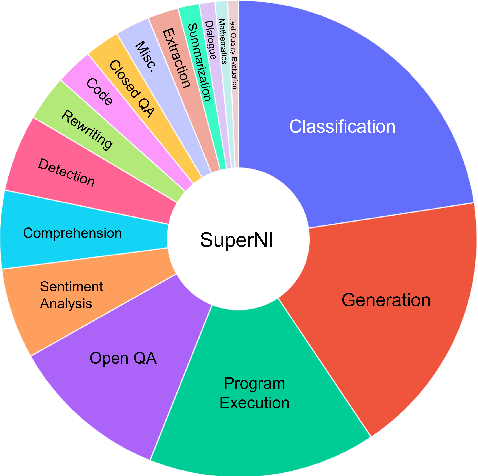
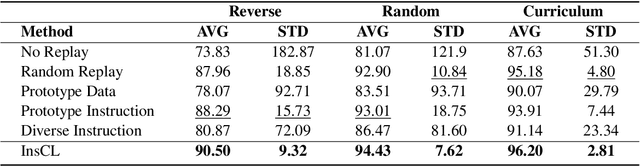
Instruction tuning effectively optimizes Large Language Models (LLMs) for downstream tasks. Due to the changing environment in real-life applications, LLMs necessitate continual task-specific adaptation without catastrophic forgetting. Considering the heavy computational cost, replay-based Continual Learning (CL) methods are the simplest and most widely used for LLMs to address the forgetting issue. However, traditional replay-based methods do not fully utilize instructions to customize the replay strategy. In this work, we propose a novel paradigm called Instruction-based Continual Learning (InsCL). InsCL dynamically replays previous data based on task similarity, calculated by Wasserstein Distance with instructions. Moreover, we further introduce an Instruction Information Metric (InsInfo) to quantify the complexity and diversity of instructions. According to InsInfo, InsCL guides the replay process more inclined to high-quality data. We conduct extensive experiments over 16 tasks with different training orders, observing consistent performance improvements of InsCL. When all tasks have been trained, InsCL achieves performance gains of 3.0 Relative Gain compared with Random Replay, and 27.96 Relative Gain compared with No Replay.
EchoReel: Enhancing Action Generation of Existing Video Diffusion Models
Mar 18, 2024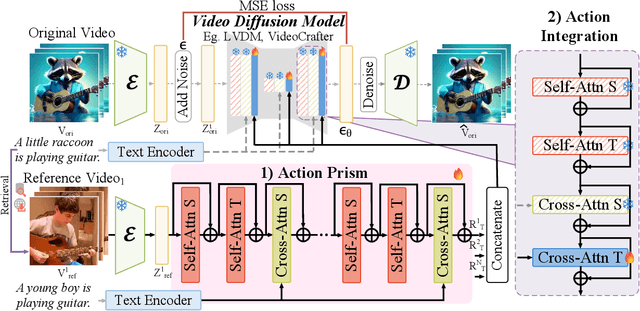
Recent large-scale video datasets have facilitated the generation of diverse open-domain videos of Video Diffusion Models (VDMs). Nonetheless, the efficacy of VDMs in assimilating complex knowledge from these datasets remains constrained by their inherent scale, leading to suboptimal comprehension and synthesis of numerous actions. In this paper, we introduce EchoReel, a novel approach to augment the capability of VDMs in generating intricate actions by emulating motions from pre-existing videos, which are readily accessible from databases or online repositories. EchoReel seamlessly integrates with existing VDMs, enhancing their ability to produce realistic motions without compromising their fundamental capabilities. Specifically, the Action Prism (AP), is introduced to distill motion information from reference videos, which requires training on only a small dataset. Leveraging the knowledge from pre-trained VDMs, EchoReel incorporates new action features into VDMs through the additional layers, eliminating the need for any further fine-tuning of untrained actions. Extensive experiments demonstrate that EchoReel is not merely replicating the whole content from references, and it significantly improves the generation of realistic actions, even in situations where existing VDMs might directly fail.
Semantic Prompting with Image-Token for Continual Learning
Mar 18, 2024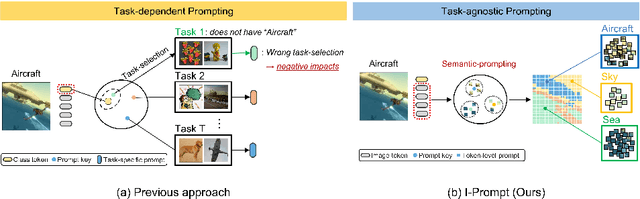
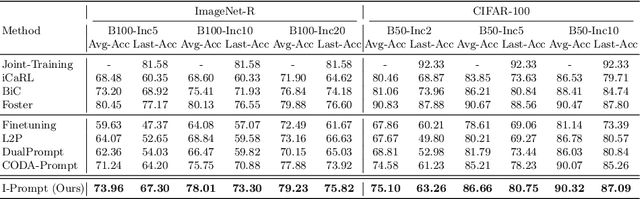
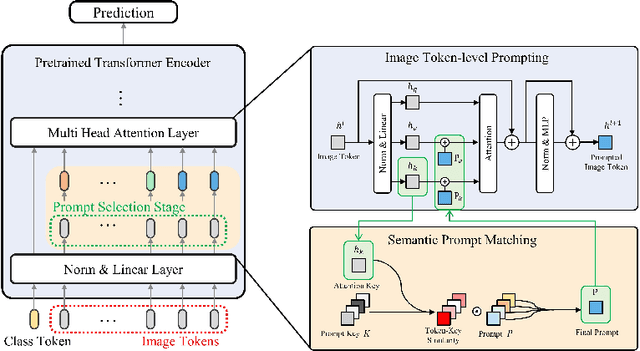
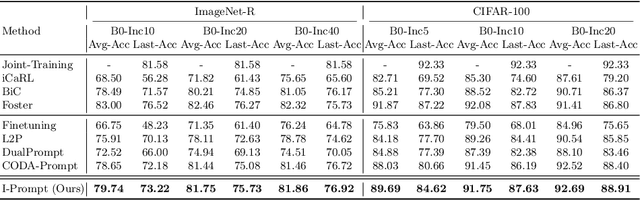
Continual learning aims to refine model parameters for new tasks while retaining knowledge from previous tasks. Recently, prompt-based learning has emerged to leverage pre-trained models to be prompted to learn subsequent tasks without the reliance on the rehearsal buffer. Although this approach has demonstrated outstanding results, existing methods depend on preceding task-selection process to choose appropriate prompts. However, imperfectness in task-selection may lead to negative impacts on the performance particularly in the scenarios where the number of tasks is large or task distributions are imbalanced. To address this issue, we introduce I-Prompt, a task-agnostic approach focuses on the visual semantic information of image tokens to eliminate task prediction. Our method consists of semantic prompt matching, which determines prompts based on similarities between tokens, and image token-level prompting, which applies prompts directly to image tokens in the intermediate layers. Consequently, our method achieves competitive performance on four benchmarks while significantly reducing training time compared to state-of-the-art methods. Moreover, we demonstrate the superiority of our method across various scenarios through extensive experiments.
GenFlow: Generalizable Recurrent Flow for 6D Pose Refinement of Novel Objects
Mar 18, 2024
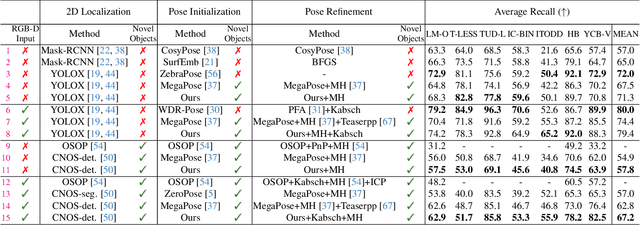
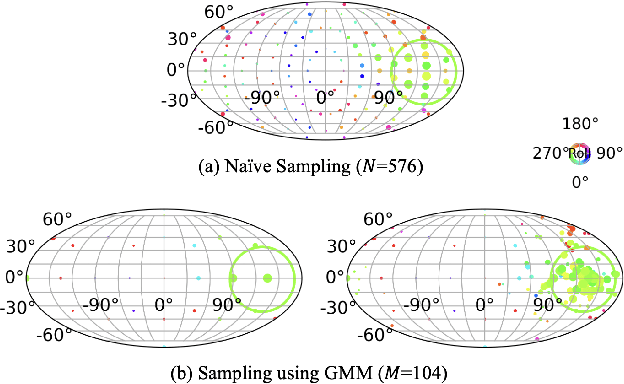
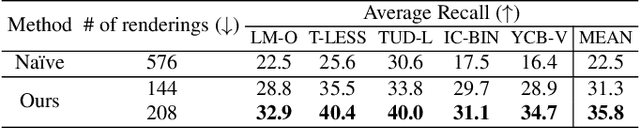
Despite the progress of learning-based methods for 6D object pose estimation, the trade-off between accuracy and scalability for novel objects still exists. Specifically, previous methods for novel objects do not make good use of the target object's 3D shape information since they focus on generalization by processing the shape indirectly, making them less effective. We present GenFlow, an approach that enables both accuracy and generalization to novel objects with the guidance of the target object's shape. Our method predicts optical flow between the rendered image and the observed image and refines the 6D pose iteratively. It boosts the performance by a constraint of the 3D shape and the generalizable geometric knowledge learned from an end-to-end differentiable system. We further improve our model by designing a cascade network architecture to exploit the multi-scale correlations and coarse-to-fine refinement. GenFlow ranked first on the unseen object pose estimation benchmarks in both the RGB and RGB-D cases. It also achieves performance competitive with existing state-of-the-art methods for the seen object pose estimation without any fine-tuning.
Graph Partial Label Learning with Potential Cause Discovering
Mar 18, 2024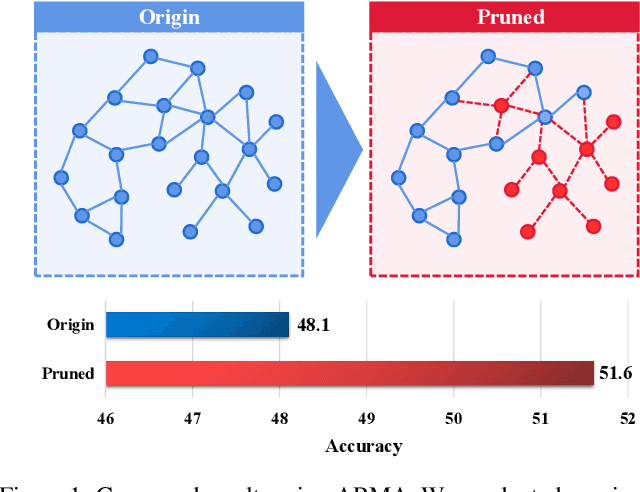
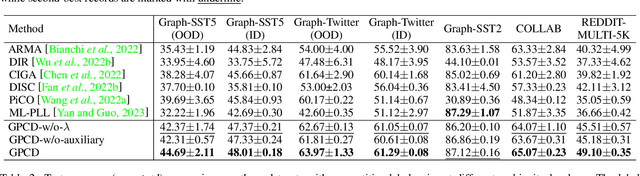
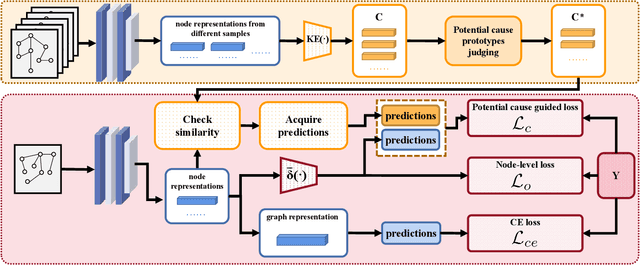
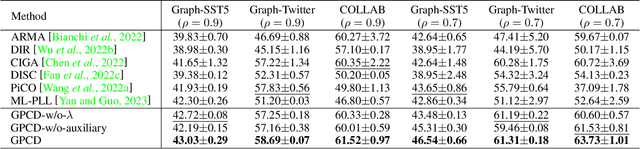
Graph Neural Networks (GNNs) have gained considerable attention for their potential in addressing challenges posed by complex graph-structured data in diverse domains. However, accurately annotating graph data for training is difficult due to the inherent complexity and interconnectedness of graphs. To tackle this issue, we propose a novel graph representation learning method that enables GNN models to effectively learn discriminative information even in the presence of noisy labels within the context of Partially Labeled Learning (PLL). PLL is a critical weakly supervised learning problem, where each training instance is associated with a set of candidate labels, including both the true label and additional noisy labels. Our approach leverages potential cause extraction to obtain graph data that exhibit a higher likelihood of possessing a causal relationship with the labels. By incorporating auxiliary training based on the extracted graph data, our model can effectively filter out the noise contained in the labels. We support the rationale behind our approach with a series of theoretical analyses. Moreover, we conduct extensive evaluations and ablation studies on multiple datasets, demonstrating the superiority of our proposed method.
AGRNav: Efficient and Energy-Saving Autonomous Navigation for Air-Ground Robots in Occlusion-Prone Environments
Mar 18, 2024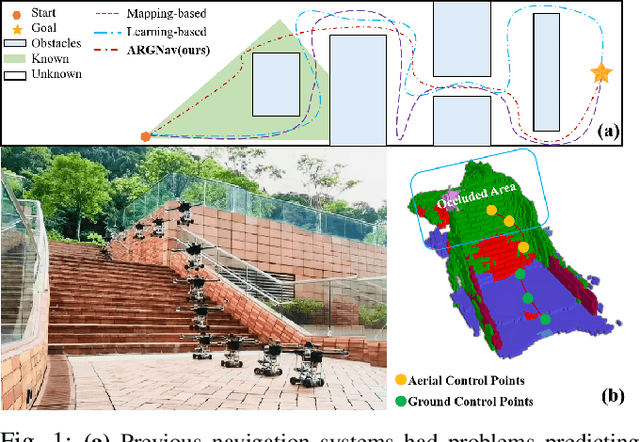
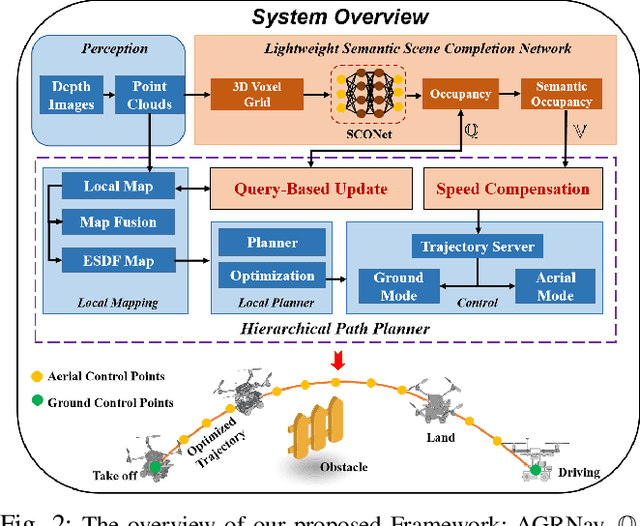
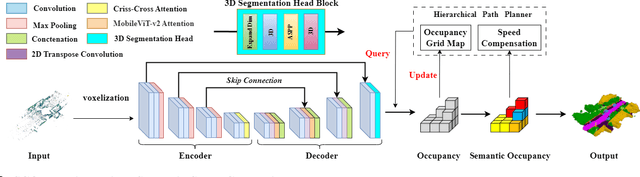
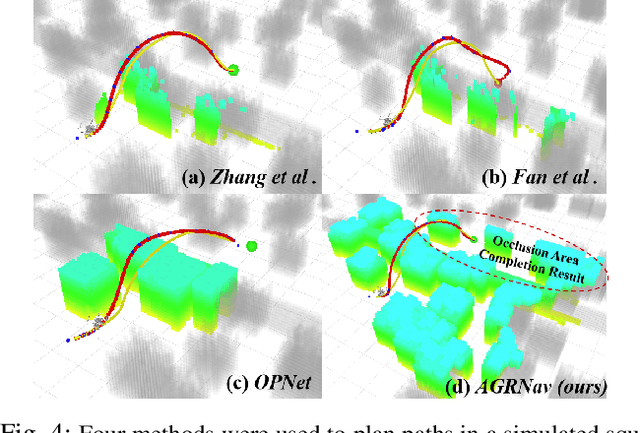
The exceptional mobility and long endurance of air-ground robots are raising interest in their usage to navigate complex environments (e.g., forests and large buildings). However, such environments often contain occluded and unknown regions, and without accurate prediction of unobserved obstacles, the movement of the air-ground robot often suffers a suboptimal trajectory under existing mapping-based and learning-based navigation methods. In this work, we present AGRNav, a novel framework designed to search for safe and energy-saving air-ground hybrid paths. AGRNav contains a lightweight semantic scene completion network (SCONet) with self-attention to enable accurate obstacle predictions by capturing contextual information and occlusion area features. The framework subsequently employs a query-based method for low-latency updates of prediction results to the grid map. Finally, based on the updated map, the hierarchical path planner efficiently searches for energy-saving paths for navigation. We validate AGRNav's performance through benchmarks in both simulated and real-world environments, demonstrating its superiority over classical and state-of-the-art methods. The open-source code is available at https://github.com/jmwang0117/AGRNav.
TCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Mar 18, 2024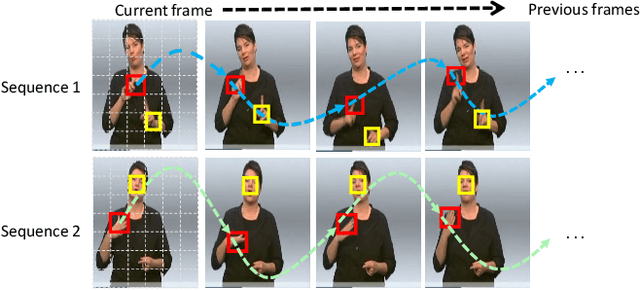
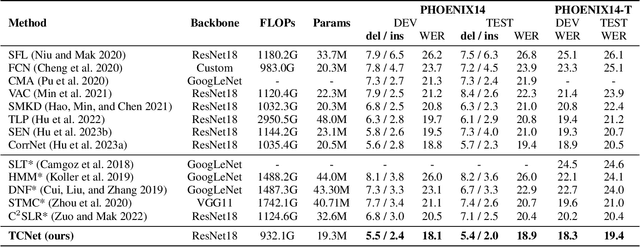
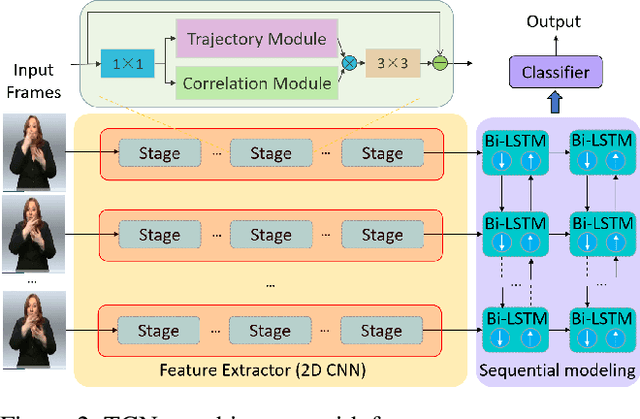
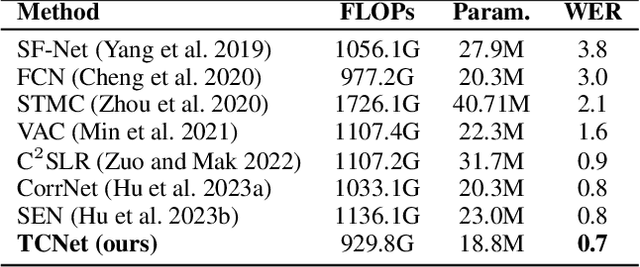
A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.
Layer-diverse Negative Sampling for Graph Neural Networks
Mar 18, 2024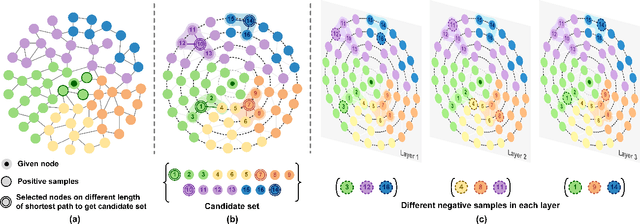
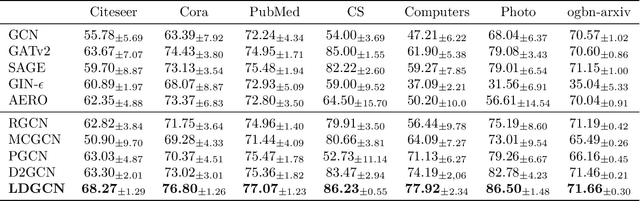
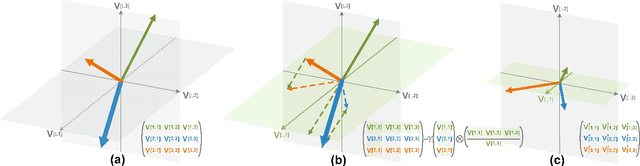
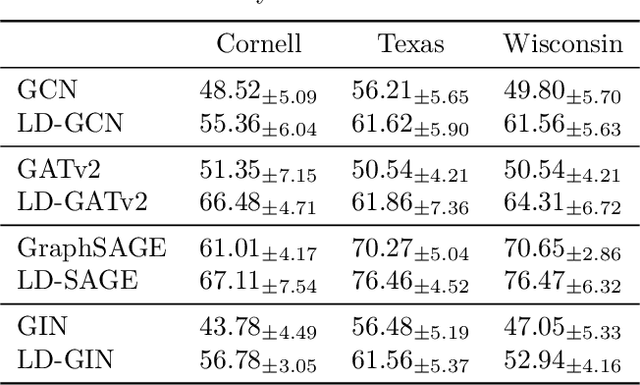
Graph neural networks (GNNs) are a powerful solution for various structure learning applications due to their strong representation capabilities for graph data. However, traditional GNNs, relying on message-passing mechanisms that gather information exclusively from first-order neighbours (known as positive samples), can lead to issues such as over-smoothing and over-squashing. To mitigate these issues, we propose a layer-diverse negative sampling method for message-passing propagation. This method employs a sampling matrix within a determinantal point process, which transforms the candidate set into a space and selectively samples from this space to generate negative samples. To further enhance the diversity of the negative samples during each forward pass, we develop a space-squeezing method to achieve layer-wise diversity in multi-layer GNNs. Experiments on various real-world graph datasets demonstrate the effectiveness of our approach in improving the diversity of negative samples and overall learning performance. Moreover, adding negative samples dynamically changes the graph's topology, thus with the strong potential to improve the expressiveness of GNNs and reduce the risk of over-squashing.
D-Cubed: Latent Diffusion Trajectory Optimisation for Dexterous Deformable Manipulation
Mar 19, 2024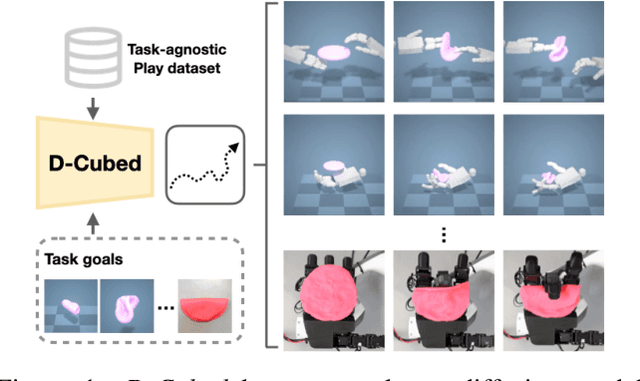

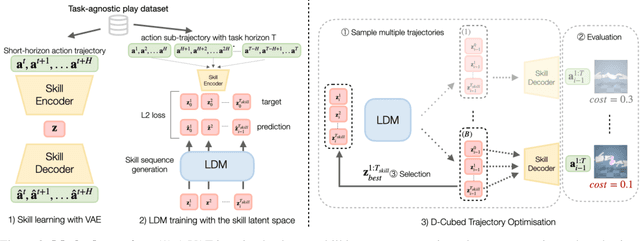
Mastering dexterous robotic manipulation of deformable objects is vital for overcoming the limitations of parallel grippers in real-world applications. Current trajectory optimisation approaches often struggle to solve such tasks due to the large search space and the limited task information available from a cost function. In this work, we propose D-Cubed, a novel trajectory optimisation method using a latent diffusion model (LDM) trained from a task-agnostic play dataset to solve dexterous deformable object manipulation tasks. D-Cubed learns a skill-latent space that encodes short-horizon actions in the play dataset using a VAE and trains a LDM to compose the skill latents into a skill trajectory, representing a long-horizon action trajectory in the dataset. To optimise a trajectory for a target task, we introduce a novel gradient-free guided sampling method that employs the Cross-Entropy method within the reverse diffusion process. In particular, D-Cubed samples a small number of noisy skill trajectories using the LDM for exploration and evaluates the trajectories in simulation. Then, D-Cubed selects the trajectory with the lowest cost for the subsequent reverse process. This effectively explores promising solution areas and optimises the sampled trajectories towards a target task throughout the reverse diffusion process. Through empirical evaluation on a public benchmark of dexterous deformable object manipulation tasks, we demonstrate that D-Cubed outperforms traditional trajectory optimisation and competitive baseline approaches by a significant margin. We further demonstrate that trajectories found by D-Cubed readily transfer to a real-world LEAP hand on a folding task.
Towards Multimodal In-Context Learning for Vision & Language Models
Mar 19, 2024
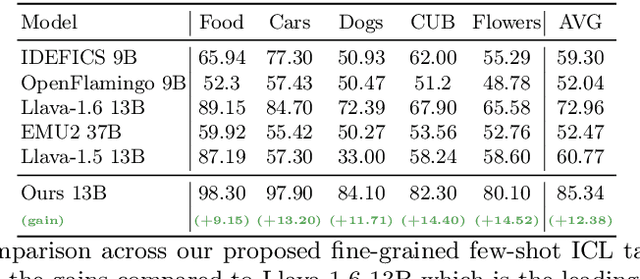
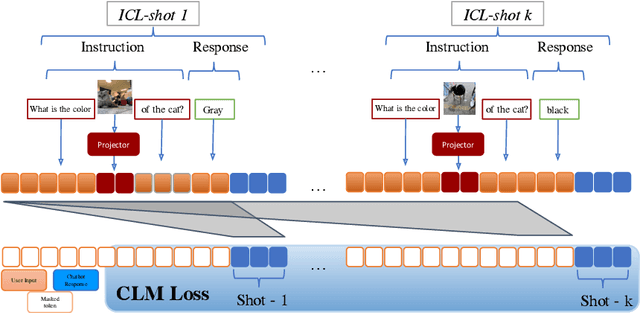
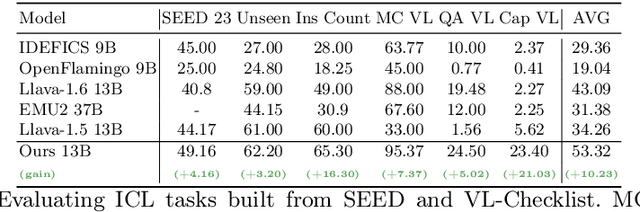
Inspired by the emergence of Large Language Models (LLMs) that can truly understand human language, significant progress has been made in aligning other, non-language, modalities to be `understandable' by an LLM, primarily via converting their samples into a sequence of embedded language-like tokens directly fed into the LLM (decoder) input stream. However, so far limited attention has been given to transferring (and evaluating) one of the core LLM capabilities to the emerging VLMs, namely the In-Context Learning (ICL) ability, or in other words to guide VLMs to desired target downstream tasks or output structure using in-context image+text demonstrations. In this work, we dive deeper into analyzing the capabilities of some of the state-of-the-art VLMs to follow ICL instructions, discovering them to be somewhat lacking. We discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot (ICL) demonstrations, likely due to their lack of `direct' ICL instruction tuning. To test this conjecture, we propose a simple, yet surprisingly effective, strategy of extending a common VLM alignment framework with ICL support, methodology, and curriculum. We explore, analyze, and provide insights into effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. We also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.